Recovery Procedure for Ultra-M AutoVNF Cluster Failure - vEPC
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Contents
Introduction
This document describes the steps required to recover the Ultra Automation Services (UAS) or AutoVNF Cluster failure in an Ultra-M setup that hosts StarOS Virtual Network Functions (VNFs).
Background Information
Ultra-M is a pre-packaged and validated virtualized mobile packet core solution that is designed in order to simplify the deployment of VNFs.
Ultra-M solution consists of the mentoned Virtual Machine (VM) types:
- Auto-IT
- Auto-Deploy
- UAS or AutoVNF
- Element Manager (EM)
- Elastic Services Controller (ESC)
- Control Function (CF)
- Session Function (SF)
The high-level architecture of Ultra-M and the components involved are depicted in this image:
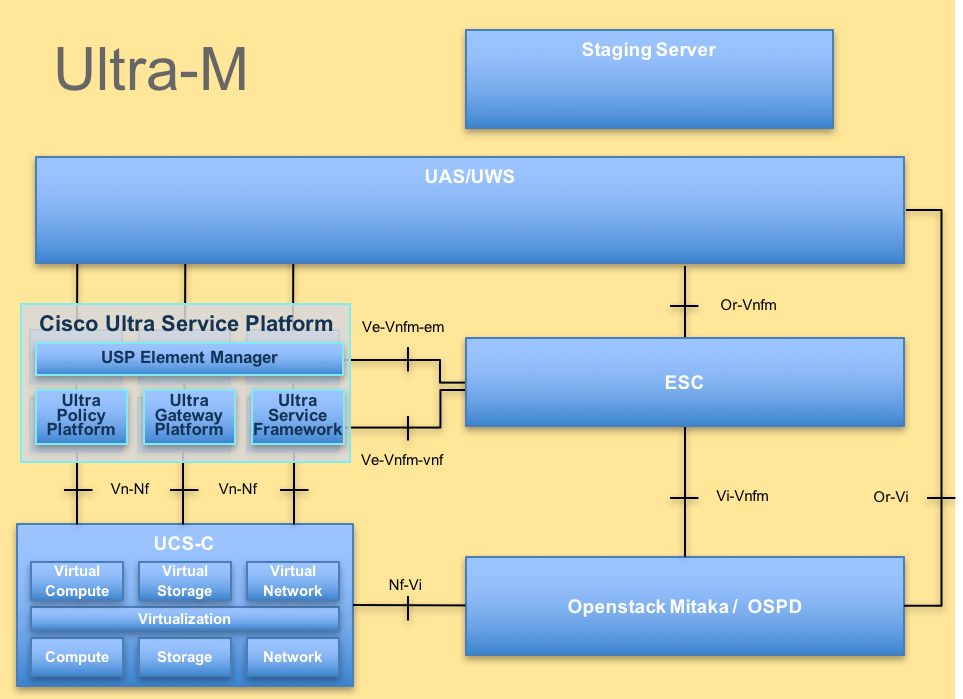 UltraM Architecture
UltraM Architecture
This document is intended for the Cisco personnel who are familiar with Cisco Ultra-M platform.
Note: Ultra M 5.1.x release is considered in order to define the procedures in this document.
Abbreviations
| VNF | Virtual Network Function |
| CF | Control Function |
| SF | Service Function |
| ESC | Elastic Service Controller |
| MOP | Method of Procedure |
| OSD | Object Storage Disks |
| HDD | Hard Disk Drive |
| SSD | Solid State Drive |
| VIM | Virtual Infrastructure Manager |
| VM | Virtual Machine |
| EM | Element Manager |
| UAS | Ultra Automation Services |
| UUID | Universally Unique IDentifier |
Workflow of the MoP
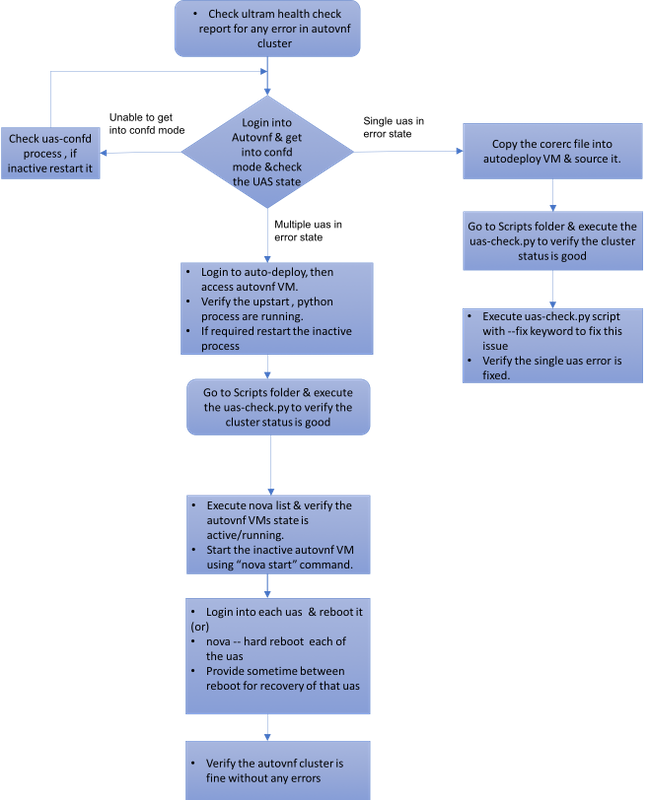
Case 1. Recovery of Single Failure of UAS Cluster
Status Check
1. Ultra-M Manager performs the health check of the Ultra-M node. Navigate to the reports /var/log/cisco/ultram-health/ directory and grep for the UAS report.
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. The expected status of UAS cluster will be as depicted, where all the three UAS are alive.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
Failure to Connect to Confd Server when you Try to Connect to UAS
1. In some cases, you will not be able to connect to the confd server.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. Check the status of the uas-confd process.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. If the confd server does not run, restart the service.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
Recover UAS from Error State
1. In case of failure of one AutoVNF among the cluster, UAS cluster shows one of the UAS in Error state .
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. Copy the corerc file (rc file of your VNF) from /home/stack in OSPD server to AutoDeploy and source it.
3. Check the status of your UAS/AutoVNF with the use of uas-check.py script . autovnf1 is the AutoVNF name.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. Recover the UAS with the use of uas-check.py script and add --fix keyword.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. You will see that the newly created UAS is alive and part of the cluster.
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Case 2. All Three UAS (AutoVNF) are in Error State
1. Ultra-M Manager performs the health check of the Ultra-M node.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. As observed in the output, Ultra-M manager reports that there is a failure for AutoVNF and it shows that all the three UAS of the cluster are in Error state.
Check the UAS Health with uas-check.py Script
1. Log in to the Auto-Deploy and check if you can access the AutoVNF UAS and get the status.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. From Auto-Deploy, Secure Shell (SSH) to AutoVNF node and enter into confd mode. Check the status with show uas.
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. It is recommended to check the status in all three UAS nodes.
Check the State of the VMs on the OpenStack Level
Check the status of the AutoVNF VMs in the nova list. If required, perform nova start in order to start the shutoff VM.
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Check the Zookeeper View
1. Check the state of the zookeeper in order to verify the mode as leader.
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. Zookeeper normally should be up.
Troubleshoot the AutoVNF - Processes and Tasks
1. Identify the reason for the Error state of the nodes. For AutoVNF to run, there is a set of processes that must be up and running as shown:
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. Verify that these python processes are running:
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. If any of the expected processes are not in start/running state, restart the process and check the status. If it still shows in Error state then follow the procedure mentioned in the next section in order to fix this issue.
Fix for Multiple UAS in Error State
1. nova --hard reboot <name of the VM> from OSPD, give some time for recovery of this VM before you proceed to the next UAS. Do it on all UAS VMs.
or
2.Log in to each of the UAS and use sudo reboot. Wait for the recovery and then proceed to other UAS VMs.
For transaction logs, check:
/var/log/upstart/autovnf.log
show logs xxx | display xml
This will fix the issue and recover the UAS from Error state.
1. Verify the same with the use of ultram_health_check report.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
Contributed by Cisco Engineers
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)