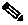Feedback
Feedback
Table Of Contents
Configuring IP Routing Protocols
Cisco's Implementation of IP Routing Protocols
The Interior Gateway Protocols
The Exterior Gateway Protocols
IP Routing Protocols Task List
Create the IGRP Routing Process
Allow Point-to-Point Updates for IGRP
Define Unequal-Cost Load Balancing
Adjust the IGRP Metric Weights
Enforce a Maximum Network Diameter
Cisco's Implementation of Enhanced IGRP
Enhanced IGRP Configuration Task List
Transition from IGRP to Enhanced IGRP
Configure IP Enhanced IGRP-Specific Parameters
Define Unequal-Cost Load Balancing
Adjust the IP Enhanced IGRP Metric Weights
Configure Summary Aggregate Addresses
Monitor IP Enhanced IGRP on an IP Network
Configure Protocol-Independent Parameters
Redistribute Routing Information
Set Metrics for Redistributed Routes
Adjust the Interval between Hello Packets and the Hold Time
Configure OSPF Interface Parameters
Configure OSPF over Different Physical Networks
Configure Your OSPF Network Type
Configure OSPF for Nonbroadcast Neworks
Configure OSPF Area Parameters
Configure Route Summarization between OSPF Areas
Configure Route Summarization When Redistributing Routes into OSPF
Force the Router ID Choice with a Loopback Interface
Configure OSPF on Simplex Ethernet Interfaces
Configure Route Calculation Timers
Disable Default OSPF Metric Calculation Based on Bandwidth
Running IGRP and RIP Concurrently
Allow Point-to-Point Updates for RIP
Advanced BGP Configuration Tasks
Configure BGP Interactions with IGPs
Configure BGP Administrative Weights
Configure BGP Route Filtering by Neighbor
Configure BGP Path Filtering by Neighbor
Disable Next-Hop Processing on BGP Updates
Configure the Multi Exit Discriminator Metric
Advanced BGP Configuration Tasks
Use Route Maps to Modify Updates
Configure BGP Neighbor Templates
Reset EBGP Connections Immediately Upon Link Failure
Disable Automatic Summarization of Network Numbers
Configure BGP Community Filtering
Configure a Routing Domain Confederation
Modify Parameters While Updating the IP Routing Table
Change the Local Preference Value
Base Path Selection on MEDs from Other Autonomous Systems
Configure EGP Neighbor Relationships
Configure Third-Party EGP Support
Configure Backup Access Servers
Define a Central Routing Information Manager (Core Gateway)
Configure IP Multicast Routing
Cisco's Implementation of IP Multicast Routing
Internet Group Management Protocol (IGMP)
Protocol-Independent Multicast (PIM) Protocol
Distance Vector Multicast Routing Protocol (DVMRP)
IP Multicast Routing Configuration Task List
Enable IP Multicast Routing on the Access Server
Configure an Access Server to Be a Member of a Group
Configure the Host-Query Message Interval
Control Access to IP Multicast Groups
Configure DVMRP Interoperability
Advertise Network 0.0.0.0 to DVMRP Neighbors
Configure an IP Multicast Static Route
Disable Fast Switching of IP Multicast
Control the Transmission Rate to a Multicast Group
Enable PIM Nonbroadcast, Multiaccess (NBMA) Mode
Configure Routing Protocol-Independent Features
Use Variable-Length Subnet Masks
Redistribute Routing Information
Prevent Routing Updates through an Interface
Control the Advertising of Routes in Routing Updates
Control the Processing of Routing Updates
Apply Offsets to Routing Metrics
Filter Sources of Routing Information
Adjust the Interval between Hello Packets and the Hold Time (EIGRP)
Enable or Disable Split Horizon
Monitor and Maintain the IP Network
Clear Caches, Tables, and Databases
Display System and Network Statistics
IP Routing Protocol Configuration Examples
Variable-Length Subnet Masks Example
Overriding Static Routes with Dynamic Protocols Example
OSPF Point-to-Multipoint Example
Static Routing Redistribution Examples
IP Enhanced IGRP Redistribution Examples
RIP and IGRP Redistribution Example
RIP and IP Enhanced IGRP Redistribution Examples
OSPF Routing and Route Redistribution Examples
Example 1: Basic OSPF Configuration
Example 2: Another Basic OSPF Configuration
Example 3: Internal, Area Border, and Autonomous System Boundary Routers
Example 4: Complex OSPF Configuration
BGP Route Advertisement and Redistribution Examples
Example 1: Simple BGP Route Advertisement
Example 2: Mutual Route Redistribution
Default Metric Values Redistribution Examples
IGRP Feasible Successor Relationship Example
BGP Path Filtering by Neighbor Example
BGP Basic Neighbor Specification Examples
Using Access Lists to Specify Neighbors
BGP Community Examples with Route Maps
TCP MD5 Authentication for BGP Example
Example for an IBGP Peer Group
Example for an EBGP Peer Group
Third-Party EGP Support Example
Backup EGP Access Server Example
Autonomous System within EGP Example
Administrative Distance Examples
IP Multicast Routing Configuration Examples
Configure an Access Server to Operate in Dense Mode Example
Configure an Access Server to Operate in Sparse Mode Example
Configure DVMRP Interoperability Examples
Configuring IP Routing Protocols
This chapter describes how to configure the various Internet Protocol (IP) routing protocols. For a complete description of the commands listed in this chapter, refer to the "IP Routing Protocols Commands" chapter of the Access and Communication Servers Command Reference publication. For information on configuring the IP protocol, refer to the "IP Commands" chapter of this publication.
Cisco's Implementation of IP Routing Protocols
Cisco's implementation of each IP routing protocol is discussed in detail at the beginning of the individual protocol configuration sections throughout this chapter.
IP routing protocols are divided into two classes: Interior Gateway Protocols (IGPs) and Exterior Gateway Protocols (EGPs). The IGPs and EGPs that Cisco supports are listed in the next two sections.
Note
Many routing protocol specifications refer to access servers as gateways, so the word gateway often appears as part of routing protocol names. However, an access server usually is defined as a Layer 3 internetworking device, whereas a protocol translation gateway usually is defined as a Layer 7 internetworking device. The reader should understand that regardless of whether a routing protocol name contains the word "gateway," routing protocol activities occur at Layer 3 of the OSI reference model.
The Interior Gateway Protocols
Interior protocols are used for routing networks that are under a common network administration. All IP Interior Gateway Protocols must be specified with a list of associated networks before routing activities can begin. A routing process listens to updates from other access servers on these networks and broadcasts its own routing information on those same networks. The interior routing protocols supported are as follows:
•
•
•
•
The Exterior Gateway Protocols
Exterior protocols exchange routing information between networks that do not share a common administration. The supported exterior routing protocols are as follows:
•
•
IP Exterior Gateway Protocols require three pieces of information before routing can begin:
•
•
•
Router Discovery Protocols
Our access servers also support two access server discovery protocols, Gateway Discovery Protocol (GDP) and ICMP Router Discovery Protocol (IRDP), which allow hosts to locate access servers.
GDP was developed by Cisco and is not an industry standard. Examples of unsupported GDP clients can be obtained upon request from Cisco. Our IRDP implementation fully conforms to the access server discovery protocol outlined in RFC 1256.
Multiple Routing Protocols
You can configure multiple routing protocols in a single access server to connect networks that use different routing protocols. You can, for example, run RIP on one subnetted network, IGRP on another subnetted network, and exchange routing information between them in a controlled fashion. The available routing protocols were not designed to interoperate with one another, so each protocol collects different types of information and reacts to topology changes in its own way. For example, RIP uses a hop-count metric and IGRP uses a five-element vector of metric information. In the case where routing information is being exchanged between different networks that use different routing protocols, there are many configuration options that allow you to filter the exchange of routing information.
Our access servers can handle simultaneous operation of up to 30 dynamic IP routing processes.The combination of routing processes on an access server can consist of the following protocols (with the limits noted):
•
•
•
•
•
IP Routing Protocols Task List
With any of the IP routing protocols, you need to create the routing process, associate networks with the routing process, and customize the routing protocol for your particular network.
You will need to perform some combination of the tasks in the following sections to configure IP routing protocols:
•
•
•
See the end of this chapter for IP routing protocol configuration examples.
Determine a Routing Process
Choosing a routing protocol is a complex task. When choosing a routing protocol, consider (at least) the following:
•
•
•
•
•
•
•
•
The following sections describe the configuration tasks associated with each supported routing protocol. This publication does not provide in-depth information on how to choose routing protocols; you must choose routing protocols that best suit your needs.
Configure IGRP
The Interior Gateway Routing Protocol (IGRP) is a dynamic distance-vector routing protocol designed by Cisco Systems in the mid-1980s for routing in an autonomous system that contains large, arbitrarily complex networks with diverse bandwidth and delay characteristics.
Cisco's IGRP Implementation
IGRP uses a combination of user-configurable metrics, including internetwork delay, bandwidth, reliability, and load.
IGRP also advertises three types of routes: interior, system, and exterior, as shown in Figure 19-1. Interior routes are routes between subnets in the network attached to an access server interface. If the network attached to an access server is not subnetted, IGRP does not advertise interior routes.
Figure 19-1 Interior, System, and Exterior Routes
System routes are routes to networks within an autonomous system. the access server derives system routes from directly connected network interfaces and system route information provided by other IGRP-speaking access servers. System routes do not include subnet information.
Exterior routes are routes to networks outside the autonomous system that are considered when identifying a gateway of last resort. the access server chooses a gateway of last resort from the list of exterior routes that IGRP provides. the access server uses the gateway (access server) of last resort if it does not have a better route for a packet and the destination is not a connected network. If the autonomous system has more than one connection to an external network, different access servers can choose different exterior access servers as the gateway of last resort.
IGRP Updates
By default, an access server running IGRP sends an update broadcast every 90 seconds. It declares a route inaccessible if it does not receive an update from the first access server in the route within three update periods (270 seconds). After seven update periods (630 seconds), the access server removes the route from the routing table.
IGRP uses flash update and poison reverse updates to speed up the convergence of the routing algorithm. Flash update is the sending of an update sooner than the standard periodic update interval of notifying other access servers of a metric change. Poison reverse updates are intended to defeat larger routing loops caused by increases in routing metrics. The poison reverse updates are sent to remove a route and place it in holddown, which keeps new routing information from being used for a certain period of time.
IGRP Configuration Task List
To configure IGRP, perform the tasks in the following sections. Creating the IGRP routing process is mandatory; the other tasks described are optional.
•
•
•
•
•
Create the IGRP Routing Process
To create the IGRP routing process, perform the following required tasks:
Step 1
See Table 2-1 earlier in this manual.
Step 2
router igrp process-number
Step 3
network network-number
IGRP sends updates to the interfaces in the specified networks. If an interface's network is not specified, it will not be advertised in any IGRP update. You are not required to have a registered autonomous system number to use IGRP. If you do not have a registered number, you can create your own. However, if you do have a registered number, we recommend that you use it to identify the IGRP process.
Allow Point-to-Point Updates for IGRP
Because IGRP is normally a broadcast protocol, in order for IGRP routing updates to reach point-to-point or nonbroadcast networks, you must configure the access server to permit this exchange of routing information.
To permit information exchange, perform the following task in router configuration mode:
Define a neighboring access server with which to exchange point-to-point routing information.
neighbor ip-address
To control the set of interfaces that you want to exchange routing updates with, you can disable the sending of routing updates on specified interfaces by configuring the passive-interface command. See the "Filter Routing Information" section later in this chapter.
Define Unequal-Cost Load Balancing
IGRP can simultaneously use an asymmetric set of paths for a given destination. This feature is known as unequal-cost load balancing. Unequal-cost load balancing allows traffic to be distributed among multiple (up to four) unequal-cost paths to provide greater overall throughput and reliability. Alternate path variance (that is, the difference in desirability between the primary and alternate paths) is used to determine the feasibility of a potential route. An alternate route is feasible if the next access server in the path is closer to the destination (has a lower metric value) than the current access server and if the metric for the entire alternate path is within the variance. Only paths that are feasible can be used for load balancing and included in the routing table. These conditions limit the number of cases in which load balancing can occur, but ensure that the dynamics of the network will remain stable.
The following general rules apply to IGRP unequal-cost load balancing:
•
•
•
If these conditions are met, the route is deemed feasible and can be added to the routing table.
By default, the amount of variance is set to one (equal-cost load balancing). You can define how much worse an alternate path can be before that path is disallowed by performing the following task in router configuration mode:
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for an example of configuring IGRP feasible successor.
Note
Control Traffic Distribution
By default, if IGRP or Enhanced IGRP have multiple routes of unequal cost to the same destination, the access server will distribute traffic among the different routes by giving each route a share of the traffic in inverse proportion to its metric. If you want to have faster convergence to alternate routes but you do not want to send traffic across inferior routes in the normal case, you might prefer to have no traffic flow along routes with higher metrics.
To control how traffic is distributed among multiple routes of unequal cost, perform the following task in router configuration mode:
Distribute traffic proportionately to the ratios of metrics, or by the minimum-cost route.
traffic-share {balanced | min}
Adjust the IGRP Metric Weights
You have the option of altering the default behavior of IGRP routing and metric computations. For example, you can tune system behavior to enable transmissions via satellite. Although IGRP metric defaults were carefully selected to provide excellent operation in most networks, you can adjust the IGRP metric. Adjusting IGRP metric weights can dramatically affect network performance, however, so ensure you make all metric adjustments carefully.
To adjust the IGRP metric weights, perform the following task in router configuration mode. Due to the complexity of this task, we recommend that you only perform it with guidance from an experienced system designer.
By default, the IGRP composite metric is a 24-bit quantity that is a sum of the segment delays and the lowest segment bandwidth (scaled and inverted) for a given route. For a network of homogeneous media, this metric reduces to a hop count. For a network of mixed media (FDDI, Ethernet, and serial lines running from 9600 bps to T1 rates), the route with the lowest metric reflects the most desirable path to a destination.
Disable Holddown
When an access server learns that a network is at a greater distance than was previously known, or it learns the network is down, the route to that network is placed into holddown. During the holddown period, the route is advertised, but incoming advertisements about that network from any access server other than the one that originally advertised the network's new metric will be ignored. This mechanism is often used to help avoid routing loops in the network, but has the effect of increasing the topology convergence time. To disable holddowns with IGRP, perform the following task in router configuration mode. All access servers in an IGRP autonomous system must be consistent in their use of holddowns.
Enforce a Maximum Network Diameter
the access server enforces a maximum diameter to the IGRP network. Routes whose hop counts exceed this diameter will not be advertised. The default maximum diameter is 100 hops. The maximum diameter is 255 hops.
To configure the maximum diameter, perform the following task in router configuration mode:
Validate Source IP Addresses
To disable the default function that validates the source IP addresses of incoming routing updates, perform the following task in router configuration mode:
Disable the checking and validation of the source IP address of incoming routing updates.
no validate-update-source
Configure Enhanced IGRP
Enhanced IGRP is an enhanced version of the Interior Gateway Routing Protocol (IGRP) developed by Cisco Systems, Inc. Enhanced IGRP uses the same distance vector algorithm and distance information as IGRP. However, the convergence properties and the operating efficiency of Enhanced IGRP have improved significantly over IGRP.
The convergence technology is based on research conducted at SRI International and employs an algorithm referred to as the Diffusing Update Algorithm (DUAL). This algorithm guarantees loop-free operation at every instant throughout a route computation and allows all access servers involved in a topology change to synchronize at the same time. Access servers that are not affected by topology changes are not involved in recomputations. The convergence time with DUAL rivals that of any other existing routing protocol.
Cisco's Implementation of Enhanced IGRP
IP Enhanced IGRP provides the following features:
•
•
Enhanced IGRP offers the following features:
•
•
•
•
•
•
•
Enhanced IGRP has four basic components:
•
•
•
•
Neighbor discovery/recovery is the process that routers use to dynamically learn of other routers on their directly attached networks. Routers must also discover when their neighbors become unreachable or inoperative. Neighbor discovery/recovery is achieved with low overhead by periodically sending small hello packets. As long as hello packets are received, a router can determine that a neighbor is alive and functioning. Once this status is determined, the neighboring routers can exchange routing information.
The reliable transport protocol is responsible for guaranteed, ordered delivery of Enhanced IGRP packets to all neighbors. It supports intermixed transmission of multicast and unicast packets. Some Enhanced IGRP packets must be transmitted reliably and others need not be. For efficiency, reliability is provided only when necessary. For example, on a multiaccess network that has multicast capabilities, such as Ethernet, it is not necessary to send hellos reliably to all neighbors individually. Therefore, Enhanced IGRP sends a single multicast hello with an indication in the packet informing the receivers that the packet need not be acknowledged. Other types of packets, such as updates, require acknowledgment, and this is indicated in the packet. The reliable transport has a provision to send multicast packets quickly when there are unacknowledged packets pending. Doing so helps ensure that convergence time remains low in the presence of varying speed links.
The DUAL finite state machine embodies the decision process for all route computations. It tracks all routes advertised by all neighbors. DUAL uses the distance information, known as a metric, to select efficient, loop-free paths. DUAL selects routes to be inserted into a routing table based on feasible successors. A successor is a neighboring router used for packet forwarding that has a least-cost path to a destination that is guaranteed not to be part of a routing loop. When there are no feasible successors but there are neighbors advertising the destination, a recomputation must occur. This is the process whereby a new successor is determined. The amount of time it takes to recompute the route affects the convergence time. Even though the recomputation is not processor intensive, it is advantageous to avoid recomputation if it is not necessary. When a topology change occurs, DUAL will test for feasible successors. If there are feasible successors, it will use any it finds in order to avoid unnecessary recomputation.
The protocol-dependent modules are responsible for network layer protocol-specific tasks. An example is the IP Enhanced IGRP module, which is responsible for sending and receiving Enhanced IGRP packets that are encapsulated in IP. It is also responsible for parsing Enhanced IGRP packets and informing DUAL of the new information received. IP Enhanced IGRP asks DUAL to make routing decisions, but the results are stored in the IP routing table. Also, IP Enhanced IGRP is responsible for redistributing routes learned by other IP routing protocols.
Enhanced IGRP Configuration Task List
To configure IP Enhanced IGRP, complete the tasks in the following sections. At a minimum, you must enable IP Enhanced IGRP. The remaining tasks are optional.
•
•
•
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for configuration examples.
Enable IP Enhanced IGRP
To create an IP Enhanced IGRP routing process, perform the following tasks:
IP Enhanced IGRP sends updates to the interfaces in the specified network(s). If you do not specify an interface's network, it will not be advertised in any IP Enhanced IGRP update.
Transition from IGRP to Enhanced IGRP
If you have access servers on your network that are configured for IGRP and you want to make a transition to routing Enhanced IGRP, you need to designate transition access servers that have both IGRP and Enhanced IGRP configured. In these cases, perform the tasks as noted in the previous section, "Create the IP Enhanced IGRP Routing Process," and also read the section "Configure IGRP" earlier in this chapter. You must use the same autonomous system number in order for routes to be redistributed automatically.
Configure IP Enhanced IGRP-Specific Parameters
To configure IP Enhanced IGRP-specific parameters, perform one or more of the following tasks:
•
•
•
•
Define Unequal-Cost Load Balancing
IP Enhanced IGRP can simultaneously use an asymmetric set of paths for a given destination. This feature is known as unequal-cost load balancing. Unequal-cost load balancing allows traffic to be distributed among up to four unequal-cost paths to provide greater overall throughput and reliability. Alternate path variance (the difference in desirability between the primary and alternate paths) is used to determine the feasibility of a potential route. An alternate route is feasible if the next access server in the path is closer to the destination (has a lower metric value) than the current access server and if the metric for the entire alternate path is within the variance. Only paths that are feasible can be used for load balancing and included in the routing table. These conditions limit the number of cases in which load balancing can occur, but ensure that the dynamics of the network will remain stable.
The following general rules apply to IP Enhanced IGRP unequal-cost load balancing:
•
•
•
If these conditions are met, the route is deemed feasible and can be added to the routing table.
By default, the amount of variance is set to one (equal-cost load balancing). To change the variance to define how much worse an alternate path can be before that path is disallowed, perform the following task in router configuration mode:
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for an example of configuring an IP Enhanced IGRP feasible successor.
Note
Adjust the IP Enhanced IGRP Metric Weights
You can adjust the default behavior of IP Enhanced IGRP routing and metric computations. For example, you can tune system behavior to allow for satellite transmission. Although IP Enhanced IGRP metric defaults have been carefully selected to provide excellent operation in most networks, you can adjust the IP Enhanced IGRP metric. Adjusting IP Enhanced IGRP metric weights can dramatically affect network performance, so be careful if you adjust them.
To adjust the IP Enhanced IGRP metric weights, perform the following task in router configuration mode:
Note
By default, the IP Enhanced IGRP composite metric is a 32-bit quantity that is a sum of the segment delays and the lowest segment bandwidth (scaled and inverted) for a given route. For a network of homogeneous media, this metric reduces to a hop count. For a network of mixed media (FDDI, Ethernet, and serial lines running from 9600 bps to T1 rates), the route with the lowest metric reflects the most desirable path to a destination.
Disable Route Summarization
You can configure IP Enhanced IGRP to perform automatic summarization of subnet routes into network-level routes. For example, you can configure subnet 172.16.1.0 to be advertised as 172.16.0.0 over interfaces that have subnets of 192.168.7.0 configured. Automatic summarization is performed when there are two or more network router configuration commands configured for the IP Enhanced IGRP process. By default, this feature is enabled.
To disable automatic summarization, perform the following task in router configuration mode:
Route summarization works in conjunction with the ip summary-address eigrp interface configuration command, in which additional summarization can be performed. If auto-summary is in effect, there usually is no need to configure network level summaries using the ip summary-address eigrp command.
Configure Summary Aggregate Addresses
You can configure a summary aggregate address for a specified interface. If there are any more-specific routes in the routing table, IP Enhanced IGRP will advertise the summary address out the interface with a metric equal to the minimum of all more-specific routes.
To configure a summary aggregate address, perform the following task in interface configuration mode:
Configure a summary aggregate address.
ip summary-address eigrp autonomous-system-number address mask
Monitor IP Enhanced IGRP on an IP Network
You can display access server statistics such as the contents of IP routing tables, caches, and databases. You can use the information displayed to determine resource utilization and solve network problems. You can also display information about node reachability and discover the routing path that your access server's packets are taking through the network.
To display various statistics, perform one or more of the following tasks at the EXEC prompt:
Configure Protocol-Independent Parameters
To configure protocol-independent parameters, perform one or more of the following tasks:
•
•
•
Redistribute Routing Information
In addition to running multiple routing protocols simultaneously, the router can redistribute information from one routing protocol to another. For example, you can instruct the router to readvertise IP Enhanced IGRP-derived routes using the RIP protocol, or to readvertise static routes using the IP Enhanced IGRP protocol. This capability applies to all the IP-based routing protocols.
You may also conditionally control the redistribution of routes between routing domains by defining a method known as route maps between the two domains.
To redistribute routes from one protocol into another, perform the following task in router configuration mode:
Redistribute routes from one routing protocol into another.
redistribute protocol autonomous-system-number [route-map map-tag]
To define route maps, perform the following task in global configuration mode:
Define any route maps needed to control distribution.
route-map map-tag [permit | deny] [sequence-number]
By default, the redistribution of default information between IP Enhanced IGRP processes is enabled. To disable the redistribution, perform the following task in router configuration mode:
Disable the redistribution of default information between IP Enhanced IGRP processes.
no default-information allowed {in | out}
Set Metrics for Redistributed Routes
The metrics of one routing protocol do not necessarily translate into the metrics of another. For example, the RIP metric is a hop count and the IP Enhanced IGRP metric is a combination of five quantities. In such situations, an artificial metric is assigned to the redistributed route. Because of this unavoidable tampering with dynamic information, carelessly exchanging routing information between different routing protocols can create routing loops, which can seriously degrade network operation.
To set metrics for redistributed routes, perform the first task when redistributing from IP Enhanced IGRP, and perform the second task when redistributing into IP Enhanced IGRP. Each task is done in router configuration mode.
Filter Routing Information
You can filter routing protocol information by performing the following tasks:
•
•
•
•
•
•
Use the information in the following sections to perform these tasks.
Prevent Routing Updates through an Interface
To prevent other routers on a local network from learning about routes dynamically, you can keep routing update messages from being sent through a router interface. This feature applies to all IP-based routing protocols except BGP and EGP.
To prevent routing updates through a specified interface, perform the following task in router configuration mode:
Suppress the sending of routing updates through a router interface.
passive-interface type number
Control the Advertising of Routes in Routing Updates
To control which routers learn about routes, you can control the advertising of routes in routing updates. To do this, perform the following task in router configuration mode:
Control the advertising of routes in routing updates.
distribute-list access-list-number out [interface-name |
routing-process | autonomous-system-number]
Control the Processing of Routing Updates
To control the processing of routes listed in incoming updates, perform the following task in router configuration mode:
Control which incoming route updates are processes.
distribute-list access-list-number in [interface-name]
Apply Offsets to Routing Metrics
To provide a local mechanism for increasing the value of routing metrics, you can apply an offset to routing metrics. To do so, perform the following task in router configuration mode:
Filter Sources of Routing Information
An administrative distance is a rating of the trustworthiness of a routing information source, such as an individual router or a group of routers. In a large network, some routing protocols and some routers can be more reliable than others as sources of routing information. Also, when multiple routing processes are running in the same router for IP, the same route may be advertised by more than one routing process. Specifying administrative distance values enables the router to discriminate between sources of routing information. The router always picks the route whose routing protocol has the lowest administrative distance.
There are no general guidelines for assigning administrative distances, because each network has its own requirements. You must determine a reasonable matrix of administrative distances for the network as a whole. shows the default administrative distance for various routing information sources.
Table 19-1 Default Administrative Distances
For example, consider a router using IP Enhanced IGRP and RIP. Suppose you trust the IP Enhanced IGRP-derived routing information more than the RIP-derived routing information. Because the default IP Enhanced IGRP administrative distance is lower than that for RIP, the router uses the IP Enhanced IGRP-derived information and ignores the RIP-derived information. However, if you lose the source of the IP Enhanced IGRP-derived information (for example, because of a power shutdown), the router uses the RIP-derived information until the IP Enhanced IGRP-derived information reappears.
Note
To filter sources of routing information, perform the following tasks in router configuration mode:
Filter on routing information sources.
distance eigrp internal-distance external-distance
Adjust the Interval between Hello Packets and the Hold Time
You can adjust the interval between hello packets and the hold time.
Routers periodically send hello packets to each other to dynamically learn of other routers on their directly attached networks. The routers use this information to discover who their neighbors are and to learn when their neighbors become unreachable or inoperative.
By default, hello packets are sent every 5 seconds. The exception is on nonbroadcast, mutiaccess (NBMA) media, where the default hello interval is 60 seconds. Low speed is considered to be a rate of T1 or slower, as specified with the bandwidth interface configuration command. The default hello interval remains 5 seconds for high speed NBMA networks. Note that for the purposes of Enhanced IGRP, Frame Relay and SMDS networks may or may not be considered to be NBMA. Therese networks are considered NBMA if the interface has not been configured to use physical multicasting; otherwise they are considered not to be NBMA.
You can configure the hold time on a specified interface for the IP Enhanced IGRP routing process designated by the autonomous system number. The hold time is advertised in hello packets and indicates to neighbors the length of time they should consider the sender valid. The default hold time is three times the hello interval, or 15 seconds. For slow speed NBMA networks, the default hold time is 180 seconds.
To change the interval between hello packets, perform the following task in interface configuration mode:
Configure the hello interval for an IP Enhanced IGRP routing process.
ip hello-interval eigrp autonomous-system-number seconds
On very congested and large networks, the default hold time might not be sufficient time for all routers to receive hello packets from their neighbors. In this case, you may want to increase the hold time.
To change the hold time, perform the following task in interface configuration mode:
Configure the hold time for an IP Enhanced IGRP routing process.
ip hold-time eigrp autonomous-system-number seconds
Note
Disable Split Horizon
Split horizon controls the sending of IP Enhanced IGRP update and query packets. When split horizon is enabled on an interface, these packets are not sent for destinations for which this interface is the next hop. This reduces the possibility of routing loops.
By default, split horizon is enabled on all interfaces.
Split horizon blocks information about routes from being advertised by a router out any interface from which that information originated. This behavior usually optimizes communications among multiple routers, particularly when links are broken. However, with nonbroadcast networks, such as Frame Relay and SMDS, situations can arise for which this behavior is less than ideal. For these situations, you may wish to disable split horizon.
To disable split horizon, perform the following task in interface configuration mode:
Configure OSPF
Open Shortest Path First (OSPF) is an IGP developed by the OSPF working group of the Internet Engineering Task Force (IETF). Designed expressly for IP networks, OSPF supports IP subnetting and tagging of externally derived routing information. OSPF also allows packet authentication and uses IP multicast when sending/receiving packets.
We support RFC 1253, Open Shortest Path First (OSPF) MIB, August 1991. The OSPF MIB defines an IP routing protocol that provides management information related to OSPF and is supported by Cisco routers and access servers.
Cisco's OSPF Implementation
Cisco's implementation conforms to the OSPF Version 2 specifications detailed in the Internet RFC 1583. The list that follows outlines key features supported in Cisco's OSPF implementation:
•
•
•
•
•
Note
OSPF Configuration Task List
OSPF typically requires coordination among many internal access servers, access servers acting as area border routers (routers connected to multiple areas), and access servers acting as autonomous system boundary routers. At a minimum, OSPF-based access servers can be configured with all default parameter values, no authentication, and interfaces assigned to areas. If you intend to customize your environment, you must ensure coordinated configurations of all access servers.
To configure OSPF, complete the tasks in the following sections. Enabling OSPF is mandatory; the other tasks are optional but might be required for your application.
•
•
•
•
•
•
In addition, you can specify route redistribution; see the "Redistribute Routing Information" section later in this chapter for information on how to configure route redistribution.
Enable OSPF
As with other routing protocols, enabling OSPF requires that you create an OSPF routing process, specify the range of IP addresses to be associated with the routing process, and assign area IDs to be associated with that range of IP addresses. Perform the following tasks, starting in global configuration mode:
Configure OSPF Interface Parameters
Our OSPF implementation allows you to alter certain interface-specific OSPF parameters, as needed.You are not required to alter any of these parameters, but some interface parameters must be consistent across all access servers in an attached network. Therefore, be sure that if you do configure any of these parameters, the configurations for all access servers on your network have compatible values.
In interface configuration mode, specify any of the following interface parameters as needed for your network:
Configure OSPF over Different Physical Networks
OSPF classifies different media into three types of networks by default:
•
•
•
You can configure your network as either a broadcast or a nonbroadcast multiaccess network.
X.25 and Frame Relay provide an optional broadcast capability that can be configured in the map to allow OSPF to run as a broadcast network. See the x25 map and frame-relay map command descriptions in the Access and Communication Servers Command Reference publication for more detail.
Configure Your OSPF Network Type
You have the choice of configuring your OSPF network type as either broadcast or nonbroadcast multiaccess, regardless of the default media type. Using this feature, you can configure broadcast networks as nonbroadcast multiaccess networks when, for example, you have routers in your network that do not support multicast addressing. You also can configure nonbroadcast multiaccess networks, such as X.25, Frame Relay, and SMDS, as broadcast networks. This feature saves you from having to configure neighbors, as described in the section "Configure OSPF for Nonbroadcast Neworks."
Configuring nonbroadcast, multiaccess networks as either broadcast or nonbroadcast assumes that there are virtual circuits from every router to every router or fully-meshed network. This is not true for some cases, for example, due to cost constraints or when you have only a partially-meshed network. In these cases, you can configure the OSPF network type as a point-to-multipoint network. Routing between two routers that are not directly connected will go through the router that has virtual circuits to both routers. Note that you do not need to configure neighbors when using this feature.
AN OSPF point-to-multipoint interface is defined as a numbered point-to-point interface having one or more neighbors. It creates multiple host routes. An OSPF point-to-multipoint network has the following benefits compared to nonbroadcast multiaccess and point-to-point networks:
•
•
•
To configure your OSPF network type, perform the following task in interface configuration mode:
Configure the OSPF network type for a specified interface.
ip ospf network {broadcast | non-broadcast | point-to-multipoint}
For an example of an OSPF point-to-multipoint network, see the section "OSPF Point-to-Multipoint Example" at the end of this chapter.
Configure OSPF for Nonbroadcast Neworks
Because there might be many access servers attached to an OSPF network, a designated access server is selected for the network. It is necessary to use special configuration parameters in the designated access server selection if broadcast capability is not configured.
These parameters need only be configured in those access servers that are themselves eligible to become the designated access server or backup designated access server (in other words, access servers with a nonzero access server priority value).
To configure access servers that interconnect to nonbroadcast networks, perform the following task in router configuration mode
Configure access servers interconnecting to nonbroadcast networks.
neighbor ip-address [priority number] [poll-interval seconds]
You can specify the following neighbor parameters, as required:
•
•
•
Configure OSPF Area Parameters
Our OSPF software allows you to configure several area parameters. These area parameters, shown in the following table, include authentication, defining stub areas, and assigning specific costs to the default summary route. Authentication allows password-based protection against unauthorized access to an area. Stub areas are areas into which information on external routes is not sent. Instead, there is a default external route generated by the area border router into the stub area for destinations outside the autonomous system.
In router configuration mode, specify any of the following area parameters as needed for your network:
Configure Route Summarization between OSPF Areas
Route summarization is the consolidation of advertised addresses. This feature causes a single summary route to be advertised to other areas by an access server acting as an area border router. In OSPF, an access server acting as an area border router will advertise networks in one area into another area. If the network numbers in an area are assigned in a way such that they are contiguous, you can configure the access server acting as an area border router to advertise a summary route that covers all the individual networks within the area that fall into the specified range.
To specify an address range, perform the following task in router configuration mode:
Specify an address range for which a single route will be advertised.
area area-id range address mask
Configure Route Summarization When Redistributing Routes into OSPF
When redistributing routes from other protocols into OSPF (as described in the section "Configure Routing Protocol-Independent Features" in this chapter, each route is advertised individually in an external link state advertisement (LSA). However, you can configure the router to advertise a single route for all the redistributed routes that are covered by a specified network address and mask. Doing so helps decrease the size of the OSPF link state database.
To have the router advertise one summary route for all redistributed routes covered by a network address and mask, perform the following task in router configuration mode:
Spsecifiy an address and mask that covers redistributed routes, so only one summary route is advertised.
summary-address address mask
Create Virtual Links
In OSPF, all areas must be connected to a backbone area. If there is a break in backbone continuity, or the backbone is purposefully partitioned, you can establish a virtual link. The two end points of a virtual link are Area Border Routers. The virtual link must be configured in both routers. The configuration information in each router consists of the other virtual endpoint (the other Area Border Router), and the nonbackbone area that the two routers have in common (called the transit area). Note that virtual links cannot be configured through stub areas.
To establish a virtual link, perform the following task in router configuration mode:
To display information about virtual links, use the show ip ospf virtual-links EXEC command. To display the router ID of an OSPF router, use the show ip ospf EXEC command.
Generate a Default Route
You can force an autonomous system boundary access server to generate a default route into an OSPF routing domain. Whenever you specifically configure redistribution of routes into an OSPF routing domain, the access server automatically becomes an autonomous system boundary access server. However, an autonomous system boundary access server does not, by default, generate a default route into the OSPF routing domain.
To force the access server acting as an autonomous system boundary router to generate a default route, perform the following task in router configuration mode:
See also the discussion of redistribution of routes in the "Configure Routing Protocol-Independent Features" section later in this chapter.
Configure Lookup of DNS Names
You can configure OSPF to look up Domain Name System (DNS) names for use in all OSPF show command displays. This feature makes it easier to identify an access server, because it is displayed by name rather than by its access server ID or neighbor ID.
To configure DNS name lookup, perform the following task in global configuration mode:
Force the Router ID Choice with a Loopback Interface
OSPF uses the largest IP address configured on the access server's interfaces as its router ID. If the interface associated with this IP address is ever brought down, or if the address is removed, the OSPF process must recalculate a new router ID and resend all of its routing information out its interfaces.
If a loopback interface is configured with an IP address, the access server will use this IP address as its router ID, even if other interfaces have larger IP addresses. Because loopback interfaces never go down, greater stability in the routing table is achieved.
OSPF automatically prefers a loopback interface over any other kind, and it chooses the highest IP address among all loopback interfaces in the router. If no loopback interfaces are present, the highest IP address in the router is chosen. You cannot tell OSPF to use any particular interface.
To configure an IP address on a loopback interface, perform the following tasks, starting in global configuration mode:
Step 1
interface loopback 01
Step 2
ip address address mask
1 This command is documented in the "Interface Commands" chapter of the Access and Communication Servers Command Reference publication.
Configure OSPF on Simplex Ethernet Interfaces
Because simplex interfaces between two routers on an Ethernet represent only one network segment, for OSPF you have to configure the transmitting interface to be a passive interface. This prevents OSPF from sending hello packets for the transmitting interface. Both routers are able to see each other via the hello packet generated for the receiving interface.
To configure OSPF on simplex Ethernet interfaces, perform the following task in router configuration mode:
Suppress the sending of hello packets through the specified interface.
passive-interface type number
Configure Route Calculation Timers
You can configure the delay time between when OSPF receives a topology change and when it starts a Shortest Path First (SPF) calculation. You can also configure the hold time between two consecutive SPF calculations. To do this, perform the following task in router configuration mode:
Disable Default OSPF Metric Calculation Based on Bandwidth
In Cisco IOS Release 10.2 and earlier, OSPF assigned default OSPF metrics to interfaces regardless of the interface bandwidth. It gave both 64K and T1 links the same metric (1562), and thus required an explicit ip ospf cost command in order to take advantage of the faster link.
In Cisco IOS Release 10.3, by default, OSPF calculates the OSPF metric for an interface according to the bandwidth of the interface. For example, a 64K link gets a metric of 1562, while a T1 link gets a metric of 64. To disable this feature, perform the following task in router configuration mode:
Disable default OSPF metric calculations based on interface bandwidth, resulting in a fixed default metric assignment.
no ospf auto-cost-determination
Configure RIP
The Routing Information Protocol (RIP) is a relatively old but still commonly used IGP created for use in small, homogeneous networks. It is a classical distance-vector routing protocol.
RIP uses broadcast User Datagram Protocol (UDP) data packets to exchange routing information. Each access server sends routing information updates every 30 seconds; this process is termed advertising. If an access server does not receive an update from another access server for 180 seconds or more, it marks the routes served by the nonupdating router as being unusable. If there is still no update after 240 seconds, the access server removes all routing table entries for the nonupdating router.
The measure, or metric, that RIP uses to rate the value of different routes is the hop count. The hop count is the number of routers that can be traversed in a route. A directly connected network has a metric of zero; an unreachable network has a metric of 16. This small range of metrics makes RIP unsuitable as a routing protocol for large networks. If the access server has a default network path, RIP advertises a route that links the access server to the pseudonetwork 0.0.0.0. The network 0.0.0.0 does not exist; RIP treats 0.0.0.0 as a network to implement the default routing feature. Our systems will advertise the default network if a default was learned by RIP or if the access server has a gateway of last resort and RIP is configured with a default metric.
RIP sends updates to the interfaces in the specified networks. If an interface's network is not specified, it will not be advertised in any RIP update.
For information about filtering RIP information, see the "Filter Routing Information" section later in this chapter. RIP is documented in RFC 1058.
To configure RIP, perform the following tasks, starting in global configuration mode:
Step 1
router rip
Step 2
network network-number
Running IGRP and RIP Concurrently
It is possible to run IGRP and RIP concurrently. The IGRP information will override the RIP information by default because of IGRP's administrative distance.
However, running IGRP and RIP concurrently does not work well when the network topology changes. Because IGRP and RIP have different update timers and because they require different amounts of time to propagate routing updates, one part of the network will end up believing IGRP routes and another part will end up believing RIP routes. This will result in routing loops. Even though these loops do not exist for very long, the time to live (TTL) will quickly reach zero, and ICMP will send a "TTL exceeded" message. This message will cause most applications to stop attempting network connections.
Validate Source IP Addresses
To disable the default function that validates the source IP addresses of incoming routing updates, perform the following task in router configuration mode:
Disable the checking and validation of the source IP address of incoming routing updates.
no validate-update-source
Allow Point-to-Point Updates for RIP
Because RIP is normally a broadcast protocol, in order for RIP routing updates to reach point-to-point or nonbroadcast networks, you must configure the access server to permit this exchange of routing information.
You configure the access server to permit this exchange of routing information by performing the following task in router configuration mode:
Define a neighboring router with which to exchange point-to-point routing information.
neighbor ip-address
To control the set of interfaces that you want to exchange routing updates with, you can disable the sending of routing updates on specified interfaces by configuring the passive-interface command. See the discussion on filtering in the "Filter Routing Information" section later in this chapter.
Configure BGP
The Border Gateway Protocol (BGP), as defined in RFCs 1163 and 1267, allows you to set up an interdomain routing system that automatically guarantees the loop-free exchange of routing information between autonomous systems.
Cisco's BGP Implementation
In BGP, each route consists of a network number, a list of autonomous systems that information has passed through (called the autonomous system path or AS path), and a list of other path attributes. We support BGP Versions 2, 3, and 4. This section describes our implementation of BGP.
The primary function of a BGP system is to exchange network reachability information with other BGP systems, including information about the list of AS paths. This information can be used to construct a graph of autonomous system connectivity from which routing loops can be pruned and with which autonomous system-level policy decisions can be enforced.
You can configure the value for the multiple exit discriminator (MULTI_EXIT_DISC, or MED) metric attribute using route maps. (The name of this metric for BGP Versions 2 and 3 is INTER_AS.) When an update is sent to an IBGP peer, the MED will be passed along without any change. This will enable all the peers in the same autonomous system to make a consistent path selection.
A third-party next-hop router address is used in the NEXT_HOP attribute, regardless of the autonomous system path of that third-party router. the access server automatically calculates the value for this attribute.
Transitive, optional path attributes are passed along to other BGP-speaking routers. The current BGP implementation does not generate such attributes.
BGP Version 4 (BGP4) supports classless interdomain routing (CIDR), which lets you reduce the size of your routing tables by creating aggregate routes, resulting in supernets. CIDR eliminates the concept of network classes within BGP and supports the advertising of IP prefixes. CIDR routes can be carried by OSPF.
See the "Route-Map Examples" section later in this chapter for examples of how to use route maps to redistribute BGP4 routes.
How BGP Selects Paths
The BGP process selects a single autonomous system path to use and to pass along to other BGP-speaking routers. Cisco's BGP implementation has a reasonable set of factory defaults that can be overridden by administrative weights. The algorithm for path selection is as follows:
•
•
•
•
•
•
•
•
•
•
BGP Configuration Task List
The tasks in this section are divided into basic and advanced BGP configuration tasks. The first three basic tasks are required to configure BGP; the remaining basic and advanced tasks are optional.
Basic BGP Configuration Tasks
•
•
•
•
•
•
Advanced BGP Configuration Tasks
•
•
•
•
•
•
•
•
•
•
Basic BGP Tasks
This section describes the basic BGP configuration tasks.
Enable BGP Routing
To enable BGP routing, establish a BGP routing process on the router by performing the following steps starting in global configuration mode:
Note
Note
Configure BGP Neighbors
Like other Exterior Gateway Protocols (EGPs), BGP must completely understand the relationships it has with its neighbors. BGP supports two kinds of neighbors: internal and external. Internal neighbors are in the same autonomous system; external neighbors are in different autonomous systems. Normally, external neighbors are adjacent to each other and share a subnet, while internal neighbors may be anywhere in the same autonomous system.
To configure BGP neighbors, perform the following task in router configuration mode:
See an example of configuring BGP neighbors in the section "BGP Path Filtering by Neighbor Example" at the end of this chapter.
Reset BGP Connections
Once you have defined two routers to be BGP neighbors, they will form a BGP connection and exchange routing information. If you subsequently change a BGP filter, weight, distance, version, or timer, or make a similar configuration change, you need to reset BGP connections for the configuration change to take effect. Perform either of the following tasks in EXEC mode to reset BGP connections:
Reset a particular BGP connection.
clear ip bgp address
Reset all BGP connections.
clear ip bgp *
Configure BGP Interactions with IGPs
If your autonomous system will be passing traffic through it from another autonomous system to a third autonomous system, it is very important that your autonomous system be consistent about the routes that it advertises. For example, if your BGP were to advertise a route before all routers in your network had learned about the route through your IGP, your autonomous system could receive traffic that some routers cannot yet route. To prevent this from happening, BGP must wait until the IGP has propagated routing information across your autonomous system. This causes BGP to be synchronized with the IGP. Synchronization is enabled by default.
In some cases, you do not need synchronization. If you will not be passing traffic from a different autonomous system through your autonomous system, or if all routers in your autonomous system will be running BGP, you can disable synchronization. Disabling this feature can allow you to carry fewer routes in your IGP and allow BGP to converge more quickly. To disable synchronization, perform the following task in router configuration mode:
When you disable synchronization, you should also clear BGP sessions using the clear ip bgp command.
See the section "BGP Synchronization Example" at the end of this chapter for an example of synchronization.
In general, you will not want to redistribute most BGP routes into your IGP. A common design is to redistribute one or two routes and to make them exterior routes in IGRP or have your BGP speaker generate a default route for your autonomous system. When redistributing from BGP into IGP, only the routes learned using EBGP get redistributed.
In most circumstances, you also will not want to redistribute your IGP into BGP. Just list the networks in your autonomous system with network router configuration commands and your networks will be advertised. Networks that are listed this way are referred to as local networks and have a BGP origin attribute of "IGP." They must appear in the main IP routing table and can have any source; for example, they can be directly connected or learned via an IGP. The BGP routing process periodically scans the main IP routing table to detect the presence or absence of local networks, updating the BGP routing table as appropriate.
If you do perform redistribution into BGP, you must be very careful about the routes that can be in your IGP, especially if the routes were redistributed from BGP into the IGP elsewhere. This creates a situation where BGP is potentially injecting information into the IGP and then sending such information back into BGP and vice versa.
Networks that are redistributed into BGP from the EGP protocol will be given the BGP origin attribute "EGP." Other networks that are redistributed into BGP will have the BGP origin attribute of "incomplete." The origin attribute in our implementation is only used in the path selection process.
Configure BGP Administrative Weights
An administrative weight is a number that you can assign to a path so that you can control the path selection process. The administrative weight is local to the router. A weight can be a number from 0 to 65535. Paths that the router originates have weight 32768 by default, other paths have weight zero. If you have particular neighbors that you want to prefer for most of your traffic, you can assign a higher weight to all routes learned from that neighbor.
Perform the following task in router configuration mode to configure BGP administrative weights:
Specify a weight for all routes from a neighbor.
neighbor {ip-address | peer-group-name} weight weight
In addition, you can assign weights based on autonomous system path access lists. A given weight becomes the weight of the route if the autonomous system path is accepted by the access list. Any number of weight filters are allowed.
To assign weights based on autonomous system path access lists, perform the following tasks starting in global configuration mode:
Configure BGP Route Filtering by Neighbor
If you want to restrict the routing information that the router learns or advertises, you can filter BGP routing updates to and from particular neighbors. To do this, define an access list and apply it to the updates. Distribute-list filters are applied to network numbers and not autonomous system paths.
To filter BGP routing updates, perform the following task in router configuration mode:
Filter BGP routing updates to/from neighbors as specified in an access list.
neighbor {ip-address | peer-group-name} distribute-list access-list-number {in | out}
Configure BGP Path Filtering by Neighbor
In addition to filtering routing updates based on network numbers, you can specify an access list filter on both incoming and outbound updates based on the BGP autonomous system paths. Each filter is an access list based on regular expressions. To do this, define an autonomous system path access list and apply it to updates to and from particular neighbors. See the "Regular Expressions" appendix in the Router Products Command Reference publication for more information on forming regular expressions.
To configure BGP path filtering, perform the following tasks starting in global configuration mode:
See the example in the section "BGP Path Filtering by Neighbor Example" at the end of this chapter.
Disable Next-Hop Processing on BGP Updates
You can configure the router to disable next-hop processing for BGP updates to a neighbor. This might be useful in non-meshed networks such as Frame Relay or X.25 where BGP neighbors might not have direct access to all other neighbors on the same IP subnet.
To disable next-hop processing, perform the following task in router configuration mode:
Disable next-hop processing on BGP updates to a neighbor.
neighbor {ip-address | peer-group-name} next-hop-self
Configuring the above command causes the current router to advertise itself as the next hop for the specified neighbor. Therefore other BGP neighbors will forward to it packets for that address. This is useful in a nonmeshed environment, since you know that a path exists from the present router to that address. In a fully meshed environment, this is not useful since it will result in unnecessary extra hops, because there might be a direct access through the fully meshed cloud with fewer hops.
Configure the BGP Version
By default, BGP sessions begin using BGP Version 4 and negotiating downward to earlier versions if necessary. To prevent negotiation and force the BGP version used to communicate with a neighbor, perform the following task in router configuration mode:
Specify the BGP version to use when communicating with a neighbor.
neighbor {ip-address | peer-group-name} version value
Set the Network Weight
Weight is a parameter that affects the best path selection process. To set the absolute weight for a network, perform the following task in router configuration mode:
Configure the Multi Exit Discriminator Metric
BGP uses the Multi Exit Discriminator (MED) metric as a hint to external neighbors about preferred paths. (The name of this metric for BGP Versions 2 and 3 is INTER_AS_METRIC.) You can set the MED of the redistributed routes by performing the following task. All of the routes without a MED will also be set to this value. Perform the following task in router configuration mode:
Alternatively, you can set the MED using the route-map command. See the section "BGP Route Map Examples" at the end of this chapter.
Advanced BGP Configuration Tasks
This section contains advanced BGP configuration tasks.
Use Route Maps to Modify Updates
You can use a route map on a per neighbor basis to filter updates and modify various attributes. A route map can be applied to either inbound or outbound updates. Only the routes that pass the route map are sent or accepted in updates.
On the inbound updates, we support matching on autonomous system path and community. On the outbound updates, we support matching based on autonomous system path, community, and network numbers. Autonomous system path matching requires the as-path access-list command, community based matching requires the community-list command and network-based matching requires the ip access-list command.
Perform the following task in router configuration mode:
Apply a route map to incoming or outgoing routes.
neighbor {ip-address | peer-group-name} route-map route-map-name {in | out}
For examples, see the section "BGP Route Map Examples" at the end of this chapter.
Configure BGP Neighbor Templates
You can configure neighbor templates that use a word argument rather than an IP address to configure BGP neighbors. During the initiation of a BGP session, the IP address of the neighbor is checked against the access list and it must pass the access list to start the BGP session. You must keep in mind that the router configured with the template name is in a passive state for these neighbors, which means it will not initiate sessions; rather it waits until a session is initiated to it and then verifies based on the criteria mentioned above.
If you use the neighbor configure-neighbors command, all the neighbors that initiate a session to the router and pass the neighbor-list are permanently entered into the configuration (NVRAM) upon issuing the write memory command. (Note that the write memory command has been replaced by the copy running-config startup-config command.)
Perform the following tasks in router configuration mode to configure BGP neighbor templates:
See the example in the section "Using Access Lists to Specify Neighbors" at the end of this chapter.
Reset EBGP Connections Immediately Upon Link Failure
Usually when a link between external neighbors goes down, the BGP session will not be reset immediately. If you want the EBGP session to be reset as soon as an interface goes down, perform the following task in router configuration mode:
Configure Aggregate Addresses
Classless interdomain routing (CIDR) lets you create aggregate routes, or supernets, to minimize the size of routing tables. You can configure aggregate routes in BGP either by redistributing an aggregate route into BGP or by using the conditional aggregation feature described in the next task table. An aggregate address will be added to the BGP table if there is at least one more specific entry in the BGP table.
To create an aggregate address in the routing table, perform one or more of the following tasks in router configuration mode:
For an example, see the section "BGP Aggregate Route Examples" at the end of this chapter.
Disable Automatic Summarization of Network Numbers
In BGP Version 3, when a subnet is redistributed from an IGP into BGP, only the network route is injected into the BGP table. By default, this automatic summarization is enabled. To disable automatic network number summarization, perform the following task in router configuration mode:
Configure BGP Community Filtering
BGP supports transit policies via controlled distribution of routing information. The distribution of routing information is based on one of three values:
•
•
•
The COMMUNITIES attribute is a way to group destinations into communities and apply routing decisions based on the communities. This method simplifies a BGP speaker's configuration that controls distribution of routing information.
A community is a group of destinations that share some common attribute. Each destination can belong to multiple communities. Autonomous system administrators can define which communities a destination belongs to. By default, all destinations belong to the general Internet community. The community is carried as the COMMUNITIES attribute.
The COMMUNITIES attribute is an optional, transitive, global attribute in the numerical range from 1 to 4,294,967,200. Along with Internet community, there are a few predefined, well-known communities, as follows:
•
•
•
Based on the community, you can control which routing information to accept, prefer, or distribute to other neighbors. A BGP speaker can set, append, or modify the community of a route when you learn, advertise, or redistribute routes. When routes are aggregated, the resulting aggregate has a COMMUNITIES attribute that contains all communities from all the initial routes.
Community lists are used to create groups of communities to use in a match clause of a route map. Just like an access list, a series of community lists can be created. Statements are checked until a match is found. As soon as one statement is satisfied, the test is concluded.
To create a community list, perform the following task in global configuration mode:
Create a community list.
ip community-list community-list-number {permit | deny} community-number
To set the COMMUNITIES attribute and match clauses based on communities, see the match community-list and set community commands in the section "Redistribute Routing Information" later in this chapter.
By default, no COMMUNITIES attribute is sent to a neighbor. You can specify that the COMMUNITIES attribute be sent to the neighbor at an IP address by performing the following task in router configuration mode:
Specify that the COMMUNITIES attribute be sent to the neighbor at this IP address.
neighbor {ip-address | peer-group-name} send-community
Configure a Routing Domain Confederation
One way to reduce the IBGP mesh is to divide an autonomous system into multiple autonomous systems and group them into a single confederation. To the outside world, the confederation looks like a single autonomous system. Each autonomous system is fully meshed within itself, and has a few connections to other autonomous systems in the same confederation. Even though the peers in different autonomous systems have EBGP sessions, they exchange routing information as if they were IBGP peers. Specifically, the next-hop, MED, and local preference information is preserved. This enables to us to retain a single Interior Gateway Protocol (IGP) for all of the autonomous systems.
To configure a BGP confederation, you must specify a confederation identifier. To the outside world, the group of autonomous systems will look like a single autonomous system with the confederation identifier as the autonomous system number. To configure a BGP confederation identifier, perform the following tasks in router configuration mode:
In order to treat the neighbors from other autonomous systems within the confederation as special EBGP peers, perform the following task in router configuration mode:
Specify the autonomous systems that belong to the confederation.
bgp confederation peers autonomous-system [autonomous-system ...]
See the example configuration of several peers in a confederation in the section "BGP Confederation Example" at the end of this chapter.
Configure Neighbor Options
To provide BGP routing information to a large number of neighbors, you can configure BGP to accept neighbors based on an access list. If a neighbor attempts to initiate a BGP connection, its address must be accepted by the access list for the connection to be accepted. If you do this, the router will not attempt to initiate a BGP connection to these neighbors, so the neighbors must be explicitly configured to initiate the BGP connection. If no access list is specified, all connections are accepted.
External BGP peers normally must reside on a directly connected network. Sometimes it is useful to relax this restriction in order to test BGP; do so by specifying the neighbor ebgp-multihop command.
For internal BGP, you might want to allow your BGP connections to stay up regardless of which interface is used to reach a neighbor. To do this, you first configure a loopback interface and assign it an IP address. Next, configure the BGP update source to be the loopback interface. Finally, configure your neighbor to use the address on the loopback interface. Now the IBGP session will be up as long as there is a route, irrespective of any interface.
You can set the minimum interval of time between BGP routing updates.
You can invoke MD5 authentication between two BGP peers, meaning that each segment sent on the TCP connection between them is verified. This feature must be configured with the same password on both BGP peers; otherwise, the connection between them will not be made. The authentication feature uses the MD5 algorithm. Invoking authentication causes the router to generate and check the MD5 digest of every segment sent on the TCP connection. If authentication is invoked and a segment fails authentication, a message appears on the console.
Configure any of the following neighbor options in router configuration mode:
Configure BGP Peer Groups
Often in a BGP speaker, there are many neighbors configured with the same update policies (that is, same outbound route maps, distribute lists, filter lists, update source, and so on). Neighbors with the same update policies can be grouped into peer groups to simplify configuration and make updating more efficient.
There are three steps to configuring a BGP peer group: creating the peer group, assigning configuration options to the peer group, and making neighbors members of the peer group.
To create a BGP peer group, perform the following task in router configuration mode:
After you create a peer group, you configure the peer group with neighbor commands. By default, members of the peer group inherit all of the configuration options of the peer group. Members can also be configured to override the options that do not affect outbound updates.
Peer group members will always inherit the following: remote-as (if configured), version, update-source, out-route-map, out-filter-list, out-dist-list, minimum-advertisement-interval, and next-hop-self. All of the peer group members will inherit changes made to the peer group.
To assign configuration options to the peer group, perform any of the following tasks in router configuration mode:
If a peer group is not configured with a remote-as, the members can be configured with the neighbor ip-address | peer-group-name remote-as command. This allows you to create peer groups containing EBGP neighbors.
Finally, to configure a BGP neighbor to be a member of that BGP peer group, perform the following task in router configuration mode, using the same peer group name:
Make a BGP neighbor a member of the peer group.
neighbor ip-address peer-group peer-group-name
For examples of IBGP and EBGP peer groups, see the section "BGP Peer Group Examples" at the end of this chapter.
Indicate Backdoor Routes
You can indicate which networks are reachable using a backdoor route that the border router should use. A backdoor network is treated as a local network, except that it is not advertised. To configure backdoor routes, perform the following task in router configuration mode:
Modify Parameters While Updating the IP Routing Table
By default, when a BGP route is put into the IP routing table, the MED is converted to an IP route metric, the BGP next hop is used as the next hop for the IP route, and the tag is not set. However, you can use a route map to perform mapping. To modify metric and tag information when the IP routing table is updated with BGP learned routes, perform the following task in router configuration mode:
Set Administrative Distance
Administrative distance is a measure of the preference of different routing protocols. BGP uses three different administrative distances—external, internal, and local. Routes learned through external BGP are given the external distance, routes learned with internal BGP are given the internal distance, and routes that are part of this autonomous system are given the local distance. To assign a BGP administrative distance, perform the following task in router configuration mode:
Assign a BGP administrative distance.
distance bgp external-distance internal-distance local-distance
Changing the administrative distance of BGP routes is considered dangerous and generally is not recommended. The external distance should be lower than any other dynamic routing protocol, and the internal and local distances should be higher than any other dynamic routing protocol.
Adjust BGP Timers
BGP uses certain timers to control periodic activities such as the sending of keepalive messages and the interval after not receiving a keepalive message after which the router declares a peer dead. You can adjust these timers. When a connection is started, BGP will negotiate the hold time with the neighbor. The smaller of the two hold times will be chosen. The keepalive timer is then set based on the negotiated holdtime and the configured keepalive time. To adjust BGP timers, perform the following task in router configuration mode:
Change the Local Preference Value
You can define a particular path as more or less preferable than other paths by changing the default local preference value of 100. To assign a different default local preference value, perform the following task in router configuration mode:
You can use route maps to change the default local preference of specific paths. See the section "BGP Route Map Examples" for examples.
Redistribute Network 0.0.0.0
By default, you are not allowed to redistribute network 0.0.0.0. To permit the redistribution of network 0.0.0.0, perform the following task in router configuration mode:
Base Path Selection on MEDs from Other Autonomous Systems
The MED is one of the parameters that is considered when selecting the best path among many alternative paths. The path with a lower MED is preferred over a path with a higher MED.
By default, during the best path selection process, MED comparison is done only among paths from the same autonomous system. You can allow comparison of MEDs among paths regardless of the autonomous system from which the paths are received. To do so, perform the following task in router configuration mode:
Allow the comparison of MEDs for paths from neighbors in different autonomous systems.
bgp always-compare-med
Configure EGP
The Exterior Gateway Protocol (EGP), specified in RFC 904, is an older EGP used for communicating with certain routers in the Defense Data Network (DDN) that the U.S. Department of Defense designates as core routers. EGP also was used extensively when attaching to the National Science Foundation Network (NSFnet) and other large backbone networks.
An exterior router uses EGP to advertise its knowledge of routes to networks within its autonomous system. It sends these advertisements to the core routers, which then readvertise their collected routing information to the exterior router. A neighbor or peer router is any router with which the access server communicates using EGP.
Cisco's EGP Implementation
Cisco's implementation of EGP supports three primary functions, as specified in RFC 904:
•
•
•
EGP Configuration Task List
To enable EGP routing on your router or access server, complete the tasks in the following sections. The tasks in the first two sections are mandatory; the tasks in the other sections are optional.
•
•
•
•
Enable EGP Routing
To enable EGP routing, you must specify an autonomous system number, generate an EGP routing process, and indicate the networks for which the EGP process will operate.
Perform these required tasks in the order given as shown in the following table:
Step 1
See Table 2-1 earlier in this manual.
Step 2
autonomous-system local-as
Step 3
router egp remote-as
Step 4
network network-number
Note
Configure EGP Neighbor Relationships
An access server using EGP cannot dynamically determine its neighbor or peer access servers. You must therefore provide a list of neighbor routers.
To specify an EGP neighbor, perform the following task in router configuration mode:
Adjust EGP Timers
The EGP timers consist of a hello timer and a poll time interval timer. The hello timer determines the frequency in seconds with which the access server sends hello messages to its peer. The poll time specifies how frequently to exchange updates. Our implementation of EGP allows these timers to be adjusted by the user.
To adjust EGP timers, perform the following task in router configuration mode:
Configure Third-Party EGP Support
EGP supports a third-party mechanism in which EGP tells an EGP peer that another access server (the third party) on the shared network is the appropriate access server for some set of destinations.
To specify third-party access servers in updates, perform the following task in router configuration mode:
Specify a third-party through which certain destinations can be achieved.
neighbor ip-address third-party third-party-ip-address
[internal | external]
See the "IP Routing Protocol Configuration Examples" section later in this chapter for an example of configuring third-party EGP support.
Configure Backup Access Servers
You might want to provide backup in the event of site failure by having a second router belonging to a different autonomous system act as a backup to the EGP access server for your autonomous system. To differentiate between the primary and secondary EGP access servers, the two access servers will advertise network routes with differing EGP distances or metrics. A network with a low metric is generally favored over a network with a high metric.
Networks declared as local are always announced with a metric of zero. Networks that are redistributed will be announced with a metric specified by the user. If no metric is specified, redistributed routes will be advertised with a metric of three. All redistributed networks will be advertised with the same metric. The redistributed networks can be learned from static or dynamic routes. See also the "Redistribute Routing Information" section later in this chapter.
See the "IP Routing Protocol Configuration Examples" section later in this chapter for an example of configuring backup access servers.
Configure Default Routes
You also can designate network 0.0.0.0 as a default route. If the next hop for the default route can be advertised as a third party, it will be included as a third party.
To enable the use of default EGP routes, perform the following task in router configuration mode:
Define a Central Routing Information Manager (Core Gateway)
Normally, an EGP process expects to communicate with neighbors from a single autonomous system. Because all neighbors are in the same autonomous system, the EGP process assumes that these neighbors all have consistent internal information. Therefore, if the EGP process is informed about a route from one of its neighbors, it will not send it out to other neighbors.
With core EGP, the assumption is that all neighbors are from different autonomous systems, and all have inconsistent information. In this case, the EGP process distributes routes from one neighbor to all others (but not back to the originator). This allows the EGP process to be a central clearinghouse for information with a single, central manager of routing information (sometimes called a core gateway). To this end, one core gateway process can be configured for each access server.
To define a core gateway process, perform the following steps in the order in which they appear:
Step 1
See Table 2-1 earlier in this manual.
Step 2
router egp 0
Step 3
orAllow the specified address to be used as the next hop in EGP advertisements.
neighbor any [access-list-number]
neighbor any third-party ip-address [internal | external]
The EGP process defined in this way can act as a peer with any autonomous system, and information is interchanged freely between autonomous systems.
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for an example of configuring an EGP core gateway.
Note
Configure GDP
The Gateway Discovery Protocol (GDP), designed by Cisco to address customer needs, allows hosts to dynamically detect the arrival of new access servers, as well as determine when an access server goes down. You must have host software to take advantage of this protocol.
For ease of implementation on a variety of host software, GDP is based on the User Datagram Protocol (UDP). The UDP source and destination ports of GDP datagrams are both set to 1997 (decimal).
There are two types of GDP messages: report and query. On broadcast media, report message packets are periodically sent to the IP broadcast address announcing that the access server is present and functioning. By listening for these report packets, a host can detect a vanishing or appearing access server. If a host issues a query packet to the broadcast address, the access servers each respond with a report sent to the host's IP address. On nonbroadcast media, access servers send report message packets only in response to query message packets. The protocol provides a mechanism for limiting the rate at which query messages are sent on nonbroadcast media.
Figure 19-2 shows the format of the GDP report message packet format. A GDP query message packet has a similar format, except that the count field is always zero and no address information is present.
Figure 19-2 GDP Report Message Packet Format
The fields in the report and query messages are as follows:
•
•
•
•
•
•
•
Numerous actions can be taken by the host software listening to GDP packets. One possibility is to flush the host's ARP cache whenever an access server appears or disappears. A more complex possibility is to update a host routing table based on the coming and going of access servers. The particular course of action taken depends on the host software and your network requirements.
To enable GDP routing and other optional GDP tasks as required for your network, perform the following tasks in interface configuration mode:
Configure IRDP
Like GDP, the ICMP Router Discovery Protocol (IRDP) allows hosts to locate access servers. When operating as a client, access server discovery packets are generated, and when operating as a host, access server discovery packets are received.
The only required task for configuring IRDP routing on a specified interface is to enable IRDP processing on an interface. Perform the following task in interface configuration mode:
When you enable IRDP processing, the default parameters will apply. You can optionally change any of these IRDP parameters. Perform the following tasks in interface configuration mode:
A access server can proxy-advertise other machines that use IRDP; however, this is not recommended because it is possible to advertise nonexistent machines or machines that are down.
Configure IP Multicast Routing
Traditional IP communication allows a host to send packets to a single host (unicast transmission) or to all hosts (broadcast transmission). IP multicast provides a third scheme, allowing a host to send packets to a subset of all hosts (group transmission). These hosts are known as group members.
Packets delivered to group members are identified by a single multicast group address. Multicast packets are delivered to a group using best-effort reliability just like IP unicast packets.
The multicast environment consists of senders and receivers. Any host, whether it is a member of a group or not, can send to a group. However, only the members of a group receive the message.
A multicast address is chosen for the receivers in a multicast group. Senders use that address as the destination address of a datagram to reach all members of the group.
Membership in a multicast group is dynamic: hosts can join and leave at any time. There is no restriction on the location or number of members in a multicast group. A host can be a member of more than one multicast group at a time.
How active a multicast group is and what members it has can vary from group to group and from time to time. A multicast group can be active for a very long while, or it may be very short-lived. Membership in a group can change constantly. A group that has members may have no activity.
access servers executing a multicast routing protocol, such as PIM, maintain forwarding tables to forward multicast datagrams. access servers use the Internet Group Management Protocol (IGMP) to learn whether members of a group are present on their directly attached subnets. Hosts join multicast groups by sending IGMP report messages.
Cisco's Implementation of IP Multicast Routing
The IOS software supports two protocols to implement IP multicast routing:
•
•
•
Internet Group Management Protocol (IGMP)
IGMP is used by IP hosts to report their group membership to directly connected multicast access servers. IGMP is an integral part of IP. IGMP is defined in RFC 1112, Host Extensions for IP Multicasting.
IGMP uses group addresses, which are Class D IP addresses. The high-order four bits of a Class D address are 1110. This means that host group addresses can be in the range 224.0.0.0 to 239.255.255.255. The address 224.0.0.0 is guaranteed not to be assigned to any group. The address 224.0.0.1 is assigned to all systems on a subnet. The address 224.0.0.2 is assigned to all access servers on a subnet.
Protocol-Independent Multicast (PIM) Protocol
The PIM protocol maintains the current IP multicast service mode of receiver-initiated membership. It is not dependent on a specific unicast routing protocol.
PIM is defined in the following IETF Internet drafts:
•
•
•
•
•
PIM can operate in two modes: dense mode and sparse mode.
In dense mode, a router assumes that all other routers want to forward multicast packets for a group. If a router receives a multicast packet and has no directly connected members or PIM neighbors present, a prune message is sent back to the source. Subsequent multicast packets are not flooded to this router on this pruned branch. PIM builds source-based multicast distribution trees.
In sparse mode, a router assumes that other routers do not want to forward multicast packets for a group unless there is an explicit request for the traffic. When hosts join a multicast group, the directly connected routers send PIM Join messages to the rendezvous point (RP). The RP keeps track of multicast groups. Hosts that send multicast packets are registered with the RP by that host's first-hop router. The RP then sends joins toward the source. At this point, packets are forwarded on a shared distribution tree. If the multicast traffic from a specific source is sufficient, the receiver's first-hop router may send joins toward the source to build a source-based distribution tree.
Distance Vector Multicast Routing Protocol (DVMRP)
DVMRP uses a flood-and-prune approach to multicast packet delivery. It assumes that all other routers want to forward multicast packets for a group, like dense-mode PIM. DVMRP is implemented in many vendors' equipment and is based on the public domain mrouted program.
Cisco routers support dynamic discovery of DVMRP routers and can interoperate with them over traditional media, such as Ethernet and FDDI, or over DVMRP-specific tunnels.
IP Multicast Routing Configuration Task List
To configure IP multicast routing, perform the required tasks described in the following sections:
•
You can also perform the optional tasks described in the following sections:
•
•
•
•
•
•
•
•
•
See the section "IP Multicast Routing Configuration Examples" at the end of this chapter.
Enable IP Multicast Routing on the Access Server
Enabling IP multicast routing on the access server allows the access server to forward multicast packets.
To enable IP multicast routing on the access server, perform the following task in global configuration mode:
Enable PIM on an Interface
Enabling PIM on an interface also enables IGMP operation on that interface. An interface can be configured to be in dense mode or sparse mode. The mode describes how the access server populates its multicast routing table and how the access server forwards multicast packets it receives from its directly connected LANs. In populating the multicast routing table, dense-mode interfaces are always added to the table. Sparse-mode interfaces are added to the table only when periodic join messages are received from downstream access servers or there is a directly connected member on the interface. When forwarding from a LAN, sparse-mode operation occurs if there is an RP known for the group. If so, the packets are encapsulated and sent toward the RP. When no RP is known, the packet is flooded in a dense-mode fashion. If the multicast traffic from a specific source is sufficient, the receiver's first-hop access server may send joins toward the source to build a source-based distribution tree.
There is no default mode setting. By default, multicast routing is disabled on an interface.
To configure PIM on an interface to be in dense mode, perform the following task in interface configuration mode:
For an example of how to configure a PIM interface in dense mode, see the section "Configure an Access Server to Operate in Dense Mode Example" later in this chapter.
To configure PIM on an interface to be in sparse mode, perform the following task in interface configuration mode:
If you configure the access server to operate in sparse mode, you must also choose one or more access servers to be RPs. You do not have to configure the access servers to be RPs; they learn this themselves. RPs are used by senders to a multicast group to announce their existence and by receivers of multicast packets to learn about new senders. An access server can be configured so that packets for a single multicast group can use one or more RPs.
You must configure the IP address of RPs in leaf access servers only. Leaf access servers are those access servers that are directly connected either to a multicast group member or to a sender of multicast messages.
The RP address is used by first-hop access servers to send PIM register messages on behalf of a host sending a packet to the group. The RP address is also used by last-hop access servers to send PIM join/prune messages to the RP to inform it about group membership. The RP does not need to know it is an RP. You need to configure the RP address only on first-hop and last-hop access servers (leaf access servers).
A PIM access server can be an RP for more than one group. A group can have more than one RP. The conditions specified by the access-list determine for which groups the access server is an RP.
To configure the address of the RP, perform the following task in global configuration mode:
For an example of how to configure a PIM interface in sparse mode, see the section "Configure an Access Server to Operate in Sparse Mode Example" later in this chapter.
Configure an Access Server to Be a Member of a Group
Cisco access servers can be configured to be members of a multicast group. This is useful for determining multicast reachability in a network. If an access server is configured to be a group member and supports the protocol that is being transmitted to the group, it can respond. An example is ping. An access server will respond to ICMP echo request packets addressed to a group for which it is a member. Another example is the multicast traceroute tools provided in the IOS software.
To have an access server join a multicast group and turn on IGMP on the access server, perform the following task in interface configuration mode:
Configure the Host-Query Message Interval
Multicast access servers send IGMP host-query messages to discover which multicast groups are present on attached networks. These messages are sent to the all-systems group address of 224.0.0.1 with a TTL of 1.
Multicast access servers send host-query messages periodically to refresh their knowledge of memberships present on their networks. If, after some number of queries, the access server discovers that no local hosts are members of a multicast group, the access server stops forwarding onto the local network multicast packets from remote origins for that group and sends a prune message upstream toward the source.
Multicast access servers elect a PIM designated access server for the LAN (subnet). This is the access server with the highest IP address. The designated router is responsible for sending IGMP host-query messages to all hosts on the LAN. In sparse mode, the designated access server also sends PIM register and PIM join messages towards the RP access server.
By default, the designated access server sends IGMP host-query messages once a minute in order to keep the IGMP overhead on hosts and networks very low. To modify this interval, perform the following task in interface configuration mode:
Configure the frequency at which the designated access server sends IGMP host-query messages.
ip igmp query-interval seconds
Control Access to IP Multicast Groups
Multicast access servers send IGMP host-query messages to determine which multicast groups have members of the access server's attached local networks. the access servers then forward to these group members all packets addressed to the multicast group. You can place a filter on each interface that restricts the multicast groups that hosts on the subnet serviced by the interface can join.
To filter multicast groups allowed on an interface, perform the following task in interface configuration mode:
Control the multicast groups that hosts on the subnet serviced by an interface can join.
ip igmp access-group access-list-number
Modify PIM Message Timers
By default, multicast access servers send PIM access server-query messages every 30 seconds. To modify this interval, perform the following task in interface configuration mode:
Configure the frequency at which multicast access servers send PIM access server-query messages.
ip pim query-interval seconds
Configure the TTL Threshold
The time-to-live (TTL) value controls whether packets are forwarded out of an interface. You specify the TTL value in hops. Any multicast packet with a TTL less than the interface TTL threshold is not forwarded on the interface. The default value is 0, which means that all multicast packets are forwarded on the interface. To change the default TTL threshold value, perform the following task in interface configuration mode:
Configure the TTL threshold of packets being forwarded out an interface.
ip multicast ttl-threshold ttl
Configure DVMRP Interoperability
Cisco multicast access servers using PIM can interoperate with non-Cisco multicast access servers that use the Distance Vector Multicast Routing Protocol (DVMRP).
PIM access servers dynamically discover DVMRP multicast access servers on attached networks. Once a DVMRP neighbor has been discovered, the access server periodically transmits DVMRP report messages advertising the unicast sources reachable in the PIM domain. By default, directly connected subnets and networks are advertised. the access server forwards multicast packets that have been forwarded by DVMRP access servers and in turn forwards multicast packets to DVMRP access servers.
You can configure what sources are advertised and what metrics are used by using the ip dvmrp metric command. You can also direct all sources learned via a particular unicast routing process to be advertised into DVMRP.
The mrouted protocol is a public domain implementation of DVMRP. It is necessary to use mrouted version 2.2 (which implements a nonpruning version of DVMRP) or version 3.2 (which implements a pruning version of DVMRP) when Cisco access servers are directly connected to DVMRP access servers or interoperate with DVMRP access servers over an MBONE tunnel. DVMRP advertisements produced by Cisco access servers can cause older versions of mrouted to corrupt their routing tables and those of their neighbors.
To configure the sources that are advertised and the metrics that are used when transmitting DVMRP report messages, perform the following task in interface configuration mode:
Configure the metric associated with a set of destinations for DVMRP reports.
ip dvmrp metric metric [access-list-number] [protocol process-id]
Our access servers answer mrinfo requests sent by mrouted systems. the access server returns information about neighbors on DVMRP tunnels. This information includes the metric, which is always set to 1, the configured TTL threshold, and the status of the tunnel.
For an example of how to configure a PIM access server to interoperate with a DVMRP access server, see the section "Configure DVMRP Interoperability Examples" later in this chapter.
Responding to MRINFO Requests
Our routers answer mrinfo requests sent by mrouted systems. The router returns information about neighbors on DVMRP tunnels. This information includes the metric, which is always set to 1, the configured TTL threshold, and the status of the tunnel.
For an example of how to configure a PIM router to interoperate with a DVMRP router, see the section "Configure DVMRP Interoperability Examples" later in this chapter.
Advertise Network 0.0.0.0 to DVMRP Neighbors
The mrouted protocol is a public domain implementation of DVMRP. If your access server is a neighbor to an mrouted version 3.6 machine, you can configure the access server to advertise network 0.0.0.0 to the DVMRP neighbor. You must specify whether only route 0.0.0.0 is advertised or whether other routes can also be advertised.
To advertise network 0.0.0.0 to DVMRP neighbors on an interface, perform the following task in interface configuration mode:
Advertise network 0.0.0.0 to DVMRP neighbors.
ip dvmrp default-information {originate | only}
Configure a DVMRP Tunnel
Cisco access servers can support DVMRP tunnels to the MBONE. (The MBONE is the multicast backbone of the Internet.) You can configure a DVMRP tunnel on an access server if the other end is running DVMRP. the access server then sends and receives multicast packets over the tunnel. This allows a PIM domain to connect to the DVMRP access server in the case where all access servers on the path do not support multicast routing.
When a Cisco access server runs DVMRP over a tunnel, it advertises sources in DVMRP report messages much as it does on real networks. In addition, DVMRP report messages received are cached on the access server and are used as part of its Reverse Path Forwarding (RPF) calculation. This allows multicast packets received over the tunnel to be forwarded by the access server.
When you configure a DVMRP tunnel, you should assign a tunnel an address for two reasons:
•
•
You can assign an IP address either by using the ip address interface configuration command or by using the ip unnumbered interface configuration command to configure the tunnel to be unnumbered. Either of these two methods allows IP multicast packets to flow over the tunnel. The IOS software will not advertise subnets over the tunnel if the tunnel has a different network number from the subnet. In this case, the IOS software advertises only the network number over the tunnel.
To configure a DVMRP tunnel, perform the following tasks:
Step 1
interface tunnel number1
Step 2
tunnel source ip-address1
Step 3
tunnel destination ip-address1
Step 4
tunnel mode dvmrp1
Step 5
or
Configure the interface as unnumbered.ip address address mask2
ip unnumbered type number2Step 6
ip pim [dense-mode | sparse-mode]
Step 7
ip dvmrp accept-filter access-list-number administrative-distance
1 This command is documented in the "Interface Commands" chapter of the Access and Communication Servers Command Reference publication.
2 This command is documented in the "IP Commands" chapter of the Access and Communication Servers Command Reference publication.
For an example of how to configure a DVMRP interoperability over a tunnel interface, see the section "Configure DVMRP Interoperability Examples" later in this chapter.
Configure an IP Multicast Static Route
IP multicast static routes (mroutes) allow you to have multicast paths diverge from the unicast paths. When using PIM, the router expects to receive packets on the same interface where it sends unicast packets back to the source. This is beneficial if your multicast and unicast topologies are congruent. However, you might want unicast packets to take one path and multicast packets to take another.
The most common reason for using separate unicast and multicast paths is tunneling. When a path between a source and a destination does not support multicast routing, a solution is to configure two routers with a GRE tunnel between them. In , the UR routers support unicast packets only; the MR routers support multicast packets.
Figure 19-3 A Tunnel for Multicast Packets
In , Source delivers multicast packets to Destination by using MR1 and MR2. MR2 accepts the multicast packet only if it thinks it can reach Source over the tunnel. If this is true, when Destination sends unicast packets to Source, MR2 sends them over the tunnel. This could be slower than natively sending the unicast packet through UR2, UR1, and MR1.
Prior to multicast static routes, the configuration in was used to overcome the problem of both unicasts and multicasts using the tunnel. In this figure, MR1 and MR2 are used as multicast routers only. When Destination sends unicast packets to Source, it uses the (UR3,UR2,UR1) path. When Destination sends multicast packets, the UR routers do not understand or forward them. But the MR routers forward the packets.
Figure 19-4 Separate Paths for Unicast and Multicast Packets
To make the configuration in work, MR1 and MR2 must run another routing protocol (typically a different instantiation of the same protocol running in the UR routers), so that paths from sources are learned dynamically.
A multicast static route allows you to use the configuration in by statically configuring a multicast source. The router uses the configuration information instead of the unicast routing table. This allows multicast packets to use the tunnel without having unicast packets use the tunnel.
To configure a multicast static route, perform the following task in global configuration mode:
Configure an IP multicast static route.
ip mroute source mask [protocol as-number] {rpf-address | type number} [distance]
Disable Fast Switching of IP Multicast
Fast switching of IP multicast packets is enabled by default on all interfaces, with one exception. It is disabled and not supported over X.25 encapsulated interfaces.
•
•
You might want to disable fast switching if you want to log debug messages, because when fast switching is enabled, debug messages are not logged.
To disable fast switching of IP multicast, perform the following task in interface configuration mode:
Control the Transmission Rate to a Multicast Group
By default, there is no limit to how fast a sender can transmit packets to a multicast group. You can control the rate that the sender from the source list can send to a multicast group in the group list by performing the following task in interface configuration mode:
Control transmission rate to a multicast group.
ip multicast rate-limit {in | out} [group-list access-list] [source-list access-list] kbps
Enable PIM Nonbroadcast, Multiaccess (NBMA) Mode
PIM nonbroadcast, multiaccess mode allows the router to replicate packets for each neighbor on the NBMA network. Traditionally, Cisco routers replicate multicast and broadcast packets to all "broadcast" configured neighbors. This might be inefficient when not all neighbors want packets for certain multicast groups. NBMA mode allows you to reduce bandwidth on links leading into the NBMA network, as well as CPU cycles in switches and attached neighbors.
Configure this feature on ATM, Frame Relay, SMDS, or X.25 networks only, especially when these media do not have native multicast available. Do not use this feature on multicast-capable LANs such as Ethernet or FDDI.
We encourage you to use sparse-mode PIM with this feature. Therefore, when each Join is received from NBMA neighbors, PIM stores each neighbor IP address/interface in the outgoing interface list for the group. When a packet is destined for the group, the router replicates the packet and unicasts (data-link unicasts) it to each neighbor that has joined the group.
To enable PIM nonbroadcast, multicaccess mode on your serial link, perform the following task in interface configuration mode:
Consider the following two factors before enabling PIM NBMA mode:
•
•
Enable SD Listener Support
The Multicast Backbone (Mbone) allows efficient, many-to-many communication and is widely used for multimedia conferencing. To help announce multimedia conference sessions and provide the necessary conference setup information to potential participants, the session directory (sd) tool was written. A session directory client announcing a conference session periodically multicasts an announcement packet on a well-known multicast address and port.
To enable session directory listener support, perform the following task in interface configuration mode:
Configure Routing Protocol-Independent Features
Previous sections addressed configurations of specific routing protocols. Complete the protocol-independent tasks described in the following sections as needed:
•
•
•
•
Use Variable-Length Subnet Masks
OSPF and static routes support variable-length subnet masks (VLSMs). With VLSMs, you can use different masks for the same network number on different interfaces, which allows you to conserve IP addresses and more efficiently use available address space. However, using VLSMs also presents address assignment challenges for the network administrator and ongoing administrative challenges.
Refer to RFC 1219 for detailed information about VLSMs and how to correctly assign addresses.
Note
The best way to implement VLSMs is to keep your existing numbering plan in place and gradually migrate some networks to VLSMs to recover address space. See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for an example of using VLSMs.
Configure Static Routes
Static routes are user-defined routes that cause packets moving between a source and a destination to take a specified path. Static routes can be important if the access server cannot build a route to a particular destination. They are also useful for specifying a gateway of last resort to which all unroutable packets will be sent.
To configure static routes, perform the following task in global configuration mode:
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for an example of configuring static routes.
the access server remembers static routes until you remove them (using the no form of the ip route global configuration command). However, you can override static routes with dynamic routing information through prudent assignment of administrative distance values. Each dynamic routing protocol has a default administrative distance, as listed in . If you would like a static route to be overridden by information from a dynamic routing protocol, simply ensure that the administrative distance of the static route is higher than that of the dynamic protocol.
Static routes that point to an interface will be advertised via RIP, IGRP, and other dynamic routing protocols, regardless of whether redistribute static commands were specified for those routing protocols. This is because static routes that point to an interface are considered in the routing table to be connected and hence lose their static nature. However, if you define a static route to an interface that is not one of the networks defined in a network command, no dynamic routing protocols will advertise the route unless a redistribute static command is specified for these protocols.
When an interface goes down, all static routes through that interface are removed from the IP routing table. Also, when the access server can no longer find a valid next hop for the address specified as the forwarding access server's address in a static route, the static route is removed from the IP routing table.
Table 19-2 Default Administrative Distances
Connected interface
0
Static route
1
External BGP
20
IGRP
100
OSPF
110
RIP
120
EGP
140
Internal BGP
200
Unknown
255
Specify Default Routes
An access server might not be able to determine the routes to all other networks. To provide complete routing capability, the common practice is to use some access servers as "smart access servers" and give the remaining access servers default routes to the smart access server. (Smart access servers have routing table information for the entire internetwork.) These default routes can be passed along dynamically or can be configured into the individual access servers.
Most dynamic interior gateway routing protocols include a mechanism for causing a smart access server to generate dynamic default information that is then passed along to other access servers.
Specify a Default Network
If an access server has a directly connected interface onto the specified default network, the dynamic routing protocols running on that access server will generate or source a default route. RIP advertises the pseudonetwork 0.0.0.0. For IGRP, the network itself is advertised and flagged as an exterior route.
An access server that is generating the default for a network may also need a default of its own. One way of doing this is to specify a static route to the network 0.0.0.0 through the appropriate access server.
To define a static route to a network as the static default route, perform the following task in global configuration mode:
Gateway of Last Resort
When default information is being passed along through a dynamic routing protocol, no further configuration is required. The system will periodically scan its routing table to choose the optimal default network as its default route. In the case of RIP, it will be only one choice, network 0.0.0.0. In the case of IGRP, there might be several networks that can be candidates for the system default. the access server uses both administrative distance and metric information to determine the default route (gateway of last resort). The selected default route appears in the gateway of last resort display of the show ip route EXEC command.
If dynamic default information is not being passed to the access server, candidates for the default route can be specified with the ip default-network command. In this usage, ip default-network takes an unconnected network as an argument. If this network appears in the routing table from any source (dynamic or static), it is flagged as a candidate default route and is a possible choice as the default route for the access server.
If the access server has no interface on the default network but does have a route to it, it will consider this network as a candidate default path. The route candidates will be examined and the best one will be chosen based on administrative distance and metric. The gateway to the best default path will become the gateway of last resort for the access server.
Redistribute Routing Information
In addition to running multiple routing protocols simultaneously, the router can redistribute information from one routing protocol to another. For example, you can instruct the router to readvertise IGRP-derived routes using the RIP protocol, or to readvertise static routes using the IGRP protocol. This applies to all of the IP-based routing protocols.
You can also conditionally control the redistribution of routes between routing domains by defining a method known as route maps between the two domains.
The following four tables list tasks associated with route redistribution.
To define a route map for redistribution, perform the following task in global configuration mode:
Define any route maps needed to control redistribution.
route-map map-tag [[permit | deny] | [sequence-number]]
A pair of match and set commands are required to follow a route-map command. To define conditions for redistributing routes from one routing protocol into another, perform at least one of the following tasks in route-map configuration mode:
A pair of match and set commands are required to follow a route-map command. To define conditions for redistributing routes from one routing protocol into another, perform at least one of the following tasks in route-map configuration mode:
For examples of BGP route maps, see the section "BGP Route Map Examples" at the end of this chapter.
To distribute routes from one routing domain into another and to control route redistribution, perform the following tasks in router configuration mode:
The metrics of one routing protocol do not necessarily translate into the metrics of another. For example, the RIP metric is a hop count and the IGRP metric is a combination of five quantities. In such situations, an artificial metric is assigned to the redistributed route. Because of this unavoidable tampering with dynamic information, carelessly exchanging routing information between different routing protocols can create routing loops, which can seriously degrade network operation.
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for examples of configuring redistribution and route maps.
Supported Metric Translations
This section describes supported automatic metric translations between the routing protocols. The following descriptions assume that you have not defined a default redistribution metric that replaces metric conversions.
•
•
•
•
•
Filter Routing Information
You can filter routing protocol information by performing the following tasks:
•
•
•
•
•
Note
The following sections describe these tasks.
Prevent Routing Updates through an Interface
To prevent a routing process from learning about routes dynamically, you can keep routing update messages from being sent through an access server interface. This feature applies to all IP-based routing protocols except BGP and EGP.
OSPF behavior is somewhat different. In OSPF, the interface address you specify as passive appears as a stub network in the OSPF domain. OSPF routing information is neither sent nor received through the specified access server interface.
To prevent routing updates through a specified interface, perform the following task in router configuration mode:
Suppress the transmission of routing updates through the specified access server interface.
passive-interface type number
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for examples of configuring passive interfaces.
Control the Advertising of Routes in Routing Updates
To prevent other routers from learning one or more routes, you can prevent the advertising of routes in routing updates. You cannot specify an interface name in OSPF. When used for OSPF, this feature applies only to external routes.
To prevent routes from being advertised in routing updates, perform the following task in router configuration mode:
Permit or deny advertising of routes in routing updates depending upon the action listed in the access list.
distribute-list access-list-number out [type number |
routing-process]
Control the Processing of Routing Updates
You might want to avoid processing certain routes listed in incoming updates. This feature does not apply to OSPF.
Perform this task in router configuration mode:
Suppress routes listed in updates from being processed.
distribute-list access-list-number in [type number]
Apply Offsets to Routing Metrics
An offset list is the mechanism for adding positive offset to incoming and outgoing metrics to routes learned via RIP and IGRP. You have an option to limit the offset list with either an access list or an interface. To increase the value of routing metrics, perform the following task in router configuration mode:
Apply an offset to routing metrics.
offset-list {in | out} offset [access-list-number | [interface-type interface-number]]
Filter Sources of Routing Information
An administrative distance is a rating of the trustworthiness of a routing information source, such as an individual access server or a group of access servers. In a large network, some routing protocols and some access servers can be more reliable than others as sources of routing information. Also, when multiple routing processes are running in the same access server for IP, it is possible for the same route to be advertised by more than one routing process. By specifying administrative distance values, you enable the access server to discriminate intelligently between sources of routing information. the access server will always pick the route whose routing protocol has the lowest administrative distance.
There are no general guidelines for assigning administrative distances, because each network has its own requirements. You must determine a reasonable matrix of administrative distances for the network as a whole. shows the default administrative distance for various sources of routing information.
Table 19-3 Default Administrative Distances
Connected interface
0
Static route
1
External BGP
20
IGRP
100
OSPF
110
RIP
120
EGP
140
Internal BGP
200
Unknown
255
For example, consider an access server using IGRP and RIP. Suppose you trust the IGRP-derived routing information more than the RIP-derived routing information. In this example, because the default IGRP administrative distance is lower than the default RIP administrative distance, the access server uses the IGRP-derived information and ignores the RIP-derived information. However, if you lose the source of the IGRP-derived information (to a power shutdown in another building, for example), the access server uses the RIP-derived information until the IGRP-derived information reappears.
Note
To filter sources of routing information, perform the following task in router configuration mode:
Filter on routing information sources.
distance weight [address-mask [access-list-number]] [ip]
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for examples of setting administrative distances.
Enable Policy Routing
Policy routing is a more flexible mechanism for routing packets than destination routing. It is a process whereby the router puts packets through a route map before routing them. The route map determines which packets are routed to which router next. You might enable policy routing if you want certain packets to be routed some way other than the obvious shortest path. Some possible applications for policy routing are to provide equal access, protocol-sensitive routing, source-sensitive routing, routing based on interactive versus batch traffic, or routing based on dedicated links.
To enable policy routing, you must identify which route map to use for policy routing and create the route map. The route map itself specifies the match criteria and the resulting action if all of the match clauses are met. These steps are described in the next three task tables.
To enable policy routing on an interface, indicate which route map the router should use by performing the following task in interface configuration mode. All packets arriving on the specified interface will subject to policy routing. This command disables fast switching of all packets arriving on this interface.
You must also define the route map to be used for policy routing. Perform the following task in global configuration mode:
Define a route map to control where packets are output.
route-map map-tag [permit | deny] [sequence-number]
The next step is to define the criteria by which packets are examined to see if they will be policy routed. No match clause in the route map indicates all packets. Perform one or more of the following tasks in route-map configuration mode:
The last step is to specify where the packets that pass the match criteria are output. To do so, perform one or more of the following tasks in route-map configuration mode:
The set commands can be used in conjunction with each other. They are evaluated in the order shown in the task table above. A usable next hop implies an interface. Once the local router finds a next hop and a usable interface, it routes the packet.
Enable Local Policy Routing
Packets that are generated by the router are not normally policy routed. To enable local policy routing for such packets, indicate which route map the router should use by performing the following task in global configuration mode. All packets originating on the router will then be subject to local policy routing.
Identify the route map to use for local policy routing.
ip local policy route-map map-tag
Use the show ip local policy command to display the route map used for local policy routing, if one exists.
Adjust Timers
Routing protocols use a variety of timers that determine such variables as the frequency of routing updates, the length of time before a route becomes invalid, and other parameters. You can adjust these timers to tune routing protocol performance to better suit your internetwork needs.
For IGRP and RIP, you can make the following timer adjustments:
•
•
•
•
•
EGP and BGP have their own timers commands, although some EGP timers might be set with the timers basic command. See the EGP and BGP sections, respectively.
It also is possible to tune the IP routing support in the software to enable faster convergence of the various IP routing algorithms and hence, quicker fallback to redundant access servers. The total effect is to minimize disruptions to end users of the network in situations where quick recovery is essential.
The following two tables list tasks associated with adjusting routing protocol timers and the keepalive interval.
Perform the following task in router configuration mode:
Perform the following the following task in interface configuration mode:
Adjust the frequency with which the access server sends messages to itself (Ethernet and Token Ring) or to the other end (HDLC-serial and PPP-serial links) to ensure that a network interface is alive for a specified interface.
keepalive [seconds] 1
1 This command is documented in the "Interface Commands" chapter of the Access and Communication Servers Command Reference publication.
You can also configure the keepalive interval, the frequency at which the access server sends messages to itself (Ethernet and Token Ring) or to the other end (hdlc-serial, ppp-serial) to ensure that a network interface is alive. The interval in some previous software versions was 10 seconds; it is now adjustable in 1-second increments down to one second. An interface is declared down after three update intervals have passed without receiving a keepalive packet.
When adjusting the keepalive timer for a very low bandwidth serial interface, large packets can delay the smaller keepalive packets long enough to cause the line protocol to go down. You might need to experiment to determine the best value.
Adjust the Interval between Hello Packets and the Hold Time (EIGRP)
You can adjust the interval between hello packets and the hold time.
Routers periodically send hello packets to each other to learn dynamically about other access servers or routers on their directly attached networks. the access servers use this information to discover who their neighbors are and to learn when their neighbors become unreachable or inoperative. By default, hello packets are sent every 5 seconds.
You can configure the hold time on a specified interface for the IP Enhanced IGRP routing process designated by the autonomous system number. The hold time is advertised in hello packets and indicates to neighbors the length of time they should consider the sender valid. The default hold time is three times the hello interval, or 15 seconds.
To change the interval between hello packets, perform the following task in interface configuration mode:
Configure the hello interval for an IP Enhanced IGRP routing process.
ip hello-interval eigrp autonomous-system-number seconds
On very congested and large networks, 15 seconds may not be sufficient time for all access servers to receive hello packets from their neighbors. In this case, you may want to increase the hold time.
To change the hold time, perform the following task in interface configuration mode:
Configure the hold time for an IP Enhanced IGRP routing process.
ip hold-time eigrp autonomous-system-number seconds
Note
Enable or Disable Split Horizon
Normally, access servers that are connected to broadcast-type IP networks and that use distance-vector routing protocols employ the split horizon mechanism to reduce the possibility of routing loops. Split horizon blocks information about routes from being advertised by an access server out any interface from which that information originated. This behavior usually optimizes communications among multiple access servers, particularly when links are broken. However, with nonbroadcast networks, such as Frame Relay and SMDS, situations can arise for which this behavior is less than ideal. For these situations, you might want to disable split horizon. This applies to IGRP and RIP.
If an interface is configured with secondary IP addresses, split horizon rules can affect whether or not routing updates are sourced by these secondary addresses. If the primary and secondary IP address network numbers belong to the same network class, routing updates source by the secondary address are suppressed unless split horizon is disabled. If the primary and secondary addresses do not belong to the same network class, routing updates sourced by the secondary address are not suppressed.
To enable or disable split horizon, perform the following tasks in interface configuration mode:
Split horizon for Frame Relay and SMDS encapsulation is disabled by default. Split horizon is not disabled by default for interfaces using any of the X.25 encapsulations. For all other encapsulations, split horizon is enabled by default.
See the "IP Routing Protocol Configuration Examples" section at the end of this chapter for an example of using split horizon.
Note
Monitor and Maintain the IP Network
You can remove all contents of a particular cache, table, or database. You also can display specific access server statistics. The following sections describe each of these tasks.
Clear Caches, Tables, and Databases
You can remove all contents of a particular cache, table, or database. Clearing a cache, table, or database can become necessary when the contents of the particular structure have become or are suspected to be invalid.
The following table lists the tasks associated with clearing caches, tables, and databases for IP routing protocols. Perform these tasks in EXEC mode:
Display System and Network Statistics
You can display specific statistics such as the contents of IP routing tables, caches, and databases. Information provided can be used to determine resource utilization and solve network problems. You can also display information about node reachability and discover the routing path your router's packets are taking through the network.
To display various router statistics, perform the following tasks in EXEC mode:
IP Routing Protocol Configuration Examples
The following sections provide IP routing protocol configuration examples:
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
Variable-Length Subnet Masks Example
OSPF and static routes support variable-length subnet masks (VLSMs). With VLSMs, you can use different masks for the same network number on different interfaces, which allows you to conserve IP addresses and more efficiently use available address space.
In the following example, a 14-bit subnet mask is used, leaving two bits of address space reserved for serial line host addresses. There is sufficient host address space for two host endpoints on a point-to-point serial link.
interface ethernet 0ip address 131.107.1.1 255.255.255.0! 8 bits of host address space reserved for ethernetsinterface serial 0ip address 131.107.254.1 255.255.255.252! 2 bits of address space reserved for serial lines! System is configured for OSPF and assigned AS 107router ospf 107! Specifies network directly connected to the systemnetwork 131.107.0.0 0.0.255.255 area 0.0.0.0Overriding Static Routes with Dynamic Protocols Example
In the following example, packets for network 10.0.0.0 from Router B, where the static route is installed, will be routed through 172.16.3.4 if a route with an administrative distance less than 110 is not available. Figure 19-5 illustrates this point. The route learned by a protocol with an administrative distance of less than 110 might cause Router B to send traffic destined for network 10.0.0.0 via the alternate path—through Router D.
ip route 10.0.0.0 255.0.0.0 172.16.3.4 110Figure 19-5 Overriding Static Routes
OSPF Point-to-Multipoint Example
In , Mollie uses DLCI 201 to communicate with Neon, DLCI 202 to Jelly, and DLCI 203 to Platty. Neon uses DLCI 101 to communicate with Mollie and DLCI 102 to communicate with Platty. Platty communicates with Neon (DLCI 401) and Mollie (DLCI 402). Jelly communicates with Mollie (DLCI 301).
Figure 19-6 OSPF Point-to-Multipoint Example
Mollie's Configuration
hostname mollie!interface serial 1ip address 10.0.0.2 255.0.0.0ip ospf network point-to-multipointencapsulation frame-relayframe-relay map ip 10.0.0.1 201 broadcastframe-relay map ip 10.0.0.3 202 broadcastframe-relay map ip 10.0.0.4 203 broadcast!router ospf 1network 10.0.0.0 0.0.0.255 area 0Neon's Configuration
hostname neon!interface serial 0ip address 10.0.0.1 255.0.0.0ip ospf network point-to-multipointencapsulation frame-relayframe-relay map ip 10.0.0.2 101 broadcastframe-relay map ip 10.0.0.4 102 broadcast!router ospf 1network 10.0.0.0 0.0.0.255 area 0Platty's Configuration
hostname platty!interface serial 3ip address 10.0.0.4 255.0.0.0ip ospf network point-to-multipointencapsulation frame-relayclockrate 1000000frame-relay map ip 10.0.0.1 401 broadcastframe-relay map ip 10.0.0.2 402 broadcast!router ospf 1network 10.0.0.0 0.0.0.255 area 0Jelly's Configuration
hostname jelly!interface serial 2ip address 10.0.0.3 255.0.0.0ip ospf network point-to-multipointencapsulation frame-relayclockrate 2000000frame-relay map ip 10.0.0.2 301 broadcast!router ospf 1network 10.0.0.0 0.0.0.255 area 0Static Routing Redistribution Examples
In the example that follows, three static routes are specified, two of which are to be advertised. Do this by specifying the redistribute static router configuration command, then specifying an access list that allows only those two networks to be passed to the IGRP process. Any redistributed static routes should be sourced by a single access server to minimize the likelihood of creating a routing loop.
ip route 192.1.2.0 255.255.255.0 192.168.7.65ip route 193.62.5.0 255.255.255.0 192.168.7.65ip route 172.16.0.0 255.255.255.0 192.168.7.65access-list 3 permit 192.1.2.0access-list 3 permit 193.62.5.0!router igrp 109network 192.168.7.0default-metric 10000 100 255 1 1500redistribute staticdistribute-list 3 out staticThe same basic example can be adapted for IP Enhanced IGRP operation:
ip route 192.1.2.0 255.255.255.0 192.168.7.65ip route 193.62.5.0 255.255.255.0 192.168.7.65ip route 172.16.0.0 255.255.0.0 192.168.7.65access-list 3 permit 192.1.2.0access-list 3 permit 193.62.5.0!router eigrp 109network 192.168.7.0redistribute static route-map static-to-eigrproute-map static-to-eigrpmatch ip address 3set metric 10000 100 255 1 1500IGRP Redistribution Examples
Each IGRP routing process can provide routing information to only one autonomous system; the access server must run a separate IGRP process and maintain a separate routing database for each autonomous system it services. However, you can transfer routing information between these routing databases.
Suppose the access server has one IGRP routing process for network 15.0.0.0 in autonomous system 71 and another for network 192.168.7.0 in autonomous system 109, as the following commands specify:
router igrp 71network 15.0.0.0router igrp 109network 192.168.7.0To transfer a route to 192.168.7.0 into autonomous system 71 (without passing any other information about autonomous system 109), use the command in the following example:
router igrp 71redistribute igrp 109distribute-list 3 out igrp 109access-list 3 permit 192.168.7.0IP Enhanced IGRP Redistribution Examples
Each IP Enhanced IGRP routing process can provide routing information to only one autonomous system; the access server must run a separate IP Enhanced IGRP process and maintain a separate routing database for each autonomous system it services. However, you can transfer routing information between these routing databases.
Suppose the access server has one IP Enhanced IGRP routing process for network 15.0.0.0 in autonomous system 71 and another for network 192.168.7.0 in autonomous system 109, as the following commands specify:
router eigrp 71network 15.0.0.0router eigrp 109network 192.168.7.0To transfer a route from 192.168.7.0 into autonomous system 71 (without passing any other information about autonomous system 109), use the command in the following example:
router eigrp 71redistribute eigrp 109 route-map 109-to-71route-map 109-to-71 permitmatch ip address 3set metric 10000 100 1 255 1500access-list 3 permit 192.168.7.0The following example is an alternative way to transfer a route to 192.168.7.0 into autonomous system 71. Unlike the previous configuration, this one does not allow you to arbitrarily set the metric.
router eigrp 71redistribute eigrp 109distribute-list 3 out eigrp 109access-list 3 permit 192.168.7.0RIP and IGRP Redistribution Example
Consider a WAN at a university that uses RIP as an interior routing protocol. Assume that the university wants to connect its wide area network to a regional network, 192.168.0.0, which uses IGRP as the routing protocol. The goal in this case is to advertise the networks in the university network to the access servers on the regional network. The commands for the interconnecting access server are listed in the example that follows:
router igrp 109network 192.168.0.0redistribute ripdefault-metric 10000 100 255 1 1500distribute-list 10 out ripIn this example, the router global configuration command starts an IGRP routing process. The network router configuration command specifies that network 192.168.0.0 (the regional network) is to receive IGRP routing information. The redistribute router configuration command specifies that RIP-derived routing information be advertised in the routing updates. The default-metric router configuration command assigns an IGRP metric to all RIP-derived routes.
The distribute-list router configuration command instructs the access server to use access list 10 (not defined in this example) to limit the entries in each outgoing update. The access list prevents unauthorized advertising of university routes to the regional network.
RIP and IP Enhanced IGRP Redistribution Examples
This section provides a simple example and a complex example.
Example 1: Simple Redistribution
Consider a wide-area network at a university that uses RIP as an interior routing protocol. Assume that the university wants to connect its wide-area network to a regional network, 192.168.0.0, which uses IP Enhanced IGRP as the routing protocol. The goal is to advertise the networks in the university network to the routers on the regional network. The following example shows the commands for the interconnecting router:
router eigrp 109network 192.168.0.0redistribute ripdefault-metric 10000 100 255 1 1500distribute-list 10 out ripThe router global configuration command starts an IP Enhanced IGRP routing process. The network router configuration command specifies that network 192.168.0.0 (the regional network) is to send and receive IP Enhanced IGRP routing information. The redistribute router configuration command specifies that RIP-derived routing information be advertised in the routing updates. The default-metric router configuration command assigns an IP Enhanced IGRP metric to all RIP-derived routes.
The distribute-list router configuration command instructs the router to use access list 10 (not defined in this example) to limit the entries in each outgoing update. The access list prevents unauthorized advertising of university routes to the regional network.
Example 2: Complex Redistribution
The most complex redistribution case is one in which mutual redistribution is required between an IGP (in this case, IP Enhanced IGRP) and BGP.
Suppose that EGP is running on a router somewhere else in autonomous system 1, and that the EGP routes are injected into IP Enhanced IGRP routing process 1. You must use filters to ensure that the proper routes are advertised. The example configuration for router R1 illustrates use of access filters and a distribution list to filter routes advertised to BGP neighbors. This example also illustrates configuration commands for redistribution between BGP and IP Enhanced IGRP.
! Configuration for router R1:router bgp 1network 172.16.0.0neighbor 192.5.10.1 remote-as 2neighbor 192.5.10.15 remote-as 1! 172.16.2.1 an internal peerneighbor 192.5.10.24 remote-as 3! 172.16.3.1 is an external peerredistribute eigrp 1distribute-list 1 out eigrp 1!! All networks that should be advertised from R1 are controlled with access lists:!access-list 1 permit 172.16.0.0access-list 1 permit 150.136.0.0access-list 1 permit 192.16825.0.0!router eigrp 1network 172.16.0.0network 192.5.10.0redistribute bgp 1OSPF Routing and Route Redistribution Examples
OSPF typically requires coordination among many internal access servers, access servers acting as area border routers, and access servers acting as autonomous system boundary routers. At a minimum, OSPF-based access servers can be configured with all default parameter values, with no authentication, and with interfaces assigned to areas.
Three examples follow:
•
•
•
Example 1: Basic OSPF Configuration
The following example illustrates a simple OSPF configuration that enables OSPF routing process 9000, attaches Ethernet 0 to area 0.0.0.0, and redistributes RIP into OSPF, and OSPF into RIP:
interface ethernet 0ip address 172.23.1.1 255.255.255.0ip ospf cost 1!interface ethernet 1ip address 172.24.1.1 255.255.255.0!router ospf 9000network 172.23.0.0 0.0.255.255 area 0.0.0.0redistribute rip metric 1 subnets!router ripnetwork 172.24.0.0redistribute ospf 9000default-metric 1Example 2: Another Basic OSPF Configuration
The following example illustrates the assignment of four area IDs to four IP address ranges. In the example, OSPF routing process 109 is initialized, and four OSPF areas are defined: 10.9.50.0, 2, 3, and 0. Areas 10.9.50.0, 2, and 3 mask specific address ranges, while Area 0 enables OSPF for all other networks.
router ospf 109network 172.16.20.0 0.0.0.255 area 10.9.50.0network 172.16.0.0 0.0.255.255 area 2network 172.29.10.0 0.0.0.255 area 3network 0.0.0.0 255.255.255.255 area 0!! Interface Ethernet0 is in area 10.9.50.0:interface ethernet 0ip address 172.16.20.5 255.255.255.0!! Interface Ethernet1 is in area 2:interface ethernet 1ip address 172.16.1.5 255.255.255.0!! Interface Ethernet2 is in area 2:interface ethernet 2ip address 172.16.2.5 255.255.255.0!! Interface Ethernet3 is in area 3:interface ethernet 3ip address 172.29.10.5 255.255.255.0!! Interface Ethernet4 is in area 0:interface ethernet 4ip address 172.29.1.1 255.255.255.0!! Interface Ethernet5 is in area 0:interface ethernet 5ip address 10.1.0.1 255.255.0.0Each network router configuration command is evaluated sequentially, so the specific order of these commands in the configuration is important. the access server sequentially evaluates the address/wildcard-mask pair for each interface. See the "IP Routing Protocols Commands" chapter of the Access and Communication Servers Command Reference publication for more information.
Consider the first network command. Area ID 10.9.50.0 is configured for the interface on which subnet 172.16.20.0 is located. Assume that a match is determined for Ethernet interface 0. Ethernet interface 0 is attached to Area 10.9.50.0 only.
The second network command is evaluated next. For Area 2, the same process is then applied to all interfaces (except Ethernet interface 0). Assume that a match is determined for Ethernet interface 1. OSPF is then enabled for that interface and Ethernet 1 is attached to Area 2.
This process of attaching interfaces to OSPF areas continues for all network commands. Note that the last network command in this example is a special case. With this command all available interfaces (not explicitly attached to another area) are attached to Area 0.
Example 3: Internal, Area Border, and Autonomous System Boundary Routers
The following example outlines a configuration for several access servers within a single OSPF autonomous system. Figure 19-7 provides a general network map that illustrates this example configuration.
Figure 19-7 Sample OSPF Autonomous System Network Map
In this configuration, five access servers are configured in OSPF autonomous system (AS) 109:
•
•
•
•
Note
Autonomous System 109 is connected to the outside world via the BGP link to the external peer at IP address 11.0.0.6.
Configuration for Access Server A - Internal Router
interface ethernet 1ip address 172.16.1.1 255.255.255.0router ospf 109network 172.16.0.0 0.0.255.255 area 1Configuration for Access Server B - Internal Router
interface ethernet 2ip address 172.16.1.2 255.255.255.0router ospf 109network 172.16.0.0 0.0.255.255 area 1Configuration for Access Server C - Area Border Router
interface ethernet 0ip address 172.16.1.3 255.255.255.0interface serial 0ip address 172.16.2.3 255.255.255.0router ospf 109network 172.16.1.0 0.0.0.255 area 1network 172.16.2.0 0.0.0.255 area 0Configuration for Access Server D - Internal Router
interface ethernet 4ip address 10.0.0.4 255.0.0.0interface serial 1ip address 172.16.2.4 255.255.255.0router ospf 109network 172.16.2.0 0.0.0.255 area 0network 10.0.0.0 0.255.255.255 area 0Configuration for Access Server E - Autonomous System Boundary Router
interface ethernet 5ip address 10.0.0.5 255.0.0.0interface serial 2ip address 11.0.0.5 255.0.0.0router ospf 109network 10.0.0.0 0.255.255.255 area 0redistribute bgp 109 metric 1 metric-type 1router bgp 109network 172.16.0.0network 10.0.0.0neighbor 11.0.0.6 remote-as 110Example 4: Complex OSPF Configuration
The following example configuration accomplishes several tasks in setting up an access server to act as an area border router. These tasks can be split into two general categories:
•
•
The specific tasks outlined in this configuration are detailed briefly in the following descriptions. Figure 19-8 illustrates the network address ranges and area assignments for the interfaces.
Figure 19-8 Interface and Area Specifications for OSPF Example Configuration
The basic configuration tasks in this example are as follows:
•
•
•
•
•
•
Configuration tasks associated with redistribution are as follows:
•
•
The following is an example OSPF configuration:
interface ethernet 0ip address 192.168.110.201 255.255.255.0ip ospf authentication-key abcdefghip ospf cost 10!interface ethernet 1ip address 172.19.251.201 255.255.255.0ip ospf authentication-key ijklmnopip ospf cost 20ip ospf retransmit-interval 10ip ospf transmit-delay 2ip ospf priority 4!interface ethernet 2ip address 172.19.254.201 255.255.255.0ip ospf authentication-key abcdefghip ospf cost 10!interface ethernet 3ip address 36.56.0.201 255.255.0.0ip ospf authentication-key ijklmnopip ospf cost 20ip ospf dead-interval 80OSPF is on network 172.19:
router ospf 201network 36.0.0.0 0.255.255.255 area 36.0.0.0network 192.168.110.0 0.0.0.255 area 192.168.110.0network 172.19.0.0 0.0.255.255 area 0area 0 authenticationarea 36.0.0.0 stubarea 36.0.0.0 authenticationarea 36.0.0.0 default-cost 20area 192.168.110.0 authenticationarea 36.0.0.0 range 36.0.0.0 255.0.0.0area 192.168.110.0 range 192.168.110.0 255.255.255.0area 0 range 172.19.251.0 255.255.255.0area 0 range 172.19.254.0 255.255.255.0redistribute igrp 200 metric-type 2 metric 1 tag 200 subnetsredistribute rip metric-type 2 metric 1 tag 200IGRP AS 200 is on 172.19.0.0:
router igrp 200network 172.19.0.0!! RIP for 192.168.110!router ripnetwork 192.168.110.0redistribute igrp 200 metric 1redistribute ospf 201 metric 1BGP Route Advertisement and Redistribution Examples
The following examples illustrate configurations for advertising and redistributing BGP routes. The first example details the configuration for two neighboring access servers that run IGRP within their respective autonomous systems and that are configured to advertise their respective BGP routes between each other. The second example illustrates route redistribution of BGP into IGRP and IGRP into BGP.
Example 1: Simple BGP Route Advertisement
This example provides the required configuration for two access servers (AS1 and AS2) that are intended to advertise BGP routes to each other and to redistribute BGP into IGRP.
Configuration for AS1
! Assumes autonomous system 1 has network number 172.16.0.0router bgp 1network 172.16.0.0neighbor 192.5.10.1 remote-as 2!router igrp 1network 172.16.0.0network 192.5.10.0redistribute bgp 1! Note that IGRP is not redistributed into BGPConfiguration for AS2
router bgp 2network 150.136.0.0neighbor 192.5.10.2 remote-as 1!router igrp 2network 150.136.0.0network 192.5.10.0redistribute bgp 2Example 2: Mutual Route Redistribution
The most complex redistribution case is one in which mutual redistribution is required between an IGP (in this case IGRP) and BGP.
Suppose that EGP is running on an access server somewhere else in autonomous system 1, and that the EGP routes are injected into IGRP routing process 1. You must filter to ensure that the proper routes are advertised. The example configuration for access server R1 illustrates use of access filters and a distribution list to filter routes advertised to BGP neighbors. This example also illustrates configuration commands for redistribution between BGP and IGRP. Only routes learned using the EBGP session with neighbors 192.5.10.1 and 192.5.10.24 are redistributed into IGRP.
Configuration for Access Server AS1
router bgp 1network 172.16.0.0neighbor 192.5.10.1 remote-as 2! External peer or neighborneighbor 192.5.10.15 remote-as 1! Same AS; therefore internal neighborneighbor 192.5.10.24 remote-as 3! A second External neighborredistribute igrp 1distribute-list 1 out igrp 1!! All networks that should be! advertised from R1 are! controlled with access lists:!access-list 1 permit 172.16.0.0access-list 1 permit 150.136.0.0access-list 1 permit 192.168.0.0!router igrp 1network 172.16.0.0network 192.5.10.0redistribute bgp 1Default Metric Values Redistribution Examples
The following example shows an access server in autonomous system 109 using both the RIP and the IGRP routing protocols. The example advertises IGRP-derived routes using the RIP protocol and assigns the IGRP-derived routes a RIP metric of 10.
router ripdefault-metric 10redistribute igrp 109Figure 19-9 shows this type of redistribution.
Figure 19-9 Assigning Metrics for Redistribution
Route-Map Examples
The examples in this section illustrate the use of redistribution, with and without route maps. Examples from both the IP and CLNS routing protocols are given.
The following example redistributes all OSPF routes into IGRP:
router igrp 109redistribute ospf 110The following example redistributes all OSPF routes into IP Enhanced IGRP:
router eigrp 109redistribute ospf 110default-metric 1000 100 255 1 1500The following example redistributes RIP routes with a hop count equal to 1 into OSPF. These routes will be redistributed into OSPF as external link state advertisements with a metric of 5, metric type of Type 1, and a tag equal to 1.
router ospf 109redistribute rip route-map rip-to-ospf!route-map rip-to-ospf permitmatch metric 1set metric 5set metric-type type1set tag 1The following example redistributes OSPF learned routes with tag 7 as a RIP metric of 15:
router ripredistribute ospf 109 route-map 5!route-map 5 permitmatch tag 7set metric 15The following example redistributes OSPF intra-area and interarea routes with next-hop access servers on serial interface 0 into BGP with an INTER_AS metric of 5:
router bgp 109redistribute ospf 109 route-map 10!route-map 10 permitmatch route-type internalmatch interface serial 0set metric 5With the following configuration, OSPF external routes with tags 1, 2, 3, and 5 are redistributed into RIP with metrics of 1, 1, 5, and 5, respectively. The OSPF routes with a tag of 4 are not redistributed.
router ripredistribute ospf 109 route-map 1!route-map 1 permitmatch tag 1 2set metric 1!route-map 1 permitmatch tag 3set metric 5!route-map 1 denymatch tag 4!route map 1 permitmatch tag 5set metric 5The following configuration sets the condition that if there is an OSPF route to network 140.222.0.0, generate the default network 0.0.0.0 into RIP with a metric of 1:
router ripredistribute ospf 109 route-map default!route-map default permitmatch ip address 1set metric 1!access-list 1 permit 140.222.0.0 0.0.255.255access-list 2 permit 0.0.0.0 0.0.0.0The following configuration example illustrates how a route map is referenced by the default-information router configuration command. This is called conditional default origination. OSPF will originate the default route (network 0.0.0.0) with a Type 2 metric of 5 if 140.222.0.0, with network 0.0.0.0 in the routing table.
route-map ospf-default permitmatch ip address 1set metric 5set metric-type type-2!access-list 1 140.222.0.0 0.0.255.255!router ospf 109default-information originate route-map ospf-defaultBGP Route Map Examples
The following example shows how you can use route maps to modify incoming data from a neighbor. Any route received from 140.222.1.1 that matches the filter parameters set in autonomous system access list 200 will have its weight set to 200 and its local preference set to 250 and will be accepted.
router bgp 100!neighbor 140.222.1.1 route-map fix-weight inneighbor 140.222.1.1 remote-as 1!route-map fix-weight permit 10match as-path 200set local-preference 250set weight 200!ip as-path access-list 200 permit ^690$ip as-path access-list 200 permit ^1800The following example shows how you can use route maps to modify outbound data to a neighbor:
router bgp 100neighbor 192.168.68.23 route-map oscar out!route-map oscarset metric 150match as-path 1!ip as-path access-list 1 permit ^2200_In the following example, route map freddy marks all paths originating from autonomous system 690 with a multiple exit discriminator (MULTI_EXIT_DISC) metric attribute of 127. The second permit clause is required so that routes not matching autonomous system path list 1 will still be accepted from neighbor 1.1.1.1.
router bgp 100neighbor 1.1.1.1 route-map freddy in!ip as-path access-list 1 permit ^690_ip as-path access-list 2 permit .*!route-map freddy permit 10match as-path 1set metric 127!route-map freddy permit 20match as-path 2The following example shows how you can use route maps to modify incoming data from the IP forwarding table:
router bgp 100redistribute igrp 109 route-map igrp2bgp!route-map igrp2bgpmatch ip address 1set local-preference 25set metric 127set weight 30000set next-hop 192.92.68.24set origin igp!access-list 1 permit 172.16.0.0 0.0.255.255access-list 1 permit 160.89.0.0 0.0.255.255access-list 1 permit 198.112.0.0 0.0.127.255It is proper behavior not to accept any autonomous system path not matching the match clause of the route map. This means that you will not set the metric and the access server will not accept the route. However, you can configure the access server to accept autonomous system paths not matched in the match clause of the route map command by using multiple maps of the same name, some without accompanying set commands.
route-map fnord permit 10match as-path 1set local-preference 5!route-map fnord permit 20match as-path 2The following example shows how you can use route maps in a reverse operation to set the route tag (as defined by the BGP/OSPF interaction document, RFC 1403) when exporting routes from BGP into the main IP routing table:
router bgp 100table-map set_ospf_tag!route-map set_ospf_tagmatch as-path 1set automatic-tag!ip as-path access-list 1 permit .*See more route map examples in the section "BGP Route Map Examples."
Route Summarization Example
The following example configures route summarization on the interface and also configures the auto-summary feature. This configuration causes IP Enhanced IGRP to summarize network 10.0.0.0 out Ethernet interface 0 only. In addition, this example disables auto summarization.
interface Ethernet 0ip summary-address eigrp 1 10.0.0.0 255.0.0.0!router eigrp 1network 172.16.0.0no auto-summaryIGRP Feasible Successor Relationship Example
In Figure 19-10, the assigned metrics meet the conditions required for a feasible successor relationship, so the paths in this example can be included in routing tables and used for load balancing.
Figure 19-10 Assigning Metrics for IGRP Path Feasibility
The feasibility test would work as follows:
Assume that AS1 already has a route to Network A with metric m and has just received an update about Network A from AS2. The best metric at AS2 is p. The metric that AS1 would use through AS2 is n.
If both of the following two conditions are met, the route to network A through AS2 will be included in AS1's routing table:
•
•
The configuration for AS1 would be as follows:
router igrp 109variance 10A maximum of four paths can be in the routing table for a single destination. If there are more than four feasible paths, the four best feasible paths are used.
BGP Synchronization Example
In Figure 19-11, with synchronization on, AS B will not advertise network 10.0.0.0 to access server A until an IGRP route for network 10.0.0.0 exists. If you specify the no synchronization router configuration command, access server B will advertise network 10.0.0.0 as soon as possible. However, because routing information still must be sent to interior peers, you must configure a full internal BGP mesh.
Figure 19-11 Illustration of Synchronization
BGP Path Filtering by Neighbor Example
The following is an example of BGP path filtering by neighbor. The routes that pass as-path access list 1 will get weight 100. Only the routes that pass as-path access list 2 will be sent to 193.1.12.10. Similarly, only routes passing access list 3 will be accepted from 193.1.12.10.
router bgp 200neighbor 192.168.12.10 remote-as 100neighbor 192.168.12.10 filter-list 1 weight 100neighbor 192.168.12.10 filter-list 2 outneighbor 192.168.12.10 filter-list 3 inip as-path access-list 1 permit _109_ip as-path access-list 2 permit _200$ip as-path access-list 2 permit ^100$ip as-path access-list 3 deny _690$ip as-path access-list 3 permit .*BGP Basic Neighbor Specification Examples
The following example specifies that the access server at the address 172.16.1.2 is a neighbor in autonomous system 109.
neighbor 172.16.1.2 remote-as 109In the following example, a BGP access server is assigned to autonomous system 109, and two networks are listed as originating in the autonomous system. Then the addresses of three remote access servers (and their autonomous systems) are listed. the access server being configured will share information about networks 172.16.0.0 and 192.168.7.0 with the neighbor access servers. The first access server listed is in the same Class B network, but in a different autonomous system; the second neighbor router configuration command illustrates specification of an internal neighbor (with the same autonomous system number) at address 172.16.234.2; and the last neighbor command specifies a neighbor on a different network.
router bgp 109network 172.16.0.0network 192.168.7.0neighbor 172.16.200.1 remote-as 167neighbor 172.16.234.2 remote-as 109neighbor 192.168.64.19 remote-as 99In Figure 19-12, access server A is being configured. The internal BGP neighbor is not directly linked to access server A. External neighbors (in autonomous system 167 and autonomous system 99) must be linked directly to access server A.
Figure 19-12 Assigning Internal and External BGP Neighbors
Using Access Lists to Specify Neighbors
In the following example, the access server is configured to allow connections from any access server that has an IP address in access list 1; that is, any access server with a 192.168.7.x address. Neighbors not explicitly specified as neighbors can connect to the access server, but the access server will not attempt to connect to them if the connection is broken. Continuing with the preceding sample configuration, the configuration is as follows:
router bgp 109network 172.16.0.0network 192.168.7.0neighbor 172.16.200.1 remote-as 167neighbor 172.16.234.2 remote-as 109neighbor 172.18.64.19 remote-as 99neighbor internal-ethernet neighbor-list 1 access-list 1 permit 192.168.7.0 0.0.0.255BGP Community Examples with Route Maps
This section contains three examples of the use of BGP communities with route maps.
In the first example, the route map set-community is applied to the outbound updates to the neighbor 171.69.232.50. The routes that pass access list 1 have the special community attribute value "no-export." The remaining routes are advertised normally. This special community value automatically prevents the advertisement of those routes by the BGP speakers in autonomous system 200.
router bgp 100neighbor 171.69.232.50 remote-as 200neighbor 171.69.232.50 send-communityneighbor 171.69.232.50 route-map set-community out!!route-map set-community 10 permitmatch address 1set community no-export!route-map set-community 20 permitmatch address 2In the second example, the route map set-community is applied to the outbound updates to neighbor 171.69.232.90. All the routes that originate from AS 70 have the community values 200 200 added to their already existing values. All other routes are advertised as normal.
route-map bgp 200neighbor 171.69.232.90 remote-as 100neighbor 171.69.232.90 send-communityneighbor 171.69.232.90 route-map set-community out!route-map set-community 10 permitmatch as-path 1set community 200 200 additive!route-map set-community 20 permitmatch as-path 2!ip as-path access-list 1 permit 70$ip as-path access-list 2 permit .*In the third example, community-based matching is used to selectively set MED and local-preference for routes from neighbor 171.69.232.55. All the routes that match community list 1 get the MED set to 8000. This includes any routes that have the communities "100 200 300" or "900 901." These routes could have other community values also.
All the routes that pass community list 2 get the local preference set to 500. This includes the routes that have community values 88 or 90. If they belong to any other community, they will not be matched by community list 2.
All the routes that match community list 3 get the local-preference set to 50. Community list 3 will match all the routes because all the routes are members of the Internet community. Thus all the remaining routes from neighbor 171.69.232.55 get a local preference 50.
router bgp 200neighbor 171.69.232.55 remote-as 100neighbor 171.69.232.55 route-map filter-on-community in!route-map filter-on-community 10 permitmatch community 1set metric 8000!route-map filter-on-community 20 permitmatch community 2 exact-matchset local-preference 500!route-map filter-on-community 30 permitmatch community 3set local-preference 50!ip community-list 1 permit 100 200 300ip community-list 1 permit 900 901!ip community-list 2 permit 88ip community-list 2 permit 90!ip community-list 3 permit internetTCP MD5 Authentication for BGP Example
The following example specifies that the router and its BGP peer at 145.2.2.2 invoke MD5 authentication on the TCP connection between them:
router bgp 109neighbor 145.2.2.2 password v61ne0qkel33&BGP Aggregate Route Examples
The following examples show how you can use aggregate routes in BGP either by redistributing an aggregate route into BGP or by using the conditional aggregate routing feature.
In the following example, the redistribute static command is used to redistribute aggregate route 193.*.*.*:
ip route 193.0.0.0 255.0.0.0 null 0!router bgp 100redistribute staticnetwork 193.0.0.0 255.0.0.0! this marks route as not incompleteThe following configuration creates an aggregate entry in the BGP routing table when there are specific routes that fall into the specified range. The aggregate route will be advertised as coming from your autonomous system and has the atomic aggregate attribute set to show that information might be missing. (By default, atomic aggregate is set unless you use the as-set keyword in the aggregate-address command.)
router bgp 100aggregate-address 193.0.0.0 255.0.0.0The following example creates an aggregate entry using the same rules as in the previous example, but the path advertised for this route will be an AS_SET consisting of all elements contained in all paths that are being summarized:
router bgp 100aggregate-address 193.0.0.0 255.0.0.0 as-setThe following example not only creates the aggegate route for 193.*.*.*, but will also suppress advertisements of more specific routes to all neighbors:
router bgp 100aggegate-address 193.0.0.0 255.0.0.0 summary-onlyBGP Confederation Example
The following is a sample configuration from several peers in a confederation. The confederation consists of three internal autonomous systems with autonomous system numbers 6001, 6002, and 6003. To the BGP speakers outside the confederation, the confederation looks like a normal autonomous system with autonomous system number 666 (specified via the bgp confederation identifier command).
In a BGP speaker in autonomous system 6001, the bgp confederation peers command marks the peers from autonomous systems 6002 and 6003 as special EBGP peers. Hence peers 171.69.232.55 and 171.69.232.56 will get the local-preference, next-hop and MED unmodified in the updates. The router at 160.69.69.1 is a normal EBGP speaker and the updates received by it from this peer will be just like a normal EBGP update from a peer in autonomous system 666.
router bgp 6001bgp confederation identified 666bgp confederation peers 6002 6003neighbor 171.69.232.55 remote-as 6002neighbor 171.69.232.56 remote-as 6003neighbor 160.69.69.1 remote-as 777In a BGP speaker in autonomous system 6002, the peers from autonomous systems 6001 and 6003 are configured as special EBGP peers. 170.70.70.1 is a normal IBGP peer and 199.99.99.2 is a normal EBGP peer from autonomous system 700.
router bgp 6002bgp confederation identified 666bgp confederation peers 6001 6003neighbor 170.70.70.1 remote-as 6002neighbor 171.69.232.57 remote-as 6001neighbor 171.69.232.56 remote-as 6003neighbor 199.99.99.2 remote-as 700In a BGP speaker in autonomous system 6003, the peers from autonomous systems 6001 and 6002 are configured as special EBGP peers. 200.200.200.200.200 is a normal EBGP peer from autonomous system 701.
router bgp 6003bgp confederation identified 666bgp confederation peers 6001 6002neighbor 171.69.232.57 remote-as 6001neighbor 171.69.232.55 remote-as 6002neighbor 200.200.200.200 remote-as 701The following is a part of the configuration from the BGP speaker 200.200.200.205 from autonomous system 701. Neighbor 171.69.232.56 is configured as a normal EBGP speaker from autonomous system 666. The internal division of the autonomous system into multiple autonomous systems is not known to the peers external to the confederation.
router bgp 701neighbor 171.69.232.56 remote-as 666neighbor 200.200.200.205 remote-as 701BGP Peer Group Examples
This section contains an IBGP peer group example and an EBGP peer group example.
Example for an IBGP Peer Group
In the following example, the peer group named internal configures the members of the peer group to be IBGP neighbors. By definition, this is an IBGP peer group because the router bgp command and the neighbor remote-as command indicate the same autonomous system (in this case, AS 100). All the peer group members use loopback 0 as the update source and use set-med as the outbound route-map. The example also shows that, except for the neighbor at address 171.69.232.55, all the neighbors have filter-list 2 as the inbound filter list.
router bgp 100neighbor internal peer-groupneighbor internal remote-as 100neighbor internal update-source loopback 0neighbor internal route-map set-med outneighbor internal filter-list 1 outneighbor internal filter-list 2 inneighbor 171.69.232.53 peer-group internalneighbor 171.69.232.54 peer-group internalneighbor 171.69.232.55 peer-group internalneighbor 171.69.232.55 filter-list 3 inExample for an EBGP Peer Group
In the following example, the peer group external-peers is defined without the neighbor remote-as command. This is what makes it an EBGP peer group. Each member of the peer group is configured with its respective autonomous system number separately. Thus the peer group consists of members from autonomous systems 200, 300, and 400. All the peer group members have set-metric route map as an outbound route map and filter-list 99 as an outbound filter list. Except for neighbor 171.69.232.110, all of them have 101 as the inbound filter list.
router bgp 100neighbor external-peers peer-groupneighbor external-peers route-map set-metric outneigbhor external-peers filter-list 99 outneighbor external-peers filter-list 101 inneighbor 171.69.232.90 remote-as 200neighbor 171.69.232.90 peer-group external-peersneighbor 171.69.232.100 remote-as 300neighbor 171.69.232.100 peer-group external-peersneighbor 171.69.232.110 remote-as 400neighbor 171.69.232.110 peer-group external-peersneighbor 171.69.232.110 filter-list 400 inThird-Party EGP Support Example
In the following example configuration, the access server is in autonomous system 110 communicating with an EGP neighbor in autonomous system 109 with address 172.16.6.5. Network 172.16.0.0 is advertised as originating within autonomous system 110. The configuration specifies that two access servers, 172.16.6.99 and 172.16.6.100, should be advertised as third-party sources of routing information for those networks that are accessible through those access servers. The global configuration commands also specify that those networks should be flagged as internal to autonomous system 110.
autonomous-system 110router egp 109network 172.16.0.0neighbor 172.16.6.5neighbor 172.16.6.5 third-party 172.16.6.99 internalneighbor 172.16.6.5 third-party 172.16.6.100 internalBackup EGP Access Server Example
The following example configuration illustrates an access server that is in autonomous system 110 communicating with an EGP neighbor in autonomous system 109 with address 172.16.6.5. Network 172.16.0.0 is advertised with a distance of 1, and networks learned by RIP are being advertised with a distance of 5. Access list 3 filters which RIP-derived networks are allowed in outgoing EGP updates.
autonomous-system 110router egp 109network 172.16.0.0neighbor 172.16.6.5redistribute ripdefault-metric 5distribute-list 3 out ripEGP Core Gateway Example
The following example illustrates how an EGP core gateway can be configured.
Figure 19-13 illustrates an environment with three access servers (designated AS 1, AS 2, and AS 3) attached to a common X.25 network. the access servers are intended to route information using EGP. With the following configuration (on the access server designated core), AS 1, AS 2, and AS 3 cannot route traffic directly to each other via the X.25 network:
access-list 1 permit 10.0.0.0 0.255.255.255! global access list assignmentrouter egp 0neighbor any 1This configuration specifies that an EGP process on any access server on network 10.0.0.0 can act as a peer with the core access server. All traffic in this configuration will flow through the core access server.
Third-party advertisements allow traffic to bypass the core access server and go directly to the access server that advertised reachability to the core.
access-list 2 permit 10.0.0.0 0.255.255.255! global access list assignmentrouter egp 0neighbor any 2neighbor any third-party 10.1.1.1Figure 19-13 Core EGP Third-Party Update Configuration Example
Autonomous System within EGP Example
The following example illustrates a typical configuration for an EGP access server process. the access server is in autonomous system 109 and is peering with access servers in autonomous system 164, as shown in Figure 19-14. It will advertise the networks 172.16.0.0 and 192.168.7.0 to the access server in autonomous system 164, 10.2.0.2. The information sent and received from peer access servers can be filtered in various ways, including blocking information from certain access servers and suppressing the advertisement of specific routes.
autonomous-system 109router egp 164network 172.16.0.0network 192.168.7.0neighbor 10.2.0.2Figure 19-14 Router in AS 164 Peers with Access Server in AS 109
Passive Interface Examples
The following example sends IGRP updates to all interfaces on network 172.16.0.0 except Ethernet interface 1. Figure 19-15 shows this configuration.
router igrp 109network 172.16.0.0passive-interface ethernet 1Figure 19-15 Filtering IGRP Updates
As in the first example, IGRP updates are sent to all interfaces on network 172.16.0.0 except Ethernet interface 1 in the following example. However, in this case a neighbor router configuration command is included. This command permits the sending of routing updates to specific neighbors. One copy of the routing update is generated per neighbor.
router igrp 109network 172.16.0.0passive-interface ethernet 1neighbor 172.16.20.4In OSPF, hello packets are not sent on an interface that is specified as passive. Hence, the access server will not be able to discover any neighbors, and none of the OSPF neighbors will be able to see the access server on that network. In effect, this interface will appear as a stub network to the OSPF domain. This is useful if you want to import routes associated with a connected network into the OSPF domain without any OSPF activity on that interface.
The passive-interface router configuration command typically is used when the wildcard specification on the network router configuration command configures more interfaces than is desirable. The following configuration causes OSPF to run on all subnets of 172.16.0.0:
interface ethernet 0ip address 172.16.1.1 255.255.255.0interface ethernet 1ip address 172.16.2.1 255.255.255.0interface ethernet 2ip address 172.16.3.1 255.255.255.0!router ospf 109network 172.16.0.0 0.0.255.255 area 0If you do not want OSPF to run on 172.16.3.0, enter the following commands:
router ospf 109network 172.16.0.0 0.0.255.255 area 0passive-interface ethernet 2Administrative Distance Examples
In the following example, the router igrp global configuration command sets up IGRP routing in autonomous system 109. The network router configuration commands specify IGRP routing on networks 192.168.7.0 and 172.31.0.0. The first distance router configuration command sets the default administrative distance to 255, which instructs the access server to ignore all routing updates from access servers for which an explicit distance has not been set. The second distance command sets the administrative distance to 90 for all access servers on the Class C network 192.168.7.0. The third distance command sets the administrative distance to 120 for the access server with the address 172.31.1.3.
router igrp 109network 192.168.7.0network 172.31.0.0distance 255distance 90 192.168.7.0 0.0.0.255distance 120 172.31.1.3 0.0.0.0The following example assigns the access server with the address 192.168.7.18 an administrative distance of 100, and all other access servers on subnet 192.168.7.0 an administrative distance of 200:
distance 100 192.168.7.18 0.0.0.0distance 200 192.168.7.0 0.0.0.255However, if you reverse the order of these commands, all access servers on subnet 192.168.7.0 are assigned an administrative distance of 200, including the access server at address 192.168.7.18:
distance 200 192.168.7.0 0.0.0.255distance 100 192.168.7.18 0.0.0.0Assigning administrative distances is a problem unique to each network and is done in response to the greatest perceived threats to the connected network. Even when general guidelines exist, the network manager must ultimately determine a reasonable matrix of administrative distances for the network as a whole.
In the following example, the distance value for IP routes learned is 90. Preference is given to these IP routes rather than routes with the default administrative distance value of 110.
router isisdistance 90 ipPolicy Routing Example
The following example provides two sources with equal access to two different service providers. Packets arriving on async interface 1 from the source 1.1.1.1 are sent to the router at 6.6.6.6 if the router has no explicit route for the packet's destination. Packets arriving from the source 2.2.2.2 are sent to the router at 7.7.7.7 if the router has no explicit route for the packet's destination. All other packets for which the router has no explicit route to the destination are discarded.
access-list 1 permit ip 1.1.1.1 0.0.0.0access-list 2 permit ip 2.2.2.2 0.0.0.0!interface async 1ip policy route-map equal-access!route-map equal-access permit 10match ip address 1set ip default next-hop 6.6.6.6route-map equal-access permit 20match ip address 2set ip default next-hop 7.7.7.7route-map equal-access permit 30set default interface null0Split Horizon Examples
Two examples of configuring split horizon are provided.
Example 1
The following sample configuration illustrates a simple example of disabling split horizon on a serial link. In this example, the serial link is connected to an X.25 network.
interface serial 0encapsulation x25no ip split-horizonExample 2
In the next example, Figure 19-16 illustrates a typical situation in which the no ip split-horizon interface configuration command would be useful. This figure depicts two IP subnets that are both accessible via a serial interface on AS C (connected to Frame Relay network). In this example, the serial interface on AS C accommodates one of the subnets via the assignment of a secondary IP address.
The Ethernet interfaces for AS A, AS B, and AS C (connected to IP networks 12.13.50.0, 10.20.40.0, and 20.155.120.0) all have split horizon enabled by default, while the serial interfaces connected to networks 192.168.1.0 and 172.16.1.0 all have split horizon disabled by default. The partial interface configuration specifications for each access server that follow Figure 19-16 illustrate that the ip split-horizon command is not explicitly configured under normal conditions for any of the interfaces.
In this example, split horizon must be disabled in order for network 192.168.0.0 to be advertised into network 172.16.0.0, and vice versa. These subnets overlap at AS C, serial interface 0. If split horizon were enabled on serial interface 0, it would not advertise a route back into the Frame Relay network for either of these networks.
Figure 19-16 Disabled Split Horizon Example for Frame Relay Network
Configuration for AS A
interface ethernet 1ip address 12.13.50.1!interface serial 1ip address 192.168.1.2encapsulation frame-relayConfiguration for AS B
interface ethernet 2ip address 20.155.120.1!interface serial 2ip address 172.16.1.2encapsulation frame-relayConfiguration for AS C
interface ethernet 0ip address 10.20.40.1!interface serial 0ip address 192.168.1.1ip address 172.16.1.1 secondaryencapsulation frame-relayIP Multicast Routing Configuration Examples
This section provides the following IP multicast routing configuration examples:
•
•
•
Configure an Access Server to Operate in Dense Mode Example
The following example configures dense-mode PIM on an Ethernet interface of the access server:
ip multicast-routinginterface ethernet 0ip pim dense-modeConfigure an Access Server to Operate in Sparse Mode Example
The following example configures the access server to operate in sparse-mode PIM. The RP access server is the access server whose address is 10.8.0.20.
access-list 1 permit 172.20.0.1!ip multicast-routingip pim rp-address 10.8.0.20 1interface ethernet 1ip pim sparse-modeConfigure DVMRP Interoperability Examples
The following example configures DVMRP interoperability for configurations when the PIM access server and the DVMRP access server are on the same network segment. In this example, access list 1 advertises the networks 98.92.35.0,192.168.36.0, 192.168.37.0,172.16.0.0, and 172.31.0.0 to the DVMRP access server, and access list 2 is used to prevent all other networks from being advertised (ip dvmrp metric 0).
interface ethernet 0ip address 172.19.244.244 255.255.255.0ip pim dense-modeip dvmrp metric 1 1ip dvmrp metric 0 2access-list 1 permit 192.168.35.0 0.0.0.255access-list 1 permit 192.168.36.0 0.0.0.255access-list 1 permit 192.168.37.0 0.0.0.255access-list 1 permit 172.16.0.0 0.0.255.255access-list 1 permit 172.31.0.0 0.0.255.255access-list 1 deny 0.0.0.0 255.255.255.255access-list 2 permit 0.0.0.0 255.255.255.255The following example configures DVMRP interoperability over a tunnel interface.
hostname Mbone(ACOnet)!boot system xx-k.Aug11 172.16.243.9boot system flashboot system rom!ip multicast-routing!interface tunnel 0no ip addressip pim dense-modetunnel source Ethernet0tunnel destination 172.16.92.133tunnel mode dvmrp!interface Ethernet0description Universitat DMZ-ethernetip address 192.168.23.23 255.255.255.240 secondaryip address 172.16.243.2 255.255.255.0ip pim dense-mode!AS igrp 11853network 172.16.243.0network 192.168.23.0