- Configuring QoS
- Index
- Preface
- Overview
- Using the Command-Line Interface
- Getting Started with CMS
- Assigning the Switch IP Address and Default Gateway
- Managing Switch Stacks
- Clustering Switches
- Administering the Switch
- Configuring SDM Templates
- Configuring Switch-Based Authentication
- Configuring 802.1X Port-Based Authentication
- Configuring Interface Characteristics
- Configuring SmartPort Macros
- Configuring VLANs
- Configuring VTP
- Configuring Voice VLAN
- Configuring STP
- Configuring MSTP
- Configuring Optional Spanning-Tree Features
- Configuring DHCP Features
- Configuring IGMP Snooping and MVR
- Configuring Port-Based Traffic Control
- Configuring CDP
- Configuring UDLD
- Configuring SPAN and RSPAN
- Configuring RMON
- Configuring System Message Logging
- Configuring SNMP
- Configuring Network Security with ACLs
- Configuring QoS
- Configuring EtherChannels
- Configuring IP Unicast Routing
- Configuring HSRP
- * Configuring IP Multicast Routing
- Configuring MSDP
- Configuring Fallback Bridging
- Troubleshooting
- Working with the Cisco IOS File System, Configuration Files, and Software Images
- Unsupported Commands in Cisco IOS Release 12.2(18)SE
- Supported MIBs
- Understanding IP Routing
- Steps for Configuring Routing
- Configuring IP Addressing
- Enabling IP Unicast Routing
- Configuring RIP
- Configuring OSPF
- Configuring EIGRP
- Configuring BGP
- Default BGP Configuration
- Enabling BGP Routing
- Managing Routing Policy Changes
- Configuring BGP Decision Attributes
- Configuring BGP Filtering with Route Maps
- Configuring BGP Filtering by Neighbor
- Configuring Prefix Lists for BGP Filtering
- Configuring BGP Community Filtering
- Configuring BGP Neighbors and Peer Groups
- Configuring Aggregate Addresses
- Configuring Routing Domain Confederations
- Configuring BGP Route Reflectors
- Configuring Route Dampening
- Monitoring and Maintaining BGP
- Configuring Protocol-Independent Features
- Configuring Distributed Cisco Express Forwarding
- Configuring the Number of Equal-Cost Routing Paths
- Configuring Static Unicast Routes
- Specifying Default Routes and Networks
- Using Route Maps to Redistribute Routing Information
- Configuring Policy-Based Routing
- Filtering Routing Information
- Managing Authentication Keys
- Monitoring and Maintaining the IP Network
Configuring IP Unicast Routing
This chapter describes how to configure IP unicast routing on the Catalyst 3750 switch. Unless otherwise noted, the term switch refers to a standalone switch and a switch stack. A switch stack operates and appears as a single router to the rest of the routers in the network. Basic routing functions, including static routing and the Routing Information Protocol (RIP), are available with both the standard multilayer software image (SMI) and the enhanced multilayer image (EMI). To use advanced routing features and other routing protocols, you must have the enhanced multilayer image installed on the standalone switch or on the stack master.
For more detailed IP unicast configuration information, refer to the Cisco IOS IP Configuration Guide, Release 12.1 For complete syntax and usage information for the commands used in this chapter, refer to these command references:
•![]() Cisco IOS IP Command Reference, Volume 1 of 3: Addressing and Services, Release 12.2
Cisco IOS IP Command Reference, Volume 1 of 3: Addressing and Services, Release 12.2
•![]() Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2
Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2
•![]() Cisco IOS IP Command Reference, Volume 3 of 3: Multicast, Release 12.2
Cisco IOS IP Command Reference, Volume 3 of 3: Multicast, Release 12.2
This chapter consists of these sections:
•![]() Steps for Configuring Routing
Steps for Configuring Routing
•![]() Configuring Protocol-Independent Features
Configuring Protocol-Independent Features
•![]() Monitoring and Maintaining the IP Network
Monitoring and Maintaining the IP Network

Note ![]() When configuring routing parameters on the switch and to allocate system resources to maximize the number of unicast routes allowed, you can use the sdm prefer routing global configuration command to set the Switch Database Management (sdm) feature to the routing template. For more information on the SDM templates, see "Configuring SDM Templates" or refer to the sdm prefer command in the command reference for this release.
When configuring routing parameters on the switch and to allocate system resources to maximize the number of unicast routes allowed, you can use the sdm prefer routing global configuration command to set the Switch Database Management (sdm) feature to the routing template. For more information on the SDM templates, see "Configuring SDM Templates" or refer to the sdm prefer command in the command reference for this release.
Understanding IP Routing
In some network environments, VLANs are associated with individual networks or subnetworks. In an IP network, each subnetwork is mapped to an individual VLAN. Configuring VLANs helps control the size of the broadcast domain and keeps local traffic local. However, network devices in different VLANs cannot communicate with one another without a Layer 3 device (router) to route traffic between the VLAN, referred to as inter-VLAN routing. You configure one or more routers to route traffic to the appropriate destination VLAN.
Figure 31-1 shows a basic routing topology. Switch A is in VLAN 10, and Switch B is in VLAN 20. The router has an interface in each VLAN.
Figure 31-1 Routing Topology Example

When Host A in VLAN 10 needs to communicate with Host B in VLAN 10, it sends a packet addressed to that host. Switch A forwards the packet directly to Host B, without sending it to the router.
When Host A sends a packet to Host C in VLAN 20, Switch A forwards the packet to the router, which receives the traffic on the VLAN 10 interface. The router checks the routing table, finds the correct outgoing interface, and forwards the packet on the VLAN 20 interface to Switch B. Switch B receives the packet and forwards it to Host C.
This section contains information on these routing topics:
Types of Routing
Routers and Layer 3 switches can route packets in three different ways:
•![]() By using default routing
By using default routing
•![]() By using preprogrammed static routes for the traffic
By using preprogrammed static routes for the traffic
•![]() By dynamically calculating routes by using a routing protocol
By dynamically calculating routes by using a routing protocol
Default routing refers to sending traffic with a destination unknown to the router to a default outlet or destination.
Static unicast routing forwards packets from predetermined ports through a single path into and out of a network. Static routing is secure and uses little bandwidth, but does not automatically respond to changes in the network, such as link failures, and therefore, might result in unreachable destinations. As networks grow, static routing becomes a labor-intensive liability.
Dynamic routing protocols are used by routers to dynamically calculate the best route for forwarding traffic. There are two types of dynamic routing protocols:
•![]() Routers using distance-vector protocols maintain routing tables with distance values of networked resources, and periodically pass these tables to their neighbors. Distance-vector protocols use one or a series of metrics for calculating the best routes. These protocols are easy to configure and use.
Routers using distance-vector protocols maintain routing tables with distance values of networked resources, and periodically pass these tables to their neighbors. Distance-vector protocols use one or a series of metrics for calculating the best routes. These protocols are easy to configure and use.
•![]() Routers using link-state protocols maintain a complex database of network topology, based on the exchange of link-state advertisements (LSAs) between routers. LSAs are triggered by an event in the network, which speeds up the convergence time or time required to respond to these changes. Link-state protocols respond quickly to topology changes, but require greater bandwidth and more resources than distance-vector protocols.
Routers using link-state protocols maintain a complex database of network topology, based on the exchange of link-state advertisements (LSAs) between routers. LSAs are triggered by an event in the network, which speeds up the convergence time or time required to respond to these changes. Link-state protocols respond quickly to topology changes, but require greater bandwidth and more resources than distance-vector protocols.
Distance-vector protocols supported by the Catalyst 3750 switch are Routing Information Protocol (RIP), which uses a single distance metric (cost) to determine the best path and Border Gateway Protocol (BGP), which adds a path vector mechanism. The switch also supports the Open Shortest Path First (OSPF) link-state protocol and Enhanced IGRP (EIGRP), which adds some link-state routing features to traditional Interior Gateway Routing Protocol (IGRP) to improve efficiency.
Note ![]() On a switch stack, the supported protocols are determined by the software running on the stack master. If the stack master is running the SMI, only default routing, static routing and RIP are supported. All other routing protocols require the EMI.
On a switch stack, the supported protocols are determined by the software running on the stack master. If the stack master is running the SMI, only default routing, static routing and RIP are supported. All other routing protocols require the EMI.
IP Routing and Switch Stacks
A Catalyst 3750 switch stack appears to the network as a single router, regardless of which switch in the stack is connected to a routing peer. For additional information about switch stack operation, see "Managing Switch Stacks."
The stack master performs these functions:
•![]() It initializes and configures the routing protocols.
It initializes and configures the routing protocols.
•![]() It sends routing protocol messages and updates to other routers.
It sends routing protocol messages and updates to other routers.
•![]() It processes routing protocol messages and updates received from peer routers.
It processes routing protocol messages and updates received from peer routers.
•![]() It generates, maintains, and distributes the distributed Cisco Express Forwarding (dCEF) database to all stack members. The routes are programmed on all switches in the stack bases on this database.
It generates, maintains, and distributes the distributed Cisco Express Forwarding (dCEF) database to all stack members. The routes are programmed on all switches in the stack bases on this database.
•![]() The MAC address of the stack master is used as the router MAC address for the whole stack, and all outside devices use this address to send IP packets to the stack.
The MAC address of the stack master is used as the router MAC address for the whole stack, and all outside devices use this address to send IP packets to the stack.
•![]() All IP packets that require software forwarding or processing go through the CPU of the stack master.
All IP packets that require software forwarding or processing go through the CPU of the stack master.
Stack members perform these functions:
•![]() They act as routing standby switches, ready to take over in case they are elected as the new stack master if the stack master fails.
They act as routing standby switches, ready to take over in case they are elected as the new stack master if the stack master fails.
•![]() They program the routes into hardware. The routes programmed by the stack members are the same that are downloaded by the stack master as part of the dCEF database.
They program the routes into hardware. The routes programmed by the stack members are the same that are downloaded by the stack master as part of the dCEF database.
If a stack master fails, the stack detects that the stack master is down and elects one of the stack members to be the new stack master. During this period, except for a momentary interruption, the hardware continues to forward packets with no protocols active.
Upon election, the new stack master performs these functions:
•![]() It starts generating, receiving, and processing routing updates.
It starts generating, receiving, and processing routing updates.
•![]() It builds routing tables, generates the CEF database, and distributes it to stack members.
It builds routing tables, generates the CEF database, and distributes it to stack members.
•![]() It begins using its MAC address as the router MAC address. To update its network peers of the new MAC address, it periodically (every few seconds for 5 minutes) sends a gratuitous ARP reply with the new router MAC address.
It begins using its MAC address as the router MAC address. To update its network peers of the new MAC address, it periodically (every few seconds for 5 minutes) sends a gratuitous ARP reply with the new router MAC address.
•![]() It attempts to determine the reachability of every proxy ARP entry by sending an ARP request to the proxy ARP IP address and receiving an ARP reply. For each reachable proxy ARP IP address, it generates a gratuitous ARP reply with the new router MAC address. This process is repeated for 5 minutes after a new stack master election.
It attempts to determine the reachability of every proxy ARP entry by sending an ARP request to the proxy ARP IP address and receiving an ARP reply. For each reachable proxy ARP IP address, it generates a gratuitous ARP reply with the new router MAC address. This process is repeated for 5 minutes after a new stack master election.
Note ![]() When a stack master is running the EMI, the stack is able to run all supported protocols, including Open Shortest Path First (OSPF), Enhanced IGRP (EIGRP), and Border Gateway Protocol (BGP). If the stack master fails and the new elected stack master is running the SMI, these protocols will no longer run in the stack.
When a stack master is running the EMI, the stack is able to run all supported protocols, including Open Shortest Path First (OSPF), Enhanced IGRP (EIGRP), and Border Gateway Protocol (BGP). If the stack master fails and the new elected stack master is running the SMI, these protocols will no longer run in the stack.

Steps for Configuring Routing
By default, IP routing is disabled on the switch, and you must enable it before routing can take place. For detailed IP routing configuration information, refer to the Cisco IOS IP Configuration Guide, Release 12.2
In the following procedures, the specified interface must be one of these Layer 3 interfaces:
•![]() A routed port: a physical port configured as a Layer 3 port by using the no switchport interface configuration command.
A routed port: a physical port configured as a Layer 3 port by using the no switchport interface configuration command.
•![]() A switch virtual interface (SVI): a VLAN interface created by using the interface vlan vlan_id global configuration command and by default a Layer 3 interface.
A switch virtual interface (SVI): a VLAN interface created by using the interface vlan vlan_id global configuration command and by default a Layer 3 interface.
•![]() An EtherChannel port channel in Layer 3 mode: a port-channel logical interface created by using the interface port-channel port-channel-number global configuration command and binding the Ethernet interface into the channel group. For more information, see the "Configuring Layer 3 EtherChannels" section.
An EtherChannel port channel in Layer 3 mode: a port-channel logical interface created by using the interface port-channel port-channel-number global configuration command and binding the Ethernet interface into the channel group. For more information, see the "Configuring Layer 3 EtherChannels" section.
Note ![]() A Layer 3 switch can have an IP address assigned to each routed port and SVI. The number of routed ports and SVIs that you can configure is not limited by software. However, the interrelationship between this number and the number and volume of features being implemented might have an impact on CPU utilization because of hardware limitations. To optimize system memory for routing, use the sdm prefer routing global configuration command.
A Layer 3 switch can have an IP address assigned to each routed port and SVI. The number of routed ports and SVIs that you can configure is not limited by software. However, the interrelationship between this number and the number and volume of features being implemented might have an impact on CPU utilization because of hardware limitations. To optimize system memory for routing, use the sdm prefer routing global configuration command.
All Layer 3 interfaces on which routing will occur must have IP addresses assigned to them. See the "Assigning IP Addresses to Network Interfaces" section.
Configuring routing consists of several main procedures:
•![]() To support VLAN interfaces, create and configure VLANs on the switch stack, and assign VLAN membership to Layer 2 interfaces. For more information, see "Configuring VLANs."
To support VLAN interfaces, create and configure VLANs on the switch stack, and assign VLAN membership to Layer 2 interfaces. For more information, see "Configuring VLANs."
•![]() Configure Layer 3 interfaces.
Configure Layer 3 interfaces.
•![]() Enable IP routing on the switch.
Enable IP routing on the switch.
•![]() Assign IP addresses to the Layer 3 interfaces.
Assign IP addresses to the Layer 3 interfaces.
•![]() Enable selected routing protocols on the switch.
Enable selected routing protocols on the switch.
•![]() Configure routing protocol parameters (optional).
Configure routing protocol parameters (optional).
Configuring IP Addressing
A required task for configuring IP routing is to assign IP addresses to Layer 3 network interfaces to enable the interfaces and allow communication with the hosts on those interfaces that use IP. These sections describe how to configure various IP addressing features. Assigning IP addresses to the interface is required; the other procedures are optional.
•![]() Default Addressing Configuration
Default Addressing Configuration
•![]() Assigning IP Addresses to Network Interfaces
Assigning IP Addresses to Network Interfaces
•![]() Configuring Address Resolution Methods
Configuring Address Resolution Methods
•![]() Routing Assistance When IP Routing is Disabled
Routing Assistance When IP Routing is Disabled
•![]() Configuring Broadcast Packet Handling
Configuring Broadcast Packet Handling
•![]() Monitoring and Maintaining IP Addressing
Monitoring and Maintaining IP Addressing
Default Addressing Configuration
Table 31-1 shows the default addressing configuration.
Assigning IP Addresses to Network Interfaces
An IP address identifies a location to which IP packets can be sent. Some IP addresses are reserved for special uses and cannot be used for host, subnet, or network addresses. RFC 1166, "Internet Numbers," contains the official description of IP addresses.
An interface can have one primary IP address. A mask identifies the bits that denote the network number in an IP address. When you use the mask to subnet a network, the mask is referred to as a subnet mask. To receive an assigned network number, contact your Internet service provider.
Beginning in privileged EXEC mode, follow these steps to assign an IP address and a network mask to a Layer 3 interface:
Use of Subnet Zero
Subnetting with a subnet address of zero is strongly discouraged because of the problems that can arise if a network and a subnet have the same addresses. For example, if network 131.108.0.0 is subnetted as 255.255.255.0, subnet zero would be written as 131.108.0.0, which is the same as the network address.
You can use the all ones subnet (131.108.255.0) and even though it is discouraged, you can enable the use of subnet zero if you need the entire subnet space for your IP address.
Beginning in privileged EXEC mode, follow these steps to enable subnet zero:
Use the no ip subnet-zero global configuration command to restore the default and disable the use of subnet zero.
Classless Routing
By default, classless routing behavior is enabled on the switch when it is configured to route. With classless routing, if a router receives packets for a subnet of a network with no default route, the router forwards the packet to the best supernet route. A supernet consists of contiguous blocks of Class C address spaces used to simulate a single, larger address space and is designed to relieve the pressure on the rapidly depleting Class B address space.
In Figure 31-2, classless routing is enabled. When the host sends a packet to 120.20.4.1, instead of discarding the packet, the router forwards it to the best supernet route. If you disable classless routing and a router receives packets destined for a subnet of a network with no network default route, the router discards the packet.
Figure 31-2 IP Classless Routing
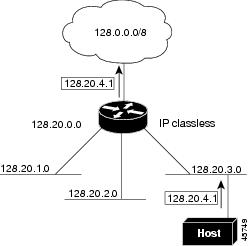
In Figure 31-3, the router in network 128.20.0.0 is connected to subnets 128.20.1.0, 128.20.2.0, and 128.20.3.0. If the host sends a packet to 120.20.4.1, because there is no network default route, the router discards the packet.
Figure 31-3 No IP Classless Routing

To prevent the switch from forwarding packets destined for unrecognized subnets to the best supernet route possible, you can disable classless routing behavior.
Beginning in privileged EXEC mode, follow these steps to disable classless routing:
To restore the default and have the switch forward packets destined for a subnet of a network with no network default route to the best supernet route possible, use the ip classless global configuration command.
Configuring Address Resolution Methods
You can control interface-specific handling of IP by using address resolution. A device using IP can have both a local address or MAC address, which uniquely defines the device on its local segment or LAN, and a network address, which identifies the network to which the device belongs.
Note ![]() In a Catalyst 3750 switch stack, network communication uses a single MAC address and the IP address of the stack.
In a Catalyst 3750 switch stack, network communication uses a single MAC address and the IP address of the stack.
The local address or MAC address is known as a data link address because it is contained in the data link layer (Layer 2) section of the packet header and is read by data link (Layer 2) devices. To communicate with a device on Ethernet, the software must learn the MAC address of the device. The process of learning the MAC address from an IP address is called address resolution. The process of learning the IP address from the MAC address is called reverse address resolution.
The switch can use these forms of address resolution:
•![]() Address Resolution Protocol (ARP) is used to associate IP address with MAC addresses. Taking an IP address as input, ARP learns the associated MAC address and then stores the IP address/MAC address association in an ARP cache for rapid retrieval. Then the IP datagram is encapsulated in a link-layer frame and sent over the network. Encapsulation of IP datagrams and ARP requests or replies on IEEE 802 networks other than Ethernet is specified by the Subnetwork Access Protocol (SNAP).
Address Resolution Protocol (ARP) is used to associate IP address with MAC addresses. Taking an IP address as input, ARP learns the associated MAC address and then stores the IP address/MAC address association in an ARP cache for rapid retrieval. Then the IP datagram is encapsulated in a link-layer frame and sent over the network. Encapsulation of IP datagrams and ARP requests or replies on IEEE 802 networks other than Ethernet is specified by the Subnetwork Access Protocol (SNAP).
•![]() Proxy ARP helps hosts with no routing tables learn the MAC addresses of hosts on other networks or subnets. If the switch (router) receives an ARP request for a host that is not on the same interface as the ARP request sender, and if the router has all of its routes to the host through other interfaces, it generates a proxy ARP packet giving its own local data link address. The host that sent the ARP request then sends its packets to the router, which forwards them to the intended host.
Proxy ARP helps hosts with no routing tables learn the MAC addresses of hosts on other networks or subnets. If the switch (router) receives an ARP request for a host that is not on the same interface as the ARP request sender, and if the router has all of its routes to the host through other interfaces, it generates a proxy ARP packet giving its own local data link address. The host that sent the ARP request then sends its packets to the router, which forwards them to the intended host.
Catalyst 3750 switches also use the Reverse Address Resolution Protocol (RARP), which functions the same as ARP does, except that the RARP packets request an IP address instead of a local MAC address. Using RARP requires a RARP server on the same network segment as the router interface. Use the ip rarp-server address interface configuration command to identify the server.
For more information on RARP, refer to the Cisco IOS Configuration Fundamentals Configuration Guide, Release 12.2.
You can perform these tasks to configure address resolution:
Define a Static ARP Cache
ARP and other address resolution protocols provide dynamic mapping between IP addresses and MAC addresses. Because most hosts support dynamic address resolution, you usually do not need to specify static ARP cache entries. If you must define a static ARP cache entry, you can do so globally, which installs a permanent entry in the ARP cache that the switch uses to translate IP addresses into MAC addresses. Optionally, you can also specify that the switch respond to ARP requests as if it were the owner of the specified IP address. If you do not want the ARP entry to be permanent, you can specify a timeout period for the ARP entry.
Beginning in privileged EXEC mode, follow these steps to provide static mapping between IP addresses and MAC addresses:
To remove an entry from the ARP cache, use the no arp ip-address hardware-address type global configuration command. To remove all nonstatic entries from the ARP cache, use the clear arp-cache privileged EXEC command.
Set ARP Encapsulation
By default, Ethernet ARP encapsulation (represented by the arpa keyword) is enabled on an IP interface. You can change the encapsulation methods to SNAP if required by your network.
Beginning in privileged EXEC mode, follow these steps to specify the ARP encapsulation type:
To disable an encapsulation type, use the no arp arpa or no arp snap interface configuration command.
Enable Proxy ARP
By default, the switch uses proxy ARP to help hosts learn MAC addresses of hosts on other networks or subnets.
Beginning in privileged EXEC mode, follow these steps to enable proxy ARP if it has been disabled:
To disable proxy ARP on the interface, use the no ip proxy-arp interface configuration command.
Routing Assistance When IP Routing is Disabled
These mechanisms allow the switch to learn about routes to other networks when it does not have IP routing enabled:
•![]() ICMP Router Discovery Protocol (IRDP)
ICMP Router Discovery Protocol (IRDP)
Proxy ARP
Proxy ARP, the most common method for learning about other routes, enables an Ethernet host with no routing information to communicate with hosts on other networks or subnets. The host assumes that all hosts are on the same local Ethernet and that they can use ARP to learn their MAC addresses. If a switch receives an ARP request for a host that is not on the same network as the sender, the switch evaluates whether it has the best route to that host. If it does, it sends an ARP reply packet with its own Ethernet MAC address, and the host that sent the request sends the packet to the switch, which forwards it to the intended host. Proxy ARP treats all networks as if they are local and performs ARP requests for every IP address.
Proxy ARP is enabled by default. To enable it after it has been disabled, see the "Enable Proxy ARP" section. Proxy ARP works as long as other routers support it.
Default Gateway
Another method for locating routes is to define a default router or default gateway. All nonlocal packets are sent to this router, which either routes them appropriately or sends an IP Control Message Protocol (ICMP) redirect message back, defining which local router the host should use. The switch caches the redirect messages and forwards each packet as efficiently as possible. A limitation of this method is that there is no means of detecting when the default router has gone down or is unavailable.
Beginning in privileged EXEC mode, follow these steps to define a default gateway (router) when IP routing is disabled:
Use the no ip default-gateway global configuration command to disable this function.
ICMP Router Discovery Protocol (IRDP)
Router discovery allows the switch to dynamically learn about routes to other networks using IRDP. IRDP allows hosts to locate routers. When operating as a client, the switch generates router discovery packets. When operating as a host, the switch receives router discovery packets. The switch can also listen to Routing Information Protocol (RIP) routing updates and use this information to infer locations of routers. The switch does not actually store the routing tables sent by routing devices; it merely keeps track of which systems are sending the data. The advantage of using IRDP is that it allows each router to specify both a priority and the time after which a device is assumed to be down if no further packets are received.
Each device discovered becomes a candidate for the default router, and a new highest-priority router is selected when a higher priority router is discovered, when the current default router is declared down, or when a TCP connection is about to time out because of excessive retransmissions.
The only required task for IRDP routing on an interface is to enable IRDP processing on that interface. When enabled, the default parameters apply. You can optionally change any of these parameters.
Beginning in privileged EXEC mode, follow these steps to enable and configure IRDP on an interface:
If you change the maxadvertinterval value, the holdtime and minadvertinterval values also change, so it is important to first change the maxadvertinterval value, before manually changing either the holdtime or minadvertinterval values.
Use the no ip irdp interface configuration command to disable IRDP routing.
Configuring Broadcast Packet Handling
After configuring an IP interface address, you can enable routing and configure one or more routing protocols, or you can configure the way the switch responds to network broadcasts. A broadcast is a data packet destined for all hosts on a physical network. The switch supports two kinds of broadcasting:
•![]() A directed broadcast packet is sent to a specific network or series of networks. A directed broadcast address includes the network or subnet fields.
A directed broadcast packet is sent to a specific network or series of networks. A directed broadcast address includes the network or subnet fields.
•![]() A flooded broadcast packet is sent to every network.
A flooded broadcast packet is sent to every network.
Note ![]() You can also limit broadcast, unicast, and multicast traffic on Layer 2 interfaces by using the storm-control interface configuration command to set traffic suppression levels. For more information, see "Configuring Port-Based Traffic Control."
You can also limit broadcast, unicast, and multicast traffic on Layer 2 interfaces by using the storm-control interface configuration command to set traffic suppression levels. For more information, see "Configuring Port-Based Traffic Control."
Routers provide some protection from broadcast storms by limiting their extent to the local cable. Bridges (including intelligent bridges), because they are Layer 2 devices, forward broadcasts to all network segments, thus propagating broadcast storms. The best solution to the broadcast storm problem is to use a single broadcast address scheme on a network. In most modern IP implementations, you can set the address to be used as the broadcast address. Many implementations, including the one in the Catalyst 3750 switch, support several addressing schemes for forwarding broadcast messages.
Perform the tasks in these sections to enable these schemes:
•![]() Enabling Directed Broadcast-to-Physical Broadcast Translation
Enabling Directed Broadcast-to-Physical Broadcast Translation
•![]() Forwarding UDP Broadcast Packets and Protocols
Forwarding UDP Broadcast Packets and Protocols
•![]() Establishing an IP Broadcast Address
Establishing an IP Broadcast Address
Enabling Directed Broadcast-to-Physical Broadcast Translation
By default, IP directed broadcasts are dropped; they are not forwarded. Dropping IP-directed broadcasts makes routers less susceptible to denial-of-service attacks.
You can enable forwarding of IP-directed broadcasts on an interface where the broadcast becomes a physical (MAC-layer) broadcast. Only those protocols configured by using the ip forward-protocol global configuration command are forwarded.
You can specify an access list to control which broadcasts are forwarded. When an access list is specified, only those IP packets permitted by the access list are eligible to be translated from directed broadcasts to physical broadcasts. For more information on access lists, see "Configuring Network Security with ACLs."
Beginning in privileged EXEC mode, follow these steps to enable forwarding of IP-directed broadcasts on an interface:
Use the no ip directed-broadcast interface configuration command to disable translation of directed broadcast to physical broadcasts. Use the no ip forward-protocol global configuration command to remove a protocol or port.
Forwarding UDP Broadcast Packets and Protocols
User Datagram Protocol (UDP) is an IP host-to-host layer protocol, as is TCP. UDP provides a low-overhead, connectionless session between two end systems and does not provide for acknowledgment of received datagrams. Network hosts occasionally use UDP broadcasts to find address, configuration, and name information. If such a host is on a network segment that does not include a server, UDP broadcasts are normally not forwarded. You can remedy this situation by configuring an interface on a router to forward certain classes of broadcasts to a helper address. You can use more than one helper address per interface.
You can specify a UDP destination port to control which UDP services are forwarded. You can specify multiple UDP protocols. You can also specify the Network Disk (ND) protocol, which is used by older diskless Sun workstations and the network security protocol SDNS.
By default, both UDP and ND forwarding are enabled if a helper address has been defined for an interface. The description for the ip forward-protocol interface configuration command in the Cisco IOS IP Command Reference, Volume 1 of 3: Addressing and Services, Release 12.2 lists the ports that are forwarded by default if you do not specify any UDP ports.
If you do not specify any UDP ports when you configure the forwarding of UDP broadcasts, you are configuring the router to act as a BOOTP forwarding agent. BOOTP packets carry Dynamic Host Configuration Protocol (DHCP) information.
Beginning in privileged EXEC mode, follow these steps to enable forwarding UDP broadcast packets on an interface and specify the destination address:
Use the no ip helper-address interface configuration command to disable the forwarding of broadcast packets to specific addresses. Use the no ip forward-protocol global configuration command to remove a protocol or port.
Establishing an IP Broadcast Address
The most popular IP broadcast address (and the default) is an address consisting of all ones (255.255.255.255). However, the switch can be configured to generate any form of IP broadcast address.
Beginning in privileged EXEC mode, follow these steps to set the IP broadcast address on an interface:
To restore the default IP broadcast address, use the no ip broadcast-address interface configuration command.
Flooding IP Broadcasts
You can allow IP broadcasts to be flooded throughout your internetwork in a controlled fashion by using the database created by the bridging STP. Using this feature also prevents loops. To support this capability, bridging must be configured on each interface that is to participate in the flooding. If bridging is not configured on an interface, it still can receive broadcasts. However, the interface never forwards broadcasts it receives, and the router never uses that interface to send broadcasts received on a different interface.
Packets that are forwarded to a single network address using the IP helper-address mechanism can be flooded. Only one copy of the packet is sent on each network segment.
To be considered for flooding, packets must meet these criteria. (Note that these are the same conditions used to consider packet forwarding using IP helper addresses.)
•![]() The packet must be a MAC-level broadcast.
The packet must be a MAC-level broadcast.
•![]() The packet must be an IP-level broadcast.
The packet must be an IP-level broadcast.
•![]() The packet must be a TFTP, DNS, Time, NetBIOS, ND, or BOOTP packet, or a UDP specified by the ip forward-protocol udp global configuration command.
The packet must be a TFTP, DNS, Time, NetBIOS, ND, or BOOTP packet, or a UDP specified by the ip forward-protocol udp global configuration command.
•![]() The time-to-live (TTL) value of the packet must be at least two.
The time-to-live (TTL) value of the packet must be at least two.
A flooded UDP datagram is given the destination address specified with the ip broadcast-address interface configuration command on the output interface. The destination address can be set to any address. Thus, the destination address might change as the datagram propagates through the network. The source address is never changed. The TTL value is decremented.
When a flooded UDP datagram is sent out an interface (and the destination address possibly changed), the datagram is handed to the normal IP output routines and is, therefore, subject to access lists, if they are present on the output interface.
Beginning in privileged EXEC mode, follow these steps to use the bridging spanning-tree database to flood UDP datagrams:
Use the no ip forward-protocol spanning-tree global configuration command to disable the flooding of IP broadcasts.
In the Catalyst 3750 switch, the majority of packets are forwarded in hardware; most packets do not go through the switch CPU. For those packets that do go to the CPU, you can speed up spanning tree-based UDP flooding by a factor of about four to five times by using turbo-flooding. This feature is supported over Ethernet interfaces configured for ARP encapsulation.
Beginning in privileged EXEC mode, follow these steps to increase spanning-tree-based flooding:
To disable this feature, use the no ip forward-protocol turbo-flood global configuration command.
Monitoring and Maintaining IP Addressing
When the contents of a particular cache, table, or database have become or are suspected to be invalid, you can remove all its contents by using the clear privileged EXEC commands. Table 31-2 lists the commands for clearing contents.
You can display specific statistics, such as the contents of IP routing tables, caches, and databases; the reachability of nodes; and the routing path that packets are taking through the network. Table 31-3 lists the privileged EXEC commands for displaying IP statistics.
Enabling IP Unicast Routing
By default, the switch is in Layer 2 switching mode and IP routing is disabled. To use the Layer 3 capabilities of the switch, you must enable IP routing.
Beginning in privileged EXEC mode, follow these steps to enable IP routing:
Use the no ip routing global configuration command to disable routing.
This example shows how to enable IP routing using RIP as the routing protocol:
Switch# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Switch(config)# ip routing
Switch(config)# router rip
Switch(config-router)# network 10.0.0.0
Switch(config-router)# end
You can now set up parameters for the selected routing protocols as described in these sections:
•![]() Configuring Protocol-Independent Features (optional)
Configuring Protocol-Independent Features (optional)
Configuring RIP
The Routing Information Protocol (RIP) is an interior gateway protocol (IGP) created for use in small, homogeneous networks. It is a distance-vector routing protocol that uses broadcast User Datagram Protocol (UDP) data packets to exchange routing information. The protocol is documented in RFC 1058. You can find detailed information about RIP in IP Routing Fundamentals, published by Cisco Press.
Note ![]() RIP is the only routing protocol supported by the SMI; other routing protocols require the stack master to be running the EMI.
RIP is the only routing protocol supported by the SMI; other routing protocols require the stack master to be running the EMI.
Using RIP, the switch sends routing information updates (advertisements) every 30 seconds. If a router does not receive an update from another router for 180 seconds or more, it marks the routes served by that router as unusable. If there is still no update after 240 seconds, the router removes all routing table entries for the non-updating router.
RIP uses hop counts to rate the value of different routes. The hop count is the number of routers that can be traversed in a route. A directly connected network has a hop count of zero; a network with a hop count of 16 is unreachable. This small range (0 to 15) makes RIP unsuitable for large networks.
If the router has a default network path, RIP advertises a route that links the router to the pseudonetwork 0.0.0.0. The 0.0.0.0 network does not exist; it is treated by RIP as a network to implement the default routing feature. The switch advertises the default network if a default was learned by RIP or if the router has a gateway of last resort and RIP is configured with a default metric. RIP sends updates to the interfaces in specified networks. If an interface's network is not specified, it is not advertised in any RIP update.
This section briefly describes how to configure RIP. It includes this information:
•![]() Configuring Basic RIP Parameters
Configuring Basic RIP Parameters
•![]() Configuring RIP Authentication
Configuring RIP Authentication
•![]() Configuring Summary Addresses and Split Horizon
Configuring Summary Addresses and Split Horizon
Default RIP Configuration
Table 31-4 shows the default RIP configuration.
Configuring Basic RIP Parameters
To configure RIP, you enable RIP routing for a network and optionally configure other parameters.
Beginning in privileged EXEC mode, follow these steps to enable and configure RIP:
To turn off the RIP routing process, use the no router rip global configuration command.
To display the parameters and current state of the active routing protocol process, use the show ip protocols privileged EXEC command. Use the show ip rip database privileged EXEC command to display summary address entries in the RIP database.
Configuring RIP Authentication
RIP version 1 does not support authentication. If you are sending and receiving RIP Version 2 packets, you can enable RIP authentication on an interface. The key chain specifies \the set of keys that can be used on the interface. If a key chain is not configured, no authentication is performed, not even the default. Therefore, you must also perform the tasks in the "Managing Authentication Keys" section.
The switch supports two modes of authentication on interfaces for which RIP authentication is enabled: plain text and MD5. The default is plain text.
Beginning in privileged EXEC mode, follow these steps to configure RIP authentication on an interface:
To restore clear text authentication, use the no ip rip authentication mode interface configuration command. To prevent authentication, use the no ip rip authentication key-chain interface configuration command.
Configuring Summary Addresses and Split Horizon
Routers connected to broadcast-type IP networks and using distance-vector routing protocols normally use the split-horizon mechanism to reduce the possibility of routing loops. Split horizon blocks information about routes from being advertised by a router on any interface from which that information originated. This feature usually optimizes communication among multiple routers, especially when links are broken.
Note ![]() In general, disabling split horizon is not recommended unless you are certain that your application requires it to properly advertise routes.
In general, disabling split horizon is not recommended unless you are certain that your application requires it to properly advertise routes.
If you want to configure an interface running RIP to advertise a summarized local IP address pool on a network access server for dial-up clients, use the ip summary-address rip interface configuration command.
Note ![]() If split horizon is enabled, neither autosummary nor interface IP summary addresses are advertised.
If split horizon is enabled, neither autosummary nor interface IP summary addresses are advertised.
Beginning in privileged EXEC mode, follow these steps to set an interface to advertise a summarized local IP address and to disable split horizon on the interface:
To disable IP summarization, use the no ip summary-address rip router configuration command.
In this example, the major net is 10.0.0.0. The summary address 10.2.0.0 overrides the autosummary address of 10.0.0.0 so that 10.2.0.0 is advertised out interface Gigabit Ethernet port 2, and 10.0.0.0 is not advertised. In the example, if the interface is still in Layer 2 mode (the default), you must enter a no switchport interface configuration command before entering the ip address interface configuration command.
Note ![]() If split horizon is enabled, neither autosummary nor interface summary addresses (those configured with the ip summary-address rip router configuration command) are advertised.
If split horizon is enabled, neither autosummary nor interface summary addresses (those configured with the ip summary-address rip router configuration command) are advertised.
Switch(config)# router rip
Switch(config-router)# interface gi1/0/2
Switch(config-if)# ip address 10.1.5.1 255.255.255.0
Switch(config-if)# ip summary-address rip 10.2.0.0 255.255.0.0
Switch(config-if)# no ip split-horizon
Switch(config-if)# exit
Switch(config)# router rip
Switch(config-router)# network 10.0.0.0
Switch(config-router)# neighbor 2.2.2.2 peer-group mygroup
Switch(config-router)# end
Configuring Split Horizon
Routers connected to broadcast-type IP networks and using distance-vector routing protocols normally use the split-horizon mechanism to reduce the possibility of routing loops. Split horizon blocks information about routes from being advertised by a router on any interface from which that information originated. This feature can optimize communication among multiple routers, especially when links are broken.
Note ![]() In general, we do not recommend disabling split horizon unless you are certain that your application requires it to properly advertise routes.
In general, we do not recommend disabling split horizon unless you are certain that your application requires it to properly advertise routes.
Beginning in privileged EXEC mode, follow these steps to disable split horizon on the interface:
To enable the split horizon mechanism, use the ip split-horizon interface configuration command.
Configuring OSPF
This section briefly describes how to configure Open Shortest Path First (OSPF). For a complete description of the OSPF commands, refer to the "OSPF Commands" chapter of the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2.
Note ![]() OSPF classifies different media into broadcast, nonbroadcast, and point-to-point networks. The Catalyst 3750 switch supports broadcast (Ethernet, Token Ring, and FDDI) and point-to-point networks (Ethernet interfaces configured as point-to-point links).
OSPF classifies different media into broadcast, nonbroadcast, and point-to-point networks. The Catalyst 3750 switch supports broadcast (Ethernet, Token Ring, and FDDI) and point-to-point networks (Ethernet interfaces configured as point-to-point links).
OSPF is an Interior Gateway Protocol (IGP) designed expressly for IP networks, supporting IP subnetting and tagging of externally derived routing information. OSPF also allows packet authentication and uses IP multicast when sending and receiving packets. The Cisco implementation supports RFC 1253, OSPF management information base (MIB).
The Cisco implementation conforms to the OSPF Version 2 specifications with these key features:
•![]() Definition of stub areas is supported.
Definition of stub areas is supported.
•![]() Routes learned through any IP routing protocol can be redistributed into another IP routing protocol. At the intradomain level, this means that OSPF can import routes learned through IGRP and RIP. OSPF routes can also be exported into IGRP and RIP.
Routes learned through any IP routing protocol can be redistributed into another IP routing protocol. At the intradomain level, this means that OSPF can import routes learned through IGRP and RIP. OSPF routes can also be exported into IGRP and RIP.
•![]() Plain text and MD5 authentication among neighboring routers within an area is supported.
Plain text and MD5 authentication among neighboring routers within an area is supported.
•![]() Configurable routing interface parameters include interface output cost, retransmission interval, interface transmit delay, router priority, router dead and hello intervals, and authentication key.
Configurable routing interface parameters include interface output cost, retransmission interval, interface transmit delay, router priority, router dead and hello intervals, and authentication key.
•![]() Virtual links are supported.
Virtual links are supported.
•![]() Not-so-stubby-areas (NSSAs) per RFC 1587are supported.
Not-so-stubby-areas (NSSAs) per RFC 1587are supported.
OSPF typically requires coordination among many internal routers, area border routers (ABRs) connected to multiple areas, and autonomous system boundary routers (ASBRs). The minimum configuration would use all default parameter values, no authentication, and interfaces assigned to areas. If you customize your environment, you must ensure coordinated configuration of all routers.
This section briefly describes how to configure OSPF. It includes this information:
•![]() Configuring Basic OSPF Parameters
Configuring Basic OSPF Parameters
•![]() Configuring OSPF Area Parameters
Configuring OSPF Area Parameters
•![]() Configuring Other OSPF Parameters
Configuring Other OSPF Parameters
•![]() Configuring a Loopback Interface
Configuring a Loopback Interface
Note ![]() To enable OSPF, the stack master must be running the EMI.
To enable OSPF, the stack master must be running the EMI.
Default OSPF Configuration
Table 31-5 shows the default OSPF configuration.
Configuring Basic OSPF Parameters
Enabling OSPF requires that you create an OSPF routing process, specify the range of IP addresses to be associated with the routing process, and assign area IDs to be associated with that range.
Beginning in privileged EXEC mode, follow these steps to enable OSPF:
To terminate an OSPF routing process, use the no router ospf process-id global configuration command.
This example shows how to configure an OSPF routing process and assign it a process number of 109:
Switch(config)# router ospf 109
Switch(config-router)# network 131.108.0.0 255.255.255.0 area 24
Configuring OSPF Interfaces
You can use the ip ospf interface configuration commands to modify interface-specific OSPF parameters. You are not required to modify any of these parameters, but some interface parameters (hello interval, dead interval, and authentication key) must be consistent across all routers in an attached network. If you modify these parameters, be sure all routers in the network have compatible values.
Note ![]() The ip ospf interface configuration commands are all optional.
The ip ospf interface configuration commands are all optional.
Beginning in privileged EXEC mode, follow these steps to modify OSPF interface parameters:
Use the no form of these commands to remove the configured parameter value or return to the default value.
Configuring OSPF Area Parameters
You can optionally configure several OSPF area parameters. These parameters include authentication for password-based protection against unauthorized access to an area, stub areas, and not-so-stubby-areas (NSSAs). Stub areas are areas into which information on external routes is not sent. Instead, the area border router (ABR) generates a default external route into the stub area for destinations outside the autonomous system (AS). An NSSA does not flood all LSAs from the core into the area, but can import AS external routes within the area by redistribution.
Route summarization is the consolidation of advertised addresses into a single summary route to be advertised by other areas. If network numbers are contiguous, you can use the area range router configuration command to configure the ABR to advertise a summary route that covers all networks in the range.
Note ![]() The OSPF area router configuration commands are all optional.
The OSPF area router configuration commands are all optional.
Beginning in privileged EXEC mode, follow these steps to configure area parameters:
Use the no form of these commands to remove the configured parameter value or to return to the default value.
Configuring Other OSPF Parameters
You can optionally configure other OSPF parameters in router configuration mode.
•![]() Route summarization: When redistributing routes from other protocols, as described in the "Using Route Maps to Redistribute Routing Information" section, each route is advertised individually in an external LSA. To help decrease the size of the OSPF link state database, you can use the summary-address router configuration command to advertise a single router for all the redistributed routes included in a specified network address and mask.
Route summarization: When redistributing routes from other protocols, as described in the "Using Route Maps to Redistribute Routing Information" section, each route is advertised individually in an external LSA. To help decrease the size of the OSPF link state database, you can use the summary-address router configuration command to advertise a single router for all the redistributed routes included in a specified network address and mask.
•![]() Virtual links: In OSPF, all areas must be connected to a backbone area. You can establish a virtual link in case of a backbone-continuity break by configuring two Area Border Routers as endpoints of a virtual link. Configuration information includes the identity of the other virtual endpoint (the other ABR) and the nonbackbone link that the two routers have in common (the transit area). Virtual links cannot be configured through a stub area.
Virtual links: In OSPF, all areas must be connected to a backbone area. You can establish a virtual link in case of a backbone-continuity break by configuring two Area Border Routers as endpoints of a virtual link. Configuration information includes the identity of the other virtual endpoint (the other ABR) and the nonbackbone link that the two routers have in common (the transit area). Virtual links cannot be configured through a stub area.
•![]() Default route: When you specifically configure redistribution of routes into an OSPF routing domain, the route automatically becomes an autonomous system boundary router (ASBR). You can force the ASBR to generate a default route into the OSPF routing domain.
Default route: When you specifically configure redistribution of routes into an OSPF routing domain, the route automatically becomes an autonomous system boundary router (ASBR). You can force the ASBR to generate a default route into the OSPF routing domain.
•![]() Domain Name Server (DNS) names for use in all OSPF show privileged EXEC command displays makes it easier to identify a router than displaying it by router ID or neighbor ID.
Domain Name Server (DNS) names for use in all OSPF show privileged EXEC command displays makes it easier to identify a router than displaying it by router ID or neighbor ID.
•![]() Default Metrics: OSPF calculates the OSPF metric for an interface according to the bandwidth of the interface. The metric is calculated as ref-bw divided by bandwidth, where ref is 10 by default, and bandwidth (bw) is specified by the bandwidth interface configuration command. For multiple links with high bandwidth, you can specify a larger number to differentiate the cost on those links.
Default Metrics: OSPF calculates the OSPF metric for an interface according to the bandwidth of the interface. The metric is calculated as ref-bw divided by bandwidth, where ref is 10 by default, and bandwidth (bw) is specified by the bandwidth interface configuration command. For multiple links with high bandwidth, you can specify a larger number to differentiate the cost on those links.
•![]() Administrative distance is a rating of the trustworthiness of a routing information source, an integer between 0 and 255, with a higher value meaning a lower trust rating. An administrative distance of 255 means the routing information source cannot be trusted at all and should be ignored. OSPF uses three different administrative distances: routes within an area (interarea), routes to another area (interarea), and routes from another routing domain learned through redistribution (external). You can change any of the distance values.
Administrative distance is a rating of the trustworthiness of a routing information source, an integer between 0 and 255, with a higher value meaning a lower trust rating. An administrative distance of 255 means the routing information source cannot be trusted at all and should be ignored. OSPF uses three different administrative distances: routes within an area (interarea), routes to another area (interarea), and routes from another routing domain learned through redistribution (external). You can change any of the distance values.
•![]() Passive interfaces: Because interfaces between two devices on an Ethernet represent only one network segment, to prevent OSPF from sending hello packets for the sending interface, you must configure the sending device to be a passive interface. Both devices can identify each other through the hello packet for the receiving interface.
Passive interfaces: Because interfaces between two devices on an Ethernet represent only one network segment, to prevent OSPF from sending hello packets for the sending interface, you must configure the sending device to be a passive interface. Both devices can identify each other through the hello packet for the receiving interface.
•![]() Route calculation timers: You can configure the delay time between when OSPF receives a topology change and when it starts the shortest path first (SPF) calculation and the hold time between two SPF calculations.
Route calculation timers: You can configure the delay time between when OSPF receives a topology change and when it starts the shortest path first (SPF) calculation and the hold time between two SPF calculations.
•![]() Log neighbor changes: You can configure the router to send a syslog message when an OSPF neighbor state changes, providing a high-level view of changes in the router.
Log neighbor changes: You can configure the router to send a syslog message when an OSPF neighbor state changes, providing a high-level view of changes in the router.
Beginning in privileged EXEC mode, follow these steps to configure these OSPF parameters:
|
|
|
|
|---|---|---|
Step 1 |
configure terminal |
Enter global configuration mode. |
Step 2 |
router ospf process-id |
Enable OSPF routing, and enter router configuration mode. |
Step 3 |
summary-address address mask |
(Optional) Specify an address and IP subnet mask for redistributed routes so that only one summary route is advertised. |
Step 4 |
area area-id virtual-link router-id [hello-interval seconds] [retransmit-interval seconds] [trans] [[authentication-key key] | message-digest-key keyid md5 key]] |
(Optional) Establish a virtual link and set its parameters. See the "Configuring OSPF Interfaces" section for parameter definitions and Table 31-5 for virtual link defaults. |
Step 5 |
default-information originate [always] [metric metric-value] [metric-type type-value] [route-map map-name] |
(Optional) Force the ASBR to generate a default route into the OSPF routing domain. Parameters are all optional. |
Step 6 |
ip ospf name-lookup |
(Optional) Configure DNS name lookup. The default is disabled. |
Step 7 |
ip auto-cost reference-bandwidth ref-bw |
(Optional) Specify an address range for which a single route will be advertised. Use this command only with area border routers. |
Step 8 |
distance ospf {[inter-area dist1] [inter-area dist2] [external dist3]} |
(Optional) Change the OSPF distance values. The default distance for each type of route is 110. The range is 1 to 255. |
Step 9 |
passive-interface type number |
(Optional) Suppress the sending of hello packets through the specified interface. |
Step 10 |
timers spf spf-delay spf-holdtime |
(Optional) Configure route calculation timers. • • |
Step 11 |
ospf log-adj-changes |
(Optional) Send syslog message when a neighbor state changes. |
Step 12 |
end |
Return to privileged EXEC mode. |
Step 13 |
show ip ospf [process-id [area-id]] database |
Display lists of information related to the OSPF database for a specific router. For some of the keyword options, see the "Monitoring OSPF" section. |
Step 14 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
Changing LSA Group Pacing
The OSPF LSA group pacing feature allows the router to group OSPF LSAs and pace the refreshing, check-summing, and aging functions for more efficient router use. This feature is enabled by default with a 4-minute default pacing interval, and you will not usually need to modify this parameter. The optimum group pacing interval is inversely proportional to the number of LSAs the router is refreshing, check-summing, and aging. For example, if you have approximately 10,000 LSAs in the database, decreasing the pacing interval would benefit you. If you have a very small database (40 to 100 LSAs), increasing the pacing interval to 10 to 20 minutes might benefit you slightly.
Beginning in privileged EXEC mode, follow these steps to configure OSPF LSA pacing:
To return to the default value, use the no timers lsa-group-pacing router configuration command.
Configuring a Loopback Interface
OSPF uses the highest IP address configured on the interfaces as its router ID. If this interface is down or removed, the OSPF process must recalculate a new router ID and resend all its routing information out its interfaces. If a loopback interface is configured with an IP address, OSPF uses this IP address as its router ID, even if other interfaces have higher IP addresses. Because loopback interfaces never fail, this provides greater stability. OSPF automatically prefers a loopback interface over other interfaces, and it chooses the highest IP address among all loopback interfaces.
Beginning in privileged EXEC mode, follow these steps to configure a loopback interface:
Use the no interface loopback 0 global configuration command to disable the loopback interface.
Monitoring OSPF
You can display specific statistics such as the contents of IP routing tables, caches, and databases.
Table 31-6 lists some of the privileged EXEC commands for displaying statistics. For more show ip ospf database privileged EXEC command options and for explanations of fields in the resulting display, refer to the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2.
Configuring EIGRP
Enhanced IGRP (EIGRP) is a Cisco proprietary enhanced version of the IGRP. EIGRP uses the same distance vector algorithm and distance information as IGRP; however, the convergence properties and the operating efficiency of EIGRP are significantly improved.
The convergence technology employs an algorithm referred to as the Diffusing Update Algorithm (DUAL), which guarantees loop-free operation at every instant throughout a route computation and allows all devices involved in a topology change to synchronize at the same time. Routers that are not affected by topology changes are not involved in recomputations.
IP EIGRP provides increased network width. With RIP, the largest possible width of your network is 15 hops. When IGRP is enabled, the largest possible width is 224 hops. Because the EIGRP metric is large enough to support thousands of hops, the only barrier to expanding the network is the transport-layer hop counter. EIGRP increments the transport control field only when an IP packet has traversed 15 routers and the next hop to the destination was learned through EIGRP. When a RIP route is used as the next hop to the destination, the transport control field is incremented as usual.
EIGRP offers these features:
•![]() Fast convergence.
Fast convergence.
•![]() Incremental updates when the state of a destination changes, instead of sending the entire contents of the routing table, minimizing the bandwidth required for EIGRP packets.
Incremental updates when the state of a destination changes, instead of sending the entire contents of the routing table, minimizing the bandwidth required for EIGRP packets.
•![]() Less CPU usage than IGRP because full update packets need not be processed each time they are received.
Less CPU usage than IGRP because full update packets need not be processed each time they are received.
•![]() Protocol-independent neighbor discovery mechanism to learn about neighboring routers.
Protocol-independent neighbor discovery mechanism to learn about neighboring routers.
•![]() Variable-length subnet masks (VLSMs).
Variable-length subnet masks (VLSMs).
•![]() Arbitrary route summarization.
Arbitrary route summarization.
•![]() EIGRP scales to large networks.
EIGRP scales to large networks.
EIGRP has these four basic components:
•![]() Neighbor discovery and recovery is the process that routers use to dynamically learn of other routers on their directly attached networks. Routers must also discover when their neighbors become unreachable or inoperative. Neighbor discovery and recovery is achieved with low overhead by periodically sending small hello packets. As long as hello packets are received, the Cisco IOS software can learn that a neighbor is alive and functioning. When this status is determined, the neighboring routers can exchange routing information.
Neighbor discovery and recovery is the process that routers use to dynamically learn of other routers on their directly attached networks. Routers must also discover when their neighbors become unreachable or inoperative. Neighbor discovery and recovery is achieved with low overhead by periodically sending small hello packets. As long as hello packets are received, the Cisco IOS software can learn that a neighbor is alive and functioning. When this status is determined, the neighboring routers can exchange routing information.
•![]() The reliable transport protocol is responsible for guaranteed, ordered delivery of EIGRP packets to all neighbors. It supports intermixed transmission of multicast and unicast packets. Some EIGRP packets must be sent reliably, and others need not be. For efficiency, reliability is provided only when necessary. For example, on a multiaccess network that has multicast capabilities (such as Ethernet), it is not necessary to send hellos reliably to all neighbors individually. Therefore, EIGRP sends a single multicast hello with an indication in the packet informing the receivers that the packet need not be acknowledged. Other types of packets (such as updates) require acknowledgment, which is shown in the packet. The reliable transport has a provision to send multicast packets quickly when there are unacknowledged packets pending. Doing so helps ensure that convergence time remains low in the presence of varying speed links.
The reliable transport protocol is responsible for guaranteed, ordered delivery of EIGRP packets to all neighbors. It supports intermixed transmission of multicast and unicast packets. Some EIGRP packets must be sent reliably, and others need not be. For efficiency, reliability is provided only when necessary. For example, on a multiaccess network that has multicast capabilities (such as Ethernet), it is not necessary to send hellos reliably to all neighbors individually. Therefore, EIGRP sends a single multicast hello with an indication in the packet informing the receivers that the packet need not be acknowledged. Other types of packets (such as updates) require acknowledgment, which is shown in the packet. The reliable transport has a provision to send multicast packets quickly when there are unacknowledged packets pending. Doing so helps ensure that convergence time remains low in the presence of varying speed links.
•![]() The DUAL finite state machine embodies the decision process for all route computations. It tracks all routes advertised by all neighbors. DUAL uses the distance information (known as a metric) to select efficient, loop-free paths. DUAL selects routes to be inserted into a routing table based on feasible successors. A successor is a neighboring router used for packet forwarding that has a least-cost path to a destination that is guaranteed not to be part of a routing loop. When there are no feasible successors, but there are neighbors advertising the destination, a recomputation must occur. This is the process whereby a new successor is determined. The amount of time it takes to recompute the route affects the convergence time. Recomputation is processor-intensive; it is advantageous to avoid recomputation if it is not necessary. When a topology change occurs, DUAL tests for feasible successors. If there are feasible successors, it uses any it finds to avoid unnecessary recomputation.
The DUAL finite state machine embodies the decision process for all route computations. It tracks all routes advertised by all neighbors. DUAL uses the distance information (known as a metric) to select efficient, loop-free paths. DUAL selects routes to be inserted into a routing table based on feasible successors. A successor is a neighboring router used for packet forwarding that has a least-cost path to a destination that is guaranteed not to be part of a routing loop. When there are no feasible successors, but there are neighbors advertising the destination, a recomputation must occur. This is the process whereby a new successor is determined. The amount of time it takes to recompute the route affects the convergence time. Recomputation is processor-intensive; it is advantageous to avoid recomputation if it is not necessary. When a topology change occurs, DUAL tests for feasible successors. If there are feasible successors, it uses any it finds to avoid unnecessary recomputation.
•![]() The protocol-dependent modules are responsible for network layer protocol-specific tasks. An example is the IP EIGRP module, which is responsible for sending and receiving EIGRP packets that are encapsulated in IP. It is also responsible for parsing EIGRP packets and informing DUAL of the new information received. EIGRP asks DUAL to make routing decisions, but the results are stored in the IP routing table. EIGRP is also responsible for redistributing routes learned by other IP routing protocols.
The protocol-dependent modules are responsible for network layer protocol-specific tasks. An example is the IP EIGRP module, which is responsible for sending and receiving EIGRP packets that are encapsulated in IP. It is also responsible for parsing EIGRP packets and informing DUAL of the new information received. EIGRP asks DUAL to make routing decisions, but the results are stored in the IP routing table. EIGRP is also responsible for redistributing routes learned by other IP routing protocols.
This section briefly describes how to configure EIGRP. It includes this information:
•![]() Configuring Basic EIGRP Parameters
Configuring Basic EIGRP Parameters
•![]() Configuring EIGRP Route Authentication
Configuring EIGRP Route Authentication
•![]() Monitoring and Maintaining EIGRP
Monitoring and Maintaining EIGRP
Note ![]() To enable EIGRP, the stack master must be running the EMI.
To enable EIGRP, the stack master must be running the EMI.
Default EIGRP Configuration
Table 31-7 shows the default EIGRP configuration.
To create an EIGRP routing process, you must enable EIGRP and associate networks. EIGRP sends updates to the interfaces in the specified networks. If you do not specify an interface network, it is not advertised in any EIGRP update.
Note ![]() If you have routers on your network that are configured for IGRP, and you want to change to EIGRP, you must designate transition routers that have both IGRP and EIGRP configured. In these cases, perform Steps 1 through 3 in the next section and also see the "Configuring Split Horizon" section. You must use the same AS number for routes to be automatically redistributed.
If you have routers on your network that are configured for IGRP, and you want to change to EIGRP, you must designate transition routers that have both IGRP and EIGRP configured. In these cases, perform Steps 1 through 3 in the next section and also see the "Configuring Split Horizon" section. You must use the same AS number for routes to be automatically redistributed.
Configuring Basic EIGRP Parameters
Beginning in privileged EXEC mode, follow these steps to configure EIGRP. Configuring the routing process is required; other steps are optional:
Use the no forms of these commands to disable the feature or return the setting to the default value.
Configuring EIGRP Interfaces
Other optional EIGRP parameters can be configured on an interface basis.
Beginning in privileged EXEC mode, follow these steps to configure EIGRP interfaces:
Use the no forms of these commands to disable the feature or return the setting to the default value.
Configuring EIGRP Route Authentication
EIGRP route authentication provides MD5 authentication of routing updates from the EIGRP routing protocol to prevent the introduction of unauthorized or false routing messages from unapproved sources.
Beginning in privileged EXEC mode, follow these steps to enable authentication:
Use the no forms of these commands to disable the feature or to return the setting to the default value.
Monitoring and Maintaining EIGRP
You can delete neighbors from the neighbor table. You can also display various EIGRP routing statistics. Table 31-8 lists the privileged EXEC commands for deleting neighbors and displaying statistics. For explanations of fields in the resulting display, refer to the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2.
Configuring BGP
The Border Gateway Protocol (BGP) is an exterior gateway protocol used to set up an interdomain routing system that guarantees the loop-free exchange of routing information between autonomous systems. Autonomous systems are made up of routers that operate under the same administration and that run Interior Gateway Protocols (IGPs), such as RIP or OSPF, within their boundaries and that interconnect by using an Exterior Gateway Protocol (EGP). BGP version 4 is the standard EGP for interdomain routing in the Internet. The protocol is defined in RFCs 1163, 1267, and 1771. You can find detailed information about BGP in Internet Routing Architectures, published by Cisco Press, and in the "Configuring BGP" chapter in the Cisco IOS IP and IP Routing Configuration Guide.
For details about BGP commands and keywords, refer to the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2. . For a list of BGP commands that are visible but not supported by the switch, see "Unsupported Commands in Cisco IOS Release 12.2(18)SE."
Routers that belong to the same autonomous system (AS) and that exchange BGP updates run internal BGP (IBGP), and routers that belong to different autonomous systems and that exchange BGP updates run external BGP (EBGP). Most configuration commands are the same for configuring EBGP and IBGP. The difference is that the routing updates are exchanged either between autonomous systems (EBGP) or within an AS (IBGP). Figure 31-4 shows a network that is running both EBGP and IBGP.
Figure 31-4 EBGP, IBGP, and Multiple Autonomous Systems
Before exchanging information with an external AS, BGP ensures that networks within the AS can be reached by defining internal BGP peering among routers within the AS and by redistributing BGP routing information to IGPs that run within the AS, such as IGRP and OSPF.
Routers that run a BGP routing process are often referred to as BGP speakers. BGP uses the Transmission Control Protocol (TCP) as its transport protocol (specifically port 179). Two BGP speakers that have a TCP connection to each other for exchanging routing information are known as peers or neighbors. In Figure 31-4, Routers A and B are BGP peers, as are Routers B and C and Routers C and D. The routing information is a series of AS numbers that describe the full path to the destination network. BGP uses this information to construct a loop-free map of autonomous systems.
The network has these characteristics:
•![]() Routers A and B are running EBGP, and Routers B and C are running IBGP. Note that the EBGP peers are directly connected and that the IBGP peers are not. As long as there is an IGP running that allows the two neighbors to reach one another, IBGP peers do not have to be directly connected.
Routers A and B are running EBGP, and Routers B and C are running IBGP. Note that the EBGP peers are directly connected and that the IBGP peers are not. As long as there is an IGP running that allows the two neighbors to reach one another, IBGP peers do not have to be directly connected.
•![]() All BGP speakers within an AS must establish a peer relationship with each other. That is, the BGP speakers within an AS must be fully meshed logically. BGP4 provides two techniques that reduce the requirement for a logical full mesh: confederations and route reflectors.
All BGP speakers within an AS must establish a peer relationship with each other. That is, the BGP speakers within an AS must be fully meshed logically. BGP4 provides two techniques that reduce the requirement for a logical full mesh: confederations and route reflectors.
•![]() AS 200 is a transit AS for AS 100 and AS 300—that is, AS 200 is used to transfer packets between AS 100 and AS 300.
AS 200 is a transit AS for AS 100 and AS 300—that is, AS 200 is used to transfer packets between AS 100 and AS 300.
BGP peers initially exchange their full BGP routing tables and then send only incremental updates. BGP peers also exchange keepalive messages (to ensure that the connection is up) and notification messages (in response to errors or special conditions).
In BGP, each route consists of a network number, a list of autonomous systems that information has passed through (the autonomous system path), and a list of other path attributes. The primary function of a BGP system is to exchange network reachability information, including information about the list of AS paths, with other BGP systems. This information can be used to determine AS connectivity, to prune routing loops, and to enforce AS-level policy decisions.
A router or switch running Cisco IOS does not select or use an IBGP route unless it has a route available to the next-hop router and it has received synchronization from an IGP (unless IGP synchronization is disabled). When multiple routes are available, BGP bases its path selection on attribute values. See the "Configuring BGP Decision Attributes" section for information about BGP attributes.
BGP Version 4 supports classless interdomain routing (CIDR) so you can reduce the size of your routing tables by creating aggregate routes, resulting in supernets. CIDR eliminates the concept of network classes within BGP and supports the advertising of IP prefixes.
These sections briefly describe how to configure BGP and supported BGP features:
•![]() Managing Routing Policy Changes
Managing Routing Policy Changes
•![]() Configuring BGP Decision Attributes
Configuring BGP Decision Attributes
•![]() Configuring BGP Filtering with Route Maps
Configuring BGP Filtering with Route Maps
•![]() Configuring BGP Filtering by Neighbor
Configuring BGP Filtering by Neighbor
•![]() Configuring Prefix Lists for BGP Filtering
Configuring Prefix Lists for BGP Filtering
•![]() Configuring BGP Community Filtering
Configuring BGP Community Filtering
•![]() Configuring BGP Neighbors and Peer Groups
Configuring BGP Neighbors and Peer Groups
•![]() Configuring Aggregate Addresses
Configuring Aggregate Addresses
•![]() Configuring Routing Domain Confederations
Configuring Routing Domain Confederations
•![]() Configuring BGP Route Reflectors
Configuring BGP Route Reflectors
•![]() Monitoring and Maintaining BGP
Monitoring and Maintaining BGP
For detailed descriptions of BGP configuration, refer to the "Configuring BGP" chapter in the Cisco IOS IP Configuration Guide, Release 12.2 . For details about specific commands, refer to the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2.
For a list of BGP commands that are visible but not supported by the switch, see "Unsupported Commands in Cisco IOS Release 12.2(18)SE."
Default BGP Configuration
Table 31-9 shows the basic default BGP configuration. For the defaults for all characteristics, refer to the specific commands in the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2.
Enabling BGP Routing
To enable BGP routing, you establish a BGP routing process and define the local network. Because BGP must completely recognize the relationships with its neighbors, you must also specify a BGP neighbor.
BGP supports two kinds of neighbors: internal and external. Internal neighbors are in the same AS; external neighbors are in different autonomous systems. External neighbors are usually adjacent to each other and share a subnet, but internal neighbors can be anywhere in the same AS.
The switch supports the use of private AS numbers, usually assigned by service providers and given to systems whose routes are not advertised to external neighbors. The private AS numbers are from 64512 to 65535. You can configure external neighbors to remove private AS numbers from the AS path by using the neighbor remove-private-as router configuration command. Then when an update is passed to an external neighbor, if the AS path includes private AS numbers, these numbers are dropped.
If your AS will be passing traffic through it from another AS to a third AS, it is important to be consistent about the routes it advertises. If BGP advertised a route before all routers in the network had learned about the route through the IGP, the AS might receive traffic that some routers could not yet route. To prevent this from happening, BGP must wait until the IGP has propagated information across the AS so that BGP is synchronized with the IGP. Synchronization is enabled by default. If your AS does not pass traffic from one AS to another AS, or if all routers in your autonomous systems are running BGP, you can disable synchronization, which allows your network to carry fewer routes in the IGP and allows BGP to converge more quickly.
Note ![]() To enable BGP, the stack master must be running the EMI.
To enable BGP, the stack master must be running the EMI.
Beginning in privileged EXEC mode, follow these steps to enable BGP routing, establish a BGP routing process, and specify a neighbor:
Use the no router bgp autonomous-system global configuration command to remove a BGP AS. Use the no network network-number router configuration command to remove the network from the BGP table. Use the no neighbor {ip-address | peer-group-name} remote-as number router configuration command to remove a neighbor. Use the no neighbor {ip-address | peer-group-name} remove-private-as router configuration command to include private AS numbers in updates to a neighbor. Use the synchronization router configuration command to re-enable synchronization.
These examples show how to configure BGP on the routers in Figure 31-4.
Router A:
Switch(config)# router bgp 100
Switch(config-router)# neighbor 129.213.1.1 remote-as 200
Router B:
Switch(config)# router bgp 200
Switch(config-router)# neighbor 129.213.1.2 remote-as 100
Switch(config-router)# neighbor 175.220.1.2 remote-as 200
Router C:
Switch(config)# router bgp 200
Switch(config-router)# neighbor 175.220.212.1 remote-as 200
Switch(config-router)# neighbor 192.208.10.1 remote-as 300
Router D:
Switch(config)# router bgp 300
Switch(config-router)# neighbor 192.208.10.2 remote-as 200
To verify that BGP peers are running, use the show ip bgp neighbors privileged EXEC command. This is the output of this command on Router A:
Switch# show ip bgp neighbors
BGP neighbor is 129.213.1.1, remote AS 200, external link
BGP version 4, remote router ID 175.220.212.1
BGP state = established, table version = 3, up for 0:10:59
Last read 0:00:29, hold time is 180, keepalive interval is 60 seconds
Minimum time between advertisement runs is 30 seconds
Received 2828 messages, 0 notifications, 0 in queue
Sent 2826 messages, 0 notifications, 0 in queue
Connections established 11; dropped 10
Anything other than state = established means that the peers are not running. The remote router ID is the highest IP address on that router (or the highest loopback interface). Each time the table is updated with new information, the table version number increments. A table version number that continually increments means that a route is flapping, causing continual routing updates.
For exterior protocols, a reference to an IP network from the network router configuration command controls only which networks are advertised. This is in contrast to Interior Gateway Protocols (IGPs), such as IGRP, which also use the network command to specify where to send updates.
For detailed descriptions of BGP configuration, refer to the "IP Routing Protocols" chapter in the Cisco IOS IP Configuration Guide, Release 12.2. For details about specific commands, refer to the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2. See "Unsupported Commands in Cisco IOS Release 12.2(18)SE," for a list of BGP commands that are visible but not supported by the switch.
Managing Routing Policy Changes
Routing policies for a peer include all the configurations that might affect inbound or outbound routing table updates. When you have defined two routers as BGP neighbors, they form a BGP connection and exchange routing information. If you later change a BGP filter, weight, distance, version, or timer, or make a similar configuration change, you must reset the BGP sessions so that the configuration changes take effect.
There are two types of reset, hard reset and soft reset. Cisco IOS Releases 12.1 and later support a soft reset without any prior configuration. To use a soft reset without preconfiguration, both BGP peers must support the soft route refresh capability, which is advertised in the OPEN message sent when the peers establish a TCP session. A soft reset allows the dynamic exchange of route refresh requests and routing information between BGP routers and the subsequent re-advertisement of the respective outbound routing table.
•![]() When soft reset generates inbound updates from a neighbor, it is called dynamic inbound soft reset.
When soft reset generates inbound updates from a neighbor, it is called dynamic inbound soft reset.
•![]() When soft reset sends a set of updates to a neighbor, it is called outbound soft reset.
When soft reset sends a set of updates to a neighbor, it is called outbound soft reset.
A soft inbound reset causes the new inbound policy to take effect. A soft outbound reset causes the new local outbound policy to take effect without resetting the BGP session. As a new set of updates is sent during outbound policy reset, a new inbound policy can also take effect.
Table 31-10 lists the advantages and disadvantages hard reset and soft reset.
Beginning in privileged EXEC mode, follow these steps to learn if a BGP peer supports the route refresh capability and to reset the BGP session:
Configuring BGP Decision Attributes
When a BGP speaker receives updates from multiple autonomous systems that describe different paths to the same destination, it must choose the single best path for reaching that destination. When chosen, the selected path is entered into the BGP routing table and propagated to its neighbors. The decision is based on the value of attributes that the update contains and other BGP-configurable factors.
When a BGP peer learns two EBGP paths for a prefix from a neighboring AS, it chooses the best path and inserts that path in the IP routing table. If BGP multipath support is enabled and the EBGP paths are learned from the same neighboring autonomous systems, instead of a single best path, multiple paths are installed in the IP routing table. Then, during packet switching, per-packet or per-destination load balancing is performed among the multiple paths. The maximum-paths router configuration command controls the number of paths allowed.
These factors summarize the order in which BGP evaluates the attributes for choosing the best path:
1. ![]() If the path specifies a next hop that is inaccessible, drop the update. The BGP next-hop attribute, automatically determined by the software, is the IP address of the next hop that is going to be used to reach a destination. For EBGP, this is usually the IP address of the neighbor specified by the neighbor remote-as router configuration command. You can disable next-hop processing by using route maps or the neighbor next-hop-self router configuration command.
If the path specifies a next hop that is inaccessible, drop the update. The BGP next-hop attribute, automatically determined by the software, is the IP address of the next hop that is going to be used to reach a destination. For EBGP, this is usually the IP address of the neighbor specified by the neighbor remote-as router configuration command. You can disable next-hop processing by using route maps or the neighbor next-hop-self router configuration command.
2. ![]() Prefer the path with the largest weight (a Cisco proprietary parameter). The weight attribute is local to the router and not propagated in routing updates. By default, the weight attribute is 32768 for paths that the router originates and zero for other paths. Routes with the largest weight are preferred. You can use access lists, route maps, or the neighbor weight router configuration command to set weights.
Prefer the path with the largest weight (a Cisco proprietary parameter). The weight attribute is local to the router and not propagated in routing updates. By default, the weight attribute is 32768 for paths that the router originates and zero for other paths. Routes with the largest weight are preferred. You can use access lists, route maps, or the neighbor weight router configuration command to set weights.
3. ![]() Prefer the route with the highest local preference. Local preference is part of the routing update and exchanged among routers in the same AS. The default value of the local preference attribute is 100. You can set local preference by using the bgp default local-preference router configuration command or by using a route map.
Prefer the route with the highest local preference. Local preference is part of the routing update and exchanged among routers in the same AS. The default value of the local preference attribute is 100. You can set local preference by using the bgp default local-preference router configuration command or by using a route map.
4. ![]() Prefer the route that was originated by BGP running on the local router.
Prefer the route that was originated by BGP running on the local router.
5. ![]() Prefer the route with the shortest AS path.
Prefer the route with the shortest AS path.
6. ![]() Prefer the route with the lowest origin type. An interior route or IGP is lower than a route learned by EGP, and an EGP-learned route is lower than one of unknown origin or learned in another way.
Prefer the route with the lowest origin type. An interior route or IGP is lower than a route learned by EGP, and an EGP-learned route is lower than one of unknown origin or learned in another way.
7. ![]() Prefer the route with the lowest multi -exit discriminator (MED) metric attribute if the neighboring AS is the same for all routes considered. You can configure the MED by using route maps or by using the default-metric router configuration command. When an update is sent to an IBGP peer, the MED is included.
Prefer the route with the lowest multi -exit discriminator (MED) metric attribute if the neighboring AS is the same for all routes considered. You can configure the MED by using route maps or by using the default-metric router configuration command. When an update is sent to an IBGP peer, the MED is included.
8. ![]() Prefer the external (EBGP) path over the internal (IBGP) path.
Prefer the external (EBGP) path over the internal (IBGP) path.
9. ![]() Prefer the route that can be reached through the closest IGP neighbor (the lowest IGP metric). This means that the router will prefer the shortest internal path within the AS to reach the destination (the shortest path to the BGP next-hop).
Prefer the route that can be reached through the closest IGP neighbor (the lowest IGP metric). This means that the router will prefer the shortest internal path within the AS to reach the destination (the shortest path to the BGP next-hop).
10. ![]() If the following conditions are all true, insert the route for this path into the IP routing table:
If the following conditions are all true, insert the route for this path into the IP routing table:
•![]() Both the best route and this route are external.
Both the best route and this route are external.
•![]() Both the best route and this route are from the same neighboring autonomous system.
Both the best route and this route are from the same neighboring autonomous system.
•![]() maximum-paths is enabled.
maximum-paths is enabled.
11. ![]() If multipath is not enabled, prefer the route with the lowest IP address value for the BGP router ID. The router ID is usually the highest IP address on the router or the loopback (virtual) address, but might be implementation-specific.
If multipath is not enabled, prefer the route with the lowest IP address value for the BGP router ID. The router ID is usually the highest IP address on the router or the loopback (virtual) address, but might be implementation-specific.
Beginning in privileged EXEC mode, follow these steps to configure some decision attributes:
Use the no form of each command to return to the default state.
Configuring BGP Filtering with Route Maps
Within BGP, route maps can be used to control and to modify routing information and to define the conditions by which routes are redistributed between routing domains. See the "Using Route Maps to Redistribute Routing Information" section for more information about route maps. Each route map has a name that identifies the route map (map tag) and an optional sequence number.
Beginning in privileged EXEC mode, follow these steps to use a route map to disable next-hop processing:
Use the no route-map map-tag command to delete the route map. Use the no set ip next-hop ip-address command to re-enable next-hop processing.
Configuring BGP Filtering by Neighbor
You can filter BGP advertisements by using AS-path filters, such as the as-path access-list global configuration command and the neighbor filter-list router configuration command. You can also use access lists with the neighbor distribute-list router configuration command. Distribute-list filters are applied to network numbers. See the "Controlling Advertising and Processing in Routing Updates" section for information about the distribute-list command.
You can use route maps on a per-neighbor basis to filter updates and to modify various attributes. A route map can be applied to either inbound or outbound updates. Only the routes that pass the route map are sent or accepted in updates. On both inbound and outbound updates, matching is supported based on AS path, community, and network numbers. Autonomous system path matching requires the match as-path access-list route-map command, community based matching requires the match community-list route-map command, and network-based matching requires the ip access-list global configuration command.
Beginning in privileged EXEC mode, follow these steps to apply a per-neighbor route map:
Use the no neighbor distribute-list command to remove the access list from the neighbor. Use the no neighbor route-map map-tag router configuration command to remove the route map from the neighbor.
Another method of filtering is to specify an access list filter on both incoming and outbound updates, based on the BGP autonomous system paths. Each filter is an access list based on regular expressions. (Refer to the "Regular Expressions" appendix in the Cisco IOS Dial Services Command Reference for more information on forming regular expressions.) To use this method, define an autonomous system path access list, and apply it to updates to and from particular neighbors.
Beginning in privileged EXEC mode, follow these steps to configure BGP path filtering:
Configuring Prefix Lists for BGP Filtering
You can use prefix lists as an alternative to access lists in many BGP route filtering commands, including the neighbor distribute-list router configuration command. The advantages of using prefix lists include performance improvements in loading and lookup of large lists, incremental update support, easier CLI configuration, and greater flexibility.
Filtering by a prefix list involves matching the prefixes of routes with those listed in the prefix list, as when matching access lists. When there is a match, the route is used. Whether a prefix is permitted or denied is based upon these rules:
•![]() An empty prefix list permits all prefixes.
An empty prefix list permits all prefixes.
•![]() An implicit deny is assumed if a given prefix does not match any entries in a prefix list.
An implicit deny is assumed if a given prefix does not match any entries in a prefix list.
•![]() When multiple entries of a prefix list match a given prefix, the sequence number of a prefix list entry identifies the entry with the lowest sequence number.
When multiple entries of a prefix list match a given prefix, the sequence number of a prefix list entry identifies the entry with the lowest sequence number.
By default, sequence numbers are generated automatically and incremented in units of five. If you disable the automatic generation of sequence numbers, you must specify the sequence number for each entry. You can specify sequence values in any increment. If you specify increments of one, you cannot insert additional entries into the list; if you choose very large increments, you might run out of values.
You do not need to specify a sequence number when removing a configuration entry. Show commands include the sequence numbers in their output.
Before using a prefix list in a command, you must set up the prefix list. Beginning in privileged EXEC mode, follow these steps to create a prefix list or to add an entry to a prefix list:
To delete a prefix list and all of its entries, use the no ip prefix-list list-name global configuration command. To delete an entry from a prefix list, use the no ip prefix-list seq seq-value global configuration command. To disable automatic generation of sequence numbers, use the no ip prefix-list sequence number command; to reenable automatic generation, use the ip prefix-list sequence number command. To clear the hit-count table of prefix list entries, use the clear ip prefix-list privileged EXEC command.
Configuring BGP Community Filtering
One way that BGP controls the distribution of routing information based on the value of the COMMUNITIES attribute. The attribute is a way to groups destinations into communities and to apply routing decisions based on the communities. This method simplifies configuration of a BGP speaker to control distribution of routing information.
A community is a group of destinations that share some common attribute. Each destination can belong to multiple communities. AS administrators can define to which communities a destination belongs. By default, all destinations belong to the general Internet community. The community is identified by the COMMUNITIES attribute, an optional, transitive, global attribute in the numerical range from 1 to 4294967200. These are some predefined, well-known communities:
•![]() internet—Advertise this route to the Internet community. All routers belong to it.
internet—Advertise this route to the Internet community. All routers belong to it.
•![]() no-export—Do not advertise this route to EBGP peers.
no-export—Do not advertise this route to EBGP peers.
•![]() no-advertise—Do not advertise this route to any peer (internal or external).
no-advertise—Do not advertise this route to any peer (internal or external).
•![]() local-as—Do not advertise this route to peers outside the local autonomous system.
local-as—Do not advertise this route to peers outside the local autonomous system.
Based on the community, you can control which routing information to accept, prefer, or distribute to other neighbors. A BGP speaker can set, append, or modify the community of a route when learning, advertising, or redistributing routes. When routes are aggregated, the resulting aggregate has a COMMUNITIES attribute that contains all communities from all the initial routes.
You can use community lists to create groups of communities to use in a match clause of a route map. As with an access list, a series of community lists can be created. Statements are checked until a match is found. As soon as one statement is satisfied, the test is concluded.
To set the COMMUNITIES attribute and match clauses based on communities, see the match community-list and set community route-map configuration commands in the "Using Route Maps to Redistribute Routing Information" section.
By default, no COMMUNITIES attribute is sent to a neighbor. You can specify that the COMMUNITIES attribute be sent to the neighbor at an IP address by using the neighbor send-community router configuration command.
Beginning in privileged EXEC mode, follow these steps to create and to apply a community list:
Configuring BGP Neighbors and Peer Groups
Often many BGP neighbors are configured with the same update policies (that is, the same outbound route maps, distribute lists, filter lists, update source, and so on). Neighbors with the same update policies can be grouped into peer groups to simplify configuration and to make updating more efficient. When you have configured many peers, we recommend this approach.
To configure a BGP peer group, you create the peer group, assign options to the peer group, and add neighbors as peer group members. You configure the peer group by using the neighbor router configuration commands. By default, peer group members inherit all the configuration options of the peer group, including the remote-as (if configured), version, update-source, out-route-map, out-filter-list, out-dist-list, minimum-advertisement-interval, and next-hop-self. All peer group members also inherit changes made to the peer group. Members can also be configured to override the options that do not affect outbound updates.
To assign configuration options to an individual neighbor, specify any of these router configuration commands by using the neighbor IP address. To assign the options to a peer group, specify any of the commands by using the peer group name. You can disable a BGP peer or peer group without removing all the configuration information by using the neighbor shutdown router configuration command.
Beginning in privileged EXEC mode, use these commands to configure BGP peers:
To disable an existing BGP neighbor or neighbor peer group, use the neighbor shutdown router configuration command. To enable a previously existing neighbor or neighbor peer group that had been disabled, use the no neighbor shutdown router configuration command.
Configuring Aggregate Addresses
Classless interdomain routing (CIDR) enables you to create aggregate routes (or supernets) to minimize the size of routing tables. You can configure aggregate routes in BGP either by redistributing an aggregate route into BGP or by creating an aggregate entry in the BGP routing table. An aggregate address is added to the BGP table when there is at least one more specific entry in the BGP table.
Beginning in privileged EXEC mode, use these commands to create an aggregate address in the routing table:
To delete an aggregate entry, use the no aggregate-address address mask router configuration command. To return options to the default values, use the command with keywords.
Configuring Routing Domain Confederations
One way to reduce the IBGP mesh is to divide an autonomous system into multiple subautonomous systems and to group them into a single confederation that appears as a single autonomous system. Each autonomous system is fully meshed within itself and has a few connections to other autonomous systems in the same confederation. Even though the peers in different autonomous systems have EBGP sessions, they exchange routing information as if they were IBGP peers. Specifically, the next hop, MED, and local preference information is preserved. You can then use a single IGP for all of the autonomous systems.
To configure a BGP confederation, you must specify a confederation identifier that acts as the autonomous system number for the group of autonomous systems.
Beginning in privileged EXEC mode, use these commands to configure a BGP confederation:
Configuring BGP Route Reflectors
BGP requires that all of the IBGP speakers be fully meshed. When a router receives a route from an external neighbor, it must advertise it to all internal neighbors. To prevent a routing information loop, all IBPG speakers must be connected. The internal neighbors do not send routes learned from internal neighbors to other internal neighbors.
With route reflectors, all IBGP speakers need not be fully meshed because another method is used to pass learned routes to neighbors. When you configure an internal BGP peer to be a route reflector, it is responsible for passing IBGP learned routes to a set of IBGP neighbors. The internal peers of the route reflector are divided into two groups: client peers and nonclient peers (all the other routers in the autonomous system). A route reflector reflects routes between these two groups. The route reflector and its client peers form a cluster. The nonclient peers must be fully meshed with each other, but the client peers need not be fully meshed. The clients in the cluster do not communicate with IBGP speakers outside their cluster.
When the route reflector receives an advertised route, it takes one of these actions, depending on the neighbor:
•![]() A route from an external BGP speaker is advertised to all clients and nonclient peers.
A route from an external BGP speaker is advertised to all clients and nonclient peers.
•![]() A route from a nonclient peer is advertised to all clients.
A route from a nonclient peer is advertised to all clients.
•![]() A route from a client is advertised to all clients and nonclient peers. Hence, the clients need not be fully meshed.
A route from a client is advertised to all clients and nonclient peers. Hence, the clients need not be fully meshed.
Usually a cluster of clients have a single route reflector, and the cluster is identified by the route reflector router ID. To increase redundancy and to avoid a single point of failure, a cluster might have more than one route reflector. In this case, all route reflectors in the cluster must be configured with the same 4-byte cluster ID so that a route reflector can recognize updates from route reflectors in the same cluster. All the route reflectors serving a cluster should be fully meshed and should have identical sets of client and nonclient peers.
Beginning in privileged EXEC mode, use these commands to configure a route reflector and clients:
Configuring Route Dampening
Route flap dampening is a BGP feature designed to minimize the propagation of flapping routes across an internetwork. A route is considered to be flapping when it is repeatedly available, then unavailable, then available, then unavailable, and so on. When route dampening is enabled, a numeric penalty value is assigned to a route when it flaps. When a route's accumulated penalties reach a configurable limit, BGP suppresses advertisements of the route, even if the route is running. The reuse limit is a configurable value that is compared with the penalty. If the penalty is less than the reuse limit, a suppressed route that is up is advertised again.
Dampening is not applied to routes that are learned by IBGP. This policy prevents the IBGP peers from having a higher penalty for routes external to the AS.
Beginning in privileged EXEC mode, use these commands to configure BGP route dampening:
To disable flap dampening, use the no bgp dampening router configuration command without keywords. To set dampening factors back to the default values, use the no bgp dampening router configuration command with values.
Monitoring and Maintaining BGP
You can remove all contents of a particular cache, table, or database. This might be necessary when the contents of the particular structure have become or are suspected to be invalid.
You can display specific statistics, such as the contents of BGP routing tables, caches, and databases. You can use the information to get resource utilization and solve network problems. You can also display information about node reachability and discover the routing path your device's packets are taking through the network.
Table 31-8 lists the privileged EXEC commands for clearing and displaying BGP. For explanations of the display fields, refer to the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2.
You can also enable the logging of messages generated when a BGP neighbor resets, comes up, or goes down by using the bgp log-neighbor changes router configuration command.
Configuring Protocol-Independent Features
This section describes how to configure IP routing protocol-independent features. These features are available on switches running the SMI or the EMI; except that with the SMI, protocol-related features are available only for RIP. For a complete description of the IP routing protocol-independent commands in this chapter, refer to the "IP Routing Protocol-Independent Commands" chapter of the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2.
This section includes these procedures:
•![]() Configuring Distributed Cisco Express Forwarding
Configuring Distributed Cisco Express Forwarding
•![]() Configuring the Number of Equal-Cost Routing Paths
Configuring the Number of Equal-Cost Routing Paths
•![]() Configuring Static Unicast Routes
Configuring Static Unicast Routes
•![]() Specifying Default Routes and Networks
Specifying Default Routes and Networks
•![]() Using Route Maps to Redistribute Routing Information
Using Route Maps to Redistribute Routing Information
•![]() Configuring Policy-Based Routing
Configuring Policy-Based Routing
•![]() Filtering Routing Information
Filtering Routing Information
Configuring Distributed Cisco Express Forwarding
Cisco Express Forwarding (CEF) is a Layer 3 IP switching technology used to optimize network performance. CEF implements an advanced IP look-up and forwarding algorithm to deliver maximum Layer 3 switching performance. CEF is less CPU-intensive than fast switching route caching, allowing more CPU processing power to be dedicated to packet forwarding. In a Catalyst 3750 switch stack, the hardware uses distributed CEF (dCEF) to achieve Gigabit-speed line rate IP traffic for each switch in the stack. In dynamic networks, fast switching cache entries are frequently invalidated because of routing changes, which can cause traffic to be process switched using the routing table, instead of fast switched using the route cache. CEF and dCEF use the Forwarding Information Base (FIB) lookup table to perform destination-based switching of IP packets.
The two main components in dCEF are the distributed FIB and the distributed adjacency tables.
•![]() The FIB is similar to a routing table or information base and maintains a mirror image of the forwarding information in the IP routing table. When routing or topology changes occur in the network, the IP routing table is updated, and those changes are reflected in the FIB. The FIB maintains next-hop address information based on the information in the IP routing table. Because the FIB contains all known routes that exist in the routing table, CEF eliminates route cache maintenance, is more efficient for switching traffic, and is not affected by traffic patterns.
The FIB is similar to a routing table or information base and maintains a mirror image of the forwarding information in the IP routing table. When routing or topology changes occur in the network, the IP routing table is updated, and those changes are reflected in the FIB. The FIB maintains next-hop address information based on the information in the IP routing table. Because the FIB contains all known routes that exist in the routing table, CEF eliminates route cache maintenance, is more efficient for switching traffic, and is not affected by traffic patterns.
•![]() Nodes in the network are said to be adjacent if they can reach each other with a single hop across a link layer. CEF uses adjacency tables to prepend Layer 2 addressing information. The adjacency table maintains Layer 2 next-hop addresses for all FIB entries.
Nodes in the network are said to be adjacent if they can reach each other with a single hop across a link layer. CEF uses adjacency tables to prepend Layer 2 addressing information. The adjacency table maintains Layer 2 next-hop addresses for all FIB entries.
Distributed CEF is enabled globally by default. If for some reason it is disabled, you can re-enable it by using the ip cef distributed global configuration command.
The default configuration is dCEF enabled on all Layer 3 interfaces.
Beginning in privileged EXEC mode, follow these steps to enable dCEF globally and on an interface in case, if, for some reason, it has been disabled:
Configuring the Number of Equal-Cost Routing Paths
When a router has two or more routes to the same network with the same metrics, these routes can be thought of as having an equal cost. The term parallel path is another way to refer to occurrences of equal-cost routes in a routing table. If a router has two or more equal-cost paths to a network, it can use them concurrently. Parallel paths provide redundancy in case of a circuit failure and also enable a router to load balance packets over the available paths for more efficient use of available bandwidth. Equal-cost routes are supported across switches in a stack.
Although the router automatically learns about and configures equal-cost routes, you can control the maximum number of parallel paths supported by an IP routing protocol in its routing table.
Beginning in privileged EXEC mode, follow these steps to change the maximum number of parallel paths installed in a routing table from the default:
Use the no maximum-paths router configuration command to restore the default value.
Configuring Static Unicast Routes
Static unicast routes are user-defined routes that cause packets moving between a source and a destination to take a specified path. Static routes can be important if the router cannot build a route to a particular destination and are useful for specifying a gateway of last resort to which all unroutable packets are sent.
Beginning in privileged EXEC mode, follow these steps to configure a static route:
Use the no ip route prefix mask {address | interface} global configuration command to remove a static route.
The switch retains static routes until you remove them. However, you can override static routes with dynamic routing information by assigning administrative distance values. Each dynamic routing protocol has a default administrative distance, as listed in Table 31-12. If you want a static route to be overridden by information from a dynamic routing protocol, set the administrative distance of the static route higher than that of the dynamic protocol.
Static routes that point to an interface are advertised through RIP, IGRP, and other dynamic routing protocols, whether or not static redistribute router configuration commands were specified for those routing protocols. These static routes are advertised because static routes that point to an interface are considered in the routing table to be connected and hence lose their static nature. However, if you define a static route to an interface that is not one of the networks defined in a network command, no dynamic routing protocols advertise the route unless a redistribute static command is specified for these protocols.
When an interface goes down, all static routes through that interface are removed from the IP routing table. When the software can no longer find a valid next hop for the address specified as the forwarding router's address in a static route, the static route is also removed from the IP routing table.
Specifying Default Routes and Networks
A router might not be able to learn the routes to all other networks. To provide complete routing capability, you can use some routers as smart routers and give the remaining routers default routes to the smart router. (Smart routers have routing table information for the entire internetwork.) These default routes can be dynamically learned or can be configured in the individual routers. Most dynamic interior routing protocols include a mechanism for causing a smart router to generate dynamic default information that is then forwarded to other routers.
If a router has a directly connected interface to the specified default network, the dynamic routing protocols running on that device generate a default route. In RIP, it advertises the pseudonetwork 0.0.0.0. In IGRP, the network itself is advertised and flagged as an exterior route.
A router that is generating the default for a network also might need a default of its own. One way a router can generate its own default is to specify a static route to the network 0.0.0.0 through the appropriate device.
Beginning in privileged EXEC mode, follow these steps to define a static route to a network as the static default route:
Use the no ip default-network network number global configuration command to remove the route.
When default information is passed through a dynamic routing protocol, no further configuration is required. The system periodically scans its routing table to choose the optimal default network as its default route. In IGRP networks, there might be several candidate networks for the system default. Cisco routers use administrative distance and metric information to set the default route or the gateway of last resort.
If dynamic default information is not being passed to the system, candidates for the default route are specified with the ip default-network global configuration command. If this network appears in the routing table from any source, it is flagged as a possible choice for the default route. If the router has no interface on the default network, but does have a path to it, the network is considered as a possible candidate, and the gateway to the best default path becomes the gateway of last resort.
Using Route Maps to Redistribute Routing Information
The switch can run multiple routing protocols simultaneously, and it can redistribute information from one routing protocol to another. For example, you can instruct the switch to readvertise IGRP-derived routes by using RIP or to readvertise static routes by using IGRP. Redistributing information from one routing protocol to another applies to all supported IP-based routing protocols.
You can also conditionally control the redistribution of routes between routing domains by defining enhanced packet filters or route maps between the two domains. The match and set route-map configuration commands define the condition portion of a route map. The match command specifies that a criterion must be matched; the set command specifies an action to be taken if the routing update meets the conditions defined by the match command. Although redistribution is a protocol-independent feature, some of the match and set route-map configuration commands are specific to a particular protocol.
One or more match commands and one or more set commands follow a route-map command. If there are no match commands, everything matches. If there are no set commands, nothing is done, other than the match. Therefore, you need at least one match or set command.
You can also identify route-map statements as permit or deny. If the statement is marked as a deny, the packets meeting the match criteria are sent back through the normal forwarding channels (destination-based routing). If the statement is marked as permit, set clauses are applied to packets meeting the match criteria. Packets that do not meet the match criteria are forwarded through the normal routing channel.
Note ![]() Although each of Steps 3 through 14 in the following section is optional, you must enter at least one match route-map configuration command and one set route-map configuration command.
Although each of Steps 3 through 14 in the following section is optional, you must enter at least one match route-map configuration command and one set route-map configuration command.
Beginning in privileged EXEC mode, follow these steps to configure a route map for redistribution:
To delete an entry, use the no route-map map tag global configuration command or the no match or no set route-map configuration commands.
You can distribute routes from one routing domain into another and control route distribution.
Beginning in privileged EXEC mode, follow these steps to control route redistribution. Note that the keywords are the same as defined in the previous procedure.
To disable redistribution, use the no form of the commands.
The metrics of one routing protocol do not necessarily translate into the metrics of another. For example, the RIP metric is a hop count, and the IGRP metric is a combination of five qualities. In these situations, an artificial metric is assigned to the redistributed route. Uncontrolled exchanging of routing information between different routing protocols can create routing loops and seriously degrade network operation.
If you have not defined a default redistribution metric that replaces metric conversion, some automatic metric translations occur between routing protocols:
•![]() RIP can automatically redistribute static routes. It assigns static routes a metric of 1 (directly connected).
RIP can automatically redistribute static routes. It assigns static routes a metric of 1 (directly connected).
•![]() IGRP can automatically redistribute static routes and information from other IGRP-routed autonomous systems. IGRP assigns static routes a metric that identifies them as directly connected. It does not change the metrics of routes derived from IGRP updates from other autonomous systems.
IGRP can automatically redistribute static routes and information from other IGRP-routed autonomous systems. IGRP assigns static routes a metric that identifies them as directly connected. It does not change the metrics of routes derived from IGRP updates from other autonomous systems.
•![]() Any protocol can redistribute other routing protocols if a default mode is in effect.
Any protocol can redistribute other routing protocols if a default mode is in effect.
Configuring Policy-Based Routing
You can use policy-based routing (PBR) to configure a defined policy for traffic flows. By using PBR, you can have more control over routing by reducing the reliance on routes derived from routing protocols. PBR can specify and implement routing policies that allow or deny paths based on:
•![]() Identity of a particular end system
Identity of a particular end system
•![]() Application
Application
•![]() Protocol
Protocol
You can use PBR to provide equal-access and source-sensitive routing, routing based on interactive versus batch traffic, or routing based on dedicated links. For example, you could transfer stock records to a corporate office on a high-bandwidth, high-cost link for a short time while transmitting routine application data such as e-mail over a low-bandwidth, low-cost link.
With PBR, you classify traffic using access control lists (ACLs) and then make traffic go through a different path. PBR is applied to incoming packets. All packets received on an interface with PBR enabled are passed through route maps. Based on the criteria defined in the route maps, packets are forwarded (routed) to the appropriate next hop.
•![]() If packets do not match any route map statements, all set clauses are applied.
If packets do not match any route map statements, all set clauses are applied.
•![]() If a statement is marked as deny, packets meeting the match criteria are sent through normal forwarding channels, and destination-based routing is performed.
If a statement is marked as deny, packets meeting the match criteria are sent through normal forwarding channels, and destination-based routing is performed.
•![]() If a statement is marked as permit and the packets do not match any route-map statements, the packets are sent through the normal forwarding channels, and destination-based routing is performed.
If a statement is marked as permit and the packets do not match any route-map statements, the packets are sent through the normal forwarding channels, and destination-based routing is performed.
For more information about configuring route maps, see the "Using Route Maps to Redistribute Routing Information" section.
You can use standard IP ACLs to specify match criteria for a source address or extended IP ACLs to specify match criteria based on an application, a protocol type, or an end station. The process proceeds through the route map until a match is found. If no match is found, or if the route map is a deny, normal destination-based routing occurs. There is an implicit deny at the end of the list of match statements.
If match clauses are satisfied, you can use a set clause to specify the IP addresses identifying the next hop router in the path.
For details about PBR commands and keywords, refer to the Cisco IOS IP Command Reference, Volume 2 of 3: Routing Protocols, Release 12.2. For a list of PBR commands that are visible but not supported by the switch, see "Unsupported Commands in Cisco IOS Release 12.2(18)SE."
PBR configuration is applied to the whole stack, and all switches use the stack master configuration.
PBR Configuration Guidelines
Before configuring PBR, you should be aware of this information:
•![]() To use PBR, you must have the EMI installed on the stack master.
To use PBR, you must have the EMI installed on the stack master.
•![]() Multicast traffic is not policy-routed. PBR applies to only to unicast traffic.
Multicast traffic is not policy-routed. PBR applies to only to unicast traffic.
•![]() You can enable PBR on a routed port or an SVI.
You can enable PBR on a routed port or an SVI.
•![]() You can apply a policy route map to an EtherChannel port channel in Layer 3 mode, but you cannot apply a policy route map to a physical interface that is a member of the EtherChannel. If you try to do so, the command is rejected. When a policy route map is applied to a physical interface, that interface cannot become a member of an EtherChannel.
You can apply a policy route map to an EtherChannel port channel in Layer 3 mode, but you cannot apply a policy route map to a physical interface that is a member of the EtherChannel. If you try to do so, the command is rejected. When a policy route map is applied to a physical interface, that interface cannot become a member of an EtherChannel.
•![]() You can define a maximum of 246 IP policy route maps on the switch stack.
You can define a maximum of 246 IP policy route maps on the switch stack.
•![]() You can define a maximum of 512 access control entries (ACEs) for PBR on the switch stack.
You can define a maximum of 512 access control entries (ACEs) for PBR on the switch stack.
•![]() To use PBR, you must first enable the routing template by using the sdm prefer routing global configuration command. PBR is not supported with the VLAN or default template. For more information on the SDM templates, see "Configuring SDM Templates."
To use PBR, you must first enable the routing template by using the sdm prefer routing global configuration command. PBR is not supported with the VLAN or default template. For more information on the SDM templates, see "Configuring SDM Templates."
•![]() The number of TCAM entries used by PBR depends on the route map itself, the ACLs used, and the order of the ACLs and route-map entries.
The number of TCAM entries used by PBR depends on the route map itself, the ACLs used, and the order of the ACLs and route-map entries.
•![]() Policy-based routing based on packet length, IP precedence and TOS, set interface, set default next hop, or set default interface are not supported. Policy maps with no valid set actions or with set action set to Don't Fragment are not supported.
Policy-based routing based on packet length, IP precedence and TOS, set interface, set default next hop, or set default interface are not supported. Policy maps with no valid set actions or with set action set to Don't Fragment are not supported.
Enabling PBR
By default, PBR is disabled on the switch. To enable PBR, you must create a route map that specifies the match criteria and the resulting action if all of the match clauses are met. Then, you must enable PBR for that route map on an interface. All packets arriving on the specified interface matching the match clauses are subject to PBR.
PBR can be fast-switched or implemented at speeds that do not slow down the switch. Fast-switched PBR supports most match and set commands. PBR must be enabled before you enable fast-switched PBR. Fast-switched PBR is disabled by default.
Packets that are generated by the switch, or local packets, are not normally policy-routed. When you globally enable local PBR on the switch, all packets that originate on the switch are subject to local PBR. Local PBR is disabled by default.
Note ![]() To enable PBR, the stack master must be running the EMI.
To enable PBR, the stack master must be running the EMI.
Beginning in privileged EXEC mode, follow these steps to configure PBR:
Use the no route-map map-tag global configuration command or the no match or no set route-map configuration commands to delete an entry. Use the no ip policy route-map map-tag interface configuration command to disable PBR on an interface. Use the no ip route-cache policy interface configuration command to disable fast-switching PBR. Use the no ip local policy route-map map-tag global configuration command to disable policy-based routing on packets originating on the switch.
Filtering Routing Information
You can filter routing protocol information by performing the tasks described in this section.
Note ![]() When routes are redistributed between OSPF processes, no OSPF metrics are preserved.
When routes are redistributed between OSPF processes, no OSPF metrics are preserved.
Setting Passive Interfaces
To prevent other routers on a local network from dynamically learning about routes, you can use the passive-interface router configuration command to keep routing update messages from being sent through a router interface. When you use this command in the OSPF protocol, the interface address you specify as passive appears as a stub network in the OSPF domain. OSPF routing information is neither sent nor received through the specified router interface.
In networks with many interfaces, to avoid having to manually set them as passive, you can set all interfaces to be passive by default by using the passive-interface default router configuration command and manually setting interfaces where adjacencies are desired.
Beginning in privileged EXEC mode, follow these steps to configure passive interfaces:
Use a network monitoring privileged EXEC command such as show ip ospf interface to verify the interfaces that you enabled as passive, or use the show ip interface privileged EXEC command to verify the interfaces that you enabled as active.
To re-enable the sending of routing updates, use the no passive-interface interface-id router configuration command. The default keyword sets all interfaces as passive by default. You can then configure individual interfaces where you want adjacencies by using the no passive-interface router configuration command. The default keyword is useful in Internet service provider and large enterprise networks where many of the distribution routers have more than 200 interfaces.
Controlling Advertising and Processing in Routing Updates
You can use the distribute-list router configuration command with access control lists to suppress routes from being advertised in routing updates and to prevent other routers from learning one or more routes. When used in OSPF, this feature applies to only external routes, and you cannot specify an interface name.
You can also use a distribute-list router configuration command to avoid processing certain routes listed in incoming updates. (This feature does not apply to OSPF.)
Beginning in privileged EXEC mode, follow these steps to control the advertising or processing of routing updates:
Use the no distribute-list in router configuration command to change or cancel a filter. To cancel suppression of network advertisements in updates, use the no distribute-list out router configuration command.
Filtering Sources of Routing Information
Because some routing information might be more accurate than others, you can use filtering to prioritize information coming from different sources. An administrative distance is a rating of the trustworthiness of a routing information source, such as a router or group of routers. In a large network, some routing protocols can be more reliable than others. By specifying administrative distance values, you enable the router to intelligently discriminate between sources of routing information. The router always picks the route whose routing protocol has the lowest administrative distance. Table 31-12 shows the default administrative distances for various routing information sources.
Because each network has its own requirements, there are no general guidelines for assigning administrative distances.
Beginning in privileged EXEC mode, follow these steps to filter sources of routing information:
To remove a distance definition, use the no distance router configuration command.
Managing Authentication Keys
Key management is a method of controlling authentication keys used by routing protocols. Not all protocols can use key management. Authentication keys are available for EIGRP and RIP Version 2.
Before you manage authentication keys, you must enable authentication. See the appropriate protocol section to see how to enable authentication for that protocol. To manage authentication keys, define a key chain, identify the keys that belong to the key chain, and specify how long each key is valid. Each key has its own key identifier (specified with the key number key chain configuration command), which is stored locally. The combination of the key identifier and the interface associated with the message uniquely identifies the authentication algorithm and Message Digest 5 (MD5) authentication key in use.
You can configure multiple keys with life times. Only one authentication packet is sent, regardless of how many valid keys exist. The software examines the key numbers in order from lowest to highest, and uses the first valid key it encounters. The lifetimes allow for overlap during key changes. Note that the router must know these lifetimes.
Beginning in privileged EXEC mode, follow these steps to manage authentication keys:
To remove the key chain, use the no key chain name-of-chain global configuration command.
Monitoring and Maintaining the IP Network
You can remove all contents of a particular cache, table, or database. You can also display specific statistics. Use the privileged EXEC commands in Table 31-13 to clear routes or display status:
 Feedback
Feedback