إستخدام بيانات التعريف إلى التقرير المخصص مع API و Python
خيارات التنزيل
-
ePub (168.3 KB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المحتويات
المقدمة
يوضح هذا المستند كيفية إستخدام البيانات الأولية بالاقتران مع واجهات برمجة التطبيقات لإعداد تقرير مخصص داخل برنامج نصي للبيثون.
المتطلبات الأساسية
المتطلبات
توصي Cisco بأن تكون لديك معرفة بالمواضيع التالية:
- CloudCenter
- بايثون
المكونات المستخدمة
لا يقتصر هذا المستند على إصدارات برامج ومكونات مادية معينة.
تم إنشاء المعلومات الواردة في هذا المستند من الأجهزة الموجودة في بيئة معملية خاصة. بدأت جميع الأجهزة المُستخدمة في هذا المستند بتكوين ممسوح (افتراضي). إذا كانت شبكتك مباشرة، فتأكد من فهمك للتأثير المحتمل لأي أمر.
معلومات أساسية
يوفر CloudCenter بعض التقارير خارج المربع، ومع ذلك فإنه لا يسمح بطريقة للتقارير استنادا إلى عوامل التصفية المخصصة. من أجل إستخدام واجهات برمجة التطبيقات (API) للحصول على المعلومات مباشرة من قاعدة البيانات، بالإضافة إلى بيانات التعريف المرفقة بالوظائف، يمكنك السماح بالتقارير المخصصة.
إعداد البيانات الأولية
يجب إضافة بيانات التعريف على مستوى كل تطبيق، بحيث يجب تعديل كل تطبيق يجب تتبعه باستخدام التقرير المخصص.
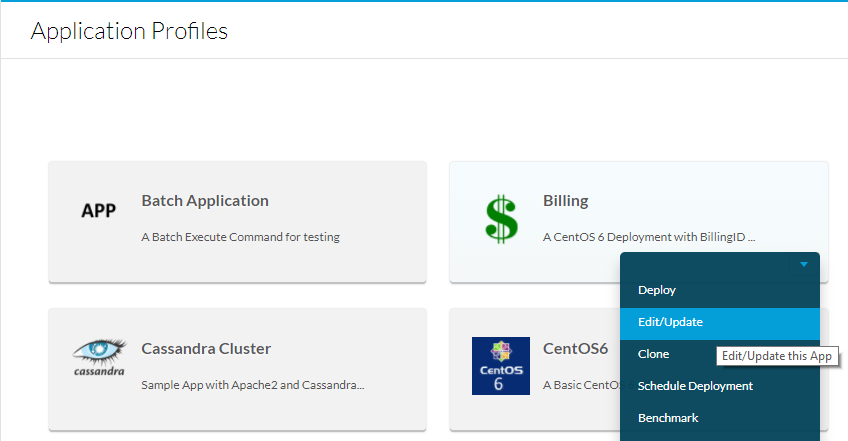
للقيام بذلك، انتقل إلى ملفات تعريف التطبيق، ثم حدد القائمة المنسدلة للتطبيق الذي سيتم تحريره ثم حدد تحرير/تحديث كما هو موضح في الصورة.
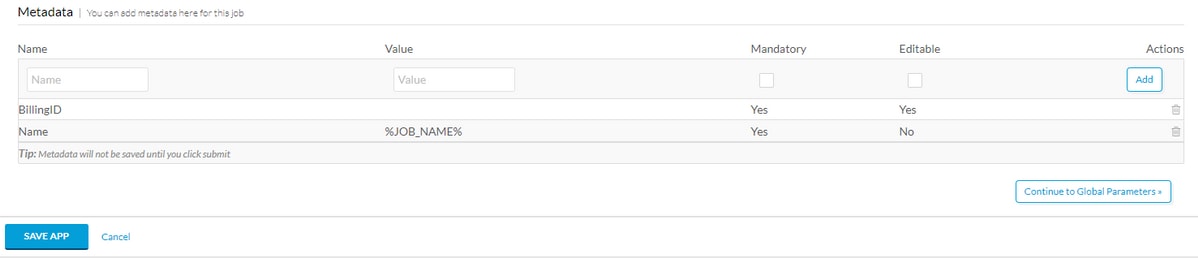
قم بالتمرير إلى أسفل المعلومات الأساسية وأضف علامة تعريف بيانات تعريف، على سبيل المثال BillingID، إذا كان يجب ملء بيانات التعريف هذه بواسطة المسؤول، مما يجعلها إلزامية وقابلة للتحرير. إذا كان مجرد ماكرو، قم بتعبئة القيمة الافتراضية ولا تجعلها قابلة للتحرير. بعد أن تقوم بتعبئة البيانات الأولية، حدد إضافة ثم حفظ تطبيق كما هو موضح في الصورة.
تجميع مفاتيح واجهة برمجة التطبيقات
لمعالجة إستدعاءات واجهة برمجة التطبيقات (API)، يلزم توفر مفاتيح اسم المستخدم وواجهة برمجة التطبيقات (API). توفر هذه المفاتيح نفس مستوى الوصول الخاص بالمستخدم، لذلك إذا كان يجب إضافة جميع عمليات نشر المستخدمين في التقرير، فمن المستحسن الحصول على مسؤول مفاتيح API للمستأجرين. إذا كان سيتم تسجيل مستأجرين فرعيين متعددين معا، إما أن يحتاج المستأجر الجذر إلى الوصول إلى جميع بيئات النشر، أو أن تكون مفاتيح API الخاصة بجميع مسؤولي المستأجرين الفرعيين مطلوبة.
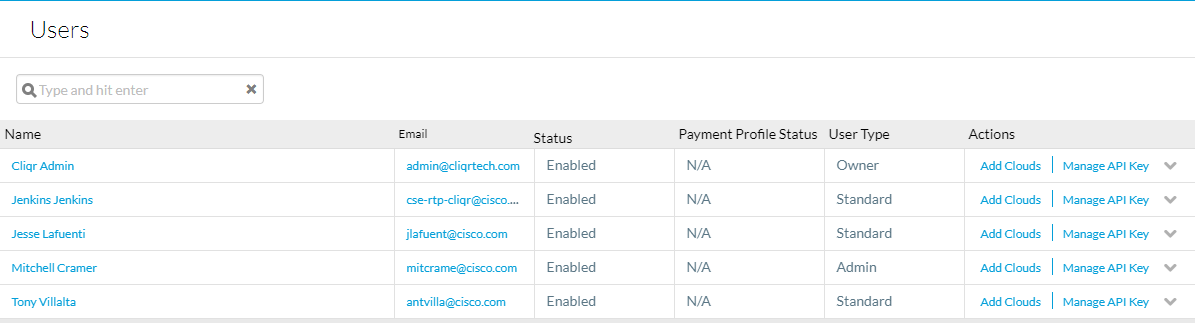
للحصول على مفاتيح واجهة برمجة التطبيقات (API) انتقل إلى Admin > Users > Management API Key، انسخ اسم المستخدم والمفتاح للمستخدمين المطلوبين.
إنشاء تقرير مخصص
قبل أن تقوم بإنشاء برنامج بيثون النصي الذي يقوم بإنشاء التقرير، تأكد من تثبيت بايثون و PIP عليه. بعد ذلك قم بتشغيل تثبيت PIP Tabulate، والجدولة هي مكتبة تقوم بمعالجة تنسيق التقرير تلقائيا.
تم إرفاق تقريرين على عينة من هذا الدليل، حيث يقوم الأول ببساطة بتجميع المعلومات حول جميع عمليات النشر ثم نشرها في جدول. ويستخدم الثاني نفس المعلومات لإنشاء تقرير مخصص باستخدام بيانات تعريف معرف الفوترة. يتم شرح هذا البرنامج النصي بالتفصيل لاستخدامه كدليل.
import datetime import json import sys import requests ##pip install tabulate from tabulate import tabulate from operator import itemgetter from decimal import Decimal
يتم إستخدام datetime لحساب التاريخ بدقة، ويتم هذا لإنشاء تقرير لآخر أيام X.
يتم إستخدام JSON للمساعدة في تحليل بيانات json، ومخرجات مكالمات API.
يستخدم SYS لمكالمات النظام.
يتم إستخدام الطلبات لتبسيط إجراء طلبات ويب لمكالمات API.
يتم إستخدام الجدولة لتنسيق الجدول تلقائيا.
يتم إستخدام ItemGetter كمكرر لفرز جدول ثنائي الأبعاد.
يستخدم الرقم العشري لتقريب التكلفة إلى مكانين عشري.
if(len(sys.argv)==1):
days = -1
elif(len(sys.argv)==2):
try:
days = int(sys.argv[1])
if(days < 1):
raise ValueError('Less than 1')
start=datetime.datetime.now()+datetime.timedelta(days*-1)
except ValueError:
print("Number of days must be an integer greater than 0")
exit()
else:
print("Enter number of days to report on, or leave blank to report all time")
exit()
يتم إستخدام هذا الجزء لتحليل معلمة سطر الأوامر لعدد الأيام.
في حالة عدم وجود معلمات سطر الأوامر (sys.argv ==1)، سيتم إعداد التقارير لكافة الوقت.
إذا كان هناك تحقق واحد من معلمة سطر الأوامر إذا كان العدد الصحيح أكبر من أو يساوي 1، وإذا تم الإبلاغ عنه في هذا العدد من الأيام، إذا لم يكن كذلك، إرجاع خطأ.
في حالة وجود أكثر من معلمة واحدة، يتم إرجاع خطأ.
departments = [] users = ['user1','user2','user3'] passwords = ['user1Key','user2Key','user3Key']
الإدارات هي القائمة التي ستحمل الناتج النهائي.
المستخدمون هي قائمة بجميع المستخدمين الذين سيقومون بإجراء مكالمات API، إذا كان هناك عدة مستأجرين فرعيين سيكون كل مستخدم هو مسؤول مستأجر فرعي مختلف.
كلمات المرور هي قائمة بمفاتيح API الخاصة بالمستخدمين، ويلزم أن يكون ترتيب المستخدمين والمفاتيح مطابقا للمفتاح الصحيح الذي سيتم إستخدامه.
for j in xrange(0,len(users)):
jobs = []
r = requests.get('https://ccm2.cisco.com/v1/jobs', auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data = r.json()
for i in xrange(0,len(data["jobs"])):
test = datetime.datetime.strptime((data["jobs"][i]["startTime"]), '%Y-%m-%d %H:%M:%S.%f')
if(days != -1):
if(start < test):
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
else:
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
for id in jobs:
q = requests.get('https://ccm2.cisco.com/v1/jobs/'+id[0], auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data2 = q.json()
id[2]=round(id[2],2)
for i in xrange(0,len(data2["metadatas"])):
if('BillingID' == data2["metadatas"][i]["name"]):
id[1]=data2["metadatas"][i]["value"]
added=0
for i in xrange(0,len(departments)):
if(departments[i][0]==id[1]):
departments[i][1]+= 1
departments[i][2]+=id[2]
added=1
if(added==0):
departments.append([id[1],1,id[2]])
ل j in xrange(0،len(المستخدمين): هو للحلقة لتكرار كل مستخدم معرف في مجموعة التعليمات البرمجية السابقة، وهذه هي الحلقة الرئيسية التي تعالج جميع إستدعاءات واجهة برمجة التطبيقات.
الوظائف هي قائمة مؤقتة سيتم إستخدامها للاحتفاظ بالمعلومات للوظائف أثناء جمعها في القائمة.
r = طلبات.الحصول على..... هو أول إستدعاء ل API، هذا واحد يسرد جميع الوظائف، لمزيد من المعلومات راجع قائمة الوظائف.
وبعد ذلك يتم تخزين النتائج بتنسيق json في البيانات.
ل i في xrange(0،len(data["jobs"]): يتم تكرارها من خلال كافة المهام التي تم إرجاعها من إستدعاء واجهة برمجة التطبيقات السابقة.
يتم سحب وقت كل مهمة من json وتحويلها إلى كائن datetime، ثم يتم مقارنتها بمعلمة سطر الأوامر التي تم إدخالها لمعرفة ما إذا كانت ضمن الحدود.
إذا كان كذلك، فإن هذه المعلومات من json هي التي يتم إلحاقها بقائمة المهام: id، totalCost، الحالة، الاسم، وقت البدء. لا تستخدم كل هذه المعلومات، ولا كل هذه المعلومات يمكن إرجاعها. تعرض وظائف القائمة كافة المعلومات التي تم إرجاعها والتي يمكن إضافتها بنفس الطريقة.
بعد تكرار كافة المهام التي تم إرجاعها من هذا المستخدم، تنتقل إلى معرف المهام: الذي يتكرر من خلال كافة المهام التي تم تنفيذها بعد التحقق من تاريخ البدء.
q = طلبات.get(..... هو إستدعاء API الثاني، يقوم هذا إستدعاء كل المعلومات المتعلقة بمعرف الوظيفة التي تم الحصول عليها من مكالمة API الأولى. لمزيد من المعلومات، راجع الحصول على تفاصيل الوظيفة.
وبعد ذلك يتم تخزين ملف json في data2.
ويتم تقريب التكلفة، التي يتم تخزينها في المعرف[2] إلى مكانين عشري.
ل i في xrange(0،len(data2["metadatas"]): يكرر خلال كل البيانات الأولية المرتبطة بالوظيفة.
إذا كانت هناك بيانات تعريف تسمى BillingID، يتم تخزينها في معلومات المهمة.
تمت إضافة علامة تستخدم لتحديد ما إذا كان BillingID قد تمت إضافته بالفعل إلى قائمة الأقسام أم لا.
ل i في xrange(0،len(الأقسام)):يتكرر في جميع الأقسام التي تمت إضافتها.
إذا كانت هذه الوظيفة جزء من إدارة موجودة بالفعل، فسيتم تكرار عدد الوظائف بمقدار واحد، وتتم إضافة التكلفة إلى إجمالي التكلفة لهذه الإدارة.
وإذا لم يكن الأمر كذلك، فسيتم إلحاق بند جديد بالأقسام التي يبلغ عدد الوظائف فيها 1 وتكلفة إجمالية تساوي تكلفة هذه الوظيفة الواحدة.
departments = sorted(departments, key=itemgetter(1)) print(tabulate(departments,headers=['Department','Number of Jobs','Total Cost']))
الأقسام = فرز (الأقسام، المفتاح=التصميم (1)) فرز الأقسام حسب عدد الوظائف.
تطبع (جدولة(الأقسام،الرؤوس=['القسم'، 'عدد المهام'، 'التكلفة الإجمالية']) جدولا تم إنشاؤه بواسطة جدولة بثلاثة رؤوس.
معلومات ذات صلة
تمت المساهمة بواسطة مهندسو Cisco
- Jesse Lafuentiمهندس TAC من Cisco
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)