إستبدال اللوحة الأم في خادم Ultra-M UCS 240M4 - CPAR
خيارات التنزيل
-
ePub (3.3 MB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المحتويات
المقدمة
يصف هذا المستند الخطوات المطلوبة لاستبدال اللوحة الأم المعيبة للخادم في إعداد Ultra-M.
ينطبق هذا الإجراء على بيئة OpenStack باستخدام إصدار NewTon حيث لا يقوم ESC بإدارة CPAR ويتم تثبيت CPAR مباشرة على VM الذي تم نشره على OpenStack.
معلومات أساسية
Ultra-M هو حل أساسي لحزم الأجهزة المحمولة تم تجميعه في حزم مسبقا والتحقق من صحته افتراضيا تم تصميمه من أجل تبسيط نشر شبكات VNF. OpenStack هو مدير البنية الأساسية الظاهرية (VIM) ل Ultra-M ويتكون من أنواع العقد التالية:
- حوسبة
- قرص تخزين الكائنات - الحوسبة (OSD - الحوسبة)
- ضابط
- النظام الأساسي OpenStack - المدير (OSPD)
تم توضيح البنية المعمارية عالية المستوى لتقنية Ultra-M والمكونات المعنية في هذه الصورة:
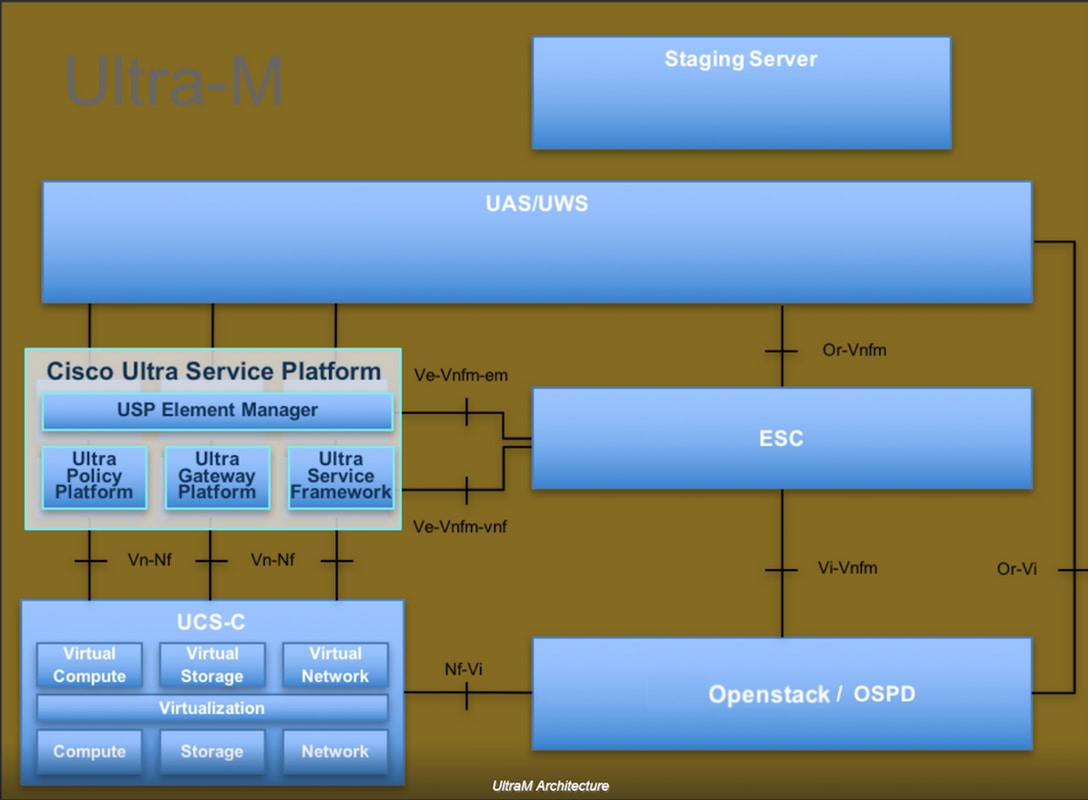
مخصص هذا المستند لأفراد Cisco المطلعين على نظام Cisco Ultra-M الأساسي ويفصل الخطوات المطلوبة لتنفيذها في نظام التشغيل OpenStack و Redhat.
ملاحظة: يتم النظر في الإصدار Ultra M 5.1.x لتحديد الإجراءات الواردة في هذا المستند.
المختصرات
| ممسحة | طريقة إجرائية |
| OSD | أقراص تخزين الكائنات |
| OSPD | مدير النظام الأساسي ل OpenStack |
| محرك الأقراص الثابتة | محرك الأقراص الثابتة |
| محرك أقراص مزود بذاكرة مصنوعة من مكونات صلبة | محرك أقراص في الحالة الصلبة |
| فيم | مدير البنية الأساسية الظاهرية |
| VM | جهاز ظاهري |
| إم | مدير العناصر |
| UAS | خدمات أتمتة Ultra |
| uID | المعرف الفريد العالمي |
سير عمل مذكرة التفاهم

إستبدال اللوحات الأم في إعداد Ultra-M
في الإعداد الفائق متعدد الوظائف، قد تكون هناك سيناريوهات تتطلب إستبدال اللوحة الأم في أنواع الخوادم التالية: الكمبيوتر وحوسبة العناصر التي تعمل بنظام التشغيل OSD ووحدة التحكم.
ملاحظة: يتم إستبدال أقراص التمهيد مع تثبيت OpenStack بعد إستبدال اللوحة الأم. وبالتالي لا يوجد أي متطلبات لإضافة العقدة مرة أخرى إلى السحابة. بمجرد تشغيل الخادم بعد نشاط الاستبدال، فإنه سيقوم بتسجيل نفسه مرة أخرى في مكدس السحابة الزائدة.
المتطلبات الأساسية
قبل إستبدال عقدة حوسبة، من المهم التحقق من الحالة الحالية لبيئة النظام الأساسي Red Hat OpenStack. من المستحسن فحص الحالة الحالية لتجنب المضاعفات عند تشغيل عملية إستبدال الكمبيوتر. ويمكن تحقيقه من خلال هذا التدفق من الاستبدال.
في حالة الاسترداد، توصي Cisco بإجراء نسخ إحتياطي لقاعدة بيانات OSPD باستخدام الخطوات التالية:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
تضمن هذه العملية إمكانية إستبدال عقدة دون التأثير على توفر أي مثيلات.
ملاحظة: تأكد من وجود لقطة للمثيل حتى يمكنك إستعادة الجهاز الظاهري عند الحاجة. اتبع هذا الإجراء للتعرف على كيفية إلتقاط لقطة على الجهاز الظاهري.
إستبدال اللوحات الرئيسية في عقدة الحوسبة
قبل النشاط، يتم إيقاف تشغيل الأجهزة الافتراضية (VM) المستضافة في عقدة "الحوسبة" بشكل جميل. وبمجرد إستبدال اللوحة الأم، تتم إستعادة الأجهزة الافتراضية.
تحديد الأجهزة الافتراضية المستضافة في عقدة الحوسبة
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
ملاحظة: في الإخراج المبين هنا، يتوافق العمود الأول مع المعرف الفريد العالمي (UUID)، بينما يمثل العمود الثاني اسم الجهاز الظاهري (VM) بينما يمثل العمود الثالث اسم المضيف الذي يوجد به الجهاز الظاهري. يتم إستخدام المعلمات من هذا الإخراج في الأقسام التالية.
النسخ الاحتياطي: عملية أخذ اللقطة
الخطوة 1. إيقاف تشغيل تطبيق حماية مستوى التحكم (CPAR).
الخطوة 1.افتح أي عميل SSH متصل بالشبكة واتصل بمثيل حماية مستوى التحكم (CPAR).
من المهم عدم إيقاف تشغيل جميع مثيلات المصادقة والتفويض والمحاسبة (AAA) الأربعة داخل موقع واحد في نفس الوقت، والقيام بذلك بطريقة واحدة.
الخطوة 2.إيقاف تشغيل تطبيق حماية مستوى التحكم (CPAR) باستخدام هذا الأمر:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
إذا ترك مستخدم جلسة CLI مفتوحة، فإن الأمر arserver stop لن يعمل ويتم عرض هذه الرسالة:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
في هذا المثال، يلزم إنهاء معرف العملية 2903 الذي تم تمييزه قبل التمكن من إيقاف حماية مستوى التحكم (CPAR). إذا كان هذا هو الحال، فيرجى إنهاء هذه العملية باستخدام هذا الأمر:
kill -9 *process_id*
ثم كرر الخطوة 1.
الخطوة 3.تحقق من إيقاف تشغيل تطبيق حماية مستوى التحكم (CPAR) بالفعل عن طريق إصدار الأمر:
/opt/CSCOar/bin/arstatus
يجب أن تظهر هذه الرسائل:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
مهمة لقطة VM
الخطوة 1.أدخل موقع واجهة المستخدم الرسومية (GUI) Horizon المطابق للموقع (City) الذي يتم العمل عليه حاليا.
عند الوصول إلى الأفق، يتم ملاحظة هذه الشاشة:

الخطوة 2.انتقل إلى مشروع > مثيلات، كما هو موضح في الصورة.
إذا كان المستخدم يستخدم حماية مستوى التحكم (CPAR)، فلن يظهر في هذه القائمة سوى مثيلات المصادقة والتفويض والمحاسبة (AAA) الأربعة.
الخطوة 3.قم بإيقاف تشغيل مثيل واحد فقط في المرة الواحدة، الرجاء تكرار العملية بأكملها في هذا المستند.
من أجل إيقاف تشغيل VM، انتقل إلى إجراءات > إيقاف تشغيل المثيل وأكد التحديد الخاص بك.

الخطوة 4.تحقق من أن المثيل تم إيقاف تشغيله بالفعل عن طريق التحقق من الحالة = إيقاف التشغيل وحالة الطاقة = إيقاف التشغيل.

تنهي هذه الخطوة عملية إيقاف تشغيل وحدة المعالجة المركزية (CPAR).
لقطة VM
بمجرد توقف أجهزة CPAR VM، يمكن أخذ اللقطات بشكل متوازي، لأنها تنتمي إلى أجهزة كمبيوتر مستقلة.
سيتم إنشاء ملفات QCOW2 الأربعة بالتوازي.
أخذ لقطة لكل مثيل AAA (25 دقيقة -1 ساعة) (25 دقيقة للتواجدات التي تستخدم صورة QCOW كمصدر وساعة للتواجدات التي تستخدم صورة خام كمصدر)
الخطوة 1. تسجيل الدخول إلى أفق OpenStack ل PODGUI.
الخطوة 2. بمجرد تسجيل الدخول، انتقل إلى قسم مشروع > حساب > مثيلات في القائمة العليا وابحث عن مثيلات AAA.

الخطوة 3. انقر فوق الزر إنشاء لقطة لمتابعة إنشاء اللقطة (يلزم تنفيذ ذلك على مثيل AAA المطابق).
الخطوة 4. بمجرد تشغيل اللقطة، انتقل إلى قائمة الصور وتأكد من أن كل شيء ينتهي وأبلغ عن عدم وجود مشاكل.

الخطوة 5. تتمثل الخطوة التالية في تنزيل اللقطة بتنسيق QCOW2 ونقلها إلى كيان بعيد في حالة فقد OSPD أثناء هذه العملية. لتحقيق ذلك، قم بتعريف اللقطة باستخدام قائمة الصور التي تظهر بلمحة عن الأمر هذه على مستوى OSPD.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
الخطوة 6. بمجرد التعرف على اللقطة التي سيتم تنزيلها (في هذه الحالة ستكون اللقطة المعلمة أعلاه باللون الأخضر)، قم بتنزيلها بتنسيق QCOW2 باستخدام الأمر show image-download كما هو موضح هنا.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- يرسل "&" العملية إلى الخلفية. سيستغرق إكمال هذا الإجراء بعض الوقت، وبمجرد تنفيذه، يمكن تحديد موقع الصورة على دليل /tmp.
- عند إرسال العملية إلى الخلفية، في حالة فقد الاتصال، يتم إيقاف العملية أيضا.
- قم بتنفيذ الأمر "disown -h" حتى في حالة فقد اتصال SSH، تستمر العملية في التشغيل والانتهاء على OSPD.
الخطوة 7. بمجرد انتهاء عملية التنزيل، يلزم تنفيذ عملية ضغط حيث قد يتم ملء هذه اللقطة بأصفار بسبب العمليات والمهام والملفات المؤقتة التي يقوم نظام التشغيل بمعالجتها. الأمر الذي سيتم إستخدامه لضغط الملفات هو متغير الشكل.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
وتستغرق هذه العملية بعض الوقت (حوالي 10 إلى 15 دقيقة). وبمجرد الانتهاء، يكون الملف الناتج هو الملف الذي يجب تحويله إلى كيان خارجي كما هو محدد في الخطوة التالية.
يلزم التحقق من تكامل الملف، لتحقيق ذلك، قم بتنفيذ الأمر التالي وابحث عن السمة "corrupt" في نهاية الإخراج الخاص بها.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
لتجنب حدوث مشكلة عند فقد OSPD، يلزم نقل اللقطة التي تم إنشاؤها مؤخرا بتنسيق QCOW2 إلى كيان خارجي. قبل بدء نقل الملف يجب علينا التحقق مما إذا كانت الوجهة بها مساحة كافية على القرص، أستخدم الأمر df -kh" للتحقق من مساحة الذاكرة. نصيحتنا هي نقله إلى موقع آخر OSPD مؤقتا باستخدام SFTP sftproot@x.x.x.x" حيث يمثل x.x.x.x IP الخاص ب OSPD بعيد. لتسريع النقل، يمكن إرسال الوجهة إلى العديد من OSPDs. بنفس الطريقة، يمكننا إستخدام الأمر التالي scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp (حيث x.x.x.x هو IP الخاص ب OSPD عن بعد) لنقل الملف إلى OSPD آخر.
إيقاف تشغيل الطاقة الرشيقة
عقدة إيقاف الطاقة
- لإيقاف تشغيل المثيل: توقف مستعر <INSTANCE_NAME>
- سترى الآن اسم المثيل مع إيقاف تشغيل الحالة.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
استبدل اللوحة الأم
يمكن الرجوع إلى الخطوات لاستبدال اللوحة الأم في خادم UCS C240 M4 من دليل خدمة وتثبيت خادم Cisco UCS C240 M4
- قم بتسجيل الدخول إلى الخادم باستخدام CIMC IP.
- قم بإجراء ترقية BIOS إذا لم تكن البرامج الثابتة متوافقة مع الإصدار الموصى به المستخدم سابقا. تم توضيح خطوات ترقية BIOS هنا: دليل ترقية BIOS للخادم المركب على حامل Cisco UCS C-Series
إستعادة الأجهزة الافتراضية
إسترداد مثيل من خلال Snapshot
عملية الاسترداد
من الممكن إعادة نشر المثيل السابق مع أخذ اللقطة في الخطوات السابقة.
الخطوة 1 [إختياري].في حالة عدم توفر لقطة VM سابقة، قم بالاتصال بعقدة OSPD التي تم فيها إرسال النسخة الاحتياطية وقم بإجراء النسخ الاحتياطي مرة أخرى إلى عقدة OSPD الأصلية الخاصة بها. باستخدام sftproot@x.x.x.x" حيث يمثل x.x.x.x عنوان IP الخاص ب OSPD الأصلي. احفظ ملف اللقطة في دليل /tmp.
الخطوة 2.الاتصال بعقدة OSPD حيث يتم إعادة نشر المثيل.
 مصدر متغيرات البيئة باستخدام هذا الأمر:
مصدر متغيرات البيئة باستخدام هذا الأمر:
# source /home/stack/pod1-stackrc-Core-CPAR
الخطوة 3.لاستخدام اللقطة كصورة ضروري لتحميلها إلى الأفق على هذا النحو. أستخدم الأمر التالي للقيام بذلك.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
ويمكن رؤية العملية في الأفق.

الخطوة 4.في الأفق، انتقل إلى مشروع > مثيلات وانقر على تشغيل المثيل.

الخطوة 5.قم بتعبئة اسم المثيل واختر منطقة التوفر.

الخطوة 6.في صفحة المصدر، أختر الصورة لإنشاء المثيل. في قائمة تحديد مصدر التمهيد حدد الصورة، يتم عرض قائمة بالصور هنا، أختر الصورة التي تم تحميلها مسبقا عند النقر فوق + علامة.
الخطوة 7.في صفحة النكهة، أختر طعم AAA وأنت تنقر فوق + علامة.

الخطوة 8.وأخيرا، انتقل إلى علامة تبويب الشبكة واختر الشبكات التي يحتاجها المثيل عند النقر فوق + علامة. بالنسبة لهذه الحالة، حدد diameter-soutable1 وradius-routable1 وtb1-mgmt.

الخطوة 9. أخيرا، انقر فوق مثيل "التشغيل" لإنشائه. يمكن مراقبة التقدم في الأفق:
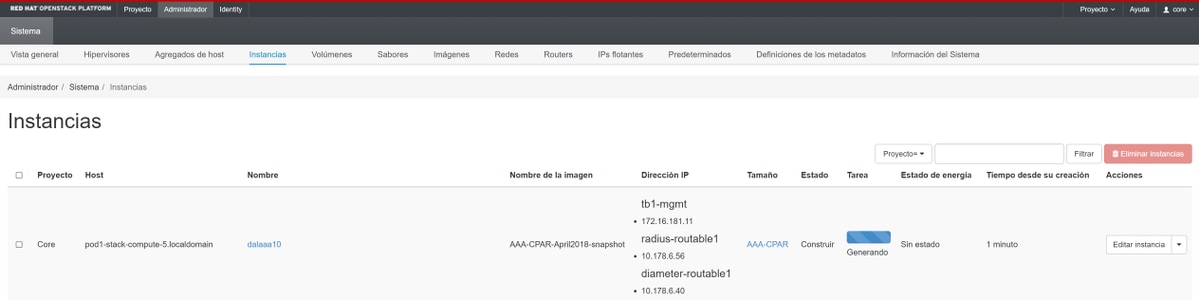
بعد بضع دقائق، يتم نشر المثيل بالكامل وهو جاهز للاستخدام.

إنشاء عنوان IP عائم وتعيينه
عنوان IP العائم هو عنوان قابل للتوجيه، مما يعني أنه يمكن الوصول إليه من خارج بنية Ultra M/OpenStack، وأنه قادر على الاتصال بالعقد الأخرى من الشبكة.
الخطوة 1.في قائمة قمة الأفق، انتقل إلى Admin > عناوين IP المتحركة.
الخطوة 2. انقر فوق ButtonAllocateIP إلى Project.
الخطوة 3. في Allocate IPwindow العائم، حدد المصدر الذي ينتمي إليه IP العائم الجديد، والعرض حيث سيتم تعيينه، وعنوان IP العائم الجديد.
على سبيل المثال:

الخطوة 4.انقر فوق AllocateFloating IPbutton.
الخطوة 5. في قائمة أعلى الأفق، انتقل إلى مشروع > مثيلات.
الخطوة 6.في ActiveColumn انقر فوق السهم الذي يشير إلى أسفل في زر إنشاء SnapShotbutton، يجب عرض قائمة. تحديد خيار IPoption عائم مقترن.
الخطوة 7. حدد عنوان IP العائم المطابق المراد إستخدامه في حقل عناوين IP، واختر واجهة الإدارة المطابقة (eth0) من المثيل الجديد حيث سيتم تعيين IP العائم هذا في المنفذ المراد اقترانه. يرجى الرجوع إلى الصورة التالية كمثال على هذا الإجراء.

الخطوة 8.أخيرا، انقر فوق OnAssociationButton.
تمكين SSH
الخطوة 1.في قائمة أعلى الأفق، انتقل إلى مشروع > مثيلات.
الخطوة 2.انقر فوق اسم المثيل/VM الذي تم إنشاؤه في SectionLunch مثيل جديد.
الخطوة 3. انقر على Consultab. سيعرض هذا الأمر خط قارن من ال VM.
الخطوة 4.بمجرد عرض واجهة سطر الأوامر (CLI)، أدخل بيانات اعتماد تسجيل الدخول المناسبة:
اسم المستخدم:الجذر
كلمة المرور:Cisco123

الخطوة 5.في واجهة سطر الأوامر (CLI)، أدخل الأمر /etc/ssh/ssh_config لتحرير تكوين SSH.
الخطوة 6. بمجرد فتح ملف تكوين SSH، اضغط على تحرير الملف. ثم ابحث عن القسم الموضح أدناه وقم بتغيير السطر الأول من مصادقة كلمة المرور إلى مصادقة كلمة المرور نعم.

الخطوة 7.اضغط على ESCand enter:wq!لحفظ تغييرات ملف sshd_config.
الخطوة 8. قم بتنفيذ إعادة تشغيل CommandService.

الخطوة 9.لاختبار تغييرات تكوين SSH التي تم تطبيقها بشكل صحيح، افتح أي عميل SSH وحاول إنشاء اتصال آمن عن بعد باستخدام IPs العائم الذي تم تعيينه للمثيل (أي 10.145.0.249) وuserRoot.
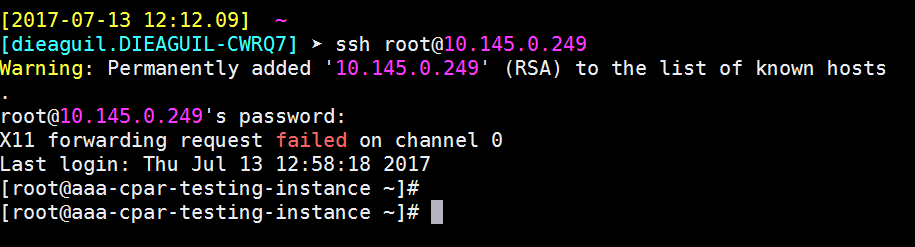
إنشاء جلسة SSH
افتح جلسة SSH باستخدام عنوان IP الخاص ب VM/server المتوافق حيث يتم تثبيت التطبيق.

بدء مثيل CPAR
يرجى اتباع الخطوات التالية بمجرد اكتمال النشاط وإعادة إنشاء خدمات حماية مستوى التحكم في الوصول (CPAR) في الموقع الذي تم إغلاقه.
- للعودة إلى الأفق، انتقل إلى مشروع > مثيل > بدء مثيل.
- تحقق من أن حالة المثيل نشطة وحالة الطاقة قيد التشغيل:
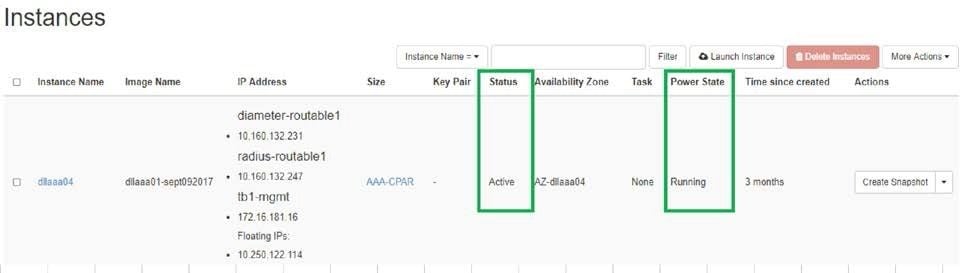
فحص صحة ما بعد النشاط
الخطوة 1.قم بتنفيذ الأمر /opt/ciscoAr/bin/arstatus على مستوى نظام التشغيل.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
الخطوة 2.قم بتنفيذ الأمر /opt/ciscoAr/bin/aCiscomd على مستوى نظام التشغيل وأدخل بيانات اعتماد المسؤول. تحقق من أن حماية حماية وحدة المعالجة المركزية (CPAR) هي 10 من 10 وواجهة سطر الأوامر (CLI) الخاصة بوحدة المعالجة المركزية (CPAR) المخرج.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
الخطوة 3.تشغيل الأمر netstat | قطر الشحم والتحقق من إنشاء جميع إتصالات DRA.
الناتج المذكور أدناه هو لبيئة يتوقع فيها روابط القطر. إذا تم عرض عدد أقل من الارتباطات، فإن ذلك يمثل انفصالا عن DRA الذي يحتاج إلى التحليل.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
الخطوة 4.تأكد من أن سجل TPS يظهر الطلبات التي تتم معالجتها بواسطة CPAR. القيم المبرزة تمثل TPS وتلك هي التي يجب أن نوليها اهتماما.
يجب ألا تتجاوز قيمة TPS 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
الخطوة 5.ابحث عن أي رسائل "خطأ" أو "تنبيه" في name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
الخطوة 6.تحقق من مقدار الذاكرة التي تستخدمها عملية حماية مستوى التحكم (CPAR) من خلال إصدار الأمر التالي:
قمة | نصف قطر GREP
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
يجب أن تكون القيمة المميزة هذه أقل من: 7 جيجابايت، وهو الحد الأقصى المسموح به على مستوى التطبيق.
إستبدال اللوحات الأم في عقدة حوسبة OSD
قبل النشاط، يتم إيقاف تشغيل الأجهزة الظاهرية (VM) المستضافة في عقدة "الحوسبة" بشكل جيد ويتم وضع CEPH في وضع الصيانة. وبمجرد إستبدال اللوحة الأم، تتم إستعادة الأجهزة الافتراضية (VM) ويتم نقل وضع CEPH خارج وضع الصيانة.
تحديد الأجهزة الافتراضية المستضافة في عقدة حوسبة OSD
التعرف على الأجهزة الافتراضية (VM) المستضافة على خادم حوسبة OSD.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0 | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
النسخ الاحتياطي: عملية أخذ اللقطة
إيقاف تشغيل تطبيق CPAR
الخطوة 1.افتح أي عميل SSH متصل بالشبكة واتصل بمثيل حماية مستوى التحكم (CPAR).
من المهم عدم إيقاف تشغيل جميع مثيلات المصادقة والتفويض والمحاسبة (AAA) الأربعة داخل موقع واحد في نفس الوقت، والقيام بذلك بطريقة واحدة.
الخطوة 2.إيقاف تشغيل تطبيق حماية مستوى التحكم (CPAR) باستخدام هذا الأمر:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
ملاحظة: إذا ترك مستخدم جلسة CLI مفتوحة، فلن يعمل الأمر arserver stop وسيتم عرض الرسالة التالية:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
في هذا المثال، يلزم إنهاء معرف العملية 2903 الذي تم تمييزه قبل التمكن من إيقاف حماية مستوى التحكم (CPAR). إذا كان هذا هو الحال، فيرجى إنهاء هذه العملية باستخدام هذا الأمر:
kill -9 *process_id*
ثم كرر الخطوة 1.
الخطوة 3.تحقق من إيقاف تشغيل تطبيق حماية مستوى التحكم (CPAR) بالفعل باستخدام هذا الأمر:
/opt/CSCOar/bin/arstatus
تظهر هذه الرسائل:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
مهمة لقطة VM
الخطوة 1.أدخل موقع واجهة المستخدم الرسومية (GUI) Horizon المطابق للموقع (City) الذي يتم العمل عليه حاليا.
عند الوصول إلى الأفق، تتم ملاحظة الصورة الموضحة:

الخطوة 2. انتقل إلى مشروع > مثيلات، كما هو موضح في الصورة.

إذا كان المستخدم يستخدم حماية مستوى التحكم (CPAR)، فلن يظهر في هذه القائمة سوى مثيلات المصادقة والتفويض والمحاسبة (AAA) الأربعة.
الخطوة 3.قم بإيقاف تشغيل مثيل واحد فقط في المرة الواحدة، الرجاء تكرار العملية بأكملها في هذا المستند.
انتقل إلى إجراءات > إيقاف تشغيل المثيل وأكد التحديد الخاص بك من أجل إيقاف تشغيل VM.

الخطوة 4.تحقق من أن المثيل تم إيقاف تشغيله بالفعل عن طريق التحقق من الحالة = إيقاف التشغيل وحالة الطاقة = إيقاف التشغيل.
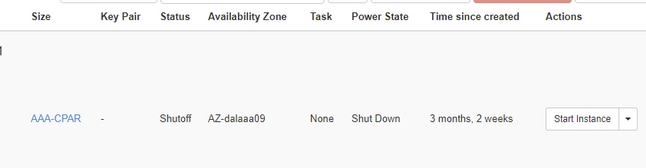
تنهي هذه الخطوة عملية إيقاف تشغيل وحدة المعالجة المركزية (CPAR).
لقطة VM
بمجرد توقف أجهزة CPAR VM، يمكن أخذ اللقطات بشكل متوازي، لأنها تنتمي إلى أجهزة كمبيوتر مستقلة.
يتم إنشاء ملفات QCOW2 الأربعة بالتوازي.
أخذ لقطة لكل مثيل AAA (25 دقيقة -1 ساعة) (25 دقيقة للتواجدات التي تستخدم صورة QCOW كمصدر وساعة للتواجدات التي تستخدم صورة خام كمصدر)
الخطوة 1. تسجيل الدخول إلى واجهة المستخدم الرسومية (GUI) ل OpenStack'POD.
الخطوة 2. بمجرد تسجيل الدخول، انتقل إلى قسم مشروع > حساب > مثيلات في القائمة العليا وابحث عن مثيلات AAA.

الخطوة 3. انقر فوق الزر إنشاء لقطة لمتابعة إنشاء اللقطة (يلزم تنفيذ ذلك على مثيل AAA المطابق).

الخطوة 4. بمجرد تشغيل اللقطة، انتقل إلى قائمة الصور وتأكد من أن كل شيء ينتهي وأبلغ عن عدم وجود مشاكل.
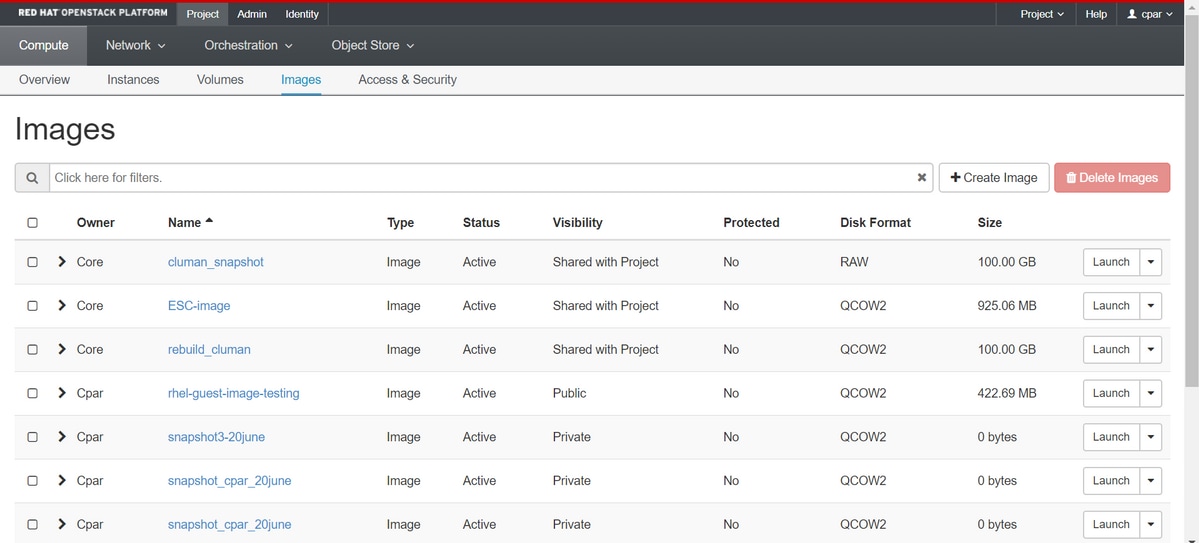
الخطوة 5. تتمثل الخطوة التالية في تنزيل اللقطة بتنسيق QCOW2 ونقلها إلى كيان بعيد في حالة فقد OSPD أثناء هذه العملية. لتحقيق ذلك، قم بتعريف اللقطة باستخدام قائمة الصور التي تظهر بلمحة عن الأمر هذه على مستوى OSPD.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
الخطوة 6. بمجرد التعرف على اللقطة التي سيتم تنزيلها (في هذه الحالة ستكون اللقطة المعلمة أعلاه باللون الأخضر)، قم الآن بتنزيلها على تنسيق QCOW2 باستخدام هذا الأمر show image-download كما هو موضح هنا.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- يرسل "&" العملية إلى الخلفية. سيستغرق إكمال هذا الإجراء بعض الوقت، وبمجرد تنفيذه، يمكن تحديد موقع الصورة على دليل /tmp.
- عند إرسال العملية إلى الخلفية، في حالة فقد الاتصال، يتم إيقاف العملية أيضا.
- قم بتنفيذ الأمر "disown -h" حتى في حالة فقد اتصال SSH، تستمر العملية في التشغيل والانتهاء على OSPD.
7. بمجرد انتهاء عملية التنزيل، يلزم تنفيذ عملية ضغط حيث قد يتم ملء هذه اللقطة بأصفار بسبب العمليات والمهام والملفات المؤقتة التي يعالجها نظام التشغيل. الأمر الذي سيتم إستخدامه لضغط الملفات هو متغير الشكل.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
وتستغرق هذه العملية بعض الوقت (حوالي 10 إلى 15 دقيقة). وبمجرد الانتهاء، يكون الملف الناتج هو الملف الذي يجب تحويله إلى كيان خارجي كما هو محدد في الخطوة التالية.
يلزم التحقق من تكامل الملف، لتحقيق ذلك، قم بتشغيل الأمر التالي وابحث عن السمة "corrupt" في نهاية مخرجها.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
لتجنب حدوث مشكلة عند فقد OSPD، يلزم نقل اللقطة التي تم إنشاؤها مؤخرا بتنسيق QCOW2 إلى كيان خارجي. قبل بدء نقل الملف يجب علينا التحقق مما إذا كانت الوجهة بها مساحة كافية على القرص، أستخدم الأمر df -kh" للتحقق من مساحة الذاكرة. نصيحتنا هي نقله إلى موقع آخر OSPD مؤقتا باستخدام SFTP sftproot@x.x.x.x" حيث يمثل x.x.x.x IP الخاص ب OSPD بعيد. لتسريع النقل، يمكن إرسال الوجهة إلى العديد من OSPDs. بنفس الطريقة، يمكننا إستخدام الأمر التالي scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp (حيث x.x.x.x هو IP الخاص ب OSPD عن بعد) لنقل الملف إلى OSPD آخر.
وضع CEPH في وضع الصيانة
الخطوة 1. التحقق من حالة شجرة الإعداد في الخادم
[heat-admin@pod2-stack-osd-compute-0 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
الخطوة 2. قم بتسجيل الدخول إلى عقدة حوسبة OSD ووضع CEPH في وضع الصيانة.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e79: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v22844323: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3858 kB/s wr, 0 op/s rd, 546 op/s wr
ملاحظة: عند إزالة CEPH، يخضع RAID VNF HD إلى الحالة المخفضة ولكن يجب الوصول إلى القرص الثابت
إيقاف تشغيل الطاقة الرشيقة
عقدة إيقاف الطاقة
- لإيقاف تشغيل المثيل: توقف مستعر <INSTANCE_NAME>
- يمكنك الاطلاع على اسم المثيل مع وضع إيقاف التشغيل.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
استبدل اللوحة الأم
يمكن الرجوع إلى الخطوات لاستبدال اللوحة الأم في خادم UCS C240 M4 من دليل خدمة وتثبيت خادم Cisco UCS C240 M4
- قم بتسجيل الدخول إلى الخادم باستخدام CIMC IP.
- قم بإجراء ترقية BIOS إذا لم تكن البرامج الثابتة متوافقة مع الإصدار الموصى به المستخدم سابقا. تم توضيح خطوات ترقية BIOS هنا: دليل ترقية BIOS للخادم المركب على حامل Cisco UCS C-Series
نقل CEPH خارج وضع الصيانة
قم بتسجيل الدخول إلى عقدة حوسبة OSD وأخرج CEPH من وضع الصيانة.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v22844355: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3658 kB/s wr, 0 op/s rd, 502 op/s wr
إستعادة الأجهزة الافتراضية
إسترداد مثيل من خلال Snapshot
عملية الاسترداد:
من الممكن إعادة نشر المثيل السابق مع أخذ اللقطة في الخطوات السابقة.
الخطوة 1 [إختياري].في حالة عدم توفر لقطة VM سابقة، قم بالاتصال بعقدة OSPD التي تم فيها إرسال النسخة الاحتياطية وقم بإجراء النسخ الاحتياطي مرة أخرى إلى عقدة OSPD الأصلية الخاصة بها. باستخدام sftproot@x.x.x.x" حيث يمثل x.x.x.x عنوان IP الخاص ب OSPD الأصلي. احفظ ملف اللقطة في دليل /tmp.
الخطوة 2.الاتصال بعقدة OSPD حيث يتم إعادة نشر المثيل.

مصدر متغيرات البيئة باستخدام هذا الأمر:
# source /home/stack/pod1-stackrc-Core-CPAR
الخطوة 3.لاستخدام اللقطة كصورة ضروري لتحميلها إلى الأفق على هذا النحو. أستخدم الأمر التالي للقيام بذلك.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
ويمكن رؤية العملية في الأفق.

الخطوة 4.في الأفق، انتقل إلى مشروع > مثيلات وانقر على تشغيل المثيل.

الخطوة 5.قم بتعبئة اسم المثيل واختر منطقة التوفر.
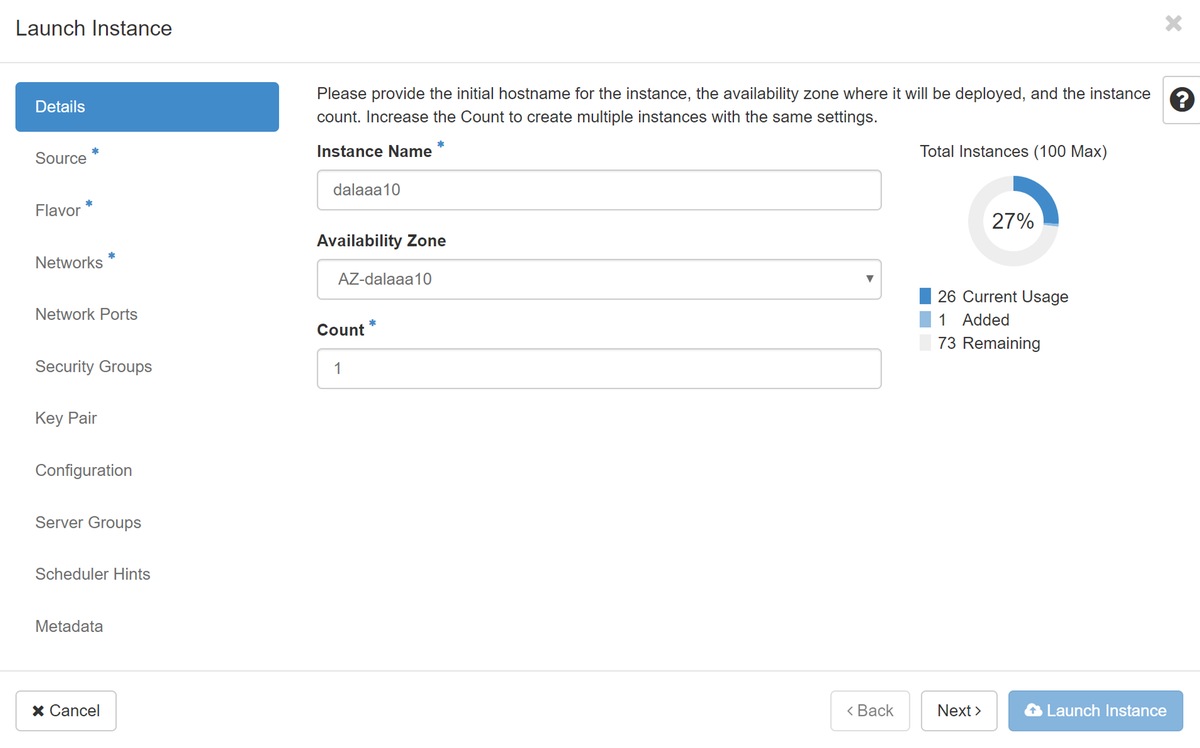
الخطوة 6.في صفحة المصدر، أختر الصورة لإنشاء المثيل. في قائمة تحديد مصدر التمهيد حدد الصورة، يتم عرض قائمة بالصور هنا، أختر الصورة التي تم تحميلها مسبقا عند النقر فوق + علامة.

الخطوة 7.في صفحة النكهة، أختر طعم AAA وأنت تنقر على علامة +.

الخطوة 8.وأخيرا، انتقل إلى علامة تبويب الشبكة واختر الشبكات التي يحتاجها المثيل عند النقر فوق علامة +. بالنسبة لهذه الحالة، حدد diameter-soutable1 وradius-routable1 وtb1-mgmt.

الخطوة 9. أخيرا، انقر فوق مثيل "التشغيل" لإنشائه. يمكن مراقبة التقدم في الأفق:
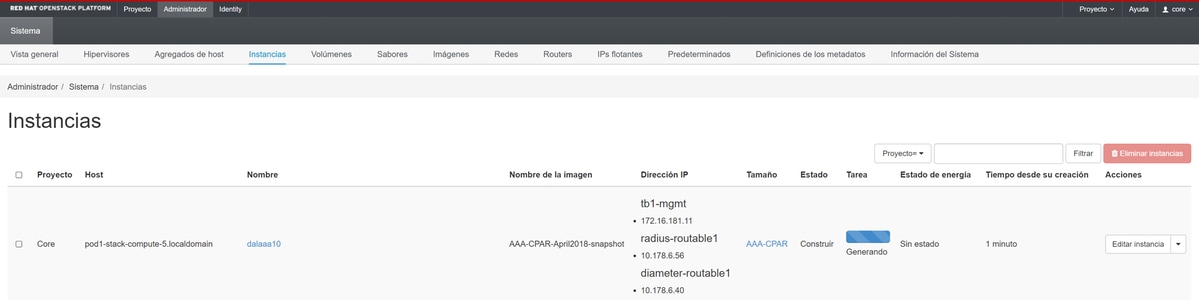
بعد بضع دقائق، يتم نشر المثيل بالكامل وهو جاهز للاستخدام.

إنشاء عنوان IP عائم وتعيينه
عنوان IP العائم هو عنوان قابل للتوجيه، مما يعني أنه يمكن الوصول إليه من خارج بنية Ultra M/OpenStack، وأنه قادر على الاتصال بالعقد الأخرى من الشبكة.
الخطوة 1.في قائمة قمة الأفق، انتقل إلى Admin > عناوين IP المتحركة.
الخطوة 2.انقر فوق ButtonAllocateIP إلى Project.
الخطوة 3. في Allocate IPwindow العائم، حدد المصدر الذي ينتمي إليه IP العائم الجديد، والعرض حيث سيتم تعيينه، وعنوان IP العائم الجديد.
على سبيل المثال:

الخطوة 4.انقر فوق AllocateFloating IPbutton.
الخطوة 5. في قائمة أعلى الأفق، انتقل إلى مشروع > مثيلات.
الخطوة 6. في ActiveColumn انقر فوق السهم الذي يشير إلى أسفل في زر إنشاء SnapShotbutton، يجب عرض قائمة. تحديد خيار IPoption عائم مقترن.
الخطوة 7. حدد عنوان IP العائم المطابق المراد إستخدامه في حقل عناوين IP، واختر واجهة الإدارة المطابقة (eth0) من المثيل الجديد حيث سيتم تعيين IP العائم هذا في المنفذ المراد اقترانه. يرجى الرجوع إلى الصورة التالية كمثال على هذا الإجراء.
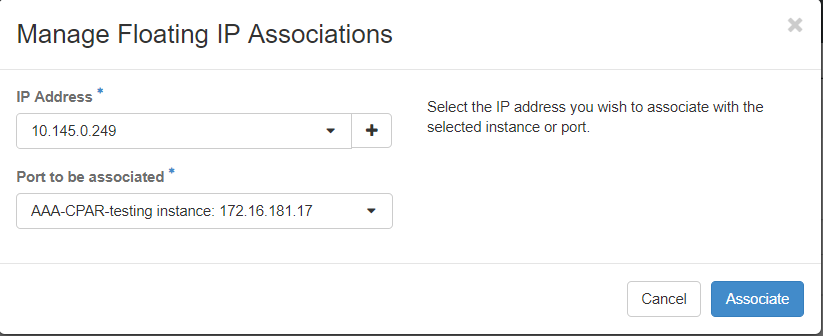
الخطوة 8.أخيرا، انقر على زر الاقتران.
تمكين SSH
الخطوة 1.في قائمة أعلى الأفق، انتقل إلى مشروع > مثيلات.
الخطوة 2.انقر فوق اسم المثيل/VM الذي تم إنشاؤه في SectionLunch مثيل جديد.
الخطوة 3.انقر على Consultab. هذا يعرض CLI من ال VM.
الخطوة 4. بمجرد عرض واجهة سطر الأوامر (CLI)، أدخل بيانات اعتماد تسجيل الدخول المناسبة:
اسم المستخدم:الجذر
كلمة المرور:Cisco123

الخطوة 5.في واجهة سطر الأوامر (CLI)، أدخل الأمر /etc/ssh/ssh_config لتحرير تكوين SSH.
الخطوة 6. بمجرد فتح ملف تكوين SSH، اضغط على تحرير الملف. ثم ابحث عن المقطع الموضح هنا وقم بتغيير السطر الأول من مصادقة كلمة المرور notoPasswordAuthentication نعم.

الخطوة 7.اضغط على ESCand enter:wq!لحفظ تغييرات ملف sshd_config.
الخطوة 8. قم بتشغيل إعادة تشغيل CommandService sshD.

الخطوة 9.لاختبار تغييرات تكوين SSH التي تم تطبيقها بشكل صحيح، افتح أي عميل SSH وحاول إنشاء اتصال آمن عن بعد باستخدام IPs العائم الذي تم تعيينه للمثيل (أي 10.145.0.249) وuserRoot.
إنشاء جلسة SSH
افتح جلسة SSH باستخدام عنوان IP الخاص ب VM/server المتوافق حيث يتم تثبيت التطبيق.

بدء مثيل CPAR
يرجى اتباع هذه الخطوات بمجرد اكتمال النشاط وإعادة إنشاء خدمات حماية مستوى التحكم في الوصول (CPAR) في الموقع الذي تم إغلاقه.
- قم بتسجيل الدخول مرة أخرى إلى الأفق، انتقل إلى مشروع > مثيل > بدء مثيل.
- تحقق من أن حالة المثيل نشطة وحالة الطاقة قيد التشغيل:

فحص صحة ما بعد النشاط
الخطوة 1. قم بتشغيل الأمر /opt/ciscoAr/bin/arstatus على مستوى نظام التشغيل.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
الخطوة 2. قم بتشغيل الأمر /opt/ciscoAr/bin/regcmd على مستوى نظام التشغيل وأدخل بيانات اعتماد المسؤول. تحقق من أن حماية حماية وحدة المعالجة المركزية (CPAR) هي 10 من 10 وواجهة سطر الأوامر (CLI) الخاصة بوحدة المعالجة المركزية (CPAR) المخرج.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
الخطوة 3.قم بتشغيل الأمر netstat | قطر الشحم والتحقق من إنشاء جميع إتصالات DRA.
الناتج المذكور هنا هو لبيئة حيث يتوقع وجود روابط القطر. إذا تم عرض عدد أقل من الارتباطات، فإن ذلك يمثل انفصالا عن DRA الذي يحتاج إلى التحليل.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
الخطوة 4.تأكد من أن سجل TPS يظهر الطلبات التي تتم معالجتها بواسطة CPAR. القيم المبرزة تمثل TPS وتلك هي التي يجب أن نوليها اهتماما.
يجب ألا تتجاوز قيمة TPS 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
الخطوة 5.ابحث عن أي رسائل "خطأ" أو "تنبيه" في name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
الخطوة 6.تحقق من مقدار الذاكرة التي تستخدمها عملية حماية مستوى التحكم (CPAR) مع هذا الأمر:
قمة | نصف قطر GREP
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
يجب أن تكون القيمة المميزة هذه أقل من: 7 جيجابايت، وهو الحد الأقصى المسموح به على مستوى التطبيق.
إستبدال اللوحة الأم في عقدة وحدة التحكم
التحقق من حالة وحدة التحكم ووضع نظام المجموعة في وضع الصيانة
من OSPD، يتم تسجيل الدخول إلى وحدة التحكم والتحقق من أن أجهزة الكمبيوتر في حالة جيدة - جميع وحدات التحكم الثلاثة على الإنترنت وجاليرا توضح وحدات التحكم الثلاثة كرئيسية.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:02:52 2018Last change: Mon Jul 2 12:49:52 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
وضع نظام المجموعة في وضع الصيانة
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:10 2018Last change: Fri Jul 6 09:03:06 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Node pod2-stack-controller-0: standby
Online: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-1 ]
Stopped: [ pod2-stack-controller-0 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
استبدل اللوحة الأم
يمكن الرجوع إلى إجراء إستبدال اللوحة الأم في خادم UCS C240 M4 من دليل خدمة وتثبيت الخادم Cisco UCS C240 M4
- قم بتسجيل الدخول إلى الخادم باستخدام CIMC IP.
- قم بإجراء ترقية BIOS إذا لم تكن البرامج الثابتة متوافقة مع الإصدار الموصى به المستخدم سابقا. تم تقديم خطوات تحديث BIOS هنا:
دليل ترقية BIOS الخاص بالخادم المركب على حامل Cisco UCS C-Series
إستعادة حالة نظام المجموعة
تسجيل الدخول إلى وحدة التحكم المتأثرة، قم بإزالة وضع الاستعداد عن طريق إعداد غير جاهز. تحقق من أن وحدة التحكم تأتي عبر الإنترنت مزودة بنظام المجموعة ويظهر برنامج Galera وحدات التحكم الثلاث جميعها كوحدات تحكم رئيسية. قد يستغرق ذلك بضع دقائق.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:37 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
تمت المساهمة بواسطة مهندسو Cisco
- Karthikeyan Dachanamoorthyالخدمات المتقدمة من Cisco
- Harshita Bhardwajالخدمات المتقدمة من Cisco
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)