المقدمة
يصف هذا المستند إجراء إسترداد "مدير المجموعة" من خادم البدء في إعداد "نظام النشر الأصلي للسحابة" (CNDP).
المتطلبات الأساسية
المتطلبات
توصي Cisco بأن تكون لديك معرفة بالمواضيع التالية:
- البنية الأساسية للخدمات الدقيقة للمشترك (SMI) من Cisco
- البنية المعمارية 5G CNDP أو SMI-Bare-metal (BM)
- جهاز الكتلة الموزع المنسوخ نسخا متماثلا (DRBD)
المكونات المستخدمة
تستند المعلومات الواردة في هذا المستند إلى إصدارات البرامج والمكونات المادية التالية:
- SMI 2020.02.2.35
- Kubernetes v1.21.0
تم إنشاء المعلومات الواردة في هذا المستند من الأجهزة الموجودة في بيئة معملية خاصة. بدأت جميع الأجهزة المُستخدمة في هذا المستند بتكوين ممسوح (افتراضي). إذا كانت شبكتك قيد التشغيل، فتأكد من فهمك للتأثير المحتمل لأي أمر.
معلومات أساسية
ما هو برنامج SMI Cluster Manager؟
مدير نظام المجموعة هو عبارة عن مجموعة ثنائية العقد من keepalive يتم إستخدامها كنقطة أولية لكل من نشر مجموعة مستوى التحكم ومستوى المستخدم. وهو يشغل مجموعة Kubernetes أحادية العقدة ومجموعة من PODs المسؤولة عن إعداد نظام المجموعة بالكامل. مدير نظام المجموعة الأساسي فقط نشط بينما يتولى المدير الثانوي فقط في حالة حدوث عطل أو يتم إسقاطه يدويا لإجراء الصيانة.
ما هو الخادم المبتكر؟
تقوم هذه العقدة بإدارة دورة حياة مدير المجموعة (CM) الذي يقع تحته، ومن هنا يمكنك دفع تكوين اليوم0.
عادة ما يتم نشر هذا الخادم في المنطقة أو في مركز البيانات نفسه مثل وظيفة التهيئة من المستوى الأعلى (على سبيل المثال NSO) ويتم تشغيله عادة كجهاز افتراضي (VM).
المشكلة
تتم إستضافة "مدير نظام المجموعة" في نظام مجموعة مكون من عقدتين مع "جهاز الحظر الموزع المكرر" (DRBD)، كما تتم إضافة هذا الجهاز إلى "مدير نظام المجموعة الأساسي" و"مدير نظام المجموعة الثانوي". في هذه الحالة، ينتقل البرنامج الثانوي لإدارة المجموعة إلى حالة إيقاف التشغيل تلقائيا أثناء تهيئة/تثبيت نظام التشغيل في UCS، مما يشير إلى أن نظام التشغيل تالف.
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 WFConnection Primary/Unknown UpToDate/DUnknown /mnt/stateful_partition ext4 568G 369G 170G 69%
إجراءات الصيانة
تساعد هذه العملية في إعادة تثبيت نظام التشغيل على خادم CM.
تعريف البيئات المضيفة
تسجيل الدخول إلى برنامج Cluster-Manager وتحديد الأجهزة المضيفة:
cloud-user@POD-NAME-cm-primary:~$ cat /etc/hosts | grep 'deployer-cm'
127.X.X.X POD-NAME-cm-primary POD-NAME-cm-primary
X.X.X.X POD-NAME-cm-primary
X.X.X.Y POD-NAME-cm-secondary
التعرف على تفاصيل نظام المجموعة من الخادم الأولي
قم بتسجيل الدخول إلى خادم Start (البدء) وادخل إلى برنامج النشر وتحقق من اسم نظام المجموعة باستخدام Host-IP من برنامج Cluster-Manager.
بعد تسجيل الدخول الناجح إلى خادم البدء، قم بتسجيل الدخول إلى مركز العمليات كما هو موضح هنا.
user@inception-server: ~$ ssh -p 2022 admin@localhost
تحقق من اسم نظام المجموعة من برنامج Cluster Manager SSH-IP (SSH-ip = node SSH ip-address = ucs-server cimc ip address).
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tab
SSH
NAME NAME IP SSH IP IP ADDRESS
------------------------------------------------------------------------------
POD-NAME-deployer cm-primary - X.X.X.X 10.X.X.X ---> Verify Name and SSH IP if Cluster is part of inception server SMI.
cm-secondary - X.X.X.Y 10.X.X.Y
تحقق من تكوين نظام المجموعة الهدف.
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME-deployer
قم بإزالة محرك الأقراص الظاهري لمسح نظام التشغيل من الخادم
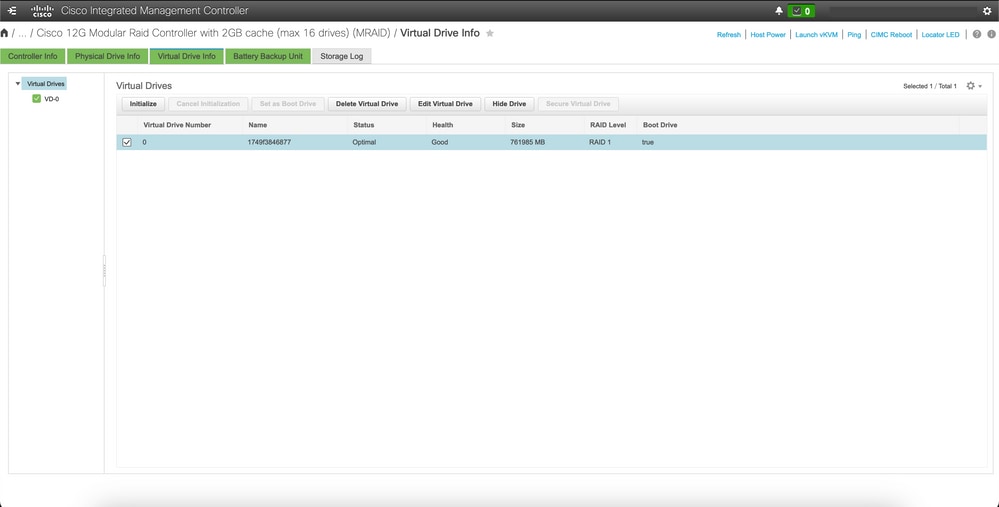
قم بالاتصال بوحدة التحكم في الوصول (CIMC) الخاصة بالمضيف المتضرر وأمسح محرك أقراص التمهيد واحذف محرك الأقراص الظاهري (VD).
a) CIMC > Storage > Cisco 12G Modular Raid Controller > Storage Log > Clear Boot Drive
b) CIMC > Storage > Cisco 12G Modular Raid Controller > Virtual drive > Select the virtual drive > Delete Virtual Drive
تشغيل مزامنة نظام المجموعة
قم بتشغيل مزامنة نظام المجموعة الافتراضية ل Cluster-Manager من الخادم الأصلي.
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
في حالة فشل ميزة مزامنة نظام المجموعة الافتراضية، فعليك تنفيذ خيار مزامنة نظام المجموعة مع إعادة نشر برنامج Force-VM لإكمال عملية إعادة التثبيت (قد يستغرق إكمال نشاط مزامنة نظام المجموعة ما بين 45 إلى 55 دقيقة تقريبا، وهذا يعتمد على عدد العقد المستضافة على نظام المجموعة)
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true force-vm-redeploy true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
مراقبة سجلات مزامنة نظام المجموعة
[inception-server] SMI Cluster Deployer# monitor sync-logs POD-NAME-deployer
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Cluster name: POD-NAME
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Force VM Redeploy: true
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: Force partition Redeploy: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: reset_k8s_nodes: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: purge_data_disks: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: upgrade_strategy: auto
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: sync_phase: all
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: debug: true
...
...
...
تمت إعادة توفير الخادم وتثبيته بواسطة مزامنة نظام المجموعة الناجحة.
PLAY RECAP *********************************************************************
cm-primary : ok=535 changed=250 unreachable=0 failed=0 skipped=832 rescued=0 ignored=0
cm-secondary : ok=299 changed=166 unreachable=0 failed=0 skipped=627 rescued=0 ignored=0
localhost : ok=59 changed=8 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
Thursday 23 February 2023 13:17:24 +0000 (0:00:00.109) 0:56:20.544 *****. ---> ~56 mins to complete cluster sync
===============================================================================
2023-02-23 13:17:24.539 DEBUG cluster_sync.POD-NAME: Cluster sync successful
2023-02-23 13:17:24.546 DEBUG cluster_sync.POD-NAME: Ansible sync done
2023-02-23 13:17:24.546 INFO cluster_sync.POD-NAME: _sync finished. Opening lock
التحقق
تحقق من إمكانية الوصول إلى "إدارة نظام المجموعة المتأثرة"، كما أن نظرة عامة على DRBD لمديري نظام المجموعة الأساسيين والثانويين في حالة UpDate.
cloud-user@POD-NAME-cm-primary:~$ ping X.X.X.Y
PING X.X.X.Y (X.X.X.Y) 56(84) bytes of data.
64 bytes from X.X.X.Y: icmp_seq=1 ttl=64 time=0.221 ms
64 bytes from X.X.X.Y: icmp_seq=2 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=3 ttl=64 time=0.151 ms
64 bytes from X.X.X.Y: icmp_seq=4 ttl=64 time=0.154 ms
64 bytes from X.X.X.Y: icmp_seq=5 ttl=64 time=0.172 ms
64 bytes from X.X.X.Y: icmp_seq=6 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=7 ttl=64 time=0.174 ms
--- X.X.X.Y ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 6150ms
rtt min/avg/max/mdev = 0.151/0.171/0.221/0.026 ms
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 Connected Primary/Secondary UpToDate/UpToDate /mnt/stateful_partition ext4 568G 17G 523G 4%
يتم تثبيت مدير نظام المجموعة المتأثر وإعادة تزويده للشبكة بنجاح.
2. 2 التحقق من اسم نظام المجموعة من برنامج Cluster Manager SSH-IP.
[startup-server] SMI Cluster Deploy# show running-config clusters * العقد * k8s ssh-ip | حدد العقد * ssh-ip | تحديد العقد * عنوان IP الخاص بوحدة التحكم في الوصول للخادم - UCS | علامة تبويب
بروتوكول النقل الآمن (SSH)
عنوان IP الخاص ب SSH للاسم
—
POD-Name cm-primary - 192.x.x.x 10.192.x.x
CM-SECONDARY - 192.X.X.Y 10.192.X.Y
*SSH IP = SSH IP للعقدة
*عنوان IP = عنوان UCS-Server cimc IP
2.3 تحقق من التكوين الخاص بنظام المجموعة الهدف.
show running-config cluster pod-name login إلى الخادم الأصلي ثم أدخل إلى المنشور وتحقق من اسم المجموعة مع المضيف-IP من Cluster-Manager. قم بتسجيل الدخول إلى خادم Start (البدء) وادخل إلى برنامج النشر وتحقق من اسم نظام المجموعة باستخدام برنامج Host-IP من برنامج Cluster-Manager.
 التعليقات
التعليقات