المقدمة
يصف هذا المستند مشاكل مدير تكوين التكرار (RCM) ووظيفة مستوى المستخدم (UPF) التي تتسبب في حالة خادم Essmgr.
المتطلبات الأساسية
المتطلبات
توصي Cisco بأن تكون لديك معرفة بالمواضيع التالية:
المكونات المستخدمة
تستند المعلومات الواردة في هذا المستند إلى إصدارات البرامج والمكونات المادية التالية:
- RCM-checkpointMGR
- UPF-Smgr
تم إنشاء المعلومات الواردة في هذا المستند من الأجهزة الموجودة في بيئة معملية خاصة. بدأت جميع الأجهزة المُستخدمة في هذا المستند بتكوين ممسوح (افتراضي). إذا كانت شبكتك قيد التشغيل، فتأكد من فهمك للتأثير المحتمل لأي أمر.
معلومات أساسية
كما يوفر دليل أستكشاف الأخطاء وإصلاحها مفصلا لمعالجة مشاكل حالة خادم البريد الإلكتروني وتعطيل حركة مرور البيانات ومعالجة المكالمات. بالإضافة إلى قسم إختبار معملي للاسترداد.
نظرة عامة على الأساسيات
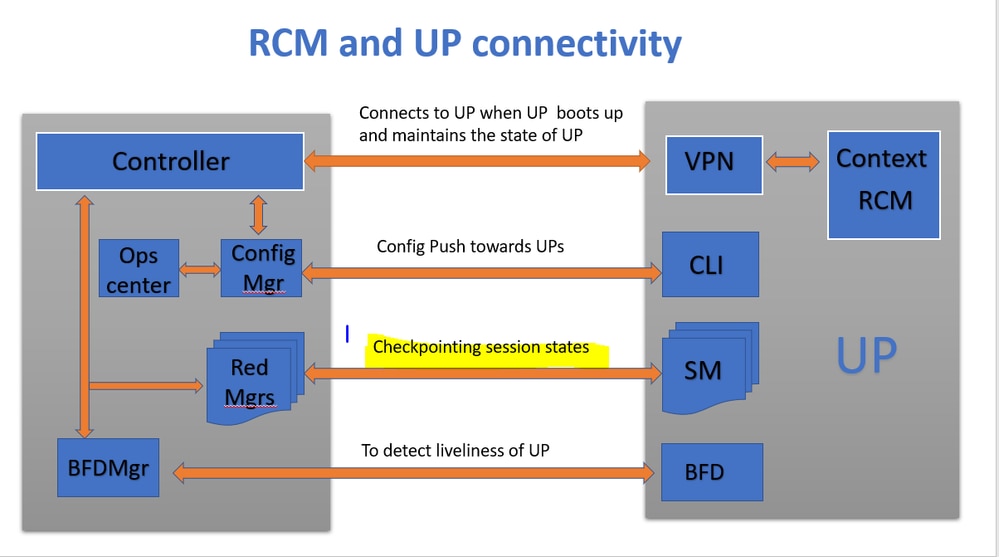
كما هو موضح في الصورة، يمكنك ملاحظة الاتصالات المباشرة بين مديري التكرار (المشار إليها باسم نقاط الفحص) في RCM والجلسات في UPFs لتتبع نقاط التفتيش.
تخطيط REDMGRS و Sesmgrs
1. تحتوي كل نقطة وصول على عدد "N" من الاختبارات.
2- لدى آلية التنسيق الإقليمي عدد من وحدات خفض الانبعاثات المعتمدة على أساس "M" وفقا لعدد الدورات في إطار إستعراض سياسات الاستثمار.
3. لدى كل من REDMGRS و Sesmgrs تخطيط 1:1 استنادا إلى معرفات الأجهزة الخاصة بهم حيث توجد وحدات حمراء منفصلة لكل جلسة.
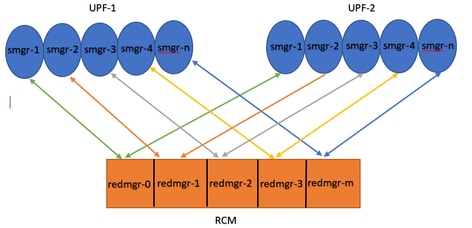
Note :: Redmgr IDs (m) = sessmgr instance ID (n-1)
For example :: smgr-1 is mapped with redmgr 0;smgr-2 is mapped with redmgr-1,
smgr-n is mapped with redmgr(m) = (n-1)
This is important to understand proper IDs of redmgr because we need to have proper logs to be checked
السجلات المطلوبة
سجلات RCM - مخرجات الأوامر:
rcm show-statistics checkpointmgr-endpointstats
RCM controller and checkpointmgr logs (refer this link)
Log collection
UPF:
Command outputs (hidden mode)
show rcm checkpoint statistics verbose
show session subsystem facility sessmgr all debug-info | grep Mode
If you see any sessmgr in server state check the sessmgr instance IDs and no of sessmgr
show task resources facility sessmgr all
استكشاف الأخطاء وإصلاحها
وعادة ما توجد 21 حالة من حالات التعميم في إطار UPF، وهي تتألف من 20 جلسة عمل نشطة وحالة إستعداد واحدة (رغم أن هذا العدد قد يختلف استنادا إلى التصميم المحدد).
مثال:
- لتعريف الجلسات النشطة غير النشطة، يمكنك إستخدام هذا الأمر:
show task resources facility sessmgr all
-
في هذا السيناريو، لا تؤدي محاولة حل المشكلة من خلال إعادة تشغيل جلسات الاختبار الإشكالية وحتى إعادة تشغيل الاختبار إلى إستعادة جلسات العمل المتأثرة.
-
وبالإضافة إلى ذلك، يلاحظ أن البرامج المتأثرة عالقة في وضع الخادم بدلا من وضع العميل المتوقع، وهو شرط يمكن التحقق منه باستخدام الأوامر المتوفرة.
show rcm checkpoint statistics verbose
show rcm checkpoint statistics verbose
Tuesday August 29 16:27:53 IST 2023
smgr state peer recovery pre-alloc chk-point rcvd chk-point sent
inst conn records calls full micro full micro
---- ------- ----- ------- -------- ----- ----- ----- ----
1 Actv Ready 0 0 0 0 61784891 1041542505
2 Actv Ready 0 0 0 0 61593942 1047914230
3 Actv Ready 0 0 0 0 61471304 1031512458
4 Actv Ready 0 0 0 0 57745529 343772730
5 Actv Ready 0 0 0 0 57665041 356249384
6 Actv Ready 0 0 0 0 57722829 353213059
7 Actv Ready 0 0 0 0 61992022 1044821794
8 Actv Ready 0 0 0 0 61463665 1043128178
Here in above command all the connection can be seen as Actv Ready state which is required
show session subsystem facility sessmgr all debug-info | grep Mode
[local]
# show session subsystem facility sessmgr all debug-info | grep Mode
Tuesday August 29 16:28:56 IST 2023
Mode: UNKNOWN State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
وهنا، ينبغي أن تكون جميع جلسات العمل في وضع العميل. مهما، في هذا إصدار، هم في نادل أسلوب، أي يمنعهم من معالجة حركة مرور.
Sesmgr ينتقل إلى وضع الخادم
-
من أجل تسهيل الاتصال ونقل نقاط التفتيش، يقوم كل مدير جلسة (sesmgr) بإنشاء اتصال نظير TCP مع مدير التكرار المقابل (redmgr).
-
بمجرد إنشاء اتصال نظير TCP، يمكن للخادم الأحمر تحديد جميع سياقات المشترك من الخادم وحفظها. وهذا يسمح بالتحويل السلس، حيث يمكن نقل نقاط التفتيش إلى وظائف أخرى لمستوى المستخدم (UPF) مع مثيلات جلسة العمل الخاصة بها.
-
من المهم للغاية أن تكون جلسة العمل دائما في وضع العميل. إذا تم اكتشاف جلسة العمل، لأي سبب من الأسباب، في وضع الخادم، فإنها تشير إلى وجود اتصال نظير TCP معطل مع الأمر redmgr المقترن. في هذا السيناريو، لن يتم الإشارة المرجعية.
-
عندما تعلق الأمر بهذه الحالة داخل UPF، يؤدي إجراء تحويل غير مخطط إلى UPF آخر دون النظر في حالة جلسة العمل إلى نفس المشكلة. تعذر على جلسة العمل معالجة حركة مرور البيانات في هذه الحالة.

ملاحظة: وهناك بعض المسائل التي تنتظر فيها نقاط التحقق نفسها تحديد المكان الذي بدأت فيه آلية التنسيق الإقليمي في وضع إشارة مرجعية وانتظار الرد من الصندوق. ولكن عند عدم وجود نقطة إختيار للاستجابة نفسها لا تكون قادرة على الاتصال مما يؤدي إلى تأخير في إكمال إجراء التحويل الذي يعبر قيمة مؤقت التحويل. حتى في مثل هذه الحالات UP يصبح عالقا في حالة PendActive.
يمكن التحقق من هذا في إحصائيات RCM وسجلات معلومات الإدارة. أيضا، باستخدام هذا الأمر، يمكنك أن تعرف أي نقاط إختيار يوجد به مشكلة مع UPF.
rcm show-statistics checkpointmgr-endpointstats
4. قد تكون هناك أسباب متعددة لتدخل جلسة العمل في وضع الخادم محليا ولكن أحد الأسباب الرئيسية لذلك هو كما هو موضح هنا.
سبب انتقال Sesmgr إلى وضع الخادم
1. استنادا إلى عدد مديري الجلسات في وظيفة مستوى المستخدم (UPF)، يتم إنشاء نسخ طبق الأصل لمدير التكرار (redmgr) وتكوينه في مدير التحكم في الموارد (RCM). يضمن هذا التكوين أن كل redmgr متصل بمثيل مدير جلسة عمل.
2. إذا كان هناك تعيين 1:1 بين redmgr و sesmgr، ماذا يحدث عندما يتجاوز معرف مثيل مدير الجلسة قيمة أعلى من عدد مديري الجلسات؟
For example :::
Sessmgr instance ID :: 1 to 20
Redmgr IDs :: 0 to 19
In this example somehow if my sessmgr instance ID goes beyond the mentioned limit i.e say 21/22/23/24/25 so in this case redmgr is already mapped with instance IDs 0 to 19 and would be unaware about this new sessmgr instance ID created by UPF from 21 to 25 and in such a case sessmgr with this instance IDs :: 21/22/23/24/25 will not be able to form any TCP peer connection with RCM redmgr leading to no checkpoint sync and since there won’t be any checkpoint sync sessmgr will get stuck into server mode and won’t take any traffic.
Refer this diagram
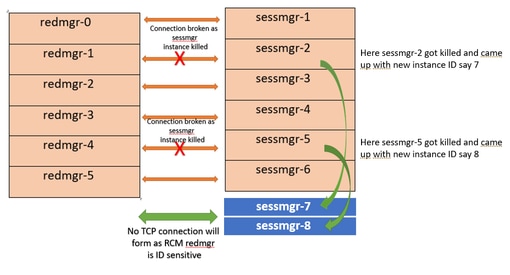
Both this sessmgr instance-7/8 have no TCP peer connection since for RCM redmgr-1 was
connected with instance-2 and redmgr-2 was connected to instance-5 so even though sessmgr
came up with new instance ID value which is beyond defined limit it wont have connection
back with redmgrs which is still just pointing to previous instance but connection is broken
الحل
يكمن الحل لهذه المشكلة في تحديد عدد معرفات مثيل جلسة العمل لمطابقة عدد جلسات العمل في UPF وعدد مرات تكرار الخطوة في RCM، كما هو محدد بواسطة الأمر المذكور.
Max value of sessmgr instance ID = no of checkpointmgr – 1
ووفقا لهذا المنطق، يلزم تحديد عدد الدورات بما في ذلك جلسات الاستعداد.
task facility sessmgr max <no of max sessmgrs>
Note :: Implementation of this command needs node reload to enable full functionality of this command
من خلال تنفيذ هذا الأمر، بغض النظر عن عدد المرات التي يتم فيها قتل المستخدم، فإنه يأتي دائما بقيمة معرف مثيل تساوي أو أقل من الحد الأقصى لعدد الأحرف. وهذا يساعد على منع مشاكل الإشارة المرجعية مع RCM ويمنع المستخدمين من الدخول إلى وضع الخادم لهذا السبب.
 التعليقات
التعليقات