إستبدال OSD-Compute UCS 240M4 - vEPC
خيارات التنزيل
-
ePub (1.3 MB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المحتويات
المقدمة
يصف هذا المستند الخطوات المطلوبة لاستبدال خادم حوسبة قرص تخزين كائنات معيب (OSD) في إعداد Ultra-M يستضيف وظائف الشبكة الظاهرية (VNF) لنظام التشغيل StarOS.
معلومات أساسية
Ultra-M هو حل أساسي لحزم الأجهزة المحمولة تم تجميعه مسبقا والتحقق من صحته افتراضيا تم تصميمه لتبسيط نشر VNFs. OpenStack هو مدير البنية الأساسية الافتراضية (VIM) ل Ultra-M ويتكون من أنواع العقد التالية:
- حوسبة
- OSD - الحوسبة
- ضابط
- النظام الأساسي OpenStack - المدير (OSPD)
يتم توضيح بنية Ultra-M التقنية عالية المستوى والمكونات المعنية في هذه الصورة:
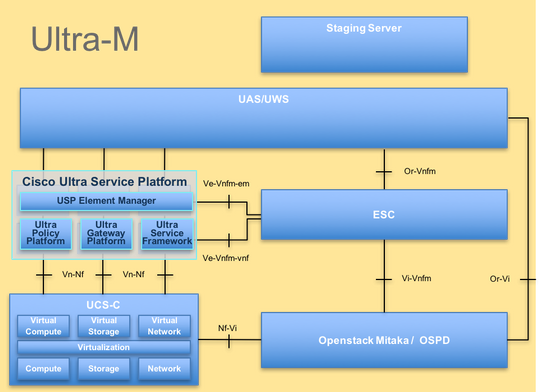
مخصص هذا المستند لأفراد Cisco المطلعين على نظام Cisco Ultra-M الأساسي وهو يفصل الخطوات المطلوبة ليتم تنفيذها على مستوى OpenStack و StarOS VNF في وقت إستبدال خادم الكمبيوتر.
ملاحظة: يتم إعتبار إصدار Ultra M 5.1.x من أجل تحديد الإجراءات الواردة في هذا المستند.
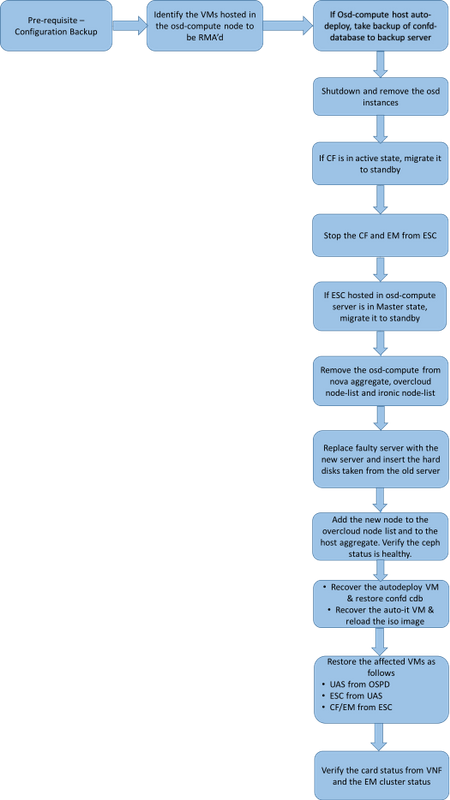
سير عمل مذكرة التفاهم
الاختصارات
| VNF | وظيفة الشبكة الافتراضية |
| CF | وظيفة التحكم |
| SF | وظيفة الخدمة |
| ESC | وحدة التحكم المرنة في الخدمة |
| MOP | طريقة الإجراء |
| OSD | أقراص تخزين الكائنات |
| HDD | محرك الأقراص الثابتة |
| SSD | محرك الأقراص ذو الحالة الصلبة |
| VIM | Virtual Infrastructure Manager |
| VM | الجهاز الافتراضي |
| EM | مدير العناصر |
| UAS | خدمات أتمتة Ultra |
| UUID | المُعرّف الفريد عالميًا |
المتطلبات الأساسية
النسخ الاحتياطي ل OSPD
قبل إستبدال عقدة OSD-Compute، من المهم التحقق من الحالة الحالية لبيئة النظام الأساسي ل Red Hat OpenStack. من المستحسن فحص الحالة الحالية لتجنب المضاعفات عند تشغيل عملية إستبدال الكمبيوتر. ويمكن تحقيقه من خلال هذا التدفق من الاستبدال.
في حالة الاسترداد، توصي Cisco بإجراء نسخ إحتياطي لقاعدة بيانات OSPD (DB) باستخدام الخطوات التالية:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
تضمن هذه العملية إمكانية إستبدال عقدة دون التأثير على توفر أي مثيلات. كما يوصى بإجراء نسخ إحتياطي لتكوين StarOS، خاصة إذا كانت عقدة الكمبيوتر التي سيتم إستبدالها تستضيف جهاز CF VM.
تحديد الأجهزة الافتراضية المستضافة في عقدة OSD-Compute
التعرف على الأجهزة الافتراضية (VM) المستضافة على خادم الحوسبة. وقد يكون هناك إحتمالان:
يحتوي خادم OSD-Compute على مجموعة EM/UAS/Auto-Deployment/Auto-IT من VMs:
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain |
يحتوي خادم الكمبيوتر على مجموعة CF/ESC/EM/UAS من VMs:
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
ملاحظة: في الإخراج المعروض هنا، يتوافق العمود الأول مع UUID، بينما يمثل العمود الثاني اسم معرف فئة المورد (VM) بينما يمثل العمود الثالث اسم المضيف الذي يوجد به الجهاز الظاهري. سيتم إستخدام المعلمات من هذا الإخراج في الأقسام التالية.
تحقق من توفر قدرة CEPH للسماح بإزالة خادم OSD واحد:
[root@pod1-osd-compute-1 ~]# sudo ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
13393G 11804G 1589G 11.87
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 3876G 0
metrics 1 4157M 0.10 3876G 215385
images 2 6731M 0.17 3876G 897
backups 3 0 0 3876G 0
volumes 4 399G 9.34 3876G 102373
vms 5 122G 3.06 3876G 31863
تحقق من تشغيل حالة الشجرة الموجودة على خادم OSD-Compute:
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
تكون عمليات CEPH نشطة على خادم OSD-Compute:
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
قم بتعطيل كل مثيل CEPH وإيقافه وإزالة كل مثيل من OSD وإلغاء تحميل الدليل. كرر لكل مثيل CEPH:
[root@pod1-osd-compute-1 ~]# systemctl disable ceph-osd@11
[root@pod1-osd-compute-1 ~]# systemctl stop ceph-osd@11
[root@pod1-osd-compute-1 ~]# ceph osd out 11
marked out osd.11.
[root@pod1-osd-compute-1 ~]# ceph osd crush remove osd.11
removed item id 11 name 'osd.11' from crush map
[root@pod1-osd-compute-1 ~]# ceph auth del osd.11
updated
[root@pod1-osd-compute-1 ~]# ceph osd rm 11
removed osd.11
[root@pod1-osd-compute-1 ~]# umount /var/lib/ceph.osd/ceph-11
[root@pod1-osd-compute-1 ~]# rm -rf /var/lib/ceph.osd/ceph-11
أو
يمكن إستخدام البرنامج النصي Clean.sh لتنفيذ هذه المهمة:
[heat-admin@pod1-osd-compute-0 ~]$ sudo ls /var/lib/ceph/osd
ceph-11 ceph-3 ceph-6 ceph-8
[heat-admin@pod1-osd-compute-0 ~]$ /bin/sh clean.sh
[heat-admin@pod1-osd-compute-0 ~]$ cat clean.sh
#!/bin/sh
set -x
CEPH=`sudo ls /var/lib/ceph/osd`
for c in $CEPH
do
i=`echo $c |cut -d'-' -f2`
sudo systemctl disable ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo systemctl stop ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd out $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd crush remove osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph auth del osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd rm $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo umount /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
sudo rm -rf /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
done
sudo ceph osd tree
بعد ترحيل/حذف كافة عمليات OSD، يمكن إزالة العقدة من السحابة الزائدة.
ملاحظة: عند إزالة CEPH، سيدخل RAID VNF HD في الحالة المخفضة ولكن يجب الوصول إلى الأقراص HD.
إيقاف تشغيل الطاقة الرشيقة
الحالة 1. تستضيف عقدة OSD-Compute CF/ESC/EM/UAS
ترحيل بطاقة CF إلى حالة الاستعداد
سجل الدخول إلى StarOS VNF وحدد البطاقة التي تطابق CF VM. أستخدم UUID الخاص ب CF VM المحدد من القسم التعرف على الأجهزة الافتراضية (VMs) المستضافة في عقدة OSD-Compute، والعثور على البطاقة التي تطابق UUID.
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
تحقق من حالة البطاقة:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Standby -
2: CFC Control Function Virtual Card Active No
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
إذا كانت البطاقة في الحالة النشطة، فقم بنقل البطاقة إلى حالة الاستعداد:
[local]VNF2# card migrate from 2 to 1
إيقاف تشغيل CF و EM VM من ESC
قم بتسجيل الدخول إلى عقدة ESC التي تتوافق مع VNF وتحقق من حالة الأجهزة الافتراضية (VMs):
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
إيقاف تشغيل CF و EM VM واحدا تلو الآخر باستخدام اسم الأجهزة الافتراضية الخاص به. اسم VM الذي تمت ملاحظته من القسم التعرف على الأجهزة الافتراضية المستضافة في عقدة OSD-Compute.
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
بعد توقفها، يجب أن يدخل VMs حالة إيقاف التشغيل:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
ترحيل ESC إلى وضع الاستعداد
قم بتسجيل الدخول إلى ESC المستضاف في عقدة الكمبيوتر وتحقق مما إذا كان في الحالة الرئيسية. إذا كانت الإجابة بنعم، فقم بتبديل ESC إلى وضع الاستعداد:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
إزالة عقدة OSD-Compute من قائمة تجميع Nova
قم بسرد التجميعات والتعرف على التجميع المطابق لخادم Compute استنادا إلى VNF الذي يستضيفه. وعادة ما يكون بالتنسيق <vnfname>-em-mgmt<x> و<vnfname>-cf-mgmt<x>:
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
في هذه الحالة، ينتمي خادم OSD-Compute إلى VNF2. لذلك، فإن التجميعات التي تتوافق ستكون VNF2-CF-MGMT2 و VNF2-EM-MGMT2.
قم بإزالة عقدة OSD-Compute من التجميع المحدد:
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-CF-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host VNF2-EM-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host POD1-AUTOIT pod1-osd-compute-0.localdomain
تحقق من إزالة عقدة OSD-Compute من التجميعات. الآن، تأكد من أن المضيف غير مدرج ضمن التجميعات:
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOIT
الحالة 2. تستضيف عقدة OSD-Compute النشر التلقائي/Auto-it/EM/UAS
نسخ CDB إحتياطيا للنشر التلقائي
قم بإجراء نسخ إحتياطي لبيانات CDB المشفرة تلقائيا بشكل دوري أو بعد كل عملية تنشيط/إلغاء تنشيط وحفظ الملف إلى خادم نسخ إحتياطي.لا يعد النشر التلقائي زائدا وفي حالة فقدان هذه البيانات، سيكون من الصعب إلغاء تنشيط النشر.
تسجيل الدخول إلى دليل VM الخاص بالنشر التلقائي ودليل CDB المضمن للنسخ الاحتياطي:
ubuntu@auto-deploy-iso-2007-uas-0:~$sudo -i
root@auto-deploy-iso-2007-uas-0:~#service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:~# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd#tar cvf autodeploy_cdb_backup.tar cdb/
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0:~# service uas-confd start
uas-confd start/running, process 13852
ملاحظة: انسخ autodeploy_cdb_backup.tar إلى خادم النسخ الاحتياطي.
النسخ الاحتياطي للنظام.cfg من Auto-IT
قم بإجراء النسخ الاحتياطي لملف system.cfg إلى خادم النسخ الاحتياطي:
Auto-it = 10.1.1.2
Backup server = 10.2.2.2
[stack@director ~]$ ssh ubuntu@10.1.1.2
ubuntu@10.1.1.2's password:
Welcome to Ubuntu 14.04.3 LTS (GNU/Linux 3.13.0-76-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Wed Jun 13 16:21:34 UTC 2018
System load: 0.02 Processes: 87
Usage of /: 15.1% of 78.71GB Users logged in: 0
Memory usage: 13% IP address for eth0: 172.16.182.4
Swap usage: 0%
Graph this data and manage this system at:
https://landscape.canonical.com/
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Cisco Ultra Services Platform (USP)
Build Date: Wed Feb 14 12:58:22 EST 2018
Description: UAS build assemble-uas#1891
sha1: bf02ced
ubuntu@auto-it-vnf-uas-0:~$ scp -r /opt/cisco/usp/uploads/system.cfg root@10.2.2.2:/home/stack
root@10.2.2.2's password:
system.cfg 100% 565 0.6KB/s 00:00
ubuntu@auto-it-vnf-uas-0:~$
ملاحظة: تكون الإجراءات التي يتعين القيام بها لإيقاف تشغيل بنية/وحدات تخزين متصلة بالشبكة (EM/UAS) على نظام OSD-Compute-0 هي نفسها في كلتا الحالتين. ارجع إلى الحالة.1 للحصول على نفس الإجراء.
حذف عقدة OSD-Compute
الخطوات المذكورة في هذا القسم شائعة بغض النظر عن الأجهزة الافتراضية (VMs) المستضافة في عقدة الحوسبة.
حذف عقدة OSD-Compute من قائمة الخدمات
حذف خدمة الحوسبة من قائمة الخدمات:
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep osd-compute-0
| 404 | nova-compute | pod1-osd-compute-0.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
حذف عوامل النترونات
احذف عامل النترونات القديم المرتبط وعامل Open vSwitch الخاص بخادم الحوسبة:
[stack@director ~]$ openstack network agent list | grep osd-compute-0
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
حذف من قاعدة بيانات Nova و Ironic
احذف عقدة من قائمة نوفا وقاعدة البيانات المفارقة وتحقق منها:
[stack@director ~]$ source stackrc
[stack@al01-pod1-ospd ~]$ nova list | grep osd-compute-0
| c2cfa4d6-9c88-4ba0-9970-857d1a18d02c | pod1-osd-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.114 |
[stack@al01-pod1-ospd ~]$ nova delete c2cfa4d6-9c88-4ba0-9970-857d1a18d02c
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-osd-compute-0 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
حذف من Overcloud
قم بإنشاء ملف برنامج نصي باسم delete_node.sh بالمحتويات كما هو موضح. تأكد من أن القوالب المذكورة هي نفس القوالب المستخدمة في البرنامج النصي deploy.sh المستخدم لنشر المكدس:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
انتظر عملية مكدس OpenStack لنقلها إلى حالة الاكتمال:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------
تثبيت عقدة الحوسبة الجديدة
- يمكن الرجوع إلى خطوات الإعداد الأولية لتثبيت خادم UCS C240 M4 جديد من:
دليل خدمة وتثبيت الخادم Cisco UCS C240 M4
- بعد تثبيت الخادم، قم بإدراج الأقراص الثابتة في الفتحات المعنية على أنها الخادم القديم
- تسجيل الدخول إلى الخادم باستخدام CIMC IP
- قم بإجراء ترقية BIOS إذا لم تكن البرامج الثابتة متوافقة مع الإصدار الموصى به المستخدم سابقا. تم تقديم خطوات تحديث BIOS هنا:
دليل ترقية BIOS الخاص بالخادم المركب على حامل Cisco UCS C-Series
- تحقق من حالة محركات الأقراص المادية. يجب أن يكون جيدا غير مقصور
- إنشاء محرك أقراص ظاهري من محركات الأقراص المادية باستخدام RAID المستوى 1
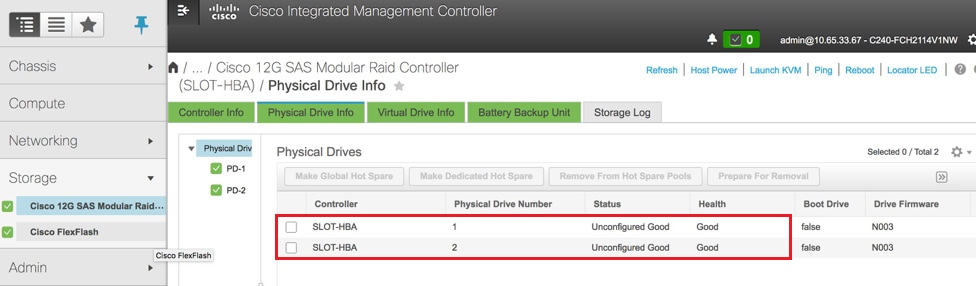 وحدة التخزين > وحدة التحكم RAID النمطية Cisco 12G SAS (slot-HBA) > معلومات محرك الأقراص المادية
وحدة التخزين > وحدة التحكم RAID النمطية Cisco 12G SAS (slot-HBA) > معلومات محرك الأقراص المادية
ملاحظة: هذه الصورة للتوضيح فقط، في CIMC الفعلية التي تعمل بنظام التشغيل OSD-Compute، سترى سبعة محركات أقراص مادية في الفتحات (1،2،3،7،8،9،10) في حالة جيدة غير مكونة حيث لا يتم إنشاء محركات أقراص افتراضية منها.
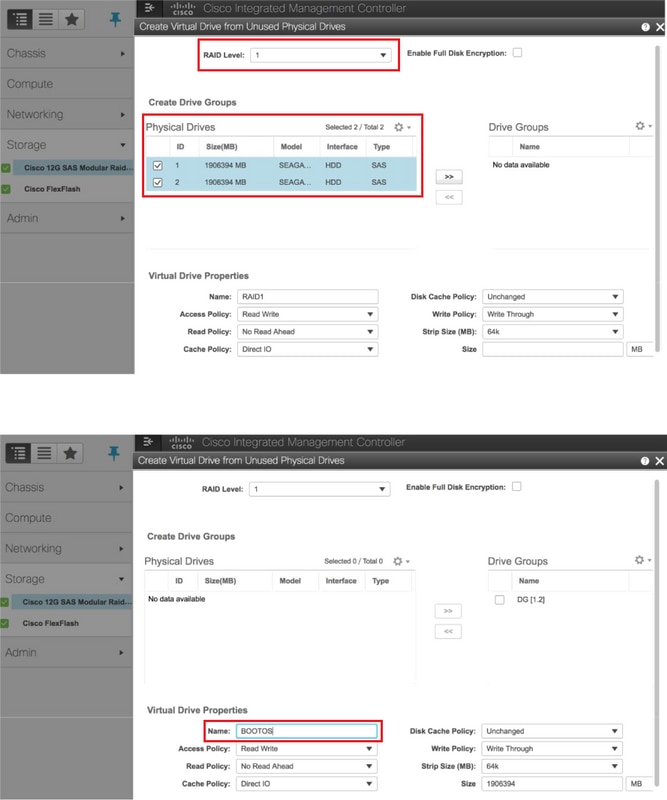 وحدة التحكم > Cisco 12G SAS القابلة لإضافة وحدات أخرى بوحدة التحكم RAID (slot-HBA) > معلومات وحدة التحكم > إنشاء محرك أقراص ظاهري من محركات الأقراص المادية غير المستخدمة
وحدة التحكم > Cisco 12G SAS القابلة لإضافة وحدات أخرى بوحدة التحكم RAID (slot-HBA) > معلومات وحدة التحكم > إنشاء محرك أقراص ظاهري من محركات الأقراص المادية غير المستخدمة
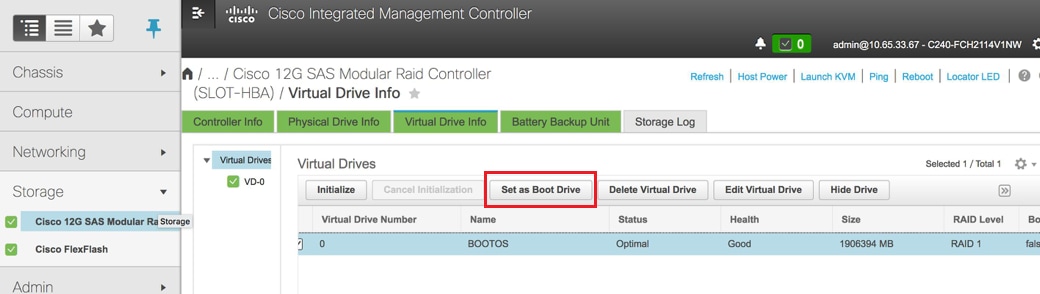 حدد معرف فئة المورد (VD) وقم بتكوين "تعيين كمحرك أقراص تمهيد"
حدد معرف فئة المورد (VD) وقم بتكوين "تعيين كمحرك أقراص تمهيد"
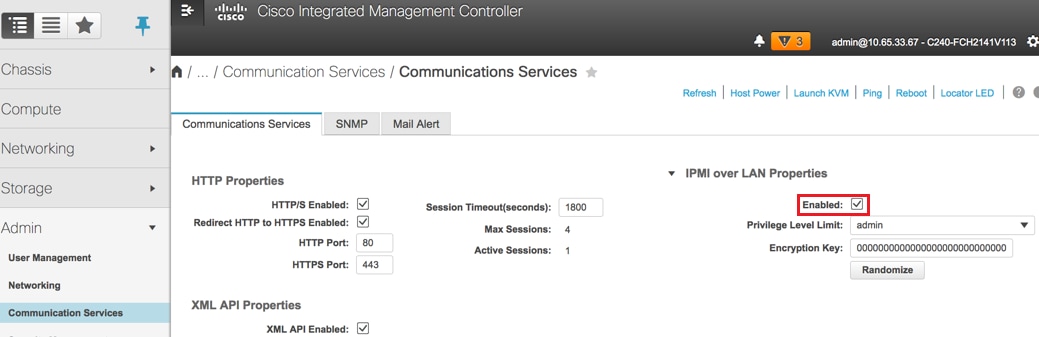 تمكين IPMI عبر LAN: إدارة > خدمات الاتصالات > خدمات الاتصالات
تمكين IPMI عبر LAN: إدارة > خدمات الاتصالات > خدمات الاتصالات
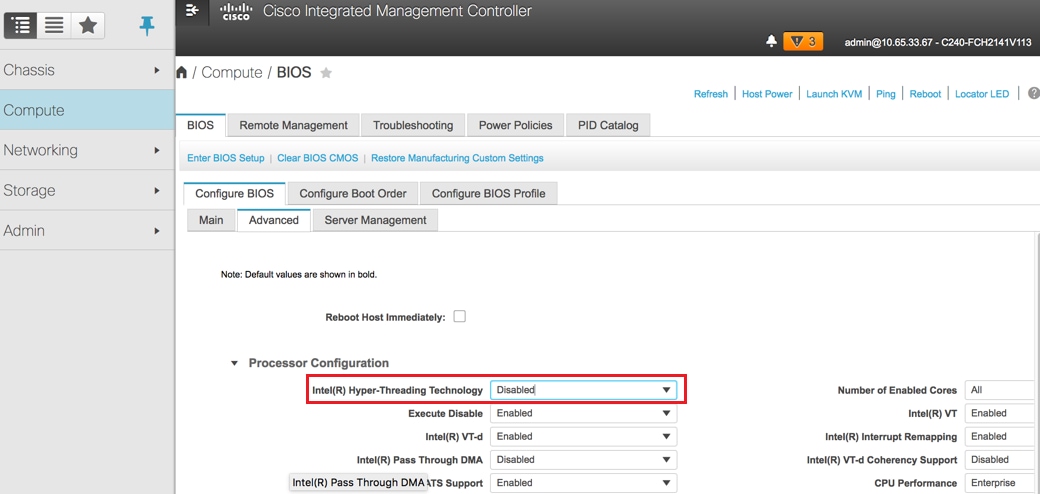 تعطيل الارتباط التشعبي: حوسبة > BIOS > تكوين BIOS > متقدم > تهيئة المعالج
تعطيل الارتباط التشعبي: حوسبة > BIOS > تكوين BIOS > متقدم > تهيئة المعالج
- على غرار BOOTOS VD الذي تم إنشاؤه باستخدام محركي الأقراص المادية 1 و 2، يمكنك إنشاء أربعة محركات أقراص افتراضية أخرى ك
دفتر اليومية > من محرك الأقراص الفعلي رقم 3
OSD1 > من محرك الأقراص الفعلي رقم 7
OSD2 > من محرك الأقراص الفعلي رقم 8
OSD3 > من محرك الأقراص الفعلي رقم 9
OSD4 > من رقم محرك الأقراص الفعلي 10 - وفي النهاية، يجب أن تكون محركات الأقراص المادية ومحركات الأقراص الافتراضية متماثلة كما هو موضح في الصورة:
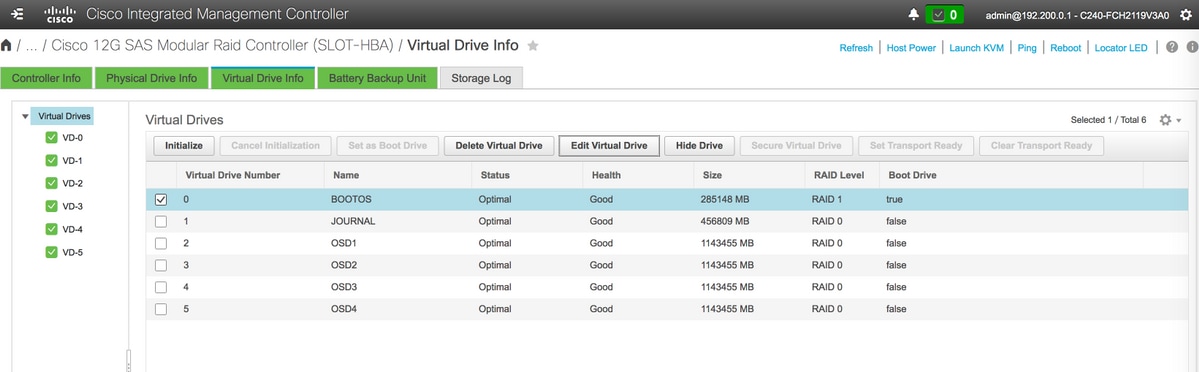 محركات الأقراص الظاهرية
محركات الأقراص الظاهرية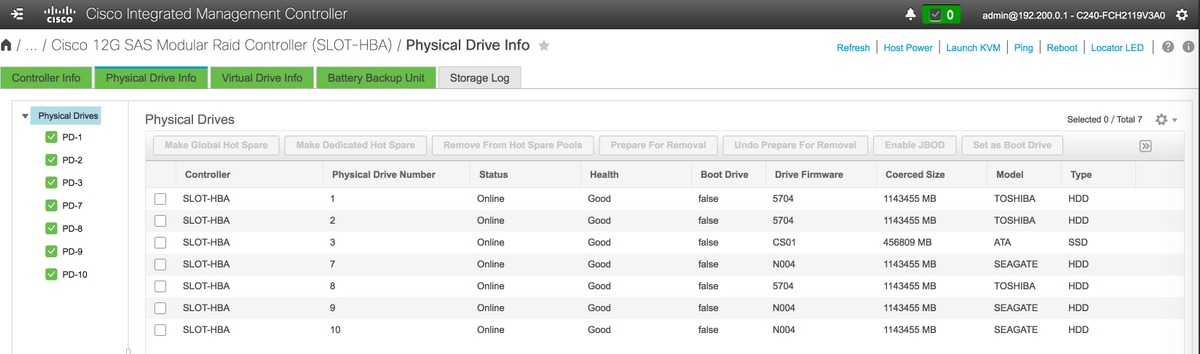 محركات الأقراص الفيزيائية
محركات الأقراص الفيزيائية
ملاحظة: تشير الصورة الموضحة هنا وخطوات التكوين المذكورة في هذا القسم إلى إصدار البرنامج الثابت 3.0(3e) وقد تكون هناك إختلافات طفيفة إذا كنت تعمل على إصدارات أخرى.
إضافة عقدة OSD-Compute الجديدة إلى OverCloud
الخطوات المذكورة في هذا القسم عامة بغض النظر عن VM المستضاف من قبل عقدة الكمبيوتر.
إضافة خادم حوسبة باستخدام فهرس مختلف.
قم بإنشاء ملف add_node.json مع تفاصيل خادم الكمبيوتر الجديد الذي ستتم إضافته فقط. تأكد من عدم إستخدام رقم الفهرس الخاص بخادم OSD-Compute الجديد من قبل. في العادة، زيادة أعلى قيمة حوسبة تالية.
مثال: تم إنشاء OSD-Compute-0 على هذا النحو في حالة نظام 2vnf.
ملاحظة: انتبهوا لصيغة الزبن.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:osd-compute-3,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
إستيراد ملف json:
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
تشغيل إدخال العقدة باستخدام UUID الملاحظ من الخطوة السابقة:
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
إضافة عناوين IP إلى custom-templates/layout.yml ضمن OsdComputeIPs. في هذه الحالة، عند إستبدال OSD-Compute-0 تقوم بإضافة هذا العنوان إلى نهاية القائمة لكل نوع:
OsdComputeIPs:
internal_api:
- 11.120.0.43
- 11.120.0.44
- 11.120.0.45
- 11.120.0.43 <<< take osd-compute-0 .43 and add here
tenant:
- 11.117.0.43
- 11.117.0.44
- 11.117.0.45
- 11.117.0.43 << and here
storage:
- 11.118.0.43
- 11.118.0.44
- 11.118.0.45
- 11.118.0.43 << and here
storage_mgmt:
- 11.119.0.43
- 11.119.0.44
- 11.119.0.45
- 11.119.0.43 << and here
قم بتشغيل البرنامج النصي deploy.sh الذي تم إستخدامه سابقا لنشر المكدس، لإضافة عقدة الحوسبة الجديدة إلى مكدس الذاكرة المؤقتة (overCloud):
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
انتظار اكتمال حالة مكدس OpenStack:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
تحقق من أن عقدة OSD-Compute الجديدة في الحالة "نشط":
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep osd-compute-3
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-osd-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep osd-compute-3
| 63 | pod1-osd-compute-3.localdomain |
قم بتسجيل الدخول إلى خادم OSD-Compute الجديد وفحص عمليات CEPH. في البداية، ستكون الحالة في HEALTH_WARN بينما يسترد CEPH عافيته:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
223 pgs backfill_wait
4 pgs backfilling
41 pgs degraded
227 pgs stuck unclean
41 pgs undersized
recovery 45229/1300136 objects degraded (3.479%)
recovery 525016/1300136 objects misplaced (40.382%)
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e986: 12 osds: 12 up, 12 in; 225 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v781746: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1553 GB used, 11840 GB / 13393 GB avail
45229/1300136 objects degraded (3.479%)
525016/1300136 objects misplaced (40.382%)
477 active+clean
186 active+remapped+wait_backfill
37 active+undersized+degraded+remapped+wait_backfill
4 active+undersized+degraded+remapped+backfilling
ولكن بعد فترة قصيرة (20 دقيقة)، عاد ترتيب CEPH إلى حالة HEALTH_OK:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v784311: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1599 GB used, 11793 GB / 13393 GB avail
704 active+clean
client io 8168 kB/s wr, 0 op/s rd, 32 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 0 host pod1-osd-compute-0
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
إعدادات إستبدال خادم النشر
بعد إضافة الخادم إلى مجموعة النظراء، يرجى الرجوع إلى الارتباط أدناه لتطبيق الإعدادات التي كانت موجودة سابقا في الخادم القديم:
إستعادة الأجهزة الافتراضية
الحالة 1. عقد OSD-Compute التي تستضيف CF و ESC و EM و UAS
إضافة إلى قائمة تجميع نوفا
قم بإضافة عقدة OSD-Compute إلى البيئات المضيفة المجمعة وتحقق مما إذا كان المضيف قد تمت إضافته. في هذه الحالة، يجب إضافة عقدة OSD-Compute إلى كل من تجميعات مضيف CF و EM.
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-CF-MGMT2 pod1-osd-compute-3.localdomain
[stack@director ~]$ nova aggregate-add-host VNF2-EM-MGMT2 pod1-osd-compute-3.localdomain
[stack@direcotr ~]$ nova aggregate-add-host POD1-AUTOIT pod1-osd-compute-3.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOITT
إستعادة نظام التشغيل UAS VM
تحقق من حالة UAS VM في قائمة نوفا وقم بحذفها:
[stack@director ~]$ nova list | grep VNF2-UAS-uas-0
| 307a704c-a17c-4cdc-8e7a-3d6e7e4332fa | VNF2-UAS-uas-0 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.10; VNF2-UAS-uas-management=172.168.10.3
[stack@director ~]$ nova delete VNF2-UAS-uas-0
Request to delete server VNF2-UAS-uas-0 has been accepted.
لاسترداد VM autoVNF-UAS، قم بتشغيل البرنامج النصي uas-check للتحقق من الحالة. يجب أن يبلغ عن خطأ. ثم قم بالتشغيل مرة أخرى باستخدام — خيار الإصلاح من أجل إعادة إنشاء جهاز UAS VM المفقود:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts/
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS
2017-12-08 12:38:05,446 - INFO: Check of AutoVNF cluster started
2017-12-08 12:38:07,925 - INFO: Instance 'vnf1-UAS-uas-0' status is 'ERROR'
2017-12-08 12:38:07,925 - INFO: Check completed, AutoVNF cluster has recoverable errors
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS --fix
2017-11-22 14:01:07,215 - INFO: Check of AutoVNF cluster started
2017-11-22 14:01:09,575 - INFO: Instance VNF2-UAS-uas-0' status is 'ERROR'
2017-11-22 14:01:09,575 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-22 14:01:09,778 - INFO: Removing instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Removed instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Creating instance VNF2-UAS-uas-0' and attaching volume ‘VNF2-UAS-uas-vol-0'
2017-11-22 14:01:49,525 - INFO: Created instance ‘VNF2-UAS-uas-0'
سجل الدخول إلى autoVNF-UAS. استني بكم دقيقة و UAS لازم ترجع متل ما هي:
VNF2-autovnf-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.17.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.17.180.6 alive CONFD-SLAVE
172.17.180.7 alive CONFD-MASTER
172.17.180.9 alive NA
ملاحظة: إذا فشل UAS-check.py-fix، فقد تحتاج إلى نسخ هذا الملف وتشغيله مرة أخرى.
[stack@director ~]$ mkdir –p /opt/cisco/usp/apps/auto-it/common/uas-deploy/
[stack@director ~]$ cp /opt/cisco/usp/uas-installer/common/uas-deploy/userdata-uas.txt /opt/cisco/usp/apps/auto-it/common/uas-deploy/
إسترداد ESC VM
تحقق من حالة ESC VM من قائمة نوفا وقم بحذفها:
stack@director scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | VNF2-ESC-ESC-1 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete VNF2-ESC-ESC-1
Request to delete server VNF2-ESC-ESC-1 has been accepted.
من AutoVNF-UAS، ابحث عن حركة نشر ESC وفي سجل الحركة ابحث عن سطر الأوامر boot_vm.py لإنشاء مثيل ESC:
ubuntu@VNF2-uas-uas-0:~$ sudo -i
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show transaction
TX ID TX TYPE DEPLOYMENT ID TIMESTAMP STATUS
-----------------------------------------------------------------------------------------------------------------------------
35eefc4a-d4a9-11e7-bb72-fa163ef8df2b vnf-deployment VNF2-DEPLOYMENT 2017-11-29T02:01:27.750692-00:00 deployment-success
73d9c540-d4a8-11e7-bb72-fa163ef8df2b vnfm-deployment VNF2-ESC 2017-11-29T01:56:02.133663-00:00 deployment-success
VNF2-uas-uas-0#show logs 73d9c540-d4a8-11e7-bb72-fa163ef8df2b | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<logs xmlns="http://www.cisco.com/usp/nfv/usp-autovnf-oper">
<tx-id>73d9c540-d4a8-11e7-bb72-fa163ef8df2b</tx-id>
<log>2017-11-29 01:56:02,142 - VNFM Deployment RPC triggered for deployment: VNF2-ESC, deactivate: 0
2017-11-29 01:56:02,179 - Notify deployment
..
2017-11-29 01:57:30,385 - Creating VNFM 'VNF2-ESC-ESC-1' with [python //opt/cisco/vnf-staging/bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689 --net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username ****** --os_password ****** --bs_os_auth_url http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username ****** --bs_os_password ****** --esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --encrypt_key ****** --user_pass ****** --user_confd_pass ****** --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3 172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh --file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py --file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
احفظ خط boot_vm.py في ملف نصي Shell (esc.sh) وقم بتحديث جميع أسطر اسم المستخدم **** وكلمة المرور ***** مع المعلومات الصحيحة (عادة core/<كلمة المرور>). تحتاج إلى إزالة خيار –encrypt_key كذلك. بالنسبة إلى user_pass و user_confd_pass، تحتاج إلى إستخدام التنسيق - اسم المستخدم: كلمة السر (مثال - admin:<كلمة السر>).
ابحث عن عنوان URL لإبقاء bootvm.py من running-config وتحميل ملف bootvm.py إلى ملف autoVNF-uas VM. في هذه الحالة، 10.1.2.3 هو عنوان IP الخاص بتقنية VM التلقائية:
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show running-config autovnf-vnfm:vnfm
…
configs bootvm
value http:// 10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
!
root@VNF2-uas-uas-0:~# wget http://10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
--2017-12-01 20:25:52-- http://10.1.2.3 /bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
Connecting to 10.1.2.3:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127771 (125K) [text/x-python]
Saving to: ‘bootvm-2_3_2_155.py’
100%[=====================================================================================>] 127,771 --.-K/s in 0.001s
2017-12-01 20:25:52 (173 MB/s) - ‘bootvm-2_3_2_155.py’ saved [127771/127771]
إنشاء ملف /tmp/esc_params.cfg:
root@VNF2-uas-uas-0:~# echo "openstack.endpoint=publicURL" > /tmp/esc_params.cfg
تشغيل برنامج نصي ل Shell لنشر ESC من عقدة UAS:
root@VNF2-uas-uas-0:~# /bin/sh esc.sh
+ python ./bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689
--net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url
http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username core --os_password <PASSWORD> --bs_os_auth_url
http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username core --bs_os_password <PASSWORD>
--esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --user_pass admin:<PASSWORD> --user_confd_pass
admin:<PASSWORD> --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3
172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh
--file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py
--file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
قم بتسجيل الدخول إلى ESC جديد وتحقق من حالة النسخ الاحتياطي:
ubuntu@VNF2-uas-uas-0:~$ ssh admin@172.168.11.14
…
####################################################################
# ESC on VNF2-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@VNF2-esc-esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
إسترداد الأجهزة الافتراضية باستخدام تقنية CF و EM من تقنية ESC
تحقق من حالة CF و EM VMs من قائمة نوفا. يجب أن تكون في حالة الخطأ:
[stack@director ~]$ source corerc
[stack@director ~]$ nova list --field name,host,status |grep -i err
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | None | ERROR|
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 |None | ERROR
سجل الدخول إلى مدير ESC، وقم بتشغيل recovery-vm-action لكل EM و CF VM متأثر. تحلَّ بالصبر. تقوم ESC بجدولة إجراء الاسترداد وقد لا يحدث ذلك لبضع دقائق. راقبت الموقع winesc.log:
sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
[admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8]
قم بتسجيل الدخول إلى em جديدة وتحقق من أن حالة em موجودة:
ubuntu@VNF2vnfddeploymentem-1:~$ /opt/cisco/ncs/current/bin/ncs_cli -u admin -C
admin connected from 172.17.180.6 using ssh on VNF2vnfddeploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
3 up up up
سجل الدخول إلى StarOS VNF وتحقق من أن بطاقة CF في حالة الاستعداد.
الحالة 2. عقدة OSD-Compute التي تستضيف تقنية المعلومات التلقائية والنشر التلقائي و EM و UAS
إسترداد ميزة النشر التلقائي للطراز VM
من OSPD، إذا تأثر النشر التلقائي ل VM ولكنه لا يزال يظهر Active/Running، ستحتاج إلى حذفه أولا. إذا لم يتأثر النشر التلقائي، فقم بالتخطي إلى إسترداد الأجهزة الافتراضية (VM) التلقائية:
[stack@director ~]$ nova list |grep auto-deploy
| 9b55270a-2dcd-4ac1-aba3-bf041733a0c9 | auto-deploy-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.12, 10.1.2.7 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7 --delete
بمجرد حذف النشر التلقائي، قم بإنشائه مرة أخرى بنفس العنوان floatingip:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7
2017-11-17 07:05:03,038 - INFO: Creating AutoDeploy deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-17 07:05:03,039 - INFO: Loading image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:14,603 - INFO: Loaded image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:15,787 - INFO: Assigned floating IP '10.1.2.7' to IP '172.16.181.7'
2017-11-17 07:05:15,788 - INFO: Creating instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Created instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Request completed, floating IP: 10.1.2.7
انسخ ملف AutoDeploy.cfg و ISO وملف tar confd_backup من خادم النسخ الاحتياطي لديك إلى النشر التلقائي ل VM واستعادة ملفات cdb المضمنة من ملف النسخ الاحتياطي tar:
ubuntu@auto-deploy-iso-2007-uas-0:~# sudo -i
ubuntu@auto-deploy-iso-2007-uas-0:# service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd# tar xvf /home/ubuntu/ad_cdb_backup.tar
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0~# service uas-confd start
uas-confd start/running, process 2036
تحقق من تحميل الإرساء بشكل صحيح عن طريق التحقق من الحركات السابقة. قم بتحديث autodeploy.cfg باسم OSD-compute جديد. ارجع إلى القسم - الخطوة النهائية: تحديث تكوين النشر التلقائي:
root@auto-deploy-iso-2007-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#show transaction
SERVICE SITE
DEPLOYMENT SITE TX AUTOVNF VNF AUTOVNF
TX ID TX TYPE ID DATE AND TIME STATUS ID ID ID ID TX ID
-------------------------------------------------------------------------------------------------------------------------------------
1512571978613 service-deployment tb5bxb 2017-12-06T14:52:59.412+00:00 deployment-success
auto-deploy-iso-2007-uas-0# exit
إسترداد Auto-IT VM
من OSPD، إذا كان VM تلقائيا قد تأثر ولكنه لا يزال يظهر ك Active/Running، فإنه يلزم حذفه. إذا لم يكن الأمر تلقائيا متأثرا، فقم بالتخطي إلى الجهاز الظاهري التالي:
[stack@director ~]$ nova list |grep auto-it
| 580faf80-1d8c-463b-9354-781ea0c0b352 | auto-it-vnf-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.3, 10.1.2.8 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./ auto-it-vnf-staging.sh --floating-ip 10.1.2.8 --delete
تشغيل النص البرمجي المرحلي auto-it-vnf وإعادة إنشاء auto-it:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-it-vnf-staging.sh --floating-ip 10.1.2.8
2017-11-16 12:54:31,381 - INFO: Creating StagingServer deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-16 12:54:31,382 - INFO: Loading image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:51,961 - INFO: Loaded image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:53,217 - INFO: Assigned floating IP '10.1.2.8' to IP '172.16.181.9'
2017-11-16 12:54:53,217 - INFO: Creating instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,929 - INFO: Created instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,930 - INFO: Request completed, floating IP: 10.1.2.8
أعد تحميل صورة ISO. في هذه الحالة، يكون عنوان IP التلقائي 10.1.2.8. يستغرق هذا بضع دقائق للتحميل:
[stack@director ~]$ cd images/5_1_7-2007/isos
[stack@director isos]$ curl -F file=@usp-5_1_7-2007.iso http://10.1.2.8:5001/isos
{
"iso-id": "5.1.7-2007"
}
to check the ISO image:
[stack@director isos]$ curl http://10.1.2.8:5001/isos
{
"isos": [
{
"iso-id": "5.1.7-2007"
}
]
}
نسخ ملفات VNF system.cfg من دليل OSPD Auto-Deployment إلى VM تلقائي:
[stack@director autodeploy]$ scp system-vnf* ubuntu@10.1.2.8:.
ubuntu@10.1.2.8's password:
system-vnf1.cfg 100% 1197 1.2KB/s 00:00
system-vnf2.cfg 100% 1197 1.2KB/s 00:00
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ pwd
/home/ubuntu
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ ls
system-vnf1.cfg system-vnf2.cfg
ملاحظة: إجراء الاسترداد الخاص ب EM و UAS VM هو نفسه في كلتا الحالتين. ارجع إلى قسم "الحالة.1" لنفس الإجراء.
معالجة فشل إسترداد ESC
في الحالات التي يفشل فيها ESC في بدء تشغيل VM بسبب حالة غير متوقعة، توصي Cisco بإجراء تحويل ESC من خلال إعادة تمهيد ESC الرئيسي. ستستغرق عملية التبديل ESC حوالي دقيقة. قم بتشغيل البرنامج النصي health.sh على الأساسي الجديد ESC للتحقق من أن الحالة قيد التشغيل. مدير ESC in order to بدأت ال VM وصححت ال VM دولة. ستستغرق مهمة الاسترداد هذه ما يصل إلى خمس دقائق لإكمالها.
يمكنك مراقبة /var/log/esc/yangesc.log و/var/log/esc/escmanager.log. إذا لم تلاحظ إسترداد الجهاز الظاهري بعد 5 إلى 7 دقائق، فسيحتاج المستخدم إلى الذهاب وإجراء عملية الاسترداد اليدوي للأجهزة الافتراضية (الأجهزة الافتراضية) المتأثرة.
تحديث تكوين النشر التلقائي
من AutoDeploy VM، قم بتحرير النشر التلقائي.cfg واستبدال الخادم القديم الذي يدعم ميزة OSD-Compute بالخادم الجديد. ثم قم بتحميل الاستبدال في confd_cli. هذه الخطوة مطلوبة لإلغاء تنشيط النشر بنجاح لاحقا.
root@auto-deploy-iso-2007-uas-0:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#config
Entering configuration mode terminal
auto-deploy-iso-2007-uas-0(config)#load replace autodeploy.cfg
Loading. 14.63 KiB parsed in 0.42 sec (34.16 KiB/sec)
auto-deploy-iso-2007-uas-0(config)#commit
Commit complete.
auto-deploy-iso-2007-uas-0(config)#end
قم بإعادة تشغيل خدمات UAS-Confd والنشر التلقائي بعد تغيير التكوين:
root@auto-deploy-iso-2007-uas-0:~# service uas-confd restart
uas-confd stop/waiting
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service uas-confd status
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service autodeploy restart
autodeploy stop/waiting
autodeploy start/running, process 14017
root@auto-deploy-iso-2007-uas-0:~# service autodeploy status
autodeploy start/running, process 14017
تمكين syslog
لتمكين syslogs لخادم UCS ومكونات OpenStack والأجهزة الافتراضية (VM) المسترجعة، الرجاء اتباع الأقسام
"إعادة تمكين syslog ل UCS ومكونات OpenStack" و"تمكين syslog ل VNFs" في الارتباط أدناه:
محفوظات المراجعة
| المراجعة | تاريخ النشر | التعليقات |
|---|---|---|
1.0 |
10-Jul-2018 |
الإصدار الأولي |
تمت المساهمة بواسطة مهندسو Cisco
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)