Service Level Management: Whitepaper zu Best Practices
Inhalt
Einführung
Dieses Dokument beschreibt das Service-Level-Management und Service-Level Agreements (SLAs) für Hochverfügbarkeitsnetzwerke. Sie umfasst wichtige Erfolgsfaktoren für das Service-Level-Management und Leistungsindikatoren zur Erfolgsbewertung. Darüber hinaus enthält das Dokument detaillierte Informationen zu SLAs, die Best Practice-Richtlinien befolgen, die vom Hochverfügbarkeitsteam festgelegt wurden.
Überblick über das Service Level Management
Netzwerkunternehmen haben in der Vergangenheit wachsende Netzwerkanforderungen erfüllt, indem sie eine solide Netzwerkinfrastruktur aufgebaut und reaktiv an der Bewältigung individueller Serviceprobleme gearbeitet haben. Bei einem Ausfall würden neue Prozesse, Managementfunktionen oder Infrastrukturen erstellt, um einen Ausfall zu verhindern. Aufgrund einer höheren Änderungsrate und steigender Verfügbarkeitsanforderungen benötigen wir jetzt jedoch ein verbessertes Modell, um ungeplante Ausfallzeiten proaktiv zu verhindern und das Netzwerk schnell zu reparieren. Viele Service Provider und Unternehmen haben versucht, das Servicelevel besser zu definieren, das zur Erreichung der Geschäftsziele erforderlich ist.
Kritische Erfolgsfaktoren
Wichtige Erfolgsfaktoren für SLAs werden zur Definition von Schlüsselelementen für die erfolgreiche Erstellung von Service-Levels und die Aufrechterhaltung von SLAs verwendet. Um sich als entscheidender Erfolgsfaktor zu qualifizieren, muss ein Prozess- oder Prozessschritt die Qualität des SLA verbessern und die Netzwerkverfügbarkeit im Allgemeinen verbessern. Der kritische Erfolgsfaktor sollte ebenfalls messbar sein, damit das Unternehmen feststellen kann, wie erfolgreich er im Vergleich zum definierten Verfahren war.
Weitere Einzelheiten finden Sie unter Implementieren des Service-Level-Managements.
Leistungsindikatoren
Leistungsindikatoren liefern den Mechanismus, mit dem ein Unternehmen kritische Erfolgsfaktoren misst. In der Regel werden diese monatlich überprüft, um sicherzustellen, dass Service-Level-Definitionen oder SLAs ordnungsgemäß funktionieren. Die Gruppe Netzwerkbetrieb und die erforderlichen Toolgruppen können die folgenden Metriken durchführen.
Hinweis: Für Unternehmen ohne SLAs empfehlen wir die Durchführung von Service-Level-Definitionen und Service-Level-Reviews zusätzlich zu den Metriken.
Leistungsindikatoren:
-
Dokumentierte Service-Level-Definition oder SLA, die Verfügbarkeit, Leistung, reaktive Service-Reaktionszeit, Problemlösungsziele und Problemeskalation beinhaltet.
-
Monatliches Treffen zur Überprüfung der Service-Level-Compliance und Implementierung von Verbesserungen auf Service-Level.
-
Leistungsindikatormetriken wie Verfügbarkeit, Leistung, Service-Reaktionszeit nach Priorität, Behebungszeit nach Priorität und andere messbare SLA-Parameter.
Weitere Informationen finden Sie unter Implementieren des Service-Level-Managements.
Ablauf des Managementprozesses auf Service-Ebene
Der allgemeine Prozessablauf für das Service-Level-Management umfasst zwei Hauptgruppen:
Klicken Sie auf die Objekte im folgenden Diagramm, um die Details für diesen Schritt anzuzeigen.
Implementierung des Service-Level-Managements
Die Implementierung des Service-Level-Managements umfasst 16 Schritte, die in die folgenden beiden Hauptkategorien unterteilt sind:
Definieren von Netzwerkservicelevels
Netzwerkmanager müssen die wichtigsten Regeln definieren, anhand derer das Netzwerk unterstützt, verwaltet und gemessen wird. Die Servicelevel stellen Ziele für alle Netzwerkmitarbeiter dar und können als Kennzahl für die Qualität des gesamten Service verwendet werden. Sie können auch Service-Level-Definitionen als Tool für die Budgetierung von Netzwerkressourcen und als Nachweis für die Notwendigkeit, höhere QoS zu finanzieren, verwenden. Sie bieten auch eine Möglichkeit, die Leistung von Anbietern und Betreibern zu bewerten.
Ohne eine Definition und Messung des Service-Levels hat das Unternehmen keine klaren Ziele. Die Service-Zufriedenheit kann durch Benutzer bestimmt werden, wobei Anwendungen, Server-/Client-Betrieb oder Netzwerk-Support nur geringfügig voneinander getrennt werden. Die Budgetierung kann schwieriger sein, da das Endergebnis für das Unternehmen nicht klar ist. Und schließlich neigt die Netzwerkorganisation dazu, bei der Verbesserung des Netzwerk- und Support-Modells eher reaktiv als proaktiv vorzugehen.
Für die Entwicklung und Unterstützung eines Service-Level-Modells empfehlen wir die folgenden Schritte:
-
Definieren Sie Verfügbarkeits- und Leistungsstandards, und definieren Sie allgemeine Begriffe.
-
Erfassen Sie Metriken, und überwachen Sie die Service-Level-Definition.
Schritt 1: Analyse technischer Ziele und Einschränkungen
Die beste Möglichkeit, technische Ziele und Zwänge zu analysieren, besteht in Brainstorming-Sitzungen oder Recherche zu technischen Zielen und Anforderungen. Manchmal ist es hilfreich, andere IT-Fachkräfte in dieses Gespräch einzuladen, da diese Personen bestimmte Ziele im Zusammenhang mit ihren Services verfolgen. Zu den technischen Zielen gehören Verfügbarkeitswerte, Durchsatz, Jitter, Verzögerung, Reaktionszeit, Skalierbarkeitsanforderungen, neue Funktionen, neue Anwendungseinführungen, Sicherheit, Verwaltbarkeit und sogar Kosten. Die Organisation sollte dann die Zwänge untersuchen, die zur Erreichung dieser Ziele angesichts der verfügbaren Ressourcen erforderlich sind. Sie können Arbeitsblätter für jedes Ziel mit einer Erläuterung der Einschränkungen erstellen. Anfänglich scheint es, als ob die meisten Ziele nicht erreichbar sind. Priorisieren Sie dann die Ziele, oder senken Sie die Erwartungen, die noch erfüllt werden können.
So können Sie beispielsweise eine Verfügbarkeit von 99,999 % oder 5 Minuten Ausfallzeit pro Jahr erreichen. Um dieses Ziel zu erreichen, gibt es zahlreiche Einschränkungen, z. B. zentrale Fehlerquellen bei der Hardware, defekte Hardware mit mittlerer Reparaturzeit (MTTR) an Remote-Standorten, die Zuverlässigkeit der Carrier, proaktive Funktionen zur Fehlererkennung, hohe Änderungsraten und aktuelle Einschränkungen bei der Netzwerkkapazität. Als Ergebnis können Sie das Ziel auf ein erreichbares Niveau anpassen. Das Verfügbarkeitsmodell im nächsten Abschnitt kann Ihnen dabei helfen, realistische Ziele zu setzen.
Möglicherweise denken Sie auch darüber nach, in bestimmten Bereichen des Netzwerks mit geringeren Einschränkungen eine höhere Verfügbarkeit bereitzustellen. Wenn die Netzwerkorganisation Servicestandards für die Verfügbarkeit veröffentlicht, kann dies für Geschäftsgruppen innerhalb des Unternehmens unannehmbar sein. Dies ist ein natürlicher Punkt, um SLA-Diskussionen oder Finanzierungs-/Budgetierungs-Modelle einzuleiten, die die Geschäftsanforderungen erfüllen können.
Arbeiten, um alle Zwänge oder Risiken zu ermitteln, die mit der Erreichung des technischen Ziels verbunden sind. Priorisieren Sie Einschränkungen in Bezug auf das größte Risiko oder die größten Auswirkungen auf das gewünschte Ziel. Auf diese Weise kann das Unternehmen Initiativen zur Netzwerkoptimierung priorisieren und ermitteln, wie schnell die Einschränkungen behoben werden können. Es gibt drei Arten von Einschränkungen:
-
Netzwerktechnologie, Ausfallsicherheit und Konfiguration
-
Lebenszyklusverfahren, einschließlich Planung, Design, Implementierung und Betrieb
-
Aktuelle Datenverkehrslast oder Anwendungsverhalten
Einschränkungen hinsichtlich Netzwerktechnologie, Ausfallsicherheit und Konfiguration sind mit der aktuellen Technologie, Hardware, Links, dem Design oder der Konfiguration verbundene Einschränkungen oder Risiken. Technologische Einschränkungen decken alle Einschränkungen ab, die durch die Technologie selbst auferlegt werden. So lässt beispielsweise keine aktuelle Technologie Konvergenzzeiten von weniger als einer Sekunde in redundanten Netzwerkumgebungen zu, was für die Aufrechterhaltung von Sprachverbindungen im gesamten Netzwerk von entscheidender Bedeutung sein kann. Ein weiteres Beispiel könnte die Rohgeschwindigkeit sein, die Daten auf terrestrischen Verbindungen übertragen können, also etwa 100 Meilen pro Millisekunde.
Die Untersuchungen zur Ausfallsicherheit von Netzwerkhardware sollten sich auf Hardwaretopologie, Hierarchie, Modularität, Redundanz und MTBF über definierte Pfade im Netzwerk konzentrieren. Einschränkungen bei Netzwerkverbindungen sollten sich auf Netzwerkverbindungen und Carrier-Konnektivität für Unternehmen konzentrieren. Verbindungseinschränkungen können Verbindungsredundanz und -vielfalt, Medieneinschränkungen, Verkabelungsinfrastruktur, Anbindung an einen lokalen Teilnehmeranschluss und Fernverbindungen umfassen. Designeinschränkungen beziehen sich auf das physische oder logische Design des Netzwerks und beinhalten alles, von verfügbarem Speicherplatz für Geräte bis hin zur Skalierbarkeit der Routing-Protokoll-Implementierung. Alle Protokoll- und Mediendesigns sollten in Bezug auf Konfiguration, Verfügbarkeit, Skalierbarkeit, Leistung und Kapazität berücksichtigt werden. Auch Einschränkungen hinsichtlich Netzwerkservices wie Dynamic Host Configuration Protocol (DHCP), Domain Name System (DNS), Firewalls, Protokoll-Übersetzer und Network Address Übersetzer sollten berücksichtigt werden.
Lebenszyklusverfahren definieren die Prozesse und das Management des Netzwerks, das für die konsistente Bereitstellung von Lösungen, die Erkennung und Behebung von Problemen, die Verhinderung von Kapazitäts- oder Leistungsproblemen und die Konfiguration des Netzwerks für Konsistenz und Modularität verwendet wird. Sie müssen diesen Bereich in Betracht ziehen, da Fachwissen und Prozesse in der Regel am stärksten zur Nichtverfügbarkeit beitragen. Der Netzwerk-Lebenszyklus bezieht sich auf den Zyklus von Planung, Design, Implementierung und Betrieb. In jedem dieser Bereiche müssen Sie mit Netzwerkmanagementfunktionen wie Leistungsmanagement, Konfigurationsmanagement, Fehlermanagement und Sicherheit vertraut sein. Im Rahmen der Cisco NSA HAS-Services (High Availability Services) ist eine Analyse des Netzwerk-Lebenszyklus verfügbar, die aktuelle Einschränkungen hinsichtlich der Netzwerkverfügbarkeit aufzeigt, die mit dem Lebenszyklus-Verfahren des Netzwerks verbunden sind.
Aktuelle Datenverkehrslast oder Anwendungseinschränkungen beziehen sich lediglich auf die Auswirkungen des aktuellen Datenverkehrs und der aktuellen Anwendungen.
Viele Anwendungen haben jedoch erhebliche Einschränkungen, die eine sorgfältige Verwaltung erfordern. Jitter, Verzögerungen, Durchsatz und Bandbreitenanforderungen für aktuelle Anwendungen sind in der Regel mit zahlreichen Einschränkungen verbunden. Die Art und Weise, wie die Anwendung geschrieben wurde, kann auch Einschränkungen verursachen. Die Erstellung von Anwendungsprofilen hilft Ihnen, diese Probleme besser zu verstehen. Im nächsten Abschnitt wird diese Funktion behandelt. Die Untersuchung der aktuellen Verfügbarkeit, des Datenverkehrs, der Kapazität und der Leistung insgesamt hilft Netzwerkmanagern außerdem, die aktuellen Erwartungen und Risiken in Bezug auf das Servicelevel zu verstehen. Dies wird in der Regel mithilfe eines Netzwerkbaselining-Prozesses erreicht, der dazu beiträgt, die durchschnittliche Netzwerkleistung, Verfügbarkeit oder Kapazität für einen bestimmten Zeitraum (in der Regel etwa einen Monat) zu definieren. Diese Informationen werden in der Regel für die Kapazitätsplanung und Trendanalyse verwendet, können aber auch zur Ermittlung von Service-Level-Problemen verwendet werden.
Im folgenden Arbeitsblatt wird die oben genannte Ziel-/Einschränkungsmethode verwendet, um z. B. einen Sicherheitsangriff oder Denial-of-Service-Angriff (DoS) zu verhindern. Sie können dieses Arbeitsblatt auch verwenden, um die Serviceabdeckung zur Minimierung von Sicherheitsangriffen zu ermitteln.
| Risiko oder Einschränkung | Einschränkungstyp | Potenzielle Auswirkungen |
|---|---|---|
| Verfügbare DoS-Erkennungstools können nicht alle Arten von DoS-Angriffen erkennen. | Technologie/Ausfallsicherheit | Hoch |
| Verfügen Sie nicht über die erforderlichen Mitarbeiter und Prozesse, um auf Warnungen zu reagieren. | Lebenszyklusverfahren | Hoch |
| Aktuelle Netzwerkzugriffsrichtlinien sind nicht vorhanden. | Lebenszyklusverfahren | Mittel |
| Die aktuelle Internetverbindung mit niedriger Bandbreite kann ein Faktor sein, wenn eine Überlastung der Bandbreite für Angriffe genutzt wird. | Netzwerkkapazität | Mittel |
| Derzeit ist die Sicherheitskonfiguration zur Verhinderung von Angriffen möglicherweise nicht ausreichend. | Technologie/Ausfallsicherheit | Mittel |
Schritt 2: Bestimmen des Verfügbarkeitsbudgets
Ein Verfügbarkeitsbudget ist die erwartete theoretische Verfügbarkeit des Netzwerks zwischen zwei definierten Punkten. Genaue theoretische Informationen sind auf verschiedene Weise nützlich:
-
Das Unternehmen kann dies als Ziel für die interne Verfügbarkeit nutzen, und Abweichungen können schnell definiert und behoben werden.
-
Die Informationen können von Netzwerkplanern bei der Bestimmung der Systemverfügbarkeit herangezogen werden, um sicherzustellen, dass das Design die geschäftlichen Anforderungen erfüllt.
Zu den Faktoren, die zu einer Nichtverfügbarkeit oder Ausfallzeit beitragen, gehören Hardwarefehler, Softwarefehler, Probleme mit Stromversorgung und Umgebung, Ausfall von Verbindungen oder Betreibern, Netzwerkdesign, menschliches Versagen oder Prozessmangel. Bei der Bewertung des gesamten Verfügbarkeitsbudgets für das Netzwerk sollten Sie jeden dieser Parameter genau bewerten.
Wenn das Unternehmen derzeit die Verfügbarkeit misst, benötigen Sie möglicherweise kein Verfügbarkeitsbudget. Verwenden Sie die Verfügbarkeitsmessung als Ausgangsbasis, um den aktuellen Service-Level für eine Service-Level-Definition zu schätzen. Sie können jedoch daran interessiert sein, die beiden zu vergleichen, um die mögliche theoretische Verfügbarkeit im Vergleich zum tatsächlichen gemessenen Ergebnis zu verstehen.
Verfügbarkeit ist die Wahrscheinlichkeit, dass ein Produkt oder Service bei Bedarf betrieben wird. Siehe folgende Definitionen:
-
Verfügbarkeit
-
1 - (Gesamtverbindungsausfallzeit) / (Gesamtdauer der In-Service-Verbindung)
-
1 - [Sigma (Anzahl der Verbindungen, die bei einem Ausfall in X Dauer des Ausfalls i betroffen sind)] / (Anzahl Verbindungen in Service X Betriebszeit)
-
-
Nichtverfügbarkeit
1 - Verfügbarkeit oder Verbindungszeit bei vollständigem Ausfall aufgrund von (Hardwarefehler, Softwarefehler, Umgebungs- und Energieprobleme, Link- oder Carrier-Ausfall, Netzwerkdesign oder Benutzerfehler und Prozessfehler)
-
Hardware-Verfügbarkeit
Der erste zu untersuchende Bereich sind mögliche Hardwarefehler und die Auswirkungen auf die Nichtverfügbarkeit. Um dies zu bestimmen, muss die Organisation die MTBF aller Netzwerkkomponenten und die MTTR für Hardwareprobleme aller Geräte im Pfad zwischen zwei Punkten verstehen. Wenn das Netzwerk modular und hierarchisch aufgebaut ist, ist die Hardware-Verfügbarkeit zwischen fast allen zwei Punkten identisch. MTBF-Informationen sind für alle Cisco Komponenten verfügbar und können auf Anfrage bei einem lokalen Account Manager eingesehen werden. Das Cisco NSA HAS-Programm verwendet außerdem ein Tool, um die Hardwareverfügbarkeit auf Netzwerkpfaden zu ermitteln, selbst wenn Modulredundanz, Chassis-Redundanz und Pfadredundanz im System vorhanden sind. Ein wichtiger Faktor für die Zuverlässigkeit der Hardware ist die MTTR. Unternehmen sollten prüfen, wie schnell sie defekte Hardware reparieren können. Wenn das Unternehmen über keinen Ersatzteilplan verfügt und sich auf eine Cisco SMARTnet™ Standardvereinbarung verlässt, beträgt die potenzielle durchschnittliche Austauschzeit etwa 24 Stunden. In einer typischen LAN-Umgebung mit Core-Redundanz und ohne Zugriffsredundanz liegt die ungefähre Verfügbarkeit bei 99,99 Prozent mit einer 4-Stunden-MTTR.
-
Softwareverfügbarkeit
Der nächste Bereich, der untersucht werden muss, sind Softwarefehler. Zu Messzwecken definiert Cisco Softwarefehler als Geräte-Kaltstart aufgrund von Softwarefehlern. Cisco hat bedeutende Fortschritte beim Verständnis der Softwareverfügbarkeit erzielt. Neuere Versionen erfordern jedoch eine gewisse Zeit zur Messung und gelten als weniger verfügbar als allgemeine Bereitstellungssoftware. Allgemeine Bereitstellungssoftware wie die IOS-Version 11.2(18) wurde mit einer Verfügbarkeit von über 99,9999 % gemessen. Diese Berechnung basiert auf den tatsächlichen Kaltstarts auf Cisco Routern, wobei sechs Minuten als Reparaturzeit (Zeit für das Neuladen des Routers) verwendet werden. Unternehmen mit einer Vielzahl von Versionen werden aufgrund der erhöhten Komplexität, der Interoperabilität und der kürzeren Fehlerbehebungszeiten voraussichtlich etwas weniger verfügbar sein. Unternehmen mit den neuesten Softwareversionen werden voraussichtlich eine höhere Nichtverfügbarkeit aufweisen. Die Verteilung für die Nichtverfügbarkeit ist ebenfalls relativ breit, d. h., dass die Kunden in der Nähe einer allgemeinen Bereitstellungsversion eine erhebliche Nichtverfügbarkeit oder Verfügbarkeit erleben könnten.
-
Umgebungs- und Stromverfügbarkeit
Sie müssen auch Umwelt- und Energiefragen in der Verfügbarkeit berücksichtigen. Umweltprobleme betreffen den Ausfall von Kühlsystemen, die für die Aufrechterhaltung der Betriebstemperatur der Geräte erforderlich sind. Viele Cisco Geräte werden einfach heruntergefahren, wenn sie nicht spezifiziert sind, anstatt Schäden an der gesamten Hardware zu riskieren. Im Rahmen eines Verfügbarkeitsbudgets wird Strom verwendet, da es die Hauptursache für die Nichtverfügbarkeit in diesem Bereich ist.
Obwohl Stromausfälle ein wichtiger Aspekt bei der Bestimmung der Netzwerkverfügbarkeit sind, ist diese Diskussion begrenzt, da eine theoretische Stromanalyse nicht genau durchgeführt werden kann. Die Bewertung der Leistung für die Geräte muss anhand der Erfahrungen in der geografischen Region, der Backup-Funktionen und des implementierten Prozesses erfolgen, um eine gleichbleibend hochwertige Energieversorgung aller Geräte sicherzustellen.
Für eine konservative Bewertung können wir sagen, dass Unternehmen mit Notstromaggregaten, USV-Systemen und Implementierungsprozessen bei der Implementierung von qualitativ hochwertigen Netzteilen eine Verfügbarkeit von 99,999 % bzw. 99,999 % erzielen können, während Unternehmen ohne diese Systeme eine Verfügbarkeit von 99,99 % bzw. etwa 36 Minuten Ausfallzeit jährlich verzeichnen können. Natürlich können Sie diese Werte auf Grundlage der Wahrnehmung des Unternehmens oder der tatsächlichen Daten an realistischere Werte anpassen.
-
Link- oder Carrier-Fehler
Verbindungs- und Carrier-Ausfälle sind wichtige Faktoren für die Verfügbarkeit in WAN-Umgebungen. Beachten Sie, dass es sich bei WAN-Umgebungen einfach um andere Netzwerke handelt, die denselben Verfügbarkeitsproblemen wie das Netzwerk des Unternehmens ausgesetzt sind, einschließlich Hardwareausfall, Softwareausfall, Benutzerfehler und Stromausfall.
Viele Carrier-Netzwerke haben bereits ein Verfügbarkeitsbudget für ihre Systeme erstellt, aber es kann schwierig sein, diese Informationen zu erhalten. Beachten Sie, dass die Betreiber häufig auch über Verfügbarkeitsgarantien verfügen, die auf einem tatsächlichen Verfügbarkeitsbudget basieren. Diese Garantien sind manchmal einfach Marketing- und Verkaufsmethoden, um den Beförderer zu fördern. In einigen Fällen veröffentlichen diese Netzwerke auch Verfügbarkeitsstatistiken, die sehr gut erscheinen. Beachten Sie, dass diese Statistiken möglicherweise nur für vollständig redundante Kernnetzwerke gelten und die Nichtverfügbarkeit aufgrund des Teilnehmeranschlusses, der einen wesentlichen Beitrag zur Nichtverfügbarkeit in WAN-Netzwerken leistet, nicht berücksichtigen.
Die Erstellung einer Schätzung der Verfügbarkeit für WAN-Umgebungen sollte auf den tatsächlichen Carrier-Informationen und dem Grad der Redundanz für die WAN-Konnektivität basieren. Wenn ein Unternehmen über mehrere Gebäudeeingangsmöglichkeiten, redundante Teilnehmeranschlussanbieter, lokalen Zugang für Synchronous-Optical-Network (SONET) und redundante Fernnetzbetreiber mit geografischer Vielfalt verfügt, wird die WAN-Verfügbarkeit erheblich verbessert.
Der Telefondienst stellt ein relativ genaues Verfügbarkeitsbudget für nicht redundante Netzwerkverbindungen in WAN-Umgebungen dar. Die End-to-End-Konnektivität für Telefone hat ein ungefähres Verfügbarkeitsbudget von 99,94 Prozent. Dabei wird ein Verfügbarkeitsbudget verwendet, das dem in diesem Abschnitt beschriebenen ähnelt. Diese Methode wurde in Datenumgebungen mit nur geringen Abweichungen erfolgreich eingesetzt und wird derzeit als Ziel in der Paketkabelspezifikation für Service-Provider-Kabelnetzwerke verwendet. Wenn wir diesen Wert auf ein vollständig redundantes System anwenden, können wir davon ausgehen, dass die WAN-Verfügbarkeit bei fast 99,9999 Prozent liegt. Natürlich verfügen nur sehr wenige Unternehmen aufgrund der Kosten und der Verfügbarkeit über vollständig redundante, geografisch verteilte WAN-Systeme. Achten Sie daher auf die entsprechende Beurteilung.
Verbindungsausfälle in einer LAN-Umgebung sind weniger wahrscheinlich. Planer möchten jedoch möglicherweise eine geringe Ausfallzeit aufgrund defekter oder loser Steckverbinder eingehen. Bei LAN-Netzwerken liegt eine konservative Schätzung bei etwa 99,9999 Prozent Verfügbarkeit bzw. etwa 30 Sekunden pro Jahr.
-
Netzwerkdesign
Das Netzwerkdesign trägt ebenfalls wesentlich zur Verfügbarkeit bei. Nicht skalierbare Designs, Designfehler und die Zeit für Netzwerkkonvergenz wirken sich negativ auf die Verfügbarkeit aus.
Hinweis: Im folgenden Abschnitt werden nicht skalierbare Design- oder Designfehler im Rahmen dieses Dokuments aufgeführt.
Das Netzwerkdesign ist dann auf einen messbaren Wert beschränkt, der auf Software- und Hardwareausfällen im Netzwerk beruht, die zu einer Umleitung des Datenverkehrs führen. Dieser Wert wird in der Regel als "Systemumschaltzeit" bezeichnet und ist ein Faktor der Self-Healing-Protokollfunktionen innerhalb des Systems.
Berechnen Sie die Verfügbarkeit, indem Sie einfach die gleichen Methoden für Systemberechnungen verwenden. Dies ist jedoch nur dann gültig, wenn die Zeit für den NetzwerkSwitchover die Anforderungen für die Netzwerkanwendung erfüllt. Wenn die Switchover-Zeit akzeptabel ist, entfernen Sie sie aus der Berechnung. Wenn ein Switchover-Zeitraum nicht akzeptabel ist, müssen Sie ihn den Berechnungen hinzufügen. Ein Beispiel hierfür ist Voice over IP (VoIP) in einer Umgebung, in der die geschätzte oder tatsächliche Switchover-Zeit 30 Sekunden beträgt. In diesem Beispiel legen Benutzer einfach auf das Telefon und versuchen es möglicherweise erneut. Die Benutzer werden diesen Zeitraum sicherlich als Nichtverfügbarkeit sehen, aber er wurde im Verfügbarkeitsbudget nicht geschätzt.
Berechnen Sie die Nichtverfügbarkeit aufgrund der Systemumstellungszeit, indem Sie die theoretische Verfügbarkeit von Software und Hardware auf redundanten Pfaden prüfen, da in diesem Bereich ein Switchover erfolgt. Sie müssen die Anzahl der Geräte kennen, die ausfallen können und einen Switchover im redundanten Pfad, die MTBF dieser Geräte und die Switchover-Zeit verursachen. Ein einfaches Beispiel wäre eine MTBF von 35.433 Stunden für jedes von zwei redundanten identischen Geräten und eine Switchover-Zeit von 30 Sekunden. Durch die Aufteilung von 35.433 auf 8.766 (Stunden pro Jahr, die im Durchschnitt Schaltjahre umfassen), stellen wir fest, dass das Gerät alle vier Jahre ausfällt. Wenn wir 30 Sekunden als Switchover-Zeit verwenden, können wir davon ausgehen, dass jedes Gerät aufgrund eines Switchover durchschnittlich 7,5 Sekunden pro Jahr nicht verfügbar ist. Da Benutzer möglicherweise beide Pfade durchlaufen, wird das Ergebnis auf 15 Sekunden pro Jahr verdoppelt. Wenn dieser Wert in Sekunden pro Jahr berechnet wird, kann die Verfügbarkeit durch Switchover als Verfügbarkeit von 99,99999785 % in diesem einfachen System berechnet werden. In anderen Umgebungen ist dies aufgrund der Anzahl redundanter Geräte im Netzwerk, in denen ein Switchover möglich ist, möglicherweise höher.
-
Benutzerfehler und -prozess
Benutzerfehler und Probleme mit der Prozessverfügbarkeit sind die Hauptursachen für die Nichtverfügbarkeit in Unternehmens- und Betreibernetzwerken. Etwa 80 Prozent der Nichtverfügbarkeit sind auf Probleme zurückzuführen, z. B. die fehlende Erkennung von Fehlern, Änderungsfehlern und Leistungsproblemen.
Unternehmen werden bei der Bestimmung des Verfügbarkeitsbudgets einfach nicht viermal so viel theoretische Nichtverfügbarkeit verwenden wollen, aber es gibt immer wieder Hinweise darauf, dass dies in vielen Umgebungen der Fall ist. Der nächste Abschnitt behandelt diesen Aspekt der Nichtverfügbarkeit genauer.
Da Sie theoretisch die Höhe der Nichtverfügbarkeit aufgrund von Benutzerfehlern und -prozessen nicht berechnen können, empfehlen wir, diese aus dem Verfügbarkeitsbudget zu entfernen und Organisationen nach Perfektion zu streben. Ein Problem besteht darin, dass Unternehmen die aktuellen Risiken für die Verfügbarkeit in ihren eigenen Prozessen und Fachkenntnissen verstehen müssen. Wenn Sie diese Risiken und Hemmnisse besser verstehen, können Netzwerkplaner aufgrund dieser Probleme eine gewisse Anzahl von Nichtverfügbarkeiten berücksichtigen. Das Cisco NSA HAS-Programm untersucht diese Probleme und kann Unternehmen dabei unterstützen, potenzielle Nichtverfügbarkeit aufgrund von Prozess-, Benutzer- oder Fachkenntnissen zu ermitteln.
-
Festlegen des endgültigen Verfügbarkeitsbudgets
Sie können das Gesamtverfügbarkeitsbudget ermitteln, indem Sie die Verfügbarkeit für jeden der zuvor definierten Bereiche multiplizieren. Dies geschieht in der Regel in homogenen Umgebungen, in denen die Konnektivität zwischen zwei beliebigen Punkten ähnlich ist, z. B. in einer hierarchisch modularen LAN-Umgebung oder einer hierarchischen Standard-WAN-Umgebung.
In diesem Beispiel erfolgt das Verfügbarkeitsbudget für eine hierarchische modulare LAN-Umgebung. Die Umgebung verwendet für alle Netzwerkkomponenten Backup-Generatoren und UPS-Systeme und verwaltet die Stromversorgung ordnungsgemäß. Die Organisation verwendet kein VoIP und möchte die Zeit für das Software-Switchover nicht berücksichtigen. Die Schätzungen lauten:
-
Verfügbarkeit des Hardwarepfads zwischen zwei Endpunkten = 99,99 % Verfügbarkeit
-
Softwareverfügbarkeit unter Verwendung der GD-Softwarezuverlässigkeit als Referenz = 99,9999 Prozent Verfügbarkeit
-
Umgebungs- und Stromverfügbarkeit mit Backup-Systemen = 99,999 % Verfügbarkeit
-
Verbindungsausfall in LAN-Umgebung = 99,999 % Verfügbarkeit
-
Die Zeit für den Systemwechsel wurde nicht berücksichtigt = 100 % Verfügbarkeit
-
Benutzerfehler und Prozessverfügbarkeit als perfekt = 100 % Verfügbarkeit
Das endgültige Verfügbarkeitsbudget, das die Unternehmen anstreben sollten, entspricht 0,9999 X 0,999999 X 0,999999 X 0,999999 = 0,999896 oder 99,9896 Prozent Verfügbarkeit. Wenn wir die potenzielle Nichtverfügbarkeit aufgrund von Benutzer- oder Prozessfehlern berücksichtigen und davon ausgehen, dass die Nichtverfügbarkeit aufgrund technischer Faktoren das Vierfache beträgt, können wir annehmen, dass das Verfügbarkeitsbudget 99,95 Prozent beträgt.
Diese Beispielanalyse zeigt dann, dass die LAN-Verfügbarkeit im Durchschnitt zwischen 99,95 und 99,989 Prozent sinken würde. Diese Zahlen können jetzt als Service-Level-Ziel für die Netzwerkorganisation verwendet werden. Sie können einen Mehrwert erzielen, indem Sie die Verfügbarkeit im System messen und feststellen, welcher Prozentsatz der Nichtverfügbarkeit auf die oben genannten sechs Bereiche zurückzuführen ist. So kann das Unternehmen Anbieter, Betreiber, Prozesse und Mitarbeiter angemessen bewerten. Diese Zahl kann auch verwendet werden, um Erwartungen innerhalb des Unternehmens zu definieren. Wenn die Zahl nicht akzeptabel ist, dann budgetieren Sie zusätzliche Ressourcen, um das gewünschte Niveau zu erreichen.
Es kann für Netzwerkmanager nützlich sein, den Umfang der Ausfallzeiten auf einer bestimmten Verfügbarkeitsstufe zu ermitteln. Die Anzahl der Ausfallzeiten (in Minuten) für einen Zeitraum von einem Jahr, abhängig von der Verfügbarkeit, beträgt:
Minuten Ausfallzeit in einem Jahr = 525600 - (Verfügbarkeitsstufe X 5256)
Wenn Sie die Verfügbarkeitsstufe von 99,95 Prozent verwenden, ergibt sich daraus ein Verhältnis von 525600 (99,95 X 5256) oder 262,8 Minuten Ausfallzeit. Für die obige Verfügbarkeitsdefinition entspricht dies der durchschnittlichen Ausfallzeit aller im Netzwerk vorhandenen Verbindungen.
-
Schritt 3: Erstellen von Anwendungsprofilen
Mithilfe von Anwendungsprofilen kann die Netzwerkorganisation die Anforderungen der Netzwerkservices für einzelne Anwendungen besser verstehen und definieren. Dadurch wird sichergestellt, dass das Netzwerk die individuellen Anwendungsanforderungen und Netzwerkservices insgesamt unterstützt. Anwendungsprofile können auch als dokumentierte Grundlage für die Unterstützung von Netzwerkservices dienen, wenn Anwendungs- oder Servergruppen auf das Netzwerk als Problem verweisen. Letztlich tragen Anwendungsprofile dazu bei, die Ziele des Netzwerkservice mit Anwendungs- oder Geschäftsanforderungen abzustimmen, indem Anwendungsanforderungen wie Leistung und Verfügbarkeit mit realistischen Zielen für Netzwerkservices oder aktuellen Einschränkungen verglichen werden. Dies ist nicht nur für das Service-Level-Management wichtig, sondern auch für das allgemeine Top-Down-Netzwerkdesign.
Erstellen Sie bei jeder Einführung neuer Anwendungen im Netzwerk Anwendungsprofile. Möglicherweise benötigen Sie eine Vereinbarung zwischen der IT-Anwendungsgruppe, den Serveradministrationsgruppen und dem Netzwerk, um die Erstellung von Anwendungsprofilen für neue und vorhandene Services durchzusetzen. Vollständige Anwendungsprofile für Geschäftsanwendungen und Systemanwendungen Geschäftsanwendungen können E-Mails, Dateiübertragungen, Internetnutzung, Bildgebung in der Medizin oder die Fertigung umfassen. Systemanwendungen können Softwareverteilung, Benutzerauthentifizierung, Netzwerk-Backup und Netzwerkmanagement umfassen.
Ein Netzwerkanalyst und eine Anwendungs- oder Serversupportanwendung sollten das Anwendungsprofil erstellen. Neue Anwendungen erfordern möglicherweise die Verwendung eines Protokollanalysators und eines WAN-Emulators mit verzögerter Emulation, um die Anwendungsanforderungen korrekt zu charakterisieren. So können Sie die erforderliche Bandbreite, maximale Verzögerung bei der Anwendungsverfügbarkeit und Jitter-Anforderungen ermitteln. Dies kann in einer Laborumgebung durchgeführt werden, sofern die erforderlichen Server vorhanden sind. In anderen Fällen, z. B. bei VoIP, sind Netzwerkanforderungen wie Jitter, Verzögerungen und Bandbreite gut veröffentlicht, sodass keine Labortests erforderlich sind. Ein Anwendungsprofil sollte die folgenden Elemente enthalten:
-
Anwendungsname
-
Art der Anwendung
-
Neue Anwendung?
-
Geschäftliche Bedeutung
-
Verfügbarkeitsanforderungen
-
Verwendete Protokolle und Ports
-
Geschätzte Benutzerbandbreite (Kbit/s)
-
Anzahl und Standort der Benutzer
-
Dateiübertragungsanforderungen (einschließlich Zeit, Volumen und Endpunkte)
-
Auswirkungen von Netzwerkausfällen
-
Verzögerungs-, Jitter- und Verfügbarkeitsanforderungen
Ziel des Anwendungsprofils ist es, die Geschäftsanforderungen für die Anwendung, die geschäftskritische Bedeutung und die Netzwerkanforderungen wie Bandbreite, Verzögerung und Jitter zu verstehen. Darüber hinaus sollte die Netzwerkorganisation die Auswirkungen von Netzwerkausfällen verstehen. In einigen Fällen ist ein Neustart von Anwendungen oder Servern erforderlich, der zu allgemeinen Anwendungsausfallzeiten führt. Wenn Sie das Anwendungsprofil fertig stellen, können Sie die Netzwerkfunktionen insgesamt vergleichen und die Service-Level des Netzwerks mit den Geschäfts- und Anwendungsanforderungen abstimmen.
Schritt 4: Definition von Verfügbarkeits- und Leistungsstandards
Verfügbarkeits- und Leistungsstandards bestimmen die Serviceerwartungen für das Unternehmen. Diese können für verschiedene Bereiche des Netzwerks oder für bestimmte Anwendungen definiert werden. Die Leistung kann auch in Bezug auf Round-Trip-Verzögerung, Jitter, maximalen Durchsatz, Bandbreitenanforderungen und allgemeine Skalierbarkeit definiert werden. Zusätzlich zur Festlegung der Serviceerwartungen sollte das Unternehmen auch die Festlegung der einzelnen Servicestandards vornehmen, damit Benutzer und IT-Gruppen, die mit Netzwerken arbeiten, den Servicestandard und dessen Verhältnis zu den Anwendungs- oder Serververwaltungsanforderungen vollständig verstehen. Benutzer und IT-Gruppen sollten auch verstehen, wie der Servicestandard gemessen werden kann.
Die Ergebnisse früherer Servicelevel-Definitionsschritte helfen bei der Erstellung des Standards. Zu diesem Zeitpunkt sollte die Netzwerkorganisation ein klares Verständnis der aktuellen Risiken und Einschränkungen im Netzwerk, ein Verständnis des Anwendungsverhaltens sowie eine theoretische Verfügbarkeitsanalyse oder eine Baseline für Verfügbarkeit entwickeln.
-
Definieren Sie die geografischen oder Anwendungsbereiche, in denen Service-Standards angewendet werden.
Dies kann Bereiche wie das Campus-LAN, WAN für den Hausgebrauch, Extranet oder Partnerverbindungen umfassen. In einigen Fällen kann das Unternehmen innerhalb eines Bereichs unterschiedliche Service Level Ziele haben. Dies ist bei Unternehmen oder Service Provider nicht ungewöhnlich. In diesen Fällen ist es nicht unüblich, auf Basis individueller Service-Anforderungen unterschiedliche Service-Level-Standards zu erstellen. Diese können innerhalb eines geografischen Gebiets oder Dienstleistungsbereichs als Gold-, Silber- und Bronzestandards klassifiziert werden.
-
Definieren Sie die Service-Standardparameter.
Verfügbarkeit und Round-Trip-Verzögerungen sind die gebräuchlichsten Netzwerkdienststandards. Maximaler Durchsatz, minimale Bandbreitenbindung, Jitter, akzeptable Fehlerraten und Skalierbarkeit können bei Bedarf ebenfalls eingeschlossen werden. Gehen Sie beim Überprüfen des Service-Parameters für Messmethoden vorsichtig vor. Unabhängig davon, ob der Parameter zu einem SLA übergeht oder nicht, sollte die Organisation darüber nachdenken, wie der Service-Parameter gemessen oder gerechtfertigt werden kann, wenn Probleme oder Service-Unstimmigkeiten auftreten.
Nachdem Sie die Servicebereiche und Serviceparameter definiert haben, erstellen Sie mithilfe der Informationen aus den vorherigen Schritten eine Matrix mit Servicestandards. Außerdem müssen Bereiche definiert werden, die Benutzer und IT-Gruppen verwirrend sein können. Beispielsweise ist die maximale Antwortzeit bei einem Round-Trip-Ping sehr unterschiedlich, wenn Sie die Eingabetaste an einem Remote-Standort für eine bestimmte Anwendung drücken. Die nachfolgende Tabelle zeigt die Leistungsziele in den Vereinigten Staaten.
| Netzwerkbereich | Verfügbarkeitsziel | Messmethode | Durchschnittliche Reaktionszeit des Netzwerks | Maximale Reaktionszeit akzeptiert | Messmethode für die Reaktionszeit |
|---|---|---|---|---|---|
| LAN | 99.99% | Betroffene Benutzerminuten | Unter 5 ms | 10 ms | Round-Trip Ping-Antwort |
| WAN | 99.99% | Betroffene Benutzerminuten | Unter 100 ms (Round-Trip Ping) | 150 ms | Round-Trip Ping-Antwort |
| Kritisches WAN und Extranet | 99.99% | Betroffene Benutzerminuten | Unter 100 ms (Round-Trip Ping) | 150 ms | Round-Trip Ping-Antwort |
Schritt 5: Netzwerkservice definieren
Dies ist der letzte Schritt hin zu einem grundlegenden Service-Level-Management. Sie definiert die reaktiven und proaktiven Prozesse und Netzwerkverwaltungsfunktionen, die Sie implementieren, um Service-Level-Ziele zu erreichen. Das endgültige Dokument wird in der Regel als betrieblicher Support-Plan bezeichnet. Die meisten Anwendungs-Supportpläne beinhalten nur reaktive Supportanforderungen. In Hochverfügbarkeitsumgebungen muss das Unternehmen auch proaktive Managementprozesse in Betracht ziehen, die zur Isolierung und Behebung von Netzwerkproblemen verwendet werden, bevor Benutzerserviceanrufe eingeleitet werden. Insgesamt sollte das endgültige Dokument
-
Beschreiben Sie den reaktiven und proaktiven Prozess zur Erreichung des Service Level Goals.
-
Verwaltung des Serviceprozesses
-
Messung des Serviceziels und Serviceprozesses.
Dieser Abschnitt enthält Beispiele für reaktive Service-Definitionen und proaktive Service-Definitionen, die viele Service Provider und Unternehmen berücksichtigen sollten. Ziel bei der Erstellung der Service-Level-Definitionen ist die Erstellung eines Service, der die Verfügbarkeits- und Leistungsziele erfüllt. Um dies zu erreichen, muss der Service unter Berücksichtigung der aktuellen technischen Einschränkungen, des Verfügbarkeitsbudgets und der Anwendungsprofile erstellt werden. Insbesondere sollte das Unternehmen einen Service definieren und erstellen, der Probleme konsistent und schnell erkennt und innerhalb der vom Verfügbarkeitsmodell zugewiesenen Zeiträume löst. Darüber hinaus muss ein Service definiert werden, der potenzielle Serviceprobleme, die sich auf Verfügbarkeit und Leistung auswirken, schnell erkennen und beheben kann, wenn diese ignoriert werden.
Sie erreichen das gewünschte Servicelevel nicht über Nacht. Mängel wie mangelndes Fachwissen, aktuelle Prozessbeschränkungen oder unzureichende Personalausstattung können die Organisation daran hindern, die gewünschten Standards oder Ziele zu erreichen, selbst nach den vorherigen Servicestudien-Analyseschritten. Es gibt keine präzise Methode, um den gewünschten Service-Level genau auf die gewünschten Ziele abzustimmen. Um dies zu ermöglichen, sollte die Organisation die Servicestandards messen und die Service-Parameter messen, die zur Unterstützung der Servicestandards verwendet werden. Wenn das Unternehmen die Serviceziele nicht erreicht, sollte es sich um Servicekennzahlen bemühen, um das Problem besser zu verstehen. In vielen Fällen können Budgetierungen vorgenommen werden, um die Support-Services zu verbessern und notwendige Verbesserungen vorzunehmen, um die gewünschten Serviceziele zu erreichen. Im Laufe der Zeit kann das Unternehmen verschiedene Anpassungen vornehmen, entweder an das Serviceziel oder an die Servicedefinition, um Netzwerkservices und geschäftliche Anforderungen abzustimmen.
Ein Unternehmen kann beispielsweise eine Verfügbarkeit von 99 Prozent erreichen, wenn das Ziel bei 99,9 Prozent Verfügbarkeit deutlich höher war. Bei der Betrachtung der Service- und Support-Kennzahlen stellten Vertreter des Unternehmens fest, dass der Austausch von Hardware ca. 24 Stunden dauerte, weitaus länger als die ursprüngliche Schätzung, da die Organisation nur vier veranschlagt hatte. Darüber hinaus wurde festgestellt, dass proaktive Verwaltungsfunktionen ignoriert und redundante Netzwerkgeräte nicht repariert wurden. Sie fanden auch heraus, dass sie nicht über das Personal verfügten, um Verbesserungen vorzunehmen. Infolgedessen hat die Organisation nach der Erwägung, die aktuellen Service-Ziele zu senken, für zusätzliche Ressourcen gesorgt, die zur Erreichung des gewünschten Service-Levels erforderlich sind.
Die Service-Definitionen sollten sowohl reaktive Support-Definitionen als auch proaktive Definitionen enthalten. Reaktive Definitionen definieren, wie das Unternehmen auf Probleme reagieren wird, nachdem sie anhand von Beschwerde- oder Netzwerkmanagementfunktionen identifiziert wurden. Proaktive Definitionen beschreiben, wie das Unternehmen potenzielle Netzwerkprobleme identifizieren und beheben kann, einschließlich Reparaturen defekter Standby-Netzwerkkomponenten, Fehlererkennung sowie Kapazitätsschwellen und Upgrades. Die folgenden Abschnitte enthalten Beispiele für reaktive und proaktive Service-Level-Definitionen.
Reaktive Service Level Definitions
Die folgenden Service-Level-Bereiche werden in der Regel mithilfe von Help-Desk-Datenbankstatistiken und regelmäßigen Audits gemessen. Diese Tabelle zeigt ein Beispiel für den Schweregrad eines Problems in einem Unternehmen. Beachten Sie, dass das Diagramm keine Informationen zum Behandeln von Anfragen für neue Services enthält, die von einem SLA oder einer zusätzlichen Anwendungsprofilerstellung und einer Performance-if-Analyse behandelt werden können. In der Regel kann es sich bei Schweregrad 5 um eine Anforderung für einen neuen Service handeln, wenn diese über denselben Support-Prozess bearbeitet wird.
| Schweregrad 1 | Schweregrad 2 | Schweregrad 3 | Schweregrad 4 |
|---|---|---|---|
| Schwere geschäftliche Auswirkungen auf LAN-Benutzer oder Serversegment, Ausfall des kritischen WAN-Standorts | Hohe geschäftliche Auswirkungen durch Verlust oder Beeinträchtigung, mögliche Problemumgehung im Campus LAN inaktiv; 5-99 Benutzer betroffenen inländischen WAN-Standort am internationalen WAN-Standort, was die kritische Leistung beeinträchtigt | Bestimmte Netzwerkfunktionen gehen verloren oder werden beeinträchtigt, z. B. der Verlust der Redundanz bei der Campus-LAN-Leistung, die die LAN-Redundanz beeinträchtigt hat | Eine funktionale Abfrage oder ein Fehler, die keine geschäftlichen Auswirkungen auf das Unternehmen hat |
Wenn der Schweregrad des Problems definiert wurde, definieren oder untersuchen Sie den Supportprozess, um Service-Antwortdefinitionen zu erstellen. Im Allgemeinen erfordern Service-Response-Definitionen eine mehrstufige Support-Struktur, gepaart mit einem Helpdesk-Software-Support-System, um Probleme über Trouble-Tickets nachzuverfolgen. Für jede Priorität, die Anzahl der Anrufe nach Priorität und die Qualität von Antwort und Problembehebung sollten Kennzahlen zur Verfügung stehen. Zur Definition des Supportprozesses können die Ziele jeder Support-Stufe im Unternehmen sowie deren Rollen und Verantwortlichkeiten definiert werden. So kann das Unternehmen die Ressourcenanforderungen und den Umfang der Fachkenntnisse für jede Support-Stufe besser verstehen. Die folgende Tabelle enthält ein Beispiel für eine Organisation für mehrstufigen Support mit Richtlinien zur Problembehebung.
| Support-Tier | Verantwortlichkeit | Ziele |
|---|---|---|
| Tier-1-Support | Helpdesk-Support in Vollzeit Anrufe beantworten, Support-Tickets einrichten, Probleme bis zu 15 Minuten bearbeiten, Ticket dokumentieren und an den entsprechenden Level-2-Support eskalieren | Auflösung von 40 % der eingehenden Anrufe |
| Tier-2-Support | Warteschlangenüberwachung, Netzwerkmanagement, Workstation-Überwachung Platzieren Sie Trouble-Tickets für Software identifizierte Probleme Implementieren Sie Anrufe von Tier-1-, Anbieter- und Tier-3-Eskalationen Nehmen Sie Anrufe von der Anrufzugehörigkeit bis zur Problembehebung an. | Auflösung von 100 % der Anrufe auf Ebene 2 |
| Tier-3-Support | Muss Tier 2 für alle Probleme der Priorität 1 sofortigen Support bereitstellen Vereinbarung zur Unterstützung aller Probleme, die durch Tier 2 nicht gelöst werden, innerhalb des SLA-Auflösungszeitraums | Keine direkten Probleme |
Im nächsten Schritt wird die Matrix für die Serviceantwort- und Serviceauflösungsservicedefinition erstellt. Damit werden Ziele für die schnelle Behebung von Problemen festgelegt, einschließlich Hardware-Ersatz. Es ist wichtig, in diesem Bereich Ziele festzulegen, da sich die Reaktionszeit und Wiederherstellungszeit der Services direkt auf die Netzwerkverfügbarkeit auswirken. Die Problemlösungszeiten sollten auch mit dem Verfügbarkeitsbudget übereinstimmen. Wenn eine große Anzahl schwerwiegender Probleme im Verfügbarkeitsbudget nicht berücksichtigt wird, kann das Unternehmen die Ursache dieser Probleme und eine mögliche Lösung ermitteln. Siehe folgende Tabelle:
| Schweregrad des Problems | Helpdesk-Antwort | Tier-2-Antwort | Tier 2 vor Ort | Hardware-Ersatz | Problembehebung |
|---|---|---|---|---|---|
| 1 | Sofortige Eskalation zu Tier 2, Network Operations Manager | 5 Minuten | 2 Stunden | 2 Stunden | 4 Stunden |
| 2 | Sofortige Eskalation zu Tier 2, Network Operations Manager | 5 Minuten | 4 Stunden | 4 Stunden | 8 Stunden |
| 3 | 15 Minuten | 2 Stunden | 12 Stunden | 24 Stunden | 36 Stunden |
| 4 | 15 Minuten | 4 Stunden | 3 Tage | 3 Tage | 6 Tage |
Erstellen Sie neben der Serviceantwort und der Serviceauflösung eine Matrix für die Eskalation. Die Eskalationsmatrix trägt dazu bei, sicherzustellen, dass die verfügbaren Ressourcen auf Probleme fokussiert sind, die den Service stark beeinträchtigen. Im Allgemeinen konzentrieren sich Analysten, wenn sie sich auf die Lösung von Problemen konzentrieren, selten darauf, zusätzliche Ressourcen für das Problem bereitzustellen. Wenn festgelegt wird, wann zusätzliche Ressourcen benachrichtigt werden sollen, wird das Problembewusstsein im Management gefördert und kann im Allgemeinen zu künftigen proaktiven oder präventiven Maßnahmen führen. Siehe folgende Tabelle:
| Verstrichene Zeit | Schweregrad 1 | Schweregrad 2 | Schweregrad 3 | Schweregrad 4 |
|---|---|---|---|---|
| 5 Minuten | Network Operations Manager, Tier-3-Support, Director Network Operations Manager | |||
| 1 Stunde | Update für Network Operations Manager, Tier-3-Support, Director Network | Update für Network Operations Manager, Tier-3-Support, Director Network | ||
| 2 Stunden | Eskalieren zu VP, Update zu Director, Operations Manager | |||
| 4 Stunden | Ursachenanalyse für VP, Director, Operations Manager, Tier-3-Support, ungelöste Benachrichtigung des CEO erforderlich | Eskalieren zu VP, Update zu Director, Operations Manager | ||
| 24 Stunden | Network Operations Manager | |||
| 5 Tage | Network Operations Manager |
Bisher lag der Schwerpunkt der Service-Level-Definitionen auf der Reaktion der Betriebsunterstützungsorganisation auf Probleme, nachdem diese identifiziert wurden. Die Betriebsorganisationen haben jahrelang betriebliche Unterstützungspläne mit ähnlichen Informationen erstellt. Was in diesen Fällen jedoch fehlt, ist, wie das Unternehmen Probleme identifizieren wird und welche Probleme es identifizieren wird. Intelligentere Netzwerkorganisationen haben versucht, dieses Problem zu beheben, indem sie einfach Ziele für den Prozentsatz der Probleme schufen, die proaktiv identifiziert werden, im Gegensatz zu Problemen, die reaktiv durch Benutzerproblemmeldung oder -beschwerden identifiziert werden.
Die nächste Tabelle zeigt, wie ein Unternehmen proaktive Support-Funktionen und proaktiven Support insgesamt messen möchte.
| Netzwerkbereich | Proaktives Problem Identification Ratio | Verhältnis zur reaktiven Problemerkennung |
|---|---|---|
| LAN | 80 % | 20 % |
| WAN | 80 % | 20 % |
Dies ist ein guter Anfang bei der Definition proaktiver Support-Definitionen, da sie einfach und relativ einfach zu messen ist, besonders wenn proaktive Tools automatisch Support-Tickets generieren. Dadurch können Sie die Tools/Informationen für das Netzwerkmanagement auf die proaktive Behebung von Problemen konzentrieren, anstatt die Ursache zu ermitteln. Das Hauptproblem bei dieser Methode ist jedoch, dass sie keine proaktiven Support-Anforderungen definiert. Dies führt in der Regel zu Lücken in den proaktiven Support-Management-Funktionen und zusätzlichen Verfügbarkeitsrisiken.
Proaktive Service-Level-Definitionen
Eine umfassendere Methodik zur Erstellung von Service-Level-Definitionen enthält detailliertere Informationen zur Überwachung des Netzwerks und zur Reaktion der Betriebsorganisation auf die Schwellenwerte für Netzwerkmanagement-Workstations (NMS), die 7x24-basiert sind. Angesichts der schieren Anzahl an Management Information Base (MIB)-Variablen und der Menge an verfügbaren Netzwerkmanagement-Informationen, die für den Netzwerkzustand relevant sind, scheint dies eine unmögliche Aufgabe zu sein. Es könnte auch sehr teuer und ressourcenintensiv sein. Leider hindern diese Einwände viele daran, eine proaktive Service-Definition zu implementieren, die von Natur aus einfach, relativ einfach zu befolgen ist und nur auf die größten Verfügbarkeits- oder Leistungsrisiken im Netzwerk anwendbar ist. Wenn ein Unternehmen dann in grundlegenden proaktiven Service-Definitionen Wert sieht, können im Laufe der Zeit weitere Variablen ohne signifikante Auswirkungen hinzugefügt werden, sofern Sie einen schrittweisen Ansatz implementieren.
Integrieren Sie den ersten Bereich proaktiver Service-Definitionen in allen Operations Support Plänen. Die Service-Definition legt einfach fest, wie die Operations Group proaktiv Netzwerkbedingungen oder Verbindungsausfälle in verschiedenen Bereichen des Netzwerks identifizieren und darauf reagieren wird. Ohne diese Definition (oder Managementunterstützung) kann das Unternehmen variable Unterstützung, unrealistische Benutzererwartungen und letztendlich eine geringere Netzwerkverfügbarkeit erwarten.
In der folgenden Tabelle wird veranschaulicht, wie eine Organisation eine Dienstdefinition für Link-/Geräte-Ausfallbedingungen erstellen kann. Das Beispiel zeigt ein Unternehmen, das je nach Tageszeit und Netzwerkbereich möglicherweise unterschiedliche Benachrichtigungs- und Antwortanforderungen hat.
| Netzwerkgerät oder Link Down | Erkennungsmethode | 5 x 8 Benachrichtigung | 7 x 24 Benachrichtigung | 5 x 8-Auflösung | Auflösung 7 x 24 |
|---|---|---|---|---|---|
| Core-LAN | SNMP-Geräte- und Link-Polling, Traps | NOC erstellt Trouble Ticket, Seite LAN-Duty Pager | Automatische Seite LAN-Dienstpager, LAN-Zollbeamter erstellt Trouble Ticket für Core-LAN-Warteschlange | LAN-Analyst innerhalb von 15 Minuten vom NOC zugewiesen, Reparatur gemäß Servicereaktionsdefinition | Prioritäten 1 und 2 Sofortige Ermittlung und Problembehebung Prioritäten 3 und 4 Warteschlange für morgendliche Problemlösung |
| Internes WAN | SNMP-Geräte- und Link-Polling, Traps | NOC erstellt Trouble Ticket, Seite WAN Duty Pager | WAN-Dienstpager für automatische Seite erstellt Trouble Ticket für WAN-Warteschlange | WAN-Analyst innerhalb von 15 Minuten vom NOC zugewiesen, Reparatur gemäß Definition der Service-Antwort | Prioritäten 1 und 2 Sofortige Ermittlung und Problembehebung Prioritäten 3 und 4 Warteschlange für morgendliche Problemlösung |
| Extranet | SNMP-Geräte- und Link-Polling, Traps | NOC erstellt Trouble Ticket, Page Partner Duty Pager | Partner Duty Pager für automatische Seiten erstellt Trouble Ticket für Partner Queue | Partner-Analyst innerhalb von 15 Minuten vom NOC zugewiesen, Reparatur gemäß Definition der Service-Antwort | Prioritäten 1 und 2 für sofortige Untersuchung und Lösung; Prioritäten 3 und 4 Warteschlange für die morgendliche Problembehebung |
Die übrigen proaktiven Service-Level-Definitionen können in zwei Kategorien unterteilt werden: Netzwerkfehler und Kapazitäts-/Leistungsprobleme. Nur ein kleiner Teil der Netzwerkorganisationen verfügt in diesen Bereichen über Service-Level-Definitionen. Infolgedessen werden diese Probleme ignoriert oder sporadisch behandelt. Dies mag in einigen Netzwerkumgebungen gut sein, für Hochverfügbarkeitsumgebungen ist jedoch in der Regel ein konsistentes, proaktives Servicemanagement erforderlich.
Netzwerkunternehmen haben aus mehreren Gründen häufig mit proaktiven Service-Definitionen zu kämpfen. Dies liegt vor allem daran, dass sie keine Anforderungsanalyse für proaktive Service-Definitionen basierend auf Verfügbarkeitsrisiken, dem Verfügbarkeitsbudget und Anwendungsproblemen durchgeführt haben. Dies führt zu unklaren Anforderungen für proaktive Service-Definitionen und unklare Vorteile, insbesondere da zusätzliche Ressourcen erforderlich sein können.
Der zweite Grund besteht darin, die Menge an proaktivem Management, die mit vorhandenen oder neu definierten Ressourcen durchgeführt werden kann, abzuwägen. Generieren Sie nur Warnmeldungen, die schwerwiegende potenzielle Auswirkungen auf Verfügbarkeit oder Leistung haben. Sie müssen auch ein Management der Ereigniskorrelation oder Prozesse in Betracht ziehen, um sicherzustellen, dass nicht mehrere proaktive Support-Tickets für dasselbe Problem generiert werden. Der letzte Grund, warum Unternehmen Schwierigkeiten haben können, ist, dass die Erstellung neuer proaktiver Warnmeldungen oft eine anfängliche Flut von Nachrichten auslösen kann, die zuvor nicht erkannt wurden. Die operative Gruppe muss auf diese anfängliche Flut von Problemen und zusätzliche kurzfristige Ressourcen vorbereitet sein, um diese zuvor unerkannten Bedingungen zu beheben oder zu beheben.
Die erste Kategorie proaktiver Service-Level-Definitionen sind Netzwerkfehler. Netzwerkfehler können in Systemfehler wie Software- oder Hardwarefehler, Protokollfehler, Fehler bei der Medienkontrolle, Genauigkeitsfehler und Umgebungswarnungen unterteilt werden. Die Entwicklung einer Service-Level-Definition beginnt mit einem allgemeinen Verständnis, wie diese Problembedingungen erkannt werden, wer sie ansieht und was geschieht, wenn sie auftreten. Fügen Sie der Service-Level-Definition bei Bedarf bestimmte Nachrichten oder Probleme hinzu. Möglicherweise benötigen Sie auch zusätzliche Arbeit in den folgenden Bereichen, um Ihren Erfolg sicherzustellen:
-
Support-Verantwortlichkeiten für Tier 1, Tier 2 und Tier 3
-
Abwägung der Priorität der Netzwerkmanagementinformationen mit der proaktiven Arbeit, die die Betriebsgruppe effektiv verarbeiten kann
-
Schulungsanforderungen, um sicherzustellen, dass Support-Mitarbeiter effektiv mit definierten Warnmeldungen umgehen können
-
Methoden zur Ereigniskorrelation, um sicherzustellen, dass nicht mehrere Trouble-Tickets für dasselbe Ursachenproblem generiert werden
-
Dokumentation über spezifische Meldungen oder Warnungen, die bei der Identifizierung von Ereignissen auf Ebene 1-Support-Ebene helfen
Die folgende Tabelle zeigt eine Beispiel-Service-Level-Definition für Netzwerkfehler, die eine klare Vorstellung davon gibt, wer für proaktive Netzwerkfehlerwarnungen verantwortlich ist, wie das Problem identifiziert wird und was geschieht, wenn das Problem auftritt. Die Organisation kann noch weitere Anstrengungen wie oben definiert benötigen, um den Erfolg sicherzustellen.
s.
| Fehlerkategorie | Erkennungsmethode | Grenzwert | Maßnahmen |
|---|---|---|---|
| Software-Fehler (durch Software erzwungene Abstürze) | Tägliche Überprüfung von Syslog-Meldungen mithilfe des Syslog Viewer Fertig durch Tier-2-Support | Jedes Vorkommen für Vorkommen der Prioritäten 0, 1 und 2 Bei Vorkommen von mehr als 100 Vorkommen der Stufe 3 oder höher | Überprüfen Sie das Problem, erstellen Sie ein Trouble-Ticket, und senden Sie es, wenn ein neues Ereignis auftritt oder ein Problem Aufmerksamkeit erfordert. |
| Hardware-Fehler (Abstürze erzwungen durch Hardware) | Tägliche Überprüfung von Syslog-Meldungen mithilfe des Syslog Viewer Fertig durch Tier-2-Support | Jedes Vorkommen für Vorkommen der Prioritäten 0, 1 und 2 Bei Vorkommen von mehr als 100 Vorkommen der Stufe 3 oder höher | Überprüfen Sie das Problem, erstellen Sie ein Trouble-Ticket, und senden Sie es, wenn ein neues Ereignis auftritt oder ein Problem Aufmerksamkeit erfordert. |
| Protokollfehler (nur IP-Routing-Protokolle) | Tägliche Überprüfung von Syslog-Meldungen mithilfe des Syslog Viewer Fertig durch Tier-2-Support | Zehn Nachrichten pro Tag für Prioritäten 0, 1 und 2 Über 100 Vorkommen von Stufe 3 oder höher | Überprüfen Sie das Problem, erstellen Sie ein Trouble-Ticket, und senden Sie es, wenn ein neues Ereignis auftritt oder ein Problem Aufmerksamkeit erfordert. |
| Fehler bei der Medienkontrolle (nur FDDI, POS und Fast Ethernet) | Tägliche Überprüfung von Syslog-Meldungen mithilfe des Syslog Viewer Fertig durch Tier-2-Support | Zehn Nachrichten pro Tag für Prioritäten 0, 1 und 2 Über 100 Vorkommen von Stufe 3 oder höher | Überprüfen Sie das Problem, erstellen Sie ein Trouble-Ticket, und senden Sie es, wenn ein neues Ereignis auftritt oder ein Problem Aufmerksamkeit erfordert. |
| Umgebungsmeldungen (Strom und Temperatur) | Tägliche Überprüfung von Syslog-Meldungen mithilfe des Syslog Viewer Fertig durch Tier-2-Support | Jede Nachricht | Erstellung eines Trouble-Tickets und Versand neuer Probleme |
| Genauigkeitsfehler (Verbindungseingabefehler) | SNMP Polling in Abständen von 5 Minuten Schwellwerte, die vom NOC empfangen wurden | Eingabe- oder Ausgabefehler Ein Fehler in einem 5-Minuten-Intervall für eine Verbindung | Erstellung eines Trouble-Tickets für neue Probleme und Versand an Tier-2-Support |
Die andere Kategorie von proaktiven Service-Level-Definitionen gilt für Leistung und Kapazität. Das wahre Leistungs- und Kapazitätsmanagement umfasst Ausnahmemanagement, Baselining, Trendanalyse und "Was-wäre-wenn"-Analyse. Die Service-Level-Definition definiert lediglich die Schwellenwerte für die Ausnahme von Leistung und Kapazität sowie die durchschnittlichen Schwellenwerte, die eine Untersuchung oder ein Upgrade auslösen. Diese Schwellenwerte können dann in gewisser Weise für alle drei Leistungs- und Kapazitätsmanagementprozesse gelten.
Definitionen von Service-Level für Kapazität und Leistung können in mehrere Kategorien unterteilt werden: Netzwerkverbindungen, Netzwerkgeräte, End-to-End-Leistung und Anwendungsleistung. Die Entwicklung von Service-Level-Definitionen in diesen Bereichen erfordert fundierte technische Kenntnisse in Bezug auf spezifische Aspekte der Gerätekapazität, Medienkapazität, QoS-Merkmale und Anwendungsanforderungen. Aus diesem Grund empfehlen wir Netzwerkarchitekten, Leistungs- und kapazitätsbezogene Service-Level-Definitionen mit Anbietereingaben zu entwickeln.
Wie bei Netzwerkfehlern beginnt die Entwicklung einer Service-Level-Definition für Kapazität und Leistung mit einem allgemeinen Verständnis dafür, wie diese Problembedingungen erkannt werden, wer sie ansieht und was geschieht, wenn sie auftreten. Sie können der Service-Level-Definition bei Bedarf bestimmte Ereignisdefinitionen hinzufügen. Möglicherweise benötigen Sie auch zusätzliche Arbeit in den folgenden Bereichen, um Ihren Erfolg sicherzustellen:
-
Ein klares Verständnis der Leistungsanforderungen von Anwendungen
-
Detaillierte technische Untersuchung von Schwellenwerten, die aufgrund von geschäftlichen Anforderungen und Gesamtkosten für das Unternehmen sinnvoll sind
-
Anforderungen an Budgetzyklen und Upgrades außerhalb des Zyklus
-
Support-Verantwortlichkeiten für Tier 1, Tier 2 und Tier 3
-
Priorität und Kritikalität der Netzwerkmanagementinformationen, abgestimmt auf die proaktive Arbeit, die die Betriebsgruppe effektiv verarbeiten kann
-
Schulungsanforderungen, um sicherzustellen, dass die Support-Mitarbeiter die Meldungen oder Warnmeldungen verstehen und effektiv mit dem definierten Zustand umgehen können
-
Methoden oder Prozesse zur Ereigniskorrelation, um sicherzustellen, dass nicht mehrere Trouble-Tickets für dasselbe Problem generiert werden
-
Dokumentation über spezifische Meldungen oder Warnungen, die bei der Ereigniserkennung auf Ebene 1 der Support-Stufe helfen
Die folgende Tabelle zeigt eine Beispiel-Service-Level-Definition für die Link-Nutzung, die eine klare Vorstellung davon gibt, wer für proaktive Netzwerkfehlerwarnungen verantwortlich ist, wie das Problem identifiziert wird und was geschieht, wenn das Problem auftritt. Die Organisation muss möglicherweise noch weitere Anstrengungen unternehmen, um den Erfolg sicherzustellen.
| Netzwerkbereich/Medien | Erkennungsmethode | Grenzwert | Maßnahmen |
|---|---|---|---|
| Campus LAN-Backbone und Distribution-Links | SNMP Polling in Abständen von 5 Minuten RMON-Ausnahmenfallen auf Core- und Distribution-Links | 50 % Auslastung in 5-Minuten-Intervallen 90 % Auslastung über Ausnahmefallen | E-Mail-Benachrichtigung an die Performance E-Mail Alias Group zur Bewertung der QoS-Anforderungen oder zur Planung von Upgrades bei wiederkehrenden Problemen |
| Inländische WAN-Verbindungen | SNMP-Polling in Intervallen von 5 Minuten | 75 % Auslastung in Intervallen von 5 Minuten | E-Mail-Benachrichtigung an die Performance E-Mail Alias Group zur Bewertung der QoS-Anforderungen oder zur Planung von Upgrades bei wiederkehrenden Problemen |
| Extranet-WAN-Links | SNMP-Polling in Intervallen von 5 Minuten | 60 % Auslastung in Abständen von 5 Minuten | E-Mail-Benachrichtigung an die Performance E-Mail Alias Group zur Bewertung der QoS-Anforderungen oder zur Planung von Upgrades bei wiederkehrenden Problemen |
In der folgenden Tabelle werden die Service-Level-Definitionen für die Gerätekapazität und die Leistungsschwellen definiert. Stellen Sie sicher, dass Sie Schwellenwerte erstellen, die aussagekräftig und nützlich sind, um Netzwerkprobleme oder Verfügbarkeitsprobleme zu vermeiden. Dies ist ein sehr wichtiger Bereich, da nicht geprüfte Ressourcenprobleme auf der Gerätekontrollebene schwerwiegende Auswirkungen auf das Netzwerk haben können.
| Cisco 7500 | CPU, Arbeitsspeicher, Puffer | RMON-Benachrichtigung für SNMP-Polling in Intervallen von -5 Minuten für CPU | CPU in 5-Minuten-Intervallen bei 75 %, 99 % über RMON-Benachrichtigungsspeicher bei 50 % in 5-Minuten-Intervallen Puffern bei 99 % Auslastung | E-Mail-Benachrichtigungsfunktion an die E-Mail-Alias-Gruppe Performance und Kapazität, um Probleme zu beheben oder ein Upgrade der RMON CPU mit 99 % zu planen, Support-Ticket zu erstellen und Support-Pager auf Stufe 2 zu erstellen |
| Cisco Serie 2600 | CPU, Speicher | SNMP-Polling in Intervallen von 5 Minuten | CPU bei 75 % in 5-Minuten-Intervallen Speicher bei 50 % in 5-Minuten-Intervallen | E-Mail-Alias-Gruppe für Leistungs- und Kapazitätsinformationen per E-Mail senden, um Probleme zu beheben oder ein Upgrade zu planen |
| Catalyst 5000 | Backplane-Nutzung, Speicher | SNMP-Polling in Intervallen von 5 Minuten | Backplane mit 50 % Arbeitsspeicher bei 75 % Auslastung | E-Mail-Alias-Gruppe für Leistungs- und Kapazitätsinformationen per E-Mail senden, um Probleme zu beheben oder ein Upgrade zu planen |
| LightStream® 1010 ATM-Switch | CPU, Speicher | SNMP-Polling in Intervallen von 5 Minuten | CPU mit 65 % Arbeitsspeicher bei 50 % Auslastung | E-Mail-Alias-Gruppe für Leistungs- und Kapazitätsinformationen per E-Mail senden, um Probleme zu beheben oder ein Upgrade zu planen |
In der nächsten Tabelle werden die Service-Level-Definitionen für End-to-End-Leistung und -Kapazität definiert. Diese Schwellenwerte basieren im Allgemeinen auf Anwendungsanforderungen, können aber auch verwendet werden, um auf ein bestimmtes Netzwerkleistungs- oder Kapazitätsproblem hinzuweisen. Die meisten Unternehmen mit Service-Level-Definitionen für die Leistung erstellen nur eine Handvoll Leistungsdefinitionen, da die Messung der Leistung von jedem Punkt im Netzwerk bis zu jedem anderen Punkt erhebliche Ressourcen erfordert und einen hohen Netzwerk-Overhead verursacht. Diese End-to-End-Leistungsprobleme können auch bei Verbindungs- oder Gerätekapazitätsschwellen auftreten. Wir empfehlen allgemeine Definitionen nach geografischer Region. Einige kritische Sites oder Links können bei Bedarf hinzugefügt werden.
| Netzwerkbereich/Medien | Messmethode | Grenzwert | Maßnahmen |
|---|---|---|---|
| Campus-LAN | Kein Problem erwartet Komplizierte Messung der gesamten LAN-Infrastruktur | Reaktionszeit bei Round-Trip in 10 Millisekunden (oder weniger), jederzeit | E-Mail-Alias-Gruppe für Leistungs- und Kapazitätsinformationen per E-Mail senden, um das Problem zu beheben oder ein Upgrade zu planen |
| Inländische WAN-Verbindungen | Aktuelle Messung von SF nach NY und SF nach Chicago nur mit IPM-ICMP-Echo (Internet Performance Monitor) | 75 Millisekunden Reaktionszeit bei Round-Trip über einen Zeitraum von 5 Minuten | E-Mail-Benachrichtigung an die Performance-E-Mail-Alias-Gruppe zur Bewertung der QoS-Anforderungen oder zur Planung eines Upgrades bei wiederkehrenden Problemen |
| San Francisco bis Tokio | Aktuelle Messwerte von San Francisco bis Brüssel mithilfe von IPM und ICMP-Echos | 250 Millisekunden Reaktionszeit bei Round-Trip über einen Zeitraum von 5 Minuten | E-Mail-Benachrichtigung an die Performance-E-Mail-Alias-Gruppe zur Bewertung der QoS-Anforderungen oder zur Planung eines Upgrades bei wiederkehrenden Problemen |
| San Francisco bis Brüssel | Aktuelle Messwerte von San Francisco bis Brüssel mithilfe von IPM und ICMP-Echos | Reaktionszeit von 175 Millisekunden bei Round-Trip über einen Zeitraum von 5 Minuten | E-Mail-Benachrichtigung an die Performance-E-Mail-Alias-Gruppe zur Bewertung der QoS-Anforderungen oder zur Planung eines Upgrades bei wiederkehrenden Problemen |
Der letzte Bereich für Service-Level-Definitionen ist die Anwendungsleistung. Definitionen der Anwendungsleistung werden normalerweise von der Anwendungs- oder Serververwaltungsgruppe erstellt, da die Leistung und Kapazität der Server selbst wahrscheinlich der größte Faktor für die Anwendungsleistung ist. Netzwerkunternehmen können von enormen Vorteilen profitieren, wenn sie Service-Level-Definitionen für die Leistung von Netzwerkanwendungen erstellen:
-
Service-Level-Definitionen und -Messungen können dazu beitragen, Konflikte zwischen Gruppen zu vermeiden.
-
Service-Level-Definitionen für einzelne Anwendungen sind wichtig, wenn QoS für wichtige Anwendungen konfiguriert wird und der andere Datenverkehr als optional gilt.
Wenn Sie die Anwendungsleistung erstellen und messen möchten, ist es wahrscheinlich am besten, wenn Sie die Leistung nicht auf dem Server selbst messen. Dadurch kann zwischen Netzwerkproblemen und Anwendungs- oder Serverproblemen unterschieden werden. Verwenden Sie Sonden oder die Systemverfügbarkeitsagenten-Software, die auf Cisco Routern ausgeführt werden, und den Cisco IPM, um den Pakettyp und die Messfrequenz zu steuern.
Die folgende Tabelle zeigt eine einfache Service-Level-Definition für die Anwendungsleistung.
| Anwendung | Messmethode | Grenzwert | Maßnahmen |
|---|---|---|---|
| ERP-Anwendung (Enterprise Resource Planning) TCP-Port 1529 Brüssel an SF | Brüssel-San-Francisco mit IPM-Messport 1529 Round-Trip Performance Brüssel-Gateway zu SFO-Gateway 2 | Reaktionszeit von 175 Millisekunden bei Round-Trip über einen Zeitraum von 5 Minuten | E-Mail-Benachrichtigung an die Performance-E-Mail-Alias-Gruppe, um das Problem zu bewerten oder ein Upgrade für wiederkehrende Probleme zu planen |
| ERP-Anwendung TCP-Port 1529 Tokio an SF | Brüssel-San-Francisco mit IPM-Messport 1529 Round-Trip Performance Brüssel-Gateway zu SFO-Gateway 2 | 200 Millisekunden Reaktionszeit bei Round-Trip über einen Zeitraum von 5 Minuten | E-Mail-Benachrichtigung an die Performance-E-Mail-Alias-Gruppe, um das Problem zu bewerten oder ein Upgrade für wiederkehrende Probleme zu planen |
| Kundensupport-Anwendung TCP-Port 1702 Sydney zu SF | Sydney nach San Francisco mit IPM-Messport 1702 Round-Trip Performance Sydney-Gateway zu SFO-Gateway 1 | 250 Millisekunden Reaktionszeit bei Round-Trip über einen Zeitraum von 5 Minuten | E-Mail-Benachrichtigung an die Performance-E-Mail-Alias-Gruppe, um das Problem zu bewerten oder ein Upgrade für wiederkehrende Probleme zu planen |
Schritt 6: Metriken erfassen und überwachen
Die Definition der Service-Level allein ist wertlos, es sei denn, das Unternehmen sammelt Kennzahlen und überwacht den Erfolg. Definieren Sie beim Erstellen einer kritischen Service-Level-Definition, wie der Service-Level gemessen und gemeldet wird. Durch die Messung des Service-Levels wird bestimmt, ob das Unternehmen seine Ziele erreicht, und es wird auch die Ursache von Verfügbarkeits- oder Leistungsproblemen ermittelt. Berücksichtigen Sie auch das Ziel bei der Auswahl einer Methode zum Messen der Service-Level-Definition. Weitere Informationen finden Sie unter Erstellen und Pflegen von SLAs.
Zur Überwachung der Servicelevel ist die Abhaltung einer regelmäßigen Überprüfungstagung, normalerweise jeden Monat, zur Erörterung des regelmäßigen Dienstes erforderlich. Besprechen Sie alle Kennzahlen und ob sie den Zielen entsprechen. Wenn sie nicht konform sind, ermitteln Sie die Ursache des Problems und implementieren Verbesserungen. Sie sollten auch aktuelle Initiativen und Fortschritte bei der Verbesserung einzelner Situationen behandeln.
Erstellen und Pflegen von SLAs
Service-Level-Definitionen sind ein hervorragender Baustein, da sie dazu beitragen, eine konsistente QoS im gesamten Unternehmen zu schaffen und die Verfügbarkeit zu verbessern. Der nächste Schritt sind SLAs, die eine Verbesserung darstellen, da sie Geschäftsziele und Kostenanforderungen direkt an die Servicequalität anpassen. Das gut konstruierte SLA dient dann als Modell für Effizienz, Qualität und Synergie zwischen der Benutzer-Community und der Support-Gruppe, indem klare Prozesse und Verfahren für Netzwerkprobleme oder -probleme beibehalten werden.
SLAs bieten mehrere Vorteile:
-
SLAs schaffen eine bidirektionale Verantwortlichkeit für den Service, d. h. Benutzer und Anwendungsgruppen sind ebenfalls für den Netzwerkservice verantwortlich. Wenn sie nicht dazu beitragen, ein SLA für einen bestimmten Service zu erstellen und die geschäftlichen Auswirkungen mit der Netzwerkgruppe zu kommunizieren, dann sind sie möglicherweise tatsächlich für das Problem verantwortlich.
-
Mithilfe von SLAs können Standardtools und -ressourcen ermittelt werden, die zur Erfüllung der geschäftlichen Anforderungen erforderlich sind. Die Entscheidung, wie viele Personen und welche Tools ohne SLAs verwendet werden sollen, ist häufig eine Schätzung des Budgets. Der Service ist möglicherweise übermäßig konzipiert, was zu Überinvestitionen oder zu einem Mangel an Technikern führt, was zu unerreichten Geschäftszielen führt. Die Anpassung der SLAs trägt dazu bei, dieses ausgewogene optimale Niveau zu erreichen.
-
Das dokumentierte SLA schafft ein klareres Mittel zur Festlegung von Service Level Erwartungen.
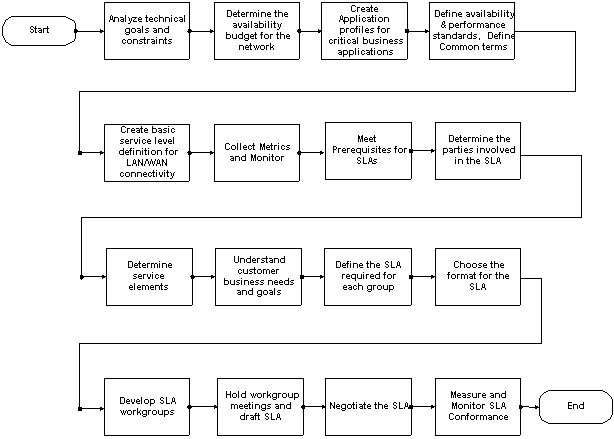
Wir empfehlen die folgenden Schritte zum Erstellen von SLAs, nachdem Service-Level-Definitionen erstellt wurden: Wir empfehlen die folgenden Schritte zum Erstellen von SLAs, nachdem Service-Level-Definitionen erstellt wurden:
7. Erfüllen Sie die Voraussetzungen für SLAs.
8. Bestimmen Sie die am SLA beteiligten Parteien.
9. Bestimmen von Serviceelementen
10. Analyse der geschäftlichen Anforderungen und Ziele des Kunden
11. Definieren Sie den für jede Gruppe erforderlichen SLA.
13. Entwicklung von SLA-Arbeitsgruppen
14. Abhalten von Arbeitsgruppenbesprechungen und Erstellen des SLAs
16. Messen und Überwachen der SLA-Konformität
Schritt 7: Erfüllung der Voraussetzungen für SLAs
Experten in der Entwicklung von IT SLAs identifizierten drei Voraussetzungen für einen erfolgreichen SLA. Leider können Organisationen, die diese Ziele nicht erreichen, Probleme mit dem SLA-Prozess erwarten und sollten die potenziellen Probleme im Zusammenhang mit dem SLA-Prozess berücksichtigen. Die Nichtimplementierung von SLAs ist nicht nachteilig, wenn die Netzwerkorganisation Service-Level-Definitionen erstellen kann, die die allgemeinen Geschäftsanforderungen erfüllen. Voraussetzung für den SLA-Prozess sind:
-
Ihr Unternehmen muss eine serviceorientierte Kultur haben.
Das Unternehmen muss die Bedürfnisse der Kunden in den Vordergrund stellen. Sie benötigen eine von oben nach unten gerichtete Priorität für den Service, die ein umfassendes Verständnis der Kundenanforderungen und -wahrnehmungen ermöglicht. Durchführung von Umfragen zur Kundenzufriedenheit und kundenorientierten Serviceinitiativen
Ein weiterer Service-Indikator kann sein, dass das Unternehmen die Zufriedenheit von Service oder Support als Unternehmensziel angibt. Dies ist nicht ungewöhnlich, da IT-Abteilungen heute entscheidend mit dem Unternehmenserfolg verknüpft sind.
Die Servicekultur ist wichtig, da es beim SLA-Prozess im Wesentlichen um Verbesserungen geht, die auf Kundenanforderungen und Geschäftsanforderungen basieren. Wenn Unternehmen dies in der Vergangenheit nicht getan haben, wird der SLA-Prozess für sie schwierig.
-
Kunden-/Geschäftsinitiativen müssen alle IT-Aktivitäten vorantreiben.
Die Vision bzw. die Mission Statements des Unternehmens müssen auf Kunden- und Geschäftsinitiativen abgestimmt sein, die dann alle IT-Aktivitäten, einschließlich SLAs, vorantreiben. Es wird zu häufig ein Netzwerk eingerichtet, um ein bestimmtes Ziel zu erreichen. Dennoch verliert die Netzwerkgruppe das Ziel und die nachfolgenden geschäftlichen Anforderungen aus den Augen. In diesen Fällen wird ein festgelegtes Budget für das Netzwerk bereitgestellt, das möglicherweise übermäßig auf aktuelle Anforderungen reagieren oder die Anforderungen in hohem Maße unterschätzen kann, was zu Fehlern führt.
Wenn Kunden-/Geschäftsinitiativen an IT-Aktivitäten ausgerichtet sind, kann die Netzwerkorganisation leichter auf neue Anwendungsbereitstellungen, neue Services oder andere geschäftliche Anforderungen reagieren. Die Beziehung und der gemeinsame Gesamtschwerpunkt auf die Erreichung der Unternehmensziele sind vorhanden, und alle Gruppen werden als Team ausgeführt.
-
Sie müssen sich zum SLA-Prozess und -Vertrag verpflichten.
Zunächst muss die Verpflichtung bestehen, den SLA-Prozess zu erlernen, um effektive Vereinbarungen zu entwickeln. Zweitens müssen Sie die Service-Anforderungen des Vertrags erfüllen. Erwarten Sie nicht, leistungsstarke SLAs zu erstellen, ohne dass alle beteiligten Personen einen wesentlichen Beitrag und Engagement leisten. Diese Verpflichtung muss auch vom Management und allen Personen, die mit dem SLA-Prozess verbunden sind, übernommen werden.
Schritt 8: Bestimmung der am SLA beteiligten Parteien
SLAs auf Unternehmensebene hängen stark von Netzwerkelementen, Serververwaltungselementen, Helpdesk-Support, Anwendungselementen und Geschäfts- oder Benutzeranforderungen ab. Normalerweise wird die Verwaltung aus jedem Bereich in den SLA-Prozess einbezogen. Dieses Szenario funktioniert gut, wenn das Unternehmen grundlegende reaktive Support-SLAs erstellt. Unternehmen mit höheren Verfügbarkeitsanforderungen benötigen möglicherweise technische Unterstützung während des SLA-Prozesses, um bei Problemen wie dem Verfügbarkeitsbudget, Leistungsbeschränkungen, der Erstellung von Anwendungsprofilen oder proaktiven Verwaltungsfunktionen behilflich zu sein. Für ein proaktiveres SLA-Management empfehlen wir ein technisches Team von Netzwerkarchitekten und Anwendungsarchitekten. Die technische Unterstützung kann die Verfügbarkeits- und Leistungsfähigkeiten des Netzwerks und die Anforderungen, die zur Erreichung bestimmter Ziele erforderlich sind, wesentlich genauer angleichen.
Service-Provider-SLAs beinhalten in der Regel keine Benutzereingaben, da sie ausschließlich zum Zweck der Erzielung von Wettbewerbsvorteilen für andere Service Provider erstellt wurden. In einigen Fällen wird die obere Führungsebene diese SLAs auf einem sehr hohen Verfügbarkeits- oder Hochleistungs-Level erstellen, um ihren Service zu fördern und interne Ziele für interne Mitarbeiter bereitzustellen. Andere Service Provider werden sich auf die technischen Aspekte der Verbesserung der Verfügbarkeit konzentrieren, indem sie strenge Service Level Definitionen erstellen, die intern gemessen und verwaltet werden. In anderen Fällen erfolgen beide Anstrengungen gleichzeitig, aber nicht notwendigerweise zusammen oder mit denselben Zielen.
Die Auswahl der am SLA beteiligten Parteien sollte dann auf den Zielen des SLA basieren. Mögliche Ziele sind:
-
Reaktive Unterstützung der Geschäftsziele
-
Maximale Verfügbarkeit durch Definition proaktiver SLAs
-
Promotions oder Verkaufen von Services
Schritt 9: Bestimmen von Serviceelementen
Die SLAs für primäre Services/Support umfassen in der Regel viele Komponenten, darunter die Support-Stufe, die Messung, den Eskalationspfad für die SLA-Abstimmung und allgemeine Bedenken hinsichtlich des Budgets. Service-Elemente für Hochverfügbarkeitsumgebungen sollten sowohl proaktive Service-Definitionen als auch reaktive Ziele umfassen. Weitere Details sind:
-
Support-Geschäftszeiten vor Ort und Verfahren für Support außerhalb der Geschäftszeiten
-
Prioritätsdefinitionen, einschließlich Problemtyp, maximale Zeit für die Bearbeitung des Problems, maximale Zeit für die Problemlösung und Eskalationsverfahren
-
Zu unterstützende Produkte oder Services, nach Geschäftskritik geordnet
-
Unterstützung von Expertenerwartungen, Leistungsanforderungen, Statusberichten und Verantwortlichkeiten der Benutzer für die Problembehebung
-
Probleme und Anforderungen auf Support-Ebene für geografische oder Geschäftseinheiten
-
Methoden und Verfahren des Problem Management (Anrufverfolgungssystem)
-
Helpdesk-Ziele
-
Erkennung von Netzwerkfehlern und Serviceantwort
-
Messung und Reporting der Netzwerkverfügbarkeit
-
Messung und Reporting der Netzwerkkapazität und -leistung
-
Verfahren zur Konfliktlösung
-
Finanzierung des implementierten SLA
Netzwerk-Anwendungs- oder Service-SLAs haben möglicherweise zusätzliche Anforderungen, die auf den Anforderungen der Benutzergruppe und der geschäftskritischen Punkte basieren. Die Netzwerkorganisation muss genau auf diese geschäftlichen Anforderungen hören und spezielle Lösungen entwickeln, die in die allgemeine Support-Struktur passen. Die Einbindung in die allgemeine Support-Kultur ist von entscheidender Bedeutung, da es wichtig ist, keinen Premium-Service zu erstellen, der nur für bestimmte Personen oder Gruppen gedacht ist. In vielen Fällen können diese zusätzlichen Anforderungen in Lösungskategorien eingeordnet werden. Ein Beispiel hierfür ist eine Platinum-, Gold- und Silver-Lösung, die den geschäftlichen Anforderungen entspricht. Im Folgenden finden Sie Beispiele für SLA-Anforderungen für spezifische Geschäftsanforderungen.
Hinweis: Support-Struktur, Eskalationspfad, Helpdesk-Verfahren, Messung und Prioritätsdefinitionen sollten weitgehend gleich bleiben, um eine konsistente Servicekultur aufrechtzuerhalten und zu verbessern.
-
Bandbreitenanforderungen und -funktionen für Bursts
-
Leistungsanforderungen
-
QoS-Anforderungen und -Definitionen
-
Verfügbarkeitsanforderungen und Redundanz für die Erstellung einer Lösungsmatrix
-
Überwachungs- und Berichterstattungsanforderungen, Methodik und Verfahren
-
Upgrade-Kriterien für Anwendungs-/Service-Elemente
-
Finanzierung von Anforderungen aus dem Haushalt oder Methodik für die Verrechnung von Lasten
Sie können beispielsweise Lösungskategorien für die WAN-Standortverbindung erstellen. Die Platin-Lösung wird mit zwei T1-Diensten für den Standort bereitgestellt. Ein anderer Carrier würde jede T1-Leitung bereitstellen. An diesem Standort sind zwei Router konfiguriert, sodass bei Ausfall eines T1- oder Routers der Standort nicht ausfällt. Der Gold-Service hätte zwei Router, aber Backup Frame Relay wird verwendet. Diese Lösung kann für die Dauer des Ausfalls eine begrenzte Bandbreite aufweisen. Die Silver-Lösung hätte nur einen Router und einen Carrier-Service. Jede dieser Lösungen würde für unterschiedliche Prioritätsebenen für Problem Tickets in Betracht gezogen. Einige Unternehmen benötigen möglicherweise eine Platin- oder Gold-Lösung, wenn für einen Ausfall ein Ticket der Priorität 1 oder 2 erforderlich ist. Kundenorganisationen können dann das erforderliche Servicelevel finanzieren. Die folgende Tabelle zeigt ein Beispiel für eine Organisation, die je nach geschäftlichem Bedarf an Extranet-Konnektivität drei Servicelevel anbietet.
| Lösung | Platinum | Gold | Silber |
|---|---|---|---|
| Geräte | Redundante Router für WAN-Verbindungen | Redundanter Router für Backup am Core-Standort | Keine Geräteredundanz |
| WAN | Redundante T1-Verbindung, mehrere Carrier | T1-Verbindung mit Frame Relay-Backup | Keine WAN-Redundanz |
| Bandbreitenanforderungen und Bursts | Redundantes T1 mit Lastverteilung für Burst | Non-Load-Sharing, Frame-Relay-Backup nur für kritische Anwendungen; Nur Frame Relay 64K CIR | Bis zu T1 |
| Leistung | Konsistente Round-Trip-Reaktionszeit von 100 ms (oder weniger) | Reaktionszeit: 100 ms oder weniger erwartet 99,9 % | Reaktionszeit: 100 ms oder weniger erwartet 99 % |
| Verfügbarkeitsanforderung | 99.99% | 99.95% | 99.9% |
| Helpdesk-Priorität nach unten | Priorität 1: Ausfall geschäftskritischer Services | Priorität 2: Betriebsunterbrechung | Priorität 3: Geschäftsverbindung ausfallen |
Schritt 10: Analyse der geschäftlichen Anforderungen und Ziele von Kunden
Dieser Schritt verleiht dem SLA-Entwickler eine Menge Glaubwürdigkeit. Wenn die Anforderungen der verschiedenen Geschäftsbereiche verstanden werden, wird das ursprüngliche SLA-Dokument den geschäftlichen Anforderungen und dem gewünschten Ergebnis deutlich näher kommen. Versuchen Sie, die Kosten von Ausfallzeiten für den Kundenservice zu verstehen. Schätzung in Bezug auf Produktivitätsverlust, Umsatz und Geschäftswert des Kunden. Bedenken Sie, dass selbst einfache Verbindungen mit wenigen Personen den Umsatz erheblich beeinflussen können. Stellen Sie in diesem Fall sicher, dass Sie dem Kunden die möglichen Verfügbarkeits- und Leistungsrisiken erklären, damit das Unternehmen das erforderliche Servicelevel besser versteht. Wenn Sie diesen Schritt verpassen, verlangen viele Kunden möglicherweise eine hundertprozentige Verfügbarkeit.
Der SLA-Entwickler sollte auch die Geschäftsziele und das Wachstum des Unternehmens verstehen, um Netzwerk-Upgrades, Workloads und Budgetierung zu unterstützen. Es ist auch hilfreich, die Anwendungen zu verstehen, die verwendet werden. Hoffentlich verfügt das Unternehmen über Anwendungsprofile für jede Anwendung, aber wenn nicht, erwägen Sie eine technische Bewertung der Anwendung, um netzwerkbezogene Probleme zu ermitteln.
Schritt 11: Definieren des für jede Gruppe erforderlichen SLA
Zu den primären Support-SLAs gehören wichtige Geschäftseinheiten und Funktionsgruppen, z. B. Netzwerkbetrieb, Serverbetrieb und Support-Gruppen für Anwendungen. Diese Gruppen sollten sowohl nach geschäftlichen Anforderungen als auch nach ihrem Anteil am Support-Prozess erkannt werden. Die Vertretung vieler Gruppen hilft auch, eine gerechte Gesamt-Support-Lösung ohne individuelle Gruppenpräferenz oder Priorität zu schaffen. Dies kann eine Support-Organisation dazu veranlassen, einzelnen Gruppen erstklassigen Service bereitzustellen. Dies kann die allgemeine Servicekultur des Unternehmens untergraben. Ein Kunde könnte beispielsweise darauf bestehen, dass seine Anwendung die wichtigste Anwendung im Unternehmen ist, wenn die Kosten für Ausfallzeiten für diese Anwendung in Bezug auf Umsatzverluste, Produktivitätsverluste und den Verlust des Firmenwerts deutlich geringer sind als die Kosten für andere Anwendungen.
Unterschiedliche Geschäftsbereiche innerhalb des Unternehmens haben unterschiedliche Anforderungen. Ein Ziel des Netzwerk-SLA sollte die Vereinbarung eines allgemeinen Formats sein, das verschiedene Service-Level berücksichtigt. Diese Anforderungen sind in der Regel Verfügbarkeit, QoS, Leistung und MTTR. Im Netzwerk-SLA werden diese Variablen durch die Priorisierung von Geschäftsanwendungen für eine potenzielle QoS-Optimierung, die Definition von Help-Desk-Prioritäten für MTTR verschiedener netzwerkrelevanter Probleme und die Entwicklung einer Lösungsmatrix, die die unterschiedlichen Verfügbarkeits- und Leistungsanforderungen unterstützt, behandelt. Ein Beispiel für eine einfache Lösungsmatrix für ein Unternehmen könnte etwa in der folgenden Tabelle dargestellt werden. Sie können Informationen zu Verfügbarkeit, QoS und Leistung hinzufügen.
| Geschäftsbereich | Anwendungen | Kosten von Ausfallzeiten | Problempriorität nach unten | Server-/Netzwerkanforderungen |
|---|---|---|---|---|
| Fertigung | ERP | Hoch | 1 | Höchste Redundanz |
| Kundensupport | Kundenbetreuung | Hoch | 1 | Höchste Redundanz |
| Technik | Dateiserver, ASIC-Design | Mittel | 2 | LAN-Core-Redundanz |
| Marketing | Dateiserver | Mittel | 2 | LAN-Core-Redundanz |
Schritt 12: Wählen Sie das Format des SLA aus.
Das Format für das SLA kann je nach Gruppenwunsch oder organisatorischen Anforderungen variieren. Im Folgenden finden Sie eine empfohlene Beispielübersicht für das Netzwerk-SLA:
-
Zweck der Vereinbarung
-
Vertragsparteien, die am Abkommen teilnehmen
-
Ziele und Ziele einer Vereinbarung
-
-
Bereitstellung von Services und unterstützte Produkte
-
Helpdesk-Service und Anrufverfolgung
-
Definition des Schweregrads des Problems basierend auf den geschäftlichen Auswirkungen für MTTR-Definitionen
-
Geschäftskritische Service-Prioritäten für QoS-Definitionen
-
Definierte Lösungskategorien basierend auf Verfügbarkeits- und Leistungsanforderungen
-
Schulungsanforderungen
-
Anforderungen an die Kapazitätsplanung
-
Eskalationsanforderungen
-
Berichterstellung
-
Bereitstellung von Netzwerklösungen
-
Neue Lösungsanforderungen
-
Nicht unterstützte Produkte oder Anwendungen
-
-
Geschäftsrichtlinien
-
Support während der Geschäftszeiten
-
Support-Definitionen nach Geschäftsschluss
-
Feierabend
-
Telefonnummern
-
Workload-Prognose
-
Abrufauflösung
-
Service-Berechtigungskriterien
-
Verantwortlichkeiten für Benutzer- und Gruppensicherheit
-
-
Problemmanagement-Verfahren
-
Anrufeinleitung (benutzerdefiniert und automatisiert)
-
Verhältnis zwischen Reaktion und Anrufreparatur auf erster Ebene
-
Anrufnachverfolgung und Aufzeichnungspflichten
-
Verantwortlichkeiten des Anrufers
-
Problemdiagnose und Anrufschließungsanforderungen
-
Netzwerkmanagement-Problemerkennung und Servicereaktion
-
Kategorien oder Definitionen für die Problemlösung
-
Behandlung chronischer Probleme
-
Behandlung kritischer Probleme/Ausnahmeanrufe
-
-
Qualitätsziele für Services
-
Qualitätsdefinitionen
-
Messwertdefinitionen
-
Qualitätsziele
-
Durchschnittliche Zeit für die Initiierung der Problembehebung nach Priorität
-
Durchschnittliche Zeit zur Problembehebung nach Priorität
-
Durchschnittliche Zeit für den Austausch von Hardware nach Priorität
-
Netzwerkverfügbarkeit und -leistung
-
Verwaltung der Kapazität
-
Wachstumssteuerung
-
Qualitätsberichte
-
-
Personal und Budgets
-
Personalmodelle
-
Betriebsbudget
-
-
Vertragsunterzeichnung
-
Zeitplan für die Konformitätsüberprüfung
-
Leistungsberichte und -überprüfung
-
Abstimmung von Berichtsmetriken
-
Regelmäßige SLA-Updates
-
-
Genehmigungen
-
Anlagen und Exponate
-
Anrufflussdiagramme
-
Eskalationsmatrix
-
Übersicht über Netzwerklösungen
-
Berichtsbeispiele
-
Schritt 13: Entwicklung von SLA-Arbeitsgruppen
Der nächste Schritt besteht in der Identifizierung der Teilnehmer in der SLA-Arbeitsgruppe, einschließlich eines Gruppenleiters. Die Arbeitsgruppe kann Benutzer oder Manager aus Geschäftsbereichen oder Funktionsgruppen oder Vertreter aus einem geografischen Gebiet umfassen. Diese Personen kommunizieren SLA-Probleme mit ihren jeweiligen Arbeitsgruppen. Vorgesetzte und Entscheidungsträger, die sich auf wichtige SLA-Elemente einigen können, sollten teilnehmen. Diese Personen können sowohl Führungskräfte als auch technische Mitarbeiter umfassen, die bei der Definition technischer Aspekte im Zusammenhang mit dem SLA und bei der Entscheidungsfindung auf IT-Ebene helfen können (z. B. Helpdesk-Manager, Server Operations Manager, Anwendungsmanager und Netzwerkbetriebsmanager).
Die Netzwerk-SLA-Arbeitsgruppe sollte auch aus einer breiten Anwendungs- und Geschäftsdarstellung bestehen, um eine Einigung über einen Netzwerk-SLA zu erzielen, der viele Anwendungen und Services umfasst. Die Arbeitsgruppe sollte befugt sein, geschäftskritische Prozesse und Services für das Netzwerk sowie Verfügbarkeits- und Leistungsanforderungen für einzelne Services zu bewerten. Anhand dieser Informationen können Sie Prioritäten für unterschiedliche, geschäftsrelevante Problemtypen festlegen, geschäftskritischen Datenverkehr im Netzwerk priorisieren und Netzwerklösungen erstellen, die auf zukünftige Anforderungen abgestimmt sind.
Schritt 14: Abhalten von Arbeitsgruppenbesprechungen und Entwurf des SLA
Die Arbeitsgruppe sollte zunächst eine Arbeitsgruppencharter erstellen. In der Charta sollten die Ziele, Initiativen und Zeitrahmen für das SLA festgelegt werden. Anschließend sollte die Gruppe spezifische Aufgabenpläne entwickeln und Zeitpläne und Zeitpläne für die Entwicklung und Implementierung des SLA festlegen. Die Gruppe sollte auch den Berichterstattungsprozess entwickeln, um die Höhe der Unterstützung anhand der Förderkriterien zu messen. Der letzte Schritt besteht in der Erstellung des Entwurfs einer SLA-Vereinbarung.
Die Netzwerk-SLA-Arbeitsgruppe sollte zunächst einmal pro Woche zusammenkommen, um das SLA zu entwickeln. Nach der Erstellung und Genehmigung des SLA kann die Gruppe monatliche oder sogar vierteljährliche Sitzungen abhalten, um SLA-Updates zu erhalten.
Schritt 15: SLA verhandeln
Der letzte Schritt bei der Erstellung des SLA ist die endgültige Aushandlung und Unterzeichnung. Dieser Schritt umfasst:
-
Überarbeitung des Entwurfs
-
Aushandlung des Inhalts
-
Bearbeiten und Überarbeiten des Dokuments
-
Einholung der endgültigen Genehmigung
Dieser Zyklus der Überprüfung des Entwurfs, der Inhaltsverhandlung und der Durchführung von Änderungen kann mehrere Zyklen dauern, bevor die endgültige Version zur Genehmigung an das Management gesendet wird.
Aus Sicht des Netzwerkmanagers ist es wichtig, messbare Ergebnisse auszuhandeln. Sichern Sie Leistungs- und Verfügbarkeitsvereinbarungen mit anderen Unternehmen. Dies kann Qualitätsdefinitionen, Messdefinitionen und Qualitätsziele umfassen. Beachten Sie, dass ein zusätzlicher Service den zusätzlichen Kosten entspricht. Stellen Sie sicher, dass die Benutzergruppen verstehen, dass zusätzliche Servicelevel mehr kosten, und lassen Sie sie entscheiden, ob es sich um eine wichtige Geschäftsanforderung handelt. Sie können auf einfache Weise eine Kostenanalyse für viele Aspekte des SLA durchführen, z. B. für den Hardware-Ersatz.
Schritt 16: Messung und Überwachung der SLA-Konformität
Die Messung der SLA-Konformität und die Berichterstellung sind wichtige Aspekte des SLA-Prozesses, die dazu beitragen, langfristige Konsistenz und Ergebnisse zu gewährleisten. Generell empfehlen wir, dass alle wichtigen Komponenten eines SLA messbar sind und vor der SLA-Implementierung eine Messmethode eingerichtet wird. Halten Sie dann monatliche Meetings zwischen Benutzern und Support-Gruppen ab, um die Messwerte zu überprüfen, die Ursachen des Problems zu ermitteln und Lösungen vorzuschlagen, die die Service-Level-Anforderungen erfüllen oder sogar übertreffen. Dadurch wird der SLA-Prozess einem modernen Qualitätsverbesserungsprogramm ähnlich.
Im folgenden Abschnitt finden Sie weitere Informationen dazu, wie das Management innerhalb eines Unternehmens die SLAs und das gesamte Service-Level-Management bewerten kann.
Leistungsindikatoren für das Servicelevel-Management
Leistungsindikatoren für das Servicelevel-Management bieten einen Mechanismus zur Überwachung und Verbesserung von Service-Levels als Maß für Erfolg. So kann das Unternehmen schneller auf Serviceprobleme reagieren und Probleme, die sich auf die Services oder die Kosten von Ausfallzeiten in der Umgebung auswirken, besser verstehen. Wenn die Definitionen der Service-Level nicht gemessen werden, werden auch positive proaktive Arbeiten überflüssig, da das Unternehmen zu einer reaktiven Haltung gezwungen wird. Niemand wird sagen, dass der Dienst gut funktioniert, aber viele Benutzer sagen, dass der Dienst, wenn sie ihre Anforderungen nicht erfüllen.
Leistungsindikatoren für das Service-Level-Management sind daher eine Hauptanforderung für das Service-Level-Management, da sie die Mittel bereitstellen, um die bestehenden Service-Level vollständig zu verstehen und Anpassungen aufgrund aktueller Probleme vorzunehmen. Dies ist die Grundlage für proaktiven Support und Qualitätsverbesserungen. Wenn das Unternehmen eine Ursachenanalyse der Probleme durchführt und Qualitätsverbesserungen vornimmt, ist dies möglicherweise die beste Methode zur Verbesserung der Verfügbarkeit, Leistung und Servicequalität.
Betrachten Sie zum Beispiel das folgende reale Szenario. Unternehmen X erhielt zahlreiche Beschwerden von Benutzern, dass das Netzwerk häufig über längere Zeit nicht erreichbar war. Durch die Messung der Verfügbarkeit stellte das Unternehmen fest, dass nur wenige WAN-Standorte das größte Problem darstellen. Eine genauere Untersuchung dieser Erkenntnisse ergab, dass sich die meisten Probleme an einigen WAN-Standorten bestanden. Die Ursache wurde gefunden, und die Organisation löste das Problem. Anschließend setzte die Organisation die Service Level Ziele für die Verfügbarkeit fest und traf Vereinbarungen mit Benutzergruppen. Bei zukünftigen Messungen wurden Probleme schnell erkannt, da das SLA nicht eingehalten wurde. Anschließend wurde die Netzwerkgruppe als mit höherer Professionalität, Fachkenntnissen und einem allgemeinen Vorteil für das Unternehmen angesehen. Die Gruppe wechselte von reaktiv zu proaktiv in der Natur und trug zum Geschäftsergebnis bei.
Leider verfügen die meisten Netzwerkunternehmen heute nur über begrenzte Service-Level-Definitionen und keine Leistungsindikatoren. Infolgedessen verbringen sie den Großteil ihrer Zeit damit, auf Beschwerden oder Probleme von Nutzern zu reagieren, anstatt proaktiv die Ursache zu ermitteln und einen Netzwerkservice zu entwickeln, der die geschäftlichen Anforderungen erfüllt.
Verwenden Sie die folgenden SLA-Leistungsindikatoren, um den Erfolg des Service-Level-Management-Prozesses zu bestimmen:
-
Dokumentierte Service-Level-Definition oder SLA, die Verfügbarkeit, Leistung, reaktive Service-Reaktionszeit, Problemlösungsziele und Problemeskalation umfasst
-
Leistungsindikatormetriken wie Verfügbarkeit, Leistung, Service-Reaktionszeit nach Priorität, Behebungszeit nach Priorität und andere messbare SLA-Parameter
-
Monatliche Meetings zum Service Level Management zur Überprüfung der Service Level Compliance und Implementierung von Verbesserungen
Dokumentation Service Level Agreement oder Service Level Definition
Der erste Leistungsindikator ist lediglich ein Dokument, in dem die SLA- oder Service-Level-Definition ausführlich beschrieben wird. Die primären Ziele der Service-Level-Definition sollten Verfügbarkeit und Leistung sein, da dies die primären Benutzeranforderungen sind.
Sekundäre Ziele sind wichtig, da sie dabei helfen zu definieren, wie die Verfügbarkeit oder das Leistungsniveau erreicht werden soll. Wenn das Unternehmen beispielsweise über aggressive Verfügbarkeits- und Leistungsziele verfügt, ist es wichtig, Probleme zu vermeiden und Probleme schnell zu beheben, wenn sie auftreten. Die sekundären Ziele helfen bei der Definition der Prozesse, die zum Erzielen der gewünschten Verfügbarkeit und Performance-Level erforderlich sind.
Reaktive sekundäre Ziele:
-
Reaktive Service-Reaktionszeit nach Anrufpriorität
-
Ziele zur Problemlösung oder MTTR
-
Eskalationsverfahren für Probleme.
Zu den proaktiven sekundären Zielen gehören:
-
Erkennung von Geräteausfall oder Verbindungsausfall
-
Erkennung von Netzwerkfehlern
-
Erkennung von Kapazitäts- oder Leistungsproblemen
Die Service-Level-Definition für primäre Ziele, Verfügbarkeit und Leistung sollte Folgendes umfassen:
Das Ziel
-
Wie das Ziel gemessen wird
-
Verantwortliche für die Messung der Verfügbarkeit und Leistung
-
Verantwortliche für Verfügbarkeits- und Leistungsziele
-
Nichtkonformitätsprozesse
Wenn möglich empfehlen wir, dass die für die Messung Verantwortlichen und die für die Ergebnisse Verantwortlichen unterschiedlich sind, um einen Interessenkonflikt zu verhindern. Von Zeit zu Zeit müssen Sie möglicherweise auch die Verfügbarkeitswerte aufgrund von Addon-/Move-/Change-Fehlern, nicht erkannten Fehlern oder Problemen bei der Verfügbarkeitsmessung anpassen. Die Service-Level-Definition kann auch einen Prozess zur Änderung der Ergebnisse enthalten, um die Genauigkeit zu verbessern und unsachgemäße Anpassungen zu vermeiden. Im nächsten Abschnitt finden Sie Methoden zur Messung von Verfügbarkeit und Leistung.
Die Service-Level-Definition für reaktive sekundäre Ziele legt fest, wie das Unternehmen nach der Identifizierung auf netzwerkweite oder IT-weite Probleme reagieren wird. Dazu gehören:
-
Problemprioritätsdefinitionen
-
Reaktive Service-Reaktionszeit nach Anrufpriorität
-
Ziele zur Problemlösung oder MTTR
-
Eskalationsverfahren für Probleme
Im Allgemeinen definieren diese Ziele, wer für Probleme zu einem bestimmten Zeitpunkt verantwortlich ist und in welchem Umfang die Verantwortlichen ihre aktuellen Aufgaben für die Arbeit an den definierten Problemen aufgeben sollten. Wie bei anderen Service-Level-Definitionen sollten im Service-Level-Dokument die Messung der Ziele, die für die Messung verantwortlichen Parteien und die Prozesse bei Nichteinhaltung beschrieben werden.
Die Service-Definition für proaktive sekundäre Ziele definiert, wie das Unternehmen proaktiven Support bereitstellt, einschließlich der Identifizierung von Netzwerkausfällen, Ausfall- oder Geräteausfällen, Netzwerkfehlern und Schwellenwerten für Netzwerkkapazität. Legen Sie Ziele fest, die ein proaktives Management fördern, da ein proaktives Qualitätsmanagement zur schnelleren Behebung von Problemen beiträgt. Dies wird in der Regel dadurch erreicht, dass das Ziel festgelegt wird, wie viele proaktive Vorgänge ohne Benutzerbenachrichtigung erstellt und behoben werden. Viele Unternehmen setzen eine Flagge für Helpdesk-Software, um proaktive Fälle im Vergleich zu reaktiven Fällen zu identifizieren. Das Service-Level-Dokument soll auch Informationen darüber enthalten, wie das Ziel gemessen wird, die für die Messung verantwortlichen Parteien und die Prozesse bei Nichteinhaltung der Vorgaben.
Leistungsindikatormetriken
Wir empfehlen stets, dass alle definierten Service-Level-Ziele messbar sind, sodass das Unternehmen Service-Level messen, Ursachen-Service-Probleme identifizieren kann, die das primäre Ziel von Verfügbarkeit und Leistung behindern, und Verbesserungen vornimmt, die auf spezifische Ziele ausgerichtet sind. Metriken sind insgesamt einfach ein Tool, mit dem Netzwerkmanager die Konsistenz der Servicelevel verwalten und Verbesserungen entsprechend der geschäftlichen Anforderungen vornehmen können.
Leider erfassen viele Unternehmen keine Verfügbarkeits-, Leistungs- und andere Kennzahlen. Unternehmen führen dies darauf zurück, dass sie nicht in der Lage sind, vollständige Genauigkeit, Kosten, Netzwerkgemeinkosten und verfügbare Ressourcen bereitzustellen. Diese Faktoren können sich auf die Fähigkeit zur Messung von Service-Levels auswirken, aber das Unternehmen sollte sich auf die allgemeinen Ziele konzentrieren, um Service-Levels zu verwalten und zu verbessern. Viele Unternehmen konnten kostengünstige Kennzahlen mit geringem Verwaltungsaufwand erstellen, die zwar keine vollständige Genauigkeit bieten, diese Hauptziele jedoch erfüllen.
Die Messung von Verfügbarkeit und Leistung ist ein Bereich, der bei Service-Level-Metriken oft vernachlässigt wird. Unternehmen, die mit diesen Metriken erfolgreich sind, verwenden zwei relativ einfache Methoden. Eine Methode besteht darin, ICMP-Pakete (Internet Control Message Protocol) von einem Kernstandort im Netzwerk an Kanten zu senden. Sie können auch mit dieser Methode eine Leistung abrufen. Unternehmen, die mit dieser Methode erfolgreich sind, gruppieren ähnliche Geräte auch in "Verfügbarkeitsgruppen", wie z. B. LAN-Geräte oder interne Außenstellen. Dies ist auch deshalb attraktiv, weil Unternehmen in der Regel unterschiedliche Service-Level-Ziele für unterschiedliche geografische oder geschäftskritische Bereiche des Netzwerks verfolgen. Auf diese Weise kann die Metrikgruppe alle Geräte mit der Verfügbarkeitsgruppe im Durchschnitt abrufen, um ein angemessenes Ergebnis zu erzielen.
Die andere erfolgreiche Methode zur Berechnung der Verfügbarkeit besteht in der Verwendung von Trouble Tickets und einer Messung, die als "Impacted User Minuten" (IUM) bezeichnet wird. Bei dieser Methode wird die Anzahl der Benutzer, die von einem Ausfall betroffen waren, berechnet und mit der Anzahl der Minuten des Ausfalls multipliziert. Wird als Prozentsatz der Gesamtminuten im Zeitraum ausgedrückt, kann dies leicht in Verfügbarkeit umgewandelt werden. In beiden Fällen kann es auch hilfreich sein, die Ursache von Ausfallzeiten zu ermitteln und zu messen, damit die Verbesserung gezielter eingesetzt werden kann. Zu den Ursachenkategorien gehören Hardwareprobleme, Softwareprobleme, Verbindungs- oder Carrier-Probleme, Probleme mit der Stromversorgung oder Umgebung, Änderungsfehler und Benutzerfehler.
Zu den messbaren reaktiven Support-Zielen gehören:
-
Reaktive Service-Reaktionszeit nach Anrufpriorität
-
Ziele zur Problemlösung oder MTTR
-
Eskalationszeit
Messen Sie reaktive Support-Ziele, indem Sie Berichte aus den Help Desk-Datenbanken generieren, darunter die folgenden Felder:
-
Zeitpunkt, zu dem ein Anruf ursprünglich gemeldet (oder in die Datenbank eingegeben) wurde
-
Uhrzeit, zu der der Anruf von einer Person angenommen wurde, die an dem Problem arbeitet
-
Die Zeit, zu der das Problem eskaliert wurde
-
Zeitpunkt des Problemabschlusses
Diese Kennzahlen können Einfluss auf das Management haben, um Probleme in die Datenbank durchgängig einzugeben und Probleme in Echtzeit zu aktualisieren. In einigen Fällen können Organisationen automatisch Support-Tickets für Netzwerkereignisse oder E-Mail-Anfragen generieren. So kann die Startzeit eines Problems genauer identifiziert werden. In Berichten, die anhand dieser Kennzahlen erstellt werden, werden Probleme normalerweise nach Priorität, Arbeitsgruppe und Einzelpersonen sortiert, um potenzielle Probleme zu ermitteln.
Die Messung proaktiver Support-Prozesse ist schwieriger, da Sie proaktive Arbeiten überwachen und eine Messung der Effektivität durchführen müssen. In diesem Bereich wurde wenig Arbeit geleistet. Es ist jedoch klar, dass nur ein kleiner Prozentsatz der Mitarbeiter Netzwerkprobleme einem Helpdesk melden wird. Wenn sie das Problem melden, wird es eindeutig Zeit dauern, das Problem zu erklären oder das Problem als netzwerkbezogen zu isolieren. Nicht alle proaktiven Fälle haben unmittelbare Auswirkungen auf die Verfügbarkeit und Leistung, auch wenn redundante Geräte oder Verbindungen ausfallen, nur geringe Auswirkungen auf die Endbenutzer.
Unternehmen, die proaktive Service Level Definitionen oder Vereinbarungen implementieren, tun dies aufgrund von Geschäftsanforderungen und potenziellen Verfügbarkeitsrisiken. Die Messung erfolgt dann anhand der Anzahl oder des Prozentsatzes der proaktiven Fälle, im Gegensatz zu reaktiven Fällen, die von den Benutzern generiert werden. Es empfiehlt sich, auch die Anzahl proaktiver Fälle in jedem Bereich zu messen. Diese Kategorien umfassen Geräte, Downlinks, Netzwerkfehler und Kapazitätsverletzungen. Einige Arbeiten können auch mithilfe von Verfügbarkeitsmodellen und proaktiven Fällen durchgeführt werden, um die Auswirkungen der Implementierung proaktiver Service-Definitionen auf die Verfügbarkeit zu ermitteln.
Prüfung des Servicelevel-Managements
Eine weitere Messgröße für den Erfolg des Service Level Managements ist die Überprüfung des Service Level Managements. Dies sollte unabhängig davon erfolgen, ob SLAs vorhanden sind. Führen Sie die Überprüfung des Servicelevel-Managements in einem monatlichen Meeting mit Personen durch, die für die Messung und Bereitstellung definierter Service-Level verantwortlich sind. Benutzergruppen können auch vorhanden sein, wenn SLAs beteiligt sind. Ziel der Besprechung ist es dann, die Leistung der gemessenen Service-Level-Definitionen zu überprüfen und Verbesserungen vorzunehmen.
Jedes Meeting sollte eine definierte Agenda haben, die Folgendes beinhaltet:
-
Überprüfung der gemessenen Service Level für den gegebenen Zeitraum
-
Überprüfung von Verbesserungsinitiativen für einzelne Bereiche
-
Aktuelle Service-Level-Metriken
-
Erörterung der erforderlichen Verbesserungen auf Basis der aktuellen Kennzahlen.
Im Laufe der Zeit kann das Unternehmen auch die Einhaltung der Service-Level verfolgen, um die Effektivität der Gruppe zu bestimmen. Dieser Prozess unterscheidet sich nicht von einem Qualitätskreis oder einem Qualitätsverbesserungsprozess. Das Meeting hilft dabei, einzelne Probleme zu beheben und Lösungen basierend auf der Ursache zu ermitteln.
Zusammenfassung der Servicelevel-Verwaltung
Zusammenfassend lässt sich sagen, dass das Service-Level-Management einem Unternehmen die Umstellung von einem reaktiven Support-Modell auf ein proaktives Support-Modell ermöglicht, bei dem die Netzwerkverfügbarkeit und -leistung durch die geschäftlichen Anforderungen und nicht durch die neuesten Probleme bestimmt werden. Dieser Prozess trägt dazu bei, ein Umfeld zu schaffen, in dem die Service-Level-Optimierung kontinuierlich weiterentwickelt und die Wettbewerbsfähigkeit gesteigert wird. Service Level Management ist auch die wichtigste Verwaltungskomponente für ein proaktives Netzwerkmanagement. Aus diesem Grund wird das Service-Level-Management in jeder Netzwerkplanungs- und Designphase dringend empfohlen und sollte mit jeder neu definierten Netzwerkarchitektur beginnen. So kann das Unternehmen Lösungen bei minimalen Ausfallzeiten oder Nachbearbeitungen sofort korrekt implementieren.
Zugehörige Informationen
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)