Upstream Scheduler Mode-Konfiguration für Cisco uBR CMTS
Inhalt
Einführung
In diesem Dokument wird die Konfiguration des Upstream-Scheduler-Modus für die Cisco Universal Broadband Router (uBR)-Serie von Cable Modem Termination Systems (CMTS) erläutert.
Dieses Dokument konzentriert sich auf Mitarbeiter, die mit dem Design und der Wartung von Hochgeschwindigkeits-Daten-over-Kabel-Netzwerken arbeiten, die Latenz- und jitter-empfindliche Upstream-Dienste nutzen, z. B. Voice- oder Video-over-IP.
Voraussetzungen
Anforderungen
Cisco empfiehlt, über Kenntnisse in folgenden Bereichen zu verfügen:
-
DOCSIS-Systeme (Data over Cable Service Interface Specification)
-
Die Cisco uBR-Serie von CMTS
Verwendete Komponenten
Die Informationen in diesem Dokument basieren auf den folgenden Software- und Hardwareversionen:
-
Cisco uBR CMTS
-
Cisco IOS® Software Release trainiert 12.3(13a)BC und 12.3(17a)BC
Hinweis: Informationen zu Änderungen an späteren Versionen der Cisco IOS Software finden Sie in den entsprechenden Versionshinweisen auf der Cisco.com-Website.
Konventionen
Weitere Informationen zu Dokumentkonventionen finden Sie unter Cisco Technical Tips Conventions (Technische Tipps zu Konventionen von Cisco).
Hintergrundinformationen
In einem DOCSIS-Netzwerk (Data-over-Cable Service Interface Specifications) steuert das CMTS die Zeitplanung und die Geschwindigkeit aller Upstream-Übertragungen, die Kabelmodems durchführen. Viele verschiedene Arten von Diensten mit unterschiedlichen Latenz-, Jitter- und Durchsatzanforderungen werden gleichzeitig in einem modernen DOCSIS-Netzwerk ausgeführt. Aus diesem Grund müssen Sie wissen, wie das CMTS entscheidet, wann ein Kabelmodem Upstream-Übertragungen für diese verschiedenen Diensttypen durchführen kann.
Dieses Whitepaper enthält:
-
Überblick über die Upstream-Planungsmodi in DOCSIS, einschließlich Best Effort, Unsolicited Grant Service (UGS) und Real-Time Polling Service (RTPS)
-
Betrieb und Konfiguration des DOCSIS-konformen Schedulers für Cisco uBR CMTS
-
Betrieb und Konfiguration des neuen Schedulers für Warteschlangenverwaltung mit niedriger Latenz für Cisco uBR CMTS
Upstream-Planung in DOCSIS
Ein DOCSIS-kompatibles CMTS kann über das Konzept eines Service-Datenflusses verschiedene Upstream-Planungsmodi für verschiedene Paket-Streams oder Anwendungen bereitstellen. Ein Servicestrom stellt entweder einen Upstream- oder einen Downstream-Datenfluss dar, den eine Service Flow ID (SFID) eindeutig identifiziert. Jeder Servicestrom kann über eigene QoS-Parameter (Quality of Service) verfügen, z. B. maximalen Durchsatz, garantierten Mindestdurchsatz und Priorität. Im Fall von Upstream-Service-Flows können Sie auch einen Planungsmodus angeben.
Sie können für jedes Kabelmodem mehr als einen Upstream-Servicestrom bereitstellen, um verschiedene Arten von Anwendungen zu unterstützen. Web- und E-Mail-Anwendungen können beispielsweise einen Service-Flow verwenden, Voice-over-IP (VoIP) einen anderen, und Internet-Spiele können einen weiteren Service-Flow verwenden. Um für jede dieser Anwendungen einen geeigneten Servicetyp bereitstellen zu können, müssen die Merkmale dieser Service-Datenflüsse unterschiedlich sein.
Das Kabelmodem und CMTS können mithilfe von Klassifizierungen die richtigen Arten von Datenverkehr in die entsprechenden Service-Flows leiten. Klassifizierungen sind spezielle Filter wie Zugriffslisten, die Paketeigenschaften wie UDP- und TCP-Portnummern zuordnen, um den geeigneten Servicestrom für Pakete zu bestimmen, die durchlaufen werden sollen.
In Abbildung 1 verfügt ein Kabelmodem über drei Upstream-Serviceflows. Der erste Servicestrom ist für Sprachdatenverkehr reserviert. Dieser Service-Flow bietet einen niedrigen maximalen Durchsatz, ist aber auch so konfiguriert, dass er eine geringe Latenz garantiert. Der nächste Servicestrom betrifft den allgemeinen Web- und E-Mail-Verkehr. Dieser Service-Fluss hat einen hohen Durchsatz. Der endgültige Service-Fluss ist für Peer-to-Peer (P2P)-Datenverkehr reserviert. Dieser Dienstfluss hat einen restriktiveren maximalen Durchsatz, um die Geschwindigkeit dieser Anwendung zu drosseln.
Abbildung 1: Kabelmodem mit drei Upstream-Dienstströmen 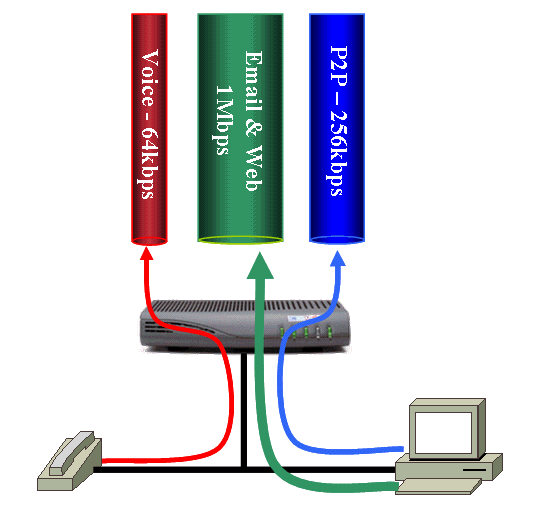
Serviceströme werden eingerichtet und aktiviert, wenn ein Kabelmodem erstmals online ist. Geben Sie in der DOCSIS-Konfigurationsdatei, die Sie zur Konfiguration des Kabelmodems verwenden, die Details der Service-Datenflüsse an. Bereitstellung von mindestens einem Service-Flow für den Upstream-Datenverkehr und einem anderen Service-Flow für den Downstream-Datenverkehr in einer DOCSIS-Konfigurationsdatei. Die ersten Upstream- und Downstream-Service-Flows, die Sie in der DOCSIS-Konfigurationsdatei angeben, werden als primäre Service-Flows bezeichnet.
Service-Flows können auch dynamisch erstellt und aktiviert werden, wenn ein Kabelmodem online ist. Dieses Szenario gilt im Allgemeinen für einen Service-Flow, der Daten entspricht, die zu einem VoIP-Telefonanruf gehören. Ein solcher Servicestrom wird erstellt und aktiviert, wenn ein Telefongespräch beginnt. Der Servicestrom wird dann deaktiviert und beim Beenden des Anrufs gelöscht. Wenn der Service-Fluss nur bei Bedarf vorhanden ist, können Sie Upstream-Bandbreitenressourcen sowie CPU-Last und Arbeitsspeicher des Systems speichern.
Kabelmodems können keine Upstream-Übertragungen durchführen. Stattdessen müssen Modems auf Anweisungen des CMTS warten, bevor sie Daten senden können, da jeweils nur ein Kabelmodem Daten auf einem Upstream-Kanal übertragen kann. Andernfalls können Übertragungen überlaufen und einander beschädigen. Die Anweisungen, wann ein Kabelmodem eine Übertragung vornehmen kann, stammen vom CMTS in Form einer MAP-Nachricht für die Bandbreitenzuweisung. Das Cisco CMTS sendet alle 2 Millisekunden eine MAP-Nachricht, um den Kabelmodems mitzuteilen, wann sie eine beliebige Übertragung durchführen können. Jede MAP-Nachricht enthält Informationen, die Modems genau anweisen, wann sie eine Übertragung durchführen, wie lange die Übertragung dauern kann und welche Art von Daten sie übertragen können. Datenübertragungen über Kabelmodem kollidieren daher nicht miteinander und verhindern Datenbeschädigungen. In diesem Abschnitt werden einige Möglichkeiten erläutert, wie ein CMTS feststellen kann, wann ein Kabelmodem die Berechtigung für eine Übertragung im Upstream erhalten soll.
Bester Aufwand
Best Effort Scheduling eignet sich für klassische Internetanwendungen ohne strenge Latenz- oder Jitter-Anforderungen. Beispiele für solche Anwendungen sind E-Mail, Web-Browsing oder die Übertragung von Peer-to-Peer-Dateien. Die Planung der bestmöglichen Leistung eignet sich nicht für Anwendungen, die eine garantierte Latenz oder Jitter erfordern, z. B. für Voice- oder Video-over-IP. Das liegt daran, dass unter überlasteten Bedingungen keine solche Garantie im bestmöglichen Modus geleistet werden kann. DOCSIS 1.0-Systeme ermöglichen nur diese Art der Planung.
Service-Datenflüsse mit bestmöglicher Leistung werden in der Regel in der DOCSIS-Konfigurationsdatei bereitgestellt, die einem Kabelmodem zugeordnet ist. Aus diesem Grund sind Best-Effort-Serviceströme in der Regel aktiv, sobald das Kabelmodem online ist. Der primäre Upstream-Servicestrom, d. h. der erste Upstream-Servicestrom, der in der DOCSIS-Konfigurationsdatei bereitgestellt wird, muss ein Dienstablauf im Best Effort-Stil sein.
Im DOCSIS 1.1/2.0-Modus werden folgende Parameter am häufigsten verwendet, um einen bestmöglichen Service-Fluss zu definieren:
-
Maximale dauerhafte Datenverkehrsrate (R)
Die maximale Dauer für dauerhaften Datenverkehr ist die maximale Rate, mit der Datenverkehr über diesen Service-Flow verarbeitet werden kann. Dieser Wert wird in Bits pro Sekunde ausgedrückt.
-
Maximaler Datenverkehrsausfall (B)
Die maximale Datenverkehrslast bezieht sich auf die Burst-Größe in Byte, die für den Token-Bucket-Durchsatzbegrenzer gilt, der Upstream-Durchsatzgrenzen erzwingt. Wenn kein Wert angegeben wird, gilt der Standardwert 3044, d. h. die Größe von zwei Full-Ethernet-Frames. Legen Sie für lange maximale kontinuierliche Datenverkehrsraten diesen Wert auf mindestens die maximale nachhaltige Datenverkehrsrate geteilt durch 64 fest.
-
Verkehrspriorität
Dieser Parameter bezieht sich auf die Priorität des Datenverkehrs in einem Dienstfluss von 0 (niedrigste) bis 7 (höchste Priorität). In den Upstream wird der gesamte ausstehende Datenverkehr für Dienstflüsse mit hoher Priorität vor der Übertragung des Datenverkehrs für Dienstflüsse mit niedriger Priorität geplant.
-
Mindestreservierungssatz
Dieser Parameter gibt einen garantierten Mindestdurchsatz in Bits pro Sekunde für den Service-Fluss an, ähnlich einer bestätigten Informationsrate (CIR). Die kombinierten reservierten Mindestraten für alle Service-Datenflüsse auf einem Kanal dürfen die verfügbare Bandbreite auf diesem Kanal nicht überschreiten. Andernfalls ist es unmöglich, die versprochenen Mindestreservesätze zu garantieren.
-
Maximale Anzahl verbundener Burst
Der maximale verbundene Burst ist die Größe (in Byte) der größten Übertragung verketteter Frames, die ein Modem im Namen des Dienstflusses erstellen kann. Wie dieser Parameter impliziert, kann ein Modem mehrere Frames in einem Durchbruch übertragen. Wenn dieser Wert nicht angegeben ist, gehen DOCSIS 1.0-Kabelmodems und ältere DOCSIS 1.1-Modems davon aus, dass für die verkettete Burst-Größe keine explizite Beschränkung festgelegt ist. Für Modems, die neuere Versionen der DOCSIS 1.1-Spezifikationen oder spätere Spezifikationen unterstützen, wird ein Wert von 1522 Byte verwendet.
Wenn ein Kabelmodem über Daten verfügt, die für einen Upstream-Servicestrom übertragen werden sollen, kann das Modem die Daten nicht einfach unverzüglich an das DOCSIS-Netzwerk weiterleiten. Das Modem muss einen Prozess durchlaufen, bei dem das Modem eine exklusive Upstream-Übertragungszeit vom CMTS anfordert. Dieser Anforderungsprozess stellt sicher, dass die Daten nicht mit den Übertragungen eines anderen Kabelmodems kollidieren, das mit demselben Upstream-Kanal verbunden ist.
Manchmal plant das CMTS bestimmte Zeiträume, in denen das CMTS Kabelmodems die Übertragung spezieller Nachrichten, so genannter Bandbreitenanforderungen, erlaubt. Die Bandbreitenanforderung ist ein sehr kleiner Frame, der Details zur Datenmenge enthält, die das Modem übertragen möchte, sowie eine Service Identifier (SID), die dem Upstream-Servicestrom entspricht, der die Daten übertragen muss. Das CMTS verwaltet eine interne Tabelle, die SID-Nummern mit Upstream-Service-Datenflüssen vergleicht.
Das CMTS plant Bandbreitenanfragen, wenn im Upstream keine weiteren Ereignisse geplant sind. Mit anderen Worten, der Scheduler bietet Möglichkeiten für Bandbreitenanfragen, wenn der Upstream-Scheduler keine bestmögliche Finanzhilfe, oder UGS-Gewährung oder eine andere Art von Zuschuss für einen bestimmten Punkt geplant hat. Wenn also ein Upstream-Kanal stark ausgelastet ist, gibt es weniger Möglichkeiten für Kabelmodems, Bandbreitenanforderungen zu übertragen.
Das CMTS stellt immer sicher, dass eine geringe Anzahl von Bandbreitenanfragen regelmäßig geplant wird, unabhängig davon, wie überlastet der Upstream-Kanal wird. Mehrere Kabelmodems können Bandbreitenanforderungen gleichzeitig übertragen und die Übertragungen der anderen übertragen. Um das Risiko von Kollisionen zu verringern, die Bandbreitenanforderungen beschädigen können, wird ein "Backoff and Retry"-Algorithmus verwendet. In den folgenden Abschnitten dieses Dokuments wird dieser Algorithmus erläutert.
Wenn der CMTS eine Bandbreitenanforderung von einem Kabelmodem empfängt, führt der CMTS folgende Aktionen durch:
-
Das CMTS verwendet die in der Bandbreitenanforderung empfangene SID-Nummer, um den Servicestrom zu untersuchen, dem die Bandbreitenanforderung zugeordnet ist.
-
Der CMTS verwendet dann den Token-Bucket-Algorithmus. Mit diesem Algorithmus kann der CMTS überprüfen, ob der Service-Fluss die vorgeschriebene maximale Dauerrate überschreitet, wenn der CMTS die angeforderte Bandbreite zuweist. Hier ist die Berechnung des Tokenbucket-Algorithmus:
Max(T) = T * (R/8) + B
wobei:
-
Max(T) gibt die maximale Anzahl von Bytes an, die im Service-Fluss über die Zeit T übertragen werden können.
-
T steht für die Zeit in Sekunden.
-
R gibt die maximale Dauer des Datenverkehrs für den Service-Fluss in Bit pro Sekunde an.
-
B ist der maximale Traffic-Burst für den Service-Fluss in Byte.
-
-
Wenn der CMTS feststellt, dass sich die Bandbreitenanforderung innerhalb der Durchsatzgrenzen befindet, stellt der CMTS dem Upstream-Scheduler die Details der Bandbreitenanforderung in die Warteschlange. Der Upstream-Scheduler entscheidet, wann die Bandbreitenanforderung erteilt wird.
Der Cisco uBR CMTS implementiert zwei Upstream-Scheduler-Algorithmen, den DOCSIS-kompatiblen Scheduler und den Scheduler für Warteschlangen mit niedriger Latenz. Weitere Informationen finden Sie im Abschnitt DOCSIS-konforme Terminplanung und Low Latency Queueing Scheduler.
-
Das CMTS enthält dann diese Details in der nächsten periodischen MAP-Nachricht für die Bandbreitenzuweisung:
-
Wenn das Kabelmodem übertragen kann.
-
Wie lange kann das Kabelmodem übertragen werden?
-
Bandbreitenanforderungs-Backoff und Retry Algorithm
Der Bandbreitenanforderungsmechanismus verwendet einen einfachen Backoff-Algorithmus, um das Risiko von Kollisionen zwischen mehreren Kabelmodems, die Bandbreitenanforderungen gleichzeitig übertragen, zu reduzieren, aber nicht vollständig zu eliminieren.
Ein Kabelmodem, das beschließt, eine Bandbreitenanforderung zu übertragen, muss zunächst auf eine zufällige Anzahl von Bandbreitenanfragen warten, bevor das Modem die Übertragung durchführt. Diese Wartezeit trägt dazu bei, die Wahrscheinlichkeit von Kollisionen zu verringern, die bei gleichzeitiger Übertragung von Bandbreitenanforderungen auftreten.
Zwei Parameter, die als Daten-Backoff-Start und als Daten-Backoff-Ende bezeichnet werden, bestimmen die zufällige Wartezeit. Die Kabelmodems erfassen diese Parameter als Teil der periodischen Upstream-Kanaldeskriptor (UCD)-Meldung. Das CMTS überträgt die UCD-Nachricht alle zwei Sekunden für jeden aktiven Upstream-Kanal.
Diese Backoff-Parameter werden als "Power of Two"-Werte ausgedrückt. Modems verwenden diese Parameter als Zweifache, um zu berechnen, wie lange gewartet wird, bevor Bandbreitenanforderungen übertragen werden. Beide Werte haben einen Bereich von 0 bis 15, und das Daten-Backoff-Ende muss größer oder gleich dem Start der Datensicherung sein.
Wenn ein Kabelmodem zum ersten Mal eine bestimmte Bandbreitenanforderung übertragen möchte, muss das Kabelmodem zunächst eine zufällige Zahl zwischen 0 und 2 wählen, um die Leistung des Daten-Backoff-Starts minus 1 zu erreichen. Wenn z. B. der Start des Daten-Backoff auf 3 festgelegt ist, muss das Modem eine Zufallszahl zwischen 0 und (23 - 1) = (8 - 1) = 7 auswählen.
Das Kabelmodem muss dann warten, bis die ausgewählte zufällige Anzahl an Bandbreitenanforderungs-Übertragungsmöglichkeiten ausgeschöpft ist, bevor das Modem eine Bandbreitenanforderung überträgt. Obwohl ein Modem aufgrund dieser Zwangspause keine Bandbreitenanforderung bei der nächsten verfügbaren Gelegenheit übertragen kann, verringert sich die Wahrscheinlichkeit einer Kollision mit der Übertragung eines anderen Modems.
Je höher der Startwert für den Daten-Backoff ist, desto geringer ist natürlich die Möglichkeit von Kollisionen zwischen Bandbreitenanforderungen. Größere Daten-Backoff-Startwerte bedeuten auch, dass Modems möglicherweise länger warten müssen, um Bandbreitenanforderungen zu übertragen. Daher nimmt die Upstream-Latenz zu.
Das CMTS enthält eine Bestätigung in der nächsten Übertragung der Bandbreitenzuweisung als MAP-Nachricht. Diese Bestätigung informiert das Kabelmodem, dass die Bandbreitenanforderung erfolgreich empfangen wurde. Diese Bestätigung kann:
-
entweder genau angeben, wann das Modem die Übertragung vornehmen kann
ODER
-
geben nur an, dass die Bandbreitenanforderung empfangen wurde und dass in einer zukünftigen MAP-Nachricht eine Zeit für die Übertragung festgelegt wird.
Wenn das CMTS keine Bestätigung der Bandbreitenanforderung in der nächsten MAP-Nachricht enthält, kann das Modem daraus schließen, dass die Bandbreitenanforderung nicht empfangen wurde. Diese Situation kann aufgrund einer Kollision oder eines Upstream-Geräuschs auftreten, oder weil der Service-Fluss die vorgeschriebene maximale Durchsatzrate überschreitet, wenn die Anforderung erteilt wird.
In beiden Fällen besteht der nächste Schritt für das Kabelmodem darin, die Bandbreitenanforderung erneut zu übertragen. Das Modem erhöht den Bereich, über den ein zufälliger Wert ausgewählt wird. Dazu fügt das Modem den Startwert für das Daten-Backoff hinzu. Wenn der Startwert für den Daten-Backoff beispielsweise 3 ist und der CMTS keine Bandbreitenanforderungsübertragung empfängt, wartet das Modem vor der erneuten Übertragung einen Zufallswert zwischen 0 und 15 Bandbreitenanfragen. Die Berechnung lautet wie folgt: 23+1 - 1 = 24 - 1 = 16 - 1 = 15
Der größere Wertebereich reduziert die Wahrscheinlichkeit einer weiteren Kollision. Wenn das Modem weitere Bandbreitenanforderungen verliert, erhöht das Modem den für jede erneute Übertragung genutzten Wert weiter um die Leistung von zwei, bis der Wert dem Wert für das Daten-Backoff-Ende entspricht. Die Leistung von zwei Geräten darf nicht größer sein als der Wert für das Daten-Backoff-Endgerät.
Das Modem überträgt eine Bandbreitenanforderung bis zu 16 Mal erneut, woraufhin das Modem die Bandbreitenanforderung verwirft. Diese Situation tritt nur unter extrem überlasteten Bedingungen auf.
Mit dem folgenden Befehl für die Kabelschnittstelle können Sie die Werte für den Start- und Datenrücklauf pro Kabel vor einem Cisco uBR CMTS konfigurieren:
Upstream-Upport-ID-Daten-Backoff Daten-Backoff-Start Daten-Backoff-End
Cisco empfiehlt, die Standardwerte für die Daten-Backoff-Start- und Daten-Back-End-Parameter (3 und 5) beizubehalten. Da das Scheduling-System "bestmöglicher Aufwand" konfliktbasiert ist, ist es für die Service-Abläufe nicht möglich, eine deterministische oder garantierte Upstream-Latenz oder Jitter bereitzustellen. Darüber hinaus können überlastete Bedingungen es unmöglich machen, einen bestimmten Durchsatz für einen bestmöglichen Service-Fluss zu garantieren. Sie können jedoch Service-Flow-Eigenschaften wie Priorität und minimale reservierte Rate verwenden. Mit diesen Eigenschaften kann der Servicestrom unter überlasteten Bedingungen den gewünschten Durchsatz erzielen.
Beispiel für den Backoff- und Retry-Algorithmus
Dieses Beispiel besteht aus vier Kabelmodems mit dem Namen A, B, C und D, die mit demselben Upstream-Kanal verbunden sind. Die Modems A, B und C werden gleichzeitig t0 genannt, um einige Daten im Upstream zu übertragen.
Hier ist der Start für die Datensicherung auf 2 und das Daten-Backoff-Ende auf 4 festgelegt. Der Bereich der Intervalle, aus denen die Modems ein Intervall auswählen, bevor sie erstmals versuchen, eine Bandbreitenanforderung zu übertragen, liegt zwischen 0 und 3. Die Berechnung lautet wie folgt:
(22 - 1) = (4 - 1) = 3 Intervalle.
Hier sehen Sie die Anzahl der Bandbreitenanfragen, die die drei Modems für eine Wartezeit von Zeit bis 0 auswählen.
-
Modem A: 1
-
Modem B: 2
-
Modem C: 1
Beachten Sie, dass Modem A und Modem C dieselbe Anzahl von Wartezeiten wählen.
Modem B wartet auf zwei Bandbreitenanfragen, die nach 0 angezeigt werden. Modem B überträgt dann die Bandbreitenanforderung, die vom CMTS empfangen wird. Modem A und Modem C warten auf 3 Bandbreitenanfragen, die nach 0 weitergeleitet werden. Die Modems A und C übertragen dann gleichzeitig Bandbreitenanforderungen. Diese beiden Bandbreitenanforderungen kollidieren und werden beschädigt. Daher erreicht keine der Anfragen erfolgreich das CMTS. Abbildung 2 zeigt diese Ereignisabfolge.
Abbildung 2: Beispiel für eine Bandbreitenanforderung, Teil 1 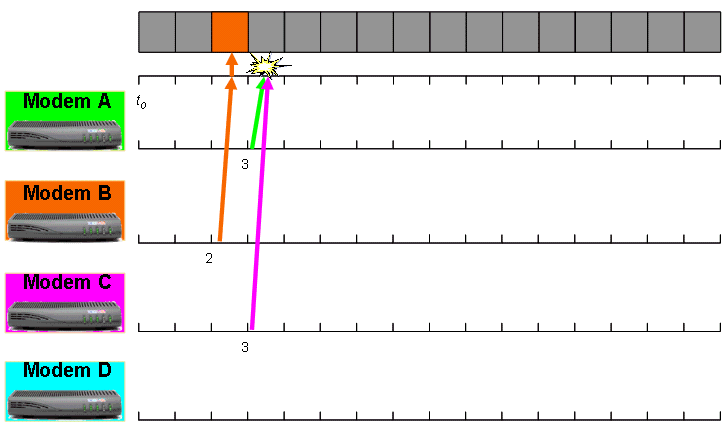
Die graue Leiste am oberen Rand des Diagramms stellt eine Reihe von Bandbreitenanfragen dar, die Kabelmodems nach dem Zeitpunkt t0 zur Verfügung stehen. Die farbigen Pfeile stellen Bandbreitenanforderungen dar, die von den Kabelmodems übertragen werden. Das farbige Kästchen in der grauen Leiste stellt eine Bandbreitenanforderung dar, die den CMTS erfolgreich erreicht.
Die nächste MAP-Nachrichtenübertragung vom CMTS enthält einen Zuschuss für Modem B, aber keine Anweisungen für die Modems A und C. Dies zeigt den Modems A und C an, dass sie ihre Bandbreitenanforderungen erneut übertragen müssen.
Beim zweiten Versuch müssen Modem A und Modem C die Leistung von zwei erhöhen, um den Bereich der Intervalle zu berechnen, aus denen ausgewählt werden soll. Modem A und Modem C wählen nun eine zufällige Anzahl von Intervallen zwischen 0 und 7 aus. Hier ist die Berechnung:
(22+1-1) = (23-1) = (8-1) = 7 Intervalle.
Nehmen Sie an, dass der Zeitpunkt, zu dem Modem A und Modem C erkennen, dass eine erneute Übertragung erforderlich ist, 1 ist. Gehen Sie außerdem davon aus, dass ein anderes Modem namens Modem D beschließt, einige Upstream-Daten gleichzeitig zu übertragen, d1. Modem D ist dabei, erstmals eine Bandbreitenanforderung zu übertragen. Daher verwendet Modem D den ursprünglichen Wert für Start- und Daten-Backoff-Ende, d. h. zwischen 0 und 3 [(22 - 1) = (4 - 1) = 3 Intervalle].
Die drei Modems wählen diese zufällige Anzahl an Bandbreitenanforderungen aus, die von Zeit zu Zeit auf1 gewartet werden können.
-
Modem A: 5
-
Modem C: 2
-
Modem D: 2
Beide Modems C und D warten auf zwei Bandbreitenanfragen, die nach der Zeit von 1 angezeigt werden. Die Modems C und D übertragen dann gleichzeitig Bandbreitenanforderungen. Diese Bandbreitenanforderungen kollidieren und erreichen daher nicht das CMTS. Modem A ermöglicht die Weiterleitung von fünf Bandbreitenanfragen. Anschließend überträgt Modem A die Bandbreitenanforderung, die der CMTS erhält. Abbildung 3 zeigt die Kollision zwischen der Übertragung der Modems C und D und dem erfolgreichen Empfang der Übertragung von Modem A. Die Startzeitreferenz für diese Zahl ist t1.
Abbildung 3: Beispiel für Bandbreitenanforderung Teil 2 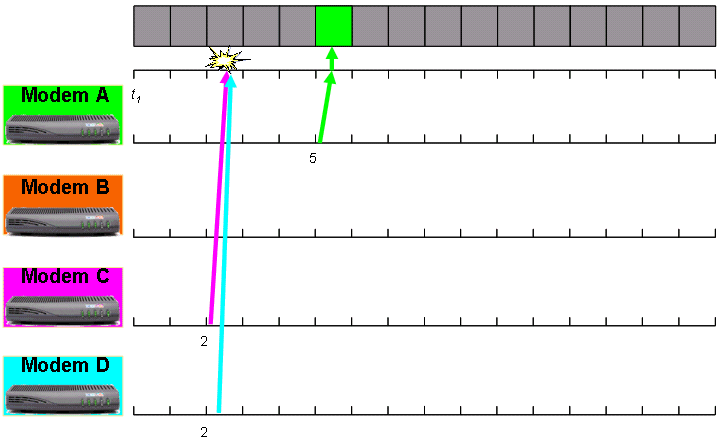
Die nächste MAP-Nachrichtensendung vom CMTS enthält einen Zuschuss für Modem A, aber keine Anweisungen für die Modems C und D. Die Modems C und D erkennen die Notwendigkeit, die Bandbreitenanforderungen erneut zu übertragen. Modem D sendet jetzt die Bandbreitenanforderung zum zweiten Mal. Modem D verwendet daher den Daten-Backoff-Start + 1 als die Leistung von zwei, um die Berechnung des Bereichs der zu wartenden Intervalle zu verwenden. Modem D wählt ein Intervall zwischen 0 und 7. Die Berechnung lautet wie folgt:
(22+1-1) = (23-1) = (8-1) = 7 Intervalle.
Das Modem C ist gerade dabei, die Bandbreitenanforderung zum dritten Mal zu übertragen. Daher verwendet Modem C bei der Berechnung des Intervalls, der gewartet werden soll, den Daten-Backoff-Start + 2 als Leistung von zwei bis. Modem C wählt ein Intervall zwischen 0 und 15. Die Berechnung lautet wie folgt:
(22+2-1) = (24-1) = (16-1) = 15 Intervalle.
Beachten Sie, dass die Leistung von zwei hier mit dem Wert des Daten-Backoff-Endwerts (vier) identisch ist. Dies ist die höchste Leistung, die für ein Modem auf diesem Upstream-Kanal möglich ist. Im nächsten Bandbreitenanforderungs-Übertragungszyklus wählen die beiden Modems die folgende Anzahl von Bandbreitenanforderungs-Optionen für das Warten aus:
-
Modem C: 9
-
Modem D: 4
Modem D kann die Bandbreitenanforderung übertragen, da Modem D auf die Übertragung von vier Bandbreitenanfragen wartet. Darüber hinaus kann Modem C auch die Bandbreitenanforderung übertragen, da Modem C die Übertragung jetzt für neun Bandbreitenanfragen verzögert.
Wenn Modem C eine Übertragung vornimmt, stört ein großer Rauschpegel die Übertragung, und der CMTS erhält die Bandbreitenanforderung nicht (siehe Abbildung 4). Daher wird in der nächsten MAP-Meldung, die das CMTS überträgt, erneut kein Zuschuss für Modem C angezeigt. Das Modem C versucht daher, eine vierte Übertragung der Bandbreitenanforderung durchzuführen.
Abbildung 4: Beispiel für eine Bandbreitenanforderung, Teil 3 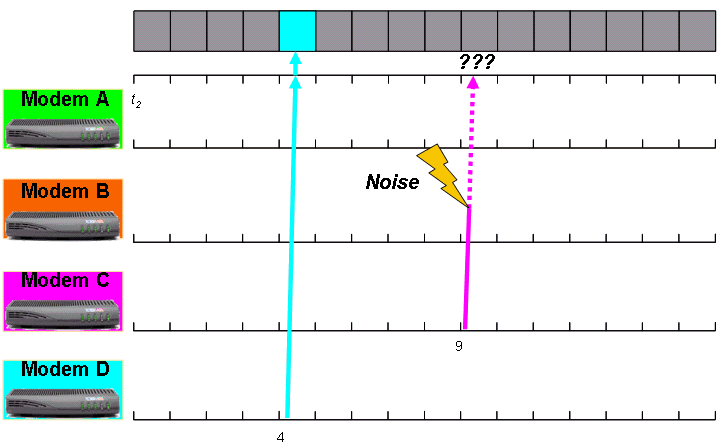
Modem C hat den Wert für das Daten-Backoff-Ende bereits 4 erreicht. Modem C kann den Bereich, der zur Auswahl einer zufälligen Anzahl von Warteintervallen verwendet wird, nicht erhöhen. Daher verwendet Modem C wieder einmal 4 als Leistung von zwei, um den zufälligen Bereich zu berechnen. Modem C verwendet weiterhin den Bereich von 0 bis 15 Intervalle gemäß dieser Berechnung:
(24 - 1) = (16 - 1) = 15 Intervalle.
Bei dem vierten Versuch ist Modem C in der Lage, eine erfolgreiche Bandbreitenanforderung zu übertragen, wenn kein Streit oder Rauschen auftritt.
Die wiederholte Übertragung mehrerer Bandbreitenanforderungen von Modem C in diesem Beispiel veranschaulicht, was auf einem überlasteten Upstream-Kanal passieren kann. Dieses Beispiel zeigt auch die potenziellen Probleme im Zusammenhang mit dem Scheduling-Modus für bestmöglichen Betrieb und warum eine bestmögliche Planung nicht für Services geeignet ist, die eine streng kontrollierte Latenz und Jitter von Paketen erfordern.
Verkehrspriorität
Wenn das CMTS über mehrere ausstehende Bandbreitenanforderungen von mehreren Service-Datenflüssen verfügt, prüft das CMTS die Verkehrspriorität jedes Service-Datenflusses, um zu entscheiden, welche zuerst Bandbreite gewährt werden soll.
Das CMTS gewährt allen ausstehenden Anfragen von Service-Datenflüssen mit einer höheren Priorität Sendezeit, bevor Bandbreitenanforderungen von Service-Datenflüssen mit geringerer Priorität ausgeführt werden. Unter überlasteten Upstream-Bedingungen führt dies in der Regel zu einem höheren Durchsatz für Service-Datenflüsse mit hoher Priorität im Vergleich zu Services mit niedriger Priorität.
Ein wichtiger Hinweis ist, dass ein Service-Fluss mit hoher Priorität zwar eher die Bandbreite schnell empfängt, der Service-Flow jedoch weiterhin der Möglichkeit von Zusammenstößen bei Bandbreitenanforderungen unterliegt. Aus diesem Grund ist die Datenverkehrspriorität zwar eine Verbesserung des Durchsatzes und der Latenzeigenschaften eines Dienstflusses, aber die Datenverkehrspriorität ist immer noch keine geeignete Methode, um eine Service-Garantie für Anwendungen bereitzustellen, die eine solche Priorität erfordern.
Mindestreservierungssatz
Bestmögliche Serviceströme erhalten einen reservierten Mindestsatz, der einzuhalten ist. Das CMTS stellt sicher, dass ein Service-Datenfluss mit einer festgelegten reservierten Mindestrate Bandbreite erhält, anstatt alle anderen Service-Datenflüsse mit bestmöglicher Leistung, unabhängig von der Priorität.
Diese Methode ist ein Versuch, eine Art von Service im CIR-Format bereitzustellen, der einem Frame-Relay-Netzwerk entspricht. Das CMTS verfügt über Zugangskontrollmechanismen, um sicherzustellen, dass die kombinierte minimale reservierte Rate aller angeschlossenen Serviceströme die verfügbare Bandbreite des Upstream-Kanals oder einen Prozentsatz davon nicht überschreiten darf. Sie können diese Mechanismen mit dem folgenden Befehl pro Upstream-Port aktivieren:
[no] Kabel Upstream Upstream-Port-ID Admission-Control Max-Reservierungslimit
Der Parameter "max-reserve-limit" (Maximale Reservierungsgrenze) hat einen Bereich von 10 bis 1.000 Prozent, um die Abonnementebene im Vergleich zum verfügbaren Upstream-Durchsatz anzugeben, den CIR-Services verbrauchen können. Wenn Sie eine maximale Reservierungsgrenze von mehr als 100 konfigurieren, können die Upstream-Dienste CIR-Stildienste bis zum angegebenen Prozentlimit überschreiben.
Das CMTS lässt keine Festlegung neuer Serviceströme mit minimaler reservierter Rate zu, wenn der Upstream-Port den konfigurierten Grenzwert für die maximale Reservierung der verfügbaren Upstream-Bandbreite überschreiten würde. Service-Datenflüsse mit minimaler reservierter Rate unterliegen weiterhin potenziellen Kollisionen von Bandbreitenanforderungen. Aus diesem Grund können reservierte Service-Datenflüsse mit minimalem Zinssatz keine echte Garantie für einen bestimmten Durchsatz bieten, insbesondere unter extrem überlasteten Bedingungen. Mit anderen Worten: Das CMTS kann nur garantieren, dass ein Servicestrom mit minimaler reservierter Rate einen bestimmten garantierten Upstream-Durchsatz erreichen kann, wenn das CMTS alle erforderlichen Bandbreitenanforderungen vom Kabelmodem empfangen kann. Diese Anforderung kann erfüllt werden, wenn der Service-Fluss anstelle eines bestmöglichen Service-Datenflusses als Echtzeit-Polling-Service (RTPS)-Servicestrom fungiert. Weitere Informationen finden Sie im Abschnitt Real Time Polling Service (RTPS).
Piggyback-Bandbreitenanforderungen
Wenn ein Upstream-Service-Fluss Frames mit hoher Geschwindigkeit überträgt, können Bandbreitenanforderungen auf Upstream-Daten-Frames übertragen werden, anstatt die Bandbreitenanforderungen separat zu übertragen. Die Details der nächsten Bandbreitenanforderung werden einfach dem Header eines Datenpakets hinzugefügt, das im vorgelagerten CMTS übertragen wird.
Dies bedeutet, dass die Bandbreitenanforderung nicht angefochten wird und daher eine viel höhere Wahrscheinlichkeit besteht, dass die Anforderung das CMTS erreicht. Das Konzept der "Piggyback"-Bandbreitenanforderungen reduziert die Zeit, die ein Ethernet-Frame benötigt, um die Geräte am Kundenstandort (CPE) des Endbenutzers zu erreichen, da die Zeit, die der Frame für die Upstream-Übertragung benötigt, verringert wird. Der Grund hierfür ist, dass das Modem nicht den Backoff-Vorgang durchlaufen muss und die Übertragung der Bandbreitenanforderung erneut versuchen muss. Dies kann zu Verzögerungen führen.
Piggyback von Bandbreitenanforderungen findet in der Regel in diesem Szenario statt:
Während das Kabelmodem auf die Übertragung eines Frames (z. B. X) im Upstream wartet, empfängt das Modem einen anderen Frame, z. B. Y, von einem CPE, um ihn in den Upstream zu übertragen. Das Kabelmodem kann die Bytes aus dem neuen Frame Y zur Übertragung nicht hinzufügen, da dies die Nutzung von mehr Upstream-Zeit erfordert, als das Modem gewährt wird. Stattdessen füllt das Modem ein Feld im DOCSIS-Header des Frames X aus, um die erforderliche Übertragungszeit für Frame Y anzugeben.
Das CMTS empfängt Frame X sowie die Details einer Bandbreitenanforderung im Auftrag von Y. Je nach Verfügbarkeit gewährt das CMTS dem Modem im Auftrag von Y weitere Übertragungszeiten.
In sehr konservativen Worten: Zwischen der Übertragung einer Bandbreitenanforderung und dem Empfang der Bandbreitenzuweisung sowie der MAP-Bestätigung, die die Zeit für die Datenübertragung zuweist, vergehen gerade einmal 5 Millisekunden. Das bedeutet, dass das Kabelmodem, um eine Pigmentunterlage zu erhalten, innerhalb von weniger als 5 ms Frames vom CPE empfangen muss.
Dies ist bemerkenswert, da ein typischer VoIP-Codec wie G.711 in der Regel einen Interframe-Zeitraum von 10 oder 20 ms verwendet. Ein typischer VoIP-Stream, der über einen Service-Flow mit bestmöglicher Leistung betrieben wird, kann nicht von der Unterstützung von Sparschwein profitieren.
Verkettung
Wenn ein Upstream-Servicestrom Frames mit hoher Geschwindigkeit überträgt, kann das Kabelmodem einige Frames miteinander verbinden und um Erlaubnis für die gleichzeitige Übertragung der Frames bitten. Dies wird als Verkettung bezeichnet. Das Kabelmodem muss nur eine Bandbreitenanforderung für alle Frames in einer Gruppe verknüpfter Frames übertragen, was die Effizienz erhöht.
Eine Verkettung tritt in der Regel unter ähnlichen Umständen wie bei der Piggyback-Unterstützung auf, jedoch erfordert die Verkettung, dass mehrere Frames in die Warteschlange im Kabelmodem gestellt werden, wenn das Modem beschließt, eine Bandbreitenanforderung zu übertragen. Dies impliziert, dass die Verkettung tendenziell bei höheren durchschnittlichen Frame-Raten erfolgt als bei Piggybacken. Außerdem arbeiten beide Mechanismen zusammen, um die Effizienz des bestmöglichen Datenverkehrs zu verbessern.
Das Feld Maximum Concatenated Burst (Maximaler verketteter Burst), das Sie für einen Dienstfluss konfigurieren können, begrenzt die maximale Größe eines verketteten Frames, den ein Dienstfluss übertragen kann. Sie können auch den Befehl default-phy-burst des Kabels verwenden, um die Größe eines verketteten Frames und die maximale Burst-Größe im Upstream-Channel-Modulationsprofil zu begrenzen.
Die Konfiguration ist auf den Upstream-Ports der Cisco uBR-Serie von CMTS standardmäßig aktiviert. Sie können die Verkettung jedoch pro Upstream-Port mithilfe des Befehls [no] für die vorgelagerte Upstream-Port-ID-Verkettung [docsis10] der Kabelschnittstelle steuern.
Wenn Sie den Parameter docsis10 konfigurieren, gilt der Befehl nur für Kabelmodems, die im DOCSIS 1.0-Modus betrieben werden.
Wenn Sie an diesem Befehl Änderungen vornehmen, müssen Kabelmodems im CMTS erneut registriert werden, damit die Änderungen wirksam werden. Die Modems auf den betroffenen Upstream müssen zurückgesetzt werden. Ein Kabelmodem erkennt, ob eine Verkettung an dem Punkt zulässig ist, an dem das Modem die Registrierung durchführt, um online zu gehen.
Fragmentierung
Die Übertragung großer Frames in den Upstream dauert lange. Diese Übertragungszeit wird als Serialisierungsverzögerung bezeichnet. Besonders große Upstream-Frames können so lange übertragen werden, dass sie Pakete, die zu zeitkritischen Diensten gehören, z. B. VoIP, auf harmlose Weise verzögern können. Dies gilt insbesondere für große verkettete Frames. Aus diesem Grund wurde in DOCSIS 1.1 eine Fragmentierung eingeführt, sodass große Frames in kleinere Frames für die Übertragung in separaten Bursts aufgeteilt werden können, die jeweils weniger Zeit für die Übertragung benötigen.
Durch die Fragmentierung können kleine, zeitempfindliche Frames zwischen den Fragmenten großer Frames verschachtelt werden, anstatt auf die Übertragung des gesamten großen Frames zu warten. Die Übertragung eines Frames als mehrere Fragmente ist etwas weniger effizient als die Übertragung eines Frames in einem Burst aufgrund der zusätzlichen Gruppe von DOCSIS-Headern, die jedes Fragment begleiten müssen. Die Flexibilität, die eine Fragmentierung dem Upstream-Kanal hinzufügt, rechtfertigt jedoch den zusätzlichen Overhead.
Kabelmodems, die im DOCSIS 1.0-Modus betrieben werden, können nicht fragmentiert werden.
Auf den Upstream-Ports der Cisco uBR-Serie von CMTS ist die Fragmentierung standardmäßig aktiviert. Mit dem Befehl [no] für die Upstream-Upstream-Port-ID-Fragmentierung der Kabelschnittstelle können Sie jedoch die Fragmentierung pro Upstream-Port aktivieren oder deaktivieren.
Sie müssen die Kabelmodems nicht zurücksetzen, damit der Befehl wirksam wird. Cisco empfiehlt, die Fragmentierung immer zu aktivieren. Eine Fragmentierung tritt in der Regel dann auf, wenn das CMTS der Ansicht ist, dass ein großer Datenrahmen die Übertragung von kleinen, zeitkritischen Frames oder bestimmten periodischen DOCSIS-Managementereignissen beeinträchtigen kann.
Sie können zwingen, dass DOCSIS 1.1/2.0-Kabelmodems alle großen Frames mit dem Befehl [no] Upstream-Port-ID-fragment-force [threshold number of fragments]-Kabelschnittstellenbefehl fragmentieren.
Diese Funktion ist standardmäßig deaktiviert. Wenn Sie in der Konfiguration keine Werte für den Grenzwert und die Anzahl der Fragmente angeben, wird der Grenzwert auf 2000 Byte festgelegt, und die Anzahl der Fragmente wird auf 3 festgelegt. Der Befehl fragment-force vergleicht die Byteanzahl, die ein Service-Flow für die Übertragung anfordert, mit dem angegebenen Schwellenwertparameter. Wenn die Anforderungsgröße größer als der Schwellenwert ist, weist das CMTS die Bandbreite für den Service-Flow in "Anzahl der Fragmente" in Teilen gleicher Größe zu.
Nehmen wir beispielsweise an, dass für eine bestimmte Upstream-Fragmentforce ein Wert von 2000 Byte für den Schwellenwert und 3 für die Anzahl der Fragmente aktiviert ist. Gehen Sie dann davon aus, dass eine Anfrage zur Übertragung eines 3000-Byte-Bursts eingeht. Da 3000 Byte den Schwellenwert von 2000 Byte überschreiten, muss der Zuschuss fragmentiert werden. Wenn die Anzahl der Fragmente auf 3 festgelegt ist, beträgt die Übertragungszeit drei gleichgroße Zuweisungen von jeweils 1000 Byte.
Achten Sie darauf, dass die Größe der einzelnen Fragmente die Kapazität des verwendeten Kabelkartentyps nicht überschreitet. Bei MC5x20S-Linecards darf das größte einzelne Fragment 2000 Byte nicht überschreiten, und bei anderen Linecards, einschließlich MC28U, MC5x20U und MC5x20H, darf das größte einzelne Fragment 4000 Byte nicht überschreiten.
Unsolicited Grant Service (UGS)
Der Unsolicited Grant Service (UGS) bietet regelmäßige Zuschüsse für einen Upstream-Service, ohne dass ein Kabelmodem Bandbreitenanforderungen übertragen muss. Diese Art von Dienst eignet sich für Anwendungen, die in regelmäßigen Abständen Frames mit fester Größe erstellen und Paketverluste nicht tolerieren. Voice over IP ist das klassische Beispiel.
Vergleichen Sie das UGS-Planungssystem mit einem Zeitschlitz in einem Time Division Multiplexing (TDM)-System wie einem T1- oder E1-Schaltkreis. UGS bietet einen garantierten Durchsatz und eine garantierte Latenz, die wiederum einen kontinuierlichen Stream von festen periodischen Intervallen für die Übertragung bereitstellt, ohne dass der Client regelmäßig Bandbreitenanfragen oder -konflikte durchführen muss. Dieses System eignet sich ideal für VoIP, da der Sprachverkehr in der Regel als kontinuierlicher Stream von periodischen Daten fester Größe übertragen wird.
UGS wurde konzipiert, weil es keine Garantien für Latenz, Jitter und Durchsatz im Modus "Best Effort Scheduling" gibt. Der Modus für die bestmögliche Planung bietet nicht die Gewähr, dass ein bestimmter Frame zu einem bestimmten Zeitpunkt übertragen werden kann, und in einem überlasteten System gibt es keine Gewähr, dass ein bestimmter Frame überhaupt übertragen werden kann.
Beachten Sie, dass Service-Datenflüsse im UGS-Stil zwar die am besten geeignete Art für die Übertragung von VoIP-Trägerdatenverkehr sind, aber nicht für klassische Internetanwendungen wie Web, E-Mail oder P2P geeignet sind. Das liegt daran, dass klassische Internetanwendungen keine Daten in festen regelmäßigen Abständen generieren und tatsächlich längere Zeiträume damit verbringen können, Daten überhaupt nicht zu übertragen. Wenn ein UGS-Servicestrom zur Übertragung von klassischem Internetdatenverkehr verwendet wird, kann der Servicestrom für längere Zeiträume ungenutzt bleiben, wenn die Anwendung die Übertragung kurz unterbricht. Dies führt zu ungenutzten UGS-Grants, die eine Verschwendung von Upstream-Bandbreitenressourcen darstellen, was nicht wünschenswert ist.
UGS-Serviceströme werden in der Regel dynamisch eingerichtet, wenn sie erforderlich sind, anstatt in der DOCSIS-Konfigurationsdatei bereitgestellt zu werden. Ein Kabelmodem mit integrierten VoIP-Ports kann das CMTS in der Regel auffordern, einen geeigneten UGS-Servicestrom zu erstellen, wenn das Modem erkennt, dass ein VoIP-Telefonanruf ausgeführt wird.
Cisco empfiehlt, in einer DOCSIS-Konfigurationsdatei keinen UGS-Servicestrom zu konfigurieren, da durch diese Konfiguration der UGS-Servicestrom so lange aktiv bleibt, wie das Kabelmodem online ist, unabhängig davon, ob Services es verwenden. Diese Konfiguration verschwendet Upstream-Bandbreite, da ein UGS-Servicestrom ständig Upstream-Übertragungszeiten für das Kabelmodem reserviert. Es ist weitaus besser, die dynamische Erstellung und Löschung des UGS-Dienstdatenflusses zuzulassen, sodass UGS bei Bedarf aktiv ist.
Nachfolgend sind die gebräuchlichsten Parameter aufgeführt, die einen UGS-Servicestrom definieren:
-
Unsolicited Grant Size (G): Die Größe jedes periodischen Zuschusses in Byte.
-
Nominal Grant Interval (I) - Das Intervall in Mikrosekunden zwischen den Finanzhilfen.
-
Tolerated Grant Jitter (J) - Die zulässige Abweichung in Mikrosekunden von exakt periodischen Zuschüssen. Dies ist also der Spielraum, den das CMTS hat, wenn das CMTS versucht, eine UGS-Finanzhilfe rechtzeitig zu planen.
Wenn ein UGS-Servicestrom aktiv ist, bietet das CMTS alle (I) Millisekunden die Möglichkeit, dass der Service-Fluss in Byte ohne angeforderte Förderungsgröße (G) übertragen wird. Obwohl der CMTS im Idealfall den Zuschuss exakt alle (I) Millisekunden anbietet, kann er sich bis zu (J) Millisekunden verspäten.
Abbildung 5 zeigt einen Zeitrahmen, der veranschaulicht, wie UGS-Zuschüsse mit einer bestimmten Zuschussgröße, einem Zuschussintervall und einem tolerierten Jitter zugewiesen werden können.
Abbildung 5: Zeitleiste mit regelmäßigen UGS-Zuschüssen 
Die grün gemusterten Blöcke stellen die Zeit dar, in der der CMTS die Upstream-Übertragungszeit einem UGS-Servicestrom zuweist.
Real-Time Polling Service (RTPS)
Real Time Polling Service (RTPS) bietet regelmäßige, nicht konfliktbasierte Bandbreitenanfragen, sodass ein Service Flow dedizierte Zeit für die Übertragung von Bandbreitenanfragen hat. Diese Unicast-Bandbreitenanforderung kann nur vom RTPS-Servicestrom verwendet werden. Andere Kabelmodems können keine Kollision bei Bandbreitenanforderungen verursachen.
RTPS eignet sich für Anwendungen, die Frames mit variabler Länge halbperiodisch erzeugen und einen garantierten Mindestdurchsatz benötigen, um effektiv arbeiten zu können. Beispiele hierfür sind Videotelefonie über IP oder Multiplayer-Online-Gaming.
RTPS wird auch für VoIP-Signalisierungsverkehr verwendet. Während VoIP-Signalisierungsverkehr nicht mit extrem niedriger Latenz oder Jitter übertragen werden muss, muss VoIP mit hoher Wahrscheinlichkeit CMTS in einem angemessenen Zeitraum erreichen. Wenn Sie statt der bestmöglichen Planung RTPS verwenden, können Sie sicher sein, dass die Sprachsignalisierung nicht durch wiederholte Kollisionen von Bandbreitenanforderungen signifikant verzögert oder verworfen wird.
Ein RTPS-Dienstfluss weist in der Regel folgende Attribute auf:
-
Nominal Polling Interval (Nominales Polling-Intervall): Das Intervall in Mikrosekunden zwischen Unicast-Bandbreitenanforderungs-Gelegenheiten.
-
Tolerated Poll Jitter (tolerierter Poll Jitter): Die zulässige Abweichung in Mikrosekunden von exakt periodischen Umfragen. Anders ausgedrückt: Dies ist der Spielraum, den der CMTS hat, wenn er versucht, eine RTPS-Unicast-Bandbreitenanforderung rechtzeitig zu planen.
Abbildung 6 zeigt eine Zeitleiste, die veranschaulicht, wie RTPS-Abfragen mit einem vorgegebenen nominalen Polling-Intervall und einem tolerierten Polling-Jitter zugewiesen werden.
Abbildung 6: Zeitleiste mit periodischem RTPS-Polling 
Die kleinen, grün gemusterten Blöcke stellen die Zeit dar, in der der CMTS einen RTPS-Service-Flow als Unicast-Bandbreitenanforderung anbietet.
Wenn das CMTS eine Bandbreitenanforderung im Namen eines RTPS-Dienstablaufs empfängt, verarbeitet das CMTS die Bandbreitenanforderung auf dieselbe Weise wie eine Anforderung eines "Best Effort"-Serviceflows. Dies bedeutet, dass zusätzlich zu den oben genannten Parametern Eigenschaften wie maximale nachhaltige Datenverkehrsrate und Verkehrspriorität in eine RTPS-Service-Flussdefinition einbezogen werden müssen. Ein RTPS-Service-Fluss enthält in der Regel auch eine minimale reservierte Datenverkehrsrate, um sicherzustellen, dass der mit dem Service-Flow verknüpfte Datenverkehr eine garantierte zugesicherte Bandbreite erhält.
Unsolicited Grant Service with Activity Detection (UGS-AD)
Unsolicited grant Service with Activity Detection (UGS-AS) weist einem Dienstfluss die Übertragungszeit im UGS-Stil nur dann zu, wenn UGS-AS Pakete tatsächlich übertragen muss. Wenn das CMTS erkennt, dass das Kabelmodem Frames für einen bestimmten Zeitraum nicht übertragen hat, bietet CMTS Bandbreitenanfragen im RTPS-Format anstelle von UGS-Stilvorgaben. Wenn das CMTS anschließend feststellt, dass der Service-Fluss Bandbreitenanforderungen ausführt, kehrt das CMTS den Service-Fluss zurück, um Zuweisungen im UGS-Stil anzubieten, und beendet das Anbieten von Bandbreitenanfragen im RTPS-Stil.
UGS-AD wird in der Regel in einer Situation verwendet, in der VoIP-Datenverkehr, der die Sprachaktivitätserkennung (VAD) verwendet hat, weitergeleitet wird. Die Erkennung von Sprachaktivitäten bewirkt, dass der VoIP-Endpunkt die Übertragung von VoIP-Frames stoppt, wenn UGS-AD eine Pause in der Sprache des Benutzers erkennt. Dieses Verhalten kann zwar Bandbreite einsparen, aber es kann Probleme mit der Sprachqualität verursachen, insbesondere wenn der Mechanismus zur Erkennung von VAD- oder UGS-AD-Aktivitäten leicht aktiviert wird, nachdem der Endteilnehmer mit dem Reden beginnt. Dies kann dazu führen, dass der Benutzer nach der Stille erneut spricht, wenn er auf den Ton klickt. Aus diesem Grund ist UGS-AD nicht weit verbreitet.
Geben Sie den globalen CMTS-Konfigurationsbefehl für den Kabelservicestrom-Inaktivitätsschwellenwert in Sekunden ein, um den Zeitraum festzulegen, nach dem der CMTS einen inaktiven UGS-AD-Servicestrom vom UGS-Modus in den RTPS-Modus umschaltet.
Der Standardwert für den Grenzwert in Sekunden-Parameter ist 10 Sekunden. UGS-AD-Serviceströme besitzen im Allgemeinen die Attribute eines UGS-Service-Flusses sowie das nominale Polling-Intervall und das tolerierte Polling-Jitter-Attribut, das mit RTPS-Service-Flows verknüpft ist.
Nicht-Echtzeit-Polling-Service (nRTPS)
Der Scheduling-Modus für Nicht-Echtzeit-Polling-Dienste (nRTPS) ist im Wesentlichen derselbe wie RTPS, jedoch ist nRTPS in der Regel mit nicht interaktiven Diensten wie Dateiübertragungen verknüpft. Die Nicht-Echtzeit-Komponente kann implizieren, dass das nominale Polling-Intervall für Unicast-Bandbreitenanfragen nicht genau normal ist oder mit einer Rate von weniger als einer pro Sekunde stattfinden kann.
Einige Kabelnetzbetreiber können zur Übertragung von Sprachsignalisierungsverkehr nRTPS anstelle von RTPS-Serviceströmen verwenden.
Planungsalgorithmen
Bevor Sie auf die Details des DOCSIS-konformen Schedulers und des Warteschlangenplaners mit niedriger Latenz eingehen, müssen Sie die Kompromisse verstehen, die Sie zur Bestimmung der Eigenschaften eines Upstream-Schedulers eingehen müssen. Auch wenn sich die Diskussion über Scheduler-Algorithmen hauptsächlich auf den UGS Scheduling Modus konzentriert, gilt die Diskussion gleichermaßen auch für RTPS Style Services.
Wenn Sie entscheiden, wie Sie UGS-Service-Datenflüsse planen, gibt es nicht viele flexible Optionen. Sie können den Scheduler nicht dazu veranlassen, die Grant-Größe oder das Grant-Intervall der UGS-Service-Flows zu ändern, da eine solche Änderung dazu führt, dass VoIP-Anrufe vollständig fehlschlagen. Wenn Sie jedoch den Jitter ändern, funktionieren Anrufe, wenn auch möglicherweise mit einer erhöhten Latenz während des Anrufs. Darüber hinaus beeinträchtigt die Änderung der maximalen Anzahl von Anrufen, die für einen Upstream zulässig ist, nicht die Qualität einzelner Anrufe. Berücksichtigen Sie daher die folgenden beiden Hauptfaktoren, wenn Sie eine große Anzahl von UGS-Serviceströmen planen:
-
Jitter
-
UGS Service Flow Capacity pro Upstream
Jitter
Ein tolerierter Grant Jitter wird als eines der Attribute eines UGS- oder RTPS-Dienstablaufs angegeben. Die gleichzeitige Unterstützung einiger Service-Flows mit sehr wenig toleriertem Jitter und anderer mit sehr großen Jitter-Mengen kann jedoch ineffizient sein. Im Allgemeinen müssen Sie eine einheitliche Entscheidung hinsichtlich des Jittertyps treffen, den ein Dienst in einem Upstream erfährt.
Wenn niedrige Jitter-Ebenen erforderlich sind, muss der Scheduler bei der Planung der Grant-Lizenzen unflexibel und starr sein. Daher muss der Scheduler die Anzahl der UGS-Serviceströme einschränken, die von einem Upstream unterstützt werden.
Jitter-Levels müssen nicht immer extrem niedrig sein, um ein normales VoIP für Privatnutzer zu ermöglichen, da die Jitter-Puffer-Technologie einen hohen Jitter-Pegel ausgleichen kann. Moderne adaptive VoIP-Jitter-Puffer sind in der Lage, mehr als 150 ms Jitter auszugleichen. Ein VoIP-Netzwerk erhöht jedoch die Latenz der Pakete um die Anzahl der Pufferungen. Eine hohe Latenz kann zu einer schlechteren VoIP-Erfahrung beitragen.
UGS Service Flow Capacity pro Upstream
Physikalische Layer-Attribute wie Kanalbreite, Modulationsschema und Fehlerkorrekturstärke bestimmen die physische Kapazität eines Upstream. Die Anzahl der gleichzeitigen UGS-Service-Flows, die der Upstream unterstützen kann, hängt jedoch auch vom Scheduler-Algorithmus ab.
Wenn keine extrem niedrigen Jitter-Levels erforderlich sind, können Sie die Steifigkeit des Schedulers entspannen und eine höhere Anzahl von UGS-Service-Flows berücksichtigen, die der Upstream gleichzeitig unterstützen kann. Sie können eine höhere Effizienz des Nicht-Sprachdatenverkehrs im Upstream erreichen, wenn Sie die Jitter-Anforderungen lockern.
Hinweis: Verschiedene Scheduling-Algorithmen können einem bestimmten Upstream-Kanal die Unterstützung verschiedener UGS- und RTPS-Service-Flows ermöglichen. Diese Dienste können jedoch nicht 100 % der Upstream-Kapazität in einem DOCSIS-System nutzen. Der Grund hierfür ist, dass der Upstream-Kanal einen Teil des DOCSIS-Verwaltungsdatenverkehrs reservieren muss, z. B. die anfänglichen Wartungsmeldungen, die Kabelmodems für den ersten Kontakt mit dem CMTS verwenden, und dass der Keepalive-Datenverkehr der Station verwendet wird, um sicherzustellen, dass Kabelmodems die Verbindung zum CMTS aufrechterhalten können.
Der DOCSIS-konforme Scheduler
Der DOCSIS-kompatible Scheduler ist das Standardsystem für die Planung von Upstream-Services auf einem Cisco uBR CMTS. Dieser Scheduler wurde entwickelt, um den Jitter zu minimieren, der den UGS- und RTPS-Service abläuft. Dieser Scheduler erlaubt Ihnen jedoch weiterhin, ein gewisses Maß an Flexibilität beizubehalten, um die Anzahl gleichzeitiger UGS-Anrufe pro Upstream zu optimieren.
Der DOCSIS-konforme Scheduler ordnet vorab die Upstream-Zeit für UGS-Service-Flows zu. Bevor andere Bandbreitenzuweisungen geplant werden, reserviert das CMTS in Zukunft Zeit für Zuschüsse, die zu aktiven UGS-Service-Datenflüssen gehören, um sicherzustellen, dass keine der anderen Arten von Service-Datenflüssen oder Datenverkehr die UGS-Zuschüsse verdrängt und zu erheblichem Jitter führt.
Wenn das CMTS Bandbreitenanfragen im Namen von Service-Flows mit bestmöglicher Leistung empfängt, muss das CMTS die Übertragungszeit für den bestmöglichen Service-Flows um die bereits zugewiesenen UGS-Zuschüsse planen, um die zeitgerechte Planung jedes UGS-Zuschusses nicht zu beeinträchtigen.
Konfiguration
Der DOCSIS-kompatible Scheduler ist der einzige verfügbare Upstream-Scheduler-Algorithmus für die Cisco IOS Software Releases 12.3(9a)BCx und frühere Versionen. Aus diesem Grund erfordert dieser Scheduler keine Konfigurationsbefehle zur Aktivierung.
Für die Cisco IOS Software Releases 12.3(13a)BC und höher ist der DOCSIS-konforme Scheduler einer von zwei alternativen Scheduler-Algorithmen, aber als Standard-Scheduler festgelegt. Sie können den DOCSIS-kompatiblen Scheduler für einen, alle oder einige der folgenden Scheduling-Typen aktivieren:
-
UGS
-
RTPS
-
NRTPS
Sie können den DOCSIS-kompatiblen Scheduler explizit für jeden dieser Scheduling-Typen mit dem vorgelagerten Upstream-Port-Planungstyp [nrtps | rtps | ugs] mode docsis Kabel-Schnittstellenbefehl.
Die Verwendung eines DOCSIS-kompatiblen Schedulers ist Teil der Standardkonfiguration. Daher müssen Sie diesen Befehl nur ausführen, wenn Sie den nicht standardmäßigen Scheduler für Warteschlangen mit niedriger Latenz ändern. Weitere Informationen finden Sie im Abschnitt Low Latency Queueing Scheduler.
Zugangskontrolle
Ein großer Vorteil des DOCSIS-konformen Schedulers besteht darin, dass dieser Scheduler sicherstellt, dass die UGS-Service-Flows die Upstream-Flows nicht überzeichnen. Wenn ein neuer UGS Service Flow erstellt werden muss und der Scheduler feststellt, dass eine Vorabplanung von GrantInnen nicht möglich ist, weil kein Platz übrig ist, lehnt das CMTS den neuen UGS Service Flow ab. Wenn UGS-Serviceströme, die VoIP-Datenverkehr übertragen, einen Upstream-Kanal überzeichnen dürfen, wird die Qualität aller VoIP-Anrufe erheblich beeinträchtigt.
Um zu demonstrieren, wie der DOCSIS-konforme Scheduler sicherstellt, dass UGS-Service-Datenflüsse die Upstream-Datenflüsse nie überzeichnen, lesen Sie die Zahlen in diesem Abschnitt. Die Abbildungen 7, 8 und 9 zeigen Zeitlinien für die Bandbreitenzuweisung.
In all diesen Zahlen zeigen die farblich gemusterten Abschnitte die Zeit, in der Kabelmodems Zuschüsse für ihre UGS-Serviceströme erhalten. Während dieser Zeit können keine anderen Upstream-Übertragungen von anderen Kabelmodems erfolgen. Der graue Teil der Zeitspanne ist noch nicht zugewiesene Bandbreite. Kabelmodems übertragen in dieser Zeit Bandbreitenanforderungen. CMTS kann diese Zeit später verwenden, um andere Arten von Services zu planen.
Abbildung 7: DOCSIS-konforme Scheduler-Vorplanung von drei UGS-Serviceflows 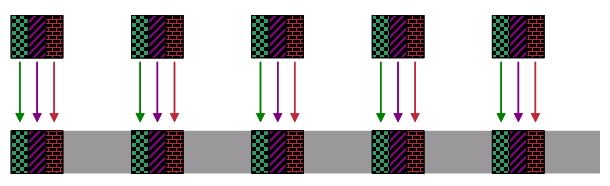
Fügen Sie zwei weitere UGS-Service-Datenflüsse mit der gleichen Zuschussgröße und dem gleichen Gewährleistungsintervall hinzu. Trotzdem hat der Scheduler keine Probleme bei der Vorplanung.
Abbildung 8: DOCSIS-konforme Scheduler-Vorplanung von fünf UGS-Serviceflows 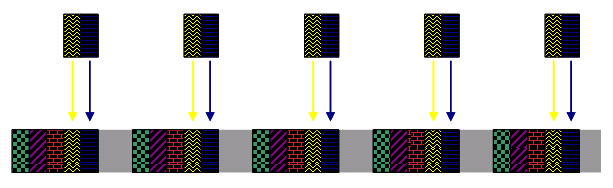
Wenn Sie fortfahren und zwei weitere UGS-Service-Datenflüsse hinzufügen, füllen Sie die gesamte verfügbare Upstream-Bandbreite aus.
Abbildung 9: UGS-Serviceflows belegen die gesamte verfügbare Upstream-Bandbreite 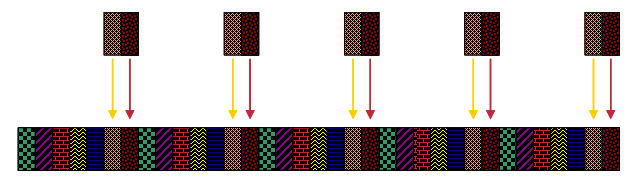
Natürlich kann der Scheduler hier keine weiteren UGS Service Flows zugeben. Wenn also ein anderer UGS-Service Flow versucht, aktiv zu werden, erkennt der DOCSIS-konforme Scheduler, dass kein Raum für weitere Zuschüsse besteht und verhindert die Einrichtung dieses Service Flow.
Hinweis: Es ist unmöglich, einen Upstream mit UGS-Service-Flows vollständig zu füllen, wie in dieser Abbildungen gezeigt. Der Scheduler muss andere wichtige Datenverkehrstypen aufnehmen, z. B. Station-Wartungsschlüssel und bestmöglichen Datenverkehr. Die Garantie zur Vermeidung von Überbelegung mit dem DOCSIS-konformen Scheduler gilt nur, wenn alle Dienstflussplanungs-Modi, d. h. UGS, RTPS und nRTPS, den DOCSIS-konformen Scheduler verwenden.
Obwohl bei Verwendung des DOCSIS-kompatiblen Schedulers keine explizite Zugangskontrolle erforderlich ist, empfiehlt Cisco, sicherzustellen, dass die Upstream-Kanalauslastung nicht auf ein Niveau ansteigt, das sich negativ auf den Datenverkehr mit bestem Datenverkehr auswirken kann. Cisco empfiehlt außerdem, dass die gesamte Upstream-Kanalauslastung während eines signifikanten Zeitraums 75 % nicht überschreiten darf. Dies ist der Grad der Upstream-Auslastung, bei dem Best-Effort-Services eine deutlich höhere Latenz und einen geringeren Durchsatz erleben. UGS-Dienste funktionieren weiterhin, unabhängig von der Upstream-Nutzung.
Wenn Sie die Anzahl der Zugriffe auf einen bestimmten Upstream begrenzen möchten, konfigurieren Sie die Zugangskontrolle für UGS, RTPS, NRTPS, UGS-AD oder Best Effort Service Flows mit dem globalen, per Kabelschnittstelle oder pro Upstream-Befehl. Der wichtigste Parameter ist das exklusive Schwellenwert-Prozent-Feld.
cable [upstream upstream-number] admission-control us-bandwidth scheduling-type UGS|AD-UGS|RTPS|NRTPS|BE minor minor-threshold-percent major major-threshold-percent exclusive exclusive-threshold-percent [non-exclusive non-excl-threshold-percent]
Die Parameter sind wie folgt:
-
[Upstream <Upstream-Nummer>]: Geben Sie diesen Parameter an, wenn der Befehl auf einen bestimmten Upstream statt auf eine Kabelschnittstelle oder global angewendet werden soll.
-
<UGS|AD-UGS|RTPS|NRTPS|BE]: Dieser Parameter gibt den Scheduling-Modus von Service-Datenflüssen an, auf die Sie die Zugangskontrolle anwenden möchten.
-
<Minor-Schwellenwert-Prozent>: Dieser Parameter gibt den Prozentsatz der Upstream-Nutzung nach konfiguriertem Scheduling-Typ an, bei dem ein kleinerer Alarm an eine Netzwerkmanagement-Station gesendet wird.
-
<Haupt-Schwellenwert-Prozent>: Dieser Parameter gibt den Prozentsatz der Upstream-Auslastung durch den konfigurierten Scheduling-Typ an, bei dem ein großer Alarm an eine Netzwerkmanagement-Station gesendet wird. Dieser Wert muss größer sein als der Wert, den Sie für den <Moldeschwelle-Prozent>-Parameter festgelegt haben.
-
<exklusive Grenzwert-Prozent>: Dieser Parameter stellt den Prozentsatz der Upstream-Nutzung dar, der ausschließlich für den angegebenen Scheduling-Typ reserviert ist. Wenn Sie den Wert für <nicht exklusive Grenzwert-Prozent> nicht angeben, stellt dieser Wert die maximale Auslastungsgrenze für diesen Servicestrom dar. Dieser Wert muss größer sein als der <major-threshold-percent>-Wert.
-
<ohne Schwellenwert-Prozent>: Dieser Parameter stellt den Prozentsatz der Upstream-Auslastung dar, der über dem <exklusive-Schwellenwert-Prozent> liegt, den dieser Scheduling-Typ verwenden kann, sofern dieser nicht bereits von einem anderen Planungstyp verwendet wird.
Nehmen Sie beispielsweise an, Sie möchten den UGS-Service-Fluss auf 60 % der gesamten verfügbaren Upstream-Bandbreite beschränken. Gehen Sie auch davon aus, dass Ihnen Netzwerkmanagement-Stationen mitgeteilt haben, dass bei einem Anstieg des Anteils der Upstream-Nutzung aufgrund von UGS-Service-Flows um über 40 % ein kleinerer Alarm gesendet werden muss und über 50 %, ein großer Alarm gesendet werden muss. Geben Sie den folgenden Befehl ein:
Cable Admission Control us-bandwidth Scheduling-Typ UGS Minor 40 Dur 50 exklusiv 60
Planen des bestmöglichen Datenverkehrs mithilfe von Fragmentierung
Der DOCSIS-konforme Scheduler plant einfach den bestmöglichen Datenverkehr im Hinblick auf bereits zugewiesene UGS- oder RTPS-Zuwendungen. Die Zahlen in diesem Abschnitt veranschaulichen dieses Verhalten.
Abbildung 10: Ausstehende Planung von Zuschüssen für bestmögliche Leistung 
Abbildung 10 zeigt, dass der Upstream drei UGS-Service-Datenflüsse mit der gleichen Zuschussgröße und dem gleichen Zuschussintervall im Voraus geplant hat. Der Upstream empfängt Bandbreitenanforderungen im Auftrag von drei separaten Service-Datenflüssen, A, B und C. Service Flow A fordert eine mittlere Übertragungszeit an, Service Flow B fordert eine geringe Übertragungszeit an, und Service Flow C fordert eine große Übertragungszeit an.
Achten Sie bei jedem Service-Datenfluss auf dieselbe Priorität. Gehen Sie außerdem davon aus, dass das CMTS die Bandbreitenanforderungen für jede dieser Zuschüsse in der Reihenfolge A, dann B und dann C erhält. Das CMTS weist zunächst die Übertragungszeit für die Zuschüsse in derselben Reihenfolge zu. Abbildung 11 zeigt, wie der DOCSIS-konforme Scheduler diese Zuschüsse zuweist.
Abbildung 11: Beantragte Zuschüsse für bestmögliche Leistung bei fest installierten UGS-Service-Flow-Stipendien 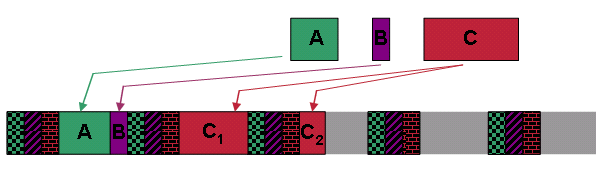
Der Scheduler ist in der Lage, die Zuschüsse für A und B in der Lücke zwischen den ersten beiden Blöcken von UGS Grants zusammenzudrücken. Der Zuschuss für C ist jedoch größer als jede verfügbare Lücke. Der DOCSIS-konforme Scheduler fragmentiert daher den Zuschuss für C rund um den dritten UGS-Grant-Block in zwei kleinere Grants, C1 und C2. Die Fragmentierung verhindert Verzögerungen bei UGS-Finanzhilfen und stellt sicher, dass diese Zuschüsse keinen Jitter unterliegen, der durch den bestmöglichen Datenverkehr verursacht wird.
Durch eine Fragmentierung wird der DOCSIS-Protokoll-Overhead bei der Datenübertragung leicht erhöht. Für jedes zusätzliche Fragment, das übertragen wird, muss ein zusätzlicher Satz von DOCSIS-Headern übertragen werden. Ohne Fragmentierung kann der Scheduler jedoch keine bestmöglichen Aufwandszuschüsse zwischen festen UGS-Grants effizient miteinander kombinieren. Eine Fragmentierung kann bei Kabelmodems, die im DOCSIS 1.0-Modus betrieben werden, nicht auftreten.
Priorität
Der DOCSIS-konforme Scheduler platziert Zuweisungen, die noch in einer Warteschlange verbleiben, basierend auf der Priorität des Dienstflusses, zu dem der Zuschuss gehört. Es gibt acht DOCSIS-Prioritäten mit 0 als niedrigste und 7 als höchste. Jede dieser Prioritäten verfügt über eine zugeordnete Warteschlange.
Der DOCSIS-kompatible Scheduler verwendet einen strikten Prioritätswarteschlangenmechanismus, um zu bestimmen, wann Zuweisungen von Zuweisungen mit unterschiedlicher Priorität die Übertragungszeit erhalten. Mit anderen Worten: Alle in Warteschlangen mit hoher Priorität gespeicherten Zuweisungen müssen vor Zuweisungen in Warteschlangen mit niedrigerer Priorität bedient werden.
Nehmen wir beispielsweise an, der DOCSIS-konforme Scheduler erhält fünf Zuschüsse in kurzer Zeit in der Reihenfolge A, B, C, D, E und F. Der Scheduler stellt jede der Zuweisungen in der Warteschlange in die Warteschlange ein, die der Priorität des Dienstflusses des Zuschusses entspricht.
Abbildung 12: Zuschüsse mit unterschiedlichen Prioritäten 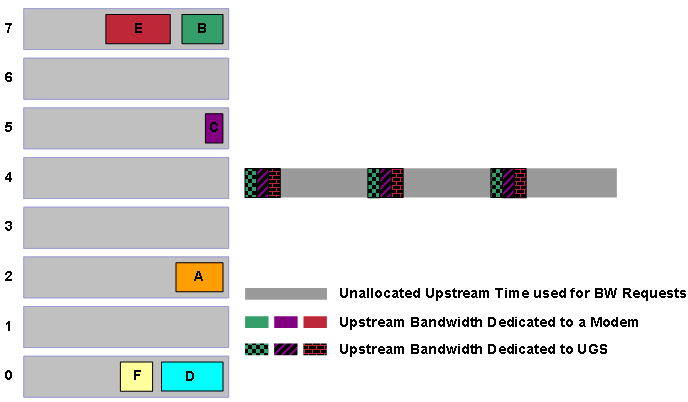
Der DOCSIS-konforme Scheduler plant die bestmögliche Aufwandszuweisung für die im Voraus geplanten UGS-Zuwendungen, die als gemusterte Blöcke in Abbildung 12 erscheinen. Der DOCSIS-konforme Scheduler prüft zunächst die Warteschlange mit der höchsten Priorität. In diesem Fall ist die Prioritätswarteschlange 7 bereit für den Zeitplan. Der Scheduler setzt die Übertragungszeit für die Grants B und E frei. Beachten Sie, dass Zuschuss E fragmentiert werden muss, damit der Zuschuss den Zeitpunkt der bereits zugewiesenen UGS-Zuschüsse nicht beeinträchtigt.
Abbildung 13: Planen von Förderungen der Priorität 7 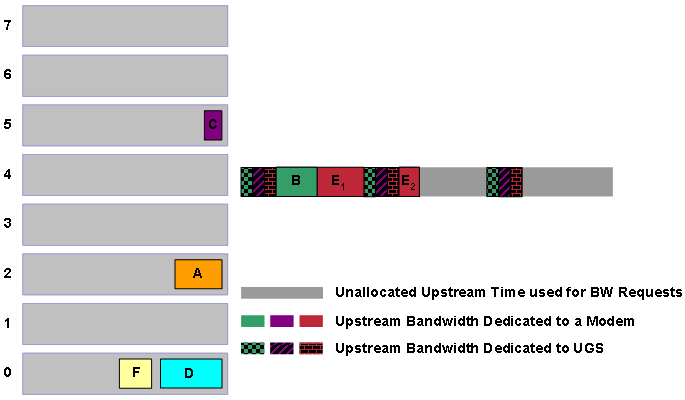
Der Scheduler stellt sicher, dass alle Priorität 7-Grants eine Übertragungszeit erhalten. Anschließend überprüft der Scheduler die Prioritätswarteschlange 6. In diesem Fall ist die Prioritätswarteschlange 6 leer, sodass der Scheduler zur Prioritätswarteschlange 5 wechselt, die Grant C enthält.
Abbildung 14: Planen von Finanzhilfen der Priorität 5 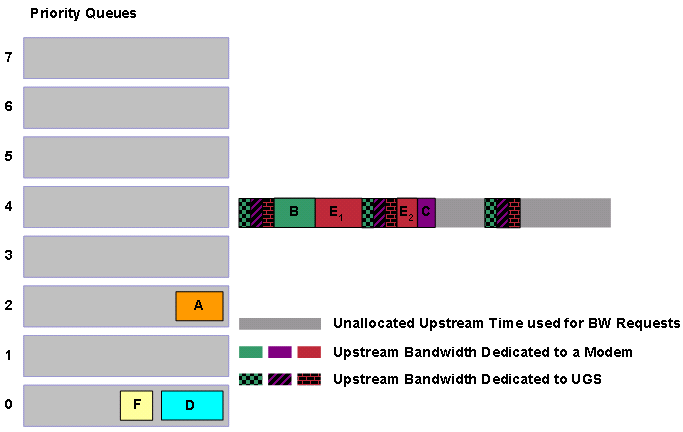
Der Scheduler setzt dann in den Warteschlangen mit niedrigerer Priorität auf ähnliche Weise fort, bis alle Warteschlangen leer sind. Wenn eine große Anzahl von Zuschüssen geplant werden muss, können neue Bandbreitenanforderungen das CMTS erreichen, bevor der DOCSIS-konforme Scheduler die Zuweisung der Übertragungszeit zu allen ausstehenden Zuschüssen beendet. Nehmen Sie an, dass das CMTS zu diesem Zeitpunkt im Beispiel eine Bandbreitenanforderung G der Priorität 6 erhält.
Abbildung 15: Ein Prioritätszuschuss 6 wird in Warteschlange gestellt 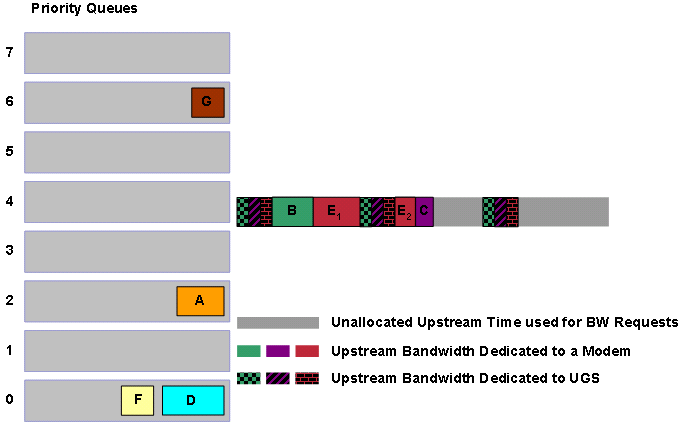
Obwohl A, F und D länger als der neu in die Warteschlange eingestellte Grant G warten, muss der DOCSIS-konforme Scheduler G als Nächstes die Übertragungszeit zuweisen, da G die höhere Priorität hat. Das bedeutet, dass die nächsten Bandbreitenzuweisungen des DOCSIS-konformen Schedulers G, A und D sind (siehe Abbildung 16).
Abbildung 16: Planen von Finanzhilfen der Priorität 6 und 2 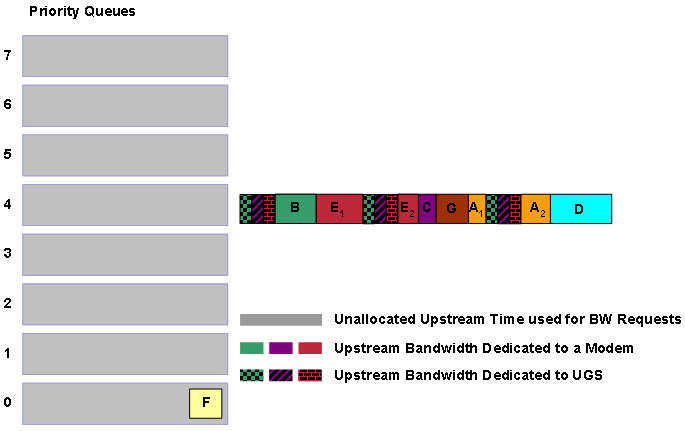
Der nächste zu planende Zuschuss ist F, wenn Sie davon ausgehen, dass keine höheren Prioritätszuweisungen in der mittleren Zeit in das Warteschlangensystem eintreten.
Der DOCSIS-kompatible Scheduler verfügt über zwei weitere Warteschlangen, die in den Beispielen nicht erwähnt wurden. Die erste Warteschlange ist die Warteschlange, die zur Planung des regelmäßigen Keepalive-Verkehrs bei der Wartung von Stationen verwendet wird, um Kabelmodems online zu halten. Diese Warteschlange dient dazu, Möglichkeiten für Kabelmodems zu planen, um den CMTS-Datenverkehr mit regelmäßigem Keepalive zu senden. Wenn der DOCSIS-kompatible Scheduler aktiv ist, wird diese Warteschlange zuerst vor allen anderen Warteschlangen bereitgestellt. Die zweite Warteschlange ist eine Warteschlange für Zuschüsse, die Service-Datenflüssen mit einem festgelegten minimalen reservierten Zinssatz (CIR) zugewiesen werden. Der Scheduler betrachtet diese CIR-Warteschlange als Prioritätswarteschlange 8, um sicherzustellen, dass Service-Datenflüsse mit einer Committed Rate den erforderlichen Mindestdurchsatz erhalten.
Nicht fragmentierte DOCSIS 1.0-Zuschüsse
In den Beispielen im vorherigen Abschnitt müssen Finanzhilfen manchmal in mehrere Teile aufgeteilt werden, um sicherzustellen, dass Jitter nicht in vorab zugewiesenen UGS-Zuschüssen ausgelöst wird. Dies kann bei Kabelmodems, die im DOCSIS 1.0-Modus in Upstream-Segmenten mit einer beträchtlichen Menge an UGS-Datenverkehr betrieben werden, problematisch sein, da ein DOCSIS 1.0-Kabelmodem anfordern kann, einen Frame zu übertragen, der für die nächste verfügbare Übertragungsmöglichkeit zu groß ist.
Hier ist ein weiteres Beispiel, das davon ausgeht, dass der Scheduler in dieser Reihenfolge neue Grants A und B erhält. Gehen Sie außerdem davon aus, dass beide Zuschüsse dieselbe Priorität haben, Zuschuss B jedoch für ein Kabelmodem gilt, das im DOCSIS 1.0-Modus betrieben wird.
Abbildung 17: Ausstehende Zuschüsse für DOCSIS 1.1 und DOCSIS 1.0 
Der Scheduler versucht, Zeit für die Vergabe A als Erstes zuzuweisen. Dann versucht der Scheduler, die nächste verfügbare Übertragungsmöglichkeit zuzuweisen, um B zuzuweisen. Es besteht jedoch kein Raum, dass Zuschuss B unzersplittert zwischen A und dem nächsten Block von UGS-Zuschüssen bleibt (siehe Abbildung 18).
Abbildung 18: Zurückgestellte DOCSIS 1.0-Finanzhilfe B 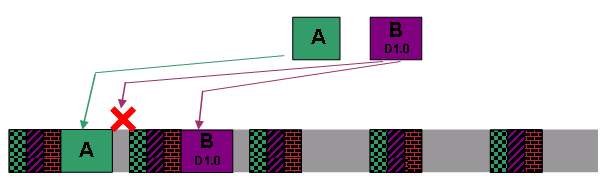
Aus diesem Grund wird der Zuschuss B nach dem zweiten Block von UGS-Zuschüssen verspätet gewährt, wenn Raum für den Zuschuss B besteht. Beachten Sie, dass vor dem zweiten Block von UGS-Zuweisungen jetzt nicht mehr genutzter Speicherplatz verfügbar ist. Kabelmodems übertragen Bandbreitenanforderungen an das CMTS in dieser Zeit. Dies stellt jedoch eine ineffiziente Bandbreitennutzung dar.
Überprüfen Sie dieses Beispiel, und fügen Sie dem Scheduler zusätzliche zwei UGS-Serviceströme hinzu. Zuschuss A kann zwar fragmentiert werden, es besteht jedoch keine Möglichkeit, den nicht fragmentierbaren Zuschuss B zu planen, da Zuschuss B zu groß ist, um zwischen den Blöcken von UGS-Zuschüssen zu passen. In diesem Fall kann das mit Zuschuss B verbundene Kabelmodem keine großen Frames im Upstream übertragen.
Abbildung 19: DOCSIS 1.0-Zuschuss B kann nicht geplant werden 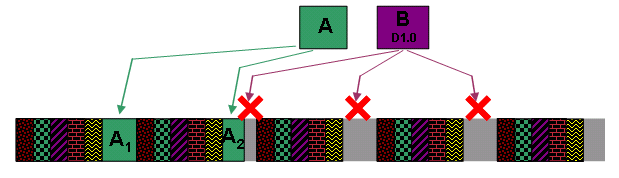
Sie können dem Scheduler erlauben, einfach einen Block von UGS-Grants auszuschieben oder leicht zu verzögern, um Raum für Grant B zu schaffen, aber diese Aktion verursacht Jitter im UGS-Service Flow. Wenn Sie im Moment davon ausgehen, dass Sie Jitter minimieren möchten, ist dies eine inakzeptable Lösung.
Um dieses Problem mit großen, nicht fragmentierbaren DOCSIS 1.0-Zuweisungen zu beheben, plant der DOCSIS-konforme Scheduler regelmäßig Upstream-Zeitblöcke vorab, die so groß sind, wie der größte Frame, den ein DOCSIS 1.0-Kabelmodem übertragen kann. Der Scheduler tut dies, bevor UGS-Serviceströme geplant werden. Dieses Mal entspricht es in der Regel etwa 2000 Byte Upstream-Übertragung und wird als "Unfragmentierbarer Block" oder "UGS-freier Block" bezeichnet.
Der DOCSIS-konforme Scheduler platziert keine UGS- oder RTPS-Stipendien in den Zeiten, die dem nicht fragmentierbaren Datenverkehr zugewiesen wurden, um sicherzustellen, dass immer die Möglichkeit besteht, große DOCSIS 1.0-Zuschüsse zu planen. In diesem System verringert die Reservierung der Zeit für nicht fragmentierbaren DOCSIS 1.0-Datenverkehr die Anzahl der UGS-Service-Datenflüsse, die der Upstream gleichzeitig unterstützen kann.
Abbildung 20 zeigt den nicht fragmentierbaren Block in blau und vier UGS-Serviceströme mit derselben Fördergröße und demselben Gewährleistungsintervall. Sie können diesem Upstream keinen weiteren UGS-Servicestrom mit derselben Fördergröße und demselben Berechtigungsintervall hinzufügen, da UGS-Zuweisungen nicht im blauen, nicht fragmentierbaren Blockbereich geplant werden dürfen.
Abbildung 20: Der nicht fragmentierbare Block: Es können keine weiteren UGS-Zuschüsse gewährt werden. 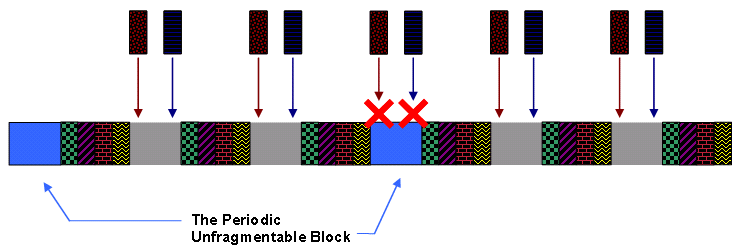
Obwohl der nicht fragmentierbare Block weniger häufig geplant wird als der Zeitraum, in dem die UGS-Zuwendungen vergeben werden, erzeugt dieser Block tendenziell einen Raum mit nicht zugewiesener Bandbreite, der so groß ist wie der Zeitraum, in dem sich die UGS-Zuwendungen befinden. Dies bietet zahlreiche Möglichkeiten, große, nicht fragmentierbare Zuschüsse zu planen.
Kehren Sie zum Beispiel zu Zuschuss A und DOCSIS 1.0 Zuschuss B zurück. Sie sehen, dass der DOCSIS-konforme Scheduler nun erfolgreich Zuschuss B nach dem ersten Block mit UGS-Zuschüssen planen kann, wenn der nicht fragmentierbare Block eingerichtet wurde.
Abbildung 21: Planen von Finanzhilfen mithilfe des nicht fragmentierbaren Blocks 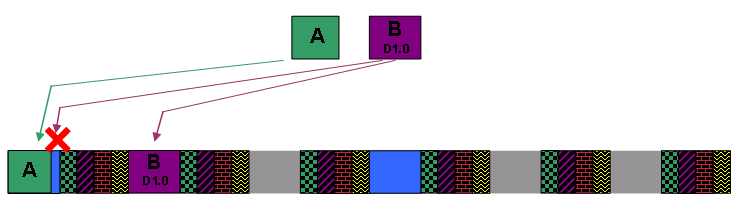
Obwohl der Zuschuss B für DOCSIS 1.0 erfolgreich geplant wurde, besteht zwischen dem Zuschuss A und dem ersten Block von UGS-Zuschüssen immer noch eine kleine Lücke im ungenutzten Bereich. Diese Lücke stellt eine suboptimale Bandbreitennutzung dar und zeigt, warum bei der Bereitstellung von UGS-Diensten Kabelmodems im DOCSIS 1.1-Modus verwendet werden müssen.
Kabelstandard-Phy-Burst
Auf einem Cisco uBR CMTS beträgt der größte Burst, den ein Kabelmodem übertragen kann, standardmäßig 2000 Byte. Dieser Wert für die größte Upstream-Burst-Größe wird verwendet, um die Größe des nicht fragmentierbaren Blocks zu berechnen, wenn der DOCSIS-konforme Scheduler verwendet.
Sie können die größte Burst-Größe mit dem Befehl default-phy-burst max-bytes-allowed-in-Burst pro Kabelschnittstelle ändern.
Der Parameter <max-bytes-allowed-in-burst> hat einen Bereich von 0 bis 4096 Byte und einen Standardwert von 2000 Byte. Wenn Sie den Standardwert ändern möchten, gibt es einige wichtige Einschränkungen hinsichtlich der Festlegung dieses Werts.
Legen Sie für Kabelschnittstellen auf der MC5x20S-Linecard diesen Parameter nicht über den Standardwert von 2000 Byte. Für alle anderen Linecard-Typen, einschließlich der Linecards MC28U, MC5x20U und MC5x20H, können Sie diesen Parameter auf bis zu 4000 Byte festlegen.
Legen Sie den <max-bytes-allowed-in-burst>-Parameter nicht niedriger als die Größe des größten Ethernet-Frames fest, den ein Kabelmodem übertragen muss, einschließlich DOCSIS oder 802.1q-Overhead. Dies bedeutet, dass dieser Wert nicht kleiner als ungefähr 1540 Byte sein darf.
Wenn Sie <max-bytes-allowed-in-burst> auf den Sonderwert 0 setzen, verwendet der CMTS diesen Parameter nicht, um die Größe eines Upstream-Bursts einzuschränken. Sie müssen andere Variablen konfigurieren, um die Upstream-Burst-Größe auf ein vertretbares Limit zu beschränken, z. B. die maximal verkettete Burst-Einstellung in der DOCSIS-Konfigurationsdatei oder der Befehl Upstream-Fragment-Force-Befehl.
Wenn Sie Kabel-Standard-Phy-Burst ändern, um die maximale Upstream-Burst-Größe zu ändern, wird auch die Größe des UGS-freien Blocks entsprechend geändert. Abbildung 22 zeigt, dass bei einer Verringerung der standardmäßigen Phy-Burst-Einstellung des Kabels die Größe des UGS-freien Blocks verringert wird und dass der DOCSIS-konforme Scheduler daher mehr UGS-Anrufe auf einem Upstream zulassen kann. Reduzieren Sie in diesem Beispiel den standardmäßigen Phy-Burst-Wert des Kabels von der Standardeinstellung 2000 auf eine niedrigere Einstellung von 1600, damit ein weiterer UGS-Servicestrom aktiviert werden kann.
Abbildung 22: Reduzierter standardmäßiger Phy-Burst reduziert die unfragmentierbare Blockgröße 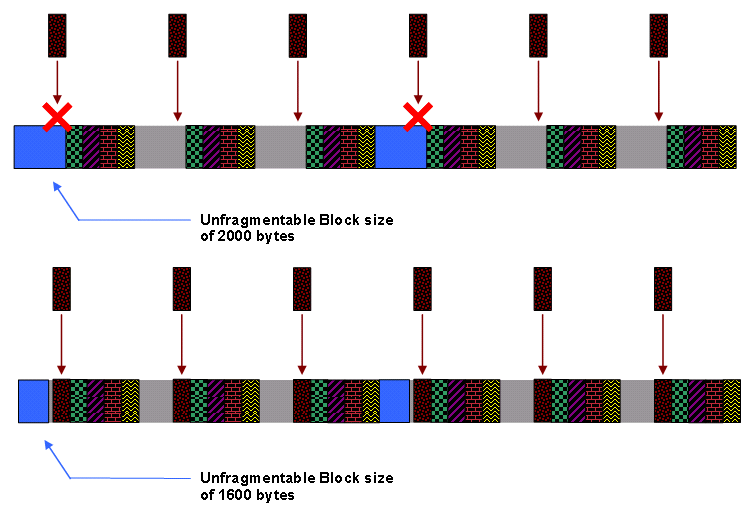
Durch die Reduzierung der maximal zulässigen Burst-Größe mithilfe des Befehls für den standardmäßigen phy-Burst-Verkehr des Kabels kann die Effizienz des Upstream für bestmöglichen Datenverkehr leicht verringert werden, da durch diesen Befehl die Anzahl der Frames verringert wird, die innerhalb eines Bursts verkettet werden können. Eine solche Reduzierung kann auch zu einer erhöhten Fragmentierung führen, wenn der Upstream eine größere Anzahl von UGS-Service-Datenflüssen aktiv ist.
Geringere verkettete Burst-Größen können die Geschwindigkeit des Daten-Uploads in einem bestmöglichen Service-Fluss beeinträchtigen. Das liegt daran, dass die gleichzeitige Übertragung mehrerer Frames schneller ist als die Übertragung einer Bandbreitenanforderung für jeden Frame. Eine reduzierte Verkettung kann sich auch auf die Download-Geschwindigkeit auswirken, da das Kabelmodem nicht in der Lage ist, eine große Anzahl von TCP-ACK-Paketen miteinander zu verknüpfen, die in die Upstream-Richtung geleitet werden.
Manchmal kann die maximale Burst-Größe, wie sie im "langen" IUC des auf einen Upstream angewendeten Modulationsprofils des Kabels konfiguriert ist, die größte Upstream-Burst-Größe bestimmen. Dies kann auftreten, wenn die maximale Burst-Größe im Modulationsprofil kleiner als der Wert des standardmäßigen Phy-Burst-Kabels in Byte ist. Dies ist ein seltenes Szenario. Wenn Sie jedoch den standardmäßigen phy-burst-Parameter des Kabels von 2000 Byte erhöhen, überprüfen Sie die maximale Burst-Größe in der Konfiguration des "langen" IUC, um sicherzustellen, dass Bursts nicht begrenzt werden.
Eine andere Einschränkung der Upstream-Burst-Größe besteht darin, dass maximal 255 Minislots in einem Burst übertragen werden können. Dies kann ein Faktor werden, wenn die Größe des Minislots auf mindestens 8 Byte festgelegt wird. Ein Minislot ist die kleinste Einheit der Upstream-Übertragung in einem DOCSIS-Netzwerk und entspricht in der Regel 8 oder 16 Byte.
Unfragmentierter SteckplatzJitter
Eine weitere Möglichkeit zur Optimierung des DOCSIS-kompatiblen Schedulers, um eine höhere Anzahl gleichzeitiger UGS-Datenflüsse auf einem Upstream zu ermöglichen, besteht darin, dem Scheduler zu ermöglichen, dass große Spitzen von nicht fragmentierbarem bestem Datenverkehr kleine Mengen von Jitter zu UGS-Serviceströmen führen. Sie können dies mit dem Befehl Upstream Upstream-Nummer unfrag-slot-jitter limit val cable interface (Kabelschnittstelle) tun.
In diesem Befehl wird <val> in Mikrosekunden angegeben und hat einen Standardwert von 0, d. h., das Standardverhalten für den DOCSIS-kompatiblen Scheduler besteht darin, nicht zu gestatten, dass unfragmentierbare Gewährleistungen Jitter für UGS- und RTPS-Service-Flows verursachen. Wenn ein positiver, nicht fragmentierbarer Steckplatzjitter angegeben wird, kann der DOCSIS-konforme Scheduler die UGS-Zuschüsse nach dem Zeitpunkt, an dem der Zuschuss geplant werden muss, idealerweise um <val> Mikrosekunden verzögern und somit Jitter verursachen.
Dies hat dieselbe Wirkung wie die Reduzierung der unfragmentierbaren Blockgröße um eine Länge, die der angegebenen Anzahl von Mikrosekunden entspricht. Wenn Sie beispielsweise den Standardwert für den Standard-Phy-Burst (2000 Byte) beibehalten und einen Wert von 1000 Mikrosekunden für einen nicht fragmentierbaren Steckplatzjitter angeben, reduziert der nicht fragmentierbare Block (siehe Abbildung 23).
Abbildung 23: Nicht-0-Jitter für nicht fragmentierbare Steckplätze verringert die Größe nicht fragmentierbarer Blöcke 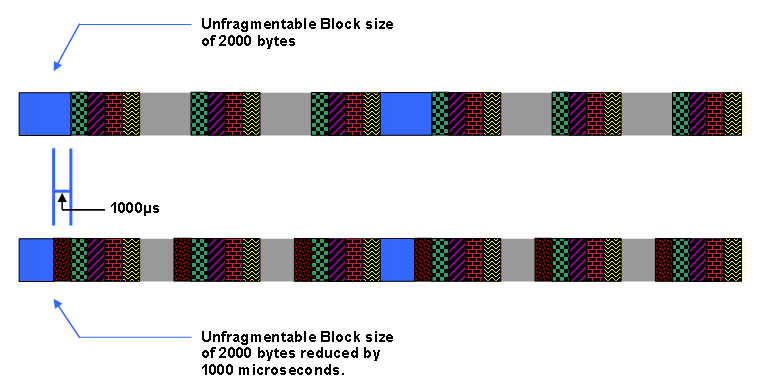
Hinweis: Die Anzahl der Byte, der das 1000-Mikrosekunden-Zeitintervall entspricht, hängt davon ab, wie schnell der Upstream-Kanal für den Betrieb über die Kanalbreite und die Modulationsschemaeinstellungen konfiguriert ist.
Hinweis: Mit einem nicht-0-freien Steckplatzjitter kann der DOCSIS-konforme Scheduler die Anzahl der UGS-Zuweisungen erhöhen, die ein Upstream unterstützt, ähnlich wie bei einem reduzierten standardmäßigen phy-Burst.
Hinweis: Kehren Sie zum Beispiel mit einem großen DOCSIS 1.1-Zuschuss A gefolgt von einem großen, nicht fragmentierbaren DOCSIS 1.0-Zuschuss B zurück, um einen Upstream zu planen. Sie legen den Jitter des nicht fragmentierbaren Steckplatzes auf 1000 Mikrosekunden fest. Der DOCSIS-konforme Scheduler verhält sich wie in den Abbildungen in diesem Abschnitt dargestellt.
Hinweis: Zunächst weist der Scheduler die Übertragungszeit für die Vergabe A zu. Hierzu fragmentiert der Scheduler die Zuschüsse in die Grant-Grant-Gaben A1 und A2, sodass die Zuschüsse vor und nach dem ersten Block von UGS Grants passen. Um Grant B zu planen, muss der Scheduler entscheiden, ob der Scheduler den nicht fragmentierbaren Block nach Vergabe von A2 ohne Verzögerung auf den nächsten Block von UGS Grants um mehr als den konfigurierten, nicht fragmentierbaren Slot Jitter von 1000 Mikrosekunden in den freien Raum einbauen kann. Diese Zahlen zeigen, dass der nächste Block des UGS-Datenverkehrs um mehr als 1500 Mikrosekunden verzögert oder zurückgeschoben wird, wenn der Scheduler Grant B neben A2 platziert. Daher kann der Scheduler Grant B nicht direkt nach Grant A2 platzieren.
Abbildung 24: Zuschuss B kann nicht geplant werden, um A2 zu gewähren. 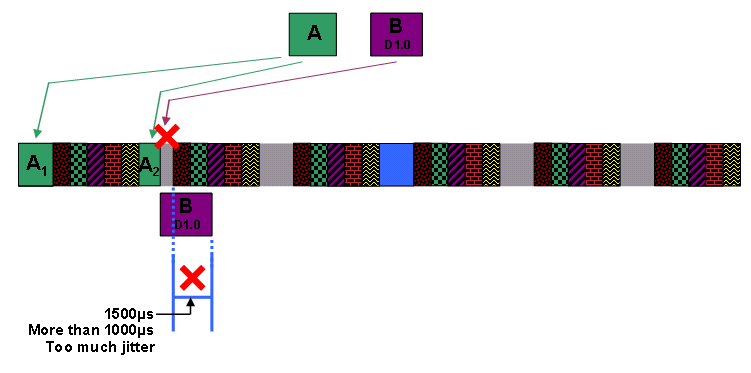
Der nächste Schritt für den DOCSIS-konformen Scheduler besteht darin zu prüfen, ob die nächste verfügbare Lücke den Zuschuss B aufnehmen kann. Abbildung 25 zeigt, dass der dritte Block nicht um mehr als den konfigurierten unfragmentierbaren Steckplatzjitter von 1000 Mikrosekunden verzögert wird, wenn der Scheduler Grant B nach dem zweiten UGS-Grant platziert.
Abbildung 25: Geplante Gewährung B nach dem zweiten Block von UGS-Zuschüssen 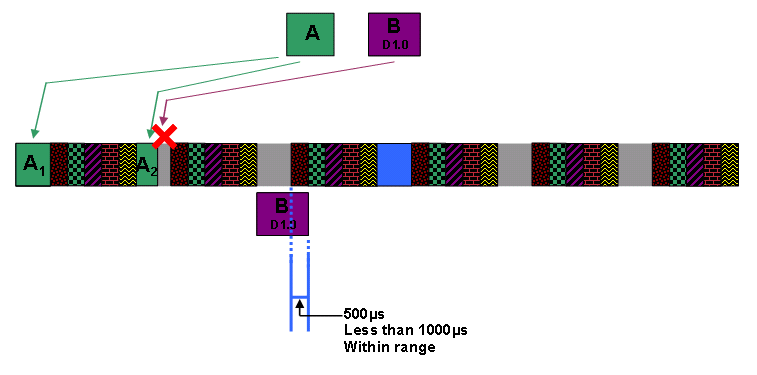
Da bekannt ist, dass die Einfügung von Zuschuss B zu diesem Zeitpunkt keine inakzeptable Jitter für UGS-Zuschüsse verursacht, fügt der DOCSIS-konforme Scheduler Grant B ein und verzögert den folgenden Block von UGS-Zuschüssen geringfügig.
Abbildung 26: Unfragmentierbarer Zuschuss B ist geplant, und UGS-Zuschüsse werden aufgeschoben 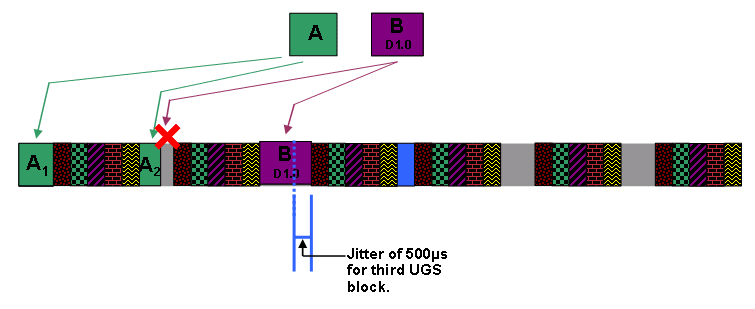
Befehlsausgabe anzeigen
Mit dem Befehl show interface cable interface-number mac-Scheduler Upstream-number können Sie den aktuellen Status des DOCSIS-konformen Schedulers messen. Im folgenden Beispiel wird die Ausgabe dieses Befehls auf einer Cisco uBR7200VXR-Line Card mit MC28U veranschaulicht.
uBR7200VXR# show interface cable 3/0 mac-scheduler 0
DOCSIS 1.1 MAC scheduler for Cable3/0/U0
Queue[Rng Polls] 0/128, 0 drops, max 1
Queue[CIR Grants] 0/64, 0 drops, max 0
Queue[BE(7) Grants] 1/64, 0 drops, max 2
Queue[BE(6) Grants] 0/64, 0 drops, max 0
Queue[BE(5) Grants] 0/64, 0 drops, max 0
Queue[BE(4) Grants] 0/64, 0 drops, max 0
Queue[BE(3) Grants] 0/64, 0 drops, max 0
Queue[BE(2) Grants] 0/64, 0 drops, max 0
Queue[BE(1) Grants] 0/64, 0 drops, max 0
Queue[BE(0) Grants] 1/64, 0 drops, max 1
Req Slots 36356057, Req/Data Slots 185165
Init Mtn Slots 514263, Stn Mtn Slots 314793
Short Grant Slots 12256, Long Grant Slots 4691
ATDMA Short Grant Slots 0, ATDMA Long Grant Slots 0
ATDMA UGS Grant Slots 0
Awacs Slots 277629
Fragmentation count 41
Fragmentation test disabled
Avg upstream channel utilization : 26%
Avg percent contention slots : 73%
Avg percent initial ranging slots : 2%
Avg percent minislots lost on late MAPs : 0%
Sched Table Rsv-state: Grants 0, Reqpolls 0
Sched Table Adm-State: Grants 6, Reqpolls 0, Util 27%
UGS : 6 SIDs, Reservation-level in bps 556800
UGS-AD : 0 SIDs, Reservation-level in bps 0
RTPS : 0 SIDs, Reservation-level in bps 0
NRTPS : 0 SIDs, Reservation-level in bps 0
BE : 35 SIDs, Reservation-level in bps 0
RTPS : 0 SIDs, Reservation-level in bps 0
NRTPS : 0 SIDs, Reservation-level in bps 0
BE : 0 SIDs, Reservation-level in bps 0
In diesem Abschnitt werden die einzelnen Zeilen der Ausgabe dieses Befehls erläutert. Beachten Sie, dass in diesem Abschnitt des Dokuments davon ausgegangen wird, dass Sie bereits mit allgemeinen Konzepten für die vorgelagerte Planung von DOCSIS vertraut sind.
-
DOCSIS 1.1 MAC-Scheduler für Cable3/0/U0
Die erste Zeile der Befehlsausgabe gibt den Upstream-Port an, zu dem die Daten gehören.
-
Warteschlange[Umfragen durchführen] 0/128, 0 Tropfen, max. 1
Diese Zeile zeigt den Status der Warteschlange, die Station-Wartungsschlüssel übernimmt oder Möglichkeiten zum DOCSIS-konformen Scheduler einleitet. 0/128 gibt an, dass derzeit 0 von maximal 128 ausstehenden Auskunftschancen in der Warteschlange verbleiben.
Der Zähler für Verwerfen gibt an, wie oft eine Bereichsmöglichkeit nicht in die Warteschlange gestellt werden konnte, da diese Warteschlange bereits voll war (d. h. 128 ausstehende Gelegenheiten). Bei einer extrem großen Anzahl von Kabelmodems im Internet und bei einer großen Anzahl von UGS- oder RTPS-Serviceströmen treten hier nur Upstream-Meldungen auf. Diese Warteschlange wird mit der höchsten Priorität behandelt, wenn der DOCSIS-Beschwerdeplaner ausgeführt wird. Aus diesem Grund sind Verwerfungen in dieser Warteschlange höchst unwahrscheinlich, weisen aber höchstwahrscheinlich auf eine ernsthafte Überbelegung des Upstream-Kanals hin.
Der Zähler max gibt die maximale Anzahl der vorhandenen und in dieser Warteschlange vorhandenen Elemente an, seit der Befehl show interface cable mac-Scheduler zuletzt ausgeführt wurde. Im Idealfall sollte dies möglichst nahe Null bleiben.
-
Warteschlange[CIR-Zuschüsse] 0/64, 0 Tropfen, max. 0
Diese Zeile zeigt den Status der Warteschlange an, die Zuweisungen für Service-Datenflüsse mit einer festgelegten minimalen reservierten Datenverkehrsrate verwaltet. Anders ausgedrückt: Diese Warteschlangen-Services gewähren für bestätigte CIR-Serviceflows (Information Rate). 0/64 gibt an, dass derzeit 0 von maximal 64 ausstehenden Zuweisungen in der Warteschlange vorhanden sind.
Der Zähler für Verwerfen gibt an, wie oft ein CIR-Zuschuss nicht in die Warteschlange gestellt werden konnte, da diese Warteschlange bereits voll war (d. h. 64 Zuweisungen in der Warteschlange). Drops können sich hier akkumulieren, wenn die Serviceströme im Stil von UGS, RTPS und CIR die Upstream überzeichnen und die Notwendigkeit einer strengeren Zugangskontrolle aufzeigen.
Der maximale Zähler gibt die maximale Anzahl von Zuweisungen in dieser Warteschlange an, seit der Befehl show interface cable mac-Scheduler zuletzt ausgeführt wurde. Diese Warteschlange hat die zweithöchste Priorität, sodass der DOCSIS-konforme Scheduler den Elementen dieser Warteschlange Zeit zuweist, bevor der Scheduler die bestmöglichen Warteschlangen bereitstellt.
-
Warteschlange[BE(w) Grants] x/64, y drop, max. z
Die nächsten acht Einträge zeigen den Status der Warteschlangen, die Zuweisungen für Dienstflüsse der Prioritäten 7 bis 0 verwalten. Die Felder in diesen Einträgen haben dieselbe Bedeutung wie die Felder im Eintrag für die CIR-Warteschlange. Die erste Warteschlange, die in dieser Gruppe zugestellt wird, ist die BE (7)-Warteschlange, und die letzte Warteschlange ist die BE (0)-Warteschlange.
In diesen Warteschlangen können Verwerfungen auftreten, wenn eine höhere Prioritätsstufe des Datenverkehrs die gesamte Upstream-Bandbreite belegt oder wenn eine Überbelegung des Upstream mit UGS-, RTPS- und CIR-Serviceströmen auftritt. Dies kann darauf hindeuten, dass die DOCSIS-Prioritäten für Dienstabläufe mit hohem Volumen neu bewertet werden müssen oder dass eine strengere Zugangskontrolle für die Upstream-Geräte erforderlich ist.
-
Req-Steckplätze 36356057
Diese Zeile gibt die Anzahl der Bandbreitenanfragen an, die angekündigt wurden, seit der Upstream-Aktivierung aktiviert wurde. Diese Zahl muss kontinuierlich steigen.
-
Anforderungs-/Datensteckplätze 185165
Obwohl der Name nahe legt, dass dieses Feld die Anzahl der Anfragen oder Datenchancen anzeigt, die in den Upstream-Bereichen angekündigt werden, zeigt dieses Feld wirklich die Anzahl der Zeiträume an, die das CMTS ankündigt, um erweiterte Funktionen für das Spektrum-Management zu vereinfachen. Dieser Zähler wird für Upstreams auf Linecards im MC28U- und MC520-Format voraussichtlich inkrementiert.
Geschäftsmöglichkeiten für Anfragen/Daten entsprechen denen für Bandbreitenanfragen, jedoch können Kabelmodems auch kleine Datenspitzen in diesen Zeiträumen übertragen. CMTS der Cisco uBR-Serie planen derzeit keine echten Anfragen/Datenchancen.
-
Initiale MTN-Steckplätze 514263
Dieser Posten stellt die Anzahl der anfänglichen Wartungschancen dar, die angekündigt wurden, seit die Upstream-Aktivitäten aktiviert wurden. Diese Zahl muss kontinuierlich steigen. Kabelmodems, die erste Versuche zur Herstellung einer Verbindung mit dem CMTS unternehmen, nutzen anfängliche Wartungsmöglichkeiten.
-
STN MTN-Steckplätze 314793
Diese Zeile gibt die Anzahl der Station-Wartung Keepalive oder die Möglichkeiten zur Bereicherung, die auf dem Upstream angeboten werden. Wenn Kabelmodems am Upstream online sind, muss diese Zahl kontinuierlich steigen.
-
Short Grant Slots 12256, Long Grant Slots 4691
Diese Zeile gibt die Anzahl der Datenzuschüsse an, die für den Upstream angeboten werden. Wenn es Kabelmodems gibt, die Upstream-Daten übertragen, müssen diese Zahlen kontinuierlich steigen.
-
ATDMA Short Grant Slots 0, ATDMA Long Grant Slots 0, ATDMA UGS Grant Slots 0
Diese Zeile stellt die Anzahl der Datenzuschüsse dar, die im Advanced Time Division Multiple Access (ATDMA)-Modus für den Upstream angeboten werden. Wenn Kabelmodems im DOCSIS 2.0-Modus betrieben werden und Upstream-Daten übertragen werden, müssen diese Zahlen kontinuierlich steigen. Beachten Sie, dass ATDMA für den UGS-Datenverkehr separat berücksichtigt.
-
Awacs-Steckplätze 277629
Diese Zeile zeigt die Anzahl der Perioden, die für ein erweitertes Spektrum-Management reserviert sind. Damit eine erweiterte Spektrum-Verwaltung möglich ist, muss der CMTS regelmäßig Zeiten planen, in denen jedes Kabelmodem eine kurze Übertragung durchführen muss, damit die interne Spektrumanalysefunktion die Signalqualität jedes Modems bewerten kann.
-
Fragmentierungszählung 41
Diese Zeile zeigt die Gesamtzahl der Fragmente, die der Upstream-Port empfangen soll. Ein Frame, der in drei Teile zerlegt wurde, würde beispielsweise dazu führen, dass dieser Zähler um drei erhöht wird.
-
Fragmentest deaktiviert
Diese Zeile gibt an, dass der Befehl zur Fragmentierung des Testkabels nicht aufgerufen wurde. Verwenden Sie diesen Befehl nicht in einem Produktionsnetzwerk.
-
Durchschnittliche Upstream-Kanalnutzung: 26 %
Diese Zeile zeigt die aktuelle Upstream-Kanalauslastung durch Upstream-Datenübertragungen. Dies umfasst Übertragungen, die durch kurze, lange, ATDMA Short-, ATDMA Long- und ATDMA UGS-Zuwendungen erfolgen. Der Wert wird jede Sekunde als gleitender Durchschnitt berechnet. Cisco empfiehlt, dass dieser Wert während Spitzenauslastungszeiten über einen längeren Zeitraum 75 % nicht überschreitet. Andernfalls können Endbenutzer Leistungsprobleme bei bestmöglichem Datenverkehr feststellen.
-
Durchschnittl. prozentualer Konfliktplatz: 73 %
Diese Zeile zeigt den Prozentsatz der Upstream-Zeit, die für Bandbreitenanforderungen reserviert ist. Dies entspricht der Freizeit in den Upstream-Bereichen und reduziert sich daher, wenn der Prozentsatz der durchschnittlichen Upstream-Kanalauslastung zunimmt.
-
Anfängliche Abstufungssteckplätze in Prozent: 2 %
Diese Zeile gibt den prozentualen Anteil der Upstream-Zeit an, die für die anfänglichen Suchmöglichkeiten verwendet wird, die Kabelmodems bei Versuchen verwenden, eine Erstverbindung mit dem CMTS herzustellen. Dieser Wert muss immer ein geringer Prozentsatz der Gesamtauslastung bleiben.
-
Durchschnittliche prozentuale Verluste bei verspäteten MAPs: 0 %
Diese Zeile gibt den Prozentsatz der Upstream-Zeit an, der nicht geplant war, da der CMTS nicht in der Lage war, eine MAP-Nachricht für die Bandbreitenzuweisung rechtzeitig an Kabelmodems zu übertragen. Dieser Parameter muss immer nahe Null sein, kann aber beginnen, größere Werte auf Systemen mit einer extrem hohen CPU-Last anzuzeigen.
-
Sched Table Rsv-State: Zuschüsse 0, Anfragen 0
Diese Zeile zeigt die Anzahl der UGS-Style Service Flows (Grants) oder RTPS Style Service Flows (Anfragen), für die im DOCSIS-konformen Scheduler bereits zugewiesene, aber noch nicht aktivierte Zuschüsse vorliegen. Dies tritt auf, wenn Sie ein Kabelmodem mit vorhandenen UGS- oder RTPS-Services durch Lastenausgleich von einem Upstream in einen anderen verschieben. Beachten Sie, dass diese Zahl nur für Zuschüsse gilt, die den DOCSIS-konformen Scheduler und nicht den LLQ-Scheduler verwenden.
-
Sched Table Adm-State: Zuschüsse 6, Anforderungen 0, bis 27 %
Diese Zeile gibt die Anzahl der UGS-Style Service Flows (Grants) oder RTPS Style Service Flows (Request) an, denen im DOCSIS-kompatiblen Scheduler für diesen Upstream bereits zugewiesene Zuwendungen zugewiesen wurden. Util ist die geschätzte Nutzung der insgesamt verfügbaren Upstream-Bandbreite durch diese Service-Datenflüsse. Beachten Sie, dass diese Zahl nur für Zuschüsse gilt, die den DOCSIS-konformen Scheduler und nicht den LLQ-Scheduler verwenden.
-
<Planungstyp>: x SIDs, Reservierungsebene in Bit/s
Diese Zeile gibt die Anzahl der <Scheduling-Type> Service-Flows oder SIDs an, die im Upstream vorhanden sind, und die Menge an Bandbreite in Bits pro Sekunde, die diese Service-Flows reserviert haben. Für bestmögliche Leistung und RTPS-artige Service-Flows wird die Bandbreite nur reserviert, wenn für den Service-Flow eine minimale reservierte Rate konfiguriert wurde.
Vorteile und Nachteile des DOCSIS-konformen Schedulers
Das Ziel des DOCSIS-konformen Schedulers besteht darin, Jitter für Dienstabläufe im Stil von UGS und RTPS zu minimieren und auch unfragmentierbare DOCSIS 1.0-Bursts zu ermöglichen. Der Kompromiss, den der DOCSIS-kompatible Scheduler zur Erreichung dieser Ziele herstellt, besteht darin, dass die maximale Anzahl von UGS-Service-Datenströmen, die pro Upstream unterstützt werden, unter dem theoretischen Höchstwert liegt, den ein DOCSIS-Upstream physisch unterstützen kann, und dass der bestmögliche Datenverkehr einer gewissen Fragmentierung unterliegen kann.
Der DOCSIS-kompatible Scheduler unterstützt zwar etwas weniger als die theoretische maximale Anzahl gleichzeitiger UGS-Service-Datenflüsse auf einem Upstream, während einige andere Scheduling-Implementierungen mehr UGS-Service-Datenflüsse pro Upstream unterstützen können, Sie müssen sich jedoch auf den Kompromiss konzentrieren.
Beispielsweise kann kein Scheduler jitterlose UGS-Serviceströme unterstützen, die fast 100 % Bandbreite eines Upstream-Kanals belegen und gleichzeitig große, nicht fragmentierbare verkettete Frames aus DOCSIS 1.0-Modems unterstützen. Im Hinblick auf das Design des DOCSIS-konformen Schedulers gibt es zwei wichtige Punkte zu verstehen.
-
75 % ist die bestmögliche Upstream-Nutzung.
Cisco hat festgestellt, dass sich die Leistung des bestmöglichen Datenverkehrs spürbar beeinträchtigt, wenn ein Upstream konsistent mit einer Auslastung von mehr als 75 % ausgeführt wird, einschließlich der Auslastung aufgrund von UGS-Service-Datenflüssen. Wenn also UGS und VoIP-Signalisierung mehr als 75 % des Upstream-Datenverkehrs verbrauchen, kann jeder normale IP-Datenverkehr, der durch Best-Effort-Service-Datenflüsse weitergeleitet wird, unter einer erhöhten Latenz leiden, die zu deutlich geringeren Durchsätzen und Reaktionszeiten führt. Diese Leistungsminderung bei höherer Auslastung ist eine Eigenschaft, die die meisten modernen Multi-Access-Netzwerksysteme gemeinsam nutzen, z. B. Ethernet- oder Wireless-LANs.
-
Wenn die normalerweise bereitgestellte Upstream-Kanalbreite von 3,2 MHz verwendet wird, ermöglicht der DOCSIS-kompatible Scheduler die Nutzung von UGS-Serviceströmen bis zu 75 % des Upstream-Kanals. Diese Serviceströme übertragen G.711-VoIP-Anrufe.
Diese beiden Punkte geben einen Einblick in die Überlegungen zum Design, die bei der Erstellung des DOCSIS-konformen Schedulers berücksichtigt wurden. Der DOCSIS-konforme Scheduler wurde so konzipiert, dass bei typischen UGS-Service-Flows (G.711) und bei der am häufigsten bereitgestellten Kanalbreite von 3,2 MHz der Anruf pro Upstream-Grenze bei etwa 75 % Nutzwert beginnt. Das bedeutet, dass der Scheduler Jitter erfolgreich minimiert und auch eine angemessene Anzahl von UGS Service Flows im Upstream zulässt.
Mit anderen Worten: Der DOCSIS-konforme Scheduler wurde so konzipiert, dass er in den DOCSIS-Produktionsnetzwerken ordnungsgemäß funktioniert und nicht, dass UGS-Serviceströme einen unrealistisch hohen Prozentsatz der Upstream-Bandbreite beanspruchen können. Dieses Szenario kann in einem entwickelten Labortestszenario auftreten.
Sie können den DOCSIS-konformen Scheduler so anpassen, dass eine erhöhte Anzahl von UGS-Anrufen pro Upstream möglich ist, wenn auch zulasten von UGS-Jitter und der Effizienz des bestmöglichen Datenverkehrs. Dazu müssen Sie den standardmäßigen phy-burst-Parameter des Kabels auf die empfohlene Mindesteinstellung von 1540 Byte reduzieren. Wenn Sie eine weitere Anrufdichte benötigen, setzen Sie den Upstream-Unfrag-Steckplatz-Jitter auf einen Wert wie 2000 Mikrosekunden. Cisco empfiehlt diese Einstellungen jedoch nicht generell für ein Produktionsnetzwerk.
Ein weiterer Vorteil des DOCSIS-konformen Scheduler besteht darin, dass CMTS-Betreiber keine obligatorische Konfiguration der Zugangskontrolle für UGS- und RTPS-Serviceflows verlangen. Der Grund hierfür ist, dass durch die Scheduling-Methode vor der Zuweisung die Möglichkeit einer versehentlichen Überbelegung ausgeschlossen wird. Auch wenn dies der Fall ist, legt Cisco nahe, dass Betreiber sicherstellen, dass die gesamte Upstream-Auslastung während der Spitzenzeiten über einen längeren Zeitraum hinweg 75 % nicht überschreitet. Aus diesem Grund empfiehlt Cisco die Konfiguration der Zugangskontrolle als Best Practice.
Ein Nachteil des DOCSIS-konformen Scheduler besteht darin, dass die feste Position von UGS-Grants die Fragmentierung von Best Effort Grants erfordern kann, wenn die UGS-Nutzung hoch ist. Im Allgemeinen führt Fragmentierung nicht zu merklichen Leistungsproblemen, sondern zu einer leichten Erhöhung der Latenz bei bestem Datenverkehr und einem Anstieg des Protokoll-Overhead auf dem Upstream-Kanal.
Ein weiterer Nachteil besteht darin, dass es bei DOCSIS 1.0-Kabelmodems, die große, nicht fragmentierbare Upstream-Übertragungen durchführen möchten, zu einer Verzögerung kommen kann, bevor eine geeignete Lücke zwischen den Blöcken von vorab geplanten UGS-Zuschüssen angezeigt wird. Dies kann auch zu einer höheren Latenz für DOCSIS 1.0-Upstream-Datenverkehr und einer nicht optimal genutzten Upstream-Übertragungszeit führen.
Schließlich ist der DOCSIS-konforme Scheduler so konzipiert, dass er am besten in Umgebungen funktioniert, in denen alle UGS-Service-Datenflüsse die gleiche Grant-Größe und dasselbe Grant-Intervall aufweisen. Dies bedeutet, dass alle VoIP-Anrufe denselben Codec verwenden, z. B. 10 ms oder 20 ms Packetization G.711, wie dies in einem typischen Packetkabel 1.0-basierten System der Fall wäre. Wenn unterschiedliche Zuschussintervalle und -größen vorhanden sind, verringert sich die Kapazität des DOCSIS-konformen Schedulers zur Unterstützung einer hohen Anzahl von UGS-Service-Flows auf einem Upstream. Darüber hinaus kann für einige Zuschüsse eine sehr geringe Jitter-Menge (weniger als 2 ms) auftreten, da der Scheduler versucht, UGS-Serviceströme mit unterschiedlichen Zeiträumen und Größen zu durchlaufen.
Da PacketCable MultiMedia (PCMM)-Netzwerke immer häufiger verwendet werden, können mehrere VoIP-Codecs mit verschiedenen Packetisierungsintervallen gleichzeitig verwendet werden. Diese Art von Umgebung kann sich an den Low Latency Queueing Scheduler leihen.
Low Latency Queueing Scheduler
Der LLQ-Scheduler (Low Latency Queuing) wurde in Version 12.3(13a)BC der Cisco IOS-Software eingeführt. LLQ ist die alternative Methode zur Planung von Upstream-Services auf einem Cisco uBR CMTS. Dieser Scheduler wurde entwickelt, um die Anzahl der UGS- und RTPS-Serviceströme zu maximieren, die Upstream gleichzeitig unterstützen kann, und um die Effizienz des bestmöglichen Datenverkehrs in Gegenwart von UGS-Service-Flows zu verbessern. Der Kompromiss besteht darin, dass der LLQ Scheduler keine Gewähr für Jitter für UGS- und RTPS-Service-Flows übernimmt.
Wie im Abschnitt DOCSIS Compliant Scheduler beschrieben, weist der DOCSIS-konforme Scheduler die Übertragungszeit vorab für UGS- und RTPS-Serviceflows zu. Dies ähnelt der Art und Weise, wie ein Legacy Time Division Multiplexing (TDM)-System einem Service Bandbreite zuweist, um bestimmte Latenz- und Jitter-Levels zu gewährleisten.
In modernen paketbasierten Netzwerken stellen Warteschlangen mit niedriger Latenz die Methode dar, mit der Router sicherstellen, dass Pakete, die mit Services mit hoher Priorität verknüpft sind, z. B. Sprache und Video, in einem Netzwerk vor anderen Paketen mit niedrigerer Priorität bereitgestellt werden können. Moderne Router stellen darüber hinaus sicher, dass Latenz und Jitter für wichtigen Datenverkehr minimiert werden.
Die Verwendung des Wortes "Garantie" für das TDM-basierte System und "minimiert" für das LLQ-basierte System in Bezug auf Jitter und Latenz. Eine Garantie für null Latenz und Jitter ist zwar wünschenswert, der Kompromiss besteht jedoch darin, dass ein solches System in der Regel unflexibel, schwer umkonfigurierbar und generell nicht in der Lage ist, sich problemlos an Veränderungen der Netzwerkbedingungen anzupassen.
Ein System, das Latenz und Jitter minimiert, anstatt eine strenge Garantie zu bieten, ist in der Lage, Flexibilität bereitzustellen, um sich im Falle von Veränderungen der Netzwerkbedingungen kontinuierlich zu optimieren. Der Scheduler für Warteschlangen mit niedriger Latenz verhält sich ähnlich wie das paketrouterbasierte LLQ-System. Anstelle eines vorab geplanten Zuweisungssystems für UGS-Zuschüsse plant dieses System die Zuschüsse "so schnell wie möglich" an dem Punkt, an dem sie geplant werden müssen.
Der Ansatz, der die Gewährung von UGS-Serviceströmen vorsieht, muss so schnell wie möglich, aber nicht unbedingt mit perfekter Periodizität, zugewiesen werden. Dieses System tauscht strenge Jitter-Garantien für eine erhöhte UGS-Kapazität und eine weniger große Datenfragmentierung durch bestmögliche Bemühungen aus.
Konfiguration
Für die Cisco IOS Software Releases 12.3(13a)BC und höher ist der LLQ Scheduler einer von zwei alternativen Scheduler Algorithmen. Sie können LLQ für einen, alle oder einige der folgenden Planungsmodi aktivieren:
-
UGS
-
RTPS
-
NRTPS
Der LLQ-Planer ist nicht standardmäßig aktiviert. Sie müssen den LLQ-Scheduler explizit für die erforderlichen Upstream-Planungstypen aktivieren. Verwenden Sie den Planungstyp Upstream Upstream-Port [nrtps | rtps | ugs] mode llq cable interface command.
Im Allgemeinen können Sie den LLQ-Scheduler für alle aufgeführten Scheduling-Modi aktivieren, wenn dies der gewünschte Scheduling-Modus ist. Im Folgenden finden Sie ein Beispiel für eine Situation, in der Sie die LLQ-Planung für nur einen Scheduling-Modus aktivieren, den DOCSIS-kompatiblen Scheduler aber für andere beibehalten möchten:
RTPS-Service-Datenflüsse haben keine strengen Anforderungen an Jitter, UGS-Service-Datenflüsse jedoch. In diesem Fall können Sie den LLQ-Scheduler für RTPS-Service-Flows aktivieren und den DOCSIS-konformen Scheduler für UGS beibehalten.
LLQ Scheduler Betrieb
Der LLQ-Scheduler arbeitet auf die gleiche Weise wie die Prioritätswarteschlangenfunktion des DOCSIS-konformen Schedulers, wobei eine spezielle Low Latency Queue (LLQ) hinzugefügt wird, die Vorrang vor allen anderen Warteschlangen hat.
Der LLQ Scheduler startet einen Timer für alle aktiven UGS- (und RTPS-) Service-Flüsse. Der Timer wird so eingestellt, dass er bei jedem "Grant-Intervall" ausgeht. Wenn der Timer abläuft, wird ein UGS-Grant in die Warteschlange für Fragen gestellt. Da dieser Zuschuss in die Warteschlange für das LLQ-Feld mit der höchsten Priorität gestellt wird, wird der Zuschuss zum nächsten möglichen Zeitpunkt gewährt, an dem freier Speicherplatz verfügbar ist.
Die Diagramme in diesem Abschnitt zeigen ein Beispiel für ein System mit drei aktiven UGS-Service-Datenflüssen mit demselben Grant-Intervall. Abbildung 27 zeigt die Timer für die UGS-Serviceströme links mit der Bezeichnung UGS-1 bis UGS-3. Der gelbe Pfeil bewegt sich im Uhrzeigersinn. Wenn der gelbe Pfeil nach oben zum roten Punkt zeigt, wird der LLQ-Warteschlange ein UGS-Zuschuss hinzugefügt. Sie sehen außerdem die bekannten acht Prioritätswarteschlangen 0 bis 7 und eine neue LLQ-Warteschlange, die allen Vorrang einräumt. Und schließlich rechts ist die Zeitleiste für die Bandbreitenzuweisung, die beschreibt, wie Zuschüsse auf den Upstream-Geräten geplant werden. Um mehr Klarheit zu schaffen, enthält die Zeitlinie für die Bandbreitenzuweisung einen Zeiger auf die aktuelle Zeit. Dieser Zeiger bewegt sich entlang der Zeitachse, während das Beispiel fortfährt.
Abbildung 27: Low Latency Queuing System (LSP) 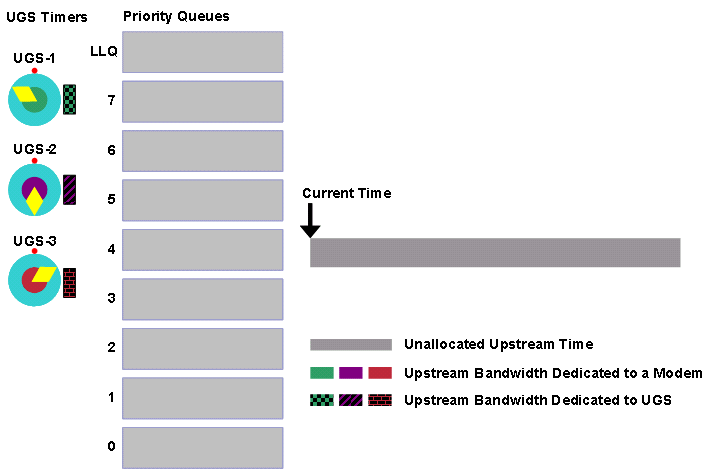
Das erste Ereignis, das auftritt, ist, dass der UGS-1-Timer oben links abläuft. Ein entsprechender Zuschuss wird in die Warteschlange für das LLQ eingefügt. Gleichzeitig wird ein "Best Effort"-Zuschuss mit der Bezeichnung "A mit Priorität 2" in die Warteschlange gestellt.
Abbildung 28: Die Zuschüsse für UGS-1 und für die Prioritätsstufe 2 von Grant A werden in die Warteschlange gestellt 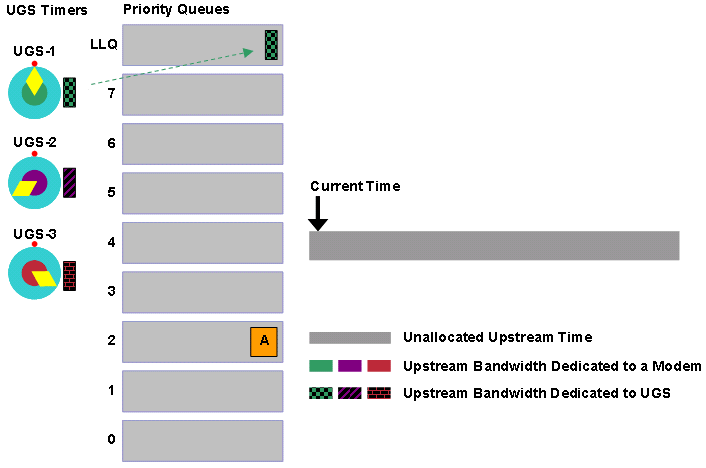
Der LLQ Scheduler weist den ausstehenden Grants nun die Übertragungszeit in der Reihenfolge ihrer Priorität zu. Der erste Zuschuss für die Übertragung ist der Zuschuss für UGS-1, der in der LLQ-Warteschlange wartet. Grant A folgt.
Abbildung 29: Zugewiesene Übertragungszeit für Zuschuss UGS-1 und Zuschuss A 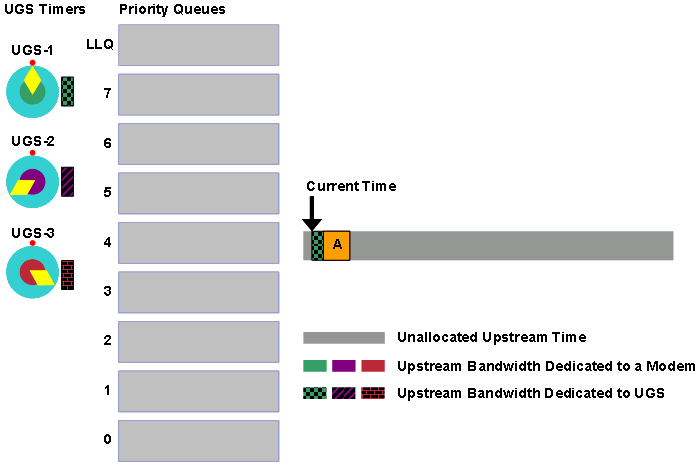
Das nächste Ereignis ist, dass der UGS-2-Timer abläuft und einen Zuschuss für den UGS-2-Servicestrom in die Warteschlange für das LLQ einreiht. Gleichzeitig wird ein Grant B der Priorität 0 in die Warteschlange gestellt, und Grant C der Priorität 6 wird in die Warteschlange gestellt.
Abbildung 30: Der Timer UGS-2 ist abgelaufen. Die Zuschüsse B und C werden in Warteschlange gestellt. 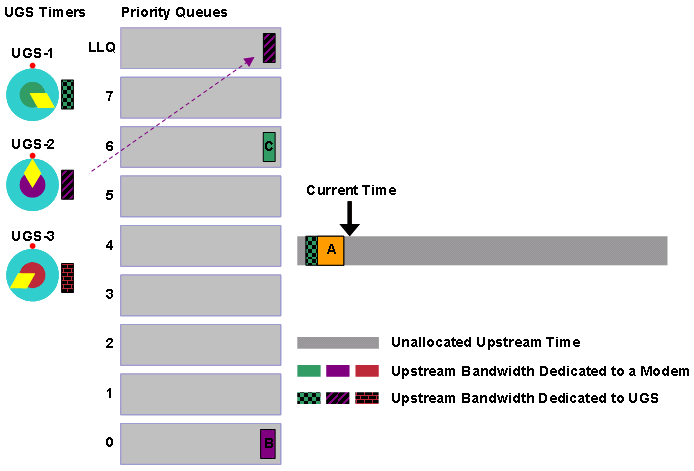
Der LLQ Scheduler weist die Übertragungszeit erneut in der Reihenfolge der Förderpriorität zu, was bedeutet, dass der Scheduler zunächst dem Zuschuss für UGS-2, dann für Zuschuss C und schließlich für Zuschuss B Zeit zuweist.
Abbildung 31: Zugewiesene Übertragungszeit für die Zuschüsse UGS-2, C und B 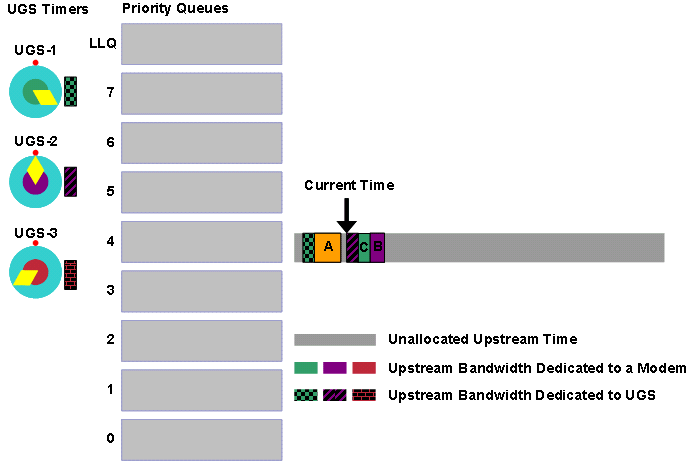
Nehmen Sie an, dass keine "Best Effort"-Gewährleistungen für eine Weile den Scheduler eingeben. Die UGS-Timer laufen jeweils ein paar Mal mehr ab. Sie können nun sehen, mit welchem Zeitraum der Scheduler den UGS-Serviceströmen Zuweisungen zuweist. Sie scheinen gleichmäßig verteilt zu sein. Nehmen wir an, dass die Zuschüsse, wenn sie in der Zeitleiste für die Bandbreitenzuweisung so zueinander erscheinen, keinen signifikanten Jitter aufweisen.
Abbildung 32: UGS-1, UGS-2 und UGS-3 erhalten eine Reihe von Zuschüssen. Grant D wird in Warteschlange gestellt 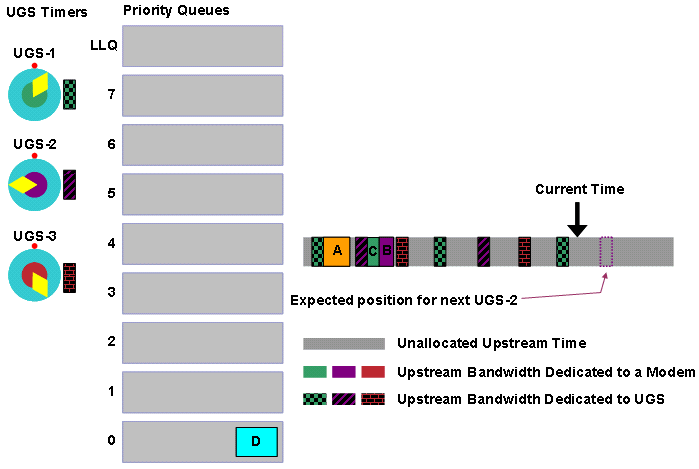
Abbildung 32 zeigt die ideale Position für die nächste UGS-2-Finanzhilfe. Wenn der Zuschuss für UGS-2 an dieser Stelle platziert werden kann, wird UGS-2 keinen Jitter für den Zuschuss erleben. Beachten Sie, dass noch Zeit ist, um die nächste UGS-2-Finanzhilfe in die Warteschlange für das LLQ einzureihen.
Abbildung 32 weist auch darauf hin, dass ein sehr großes Grant D mit der Priorität 0 gerade in die Warteschlange mit der Prioritätsstufe 0 eingedrungen ist. Der LLQ Scheduler plant als Nächstes die Übertragungszeit für Grant D.
Abbildung 33 zeigt dieses Szenario. Wind die Uhr ein wenig weiter bis zu dem Punkt, an dem der nächste Zuschuss für UGS-2 in die Warteschlange gestellt wird.
Abbildung 33: Übertragung mit Empfangsbestätigung D Gewährung für UGS-2 wird in Warteschlange gestellt 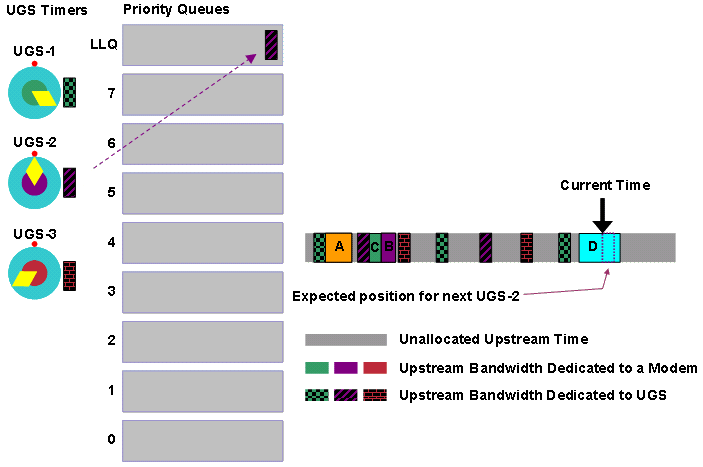
Zuschuss D scheint zum Zeitpunkt geplant zu sein, zu dem der nächste Zuschuss für UGS-2 für null Jitter geplant sein muss. Nun stellt sich die Frage, warum der LLQ-Scheduler es erlaubt, zu diesem Zeitpunkt die Zuweisung D zu planen und die Vergabe von D nicht bis nach der Gewährung für UGS-2 verzögert oder warum D nicht fragmentiert ist. Die Antwort ist, dass der LLQ-Scheduler die Übertragungszeit für UGS-Service-Flows nicht vorab zuweist. Der LLQ-Scheduler weiß daher nicht im Voraus, wo UGS-Zuweisungen auf der Zeitachse für die Bandbreitenzuweisung platziert werden. Der LLQ-Scheduler kennt UGS-Gewährleistungen erst, wenn sie in der LLQ-Warteschlange enthalten sind. In diesem Beispiel ist, wenn der Zuschuss für UGS-2 in die Warteschlange gestellt wird, bereits die Zuweisung D geplant.
Der LLQ Scheduler plant den Zuschuss für UGS-2 bei der nächsten verfügbaren Gelegenheit, aber dieser Zuschuss wird von der idealen Position etwas verzögert, was per definitionem bedeutet, dass dieser spezielle Zuschuss etwas Jitter erfährt.
Abbildung 34: Die Gewährung für UGS-2 ist verzögert, und der Jitter für Anwendererlebnisse 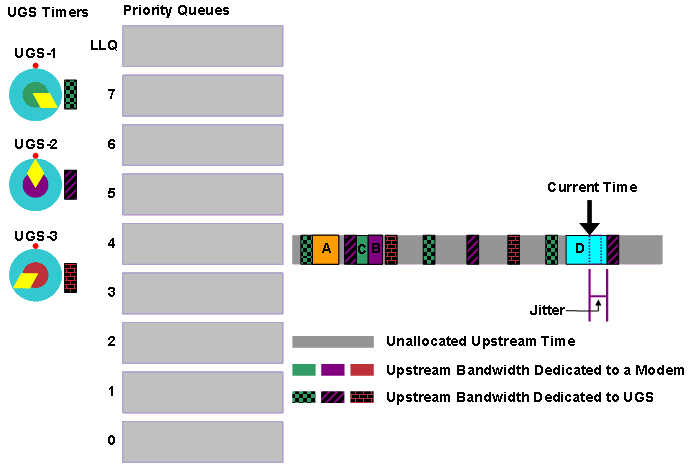
Der DOCSIS-konforme Scheduler hätte diesen Jitter vermeiden können, der LLQ-Scheduler vermeidet jedoch eine Verzögerung oder Fragmentierung des Zuschusses D auf Kosten von nur einer geringen Menge Jitter. Ein Jitter-Puffer in einem VoIP-Endpunkt kann diesen Jitter leicht ausgleichen.
Die andere Situation, in der Jitter auftreten kann, ist, wenn der LLQ-Timer für mehrere Service-Datenflüsse gleichzeitig abläuft und UGS-Zuweisungen hinter anderen UGS-Zuweisungen in der LLQ-Warteschlange warten. Der LLQ Scheduler wurde entwickelt, um die Möglichkeit dieses Ereignisses zu minimieren. Der Scheduler verteilt automatisch die Ablaufzeiten für die Service Flow Timer.
Laut dem DOCSIS-konformen Scheduler verfügt der LLQ-Scheduler über zwei weitere Warteschlangen, die in den Beispielen nicht erwähnt werden. Hier sind die Warteschlangen:
-
Die erste Warteschlange dient der Planung des regelmäßigen Keepalive-Datenverkehrs der Station, um Kabelmodems online zu halten. Diese Warteschlange wird unmittelbar nach der LLQ-Warteschlange serviert.
-
Die zweite Warteschlange ist eine Warteschlange für Zuschüsse, die Service-Datenflüssen mit einem minimalen reservierten Satz (CIR-Service-Datenflüsse) zugewiesen werden. Diese CIR-Warteschlange wird als "Prioritätswarteschlange 8" behandelt, um sicherzustellen, dass Service-Datenflüsse mit einer festgelegten Rate den erforderlichen Mindestdurchsatz erhalten.
Zugangskontrolle
Anders als der DOCSIS-konforme Scheduler verwendet der LLQ-Scheduler kein Pre-Scheduling-System, das eine versehentliche Überbelegung eines Upstream-Datenverkehrs mit UGS- und RTPS-Serviceströmen verhindert. Aus diesem Grund müssen Sie die Upstream-Zugangskontrolle explizit für jeden Upstream konfigurieren, der den LLQ-Scheduler verwendet. Diese Konfiguration stellt sicher, dass die gesamte Upstream-Bandbreite der UGS-Service-Datenflüsse die zulässigen Werte nicht überschreitet.
Cisco empfiehlt im Allgemeinen, dass Sie die Nutzung eines Upstream-Kanals über einen längeren Zeitraum bei Spitzenauslastungen nicht zulassen, dass dieser 75 % überschreitet. Wenn beispielsweise der UGS-Datenverkehr mehr als 75 % der Upstream-Bandbreite beansprucht, treten bei Best Effort-Daten übermäßige Latenz und Probleme bei der Durchsatzleistung auf.
Wenn ein CMTS-Betreiber die negativen Folgen für den Datenverkehr mit bestem Datenverkehr akzeptieren kann, können Sie natürlich zulassen, dass die UGS-Serviceströme mehr als 75 % der verfügbaren Upstream-Bandbreite beanspruchen. Sie müssen jedoch auch die Auswirkungen auf den Layer-2-Management-Datenverkehr auf den Upstream-Kanal berücksichtigen. Sie müssen Zeit für die anfängliche und die Station-Wartung Messaging (Kabelmodem-Keepalives). Wenn Sie dies nicht berücksichtigen und der UGS-Datenverkehr fast 100 % der Bandbreite beansprucht, können Kabelmodems nicht online oder offline geschaltet werden.
Hier ist eine Beispielkonfiguration für die Zugangskontrolle. In diesem Beispiel werden die UGS-Serviceströme für einen bestimmten Upstream auf 50 % der verfügbaren Bandbreite des Upstream beschränkt. Diese Form des Befehls überträgt SNMP-Traps auch an alle konfigurierten Netzwerkmanagement-Stationen, wenn die Unter- und Hauptschwellenwerte von 30 % und 40 % der Auslastung erreicht sind. Der Befehl lautet:
Upstream-Upstream-Nummer "Admission Control us-Bandbreite" UGS Minor 30 Dur 40 exklusive 50
Informationen zum Konfigurieren der Zugangskontrolle finden Sie im Abschnitt Zugangskontrolle im DOCSIS-kompatiblen Scheduler.
Befehlsausgabe anzeigen
Geben Sie den Befehl show interface cable interface-number mac-Scheduler Upstream-number aus, um den aktuellen Status des LLQ Scheduler zu messen.
Hier ein Beispiel für die Ausgabe dieses Befehls. Teile der Befehlsausgabe, die sich von denen unterscheiden, wenn der DOCSIS-kompatible Scheduler betriebsbereit ist, sind fett formatiert:
uBR7200VXR# show interface cable 5/0 mac-scheduler 0
DOCSIS 1.1 MAC scheduler for Cable5/0/U0
Queue[Rng Polls] 0/128, 0 drops, max 1
Queue[CIR Grants] 0/64, 0 drops, max 2
Queue[BE(7) Grants] 0/64, 0 drops, max 0
Queue[BE(6) Grants] 0/64, 0 drops, max 0
Queue[BE(5) Grants] 0/64, 0 drops, max 0
Queue[BE(4) Grants] 0/64, 0 drops, max 0
Queue[BE(3) Grants] 0/64, 0 drops, max 2
Queue[BE(2) Grants] 0/64, 0 drops, max 0
Queue[BE(1) Grants] 0/64, 0 drops, max 0
Queue[BE(0) Grants] 0/64, 0 drops, max 5
Queue[LLQ Grants] 0/64, 0 drops, max 3
Req Slots 165488850, Req/Data Slots 871206
Init Mtn Slots 1727283, Stn Mtn Slots 1478295
Short Grant Slots 105668683, Long Grant Slots 52721
ATDMA Short Grant Slots 0, ATDMA Long Grant Slots 0
ATDMA UGS Grant Slots 0
Awacs Slots 1303668
Fragmentation count 11215
Fragmentation test disabled
Avg upstream channel utilization : 6%
Avg percent contention slots : 91%
Avg percent initial ranging slots : 3%
Avg percent minislots lost on late MAPs : 0%
Sched Table Rsv-state: Grants 0, Reqpolls 0
Sched Table Adm-State: Grants 0, Reqpolls 0, Util 1%
UGS : 3 SIDs, Reservation-level in bps 278400
UGS-AD : 0 SIDs, Reservation-level in bps 0
RTPS : 0 SIDs, Reservation-level in bps 0
NRTPS : 0 SIDs, Reservation-level in bps 0
BE : 14 SIDs, Reservation-level in bps 0
r4k ticks in 1ms 600000
Total scheduling events 5009
No search was needed 5009
Previous entry free 0
Next entry free 0
Could not schedule 0
Recovery failed 0
Curr time 1341 entry 61
Entry 188, Bin 13
SID: 416 IUC: 5, size_ms: 17 size_byte: 232 Frag: N Inval: 20
type 8, perfect time ref 188, skew from ref 0, priority 10
position 188, bin 13
Entry 188, Bin 14
SID: 414 IUC: 5, size_ms: 17 size_byte: 232 Frag: N Inval: 20
type 8, perfect time ref 188, skew from ref 0, priority 10
position 188, bin 14
Entry 192, Bin 12
SID: 415 IUC: 5, size_ms: 17 size_byte: 232 Frag: N Inval: 20
type 8, perfect time ref 192, skew from ref 0, priority 10
position 192, bin 12
Eine Erklärung der einfachen Textzeilen in dieser Ausgabe finden Sie im Abschnitt Befehlsausgabe anzeigen für DOCSIS-konforme Zeitplanung.
Nachfolgend finden Sie die Beschreibungen der fett formatierten Zeilen der Befehlsausgabe show:
-
Warteschlange[LLQ Grants] 0/64, 0 Tropfen, max. 3
Diese Zeile zeigt den Status der LLQ-Warteschlange an, die die Zuweisung von Service-Flow-Typen verwaltet, die im Kabelvorlaufplanungstyp angegeben sind [nrtps | rtps | ugs] mode llq-Befehl. 0/64 gibt an, dass derzeit 0 von maximal 64 ausstehenden Zuweisungen in der Warteschlange vorhanden sind.
Der Zähler für Verwerfen gibt an, wie oft der Scheduler keine Warteschlange für ein UGS-Grant oder eine RTPS-Abfrage erstellen konnte, da diese Warteschlange bereits voll war (d. h. wenn 64 Grants in der Warteschlange sind). Wenn es in dieser Warteschlange zu Unterbrechungen kommt, ist die wahrscheinlichste Erklärung, dass der Upstream mit UGS- oder RTPS-Service-Flows überbelegt ist und Sie eine strengere Zugangskontrolle anwenden müssen.
Der maximale Zähler gibt die maximale Anzahl von Zuweisungen an, die sich in dieser Warteschlange befinden, seit der Befehl show interface cable mac-Scheduler zuletzt ausgeführt wurde. Wenn diese Warteschlange vorhanden ist, hat sie die höchste Priorität aller aufgelisteten Warteschlangen.
-
r4k Zecken in 1 ms 60000
Dieses Feld stellt eine interne Timing-Variable dar, die der LLQ-Scheduler verwendet, um sicherzustellen, dass Zuweisungen mit hoher Genauigkeit in die LLQ-Warteschlange eingefügt werden.
-
Planungsereignisse insgesamt 5009
Diese Zeile gibt an, wie oft der LLQ-Scheduler versucht, einen Zuschuss in die Warteschlange zu stellen, seit der Befehl show interface cable mac-Scheduler zuletzt für diesen Upstream ausgeführt wurde. Dieser Zähler wird jedes Mal zurückgesetzt, wenn der Befehl show ausgeführt wird.
-
Keine Suche erforderlich 5009
Nachdem der LLQ-Scheduler einen Zuschuss in die Warteschlange gestellt hat, versucht der LLQ-Scheduler, den Service-Flow-Timer zurückzusetzen, um sich auf das nächste Mal vorzubereiten, wenn ein Zuschuss in die Warteschlange gestellt wird. Wenn bei der Zurücksetzung des Timers keine Probleme auftreten, erhöht sich dieser Zähler. Dieser Zähler muss idealerweise denselben Wert wie der Zähler für die Gesamtterminierungsereignisse aufweisen.
-
Vorheriger Eintrag frei 0, Nächster Eintrag frei 0
Keiner dieser Zähler erhöht die aktuellen Versionen der Cisco IOS Software je. Diese Zähler bleiben immer bei Null.
-
Konnte 0 nicht planen, Wiederherstellung fehlgeschlagen 0
Diese Zeile gibt an, wie oft der LLQ-Planer nicht in der Lage war, den Grant-Timer eines Service-Datenflusses korrekt festzulegen. Dies darf nur auftreten, wenn der LLQ-Scheduler eine extrem große Anzahl von Finanzhilfen mit sehr niedrigen Gewährleistungsintervallen behandelt. Diese Zähler werden in einem Produktionsnetzwerk höchstwahrscheinlich nie steigen. Eine Erhöhung dieser Zähler kann darauf hinweisen, dass UGS- und RTPS-Serviceströme mehr Bandbreite verbrauchen, als tatsächlich für die Upstream-Datenströme verfügbar ist. In diesem Szenario müssen Sie entsprechende Befehle zur Zugangskontrolle implementieren.
-
Aktueller Wert: 1341 Eintrag 61
Diese Zeile zeigt die internen Timer für den LLQ Scheduler, gemessen in Millisekunden. Wenn der hier aufgeführte "Eintrag" dem in der Service-Flow-Statistik aufgelisteten Feld "Eintrag" entspricht, wird ein Zuschuss in die Warteschlange für das LLQ eingefügt.
Diese Statistiken werden für jeden Servicestrom wiederholt, den der LLQ-Scheduler verarbeitet. In diesem Beispiel gibt es drei derartige Service-Flows.
-
Eintrag 188, Bin 13
Wenn der Wert "Entry" (Eintrag) dem Feld "entry" (Eintrag) im vorherigen Element entspricht, läuft der Timer für diesen Dienstablauf ab, und ein Zuschuss wird in die LLQ-Warteschlange gestellt. Dieses Feld wird jedes Mal zurückgesetzt, wenn der Service-Fluss über eine Grant-Warteschlange verfügt.
-
SID: 416
Die Service Identifier (SID) für den Service Flow, der den LLQ Scheduler plant.
-
IUC: 5
Der in einer MAP-Nachricht angegebene Intervallnutzungscode für Zuweisungen, die zu diesem Dienstablauf gehören. Dies sind fast immer 5 für "Short Data" (Kurze Daten), 6 für "Long Data" (Langdaten) oder 11 für "Advanced PHY UGS" (Erweiterte PHY UGS), wenn ein Servicestrom im UGS-Stil verwendet wird. Für den Servicestrom im RTPS-Format ist dieser Wert immer 1 für "Anforderung".
-
size_ms: 17 size_byte: 232
Die Größe des Zuschusses in Minislots gefolgt von der Größe des Zuschusses in Byte. Ein Minislot ist die kleinste Einheit der Upstream-Übertragung in einem DOCSIS-Netzwerk und entspricht in der Regel 8 oder 16 Byte.
-
Frag: N
Gibt an, ob der Zuschuss fragmentierbar ist. Derzeit ist dieser Wert immer auf N festgelegt.
-
Invalide: 20
Das Grant- oder Polling-Intervall in Millisekunden.
-
Typ 8
8 bedeutet, dass der Servicestrom UGS ist, 10 steht für RTPS und 11 für NRTPS.
-
perfekte Uhrzeit ref 188
Der ideale Zeitpunkt, zu dem der Zuschuss geplant werden muss. Dies entspricht in der Regel dem Eintrag oben. Wenn nicht, gibt es Hinweise auf einen stark überlasteten Upstream, der eine strengere Zugangskontrolle erfordert.
-
Verzerrung von ref 0
Die Differenz zwischen dem Zeitpunkt, zu dem der Zuschuss geplant wurde, und dem Zeitpunkt, zu dem der Zuschuss im Idealfall eingeplant werden muss. Dies ist der Unterschied zwischen "Entry" und "perfect time ref". Daher muss dieser Wert normalerweise 0 sein.
-
Priorität 10
In aktuellen Versionen der Cisco IOS Software ist dieser Wert immer auf 10 festgelegt, kann jedoch in Zukunft variieren.
-
Position 188, bin 13
Diese Felder müssen mit "Entry, Bin" (Eintrag, Bin) oben in dieser Liste übereinstimmen.
Vorteile und Nachteile des LLQ Scheduler
Ziel des LLQ Scheduler ist es, die UGS- und RTPS-Kapazität für Upstream-Kanäle zu erhöhen und die Effizienz des bestmöglichen Datenverkehrs zu steigern. Der Kompromiss, den der LLQ Scheduler zur Erreichung dieser Ziele eingeht, besteht darin, dass dieser Scheduler keine expliziten Garantien für UGS und RTPS Service Flow Jitter bietet. Stattdessen plant der LLQ Scheduler UGS-Zuschüsse und RTPS-Umfragen so nahe wie möglich zur idealen Zeit, um Jitter zu minimieren.
Der LLQ-Scheduler kann auch mehrere UGS-Service-Datenflüsse mit unterschiedlichen Gewährleistungsintervallen und Gewährleistungsgrößen besser handhaben als der DOCSIS-konforme Scheduler. Diese Funktion kann in einer PCMM-Umgebung hilfreich sein, in der verschiedene Arten von VoIP-Anrufen und möglicherweise andere Anwendungen gleichzeitig auf einem Upstream-Kanal ausgeführt werden.
Der LLQ-Scheduler plant den bestmöglichen Datenverkehr effizienter, da der LLQ-Scheduler die Wahrscheinlichkeit einer Fragmentierung von Grants reduziert. Wenn unfragmentierbare DOCSIS 1.0-Bursts geplant sind, erzeugt der LLQ-Scheduler vor UGS-Grants oder RTPS-Polls keine Lücken von ungenutzter Bandbreite, wie dies der DOCSIS-kompatible Scheduler manchmal tut. Dies führt zu einer besseren Nutzung der verfügbaren Upstream-Zeit.
Obwohl der UGS-Jitter in der Regel höher ist, wenn Sie den LLQ-Scheduler verwenden, als wenn Sie den DOCSIS-kompatiblen Scheduler verwenden, liegen die Jitter-Ebenen des LLQ-Schedulers in herkömmlichen DOCSIS- oder PacketCable-Netzwerken weit innerhalb der Kapazität der Jitter-Puffer-Technologie für VoIP-Endpunkte. Dies bedeutet, dass die VoIP-Anrufqualität nicht spürbar beeinträchtigt wird, wenn Sie den LLQ Scheduler in einem ordnungsgemäß konzipierten VoIP-Netzwerk verwenden.
Sie können Jitter begrenzen, der bei großen Upstream-Spitzen auftritt. Stellen Sie dabei sicher, dass der Standardwert von 2000 Byte oder weniger für den Parameter "default-phy-burst" des Kabels verwendet wird. Wenn ein System einen besonders langsamen Upstream-Kanal verwendet, z. B. mit 800 kHz oder einer kleineren Kanalbreite, können Sie weitere Jitter-Reduzierungen erzielen, wenn Sie große Bursts mit dem Befehl Upstream-fragmentierung in kleinere Bursts fragmentieren lassen.
Wenn der LLQ Scheduler verwendet wird, müssen Sie die Kabelzugangskontrolle konfigurieren, um eine Überbelegung des Upstream-Kanals zu verhindern. Aktivere UGS-Service-Flows als der Upstream physisch verarbeiten kann, führt zu einer schlechten Sprachqualität in allen UGS-Service-Flows im Upstream. In Extremfällen bedeutet dies auch, dass Kabelmodems offline fallen und neue Kabelmodems nicht online gehen können. Cisco empfiehlt, dass CMTS-Betreiber die Zugangskontrolle so konfigurieren, dass die gesamte Upstream-Auslastung an jedem Upstream-Port über einen längeren Zeitraum nicht über 75 % liegt.
Schlussfolgerungen
Die Cisco uBR-Serie von DOCSIS CMTS-Produkten bietet zwei alternative Upstream-Scheduling-Algorithmen und kann somit eine Vielzahl von Netzwerkbedingungen erfüllen.
Der DOCSIS-konforme Scheduler ist für niedrige Jitter optimiert und eignet sich am besten für typische Packetcable 1.x Sprachsysteme mit einem einheitlichen VoIP Codec, bei denen eine standardmäßige Upstream-Kanalnutzung durch UGS-Service-Flows gewünscht wird.
Der Scheduler für Low Latency Queueing wurde entwickelt, um eine höhere Upstream-Auslastung durch UGS-Service-Flows, eine höhere Effizienz des bestmöglichen Datenverkehrs und Systeme zu unterstützen, die UGS- und RTPS-Service-Flows mit einer Vielzahl von Zuschussintervallen und Zuschussgrößen verwenden.
Anhang A: Mini-Logos
Ein Minislot ist die kleinste Übertragungseinheit im DOCSIS-Upstream. Wenn ein Kabelmodem eine Bandbreitenanforderung an den CMTS überträgt, um die Upstream-Übertragungszeit anzufordern, fragt das Modem in Einheiten von Minislots statt in Byte oder Millisekunden ab. Wenn eine MAP-Nachricht der Bandbreitenzuweisung Modems darüber informiert, wann und wie lange sie übertragen werden können, enthält die Nachricht die Informationen in Einheiten von Minislots.
Die maximale Anzahl von Minislots, die ein Modem anfordern kann, um Daten in einem Burst zu übertragen, beträgt 255. Die Größe des Minislots wird in Einheiten angegeben, die DOCSIS-Ticks genannt werden. Ein DOCSIS-Zecken entspricht 6,25 Mikrosekunden in der Zeit.
Um die Größe des Minislots in Ticks für einen Upstream-Port festzulegen, geben Sie das Upstream-Kabel in der Minislot-Größe an [1] | 2 | 4 | 8 | 16 | 32 | 64 | 128] Cable Interface-Befehl.
Es sind nur bestimmte Minislots mit bestimmten Upstream-Kanalbreiten zulässig. Diese Tabelle zeigt gültige Minislot-Größen im Vergleich zu DOCSIS-Upstream-Kanalbreiten sowie die Länge in Modulationsschemasymbolen eines Minislots mit gültigen Einstellungen.
Hinweis: Ein X-Zeichen bedeutet eine ungültige Kombination.
| Kanalbreite | 200 kHz | 400 kHz | 800 kHz | 1,6 MHz | 3,2 MHz | 6,4 MHz | |
|---|---|---|---|---|---|---|---|
| Minislot-Größe in Zecken | |||||||
| 1 | X | X | X | X | X | 32 | |
| 2 | X | X | X | X | 32 | 64 | |
| 4 | X | X | X | 32 | 64 | 128 | |
| 8 | X | X | 32 | 64 | 128 | 256 | |
| 16 | X | 32 | 64 | 128 | 256 | X | |
| 32 | 32 | 64 | 128 | 256 | X | X | |
| 64 | 64 | 128 | 256 | X | X | X | |
| 128 | 128 | 256 | X | X | X | X |
Um die Anzahl der Byte pro Minislot zu berechnen, multiplizieren Sie die Symbole pro Minislot mit der Anzahl der Bits pro Symbol für das konfigurierte Modulationsschema. Verschiedene Modulationsschemata übertragen unterschiedliche Bitzahlen pro Symbol, wie in dieser Tabelle gezeigt:
| DOCSIS 1.1 TDMA-Modulationsschemata | Bit pro Symbol |
|---|---|
| QPSK | 2 |
| 16-QAM | 4 |
| DOCSIS 2.0 ATDMA-Modulationsschemata | Bit pro Symbol |
|---|---|
| 8-QAM | 1 |
| 32-QAM | 5 |
| 64-QAM | 6 |
Mit einer Kanalbreite von 1,6 MHz und einer Minimalgröße von 4 Zecken können Sie beispielsweise mit der ersten Tabelle 32 Symbole pro Minislot erreichen. Verwenden Sie die zweite Tabelle, um diese Zahl in Byte zu konvertieren, da ein QPSK-Symbol 2 Bit enthält. Ein Minislot in diesem Beispiel entspricht 32 Symbolen pro Minislot * 2 Bit pro Symbol = 64 Bit pro Minislot = 8 Byte pro Minislot.
Beachten Sie, dass die maximale Anzahl von Minislots, die ein Kabelmodem für die Übertragung anfordern kann, 255 beträgt. In diesem Beispiel liegt der größte Burst in Bytes, den ein Modem machen kann, im Upstream bei 255 Minislots * 8 Byte pro Minislot = 2040 Byte.
Beachten Sie, dass diese Zahl in Byte die Fehlerkorrektur für die Post-Forward- und die Post-Physical-Layer-Overhead-Figur ist. Die Fehlerkorrektur und andere DOCSIS PHY-Schicht-Overhead vergrößern die Länge eines Ethernet-Frames um etwa 10 bis 20 Prozent, wenn er den Upstream-Kanal durchläuft. Um die genaue Zahl abzuleiten, verwenden Sie das Modulationsprofil, das auf den Upstream-Port angewendet wird.
Diese Diskussion ist von Bedeutung, da in einem früheren Abschnitt dieses Dokuments angegeben wurde, dass eine der Beschränkungen für die maximale Burst-Größe eines Kabelmodems der im Befehl default-phy-burst konfigurierte Wert ist. Wenn der Befehl default-phy-burst des Kabels im Kontext dieses Beispiels auf 4000 Byte festgelegt ist, ist der Begrenzungsfaktor oder die Burst-Größe der Grenzwert-Grenzwert 255-Minislot (2040 Byte minus Overhead) und nicht der standardmäßige phy-burst-Wert des Kabels.
Mithilfe des Befehls show controller cable interface-number Upstream Upstream-number können Sie verschiedene Ausdrücke der Minislot-Größe für einen Upstream beobachten. Hier ein Beispiel:
uBR7200VXR# show controller cable 5/0 upstream 0 Cable5/0 Upstream 0 is up Frequency 20.600 MHz, Channel Width 1.600 MHz, QPSK Symbol Rate 1.280 Msps This upstream is mapped to physical port 0 Spectrum Group 1, Last Frequency Hop Data Error: NO(0) MC28U CNR measurement : better than 40 dB US phy MER(SNR)_estimate for good packets - 36.1280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 3100 Ranging Backoff Start 3, Ranging Backoff End 6 Ranging Insertion Interval automatic (60 ms) US throttling off Tx Backoff Start 3, Tx Backoff End 5 Modulation Profile Group 41 Concatenation is enabled Fragmentation is enabled part_id=0x3138, rev_id=0x03, rev2_id=0x00 nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 8 Minislot Size in Symbols = 64 Bandwidth Requests = 0x338C Piggyback Requests = 0x66D Invalid BW Requests= 0xD9 Minislots Requested= 0x756C2 Minislots Granted = 0x4E09 Minislot Size in Bytes = 16 Map Advance (Dynamic) : 2482 usecs UCD Count = 8353
Cisco empfiehlt, die Mindestgröße so festzulegen, dass ein Minislot 16 Byte oder dem nächstzulässigen Wert entspricht. Eine Minislot-Größe von 16 Byte gibt Kabelmodems die Möglichkeit, einen Post-FEC-Burst von bis zu 255 * 16 = 4096 Byte zu erzeugen.
Anhang B: MAP Advance
Das CMTS generiert in regelmäßigen Abständen eine spezielle Meldung, die als Bandbreitenzuweisungs-MAP bezeichnet wird. Diese Meldung informiert Kabelmodems über eine genaue Uhrzeit, zu der Modems Übertragungen auf dem Upstream-Kanal durchführen können. Die elektrischen Signale, die die MAP-Nachricht übertragen, benötigen eine begrenzte Zeit, um sich physisch über das Hybrid Fiber Coax (HFC)-Netzwerk vom CMTS an alle angeschlossenen Kabelmodems zu verbreiten. Daher muss die MAP-Nachricht früh genug übertragen werden, damit die Modems die Nachricht empfangen und ihre Upstream-Übertragungen durchführen können, damit sie zum festgelegten Zeitpunkt das CMTS erreichen.
Die MAP-Vorlaufzeit oder die MAP-Look-ahead-Zeit stellt die Differenz zwischen dem Zeitpunkt dar, zu dem der CMTS die MAP-Nachricht generiert, und dem Zeitpunkt, zu dem die erste vom MAP bestellte Übertragung vom CMTS empfangen werden muss. Diese Zeit stellt eine Kombination dieser Verzögerungen in einem DOCSIS-System dar:
-
Die Zeit, die der CMTS benötigt, um die MAP-Nachricht in der Software zu erstellen und die Nachricht in die Warteschlange zu stellen und vom Downstream-Transmission-Schaltkreis zu verarbeiten. Der Wert dieser Komponente ist für verschiedene Plattformen und Architekturen spezifisch und stellt im Allgemeinen einen festen Wert dar.
-
Die Latenz, die die Downstream-Verschachtelungsfunktion hinzufügt, die für die Vorwärtsfehlerkorrektur zum Schutz vor Impulsgeräuschen verwendet wird. Ändern Sie zum Ändern dieses Werts die Downstream-Interleaver-Parameter.
-
Die Zeit, die elektrische Signale benötigen, um vom CMTS durch das HFC-Netzwerk zum Kabelmodem und dann wieder zurück zu gelangen. DOCSIS legt eine maximale unidirektionale Trip-Zeit zwischen dem CMTS und dem Kabelmodem von 800 Mikrosekunden fest. Dieser Wert variiert je nach physischer Länge der Kabelanlage. Dieser Wert wird auch durch das Downstream-Modulationsschema und das Upstream-Kanalbreite- und Modulationsschema beeinflusst.
-
Die Zeit, die das Kabelmodem für die Verarbeitung einer empfangenen MAP-Nachricht und die Vorbereitung auf die Upstream-Übertragung benötigt. Der Wert darf nicht mehr als 200 Mikrosekunden und alle Upstream-Schaltverzögerungen gemäß den Richtlinien der DOCSIS-Spezifikation betragen. In Wirklichkeit kann diese Zeit bis zu 300 Mikrosekunden oder bis zu 100 Mikrosekunden, je nach Marke, Modell und Firmware-Version des Kabelmodems.
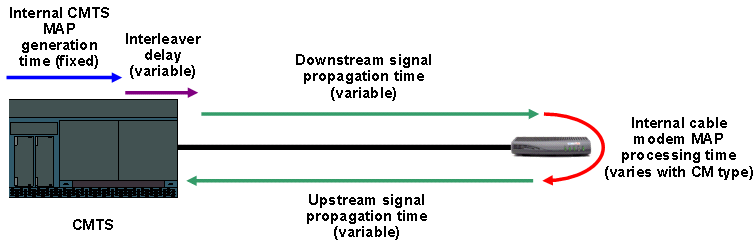
Die Vorlaufzeit der Karte kann die Latenz von Upstream-Übertragungen erheblich beeinflussen, da dieser Wert die minimale Verzögerung zwischen dem Zeitpunkt darstellt, zu dem das CMTS weiß, dass ein Kabelmodem eine Übertragung durchführen möchte, und dem Zeitpunkt, zu dem das Modem diese Übertragung durchführen darf. Minimieren Sie deshalb die Vorlaufzeit, um die Upstream-Latenz zu reduzieren.
Beachten Sie, dass in einem überlasteten Upstream auch andere Faktoren die Upstream-Latenz beeinflussen. Beispielsweise Verzögerungen, die durch den Algorithmus für Backoff- und Restry-Bandbreitenanforderungen verursacht werden, und die Warteschlangenverwaltung ausstehender Zuwendungen untereinander.
Abbildung 36 zeigt die Beziehung zwischen einem vom CMTS generierten MAP und dem entsprechenden Datenempfang am Upstream.
Abbildung 36: Beziehung zwischen der MAP-Erstellung und dem Empfang von Upstream-Daten 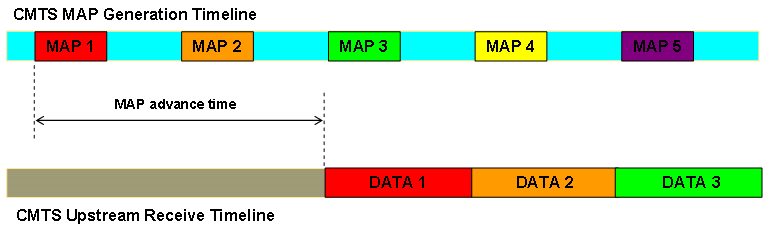
Querrudertiefe
Der erste Faktor in der Kartenvorlaufzeit, der variieren kann, ist der Downstream-Schaltkreis, der für Impulsgeräuschschutz verwendet wird. Diese Tabelle zeigt die Latenz, die Downstream-Übertragungen für verschiedene Interleaver-Tap- und Interleaver-Inkrementeneinstellungen hinzugefügt wird:
Hinweis: Je größer die Tackgröße, desto leistungsstärker die Fehlerkorrektur, aber auch desto größer ist die induzierte Latenz.
| I (Anzahl der Tippbewegungen) | J (Steigerung) | Latenz 64-QAM | Latenz 256-QAM |
|---|---|---|---|
| 8 | 16 | 220 µs | 150 µs |
| 16 | 8 | 480 µs | 330 µs |
| 32 | 4 | 980 µs | 680 µs |
| 64 | 2 | 2000 µs | 1400 µs |
| 128 | 1 | 4000 µs | 2800 µs |
| 12 (EuroDOCSIS) | 17 (EuroDOCSIS) | 430 µs | 320 µs |
Sie können die Interleaver-Parameter mit der Downstream-Interleaving-Tiefe einstellen [8 | 16 | 32 | 64 | 128] Konfigurationsbefehl für Kabelschnittstellen
Hinweis: Der Wert für I (Anzahl der Tippbewegungen) wird angegeben und ein fester entsprechender Wert für J (Erhöhung), wie in der Tabelle dargestellt, wird automatisch angewendet. Für den EuroDOCSIS-Modus (Anhang A) sind die Überleitungsparameter auf I = 12 und J = 17 festgelegt. Der Standardwert für I ist 32, was einen Standardwert für J von 4 ergibt.
Round-Trip-Zeit
Der zweite Faktor, der dazu beiträgt, die Vorlaufzeit abzubilden, die variiert werden kann, ist die elektrische Round-Trip-Zeit zwischen dem CMTS und den Kabelmodems. Der physische Abstand zwischen den CMTS- und Kabelmodems und die Verarbeitungsverzögerung der Kabelmodems beeinflussen diesen Wert.
Die DOCSIS-Spezifikation schreibt vor, dass die maximal zulässige unidirektionale Übertragungszeit zwischen dem CMTS und dem am weitesten entfernten Kabelmodem im System 800 Mikrosekunden nicht überschreitet. Dies impliziert eine Round-Trip-Zeit (ohne Verzögerung bei der Verarbeitung des Kabelmodems) von etwa 1600 Mikrosekunden.
Die Lichtgeschwindigkeit in einem Vakuum beträgt ca. 300.000 km/s, und die Geschwindigkeit der Propagierung für Glasfaserkabel wird in der Regel als 0,67 angegeben. Daher beträgt der maximal zulässige Abstand zwischen einem CMTS und einem Kabelmodem in einer Richtung ungefähr:
Distance = Velocity * Time
= (186,000 miles/sec * 0.67) * 800 microseconds
= 100 miles or 161 kilometers.
Gemäß DOCSIS-Spezifikation darf die Verarbeitungsverzögerung für das Kabelmodem 200 Mikrosekunden sowie jegliche vorgelagerte Verschachtelungsverzögerung nicht überschreiten. In seltenen Fällen kann es jedoch bis zu 300 Mikrosekunden dauern, bis eine MAP-Nachricht von älteren Kabelmodemmarken verarbeitet wird. Neuere Kabelmodems mit leistungsstärkeren CPUs können bis zu 100 Mikrosekunden für die Verarbeitung einer MAP-Nachricht benötigen.
Angenommen, Kabelmodems entsprechen im Durchschnitt der DOCSIS-Spezifikation. Daher muss die maximale Round-Trip-Zeit 1600 + 200 = 1800 Mikrosekunden betragen.
Die meisten Kabelsysteme sind viel kürzer als 100 Meilen. Daher ist es für ein CMTS nicht optimal, immer davon auszugehen, dass die elektrische Round-Trip-Zeit zwischen dem CMTS und dem am weitesten entfernten Kabelmodem den Maximalwert von 1800 Mikrosekunden beträgt.
Für eine grobe Schätzung der größten erwarteten elektrischen Round-Trip-Zeit addieren Sie den Glasfaserabstand zwischen dem CMTS- und Kabelmodem und multiplizieren Sie ihn mit 16 Mikrosekunden pro Meile (10 Mikrosekunden pro km). Addieren Sie dann die Entfernung einer Koaxialkabel und multiplizieren Sie diesen Wert mit 12,4 Mikrosekunden pro Meile (7,6 Mikrosekunden pro km). Fügen Sie dann die Verarbeitungsverzögerung von 200 Mikrosekunden hinzu.
Ein HFC-Segment mit einer Gesamtlänge von 30 Kilometern Glasfaser und einer Kilometer Koaxialkabel zwischen dem CMTS und dem am weitesten entfernten Kabelmodem könnte beispielsweise eine elektrische Round-Trip-Verzögerung von Folgendem erwarten:
20 miles * 16 microseconds/mile + 1 mile * 12.4 microseconds/mile + 200 microseconds = 320 microseconds + 12.4 microseconds + 200 microseconds = 532.4 microseconds
Diese Zahl berücksichtigt keine zusätzlichen Verzögerungen aufgrund von Upstream- und Downstream-Kanalmerkmalen und unterschiedlichen Modemverarbeitungszeiten. Daher ist dieser Wert nicht für die Berechnung der MAP-Vorlaufzeit geeignet.
Eine genauere Möglichkeit zur Bestimmung der Round-Trip-Zeit in einem System besteht darin, den "Timing Offset" für Kabelmodems zu beachten, wie in der Ausgabe des Befehls show cable modem zu sehen ist.Als Teil des umfassenden Prozesses, den Kabelmodems für die Aufrechterhaltung der Kommunikation mit dem CMTS verwenden, berechnet der CMTS die Round-Trip-Zeit für jedes Kabelmodem. Diese Round-Trip-Zeit erscheint als "Timing Offset" in der Befehlsausgabe des Anzeigekabels-Modems in Einheiten von 1/10,24 MHz = 97,7 Nanosekunden, dem Timing Offset oder Ranging Offset Units. Um den Timing-Offset für ein Modem in Mikrosekunden zu konvertieren, multiplizieren Sie den Wert mit 25/256, oder teilen Sie ihn grob mit 10.
Im folgenden Beispiel werden die Timing-Offsets verschiedener Modems in der Befehlsausgabe des Anzeigekabels-Modems in einen Mikrosekundenwert konvertiert:
Hinweis: Der Mikrosekunde-Wert wird kursiv angezeigt.
uBR7200VXR# show cable modem
MAC Address IP Address I/F MAC Prim RxPwr Timing Num BPI
State Sid (dB) Offset CPE Enb
00aa.bb99.0859 4.24.64.28 C5/1/U0 online(pt) 16 0.00 2027 0 Y (198μs)
00aa.bb99.7459 4.24.64.11 C5/1/U0 online(pt) 17 1.00 3528 0 Y (345μs)
00aa.bbf3.7258 4.24.64.31 C5/1/U0 online(pt) 18 0.00 2531 0 Y (247μs)
00aa.bbf3.5658 4.24.64.39 C5/1/U0 online(pt) 19 0.00 6030 0 Y (589μs)
In diesem Fall ist das am weitesten entfernte Modem das letzte Modem mit einem Timing-Offset von 6030. Dies entspricht einer Round-Trip-Zeit von 6030 * 25/256 = 589 Mikrosekunden.
Statische MAP-Erweiterung
In einem System, in dem Sie wissen, dass die Länge des HFC-Netzwerks deutlich unter 100 Meilen liegt, können Sie das CMTS so konfigurieren, dass eine maximale Round-Trip-Zeit verwendet wird, die unter der standardmäßigen 1800 Mikrosekunden liegt, wenn Sie die MAP-Vorlaufzeit berechnen.
Um zu erzwingen, dass der CMTS bei der Vorberechnung des MAP einen benutzerdefinierten Wert für die Round-Trip-Zeit verwendet, führen Sie den Schnittstellenbefehl für die Kabelzuordnung vorwärts statischer Max-Round-Trip-Time aus.
Der Bereich für die maximale Round-Trip-Zeit beträgt 100 bis 2000 Mikrosekunden. Wenn für die maximale Round-Trip-Zeit kein Wert angegeben ist, gilt der Standardwert von 1800 Mikrosekunden.
Hinweis: Sie können das statische Schlüsselwort durch das dynamische Schlüsselwort ersetzen. Siehe nächster Abschnitt.
Stellen Sie sicher, dass die angegebene Round-Trip-Zeit tatsächlich größer ist als die höchste CMTS-to-Cable-Modem-Round-Trip-Zeit am Downstream-Kanal. Wenn ein Kabelmodem eine längere Round-Trip-Zeit als in der Maximum-Round-Trip-Zeit angegeben hat, kann es für das Modem schwierig sein, online zu bleiben. Dies liegt daran, dass ein solches Modem nicht über genügend Zeit verfügt, um auf eine MAP-Nachricht zu reagieren, und daher nicht mit dem CMTS kommunizieren kann.
Wenn der Zeitversatz eines in Mikrosekunden umgewandelten Kabelmodems die angegebene maximale Round-Trip-Zeit überschreitet, wird das Modem mit der Markierung für den falschen Timing-Offset gekennzeichnet. Diese Offset-Markierung wird in der Befehlsausgabe des Kabelmodems als Ausrufezeichen (!) neben dem Timing-Offset des Kabelmodems angezeigt. Diese Situation kann auftreten, wenn der Parameter "max-round-trip" zu niedrig eingestellt ist oder das Kabelmodem an einem Problem leidet, bei dem der Timing-Offset instabil ist und sich im Laufe der Zeit ständig erhöht.
Hier ein Beispiel:
uBR7200VXR# show cable modem
MAC Address IP Address I/F MAC Prim RxPwr Timing Num BPI
State Sid (dB) Offset CPE Enb
00aa.bb99.0859 4.24.64.28 C5/1/U0 online(pt) 16 0.00 2027 0 Y (198μs)
00aa.bb99.7459 4.24.64.11 C5/1/U0 online(pt) 17 1.00 3528 0 Y (345μs)
00aa.bbf3.7258 4.24.64.31 C5/1/U0 online(pt) 18 0.00 2531 0 Y (247μs)
00aa.bbf3.5658 4.24.64.39 C5/1/U0 online(pt) 19 0.00 !5120 0 Y (500μs)
In diesem Beispiel wird der Befehl cable map-advance static 500 angegeben. Allerdings hat eines der an die Kabelschnittstelle angeschlossenen Kabelmodems einen Timing-Offset von mehr als 500 Mikrosekunden (entspricht 500 * 256/25 = 5120 Timing Offset Units).
Beachten Sie, dass der Timing-Offset des letzten Kabelmodems mit der Fehlzeitversatz-Markierung "!" gekennzeichnet ist. Dieser Wert wird auch auf den maximal zulässigen Wert von 5120 Einheiten festgelegt, obwohl der tatsächliche Timing-Offset wesentlich höher sein kann. Dieses Kabelmodem kann offline gehen und unter schlechter Leistung leiden.
Die Markierung für den falschen Timing-Offset für das Kabelmodem bleibt auch dann aktiv, wenn der Timing-Offset unter die maximale Round-Trip-Zeit fällt. Die einzige Möglichkeit, die Markierung zu löschen, besteht darin, das Modem vorübergehend aus der Liste der angezeigten Kabelmodems zu entfernen. Dazu können Sie den Befehl clear cable modem mac-address delete verwenden. Alternativ können Sie die Kabelschnittstelle oder den Upstream-Port zurücksetzen.
Um die Funktionsweise des Algorithmus für die statische Kartenvorschubangabe auf Upstream-Basis zu beobachten, geben Sie den Befehl show controller cable interface-number vorgelagerte Upstream-Nummer-Befehle ein. Hier ein Beispiel:
uBR7200VXR# show controller cable 5/0 upstream 0 Cable5/0 Upstream 0 is up Frequency 20.600 MHz, Channel Width 1.600 MHz, QPSK Symbol Rate 1.280 Msps This upstream is mapped to physical port 0 Spectrum Group is overridden US phy MER(SNR)_estimate for good packets - 36.1280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2037 Ranging Backoff automatic (Start 0, End 3) Ranging Insertion Interval automatic (60 ms) US throttling off Tx Backoff automatic (Start 0, End 3) Modulation Profile Group 43 Concatenation is enabled Fragmentation is enabled part_id=0x3138, rev_id=0x03, rev2_id=0x00 nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 16 Minislot Size in Symbols = 128 Bandwidth Requests = 0x6ECEA Piggyback Requests = 0xDE79 Invalid BW Requests= 0x63D Minislots Requested= 0x8DEE0E Minislots Granted = 0x7CE03 Minislot Size in Bytes = 32 Map Advance (Static) : 3480 usecs UCD Count = 289392
Das Feld Map Advance (Static) (Kartenfortschritt) zeigt eine Vorankündigungszeit von 3480 Mikrosekunden an. Wenn Sie die Downstream-Interleaver-Eigenschaften oder den max-round-trip-time-Parameter ändern, spiegelt sich die Änderung im statischen Kartenvorgabewert wider.
Dynamischer MAP-Fortschritt
Die Verwendung der statischen MAP-Vorausberechnung zur Optimierung der MAP-Vorlaufzeiten erfordert, dass der CMTS-Betreiber die größte Round-Trip-Zeit für ein Kabelsegment manuell festlegt. Wenn sich die Downstream- oder Upstream-Kanalmerkmale ändern oder sich die Betriebsbedingungen ändern, kann sich die maximale Round-Trip-Zeit erheblich ändern. Es kann schwierig sein, die Konfiguration fortlaufend zu aktualisieren, um den Veränderungen der Systembedingungen Rechnung zu tragen.
Der Algorithmus für dynamische MAP-Erweiterungen löst dieses Problem. Der Algorithmus für den dynamischen MAP-Vorlauf durchsucht in regelmäßigen Abständen die Liste des angezeigten Kabelmodems, um nach dem Modem mit dem größten Timing-Offset für den anfänglichen Bereich zu suchen. Anschließend wird dieser Wert automatisch zur Berechnung der MAP-Vorlaufzeit verwendet. Daher verwendet der CMTS immer die niedrigstmögliche Kartenvorlaufzeit.
Der ursprüngliche Zeitabstand für ein Kabelmodem ist der Timing-Offset, der vom Modem an der Stelle gemeldet wird, an der das Modem online ist. In den meisten Fällen befindet sich dieser Timing-Offset in der Befehlsausgabe des Anzeigekabels-Modems. Einige Kabelmodems haben jedoch ein Problem, bei dem der Timing-Offset mit der Zeit auf sehr große Werte hochschaltet. Dies kann die Berechnung der Kartenvorlaufzeit verzerren. Es wird also nur der ursprüngliche Spanning-Timing-Offset verwendet, der nur aktualisiert wird, wenn ein Modem online ist. Führen Sie den Befehl show cable modem ausführse (Leitfaden für das Kabelmodem anzeigen) aus, um den anfänglichen Ranging-Offset und den laufenden Timing-Offset für ein Kabelmodem anzuzeigen. Hier ein Beispiel:
uBR7200VXR# show cable modem 00aa.bbf3.7858 verbose
MAC Address : 00aa.bbf3.7858
IP Address : 4.24.64.18
Prim Sid : 48
Interface : C5/1/U0
Upstream Power : 39.06 dBmV (SNR = 36.12 dB)
Downstream Power : 14.01 dBmV (SNR = 35.04 dB)
Timing Offset : 2566
Initial Timing Offset : 2560
Received Power : 0.00 dBmV
MAC Version : DOC1.1
QoS Provisioned Mode : DOC1.1
Enable DOCSIS2.0 Mode : Y
Phy Operating Mode : tdma
Capabilities : {Frag=Y, Concat=Y, PHS=Y, Priv=BPI+}
Sid/Said Limit : {Max US Sids=16, Max DS Saids=15}
Optional Filtering Support : {802.1P=N, 802.1Q=N}
Transmit Equalizer Support : {Taps/Symbol= 1, Num of Taps= 8}
Number of CPE IPs : 0(Max CPE IPs = 16)
CFG Max-CPE : 32
Flaps : 4(Mar 13 21:13:50)
Errors : 0 CRCs, 0 HCSes
Stn Mtn Failures : 0 aborts, 1 exhausted
Total US Flows : 1(1 active)
Total DS Flows : 1(1 active)
Total US Data : 321 packets, 40199 bytes
Total US Throughput : 129 bits/sec, 0 packets/sec
Total DS Data : 28 packets, 2516 bytes
Total DS Throughput : 0 bits/sec, 0 packets/sec
Active Classifiers : 0 (Max = NO LIMIT)
DSA/DSX messages : permit all
Total Time Online : 1h00m
In diesem Beispiel ist der laufende Zeitversatz (2566) etwas höher als der ursprüngliche Spanning-Timing-Offset (2560). Diese Werte können leicht abweichen. Wenn die Werte jedoch um mehr als einige hundert Einheiten voneinander abweichen, kann die Steuerung des Timing-Offsets des Kabelmodems problematisch sein.
Um die Berechnung der dynamischen Kartenvorlaufberechnung zu aktivieren, geben Sie den Schnittstellenbefehl für die dynamische Sicherheitsfaktor-maximale Round-Trip-Zeit-Kabelschnittstelle ein.
Der Sicherheitsfaktor-Parameter liegt zwischen 100 und 2000 Mikrosekunden. Dieser Parameter wird zur MAP-Vorlaufzeit hinzugefügt, um eine kleine Absicherung zu bieten, um eventuelle unvorhergesehene Verzögerungen bei der Signalübertragung auszugleichen. Der Standardwert ist 1000 Mikrosekunden. Bei stabilen Kabelsystemen, bei denen in der Kabelanlage oder in den Upstream- oder Downstream-Kanälen keine signifikanten Änderungen vorgenommen werden, sollten Sie jedoch einen niedrigeren Wert wie 500 Mikrosekunden verwenden.
Der maximale Round-Trip-Time-Parameter liegt zwischen 100 und 2000 Mikrosekunden. Dieser Parameter wird als Obergrenze für die Zeitausgleich von Kabelmodems verwendet, die mit dem Kabelsegment verbunden sind. Der Standardwert ist 1800 Mikrosekunden. Wenn der Zeitversatz eines in Mikrosekunden umgewandelten Kabelmodems die angegebene maximale Round-Trip-Zeit überschreitet, erscheint dieser mit der Markierung für den falschen Timing-Offset gekennzeichnet.
Legen Sie den Wert für die maximale Round-Trip-Zeit auf einen nicht standardmäßigen Wert fest, wenn Sie wissen, dass die Länge des Kabelsystems deutlich unter 100 Meilen liegt, und wenn Sie wissen, was der maximale normale Zeitversatz für Kabelmodems sein muss, die mit dem Segment verbunden sind.
Beobachten Sie die Funktionsweise des Algorithmus zum dynamischen Kartenvorlauf auf Upstream-Basis mit dem Befehl show controller cable interface-number vorgelagerter Upstream-Number-Befehl. Hier ein Beispiel:
uBR7200VXR# show controller cable 5/0 upstream 0 Cable5/0 Upstream 0 is up Frequency 20.600 MHz, Channel Width 1.600 MHz, QPSK Symbol Rate 1.280 Msps This upstream is mapped to physical port 0 Spectrum Group 1, Last Frequency Hop Data Error: NO(0) MC28U CNR measurement : better than 40 dB US phy MER(SNR)_estimate for good packets - 36.1280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 3100 Ranging Backoff Start 3, Ranging Backoff End 6 Ranging Insertion Interval automatic (60 ms) US throttling off Tx Backoff Start 3, Tx Backoff End 5 Modulation Profile Group 41 Concatenation is enabled Fragmentation is enabled part_id=0x3138, rev_id=0x03, rev2_id=0x00 nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 8 Minislot Size in Symbols = 64 Bandwidth Requests = 0x338C Piggyback Requests = 0x66D Invalid BW Requests= 0xD9 Minislots Requested= 0x756C2 Minislots Granted = 0x4E09 Minislot Size in Bytes = 16 Map Advance (Dynamic) : 2482 usecs UCD Count = 8353
Der Tx Timing Offset-Wert zeigt den größten Timing-Offset für alle mit den Upstream-Kabeln verbundenen Kabelmodems in Timing Offset-Einheiten. Verwenden Sie diesen Wert, um die MAP-Vorlaufzeit zu berechnen. Das Feld Map Advance (Dynamic) zeigt die resultierende Vorlaufzeit der Karte an. Dieser Wert kann variieren, wenn sich der Tx-Timing-Offset ändert, der Sicherheitswert geändert wird oder die Downstream-Interleaver-Eigenschaften geändert werden.
Der Algorithmus für die dynamische MAP-Weiterleitung hängt davon ab, ob Kabelmodems den Timing Offset für die anfängliche Bereichsauswahl dem CMTS korrekt melden. Leider berichten einige Hersteller und Modelle von Kabelmodems über die anfänglichen Spanning-Timing-Offsets als Werte, die deutlich unter dem tatsächlichen Wert liegen. Sie können dies beobachten, wenn Modems Timing Offsets anzeigen, die nahe Null oder sogar negative Werte aufweisen.
Fehlermeldungen ähnlich dem %UBR7200-4-BADTXOFFSET: Schlechter Timing-Offset -2 wurde für Kabelmodem 00ff.0bad.caf3 erkannt. Diese Kabelmodems melden ihre Timing Offsets nicht DOCSIS-konform, der Algorithmus für die dynamische Kartenvorschubberechnung kann keine korrekte Kartenvorlaufzeit berechnen, die garantiert jedem Kabelmodem Zeit zum Empfang und Beantworten von MAP-Nachrichten einräumt.
Wenn solche Kabelmodems in einem Kabelsegment vorhanden sind, deaktivieren Sie den dynamischen MAP-Erweiterungs-Algorithmus, und kehren Sie zum statischen MAP-Erweiterungs-Algorithmus zurück. Weitere Informationen finden Sie unter Warum zeigen einige Kabelmodems ein negatives Time Offset an? für weitere Informationen.
Zugehörige Informationen
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
03-Apr-2006 |
Erstveröffentlichung |
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)