Ultra-M UCS 240M4 Single-HDD-Fehler - Verfahren für Hot-Swap-fähig - CPAR
Download-Optionen
-
ePub (617.4 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einführung
Dieses Dokument beschreibt die erforderlichen Schritte, um die fehlerhafte Festplatte (HDD) in einem Server in einer Ultra-M-Konfiguration zu ersetzen.
Dieses Verfahren gilt für eine OpenStack-Umgebung mit NEWTON-Version, in der CPAR und CPAR nicht direkt auf dem virtuellen System (VM), das auf dem OpenStack bereitgestellt wird, installiert werden.
Hintergrundinformationen
Ultra-M ist eine vorkonfigurierte und validierte Kernlösung für virtualisierte mobile Pakete, die die Bereitstellung von Virtual Network Functions (VNFs) vereinfacht. OpenStack ist der Virtual Infrastructure Manager (VIM) für Ultra-M und besteht aus den folgenden Knotentypen:
- Computing
- Object Storage Disk - Computing (OSD - Computing)
- Controller
- OpenStack-Plattform - Director (OSPD)
Die High-Level-Architektur von Ultra-M und die beteiligten Komponenten sind in diesem Bild dargestellt:

Dieses Dokument richtet sich an Mitarbeiter von Cisco, die mit der Cisco Ultra-M-Plattform vertraut sind. Es enthält eine Beschreibung der Schritte, die bei einem Austausch des OSPD-Servers auf OpenStack-Ebene durchgeführt werden müssen.
Hinweis: Ultra M 5.1.x wird zur Definition der Verfahren in diesem Dokument berücksichtigt.
Abkürzungen
| VNF | Virtuelle Netzwerkfunktion |
| MoP | Verfahrensweise |
| OSD | Objektspeicherdatenträger |
| OSPD | OpenStack Platform Director |
| HDD | Festplattenlaufwerk |
| SSD | Solid-State-Laufwerk |
| VIM | Virtueller Infrastrukturmanager |
| VM | Virtuelles System |
| EM | Element Manager |
| USA | Ultra-Automatisierungsservices |
| UUID | Universeller Identifikator |
MoP-Workflow
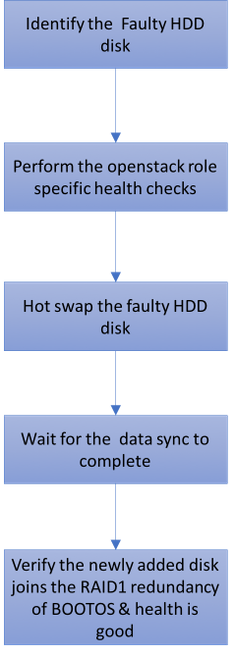
Ausfall einer Festplatte
- Jeder Baremetal-Server wird mit zwei HDD-Laufwerken bereitgestellt, um als BOOT-DISK in der RAID 1-Konfiguration zu fungieren. Bei Ausfall einer Festplatte kann die fehlerhafte Festplatte durch eine Hot-Swap-Funktion ersetzt werden, da die Redundanz auf RAID 1-Ebene vorliegt.
- Verfahren zum Ersetzen einer fehlerhaften Komponente auf dem UCS C240 M4 Server können unter "Ersetzen der Serverkomponenten" aufgerufen werden.
- Bei Ausfall einer einzelnen Festplatte wird nur die fehlerhafte Festplatte im laufenden Betrieb ausgetauscht, sodass nach dem Austausch neuer Festplatten kein BIOS-Upgrade erforderlich ist.
- Nach dem Austausch der Festplatten müssen Sie auf die Datensynchronisierung zwischen den Festplatten warten. Es kann Stunden dauern.
- Bei einer OpenStack-basierten (Ultra-M) Lösung kann der UCS 240M4 Bare-Metal-Server eine der folgenden Rollen übernehmen: Computing, OSD-Computing, Controller und OSPD. Die Schritte, die für die Handhabung eines Festplattenausfalls in jeder dieser Serverrollen erforderlich sind, sind identisch. Der Abschnitt hier beschreibt die Integritätsprüfungen, die vor dem Hot-Swap der Festplatte durchzuführen sind.
Einzelner Festplattenfehler auf dem Computing-Server
- Wenn beim UCS 240M4, der als Computing-Knoten fungiert, ein Festplattenausfall auftritt, führen Sie eine Statusprüfung durch, bevor Sie den defekten Datenträger erneut austauschen.
- Identifizieren Sie die VMs, die auf diesem Server ausgeführt werden, und überprüfen Sie, ob der Status der Funktionen gut ist.
Identifizieren von im Compute-Knoten gehosteten VMs
Identifizieren Sie die VMs, die auf dem Computing-Server gehostet werden, und überprüfen Sie, ob sie aktiv und aktiv sind.
[stack@director ~]$ nova list | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
Health Checks
Schritt 1: Führen Sie den Befehl /opt/CSCOar/bin/arstatus auf Betriebssystemebene aus.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Schritt 2: Führen Sie den Befehl /opt/CSCOar/bin/aregcmd auf Betriebssystemebene aus, und geben Sie die Administratorberechtigungen ein. Überprüfen Sie, ob die CPAR-Health-Funktion 10 von 10 und die CPAR-CLI-Option verlassen.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Schritt 3: Führen Sie den Befehl netstat aus | grep-Durchmesser und überprüfen Sie, ob alle Diameter Routing Agent (DRA)-Verbindungen hergestellt sind.
Die hier erwähnte Ausgabe ist für eine Umgebung vorgesehen, in der Durchmesser-Links erwartet werden. Wenn weniger Links angezeigt werden, stellt dies eine Trennung von DRA dar, die analysiert werden muss.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Schritt 4: Überprüfen Sie, ob das TPS-Protokoll Anforderungen anzeigt, die von CPAR verarbeitet werden. Die hervorgehobenen Werte stellen TPS dar. Sie müssen genau auf diese Werte achten.
Der TPS-Wert darf 1500 nicht überschreiten.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Schritt 5: Suchen Sie nach "error"- oder "alarm"-Meldungen in name_radius_1_log.
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Schritt 6: Führen Sie den folgenden Befehl aus, um die Speichergröße zu überprüfen, die vom CPAR-Prozess verwendet wird:
top | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Der hervorgehobene Wert muss kleiner als 7 GB sein. Dies ist der maximal zulässige Wert auf Anwendungsebene.
Schritt 7: Um die Festplattenauslastung zu überprüfen, führen Sie den Befehl df -h aus.
[root@aaa02 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_arucsvm51-lv_root 26G 21G 4.1G 84% / tmpfs 1.9G 268K 1.9G 1% /dev/shm /dev/sda1 485M 37M 424M 8% /boot /dev/mapper/vg_arucsvm51-lv_home 23G 4.3G 17G 21% /home
Dieser Gesamtwert muss unter 80 % liegen, wenn er mehr als 80 % beträgt, dann müssen die unnötigen Dateien identifiziert und bereinigt werden.
Schritt 8: Vergewissern Sie sich, dass keine Kerndatei generiert wurde.
- Die Core-Datei wird bei einem Anwendungsabsturz generiert, wenn CPAR eine Ausnahme nicht behandeln kann und an diesen beiden Standorten generiert wird:
[root@aaa02 ~]# cd /cisco-ar/ [root@aaa02 ~]# cd /cisco-ar/bin
An diesen beiden Speicherorten dürfen sich keine Kerndateien befinden. Falls gefunden, lösen Sie einen Cisco TAC-Fall aus, um die Ursache für diese Ausnahme zu ermitteln, und fügen Sie die Kerndateien zum Debuggen an.
- Wenn die Integritätsprüfungen in Ordnung sind, fahren Sie mit dem fehlerhaften Hot-Swap-Verfahren fort und warten Sie, bis die Datensynchronisierung abgeschlossen ist, da es Stunden dauert.
Ersetzen der Serverkomponenten
- Wiederholen Sie die Health Check-Verfahren, um sicherzustellen, dass der Systemstatus der auf dem Computing-Knoten gehosteten VMs wiederhergestellt wird.
Single HDD Failure auf Controller-Server
- Wenn beim UCS 240M4, der als Controller-Knoten fungiert, ein Ausfall der Festplattenlaufwerke festgestellt wird, führen Sie diese Statusprüfungen durch, bevor Sie die fehlerhafte Festplatte im laufenden Betrieb austauschen.
- Überprüfen Sie den Status des Schrittmachers auf Controllern.
- Melden Sie sich bei einem der aktiven Controller an, und überprüfen Sie den Status des Schrittmachers. Alle Dienste müssen auf den verfügbaren Controllern ausgeführt und auf dem ausgefallenen Controller gestoppt werden.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Tue Jul 10 10:04:15 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
- Überprüfen Sie den MariaDB-Status in den aktiven Controllern.
[stack@director ~]$ nova list | grep control
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| e19b9625-5635-4a52-a369-44310f3e6a21 | pod2-stack-controller-2 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_ state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st5 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st3 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_s1 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_9 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_loca. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_loc2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_lo0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_l0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsre. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsr1 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'ws2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'w0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE '
*** 192.200.0.102 ***
Variable_nameValue
wsrep_local_state_commentSynced
Variable_nameValue
wsrep_cluster_size2
*** 192.200.0.110 ***
Variable_nameValue
wsrep_local_state_commentSynced
Variable_nameValue
wsrep_cluster_size2
- Überprüfen Sie, ob diese Leitungen für jeden aktiven Controller vorhanden sind:
wsrep_local_state_comment: Synced wsrep_cluster_size: 2
- Überprüfen Sie den Rabbitmq-Status in den aktiven Controllern.
[heat-admin@pod2-stack-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod2-stack-controller-0' ...
[{nodes,[{disc,['rabbit@pod2-stack-controller-0',
'rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2']}]},
{running_nodes,['rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2',
'rabbit@pod2-stack-controller-0']},
{cluster_name,<<"rabbit@pod2-stack-controller-1.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod2-stack-controller-1',[]},
{'rabbit@pod2-stack-controller-2',[]},
{'rabbit@pod2-stack-controller-0',[]}]}]
- Wenn die Integritätsprüfungen in Ordnung sind, fahren Sie mit dem fehlerhaften Hot-Swap-Verfahren fort und warten Sie, bis die Datensynchronisierung abgeschlossen ist, da es Stunden dauert.
Ersetzen der Serverkomponenten
- Wiederholen Sie die Health Check-Verfahren, um sicherzustellen, dass der Gesundheitsstatus des Controllers wiederhergestellt wird.
Single HDD Failure auf OSD-Compute-Server
- Wenn beim UCS 240M4, der als OSD-Compute-Knoten fungiert, ein Ausfall der Festplattenlaufwerke festgestellt wird, führen Sie eine Statusprüfung durch, bevor Sie den defekten Datenträger Hot-Swap durchführen.
- Identifizieren der im OSD-Computing-Knoten gehosteten VMs
- Identifizieren der VMs, die auf dem Computing-Server gehostet werden
[stack@director ~]$ nova list | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
- CEPH-Prozesse sind auf dem osd-Computing-Server aktiv.
[heat-admin@pod2-stack-osd-compute-1 ~]$ systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d1.mount loaded active mounted /var/lib/ceph/osd/ceph-1
var-lib-ceph-osd-ceph\x2d10.mount loaded active mounted /var/lib/ceph/osd/ceph-10
var-lib-ceph-osd-ceph\x2d4.mount loaded active mounted /var/lib/ceph/osd/ceph-4
var-lib-ceph-osd-ceph\x2d7.mount loaded active mounted /var/lib/ceph/osd/ceph-7
ceph-osd@1.service loaded active running Ceph object storage daemon
ceph-osd@10.service loaded active running Ceph object storage daemon
ceph-osd@4.service loaded active running Ceph object storage daemon
ceph-osd@7.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
14 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
- Stellen Sie sicher, dass die Zuordnung von OSD (HDD Disk) zu Journal (SSD) funktioniert.
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
- Stellen Sie sicher, dass die ceph health und osd tree mapping fehlerfrei funktionieren.
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v23095222: 704 pgs, 6 pools, 809 GB data, 424 kobjects
2418 GB used, 10974 GB / 13393 GB avail
704 active+clean
client io 1329 kB/s wr, 0 op/s rd, 122 op/s wr
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
- Wenn die Integritätsprüfungen in Ordnung sind, fahren Sie mit dem fehlerhaften Hot-Swap-Vorgang für die Festplatte fort und warten Sie, bis die Datensynchronisierung abgeschlossen ist, da sie Stunden in Anspruch nimmt.
Ersetzen der Serverkomponenten
- Wiederholen Sie die Health Check-Verfahren, um sicherzustellen, dass der Status der auf dem OSD-Compute-Knoten gehosteten VMs wiederhergestellt wird.
Single HDD Failure auf OSPD-Server
- Wenn beim UCS 240M4, der als OSPD-Knoten fungiert, ein Ausfall der HDD-Laufwerke festgestellt wird, führen Sie eine Statusprüfung durch, bevor Sie die defekte Festplatte erneut austauschen.
- Überprüfen Sie den Status des OpenStack-Stacks und der Knotenliste.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
- Überprüfen Sie, ob alle unterCloud-Services über den OSP-D-Knoten im Status "load", "active" und "running" sind.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-metadata-agent.service loaded active running OpenStack Neutron Metadata Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
lines 1-43
lines 2-44 37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END)
- Wenn die Integritätsprüfungen in Ordnung sind, fahren Sie mit dem fehlerhaften Hot-Swap-Vorgang für die Festplatte fort und warten Sie, bis die Datensynchronisierung abgeschlossen ist, da sie Stunden in Anspruch nimmt.
Ersetzen der Serverkomponenten
- Wiederholen Sie die Health Check-Verfahren, um sicherzustellen, dass der Status des OSPD-Knotens wiederhergestellt wird.
Beiträge von Cisco Ingenieuren
- Karthikeyan DachanamoorthyCisco Advanced Services
- Harshita BhardwajCisco Advanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)