Überprüfen der Integrität eines Tetration Analytics-Clusters
Download-Optionen
-
ePub (715.2 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einführung
In diesem Dokument wird beschrieben, wie der Zustand eines Tetration Analytics-Clusters überprüft wird.
Voraussetzungen
Anforderungen
Cisco empfiehlt, über Kenntnisse in folgenden Bereichen zu verfügen:
- Anmeldung bei einem Cluster
- Grundlegende Benutzeroberfläche
Verwendete Komponenten
Die Informationen in diesem Dokument basieren auf den folgenden Software- und Hardwareversionen:
- Version 2.2.1.x
- 39-HE-Tetration Analytics-Cluster
Die Informationen in diesem Dokument wurden von den Geräten in einer bestimmten Laborumgebung erstellt. Alle in diesem Dokument verwendeten Geräte haben mit einer leeren (Standard-)Konfiguration begonnen. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die potenziellen Auswirkungen eines Befehls verstehen.
Hintergrundinformationen
Ein Tetration-Cluster besteht aus Hunderten von Prozessen (Programmen), die auf mehreren VMs [virtuelle Systeme] auf mehreren UCS C220-M4 Servern ausgeführt werden. Es stehen mehrere Dienste und Funktionen zur Verfügung, um die Vorgänge des Clusters zu überwachen und den Administrator zu benachrichtigen, wenn der Cluster möglicherweise nicht voll funktionsfähig ist.
Dieses Dokument bietet eine Übersicht über die Funktionen, die bei der Überprüfung der Integrität des Clusters überprüft werden müssen. Während der Umfang dieses Dokuments die Überprüfung der Integrität umfasst, sollten Maßnahmen ergriffen werden, um Probleme zu beheben, die scheinbar nicht ordnungsgemäß funktionieren, eine Momentaufnahme erstellen und beim Cisco Tetration Solution Support TAC-Team ein Ticket erstellen.
Zwei gängige Tools zur Überprüfung der Integrität des Clusters sind die Seiten Cluster-Status und Dienststatus, die in diesem Dokument zusammen mit einigen anderen Systemtools behandelt werden. Obwohl kritische E-Mail-Warnmeldungen von Bosun häufig einer der ersten Hinweise für einen Administrator sind, dass im Cluster möglicherweise etwas vorkommt, wird die Überprüfung der Integrität des Clusters in der Regel am besten über die Seiten Cluster-Status und Dienststatus durchgeführt.
Während Boson-Warnungen syslog-ähnliche Funktionen bieten, wurden in einigen Tetration-Versionen einige kritische Bosun-Warnungen in einem normalerweise funktionierenden Cluster ausgelöst. Eine Suche über das Bug Search Tool für Tetration mit dem Metric-Schlüsselwort cisco.com hilft bei der Identifizierung möglicher Probleme für eine bestimmte Metrik.
Wann wird der Status des Clusters überprüft?
Normalerweise muss der Administrator des Clusters die Funktionalität des Clusters nicht überprüfen. Es gibt jedoch gewisse Zeiten, in denen dies notwendig sein kann. Hier einige Beispiele:
- Wenn der Benutzer ein unerwartetes Verhalten in der Benutzeroberfläche (user interface, UI) erkennt. Dies beruht zum Teil auf den Kenntnissen und Erfahrungen des Benutzers, wie der Cluster funktionieren soll, aber einige Beispiele sind in diesem Abschnitt Betriebliche Anzeigeparameter dargestellt.
- Wenn erwartet wird, dass einige Daten angezeigt werden, aber nicht in der Benutzeroberfläche angezeigt werden. Zum Beispiel fließen Daten von einem Software- oder Hardware-Agent (Sensor), wenn der richtige Bereich und der richtige Zeitraum angezeigt werden, in dem Daten angezeigt werden sollen.
- Vor und nach einem geplanten Service, Upgrade oder größeren Aktionen des Clusters. Es ist empfehlenswert, einen Snapshot vor und einen weiteren Snapshot nach Wartungsarbeiten zu sammeln und diesen für den Fall verfügbar zu machen, dass ein TAC-Ticket geöffnet wird. Dadurch kann das TAC das Problem isolieren, indem es nach Änderungen sucht, die während der Wartung vorgenommen wurden.
Hinweis: Einige Serviceunterbrechungen sind für einen bestimmten Zeitraum unmittelbar nach der Systemwartung im Cluster normal. Der Zeitraum kann im Beispiel eines Serveraustauschs bis zu 24 Stunden betragen, wenn ein Datode-VM auf diesem Server ausgeführt wird. Normale Systemredundanz im Cluster reduziert in der Regel die negativen Auswirkungen eines Serveraustauschs.
Verschiedene Möglichkeiten zur Überprüfung des Betriebsstatus eines Tetration-Clusters
Betriebliche Anzeigeparameter
Ein Administrator, der über Kenntnisse und Erfahrung im Betrieb des Clusters verfügt, kann erkennen, wie der normale Betrieb des Clusters in seiner Umgebung aussieht. Dies sind einige Beispiele für die Vorgehensweise bei der Überprüfung, ob der Cluster normal arbeitet.
Beispiel 1: Die aktuellste verfügbare Flow-Zeit ist innerhalb von 10 Minuten nach der aktuellen Zeit verfügbar.

Beispiel 2: Die neueste verfügbare Anwendungs-Workspace-Zeit ist innerhalb von 10 Stunden nach der aktuellen Zeit verfügbar:

Beispiel 3: Dashboard-Inhalte werden gefüllt.

Cluster-Status
Ein Tetration Analytics-Cluster besteht je nach Cluster-Typ aus entweder 6 (8 HE) oder 36 (39 HE) Servern. Die Seite "Cluster Status" (Cluster-Status) zeigt den Status der Server sowie weitere Bare-Metal-Serverinformationen an.
Die Seite Cluster Status (Clusterstatus) befindet sich im Menü Maintenance (Wartung), das über das Dropdown-Menü Settings (Einstellungen > Maintenance (Einstellungen > Wartung) verfügbar ist. Cluster-Status in der linken Spalte.)
Hinweis: Nur das Symbol wird angezeigt, bis Sie auf die linke Spalte klicken.
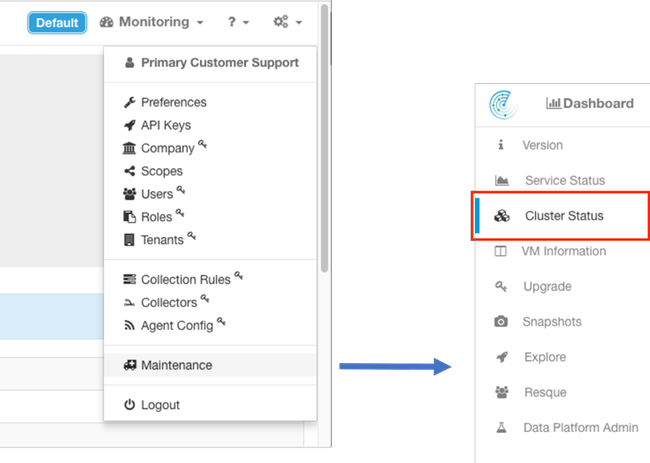
Hinweis: Image wird auf die ersten 6 von 36 Servern (39-HE-Cluster) abgeschnitten.

- Instanzen (virtuelle Systeme), die auf dem Bare-Metal-Server ausgeführt werden.
- Private IP-Adresse innerhalb des Clusters.
- CIMC-IP-Adresse im Cluster.
- Firmware-Versionen (BIOS, CIMC, RAID-Controller), die auf dem Server ausgeführt werden.

Servicestatus
Die ServiceStatus Seite zeigt alle Dienstdie im Cisco Tetration Analytics-Cluster mit ihren Abhängigkeiten und ihrem Status verwendet werden Status.
Die Seite Service Status (Dienststatus) befindet sich im Menü Maintenance (Wartung), das über das Dropdown-Menü Settings (Einstellungen) verfügbar ist. (Einstellungen > Wartung; Dienststatus in der linken Spalte.)
Hinweis: Nur das Symbol wird angezeigt, bis Sie auf die linke Spalte klicken.

Standardmäßig zeigt die Seite "Dienststatus" die Clusterfunktionen und -abhängigkeiten in einer grafischen Ansicht an. Wenn alle Symbole grün leuchten, wird kein Fehler erkannt.

Wenn ein Dienst rot oder orange angezeigt wird, wird in der Strukturansicht eine Liste mit Diensten angezeigt, in der Sie detaillierte Informationen zu den Abhängigkeiten des Dienstes sowie zu anderen Details finden können, die von der Funktion Dienststatus erkannt wurden. Diese Informationen zu Abhängigkeitsfehlern sind besonders wichtig, wenn Sie beim TAC ein Ticket erstellen.
So sieht die Listenansicht beispielsweise aus, wenn eines der virtuellen HDFS DataNode-Systeme im Cluster ausgefallen ist.
Hinweis: Die Redundanz, die im Tetration-Cluster vorgesehen ist, hat möglicherweise keine nennenswerten Auswirkungen auf den Cluster.
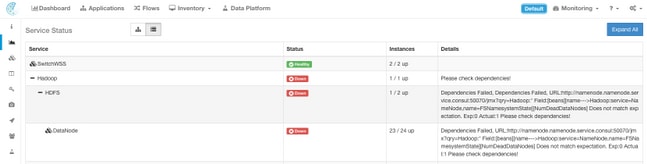
Hinweis: Bestimmte Dienste können nach der Durchführung der Wartung zu einem funktionierenden Zustand zurückkehren. Beispielsweise kann es bis zu 24 Stunden dauern, bis ein Server, auf dem eine Instanz des virtuellen DataNode-Systems ausgeführt wird und der für die RMA-Wartung außer Betrieb genommen und wieder außer Betrieb genommen wird, bevor das erkannte Problem behoben wird.
Obwohl Details zum Service-Status darauf hinweisen, was im Falle eines aufgedeckten Problems passieren könnte, wird empfohlen, ein TAC-Ticket zu eröffnen, wenn Fragen zur Bedeutung und/oder zu möglichen Gegenmaßnahmen bestehen.
Bosun-Warnungen
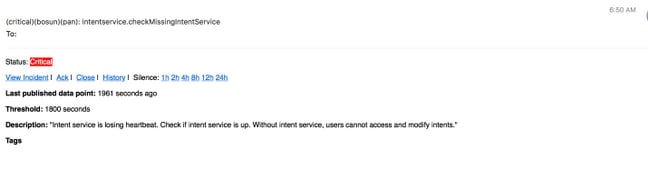

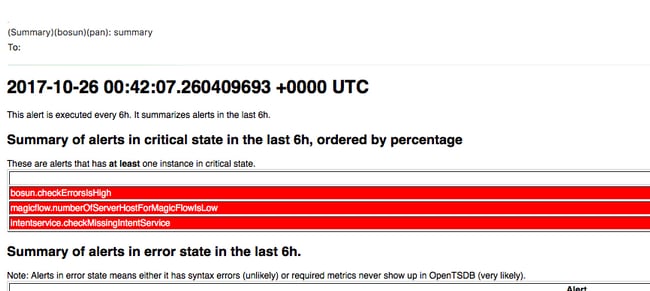
Snapshot erstellen und TAC-Ticket öffnen
Das Cisco Tetration Solution Team ist auf Tetration Analytics-Kunden spezialisiert und unterstützt diese. Eine der gängigsten Aufgaben, die TAC bei der Fehlerbehebung am meisten unterstützen, ist eine Snapshot-Sammlung von Protokollen aus dem Cluster. Manchmal reichen nur die in den Snapshot-Protokolldateien enthaltenen Informationen aus, um das Problem zu verstehen. Ist dies nicht der Fall, stellt ein Snapshot in vielen Fällen den Ausgangspunkt für die Fehlerbehebung dar.
Ein Snapshot in einem Tetration-Cluster ähnelt dem Technologiesupport in anderen Cisco Produkten. Es handelt sich um komprimierte Tarball-Dateien oder Protokolldateien von allen Servern und virtuellen Systemen, die Folgendes umfassen:
- Protokolle
- Bundesstaat der Hadoop/YARN-Anwendung und Protokolle
- Warnmeldungsverlauf
- Zahlreiche TSDB-Statistiken
Die Snapshot-Seite befindet sich im Menü Maintenance (Wartung), das über das Einstellungs-Pulldown-Menü verfügbar ist. (Einstellungen > Wartung; Snapshots in der linken Spalte).
Hinweis: Nur das Symbol wird angezeigt, bis Sie auf die linke Spalte klicken.

Die Snapshot-Seite bietet verschiedene Optionen zur Auswahl, aber wenn Sie nicht von einem TAC-Techniker angewiesen werden, können die Standardwerte zum Erfassen des Snapshots verwendet werden.
Ein wichtiger Bereich, der geändert werden muss, sind Kommentare. Kommentare sollten Informationen bereitstellen, um anzugeben, warum der Snapshot erfasst wurde, wenn mehrere Snapshots vom Cluster gesammelt wurden, und der hinzugefügte Kommentar auch im Snapshot während der Analyse durch das Cisco TAC verfügbar ist.

Wenn auf die Schaltfläche Erstellen geklickt wird, beginnt der Snapshot-Prozess. Es kann jeweils nur ein Snapshot erstellt werden. Der Vorgang kann einige Minuten in Anspruch nehmen. Eine Statusanzeige für die Snapshot-Sammlung wird oben auf der Snapshot-Seite angezeigt.
Der Snapshot kann dann auf das lokale System des Benutzers heruntergeladen werden, wenn Sie auf den entsprechenden Download-Link auf der Snapshot-Seite geklickt haben, wie im Bild gezeigt:

Hinweis: Die Snapshot-Datei kann eine Größe von bis zu mehreren hundert Megabyte haben. Diese Datei kann dann in das offene TAC-Ticket hochgeladen werden.
Zugehörige Informationen
Beiträge von Cisco Ingenieuren
- Bryan DeaverCisco TAC Enginer
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)