Einleitung
In diesem Dokument wird der Prozess zum erneuten Bereitstellen eines Offline-Knotens in Cisco Hyperflex-Clustern beschrieben.
Voraussetzungen
Anforderungen
Dies wird nur für Hyperflex-Cluster unterstützt, die von Intersight und ab Version 5.0(2b) bereitgestellt werden. Cluster, die über den Hyperflex-Installer bereitgestellt und nach Intersight importiert werden, werden für diese Funktion noch nicht unterstützt.
Für diese Intersight-Funktion unterstützte Szenarios:
- FI/Standard-Cluster, Strech-Cluster, Edge-Cluster und DC-No-FI-Cluster
- Cluster mit SED (selbstverschlüsselte Laufwerke)
- Cluster werden nur über Intersight bereitgestellt
- ESXi und SCVM erneut bereitstellen
- Nur SCVM-Redeploy
Nicht unterstützte Szenarien
- 1 GbE HyperFlex Edge- und Stretch-Cluster.
- Cluster in Intersight importiert
Lizenzierung
Für die Neubereitstellung von HyperFlex-Knoten ist eine Intersight Essentials- oder Superior-Lizenz erforderlich. Alle Server im HyperFlex-Cluster müssen mit Intersight Essentials- oder Superior-Lizenz angefordert und konfiguriert werden.
Verwendete Komponenten
- Cisco Interview
- Cisco UCSM (optional)
- Cisco UCS-Server
- Cisco HyperFlex-Cluster Version 5.0(2c)
- VMware ESXi
- VMware vCenter
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
Die Aufrechterhaltung eines Clusters hat aus mehreren Gründen Priorität, am wichtigsten ist jedoch die Redundanz für die Datenintegrität in der Hypercoverge-Speicherlösung. Es gibt mehrere Szenarien, in denen ESXi und SCVM (Storage Controller Virtual Machine) gleichzeitig neu bereitgestellt werden müssen, z. B. das Ersetzen des Bootlaufwerks in Konvergenzknoten.
Für Cluster, die von Intersight bereitgestellt werden, können Sie SCVM erneut bereitstellen, um sie wieder dem Hyperflex-Cluster hinzuzufügen. Diese Aktivität kann jetzt ohne TAC-Unterstützung über Intersight ausgeführt werden.
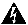
Warnung: Wenn Sie diesen Prozess nicht erfolgreich durchführen, können mehrere unerwartete Probleme auftreten, z. B. künftige Cluster-Upgrades oder Cluster-Erweiterungen.
Konfiguration
Für dieses Beispiel verwenden wir einen Cluster mit 3 Node Edge mit dem Namen Medellin, der Knoten 3 aufgrund eines M.2-Festplattenausfalls beschädigt hat.
Von Intersight geht unser Ausgangspunkt davon aus, dass einige Aspekte bereits abgedeckt sind:
- M.2 Speicher wurde bereits ersetzt
- Der HyperFlex-Cluster ist immer noch fehlerhaft, da dieser Knoten offline ist.
Offline-Überprüfung des Clusterknotens
Sie können sehen, Cluster ist ungesund wie erklärt, und Sie müssen den Knoten wiederherstellen, der offline ist jetzt, da das M.2 Problem behoben wurde
Von Intersight gehen Sie zu Infrastructure Service > Hyperflex Cluster > Overview > Events. Der Status der Ausfallsicherheit wird angezeigt.
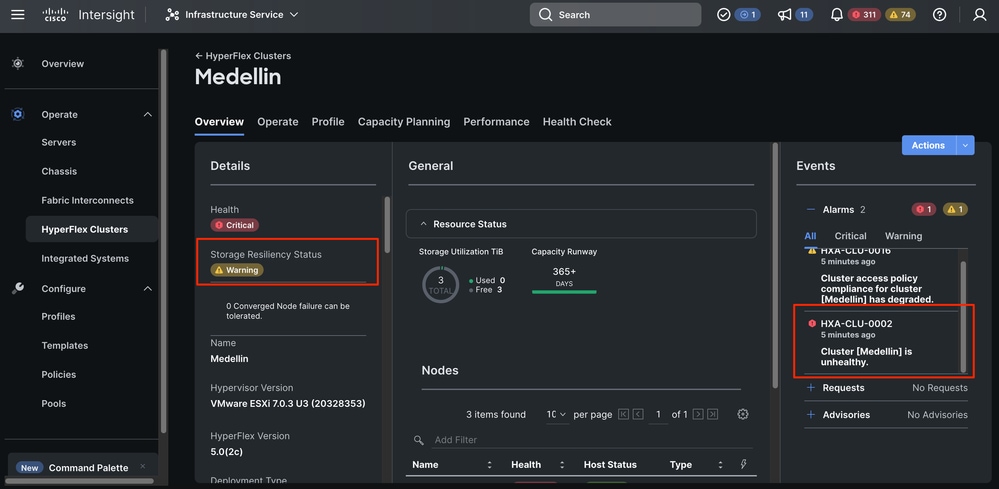
Auf derselben Registerkarte Übersicht können Sie sehen, welcher Knoten ebenfalls offline ist.
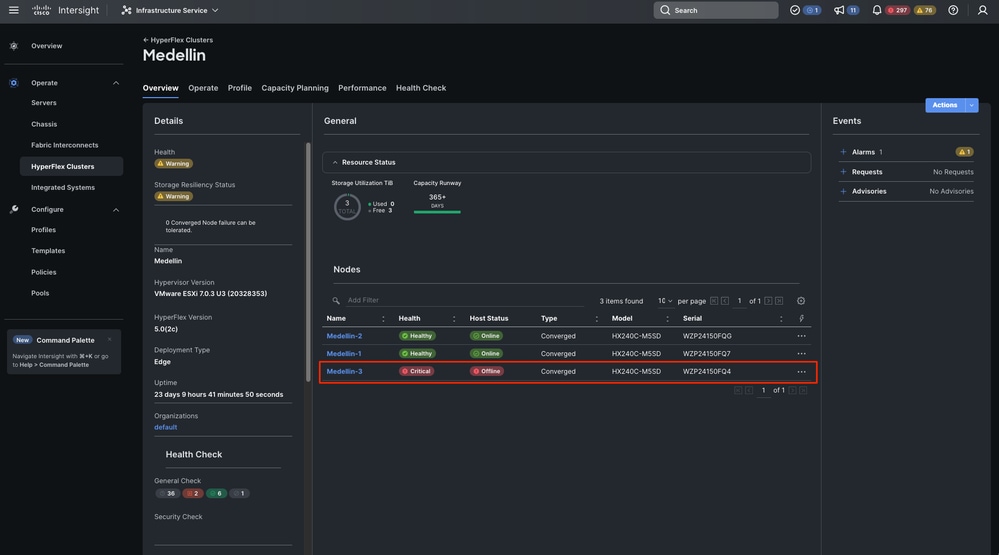
Von vCenter wird außerdem eine Warnung über einen fehlerhaften Cluster ausgegeben.
Schließlich können Sie über die CLI auch den Cluster-Status bestätigen:
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : WARNING
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 0
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 30.4 GiB
Free Capacity : 3.0 TiB
Compression Savings : 62.06%
Deduplication Savings : 0.00%
Total Savings : 62.06%
# of Nodes Configured : 3
# of Nodes Online : 2
Data IP Address : 169.254.218.1
Resiliency Health : WARNING
Policy Compliance : NON_COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 0
# of persistent device failures tolerable : 1
# of cache device failures tolerable : 1
Zone Type : Unknown
All Flash : No
Schritte erneut bereitstellen
Schritt 1: Installieren Sie das ESXi-Betriebssystem neu. Gehen Sie dazu zu Server > Select the Server > Options (three dots) > Select Launch the KVM.
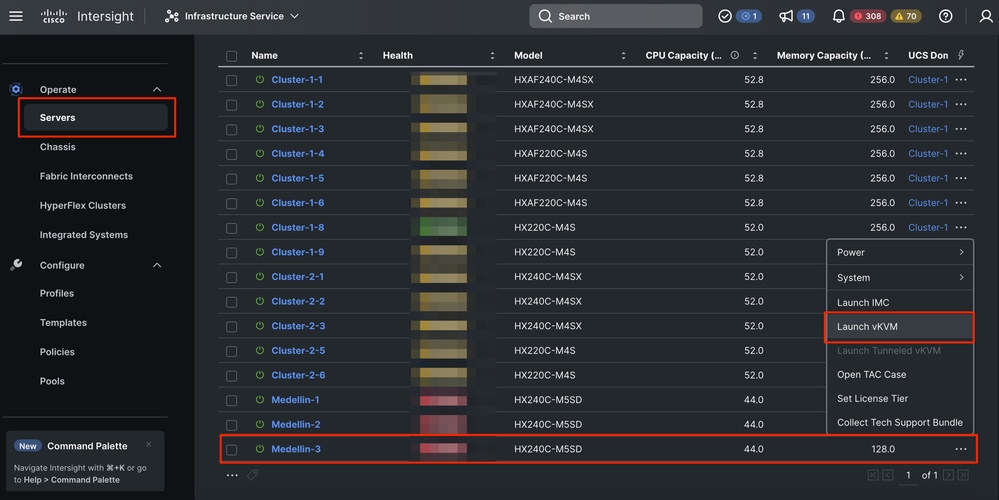
Achtung: Sie müssen ein benutzerdefiniertes Cisco Hyperflex-Image für die gleiche ESXi-Version herunterladen, die andere Knoten im Cluster ausführen. Sie können es von hier herunterladen
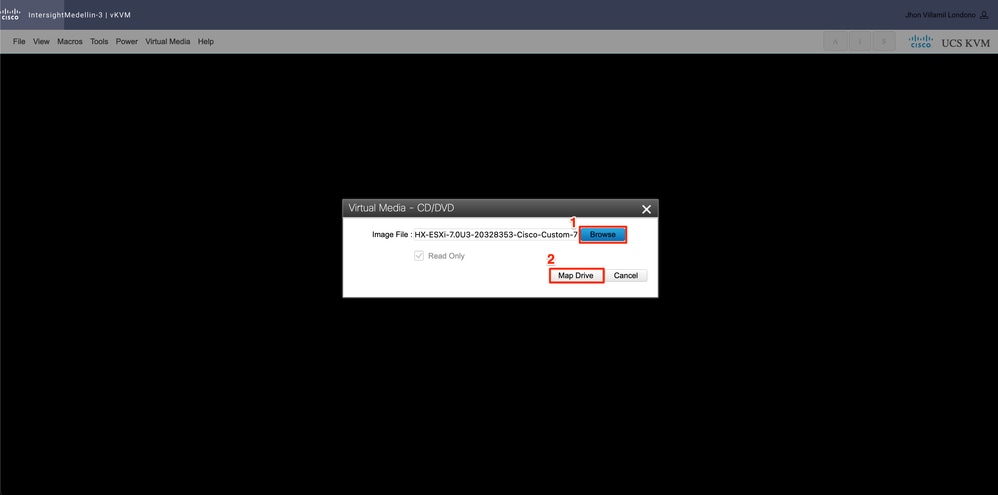
Nach dem Start von KVM Navigate to Virtual Media> Select Activate Virtual Devices (Virtuelle Geräte aktivieren)

Wählen Sie dann Durchsuchen > Wählen Sie das Hyperflex ESXi ISO-Image von Ihrem lokalen Computer aus > Wählen Sie Laufwerk zuordnen
Navigieren Sie je nach Serverstatus zu Ein>, und wählen Sie entweder System einschalten oder System zurücksetzen oder System aus. 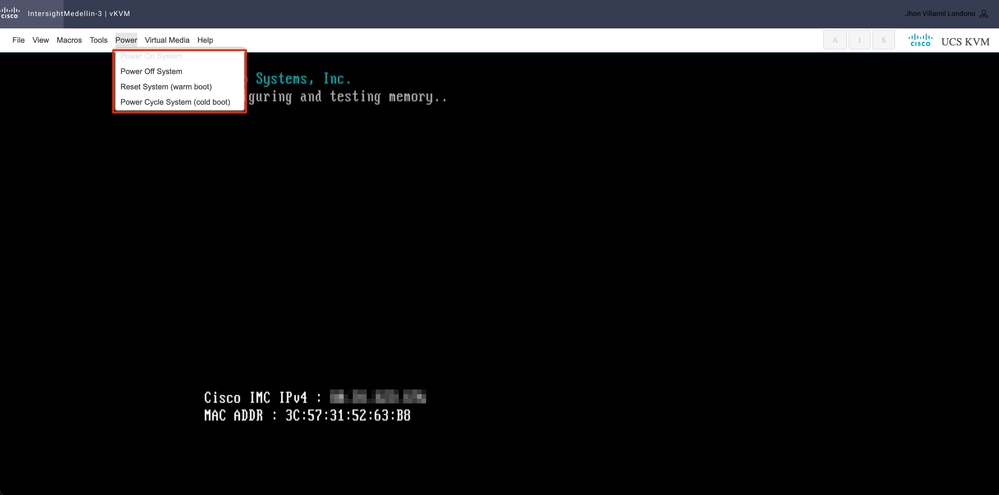
Tipp: Reset System (Warmstart) startet das System neu, ohne es abzuschalten, während Power Cycle System (Kaltstart) das System abschaltet und wieder einschaltet. In diesem Szenario erfüllen beide Optionen bei beschädigter SCVM und neu installierter ESXi denselben Zweck
Sie müssen das virtuelle CD/DVD-Gerät starten. Navigieren Sie zu Tools > Select Keyboard > When you see Boot Menu prompt (Extras > Tastatur auswählen), drücken Sie F6.
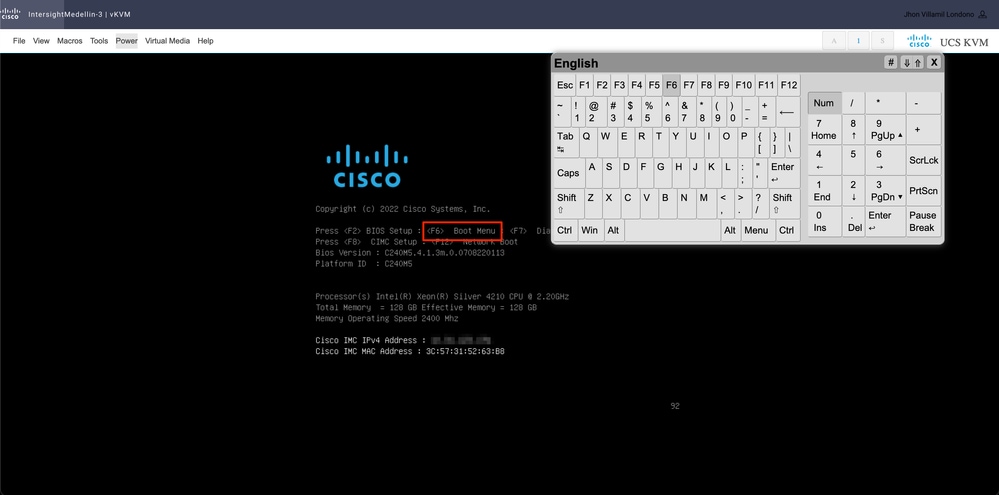
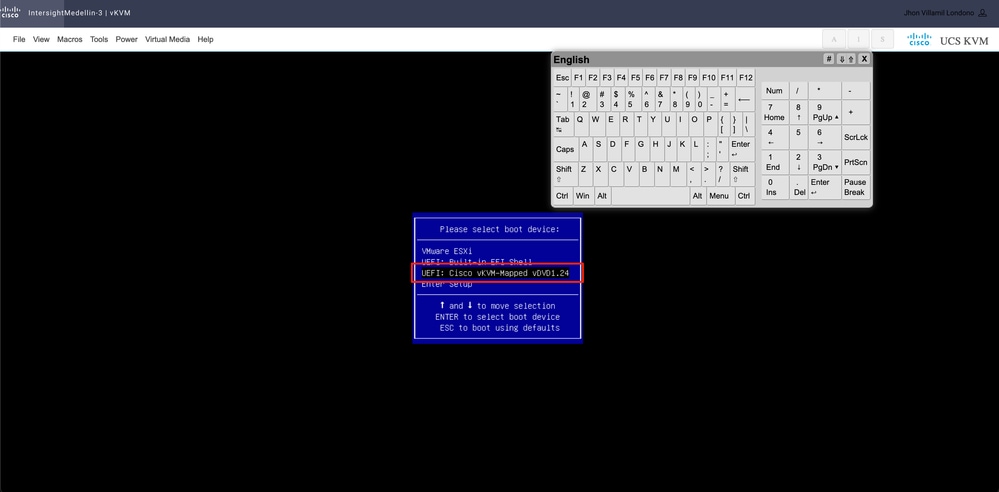
Sie gelangen zum Startmenü und wählen dort Cisco vKVM-Mapped vDVD1.24 aus und drücken Enter
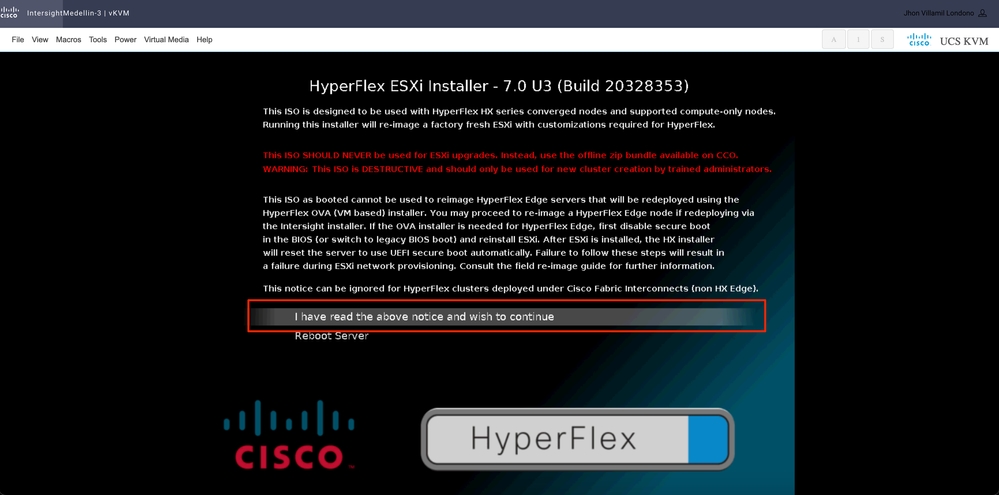
Wählen Sie Ich habe die obige Mitteilung gelesen und möchte fortfahren und drücken Sie Enter
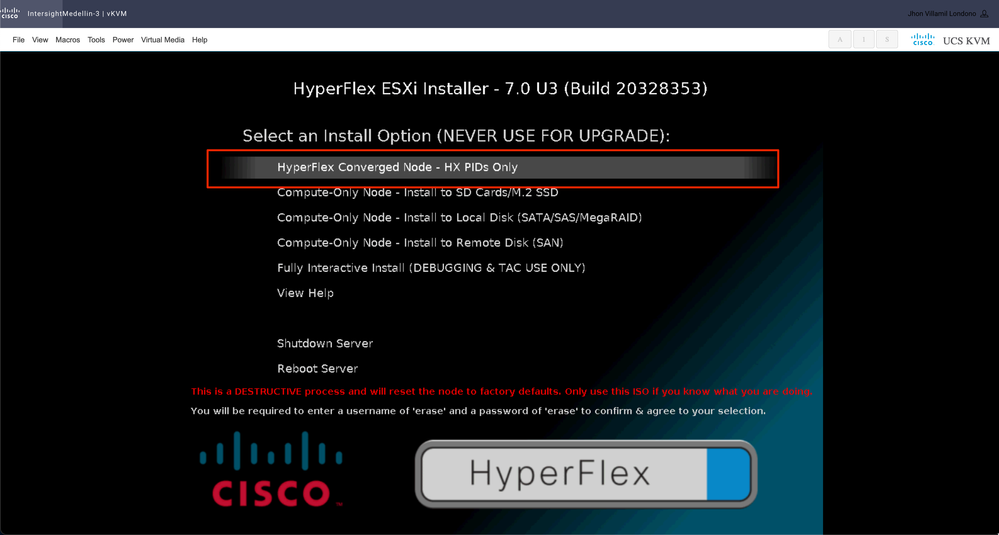
Regelmäßig sehen Sie verschiedene Optionen für Rechenknoten, je nachdem, welches spezielle Boot-Gerät verwendet wird, und eine weitere Option für Konvergenzknoten, die Sie hier auswählen müssen
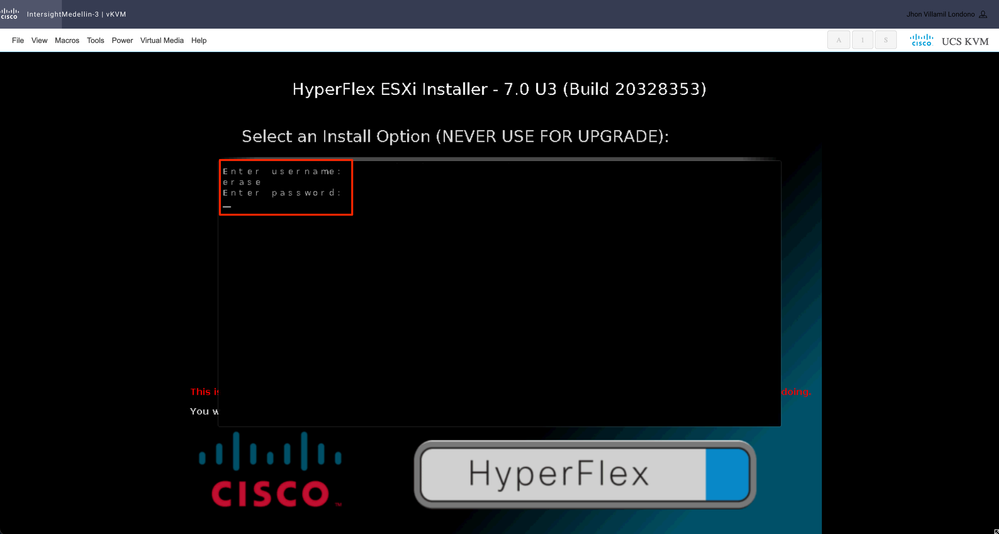
Danach werden Sie aufgefordert, Ihren Benutzernamen und Ihr Kennwort einzugeben. Geben Sie username erase ein > drücken Sie die Eingabetaste > Geben Sie password erase ein> drücken Sie die Eingabetaste. Eingabe
Hinweis: Wenn ein falsches Kennwort/ein falscher Benutzername eingegeben wird, können Sie einen Schritt zurückgehen und es dann erneut versuchen.
Die Installation beginnt an dieser Stelle, und Sie können sie über vKVM überwachen.
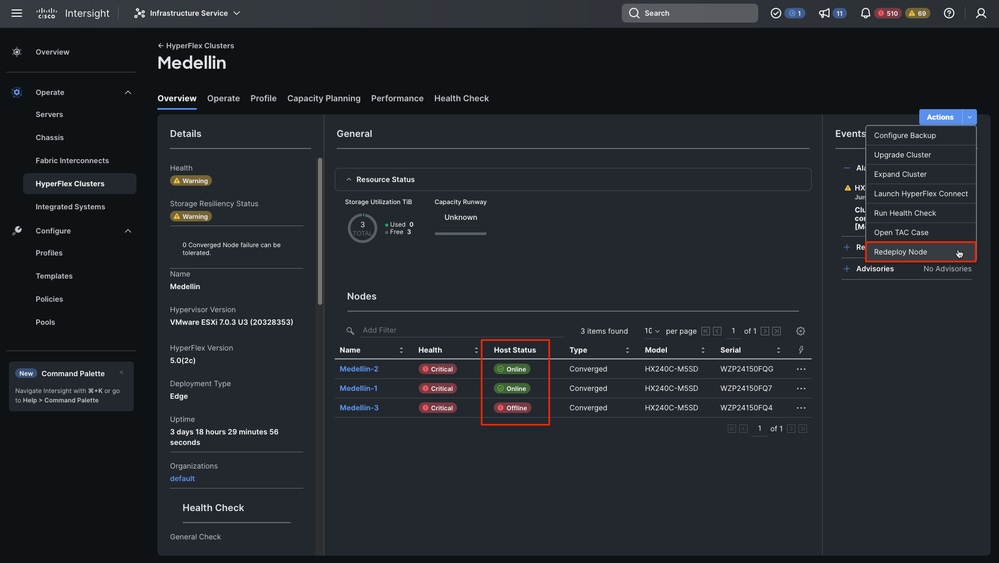
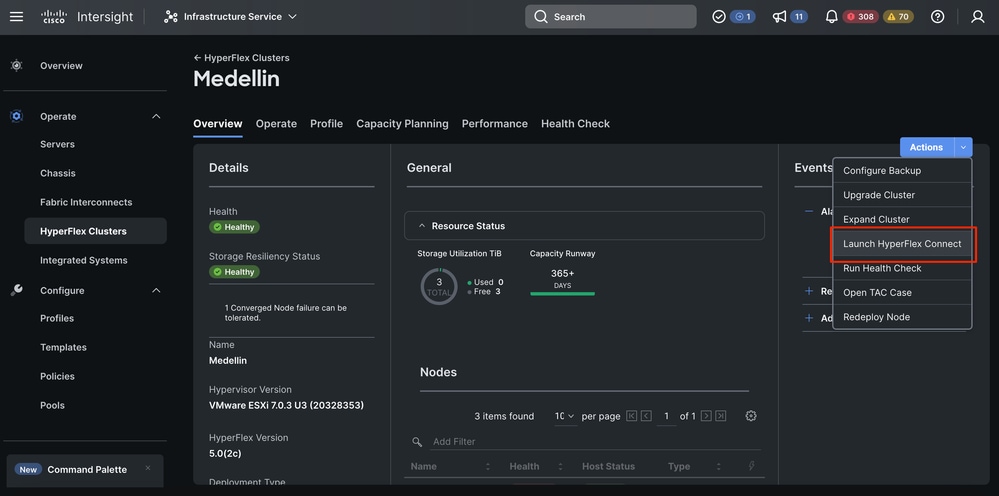
Schritt 2: Navigieren Sie zu Infrastructure Service > Hypeflex Clusters > Wählen Sie Ihren HyperFlex Cluster aus > Wählen Sie Aktionen > Wählen Sie den Befehl "Redeploy Node" aus.

Tipp: Wenn nur SCVM beschädigt ist und neu installiert werden muss, müssen Sie den Server vor der Auswahl von "Redeploy" ausschalten, wenn Sie nicht die Fehlermeldung "Redeploy Node cannot be triggered, there are no offline hosts in this cluster" (Knoten kann nicht ausgelöst werden, da es keine Offline-Hosts in diesem Cluster gibt) erhalten.
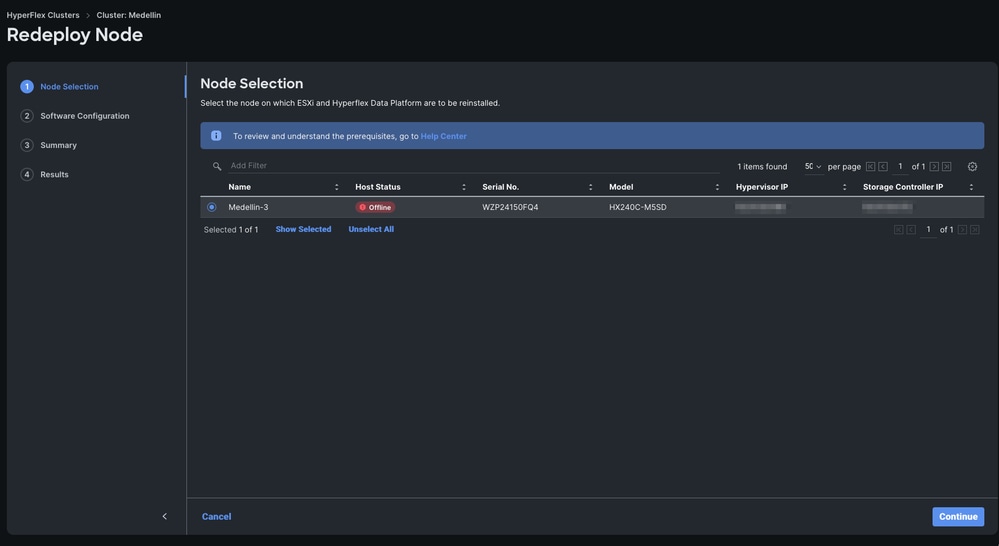
Schritt 3: Wählen Sie den Knoten offline aus > Wählen Sie Weiter aus
Schritt 4: Überprüfen Sie, ob die Richtlinien für Sicherheit, vCenter und Proxy-Einstellungen demselben Cluster entsprechen, und wählen Sie Weiter aus.
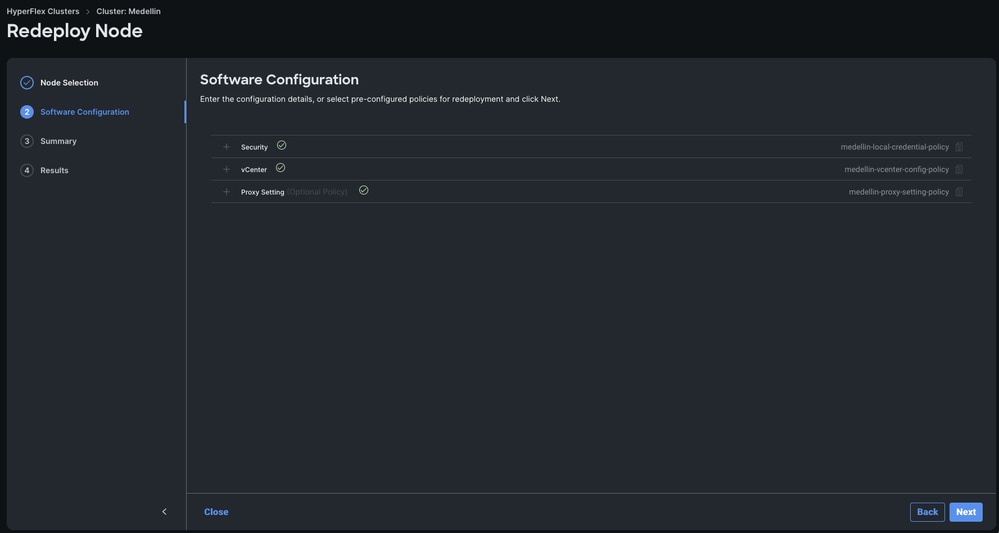
Wenn jedoch nur SCVM neu bereitgestellt wird und ESXi intakt ist, müssen Sie in der Sicherheitsrichtlinie die Option "Der Hypervisor auf diesem Knoten verwendet das werksseitig voreingestellte Kennwort" deaktivieren und sicherstellen, dass das aktuelle ESXi-Kennwort dort aktualisiert wird, bevor Sie Weiter auswählen.
Schritt 5: Validieren und erneutes Bereitstellen auswählen
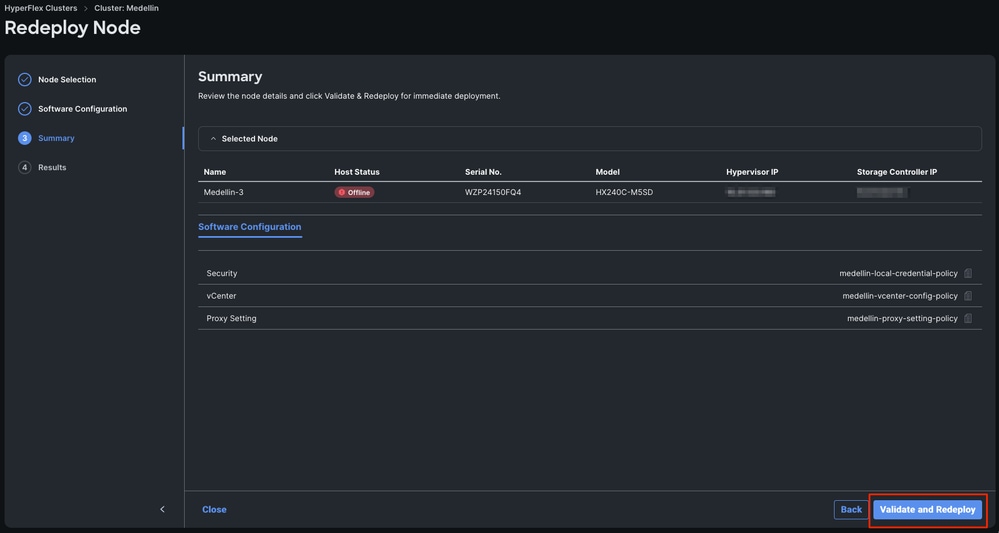
Schritt 6: Warten, bis der Workflow abgeschlossen ist
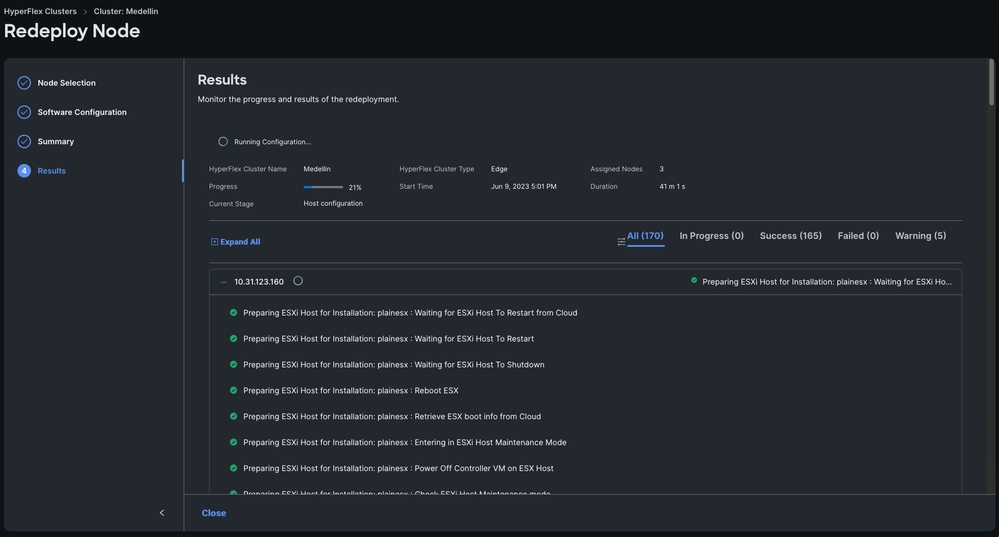
Anmerkung: Sie können den Fortschritt überwachen, aber es dauert in der Regel einige Stunden
Endlich wieder bereitstellen abgeschlossen und Medellin Cluster ist wieder gesund
Überprüfung des Cluster-Zustands
Validierung durch Intersight
Navigieren Sie zu Hyperflex-Cluster > Cluster auswählen > Übersicht auswählen (Registerkarte)
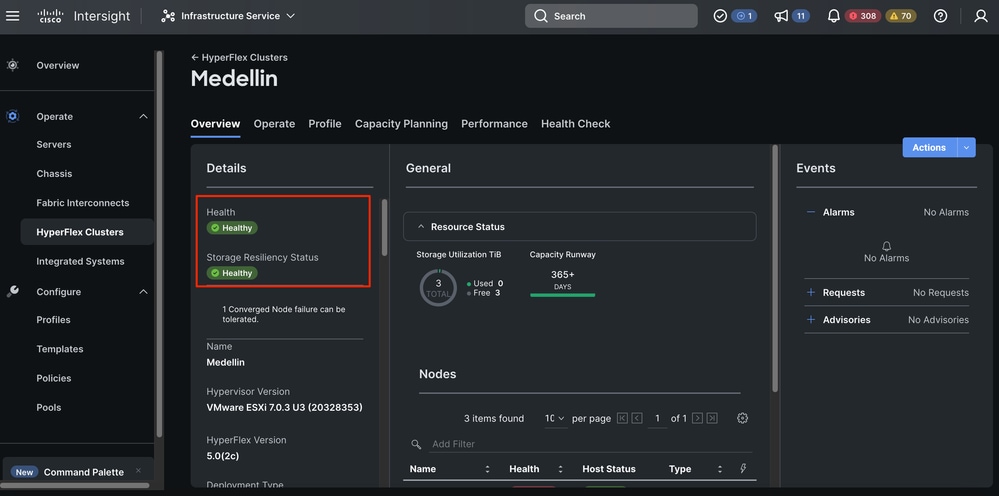
Validierung von Hyperflex Connect
Starten Sie HXDP von Intersight, um den Status zu überprüfen.
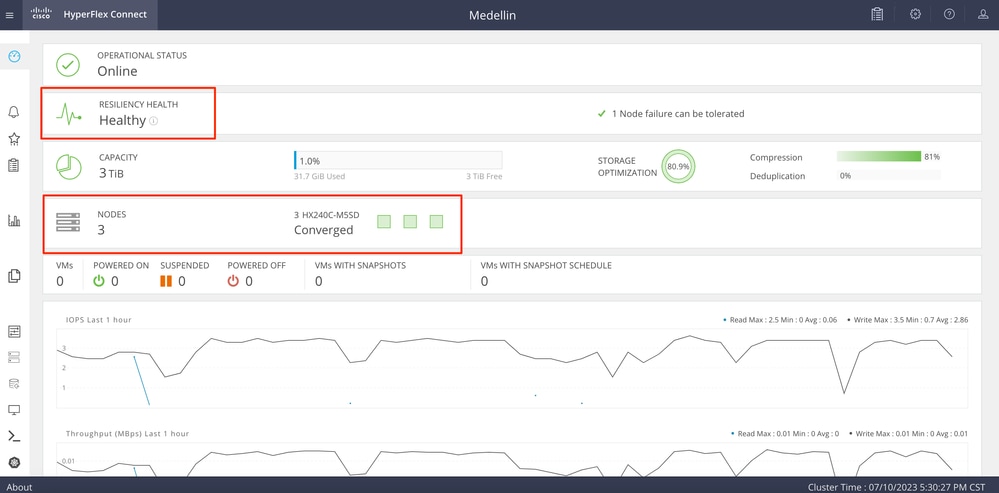
Validierung von CLI
Von CLI aus können Sie Befehle wie hxcli cluster status , hxcli cluster info, hxcli cluster health, hxcli node list verwenden
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : HEALTHY
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 1
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 31.7 GiB
Free Capacity : 3.0 TiB
Compression Savings : 80.90%
Deduplication Savings : 0.00%
Total Savings : 80.90%
# of Nodes Configured : 3
# of Nodes Online : 3
Data IP Address : 169.254.218.1
Resiliency Health : HEALTHY
Policy Compliance : COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 1
# of persistent device failures tolerable : 2
# of cache device failures tolerable : 2
Zone Type : Unknown
All Flash : No
Zugehörige Informationen
Workflow zur Neubereitstellung von HyperFlex-Knoten
 Feedback
Feedback