Einleitung
Dieses Dokument beschreibt Cisco Express Forwarding (CEF) switching und deren Implementierung auf dem Cisco Internet Router der Serie 12000.
Voraussetzungen
Anforderungen
Es gibt keine spezifischen Anforderungen für dieses Dokument.
Verwendete Komponenten
Dieses Dokument ist nicht auf bestimmte Software- und Hardware-Versionen beschränkt.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Konventionen
Weitere Informationen zu Dokumentkonventionen finden Sie unter Cisco Technical Tips Conventions (Technische Tipps von Cisco zu Konventionen).
Überblick
Cisco Express Forwarding (CEF) Switching ist eine proprietäre Form von skalierbarem Switching, das zur Bewältigung von Problemen im Zusammenhang mit dem Caching von Nachfrage konzipiert wurde. Bei der CEF-Vermittlung werden die üblicherweise in einem Routen-Cache gespeicherten Informationen auf mehrere Datenstrukturen aufgeteilt. Der CEF-Code kann diese Datenstrukturen sowohl im Gigabit Route Processor (GRP) als auch in sekundären Prozessoren wie den Linecards der 12000-Router aufrechterhalten. Zu den Datenstrukturen, die eine optimierte Suche für eine effiziente Paketweiterleitung ermöglichen, gehören:
-
Die Forwarding Information Base (FIB)-Tabelle - CEF verwendet eine FIB, um auf dem IP-Zielpräfix basierende Switching-Entscheidungen zu treffen. Die FIB ähnelt vom Konzept her einer Routing-Tabelle oder Informationsbasis. Er pflegt ein Spiegelbild der in der IP-Routing-Tabelle enthaltenen Weiterleitungsinformationen. Bei Routing- oder Topologieänderungen im Netzwerk wird die IP-Routing-Tabelle aktualisiert, und diese Änderungen werden in der FIB übernommen. Die FIB verwaltet Informationen zur Next-Hop-Adresse auf Basis der Informationen in der IP-Routing-Tabelle. Da eine Eins-zu-Eins-Korrelation zwischen FIB-Einträgen und Einträgen in der Routing-Tabelle besteht, enthält die FIB alle bekannten Routen und macht die Wartung des Routen-Caches überflüssig, die mit Switching-Pfaden wie schnellem Switching und optimalem Switching verbunden ist.
-
Adjacency-Tabelle: Knoten im Netzwerk sind angeblich benachbart, wenn sie sich über einen einzelnen Hop auf einer Link-Ebene erreichen können. Zusätzlich zur FIB verwendet CEF Adjacency-Tabellen, um Layer-2-Adressierungsinformationen anzuhängen. Die Adjacency-Tabelle verwaltet Layer-2-Next-Hop-Adressen für alle FIB-Einträge.
CEF kann in einem von zwei Modi aktiviert werden:
-
Central CEF-Modus - Wenn der CEF-Modus aktiviert ist, befinden sich die CEF-FIB- und Adjacency-Tabellen auf dem Routingprozessor, und der Routingprozessor führt die Express-Weiterleitung durch. Sie können den CEF-Modus verwenden, wenn Linecards nicht für das CEF-Switching verfügbar sind oder wenn Sie Funktionen verwenden müssen, die nicht mit verteiltem CEF-Switching kompatibel sind.
-
Distributed CEF (dCEF) mode (Verteilter CEF-Modus (dCEF)): Wenn dCEF aktiviert ist, verwalten die Linecards identische Kopien der FIB- und Adjacency-Tabellen. Die Linecards können die Expressweiterleitung selbst durchführen, wodurch der Hauptprozessor - der Gigabit Route Processor (GRP) - vom Eingriff in den Switching-Vorgang entlastet wird. Dies ist die einzige auf dem Cisco Router der Serie 12000 verfügbare Switching-Methode.
dCEF verwendet einen IPC-Mechanismus (Inter-Process Communication), um die Synchronisierung von FIBs und Adjacency-Tabellen auf dem Routingprozessor und den Linecards sicherzustellen.
Weitere Informationen zu CEF-Switching finden Sie im Cisco Express Forwarding (CEF) Whitepaper .
CEF-Betrieb
Aktualisieren der GRPs-Routing-Tabellen
Abbildung 1 zeigt den Prozess, mit dem ein Routing-Aktualisierungspaket an den Gigabit Route Processor (GRP) gesendet wird und die sich daraus ergebenden Weiterleitungs-Aktualisierungsnachrichten an FIB-Tabellen auf den Linecards gesendet werden.
Der Übersichtlichkeit halber entspricht die Nummerierung der nächsten Absätze der Nummerierung in Abbildung 1.
Der nächste Prozess findet bei der Initialisierung der Routing-Tabelle oder bei jeder Änderung der Netzwerktopologie (beim Hinzufügen, Entfernen oder Ändern von Routen) statt. Das in Abbildung 1 dargestellte Verfahren umfasst fünf Hauptschritte:
-
Ein IP-Datagramm wird in die Eingangspuffer der empfangenden Linecard (Eingangs-Linecard) eingefügt, und die L2/L3-Weiterleitungs-Engine greift auf die Layer-2- und Layer-3-Informationen im Paket zu und sendet sie an den Weiterleitungsprozessor. Der Weiterleitungsprozessor bestimmt, dass das Paket Weiterleitungsinformationen enthält. Der Weiterleitungsprozessor sendet den Zeiger an die virtuelle GRP-Ausgabewarteschlange (VOQ) und gibt an, dass das Paket im Pufferspeicher an die GRP gesendet werden muss.
-
Die Linecard sendet eine Anfrage an die Uhr- und Scheduler-Karte (CSC). Die Scheduler-Karte gewährt eine Freigabe, und das Paket wird über die Switching-Fabric an die GRP gesendet.
-
Die GRP verarbeitet die Routing-Informationen. Der R5000 (Prozessor) auf dem GRP aktualisiert die Netzwerk-Routing-Tabelle. Abhängig von den Routing-Informationen im Paket kann der Layer-3-Prozessor Link-State-Informationen an benachbarte Router übertragen (wenn das interne Routing-Protokoll OSPF (Open Shortest Path First) ist). Der Prozessor generiert die IP-Pakete, die die Verbindungsstatusinformationen und das interne Update für die FIB-Tabellen enthalten. Darüber hinaus berechnet die GRP alle rekursiven Routen, die auftreten, wenn sowohl ein internes als auch ein externes Gateway-Protokoll (z. B. Border Gateway Protocol [BGP]) unterstützt wird.
Die berechneten rekursiven Routeninformationen werden an die FIBs jeder Linecard gesendet. Dadurch wird der Weiterleitungsprozess erheblich beschleunigt, da sich der Layer-3-Prozessor auf der Linecard auf die Weiterleitung des Pakets konzentrieren kann und die rekursive Route nicht berechnet wird.
-
Die GRP sendet interne Updates an die FIB-Tabellen aller Linecards, einschließlich der auf der GRP gespeicherten Updates. Die FIB-Updates der Line Cards werden überwacht und nach Bedarf gedrosselt. Das GRP verfügt über eine Kopie jeder Line Card-FIB-Tabelle. Wenn also eine neue Line Card in das Chassis eingesetzt wird, lädt das GRP die neuesten Weiterleitungsinformationen auf die neue Karte herunter, sobald diese aktiviert wurde.
-
Die GRP wird von den Linecards benachrichtigt, wenn ein neuer Nachbar-Router mit dem 12000-Router verbunden wird. Der Prozessor auf der Linecard sendet ein Paket an die GRP, das die neuen Layer-2-Informationen enthält (in der Regel PPP-Header-Informationen (Point-to-Point Protocol)). Die GRP verwendet diese Layer-2-Informationen, um die Adjacency-Tabelle auf der GRP und den Linecards zu aktualisieren. Jede Linecard fügt diese Layer-2-Informationen zu jedem Paket hinzu, während das Paket vom 12000-Router gesendet wird. Eine Kopie der Adjacency-Tabelle wird zu Initialisierungszwecken auf dem GRP beibehalten.
Abbildung 1: Pfadbestimmung und Layer-3-Switching
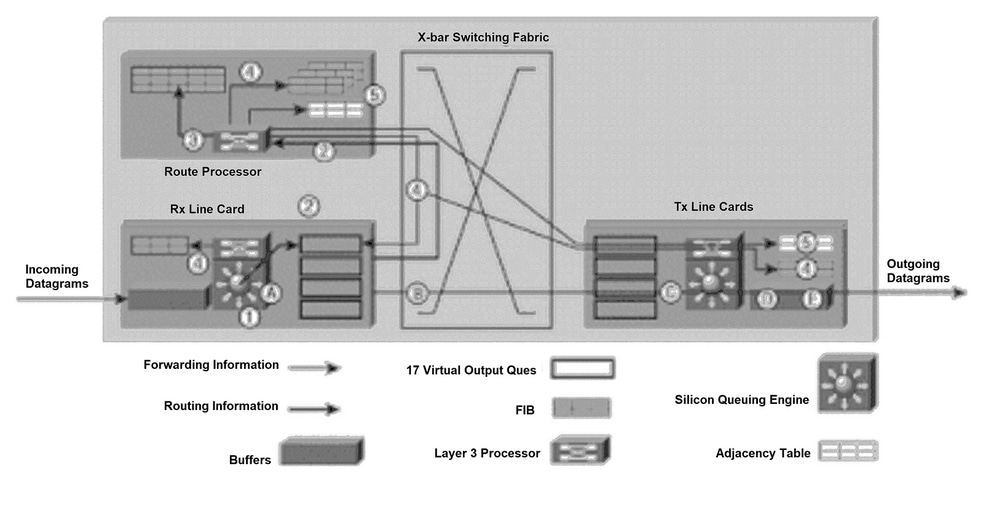 Pfadbestimmung und Layer-3-Switching-Diagramm
Pfadbestimmung und Layer-3-Switching-Diagramm
Paketweiterleitung für alle Linecards außer OC48 und QOC12
Sobald die Linecards über ausreichende Weiterleitungsinformationen verfügen, um den Pfad durch die Switching-Fabric zu bestimmen (z. B. das Ziel des nächsten Hop), ist der Router 12000 bereit, Pakete weiterzuleiten. Die nächsten Schritte beschreiben die einfache und schnelle Weiterleitungstechnik, die vom 12000-Router verwendet wird (siehe Abbildung 1). Der Übersichtlichkeit halber entspricht die Beschriftung der Absätze der Beschriftung in Abbildung 1.
-
A. Ein IP-Datagramm wird in die Eingangspuffer der empfangenden Linecard (Rx Linecard) eingefügt, und die L2/L3-Weiterleitungs-Engine greift auf die Layer 2- und Layer 3-Informationen im Paket zu und sendet diese an den Weiterleitungsprozessor. Der Weiterleitungsprozessor stellt fest, dass das Paket Daten enthält und keine Routing-Aktualisierung darstellt. Basierend auf den Layer-2- und Layer-3-Informationen in der FIB-Tabelle sendet der Weiterleitungsprozessor den Zeiger an die entsprechende Line Card VOQ und gibt an, dass das Paket im Pufferspeicher an diese Line Card gesendet werden soll.
-
B.Der Linecard Scheduler sendet eine Anfrage an den Scheduler. Der Scheduler stellt eine Freigabe aus, und das Paket wird vom Pufferspeicher über die Switching Fabric an die Linecard (Tx Linecard) gesendet.
-
C.Die Tx Line Card puffert die eingehenden Pakete.
-
D. Der Layer-3-Prozessor und die zugehörigen anwendungsspezifischen integrierten Schaltungen (ASICs) auf der Tx-Linecard fügen jedem übertragenen Paket die Layer-2-Informationen (eine PPP-Adresse) hinzu. Das Paket wird für jeden Port der Linecard dupliziert (falls erforderlich).
-
E.The Tx Line Card Transmitter senden das Paket über die Glasfaserschnittstelle.
Der Vorteil dieses einfachen Weiterleitungsprozesses besteht darin, dass die meisten Datenübertragungsaufgaben in ASICs ausgeführt werden können und dass die 12000 mit Gigabit-Raten betrieben werden kann. Außerdem werden Datenpakete nie an die GRP gesendet.
Paketweiterleitung für OC48- und QOC12-Linecards
Wenn die Linecards über genügend Weiterleitungsinformationen verfügen, um den Pfad durch die Switching-Fabric zu bestimmen (z. B. das Ziel des nächsten Hop), ist der Router 12000 bereit, Pakete weiterzuleiten. Die folgenden Schritte bilden die einfache und extrem schnelle Weiterleitungstechnik, die von der 12000 verwendet wird (siehe Abbildung 2). Der Übersichtlichkeit halber entspricht die Beschriftung der Absätze der Beschriftung in Abbildung 2.
-
A. Ein IP-Datagramm (kein Routing-Update, Internet Control Message Protocol (ICMP) und IP-Pakete mit Optionen) wird in die Linecard empfangen und durchläuft die Layer-2-Verarbeitung. Basierend auf den Layer-2- und Layer-3-Informationen in der lokalen FIB-Tabelle bestimmt der Fast Packet Processor das Ziel des Pakets und ändert den Paketkopf. Je nach Ziel wird das Paket dann in der entsprechenden Line Card VOQ platziert.
-
B. In seltenen Fällen, in denen der Fast Packet Processor das Paket nicht ordnungsgemäß weiterleiten kann, wird das Paket vom Weiterleitungsprozessor verarbeitet. Der Weiterleitungsprozessor sendet anhand der Layer-2- und Layer-3-Informationen seiner lokalen FIB-Tabelle den Zeiger an die entsprechende Line Card VOQ, die angibt, dass das Paket im Pufferspeicher an diese Line Card gesendet werden soll.
-
C. Sobald sich das Paket im entsprechenden VOQ befindet, sendet der Linecard-Scheduler eine Anfrage an den Scheduler. Der Scheduler stellt eine Freigabe aus, und das Paket wird vom Pufferspeicher über die Switching Fabric an die Linecard (Tx Linecard) gesendet.
-
D. Die Tx-Linecard puffert die eingehenden Pakete.
-
E. Der Layer-3-Prozessor und die zugehörigen ASICs auf der Tx-Linecard hängen die Layer-2-Informationen (eine PPP-Adresse) an jedes übertragene Paket an. Das Paket wird für jeden Port der Linecard dupliziert (falls erforderlich).
-
F. Die Tx Line Card-Sender senden das Paket über die Glasfaserschnittstelle.
Der Vorteil des neuen Weiterleitungsprozesses besteht darin, dass die Karte speziell für höhere Geschwindigkeiten optimiert wird, wie z. B. beim OC48/STM16.
Abbildung 2: Packet-Switching für schnellere Line Cards
 Packet-Switching für schnellere Line Cards
Packet-Switching für schnellere Line Cards
Zugehörige Informationen
 Feedback
Feedback