Fehlerbehebung bei hoher CPU auf Routern der Serie ASR1000
Download-Optionen
-
ePub (423.5 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einführung
In diesem Dokument wird beschrieben, wie bei einem Router der Serie ASR 1000 Probleme mit der CPU behoben werden.
Voraussetzung
Anforderungen
Cisco empfiehlt, dass Sie die ASR1000-Architektur zur Interpretation und Verwendung dieses Dokuments verstehen.
Beschreibung
Eine hohe CPU auf einem Cisco Router kann definiert werden als der Zustand, in dem die CPU-Auslastung auf dem Router über der normalen Auslastung liegt. In einigen Szenarien ist eine erhöhte CPU-Auslastung zu erwarten, in anderen Szenarien kann dies auf ein Problem hinweisen. Eine vorübergehende hohe CPU-Auslastung auf dem Router aufgrund von Netzwerkänderungen oder Konfigurationsänderungen kann ignoriert werden und ist erwartungsgemäß.
Ein Router, der über einen längeren Zeitraum eine hohe CPU-Auslastung ohne Änderungen im Netzwerk oder in der Konfiguration aufweist, ist jedoch ungewöhnlich und muss analysiert werden. Wenn die CPU überlastet ist, kann sie daher nicht aktiv für alle anderen Prozesse eingesetzt werden. Dies führt zu einer langsamen Befehlszeile, Latenz auf der Kontrollebene, Paketverlusten und einem Ausfall der Services.
Die Ursachen für eine hohe CPU sind:
- Die CPU der Kontrollebene erhält zu viel Datenverkehr.
- Ein Prozess, der sich unerwartet verhält und zu CPU-Überlastung führt
- Datenebenenprozessor wird überlastet/überbelegt
- Zu viele Prozessorunterbrechungen
Eine hohe CPU ist nicht immer ein Problem mit Routern der Serie ASR1000, da die CPU-Auslastung des Routers direkt proportional zur Auslastung des Routers ist. Wenn beispielsweise ein Netzwerk geändert wird, verursacht dies einen hohen Datenverkehr auf Kontrollebene, da das Netzwerk neu konvergiert. Daher müssen wir die Ursache der CPU-Überlastung ermitteln, um festzustellen, ob es sich um ein erwartetes Verhalten oder ein Problem handelt.
Im folgenden Diagramm wird ein schrittweiser Prozess zur Fehlerbehebung bei Problemen mit hoher CPU beschrieben:
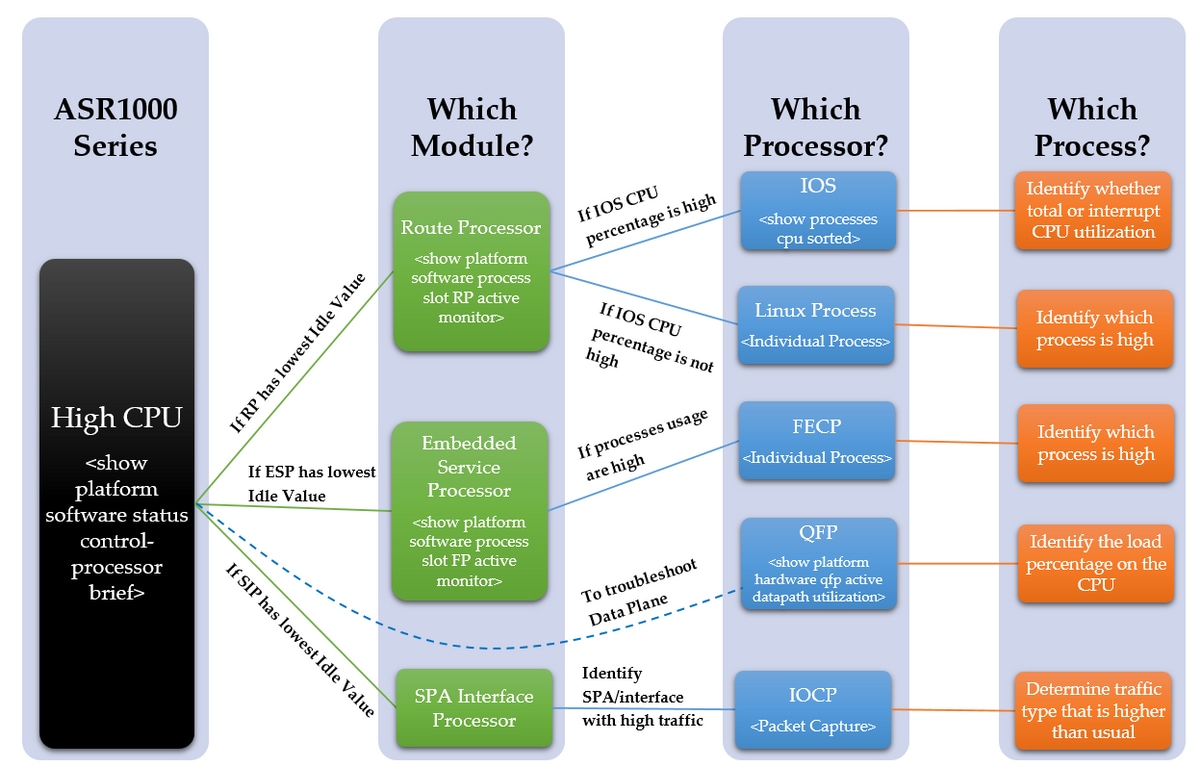
Schritte zur Fehlerbehebung
Schritt 1: Identifizieren des Moduls mit hoher CPU
ASR1000 verfügt über mehrere CPUs der verschiedenen Module. Deshalb müssen wir sehen, welches Modul mehr als die normale Nutzung anzeigt. Dies wird durch den Inaktivitätswert sichtbar, da die CPU-Auslastung des Moduls umso höher ist, je niedriger der Inaktivitätswert ist. Diese unterschiedlichen CPUs spiegeln alle die Steuerungsebene der Module wider.
Stellen Sie fest, bei welchem Modul im Gerät eine hohe CPU festgestellt wird. Ist es der RP, ESP oder SIP mit dem folgenden Befehl?
show platform software status control processor brief
In der unten stehenden Ausgabe können Sie die hervorgehobene Spalte anzeigen.
Wenn der RP einen niedrigen Leerwert hat, fahren Sie mit Schritt 2 Punkt 1 fort.
Wenn der ESP-Wert niedrig ist, fahren Sie mit Schritt 3, Punkt 2 fort.
Wenn das SIP einen niedrigen Leerwert hat, fahren Sie mit Schritt 4, Punkt 3 fort.
Router#show Platform software status control-processor brief
Lastdurchschnitt
Steckplatzstatus 1-min 5-min 15 Minuten
RP0 Healthy 0,00 0,02 0,00
ESP0 Healthy 0,01 0,02 0,00
SIP0 Healthy 0,00 0,01 0,00
Arbeitsspeicher (kB)
Gesamtstatus des belegten Steckplatzes (PCT) frei (PPT) (PPT)
RP0 Gesund 2009376 1879196 (94 %) 130180 (6 %) 1432748 (71 %)
ESP0 Gesundheit 2009400 692100 (34 %) 1317300 (66 %) 472536 (24 %)
SIP0 Gesund 471804 284424 (60 %) 187380 (40 %) 193148 (41 %)
CPU-Auslastung
Steckplatz-CPU-Benutzersystem Nice Idle IRQ SIRQ IOwait
RP0 0 2,59 2,49 0,00 94,80 0,00 0,09 0,00
ESP0 0 2,30 17,90 0,00 79,80 0,00 0,00 0,00
SIP0 0 1,29 4,19 0,00 94,41 0,09 0,00 0,00
Wenn alle Leerwerte relativ hoch sind, handelt es sich möglicherweise nicht um ein Problem mit der Kontrollebene. Zur Fehlerbehebung auf Datenebene muss der QFP des ESP beachtet werden. Die Symptome einer "hohen CPU" können weiterhin aufgrund eines überlasteten QFP beobachtet werden, was nicht zu einer hohen CPU auf den Kontrollebenen führt. Fahren Sie mit SCHRITT 6 fort.
Schritt 2: Modul analysieren
- Routingprozessor
Bestätigen Sie innerhalb des RP mit dem folgenden Befehl, welcher Prozessor eine hohe CPU-Auslastung aufweist. Handelt es sich um den Linux-Prozess oder das IOS?
show plattform software prozess steckplatz RP Active Monitor
Wenn der Prozentsatz der IOS-CPU hoch ist (linux_iosd-image), ist dies der RP IOS. Fahren Sie mit SCHRITT 3 fort.
Wenn der CPU-Prozentsatz anderer Prozesse hoch ist, ist dies wahrscheinlich der Linux-Prozess. Fahren Sie mit SCHRITT 4 fort.
- Embedded Services Processor
Überprüfen Sie im ESP, ob der Kontrollebenen-Prozessor eine hohe CPU-Auslastung aufweist. Ist es die FECP?
show plattform software prozess steckplatz FP active monitor
Wenn die Prozesse hoch sind, dann ist dies das FECP, dann fahren Sie bei SCHRITT 5 fort.
Wenn es sich nicht um das FECP handelt, handelt es sich nicht um ein Problem im Zusammenhang mit den Prozessen auf Kontrollebene innerhalb des ESP. Wenn weiterhin Symptome wie Netzwerklatenz oder Warteschlangenverluste beobachtet werden, muss die Datenebene möglicherweise auf eine Überlastung hin überprüft werden. Fahren Sie mit SCHRITT 6 fort.
- SPA-Schnittstellenprozessor
Wenn das SIP eine hohe CPU-Auslastung aufweist, wird festgestellt, dass das IOCP eine hohe CPU aufweist. Bestimmen Sie, welche Prozesse oder Prozesse innerhalb des IOCP eine hohe CPU-Auslastung aufweisen.
Führen Sie eine Paketerfassung durch, und ermitteln Sie, welcher Datenverkehr höher ist als gewöhnlich, und welche Prozesse diesem Datenverkehrstyp zugeordnet sind. Fahren Sie mit SCHRITT 7 fort.
Schritt 3: IOS-Prozesse
In der unten stehenden Ausgabe ist der erste Prozentsatz die gesamte CPU-Auslastung und der zweite Prozentsatz die CPU-Auslastung durch Unterbrechung, d. h. die CPU-Auslastung, die für die Verarbeitung ausgehöhlter Pakete verwendet wird.
Wenn der Interrupt-Prozentsatz hoch ist, bedeutet dies, dass ein großer Teil des Datenverkehrs an den RP geleitet wird (dies kann mit dem Befehl show platform software infrastructure punt bestätigt werden)
Wenn der Interrupt-Prozentsatz niedrig ist, die CPU-Gesamtgröße jedoch hoch ist, dann gibt es einen oder mehrere Prozesse, die beobachtet werden, um die CPU über einen längeren Zeitraum zu nutzen.
Bestätigen Sie innerhalb des IOS mit dem folgenden Befehl, welche Prozesse oder Prozesse eine hohe CPU-Auslastung aufweisen.
show prozesse cpu sortiert
Bestimmen Sie, welcher Prozentsatz hoch ist (Gesamt-CPU oder Interrupt-CPU), und geben Sie ggf. die einzelnen Prozesse/Prozesse an. Fahren Sie mit SCHRITT 7 fort.
Router#show-Prozesse, CPU sortiert
CPU-Auslastung für fünf Sekunden: 0 %/0 %; eine Minute: 1 %; fünf Minuten: 1 %
PID Runtime(ms) aufgerufen uSecs 5Sec 1Min 5 Min TTY Prozess
PID Runtime(ms) aufgerufen uSecs 5Sec 1Min 5 Min TTY Prozess
188 8143 434758 18 0,15 % 0,18 % 0,19 % 0 Ethernet Msec Ti
515 380 7050 53 0,07 % 0,00 % 0,00 % 0 SBC Hauptprozess
3 2154 215 1018 0,07 % 0,00 % 0,19 % 0 Exec
380 1783 55002 32 0,07 % 0,06 % 0,06 % 0 MMA DB TIMER
63 3132 11143 281 0,07% 0,07% 0,07% 0 IOSD ipc Aufgabe
5 1 2 500 0,00 % 0,00 % 0,00 % 0 IPC ISSU Dispatc
6 19 12 1583 0,00 % 0,00 % 0,00 % 0 RF-Slave Main th
8 0 1 0 0,00 % 0,00 % 0,00 % 0 RO Benachrichtigungs-Timer
7 0 1 0 0,00 % 0,00 % 0,00 % 0 EDDRI_MAIN
10 6 75 80 0,00 % 0,00 % 0,00 % 0 Pool Manager
9 5671 538 10540 0,00 % 0,14 % 0,12 % 0 Scheckheaps
Schritt 4 - Linux-Prozesse
Wenn beim IOS festgestellt wird, dass die CPU überlastet ist, müssen wir die CPU-Auslastung für den einzelnen Linux-Prozess beobachten. Diese Prozesse sind die anderen Prozesse, die im RP Active Monitor für den Anzeigeplattform-Software-Prozesssteckplatz aufgeführt sind. Identifizieren Sie, bei welchen Prozessen oder Prozessen eine hohe CPU zu beobachten ist, und fahren Sie dann mit SCHRITT 7 fort.
Schritt 5: FECP-Prozesse
Wenn ein Prozess oder Prozesse hoch ist, sind wahrscheinlich die Prozesse innerhalb des FECP für die hohe CPU-Auslastung verantwortlich. Fahren Sie mit SCHRITT 7 fort.
Schritt 6: QFP-Auslastung
Der Quantum Flow-Prozessor ist der weiterleitende ASIC. Um die Last der Weiterleitungs-Engine zu bestimmen, kann der QFP überwacht werden. Der folgende Befehl listet die Ein- und Ausgabepakete (Priorität und Nicht-Priorität) in Paketen pro Sekunde und Bit pro Sekunde auf. Die letzte Zeile zeigt die gesamte CPU-Last aufgrund der Paketweiterleitung in Prozent an.
show plattform hardware qfp active datapath use
Bestimmen Sie, ob die Ein- und Ausgabe hoch ist, und zeigen Sie die Prozesslast an, und fahren Sie dann mit SCHRITT 7 fort.
Router#show plattformhardware qfp - aktive Datapath-Nutzung
CPP 0: Subdev 0 5 s 1 min 5 min 60 min
Eingabe: Priorität (pps) 0 0 0 0
208 176 176 176 176
Nicht Priorität (pps) 0 2 2 2
64 784 784 784
Insgesamt (pps) 0 2 2 2
272 960 960 960
Ausgabe: Priorität (pps) 0 0 0 0
192 160 160 160 160
Nicht Priorität (pps) 0 1 1 1
0 6488 6496 6488
Insgesamt (pps) 0 1 1 1
(Bit/s) 192 6648 6656 6648
Verarbeitung: Last (pct) 0 0 0 0
Schritt 7 - Bestimmen der Ursache und Beheben der Ursache
Bei dem Prozess oder den Prozessen, bei denen beobachtet wird, dass die CPU überlastet ist, wird ein klareres Bild davon gemacht, warum es zu einer hohen CPU gekommen ist. Recherchieren Sie anschließend die Funktionen, die durch den identifizierten Prozess ausgeführt werden. Dies hilft bei der Festlegung eines Aktionsplans zur Problemlösung. Beispiel: Wenn der Prozess für ein bestimmtes Protokoll verantwortlich ist, sollten Sie sich die Konfiguration für dieses Protokoll ansehen.
Wenn weiterhin CPU-bezogene Probleme auftreten, empfiehlt es sich, sich an das TAC zu wenden, damit Ihnen ein Techniker bei der weiteren Fehlerbehebung behilflich sein kann. Die oben beschriebenen Schritte zur Fehlerbehebung helfen dem Techniker, das Problem effizienter zu identifizieren.
Beispiel zur Fehlerbehebung
In diesem Beispiel führen wir den Prozess zur Fehlerbehebung durch und versuchen am besten, eine mögliche Ursache für die hohe CPU des Routers zu ermitteln. Stellen Sie zunächst fest, welches Modul beobachtet wird, um die hohe CPU zu erleben, die folgende Ausgabe:
Router#show Platform software status control-processor brief
Lastdurchschnitt
Steckplatzstatus 1-min 5-min 15 Minuten
RP0 Healthy 0,66 0,15 0,05
ESP0 Healthy 0,00 0,00 0,00
SIP0 Healthy 0,00 0,00 0,00
Arbeitsspeicher (kB)
Gesamtstatus des belegten Steckplatzes (PCT) frei (PPT) (PPT)
RP0 Gesund 2009376 1879196 (94 %) 130180 (6 %) 1432756 (71 %)
ESP0 Gesundheit 2009400 692472 (34 %) 1316928 (66 %) 472668 (24 %)
SIP0 Gesund 471804 284556 (60 %) 187248 (40 %) 193148 (41 %)
CPU-Auslastung
Steckplatz CPU-Benutzersystem Nizza Inaktive IRQ SIRQ IOwait
RP0 0 57,11 14,42 0,00 0,00 28,25 0,19 0,00
ESP0 0 2,10 17,91 0,00 79,97 0,00 0,00 0,00
SIP0 0 1,20 6,00 0,00 92,80 0,00 0,00 0,00
Da die Leerlaufmenge innerhalb von RP0 sehr niedrig ist, deutet dies auf ein hohes CPU-Problem innerhalb des Routingprozessors hin. Zur weiteren Fehlerbehebung wird daher ermittelt, bei welchem Prozessor im RP eine hohe CPU-Leistung zu verzeichnen ist.
Router#show-Prozesse, CPU sortiert
CPU-Auslastung für fünf Sekunden: 84 %/36 %; eine Minute: 34 % fünf Minuten: 9 %
PID Runtime(ms) aufgerufen uSecs 5Sec 1Min 5 Min TTY Prozess
107 303230 50749 5975 46,69 % 18,12 % 4,45 % 0 IOSXE-RP Punt SE
63 105617 540091 195 0,23 % 0,10 % 0,08 % 0 IOSD IPC-Aufgabe
159 74792 2645991 28 0,15 % 0,06 % 0,06 % 0 VRRS Hauptthread
116 53685 169683 316 0,15 % 0,05 % 0,01 % 0 Jobs pro Sekunde
9 305547 26511 11525 0,15 % 0,28 % 0,16 % 0 Scheckheaps
188 362507 20979154 17 0,15 % 0,15 % 0,19 % 0 Ethernet Msec Ti
3 147 186 790 0,07 % 0,08 % 0,02 % 0 Exec
2 32126 33935 946 0,07 % 0,03 % 0,00 % 0 Auslastungsmessgerät
446 416 33932 12 0,07 % 0,00 % 0,00 % 0 VDC-Prozess
164 59945 5261819 11 0,07 % 0,04 % 0,02 % 0 IP ARP Retry Age
43 1703 16969 100 0,07 % 0,00 % 0,00 % 0 IPC Keep Alive m
Aus dieser Ausgabe lässt sich erkennen, dass der gesamte CPU-Prozentsatz und der Interrupt-Prozentsatz höher sind als erwartet. Der oberste Prozess, der die CPU verwendet, ist der "IOSXE-RP Punt Se". Dieser Prozess verarbeitet den Datenverkehr für die RP-CPU. Daher können wir diesen Datenverkehr, der an den RP geleitet wird, genauer untersuchen.
Router#show Plattform-Software-Infrastruktur-Expert
Interne Statistiken der LSMPI-Schnittstelle:
enabled=0, disabled=0, gedrosselt=0, ungedrosselt=0, Zustand ist bereit
Eingabepuffer = 90100722
Ausgabepuffer = 100439
xdon count = 90100722
Txdon count = 100436
Rx no particletype count = 0
Tx no particletype count = 0
Txbuf = 0
Kein Paketstart = 0
Kein Ende des Pakets = 0
Statistiken zum Ablegen von Warteschlangen:
Schlechte Version 0
Schlechter Typ 0
Kopfzeilenüberschrift 0
Kopfzeilenüberschrift 0
Feature-Header fehlt 0
Häufige Header-Diskrepanz 0
Schlechte Gesamtlänge 0
Schlechte Paketlänge 0
Schlechter Netzwerkversatz 0
Header 0 wird nicht gestrichen
Unbekannter Verbindungstyp 0
Keine Swidm 1
Fehlerhafter ESS-Feature-Header 0
Keine ESS-Funktion 0
Keine SSL VPN-Funktion 0
Sammelanschluss für US-Typ unbekannt 0
Ursache der Anbringung außerhalb des Bereichs 0
Ursachen für das IOSXE-RP-Punt-Paket:
62210226 Layer-2-Kontroll- und Legacy-Pakete
147 ARP-Anforderungs- oder -Antwortpakete
27801234 Für Datenpakete
84426 RP<->QFP-Keepalive-Pakete
6 Glean-Adjacency-Pakete
1647 For-us-Kontrollpakete
FOR_US Control IPv4-Protokollstatus:
1647 OSPF-Pakete
Packet Histogram (500 Byte/bin), durchschnittliche Größe in 92, von 56:
Anzahl der ausgehenden Pak-Size-Einheiten
0+: 90097805 98790
Über 500: 0 7
In dieser Ausgabe sehen wir eine große Anzahl von Paketen in den "For-us-Datenpaketen", die den an den Router gerichteten Datenverkehr anzeigen. Dieser Zähler wurde bestätigt, dass er durch die Beobachtung des Befehls mehrmals über mehrere Minuten erhöht wurde. Dies bestätigt, dass die CPU durch eine große Menge an Datenverkehr überlastet wird, der häufig Datenverkehr auf Kontrollebene darstellt. Der Datenverkehr auf Kontrollebene kann ARP, SSH, SNMP, Routen-Updates (BGP, EIGRP, OSPF) usw. umfassen. Anhand dieser Informationen können wir die potenzielle Ursache der hohen CPU identifizieren und so die Fehlerbehebung für die Ursache unterstützen. Beispielsweise könnte eine Paketerfassung oder ein Monitor für unterschiedlichen Datenverkehr implementiert werden, um den genauen Datenverkehr zu erkennen, der an den RP geleitet wird. Dadurch kann die Ursache identifiziert und gelöst werden, um ein ähnliches Problem in Zukunft zu vermeiden.
Nach Abschluss der Paketerfassung sind folgende Beispiele für potenziell gestohlenen Datenverkehr:
- ARP: Dies könnte auf eine übermäßige Anzahl von ARP-Anfragen zurückzuführen sein, die auftreten würden, wenn mehrere IP-Adressen ARP-Anfragen über die Konfiguration einer IP-Route an eine Broadcast-Schnittstelle senden würden. Dies kann auch auf geleaster Einträge aus der ARP-Tabelle zurückzuführen sein und muss basierend auf den veralteten MAC-Adresseinträgen neu erlernt werden, oder es muss eine Schnittstelle zum Start/Down eingerichtet werden.
- SSH: Dies kann zu einer hohen CPU führen, da ein großer show-Befehl (show tech-support) oder eine Vielzahl von Debug-Befehlen aktiviert sind, wodurch viele CLI-Befehle über die SSH-Sitzung gesendet werden müssen.
- SNMP: Dies kann auf den SNMP-Agenten zurückzuführen sein, der eine Anfrage über einen langen Zeitraum verarbeitet und somit die hohe CPU verursacht. Häufig sind zwei mögliche Ursachen MIBs, die abgefragt werden, oder Routing- und/oder ARP-Tabellen, die vom NMS abgefragt werden.
- Routenaktualisierungen: Häufig sind Routen-Updates auf eine Netzwerkkonvergenz oder auf Verbindungs-Flaps zurückzuführen. Dies könnte auf Routen hinweisen, die innerhalb des Netzwerks ausfallen, oder auf ganze Geräte, die ausfallen und das Netzwerk zwingen, die besten Routen zu konvergieren und neu zu berechnen. Dies hängt davon ab, welches Routing-Protokoll verwendet wird.
Dies verdeutlicht, wie die Ursache der hohen CPU durch Identifizierung der Ursache isoliert werden kann, wenn es auf eine einzelne Prozessebene ankommt. Von hier aus können einzelne Prozesse oder Protokolle isoliert analysiert werden, um festzustellen, ob es sich um ein Konfigurationsproblem, ein Softwareproblem, ein Netzwerkdesign oder eine beabsichtigte Praxis handelt.
Zusätzliche Befehle
Im Folgenden finden Sie eine Liste weiterer nützlicher Befehle, die verwendet werden können. Sie sind sortiert nach dem Prozessor, auf den sie sich beziehen:
Routingprozessor
- <Verlauf des Prozesses anzeigen>
- Zeigt den CPU-Verlauf der letzten 60 Sekunden, Minuten und 72 Stunden an.
- <Prozess-Prozess anzeigen_ID>
- Detaillierte Informationen zu den einzelnen Arbeitsspeicher- und CPU-Zuweisungen des Prozesses
- <show platform software infrastructure punt>
- Stellt Informationen über den gesamten Datenverkehr bereit, der an den RP geleitet wird
- <Plattformsoftware-Status-Control-Prozessor-Übersicht anzeigen>
- Details zu Last und Status der CPU sowie zu Speicher- und Modulstatistiken
- <Plattform-Softwareprozess-Steckplatz r0|r1 Monitor anzeigen>
- Details zu den verschiedenen Prozessen und ihren CPU- und Speicherzuweisungen auf dem ausgewählten Modul
- <Überwachungsplattform software prozess r0|r1>
- Bietet einen Live-Feed, der die Prozesse aktualisiert, während sie die CPU verwenden
- Der Befehl "terminal terminal terminal type" muss zuerst im globalen Konfigurationsmodus eingegeben werden, damit er korrekt funktioniert.
Embedded Services Processor
- <Plattformsoftware-Prozessliste anzeigen fp active summary>
- Beschreibt die Zusammenfassung aller Prozesse, die auf der CPU ausgeführt werden, sowie die durchschnittliche Last.
- <Plattform-Softwareprozess-Steckplatz f0|f1 Monitor anzeigen>
- Details zu den verschiedenen Prozessen und ihren CPU- und Speicherzuweisungen auf dem ausgewählten Modul
- <Überwachungsplattform-Softwareprozess f0|f1>
- Bietet einen Live-Feed, der die Prozesse aktualisiert, wenn sie die CPU nutzen
- Der Befehl "terminal terminal terminal type" muss zuerst im globalen Konfigurationsmodus eingegeben werden, damit er korrekt funktioniert.
Beiträge von Cisco Ingenieuren
- Chris CourtelisCisco Systems
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)