Fehlerbehebung bei Punt-Fabric-Datenpfadausfällen der Serie ASR 9000
Download-Optionen
-
ePub (609.7 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
In diesem Dokument werden Fehlermeldungen über Datenpfade in der einzelnen Fabric beschrieben, die beim Betrieb des Cisco Aggregation Services Routers (ASR) der Serie 9000 aufgetreten sind.
Die Meldung wird in folgendem Format angezeigt:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
Dieses Dokument richtet sich an alle, die die Fehlermeldung und die Maßnahmen verstehen möchten, die bei Auftreten des Problems ergriffen werden müssen.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über umfassende Kenntnisse in den folgenden Bereichen verfügen:
- ASR 9000 Line Cards
- Fabric-Karten
- Routingprozessoren
- Chassis-Architektur
Für dieses Dokument müssen die Leser jedoch nicht mit den Details zur Hardware vertraut sein. Bevor die Fehlermeldung erklärt wird, werden die notwendigen Hintergrundinformationen bereitgestellt. In diesem Dokument wird der Fehler sowohl bei Trident- als auch bei Typhoon-basierten Line Cards beschrieben. Eine Erläuterung dieser Begriffe finden Sie unter Grundlegendes zu Line Card-Typen der ASR Serie 9000.
Verwendete Komponenten
Dieses Dokument ist nicht auf bestimmte Software- und Hardware-Versionen beschränkt.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Verwendung dieses Dokuments
Berücksichtigen Sie die folgenden Vorschläge zur Verwendung dieses Dokuments, um wichtige Details zu erfahren und als Referenz für die Fehlerbehebung zu dienen:
- Wenn keine Dringlichkeit besteht, einen Fehler im Datenpfad der Einfügestruktur zu verursachen, lesen Sie alle Abschnitte dieses Dokuments. In diesem Dokument wird der erforderliche Hintergrund erstellt, um eine fehlerhafte Komponente zu isolieren, wenn ein solcher Fehler auftritt.
- Wenn Sie eine bestimmte Frage im Sinn haben, für die eine schnelle Antwort benötigt wird, können Sie den Abschnitt FAQ verwenden. Wenn die Frage nicht im FAQ-Abschnitt enthalten ist, prüfen Sie, ob das Hauptdokument die Frage beantwortet.
- Verwenden Sie alle Abschnitte unter Fehler analysieren auf, um das Problem auf eine fehlerhafte Komponente zu isolieren, wenn ein Router einen Fehler aufweist, oder um zu überprüfen, ob es sich um ein bekanntes Problem handelt.
Hintergrundinformationen
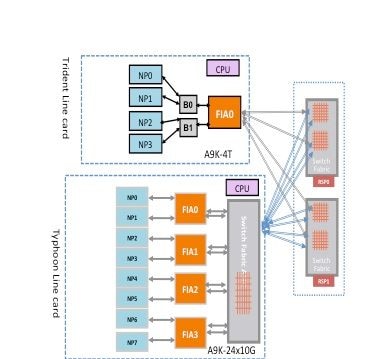
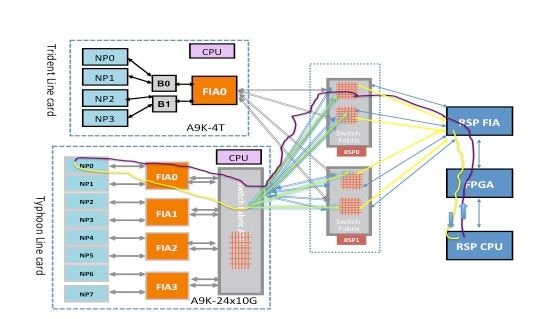
Ein Paket kann je nach Linecard-Typ entweder zwei oder drei Hops durch die Switch-Fabric durchlaufen. Typhoon-Line-Cards fügen ein zusätzliches Switch-Fabric-Element hinzu, während Trident-basierte Line-Cards den gesamten Datenverkehr nur mit der Fabric auf der Routingprozessorkarte weiterleiten. Diese Diagramme zeigen Fabric-Elemente für beide Linecard-Typen sowie die Fabric-Verbindung mit der Routingprozessorkarte:

Punt-Fabric-Diagnosepaketpfad
Die Diagnoseanwendung, die auf der Routingprozessorkarten-CPU ausgeführt wird, sendet regelmäßig Diagnosepakete an jeden Netzwerkprozessor (NP). Das Diagnosepaket befindet sich innerhalb des NP und wird wieder in die CPU der Routingprozessorkarte eingespeist, von der das Paket stammt. Diese regelmäßige Integritätsprüfung jedes NP mit einem eindeutigen Paket pro NP durch die Diagnoseanwendung auf der Routingprozessorkarte gibt eine Warnung für Funktionsfehler auf dem Datenpfad während des Routerbetriebs aus. Es muss unbedingt darauf hingewiesen werden, dass die Diagnoseanwendung sowohl auf dem aktiven Routingprozessor als auch auf dem Standby-Routingprozessor periodisch ein Paket pro NP einfügt und eine Erfolgs- oder Fehleranzahl pro NP aufrechterhält. Wenn ein Schwellenwert für verlorene Diagnosepakete erreicht wird, löst die Anwendung einen Fehler aus.
Konzeptionelle Ansicht des Diagnosepfads
Bevor das Dokument den Diagnosepfad auf Trident- und Typhoon-basierten Line Cards beschreibt, bietet dieser Abschnitt einen allgemeinen Überblick über den Fabric-Diagnosepfad von den aktiven und Standby-Route-Prozessorkarten zum NP auf der Line Card.
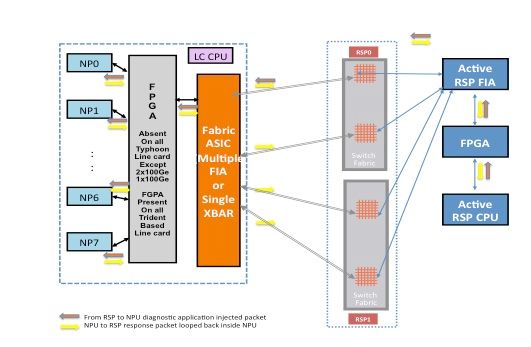
Paketpfad zwischen der aktiven Routingprozessorkarte und der Linecard
Diagnosepakete, die vom aktiven Routingprozessor in die Fabric zum NP eingespeist werden, werden von der Switch-Fabric als Unicast-Pakete behandelt. Bei Unicast-Paketen wählt die Switch-Fabric die ausgehende Verbindung basierend auf der aktuellen Datenverkehrslast der Verbindung aus. So können Diagnosepakete der Datenverkehrslast auf dem Router unterworfen werden. Wenn mehrere ausgehende Links zum NP vorhanden sind, wählt der Switch Fabric-ASIC einen Link aus, der derzeit am wenigsten geladen ist.
Dieses Diagramm zeigt den Diagnosepaketpfad, der vom aktiven Routingprozessor stammt.
Hinweis: Die erste Verbindung, die den Fabric Interface ASIC (FIA) auf der Linecard mit der Crossbar (XBAR) auf der Routingprozessorkarte verbindet, wird für Pakete, die an den NP gerichtet sind, ständig ausgewählt. Antwortpakete vom NP werden einem Link-Load-Verteilungsalgorithmus unterzogen (wenn die Linecard auf einem Typhoon basiert). Das bedeutet, dass das Antwortpaket vom NP zum aktiven Routingprozessor einen beliebigen Fabric-Link auswählen kann, der die Linecards mit der Routingprozessorkarte verbindet. Dies hängt von der Last des Fabric-Links ab.
Paketpfad zwischen der Standby-Route-Prozessorkarte und der Line Card
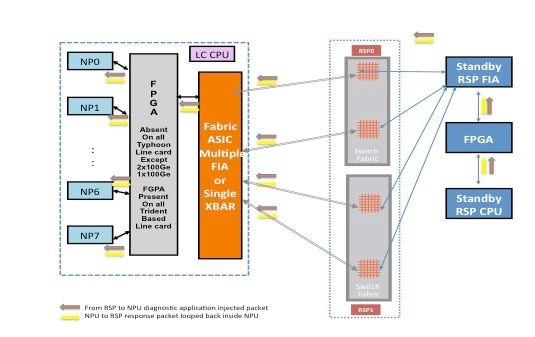
Diagnosepakete, die vom Standby-Routingprozessor in die Fabric zum NP eingespeist werden, werden von der Switch-Fabric als Multicast-Pakete behandelt. Obwohl es sich um ein Multicast-Paket handelt, findet innerhalb der Fabric keine Replikation statt. Jedes Diagnosepaket, das vom Standby-Routingprozessor stammt, erreicht immer noch nur jeweils einen NP. Das Antwortpaket vom NP zum Routing-Prozessor ist ebenfalls ein Multicast-Paket über die Fabric, das nicht repliziert wird. Daher empfängt die Diagnoseanwendung auf dem Standby-Routingprozessor ein einzelnes Antwortpaket von den NPs, und zwar jeweils ein Paket. Die Diagnoseanwendung verfolgt jeden NP im System, da sie ein Paket pro NP einfügt und Antworten von jedem NP erwartet, jeweils ein Paket. Bei einem Multicast-Paket wählt die Switch-Fabric die ausgehende Verbindung basierend auf einem Feldwert im Paket-Header aus, wodurch Diagnosepakete über jede Fabric-Verbindung zwischen der Routingprozessorkarte und der Linecard eingespeist werden können. Der Standby-Routingprozessor verfolgt den NP-Zustand über jeden Fabric-Link, der zwischen der Routingprozessorkarte und dem Linecard-Steckplatz angeschlossen ist.
Das vorherige Diagramm zeigt den Diagnosepaketpfad, der vom Standby-Routingprozessor stammt. Beachten Sie, dass im Gegensatz zum Fall des aktiven Routingprozessors alle Verbindungen, die die Linecard mit der XBAR auf dem Routingprozessor verbinden, ausgeführt werden. Die Antwortpakete vom NP leiten sich von derselben Fabric-Verbindung, die das Paket im Routingprozessor verwendet hat, in die Linecard-Richtung weiter. Dieser Test stellt sicher, dass alle Verbindungen, die den Standby-Routingprozessor mit der Linecard verbinden, kontinuierlich überwacht werden.
Fabric-Diagnosepaketpfad auf der Trident-basierten Linecard auslösen
Dieses Diagramm zeigt die vom Routingprozessor bezogenen Diagnosepakete, die an einen NP gerichtet sind, der in Richtung des Routingprozessors zurückgeschleift ist. Beachten Sie die Datenpfad-Verbindungen und ASICs, die allen NPs gemeinsam sind, sowie die Verbindungen und Komponenten, die für eine Untergruppe von NPs spezifisch sind. Beispielsweise ist die Bridge-ASIC 0 (B0) für NP0 und NP1 gleich, während FIA0 für alle NPs gleich ist. Auf der Seite des Routingprozessors sind alle Verbindungen, Datenpfad-ASICs und das Field-Programmable Gate Array (FPGA) für alle Linecards und damit für alle NPs in einem Chassis gleich.
Fabric-Diagnosepaketpfad auf der Typhoon-basierten Linecard auslösen
Dieses Diagramm zeigt von der Routingprozessorkarte ausgehende Diagnosepakete, die an einen NP gerichtet sind, der in Richtung des Routingprozessors zurückgeschleift wird. Beachten Sie die Datenpfad-Verbindungen und ASICs, die allen NPs gemeinsam sind, sowie die Verbindungen und Komponenten, die für eine Untergruppe von NPs spezifisch sind. Beispielsweise ist FIA0 für NP0 und NP1 gleich. Auf der Seite der Routingprozessorkarte sind alle Verbindungen, Datenpfad-ASICs und der FGPA für alle Linecards und somit für alle NPs in einem Chassis gleich.
Punt Fabric Diagnostic Packet Path auf der Tomahawk-, Lightspeed- und LightspeedPlus-basierten Linecard
Bei den Tomahawk Line Cards besteht eine 1:1-Verbindung zwischen der FIA und dem NP.
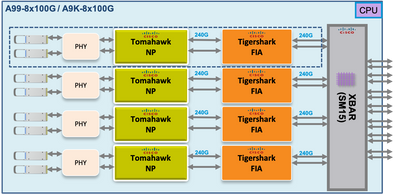
Bei Lightspeed- und LightspeedPlus-Linecards ist die FIA in den NP-Chip integriert.

In den nächsten Abschnitten wird versucht, den Paketpfad zu jedem NP darzustellen. Dies ist erforderlich, um die Fehlermeldung "Datenpfad des Punt-Fabrics" zu verstehen und um den Fehlerpunkt zu ermitteln.
Punt-Fabric-Diagnosealarm und Fehlerberichte
Wenn Antworten von einem NP in einem ASR 9000-Router nicht empfangen werden, wird ein Alarm ausgelöst. Die Entscheidung, einen Alarm von der Online-Diagnoseanwendung auszulösen, die auf dem Routingprozessor ausgeführt wird, tritt auf, wenn drei aufeinander folgende Fehler auftreten. Die Diagnoseanwendung unterhält ein Fehlerfenster von drei Paketen für jeden NP. Der aktive Routingprozessor und der Standby-Routingprozessor diagnostizieren unabhängig und parallel. Der aktive Routingprozessor, der Standby-Routingprozessor oder beide Routingprozessorkarten können den Fehler melden. Der Ort des Fehlers und der Paketverlust bestimmen, welcher Routingprozessor den Alarm meldet.
Die Standardfrequenz des Diagnosepakets für jeden NP beträgt ein Paket pro 60 Sekunden oder ein Paket pro Minute.
Hier ist das Format der Erinnerungsnachricht:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
Die Nachricht zeigt ein Versagen beim Erreichen der NP 1, 2, 3, 4, 5, 6 und 7 auf der Linecard 0/7/cpu0 vom Routing-Prozessor 0/rsp0/cpu0.
Aus der Liste der Online-Diagnosetests können Sie die Attribute des Loopback-Tests für die Punt-Fabric mit dem folgenden Befehl anzeigen:
RP/0/RSP0/CPU0:iox(admin)#show diagnostic content location 0/RSP0/CPU0
RP 0/RSP0/CPU0:
Diagnostics test suite attributes:
M/C/* - Minimal bootup level test / Complete bootup level test / NA
B/O/* - Basic ondemand test / not Ondemand test / NA
P/V/* - Per port test / Per device test / NA
D/N/* - Disruptive test / Non-disruptive test / NA
S/* - Only applicable to standby unit / NA
X/* - Not a health monitoring test / NA
F/* - Fixed monitoring interval test / NA
E/* - Always enabled monitoring test / NA
A/I - Monitoring is active / Monitoring is inactive
Test Interval Thre-
ID Test Name Attributes (day hh:mm:ss.ms shold)
==== ================================== ============ ================= =====
1) PuntFPGAScratchRegister ---------- *B*N****A 000 00:01:00.000 1
2) FIAScratchRegister --------------- *B*N****A 000 00:01:00.000 1
3) ClkCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
4) IntCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
5) CPUCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
6) FabSwitchIdRegister -------------- *B*N****A 000 00:01:00.000 1
7) EccSbeTest ----------------------- *B*N****I 000 00:01:00.000 3
8) SrspStandbyEobcHeartbeat --------- *B*NS***A 000 00:00:05.000 3
9) SrspActiveEobcHeartbeat ---------- *B*NS***A 000 00:00:05.000 3
10) FabricLoopback ------------------- MB*N****A 000 00:01:00.000 3
11) PuntFabricDataPath --------------- *B*N****A 000 00:01:00.000 3
12) FPDimageVerify ------------------- *B*N****I 001 00:00:00.000 1
RP/0/RSP0/CPU0:ios(admin)#
Die Ausgabe zeigt an, dass die Testfrequenz von PuntFabricDataPath bei einem Paket pro Minute und der Fehlerschwellenwert bei drei liegt. Dies bedeutet, dass der Verlust von drei aufeinander folgenden Paketen nicht toleriert wird und ein Alarm ausgelöst wird. Die angezeigten Testattribute sind Standardwerte. Um die Standardeinstellungen zu ändern, geben Sie diagnostic monitor interval und diagnostic monitor threshold -Befehlen im Administrationskonfigurationsmodus.
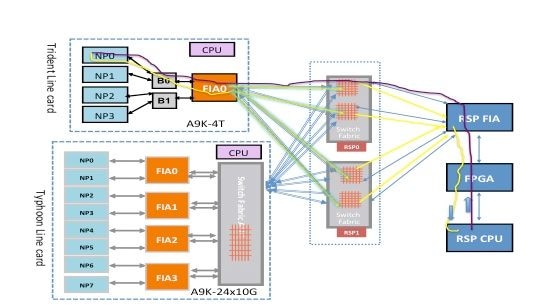
Trident-basierter Line Card-Diagnosepaketpfad
NP0-Diagnosefehler
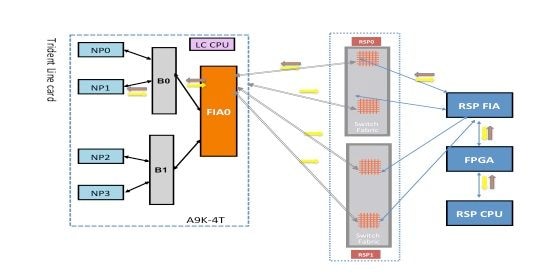
Fabric-Diagnosepfad
Dieses Diagramm zeigt den Paketpfad zwischen dem Routingprozessor CPU und der Linecard NP0. Die Verbindung, die B0 und NP0 verbindet, ist die einzige Verbindung, die spezifisch für NP0 ist. Alle anderen Verbindungen fallen in den gemeinsamen Pfad.
Notieren Sie sich den Paketpfad vom Routingprozessor zu NP0. Obwohl es vier Verbindungen für Pakete gibt, die vom Routingprozessor an NP0 gerichtet sind, wird die erste Verbindung zwischen dem Routingprozessor und dem Linecard-Steckplatz für das Paket vom Routingprozessor zur Linecard verwendet. Das von NP0 zurückgegebene Paket kann über einen der beiden Fabric-Link-Pfade zwischen dem Linecard-Steckplatz und dem aktiven Route-Prozessor an den aktiven Route-Prozessor zurückgesendet werden. Die Wahl, welche der beiden Verbindungen verwendet werden soll, hängt von der jeweiligen Verbindungslast ab. Das Antwortpaket vom NP0 zum Standby-Routing-Prozessor verwendet beide Verbindungen, jeweils nur eine. Die Auswahl des Links basiert auf dem Header-Feld, das von der Diagnoseanwendung ausgefüllt wird.

NP0 Diagnose-Fehleranalyse
Einzelfehler-Szenario
Wenn ein einzelner Platform Fault Manager (PFM)-Alarm zum Fabric-Datenpfadausfall erkannt wird, der nur NP0 in der Fehlermeldung enthält, liegt der Fehler nur auf dem Fabric-Pfad, der den Routingprozessor mit der Linecard NP0 verbindet. Das ist ein einziger Fehler. Wenn der Fehler an mehr als einem NP erkannt wird, lesen Sie den Abschnitt Multiple Fault Scenario (Szenario mit mehreren Fehlern).
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 0)
Hinweis: Dieser Abschnitt des Dokuments gilt für jeden Linecard-Steckplatz in einem Chassis, unabhängig vom Chassis-Typ. Dies kann somit auf alle Linecard-Steckplätze angewendet werden.
Wie im vorherigen Datenpfaddiagramm dargestellt, muss sich der Fehler an einer oder mehreren der folgenden Stellen befinden:
- Verbindung zwischen NP0 und B0
- In B0-Warteschlangen, die an NP0 gerichtet sind
- Interner NP0
Szenario mit mehreren Fehlern
Mehrere NP-Fehler
Wenn andere Fehler auf NP0 festgestellt werden oder der Fehler PUNT_FABRIC_DATA_PATH_FAILED auch von anderen NPs auf derselben Linecard gemeldet wird, erfolgt die Fehlerisolierung durch Korrelation aller Fehler. Wenn beispielsweise sowohl der Fehler PUNT_FABRIC_DATA_PATH_FAILED als auch der Fehler LC_NP_LOOPBACK_FAILED auf NP0 auftreten, hat der NP die Verarbeitung von Paketen gestoppt. Im Abschnitt NP LoopBack Diagnostic Path finden Sie weitere Informationen zum Loopback-Fehler. Dies könnte ein frühzeitiger Hinweis auf einen kritischen Fehler innerhalb von NP0 sein. Tritt jedoch nur einer der beiden Fehler auf, so wird der Fehler entweder auf den Datenpfad des Punt-Fabric oder auf der Linecard-CPU auf den NP-Pfad lokalisiert.
Wenn auf einer Linecard mehr als ein NP einen Datenpfadfehler in der Punktstruktur aufweist, müssen Sie den Baumpfad der Fabric-Verbindungen aufwärts gehen, um eine fehlerhafte Komponente zu isolieren. Wenn beispielsweise sowohl NP0 als auch NP1 einen Fehler aufweisen, muss der Fehler in B0 oder der Verbindung liegen, die B0 und FIA0 verbindet. Es ist weniger wahrscheinlich, dass sowohl NP0 als auch NP1 gleichzeitig auf einen kritischen internen Fehler stoßen. Obwohl es weniger wahrscheinlich ist, ist es für NP0 und NP1 möglich, einen kritischen Fehler aufgrund der fehlerhaften Verarbeitung eines bestimmten Pakets oder eines fehlerhaften Pakets zu entdecken.
Beide Routingprozessorkarten melden einen Fehler.
Wenn sowohl die aktive als auch die Standby-Routingprozessorkarte einen Fehler an einen oder mehrere NPs auf einer Linecard melden, überprüfen Sie alle gemeinsamen Verbindungen und Komponenten auf dem Datenpfad zwischen den betroffenen NPs und beiden Routingprozessorkarten.
NP1-Diagnosefehler
Dieses Diagramm zeigt den Paketpfad zwischen der Routingprozessorkarte CPU und der Linecard NP1. Die Verbindung, die Bridge ASIC 0 (B0) und NP1 verbindet, ist die einzige Verbindung, die für NP1 spezifisch ist. Alle anderen Verbindungen fallen in den gemeinsamen Pfad.
Notieren Sie sich den Paketpfad von der Routingprozessorkarte zu NP1. Obwohl es vier Verbindungen für Pakete gibt, die vom Routingprozessor an NP0 gerichtet sind, wird die erste Verbindung zwischen dem Routingprozessor und dem Linecard-Steckplatz für das Paket vom Routingprozessor zur Linecard verwendet. Das von NP1 zurückgegebene Paket kann über einen der beiden Fabric-Link-Pfade zwischen dem Linecard-Steckplatz und dem aktiven Route-Prozessor an den aktiven Route-Prozessor zurückgesendet werden. Die Wahl, welche der beiden Verbindungen verwendet werden soll, hängt von der jeweiligen Verbindungslast ab. Das Antwortpaket vom NP1 zum Standby-Routing-Prozessor verwendet beide Verbindungen, jeweils nur eine. Die Auswahl des Links basiert auf dem Header-Feld, das von der Diagnoseanwendung ausgefüllt wird.
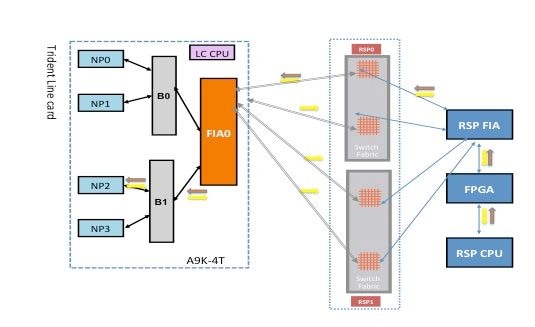
Fabric-Diagnosepfad
NP1-Diagnose-Fehleranalyse
Gehen Sie zum Abschnitt NP0 Diagnostic Failure Analysis (Analyse von Diagnosefehlern), wenden Sie jedoch denselben Grund für NP1 an (anstatt NP0).
NP2-Diagnosefehler
Dieses Diagramm zeigt den Paketpfad zwischen der Routingprozessorkarte CPU und der Linecard NP2. Die Verbindung, die B1 und NP2 verbindet, ist die einzige Verbindung, die spezifisch für NP2 ist. Alle anderen Verbindungen fallen in den gemeinsamen Pfad.
Notieren Sie sich den Paketpfad von der Routingprozessorkarte zu NP2. Obwohl es vier Verbindungen für Pakete gibt, die vom Routingprozessor an NP2 gerichtet sind, wird die erste Verbindung zwischen dem Routingprozessor und dem Linecard-Steckplatz für das Paket vom Routingprozessor zur Linecard verwendet. Das vom NP2 zurückgegebene Paket kann über einen der beiden Fabric-Link-Pfade zwischen dem Linecard-Steckplatz und dem aktiven Routingprozessor an den aktiven Routingprozessor zurückgesendet werden. Die Wahl, welche der beiden Verbindungen verwendet werden soll, hängt von der jeweiligen Verbindungslast ab. Das Antwortpaket vom NP2 zum Standby-Routing-Prozessor verwendet beide Verbindungen, jeweils nur eine. Die Auswahl des Links basiert auf dem Header-Feld, das von der Diagnoseanwendung ausgefüllt wird.
Fabric-Diagnosepfad
NP2-Diagnose-Fehleranalyse
Gehen Sie zum Abschnitt NP0 Diagnostic Failure Analysis (Analyse von Diagnosefehlern), wenden Sie jedoch denselben Grund für NP2 an (anstatt NP0).
NP3-Diagnosefehler
Dieses Diagramm zeigt den Paketpfad zwischen der Routingprozessorkarte CPU und der Linecard NP3. Die Verbindung, die Bridge ASIC 1 (B1) und NP3 verbindet, ist die einzige Verbindung, die für NP3 spezifisch ist. Alle anderen Verbindungen fallen in den gemeinsamen Pfad.
Notieren Sie sich den Paketpfad von der Routingprozessorkarte zum NP3. Obwohl es vier Verbindungen für Pakete gibt, die vom Routingprozessor an NP3 gerichtet sind, wird die erste Verbindung zwischen dem Routingprozessor und dem Linecard-Steckplatz für das Paket vom Routingprozessor zur Linecard verwendet. Das vom NP3 zurückgegebene Paket kann über einen der beiden Fabric-Link-Pfade zwischen dem Linecard-Steckplatz und dem aktiven Routingprozessor an den aktiven Routingprozessor zurückgesendet werden. Die Wahl, welche der beiden Verbindungen verwendet werden soll, hängt von der jeweiligen Verbindungslast ab. Das Antwortpaket vom NP3 zum Standby-Routingprozessor verwendet beide Verbindungen, jeweils nur eine. Die Auswahl des Links basiert auf dem Header-Feld, das von der Diagnoseanwendung ausgefüllt wird.
Fabric-Diagnosepfad
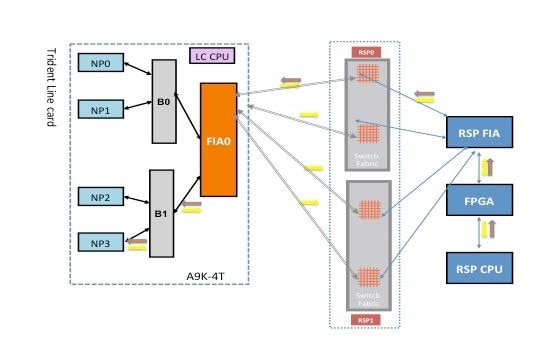
NP3-Diagnose-Fehleranalyse
Gehen Sie zum Abschnitt NP0 Diagnostic Failure Analysis (Analyse von Diagnosefehlern), wenden Sie jedoch denselben Grund für NP3 an (anstatt NP0).
Typhoon-basierter Line Card-Diagnosepaketpfad
Dieser Abschnitt enthält zwei Beispiele, um den Hintergrund für Fabric-Punt-Pakete mit Typhoon-basierten Line Cards festzulegen. Im ersten Beispiel wird NP1 und im zweiten Beispiel NP3 verwendet. Die Beschreibung und Analyse kann auf andere NPs auf jeder Typhoon-basierten Line Card erweitert werden.
Typhoon NP1 - Diagnosefehler
Das nächste Diagramm zeigt den Paketpfad zwischen der Routingprozessorkarte CPU und der Linecard NP1. Die Verbindung, die FIA0 und NP1 verbindet, ist die einzige Verbindung, die für den Pfad NP1 spezifisch ist. Alle anderen Verbindungen zwischen dem Linecard-Steckplatz und dem Routingprozessorkarten-Steckplatz fallen in den gemeinsamen Pfad. Die Links, die den Fabric-XBAR-ASIC auf der Linecard mit den FIAs auf der Linecard verbinden, sind für eine Untergruppe von NPs spezifisch. Beispielsweise werden beide Verbindungen zwischen FIA0 und dem lokalen Fabric XBAR ASIC auf der Linecard für den Datenverkehr zu NP1 verwendet.
Notieren Sie sich den Paketpfad von der Routingprozessorkarte zu NP1. Obwohl es acht Verbindungen für Pakete gibt, die von der Routingprozessorkarte an NP1 gerichtet sind, wird ein einziger Pfad zwischen der Routingprozessorkarte und dem Linecard-Steckplatz verwendet. Das von NP1 zurückgegebene Paket kann über acht Fabric-Verbindungspfade zwischen dem Linecard-Steckplatz und dem Routingprozessor an die Routingprozessorkarte zurückgesendet werden. Jede dieser acht Verbindungen wird einzeln nacheinander ausgeführt, wenn das Diagnosepaket zurück zur Routingprozessorkarte CPU geleitet wird.
Fabric-Diagnosepfad

Typhoon NP3-Diagnosefehler
Dieses Diagramm zeigt den Paketpfad zwischen der Routingprozessorkarte CPU und der Linecard NP3. Die Verbindung, die FIA1 und NP3 verbindet, ist die einzige Verbindung, die für den NP3-Pfad spezifisch ist. Alle anderen Verbindungen zwischen dem Linecard-Steckplatz und dem Routingprozessorkarten-Steckplatz fallen in den gemeinsamen Pfad. Die Links, die den Fabric-XBAR-ASIC auf der Linecard mit den FIAs auf der Linecard verbinden, sind für eine Untergruppe von NPs spezifisch. Beispielsweise werden beide Verbindungen zwischen FIA1 und dem lokalen Fabric XBAR ASIC auf der Linecard für den Datenverkehr zum NP3 verwendet.
Notieren Sie sich den Paketpfad von der Routingprozessorkarte zum NP3. Obwohl es acht Verbindungen für Pakete gibt, die von der Routingprozessorkarte an NP3 gerichtet sind, wird ein einziger Pfad zwischen der Routingprozessorkarte und dem Linecard-Steckplatz verwendet. Das von NP1 zurückgegebene Paket kann über acht Fabric-Verbindungspfade zwischen dem Linecard-Steckplatz und dem Routingprozessor an die Routingprozessorkarte zurückgesendet werden. Jede dieser acht Verbindungen wird einzeln nacheinander ausgeführt, wenn das Diagnosepaket zurück zur Routingprozessorkarte CPU geleitet wird.
Fabric-Diagnosepfad

Tomahawk-basierter Line Card-Diagnosepaketpfad
Aufgrund der 1:1-Verbindung zwischen der FIA und dem NP ist der einzige Datenverkehr, der FIA0 durchquert, der zu/von NP0.
Paketpfad für Lightspeed- und LightspeedPlus-basierte Line Card-Diagnose
Da die FIA in den NP-Chip integriert ist, ist der einzige Datenverkehr, der FIA0 durchquert, der zu/von NP0.
Fehler analysieren
Dieser Abschnitt kategorisiert Fehler in schwerwiegende und vorübergehende Fälle und führt die Schritte zur Identifizierung eines schwerwiegenden oder vorübergehenden Fehlers auf. Nach der Ermittlung des Fehlertyps werden im Dokument die Befehle angegeben, die auf dem Router ausgeführt werden können, um den Fehler zu erkennen und festzustellen, welche Korrekturmaßnahmen erforderlich sind.
Übergangsfehler
Wenn nach einer eingestellten PFM-Nachricht eine leere PFM-Nachricht folgt, ist ein Fehler aufgetreten, und der Router hat den Fehler selbst behoben. Vorübergehende Fehler können aufgrund von Umgebungsbedingungen und behebbaren Fehlern in Hardwarekomponenten auftreten. Manchmal kann es schwierig sein, vorübergehende Fehler einem bestimmten Ereignis zuzuordnen.
Zur Verdeutlichung wird hier ein Beispiel für einen vorübergehenden Fabric-Fehler aufgeführt:
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
RP/0/RSP0/CPU0:Feb 5 05:05:46.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Vorübergehende Maßnahmen zur Fehlerbehebung
Es wird vorgeschlagen, bei transienten Fehlern nur auf weiteres Auftreten solcher Fehler zu achten. Tritt ein vorübergehender Fehler mehr als einmal auf, behandeln Sie den vorübergehenden Fehler als schwerwiegenden Fehler und befolgen Sie die Empfehlungen und Schritte, um die im nächsten Abschnitt beschriebenen Fehler zu analysieren.
Harter Fehler
Wenn auf eine eingestellte PFM-Nachricht keine eindeutige PFM-Nachricht folgt, ist ein Fehler aufgetreten, und der Router hat den Fehler nicht durch den Fehlerbehandlungscode selbst behoben, oder der Hardwarefehler kann nicht behoben werden. Harte Fehler können aufgrund von Umgebungsbedingungen und nicht behebbaren Fehlern in Hardwarekomponenten auftreten. Der empfohlene Ansatz für schwerwiegende Fehler besteht darin, die im Abschnitt Analyse von schwerwiegenden Fehlern genannten Richtlinien zu verwenden.
Zur Verdeutlichung wird hier ein Beispiel für einen "hard fabric"-Fehler aufgelistet. Für diese Beispielmeldung gibt es keine entsprechende leere PFM-Meldung.
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Maßnahmen zur Behebung schwerwiegender Fehler
Erfassen Sie im Fall eines schwerwiegenden Fehlers alle Befehle, die im Abschnitt Zu erfassende Daten vor Erstellung von Serviceanfragen aufgeführt sind, und öffnen Sie eine Serviceanfrage. Wenn Sie in dringenden Fällen die gesamte Fehlerbehebungsbefehlsausgabe erfasst haben, starten Sie basierend auf der Fehlerisolierung eine Routingprozessorkarte oder ein erneutes Laden der Linecard. Wenn der Fehler nach dem Neuladen nicht behoben wird, starten Sie eine Warenrücksendung (Return Material Authorization, RMA).
Analyse vorübergehender Fehler
Führen Sie diese Schritte aus, um vorübergehende Fehler zu analysieren.
- Geben Sie
show logging | inc “PUNT_FABRIC_DATA_PATH", um festzustellen, ob der Fehler ein- oder mehrmals aufgetreten ist. - Geben Sie
show pfm location allum den aktuellen Status (SET oder CLEAR) zu ermitteln. Ist der Fehler offen oder behoben? Wenn sich der Fehlerstatus zwischen SET und CLEAR ändert, treten ein oder mehrere Fehler im Fabric-Datenpfad wiederholt auf und werden entweder durch Software oder Hardware behoben. - Bereitstellung von SNMP-Traps (Simple Network Management Protocol) oder Ausführung eines Skripts, das
show pfm location all-Befehl ausgegeben wird, und sucht regelmäßig nach der Fehlerzeichenfolge, um das zukünftige Auftreten des Fehlers zu überwachen (wenn der letzte Status des Fehlers auf CLEAR gesetzt ist und keine neuen Fehler auftreten).
Zu verwendende Befehle
Geben Sie die folgenden Befehle ein, um vorübergehende Fehler zu analysieren:
show logging | inc “PUNT_FABRIC_DATA_PATH”show pfm location all
Analyse von schwerwiegenden Fehlern
Wenn Sie die Fabric-Datenpfad-Links auf einer Linecard als Baum betrachten (wobei die Details im Abschnitt Hintergrundinformationen beschrieben werden), müssen Sie - basierend auf dem Fehlerpunkt - darauf schließen, ob ein oder mehrere NPs nicht zugänglich sind. Wenn mehrere Fehler auf mehreren NPs auftreten, verwenden Sie die in diesem Abschnitt aufgeführten Befehle, um die Fehler zu analysieren.
Zu verwendende Befehle
Geben Sie die folgenden Befehle ein, um schwerwiegende Fehler zu analysieren:
show logging | inc “PUNT_FABRIC_DATA_PATH”
Die Ausgabe kann einen oder mehrere NPs enthalten (z. B. NP2, NP3).show controller fabric fia link-status location
Da sowohl NP2 als auch NP3 (im Abschnitt Typhoon NP3 Diagnostic Failure) eine einzelne FIA empfangen und senden, kann davon ausgegangen werden, dass sich der Fehler in einer zugehörigen FIA auf dem Pfad befindet.show controller fabric crossbar link-status instance <0 and 1> location
Wenn für die Diagnoseanwendung nicht alle NPs auf der Linecard erreichbar sind, kann daraus geschlossen werden, dass die Verbindungen, die den Linecard-Steckplatz mit der Routingprozessorkarte verbinden, einen Fehler auf einem der ASICs haben können, die den Datenverkehr zwischen der Routingprozessorkarte und der Linecard weiterleiten.show controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 0 location 0/rsp1/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp1/cpu0show controller fabric fia link-status location 0/rsp*/cpu0show controller fabric fia link-status location 0/rsp0/cpu0show controller fabric fia link-status location 0/rsp1/cpu0show controller fabric fia bridge sync-status location 0/rsp*/cpu0show controller fabric fia bridge sync-status location 0/rsp0/cpu0show controller fabric fia bridge sync-status location 0/rsp1/cpu0show tech fabric terminal
Hinweis: Wenn alle NPs auf allen Linecards einen Fehler melden, liegt der Fehler höchstwahrscheinlich auf der Routingprozessorkarte (aktive Routingprozessorkarte oder Standby-Routingprozessorkarte). Siehe Link, der die Routingprozessorkarte CPU mit dem FPGA und der Routingprozessorkarte FIA verbindet, im Abschnitt Hintergrundinformationen.
Vergangene Fehler
In der Vergangenheit konnten 99 Prozent der Fehler behoben werden, und in den meisten Fällen konnten die Fehler durch eine softwaregestützte Wiederherstellungsaktion behoben werden. In sehr seltenen Fällen treten jedoch nicht behebbare Fehler auf, die nur mit der RMA der Karten behoben werden können.
In den nächsten Abschnitten werden einige Fehler aufgeführt, die in der Vergangenheit aufgetreten sind. Sie dienen als Orientierungshilfe, wenn ähnliche Fehler beobachtet werden.
Vorübergehender Fehler aufgrund von NP-Überbelegung
Diese Meldungen werden angezeigt, wenn der Fehler auf eine NP-Überbelegung zurückzuführen ist.
RP/0/RP1/CPU0:Jun 26 13:08:28.669 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0, 0)
RP/0/RP1/CPU0:Jun 26 13:09:28.692 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0,0)
Vorübergehende Störungen können schwieriger zu bestätigen sein. Eine Methode, um festzustellen, ob ein NP derzeit überbelegt ist oder in der Vergangenheit überbelegt wurde, besteht darin, eine bestimmte Art von Tropfen innerhalb des NP und eine Schwanzflosse in der FIA zu überprüfen. IFDMA-Drops (Ingress Front Direct Memory Access) innerhalb des NP treten auf, wenn der NP überlastet ist und nicht mit dem eingehenden Datenverkehr Schritt halten kann. FIA-Tail-Drops treten auf, wenn ein Ausgangs-NP eine Flusskontrolle durchführt (fordert die Eingangs-Linecard auf, weniger Datenverkehr zu senden). Im Szenario der Flusskontrolle weist die Eingangs-FIA Tail Drops auf.
Hier ein Beispiel:
RP/0/RSP0/CPU0:RP/0/RSP0/CPU0:ASR9006-C#show controllers np counters all
Wed Feb 19 13:10:11.848 EST
Node: 0/1/CPU0:
----------------------------------------------------------------
Show global stats counters for NP0, revision v3
Read 93 non-zero NP counters:
Offset Counter FrameValue Rate (pps)
-----------------------------------------------------------------------
22 PARSE_ENET_RECEIVE_CNT 46913080435 118335
23 PARSE_FABRIC_RECEIVE_CNT 40175773071 5
24 PARSE_LOOPBACK_RECEIVE_CNT 5198971143966 0
<SNIP>
Show special stats counters for NP0, revision v3
Offset Counter CounterValue
----------------------------------------------------------------------------
524032 IFDMA discard stats counters 0 8008746088 0 <<<<<
Hier ein Beispiel:
RP/0/RSP0/CPU0:ASR9006-C#show controllers fabric fia drops ingress location 0/1/cPU0
Wed Feb 19 13:37:27.159 EST
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 0
Tail Drop-0 0 <<<<<<<
Tail Drop-1 0 <<<<<<<
Tail Drop-2 0 <<<<<<<
Tail Drop-3 0 <<<<<<<
Tail Drop DE-0 0
Tail Drop DE-1 0
Tail Drop DE-2 0
Tail Drop DE-3 0
Hard Drop-0 0
Hard Drop-1 0
Hard Drop-2 0
Hard Drop-3 0
Hard Drop DE-0 0
Hard Drop DE-1 0
Hard Drop DE-2 0
Hard Drop DE-3 0
WRED Drop-0 0
WRED Drop-1 0
WRED Drop-2 0
WRED Drop-3 0
WRED Drop DE-0 0
WRED Drop DE-1 0
WRED Drop DE-2 0
WRED Drop DE-3 0
Mc No Rep 0
Harter Fehler durch NP Fast Reset
Wenn PUNT_FABRIC_DATA_PATH_FAILED auftritt und der Fehler auf das schnelle Zurücksetzen des NP zurückzuführen ist, werden ähnliche Protokolle wie hier für eine Typhoon-basierte Linecard angezeigt. Der Health Monitoring-Mechanismus ist auf Typhoon-basierten Line Cards verfügbar, nicht jedoch auf Trident-basierten Line Cards.
LC/0/2/CPU0:Aug 26 12:09:15.784 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:18.798 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:21.812 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST:
prm_server_ty[303]: NP-DIAG health monitoring failure on NP0
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST: pfm_node_lc[291]:
%PLATFORM-NP-0-NP_DIAG : Set|prm_server_ty[172112]|
Network Processor Unit(0x1008000)| NP diagnostics warning on NP0.
LC/0/2/CPU0:Aug 26 12:09:40.492 CEST: prm_server_ty[303]:
Starting fast reset for NP 0 LC/0/2/CPU0:Aug 26 12:09:40.524 CEST:
prm_server_ty[303]: Fast Reset NP0 - successful auto-recovery of NP
Bei Trident-basierten Line Cards wird dieses Protokoll mit einem schnellen Reset eines NP angezeigt:
LC/0/1/CPU0:Mar 29 15:27:43.787 test:
pfm_node_lc[279]: Fast Reset initiated on NP3
Fehler zwischen RSP440 Routingprozessoren und Typhoon Line Cards
Cisco hat ein Problem behoben, bei dem selten Fabric-Verbindungen zwischen Route Switch Processor (RSP) 440 und Typhoon-basierten Line Cards auf der Backplane neu geschult werden. Fabric-Verbindungen werden neu trainiert, da die Signalstärke nicht optimal ist. Dieses Problem tritt in den grundlegenden Cisco IOS® XR Softwareversionen 4.2.1, 4.2.2, 4.2.3, 4.3.0, 4.3.1 und 4.3.2 auf. Für jede dieser Versionen wird auf Cisco Connection Online ein Software Maintenance Update (SMU) veröffentlicht, das mit der Cisco Bug-ID CSCuj10837 und der Cisco Bug-ID CSCul39674 verfolgt wird.
Wenn dieses Problem auf dem Router auftritt, kann eines der folgenden Szenarien auftreten:
- Die Verbindung geht runter und kommt hoch. (Übergangsmodell)
- Die Verbindung fällt dauerhaft aus.
Cisco Bug-ID CSCuj10837 - Fabric Retrain Between RSP and LC (TX Direction)
Sammeln Sie zur Bestätigung die Trace-Ausgänge von LC und von beiden RSPs (show controller fabric crossbar ltrace location <>) und überprüfen Sie, ob diese Ausgabe in RSP-Zeichenfolgen angezeigt wird:
SMU ist bereits verfügbar.
Hier ein Beispiel:
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain:
destslot:0 fmlgrp:3 rc:0
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (2,0,7) initiated
Oct 1 08:22:58.969 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (2,1,0),(2,2,0),0.
Der Begriff TX-Richtung bezieht sich auf die Richtung vom Standpunkt der RSPs-Crossbar-Fabric-Schnittstelle zu einer Fabric-Crossbar-Schnittstelle auf einer Typhoon-basierten Line Card.
Die Cisco Bug-ID CSCuj10837 zeichnet sich dadurch aus, dass die Typhoon Line Card ein Problem auf der RX-Verbindung vom RSP erkennt und einen Link-Retrain einleitet. Beide Seiten (LC oder RSP) können das Ereignis für die Neuschulung initiieren. Im Fall der Cisco Bug-ID CSCuj10837 initiiert der LC den Retrain und kann durch die init xbar_trigger_link_retrain:-Nachricht in den Traces auf dem LC erkannt werden.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain: destslot:
0 fmlgrp:3 rc:0
Wenn der LC die Neuschulung initiiert, meldet der RSP einen rcvd link_retrain in der Ablaufverfolgungsausgabe.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
Cisco Bug-ID CSCul39674 - Fabric Retrain Between RSP and LC (RX Direction)
Sammeln Sie zur Bestätigung die Leiterausgänge der Linecard und der beiden RSPs (show controller fabric crossbar ltrace location <>) und überprüfen Sie, ob diese Ausgabe in RSP-Zeichenfolgen angezeigt wird:
Hier ein Beispiel:
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain:
destslot:4 fmlgrp:3 rc:0
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (5,1,11) initiated
Jan 8 17:28:39.256 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (5,1,1),(0,1,0),0.
Der Begriff RX-Richtung bezieht sich auf die Richtung aus Sicht der RSPs Crossbar Fabric-Schnittstelle von einer Fabric Crossbar-Schnittstelle auf einer Typhoon-basierten Line Card.
Die Cisco Bug-ID CSCul39674 zeichnet sich dadurch aus, dass der RSP ein Problem an der RX-Verbindung von der Typhoon Line Card erkennt und einen Link-Retrain einleitet. Beide Seiten (LC oder RSP) können das Ereignis für die Neuschulung initiieren. Im Fall der Cisco Bug-ID CSCul39674 initiiert der RSP die Neuschulung und kann durch die Meldung init xbar_trigger_link_retrain: in den Traces auf dem RSP erkannt werden.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain: destslot:4 fmlgrp:
3 rc:0
Wenn der RSP die Neuschulung initiiert, meldet der LC ein rcvd link_retrain-Ereignis in der Ablaufverfolgungsausgabe.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
Fabric Retrain-Unterschiede in Version 4.3.2 und höher
In Cisco IOS XR Version 4.3.2 und höher wurde viel Arbeit geleistet, um die Zeit für die Umschulung eines Fabric Links zu verkürzen. Die Fabric-Bereinigung erfolgt jetzt in Sekundenbruchteilen und ist für den Datenverkehr nicht wahrnehmbar. In Cisco IOS XR Version 4.3.2 werden nur diese Syslog-Meldungen angezeigt, wenn eine Fabric Link-Neuschulung stattgefunden hat.
%PLATFORM-FABMGR-5-FABRIC_TRANSIENT_FAULT : Fabric backplane crossbar link
underwent link retraining to recover from a transient error: Physical slot 1
Fehler aufgrund eines Fabric-ASIC-FIFO-Überlaufs
Cisco hat ein Problem behoben, bei dem der Fabric-ASIC (FIA) aufgrund eines nicht behebbaren FIFO-Überlaufs (First In First Out) zurückgesetzt werden konnte. Dies wird mit der Cisco Bug-ID CSCul66510 behoben. Dieses Problem betrifft nur die Trident-basierten Line Cards und tritt nur in seltenen Fällen bei starker Überlastung des Eingangspfads auf. Wenn dieses Problem auftritt, wird diese Syslog-Meldung angezeigt, bevor die Linecard zurückgesetzt wird, um den Fehler zu beheben.
RP/0/RSP0/CPU0:asr9k-2#show log
LC/0/3/CPU0:Nov 13 03:46:38.860 utc: pfm_node_lc[284]:
%FABRIC-FIA-0-ASIC_FATAL_FAULT Set|fialc[159814]
|Fabric Interface(0x1014000)|Fabric interface asic ASIC1 encountered fatal
fault 0x1b - OC_DF_INT_PROT_ERR_0
LC/0/3/CPU0:Nov 13 03:46:38.863 utc: pfm_node_lc[284]:
%PLATFORM-PFM-0-CARD_RESET_REQ : pfm_dev_sm_perform_recovery_action,
Card reset requested by: Process ID:159814 (fialc), Fault Sev: 0, Target node:
0/3/CPU0, CompId: 0x10, Device Handle: 0x1014000, CondID: 2545, Fault Reason:
Fabric interface asic ASIC1 encountered fatal fault 0x1b - OC_DF_INT_PROT_ERR_0
Fehler aufgrund von starkem Aufbau einer virtuellen Ausgabewarteschlange (VOQ) aufgrund einer Fabric-Überlastung
Cisco hat ein Problem behoben, bei dem eine ausgedehnte, starke Überlastung zur Erschöpfung der Fabric-Ressourcen und zum Verlust von Datenverkehr führen könnte. Der Datenverkehrsverlust kann sogar bei nicht zusammenhängenden Datenströmen auftreten. Dieses Problem wurde mit der Cisco Bug-ID CSCug90300 behoben und wurde in Cisco IOS XR Version 4.3.2 und höher behoben. Die Fehlerbehebung wurde auch in Cisco IOS XR Version 4.2.3, CSMU#3, Cisco Bug-ID CSCui33805, implementiert. Dieses seltene Problem kann auf Trident- oder Taifun-basierten Line Cards auftreten.
Relevante Befehle
Sammeln Sie die Ausgabe dieser Befehle:
show tech-support fabricshow controller fabric fia bridge flow-control location<=== Ausgabe für alle LCs abrufenshow controllers fabric fia q-depth location
Hier einige Beispielausgaben:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia q-depth location 0/6/CPU0
Sun Dec 29 23:10:56.307 UTC
********** FIA-0 **********
Category: q_stats_a-0
Voq ddr pri pktcnt
11 0 2 7
********** FIA-0 **********
Category: q_stats_b-0
Voq ddr pri pktcnt
********** FIA-1 **********
Category: q_stats_a-1
Voq ddr pri pktcnt
11 0 0 2491
11 0 2 5701
********** FIA-1 **********
Category: q_stats_b-1
Voq ddr pri pktcnt
RP/0/RSP0/CPU0:asr9k-1#
RP/0/RSP0/CPU0:asr9k-1#show controllers pm location 0/1/CPU0 | in "switch|if"
Sun Dec 29 23:37:05.621 UTC
Ifname(2): TenGigE0_1_0_2, ifh: 0x2000200 : <==Corresponding interface ten 0/1/0/2
iftype 0x1e
switch_fabric_port 0xb <==== VQI 11
parent_ifh 0x0
parent_bundle_ifh 0x80009e0
RP/0/RSP0/CPU0:asr9k-1#
Unter normalen Bedingungen ist es sehr unwahrscheinlich, dass ein VOQ mit in die Warteschlange gestellten Paketen vorhanden ist. Dieser Befehl ist ein schneller Echtzeit-Snapshot der FIA-Warteschlangen. In der Regel zeigt dieser Befehl keine in der Warteschlange befindlichen Pakete an.
Auswirkungen auf den Datenverkehr durch weiche Bridge-/FPGA-Fehler auf Trident-basierte Line Cards
Weiche Fehler sind nicht permanente Fehler, die dazu führen, dass der Statuscomputer nicht mehr synchronisiert ist. Diese werden als Cyclic Redundancy Check (CRC), Frame Check Sequence (FCS) oder fehlerhafte Pakete auf der Fabric-Seite des NP oder auf der Eingangsseite der FIA angesehen.
Hier einige Beispiele, wie dieses Problem zu sehen ist:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia drops ingress location 0/3/CPU0
Fri Dec 6 19:50:42.135 UTC
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 32609856 <=== Errors
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia errors ingress location 0/3/CPU0
Fri Dec 6 19:50:48.934 UTC
********** FIA-0 **********
Category: in_error-0
DDR Rx CRC-0 0
DDR Rx CRC-1 32616455 <=== Errors
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/0/CPU0
Ingress Drop Stats (MC & UC combined)
**************************************
PriorityPacket Error Threshold
Direction Drops Drops
--------------------------------------------------
LP NP-3 to Fabric 0 0
HP NP-3 to Fabric 1750 0
RP/0/RSP1/CPU0:asr9k-1#
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/6/CPU0
Sat Jan 4 06:33:41.392 CST
********** FIA-0 **********
Category: bridge_in-0
UcH Fr Np-0 16867506
UcH Fr Np-1 115685
UcH Fr Np-2 104891
UcH Fr Np-3 105103
UcL Fr Np-0 1482833391
UcL Fr Np-1 31852547525
UcL Fr Np-2 3038838776
UcL Fr Np-3 30863851758
McH Fr Np-0 194999
McH Fr Np-1 793098
McH Fr Np-2 345046
McH Fr Np-3 453957
McL Fr Np-0 27567869
McL Fr Np-1 12613863
McL Fr Np-2 663139
McL Fr Np-3 21276923
Hp ErrFrNp-0 0
Hp ErrFrNp-1 0
Hp ErrFrNp-2 0
Hp ErrFrNp-3 0
Lp ErrFrNp-0 0
Lp ErrFrNp-1 0
Lp ErrFrNp-2 0
Lp ErrFrNp-3 0
Hp ThrFrNp-0 0
Hp ThrFrNp-1 0
Hp ThrFrNp-2 0
Hp ThrFrNp-3 0
Lp ThrFrNp-0 0
Lp ThrFrNp-1 0
Lp ThrFrNp-2 0
Lp ThrFrNp-3 0
********** FIA-0 **********
Category: bridge_eg-0
UcH to Np-0 779765
UcH to Np-1 3744578
UcH to Np-2 946908
UcH to Np-3 9764723
UcL to Np-0 1522490680
UcL to Np-1 32717279812
UcL to Np-2 3117563988
UcL to Np-3 29201555584
UcH ErrToNp-0 0
UcH ErrToNp-1 0
UcH ErrToNp-2 129 <==============
UcH ErrToNp-3 0
UcL ErrToNp-0 0
UcL ErrToNp-1 0
UcL ErrToNp-2 90359 <==========
Zu ermittelnde Befehle für weiche Bridge-/FPGA-Fehler auf Trident-basierten Linecards
Sammeln Sie die Ausgabe dieser Befehle:
show tech-support fabricshow tech-support npshow controller fabric fia bridge stats location <>(erhalten Sie mehrmals)
Wiederherstellung nach Bridge-/FPGA-Softfehlern
Die Wiederherstellungsmethode besteht darin, die betroffene Linecard neu zu laden.
RP/0/RSP0/CPU0:asr9k-1#hw-module location 0/6/cpu0 reload
Online-Diagnosetestbericht
Die Fehlermeldung show diagnostic result location
bietet eine Zusammenfassung aller Online-Diagnosetests und -Fehler sowie den letzten Zeitstempel, wenn ein Test bestanden wurde. Die Test-ID für den Datenpfadausfall der Punt-Fabric lautet zehn. Eine Liste aller Tests zusammen mit der Häufigkeit der Testpakete finden Sie im show diagnostic content location
aus.
Die Ausgabe des Punt-Fabric-Datenpfad-Testergebnisses ähnelt der folgenden Beispielausgabe:
RP/0/RSP0/CPU0:ios(admin)#show diagnostic result location 0/rsp0/cpu0 test 10 detail
Current bootup diagnostic level for RP 0/RSP0/CPU0: minimal
Test results: (. = Pass, F = Fail, U = Untested)
___________________________________________________________________________
10 ) FabricLoopback ------------------> .
Error code ------------------> 0 (DIAG_SUCCESS)
Total run count -------------> 357
Last test execution time ----> Sat Jan 10 18:55:46 2009
First test failure time -----> n/a
Last test failure time ------> n/a
Last test pass time ---------> Sat Jan 10 18:55:46 2009
Total failure count ---------> 0
Consecutive failure count ---> 0
Verbesserungen für die automatische Wiederherstellung
Wie in Cisco Bug-ID CSCuc04493 beschrieben, besteht nun die Möglichkeit, den Router automatisch alle Ports herunterzufahren, die mit den auf Active RP/RSP ausgelösten PUNT_FABRIC_DATA_PATH-Fehlern verknüpft sind.
Die erste Methode wird über die Cisco Bug-ID CSCuc04493 verfolgt. Für Version 4.2.3 ist dies in der Cisco Bug-ID CSCui33805 enthalten. In dieser Version ist sie so eingestellt, dass alle Ports, die den betroffenen NPs zugeordnet sind, automatisch deaktiviert werden.
Das folgende Beispiel zeigt, wie die Syslogs angezeigt werden:
RP/0/RSP0/CPU0:Jun 10 16:11:26 BKK: pfm_node_rp[359]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System
Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/1/CPU0, 0)
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/1, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/1, changed state to Down
Der Controller gibt an, dass der Grund für den Ausfall der Schnittstelle DATA_PATH_DOWN. Hier ein Beispiel:
RP/0/RSP0/CPU0:ASR9006-E#show controllers gigabitEthernet 0/0/0/13 internal
Wed Dec 18 02:42:52.221 UTC
Port Number : 13
Port Type : GE
Transport mode : LAN
BIA MAC addr : 6c9c.ed08.3cbd
Oper. MAC addr : 6c9c.ed08.3cbd
Egress MAC addr : 6c9c.ed08.3cbd
Port Available : true
Status polling is : enabled
Status events are : enabled
I/F Handle : 0x04000400
Cfg Link Enabled : tx/rx enabled
H/W Tx Enable : no
UDLF enabled : no
SFP PWR DN Reason : 0x00000000
SFP Capability : 0x00000024
MTU : 1538
H/W Speed : 1 Gbps
H/W Duplex : Full
H/W Loopback Type : None
H/W FlowCtrl type : None
H/W AutoNeg Enable: Off
H/W Link Defects : (0x00080000) DATA_PATH_DOWN <<<<<<<<<<<
Link Up : no
Link Led Status : Link down -- Red
Input good underflow : 0
Input ucast underflow : 0
Output ucast underflow : 0
Input unknown opcode underflow: 0
Pluggable Present : yes
Pluggable Type : 1000BASE-LX
Pluggable Compl. : (Service Un) - Compliant
Pluggable Type Supp.: (Service Un) - Supported
Pluggable PID Supp. : (Service Un) - Supported
Pluggable Scan Flg: false
In Version 4.3.1 und höher muss dieses Verhalten aktiviert sein. Es gibt einen neuen admin-config-Befehl, der verwendet wird, um dies zu erreichen. Da das Standardverhalten nicht mehr darin besteht, die Ports herunterzufahren, muss dies manuell konfiguriert werden.
RP/0/RSP1/CPU0:ASR9010-A(admin-config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
Auf der 64-Bit-Version von Cisco IOS XR ist der Konfigurationsbefehl im virtuellen System XR (nicht im virtuellen System Sysadmin) verfügbar:
RP/0/RSP0/CPU0:CORE-TOP(config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
Die Cisco Bug-ID CSCui15435 behebt die weichen Fehler, die auf den Trident-basierten Line Cards auftreten, wie im Abschnitt Datenverkehrsauswirkungen aufgrund von Bridge-/FPGA-weichen Fehlern auf Trident-basierten Line Cards beschrieben. Dabei wird eine andere Erkennungsmethode als die übliche Diagnosemethode verwendet, die in Cisco Bug-ID CSCuc04493 beschrieben wird.
Durch diesen Fehler wurde auch der neue CLI-Befehl admin-config eingeführt:
(admin-config)#fabric fia soft-error-monitor <1|2> location
1 = shutdown the ports
2 = reload the linecard
Default behavior: no action is taken.
Wenn dieser Fehler auftritt, kann dieses Syslog beobachtet werden:
RP/0/RSP0/CPU0:Apr 30 22:17:11.351 : config[65777]: %MGBL-SYS-5-CONFIG_I : Configured
from console by root
LC/0/2/CPU0:Apr 30 22:18:52.252 : pfm_node_lc[283]:
%PLATFORM-BRIDGE-1-SOFT_ERROR_ALERT_1 : Set|fialc[159814]|NPU
Crossbar Fabric Interface Bridge(0x1024000)|Soft Error Detected on Bridge instance 1
RP/0/RSP0/CPU0:Apr 30 22:21:28.747 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/2/CPU0, 2) (0/2/CPU0, 3)
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINK-3-UPDOWN :
Interface TenGigE0/2/0/2, changed state to Down
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINEPROTO-5-UPDOWN :
Line protocol on Interface TenGigE0/2/0/2, changed state to Down
RP/0/RSP1/CPU0:Apr 30 22:21:35.086 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED :
Set|online_diag_rsp[237646]|System Punt/Fabric/data Path Test(0x2000004)|failure
threshold is 3, (slot, NP) failed: (0/2/CPU0, 2) (0/2/CPU0, 3)
Wenn die betroffenen Ports ausgeschaltet werden, kann die Netzwerkreddenz übernehmen und ein Blackholing des Datenverkehrs vermeiden. Um sich zu erholen, muss die Linecard neu geladen werden.
Häufig gestellte Fragen
Frage: Sendet die primäre oder Standby-Routingprozessorkarte die Keepalives oder Online-Diagnosepakete an jeden NP im System?
Antwort: Ja. Beide Routingprozessorkarten senden Online-Diagnosepakete an jeden NP.
Frage: Ist der Pfad derselbe, wenn die erste Routingprozessorkarte (RSP1) aktiv ist?
A. Der Diagnosepfad ist für RSP0 oder RSP1 identisch. Der Pfad hängt vom Status des RSP ab. Weitere Informationen finden Sie im Abschnitt Punt Fabric Diagnostic Packet Path dieses Dokuments.
Frage: Wie oft senden RSP Diagnosepakete, und wie viele Diagnosepakete müssen verpasst werden, bevor ein Alarm ausgelöst wird?
A. Jeder RSP sendet unabhängig ein Diagnosepaket einmal pro Minute an jeden NP. Beide RSP können einen Alarm auslösen, wenn drei Diagnosepakete nicht bestätigt werden.
F. Wie stellen Sie fest, ob ein NP überbelegt ist oder wurde?
A. Eine Möglichkeit, um zu überprüfen, ob ein NP derzeit überbelegt ist oder in der Vergangenheit überbelegt wurde, besteht darin, eine bestimmte Art von Tropfen innerhalb des NP und eine Schwanzflosse in der FIA zu überprüfen. IFDMA-Drops (Ingress Front Direct Memory Access) innerhalb des NP treten auf, wenn der NP überlastet ist und nicht mit dem eingehenden Datenverkehr Schritt halten kann. FIA-Tail-Drops treten auf, wenn ein Ausgangs-NP eine Flusskontrolle durchführt (fordert die Eingangs-Linecard auf, weniger Datenverkehr zu senden). Im Szenario der Flusskontrolle weist die Eingangs-FIA Tail Drops auf.
F. Wie stellen Sie fest, ob ein NP an einem Fehler leidet, der ein Zurücksetzen erfordert?
A. Normalerweise wird ein NP-Fehler durch ein schnelles Zurücksetzen behoben. Der Grund für ein schnelles Zurücksetzen wird in den Protokollen angezeigt.
F. Kann ein NP manuell zurückgesetzt werden?
A. Ja, von der Linecard KSH:
run attach 0/[x]/CPU0 #show_np -e [np#] -d fast_reset
F. Was wird angezeigt, wenn ein NP einen nicht behebbaren Hardwarefehler aufweist?
A. Es liegt sowohl ein Fehler im Datenpfad der einzelnen Fabrics für diesen NP als auch ein Fehler im NP-Loopback-Test vor. Die Fehlermeldung für den NP-Loopback-Test wird im Anhang dieses Dokuments behandelt.
F. Wird ein Diagnosepaket, das von einer Routingprozessorkarte stammt, auf dieselbe Karte zurückgeleitet?
A. Da Diagnosepakete von beiden Routingprozessorkarten stammen und auf Basis von Routingprozessorkarten nachverfolgt werden, wird ein von einer Routingprozessorkarte stammendes Diagnosepaket vom NP zu derselben Routingprozessorkarte zurückgeschleift.
Frage: Der Cisco Bug mit der CSCuj10837 SMU behebt das Fabric Link Retraining-Ereignis. Ist dies die Ursache und Lösung für viele Fabric-Datenpfadausfälle?
A. Ja, es ist erforderlich, die ersetzende SMU für die Cisco Bug-ID CSCul39674 zu laden, um Fabric Link Retraining-Ereignisse zu vermeiden.
Frage: Wie lange dauert es, bis die Fabric-Verbindungen neu geschult werden, sobald die Entscheidung getroffen wurde?
A. Die Entscheidung für eine Umschulung wird getroffen, sobald ein Verbindungsausfall erkannt wird. Vor Release 4.3.2 konnte die Umschulung einige Sekunden dauern. Nach Release 4.3.2 wurde die Umschulungszeit deutlich verbessert und dauert weniger als eine Sekunde.
Frage: Wann wird die Entscheidung für eine Umschulung einer Fabric-Verbindung getroffen?
A. Sobald ein Verbindungsfehler erkannt wird, entscheidet sich der Fabric-ASIC-Treiber für eine Umschulung.
F. Verwenden Sie nur zwischen der FIA auf einer aktiven Routingprozessorkarte und der Fabric den ersten Link, und ist dieser dann der am wenigsten geladene Link, wenn mehrere Links verfügbar sind?
A. Richtig. Die erste Verbindung, die mit der ersten XBAR-Instanz auf dem aktiven Routingprozessor verbunden wird, wird verwendet, um Datenverkehr in die Fabric zu injizieren. Das Antwortpaket vom NP kann auf alle Verbindungen, die mit der Routingprozessorkarte verbunden sind, auf die aktive Routingprozessorkarte zurückgreifen. Die Wahl der Verbindung hängt von der Verbindungslast ab.
Frage: Gehen während der Schulung alle Pakete verloren, die über diese Fabric-Verbindung gesendet werden?
A. Ja, aber mit den Verbesserungen in Version 4.3.2 und höher ist die Umschulung praktisch nicht mehr nachweisbar. In einem früheren Code konnte es jedoch einige Sekunden dauern, bis die Schulung erneut durchgeführt wurde, was zu Paketverlusten in diesem Zeitraum führte.
Frage: Wie oft wird nach dem Upgrade auf eine Version oder SMU mit der Fehlerbehebung für die Cisco Bug-ID CSCuj10837 voraussichtlich ein XBAR Fabric Link Retraining stattfinden?
A. Selbst mit der Korrektur für Cisco Bug-ID CSCuj10837 ist es immer noch möglich, Fabric-Link-Umschulungen aufgrund von Cisco Bug-ID CSCul39674 zu sehen. Sobald Sie jedoch den Fehler mit der Cisco Bug-ID CSCul39674 behoben haben, sollte es nie zu einer Umschulung der Fabric-Verbindung auf den Fabric-Backplane-Verbindungen zwischen dem RSP440 und den Typhoon-basierten Line Cards kommen. Falls ja, stellen Sie eine Serviceanfrage beim Cisco Technical Assistance Center (TAC), um das Problem zu beheben.
F. Wirkt sich der Cisco Bug-ID CSCuj10837 und der Cisco Bug-ID CSCul39674 auf den RP des ASR 9922 mit Typhoon-basierten Line Cards aus?
A. Ja
Frage: Wirken sich die Cisco Bug-ID CSCuj10837 und die Cisco Bug-ID CSCul39674 auf die Router ASR-9001 und ASR-9001-S aus?
A. Nein
F. Wenn Sie einen nicht vorhandenen Steckplatz mit dieser Meldung als fehlerhaft identifizieren: "PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[237686]|System Punt/Fabric/data Path Test(0x2000004)|Failure Threshold ist 3 (Steckplatz, NP) fehlgeschlagen: (8, 0) ", in einem Chassis mit 10 Steckplätzen, an welchem Steckplatz liegt das Problem?
A. In früheren Versionen müssen Sie die hier gezeigten physischen und logischen Zuordnungen berücksichtigen. In diesem Beispiel entspricht Steckplatz 8 0/6/CPU0.
For 9010 (10 slot chassis)
L P
#0 --- #0
#1 --- #1
#2 --- #2
#3 --- #3
RSP0 --- #4
RSP1 --- #5
#4 --- #6
#5 --- #7
#6 --- #8
#7 --- #9
For 9006 (6 slot chassis)
L P
RSP0 --- #0
RSP1 --- #1
#0 --- #2
#1 --- #3
#2 --- #4
#3 --- #5
Zu erfassende Daten vor Erstellung des Serviceantrags
Die folgenden Befehle müssen mindestens ausgeführt werden, bevor eine Aktion ausgeführt wird:
show loggingshow pfm location alladmin show diagn result loc 0/rsp0/cpu0 test 8 detailadmin show diagn result loc 0/rsp1/cpu0 test 8 detailadmin show diagn result loc 0/rsp0/cpu0 test 9 detailadmin show diagn result loc 0/rsp1/cpu0 test 9 detailadmin show diagn result loc 0/rsp0/cpu0 test 10 detailadmin show diagn result loc 0/rsp1/cpu0 test 10 detailadmin show diagn result loc 0/rsp0/cpu0 test 11 detailadmin show diagn result loc 0/rsp1/cpu0 test 11 detailshow controller fabric fia link-status locationshow controller fabric fia link-status locationshow controller fabric fia bridge sync-status locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 1 locationshow controller fabric ltrace crossbar locationshow controller fabric ltrace crossbar locationshow tech fabric locationshow tech fabric locationfile
Nützliche Diagnosebefehle
Nachfolgend finden Sie eine Liste von Befehlen, die für Diagnosezwecke nützlich sind:
show diagnostic ondemand settingsshow diagnostic content location < loc >show diagnostic result location < loc > [ test {id|id_list|all} ] [ detail ]show diagnostic statusadmin diagnostic start location < loc > test {id|id_list|test-suite}admin diagnostic stop location < loc >- Admin Diagnostic on Demand Iterationen < Iterationsanzahl >
admin diagnostic ondemand action-on-failure {continue failure-count|stop}- admin-config#
[ no ] diagnostic monitor location < loc > test {id | test-name} [disable] - admin-config#
[ no ] diagnostic monitor interval location < loc > test {id | test-name} day hour:minute:second.millisec - admin-config#
[ no ] diagnostic monitor threshold location < loc > test {id | test-name} failure count
Schlussfolgerung
Ab dem Zeitrahmen von Cisco IOS XR Software, Version 4.3.4, werden die meisten Probleme im Zusammenhang mit Datenpfadfehlern in der Einstiegsstruktur behoben. Bei Routern, die von der Cisco Bug-ID CSCuj10837 und der Cisco Bug-ID CSCul39674 betroffen sind, laden Sie die ersetzende SMU für die Cisco Bug-ID CSCul39674, um Fabric Link-Umschulungen zu vermeiden.
Das Plattform-Team hat eine hochmoderne Fehlerbehebung installiert, sodass der Router bei einem wiederherstellbaren Datenpfad-Fehler in Sekundenbruchteilen wiederhergestellt werden kann. Dieses Dokument wird jedoch empfohlen, um dieses Problem zu verstehen, auch wenn kein solcher Fehler festgestellt wird.
Anhang
NP-Loopback-Diagnosepfad
Die Diagnoseanwendung, die auf der Linecard-CPU ausgeführt wird, verfolgt den Zustand jedes NP, indem sie den Betriebsstatus des NP regelmäßig überprüft. Ein Paket wird von der Linecard-CPU eingekoppelt, die an den lokalen NP gerichtet ist. Der NP sollte sich zurückschleifen und zur Linecard-CPU zurückkehren. Jeder Verlust solcher periodischer Pakete wird mit einer Plattform-Protokollmeldung gekennzeichnet. Hier ein Beispiel für eine solche Nachricht:
LC/0/7/CPU0:Aug 18 19:17:26.924 : pfm_node[182]:
%PLATFORM-PFM_DIAGS-2-LC_NP_LOOPBACK_FAILED : Set|online_diag_lc[94283]|
Line card NP loopback Test(0x2000006)|link failure mask is 0x8
Diese Protokollmeldung bedeutet, dass dieser Test das Loopback-Paket vom NP3 nicht empfangen hat. Die Maske für den Verbindungsausfall ist 0x8 (Bit 3 ist festgelegt), was auf einen Ausfall zwischen der Linecard-CPU für Steckplatz 7 und NP3 in Steckplatz 7 hinweist.
Sammeln Sie die Ausgabe der folgenden Befehle, um weitere Details zu erhalten:
admin show diagnostic result location 0//cpu0 test 9 detail show controllers NP counter NP<0-3> location 0//cpu0
Fabric-Debugbefehle
Die in diesem Abschnitt aufgeführten Befehle gelten für alle Trident-basierten Line Cards sowie für die Typhoon-basierte 100GE Line Card. Der Bridge FPGA ASIC ist auf Typhoon-basierten Line Cards (mit Ausnahme der 100GE Typhoon-basierten Line Cards) nicht vorhanden. Die show controller fabric fia bridge Typhoon-basierte Line Cards sind von diesen Befehlen ausgenommen, mit Ausnahme der 100GE-Versionen.
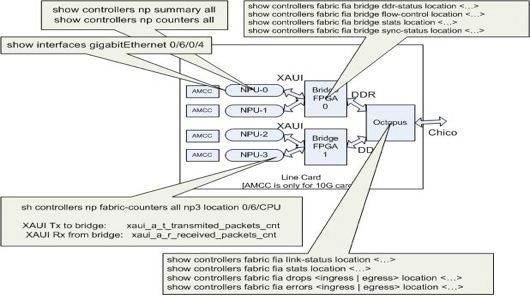
Diese bildliche Darstellung hilft, jeden show-Befehl der Position im Datenpfad zuzuordnen. Verwenden Sie diese Befehle zum Anzeigen, um Paketverluste und -fehler zu isolieren.
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
2.0 |
26-Jun-2023 |
Abschnitt für Verbesserungen der automatischen Wiederherstellung für Cisco Bug-ID CSCuc04493 aktualisiert und FAQ-Abschnitt aktualisiert. |
1.0 |
29-Oct-2013 |
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Mahesh ShirshyadCisco TAC Engineer
- David PowersCisco TAC Engineer
- Jean-Christophe RodeCisco TAC Engineer
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)