ASR 9000 nV-Declusterverfahren
Download-Optionen
-
ePub (826.1 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
In diesem Dokument werden einige der nV-Cluster-Funktionen der ASR Serie 9000 beschrieben und es wird beschrieben, wie die Cluster-Trennung durchgeführt wird.
Das Verfahren wurde in realen Umgebungen mit Cisco Kunden getestet, die sich bereits für den in diesem Dokument beschriebenen Entclusterungsprozess entschieden haben.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen:
- IOS XR
- ASR 9000-Plattform
- nV-Cluster-Funktion
Verwendete Komponenten
Die Informationen in diesem Dokument basieren auf der ASR 9000-Plattform mit IOS XR 5.x.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
Die Produktgeschäftseinheit (Product Business Unit, BU) kündigte das Ende des Vertriebszeitraums (End-of-Sale, EOS) für nV-Cluster auf der ASR 9000-Plattform an: Ankündigung des Vertriebsendes und des Produktlebenszyklusendes für den Cisco nV-Cluster
Wie Sie in der Ankündigung lesen können, ist der 15. Januar 2018 der letzte Tag, an dem dieses Produkt bestellt werden kann, und die letzte unterstützte Version für nV-Cluster ist IOS-XR 5.3.x.
Die Meilensteine, die Sie beachten sollten, sind in dieser Tabelle aufgelistet:

ASR9k nV-Cluster - Grundlagen und Überlegungen
In diesem Abschnitt soll eine kurze Aktualisierung der Cluster-Konfigurationen und -Konzepte beschrieben werden, die für das Verständnis der nächsten Abschnitte dieses Dokuments erforderlich sind.

Ethernet Out of Band Channel (EOBC)
Der Ethernet-Out-of-Band-Kanal erweitert die Kontrollebene zwischen den beiden ASR9k-Chassis und besteht im Idealfall aus vier Interconnects, die ein Mesh zwischen Route Switch Processor (RSP) mit unterschiedlichen Chassis bilden. Diese Konfiguration bietet zusätzliche Redundanz beim Ausfall der EOBC-Verbindung. Das Unidirectional Link Detection Protocol (UDLD) stellt eine bidirektionale Datenweiterleitung sicher und erkennt Verbindungsausfälle schnell. Eine Fehlfunktion aller EOBC-Verbindungen hat schwerwiegende Auswirkungen auf das Cluster-System und kann schwerwiegende Folgen haben, die später im Abschnitt Split Node Scenarios beschrieben werden.
Inter-Rack-Verbindungen (IRL)
Die Rack-Verbindungen erweitern die Datenebene zwischen den beiden ASR9k-Chassis. Im Idealfall werden Pakete nur von Protokoll-Punt und Protokoll-Injections über die IRL geleitet, mit Ausnahme von Single-Homed-Diensten oder bei Netzwerkausfällen. Theoretisch sind alle Endsysteme dual-homed und verfügen über eine Verbindung zu beiden ASR9K-Chassis. Ähnlich wie bei den EOBC-Verbindungen wird auch UDLD auf der IRL ausgeführt, um die bidirektionale Weiterleitungsintegrität der Verbindungen zu überwachen.
Ein IRL-Grenzwert kann definiert werden, um beispielsweise zu verhindern, dass überlastete IRLs Pakete bei einem LC-Ausfall verwerfen. Wenn die Anzahl der IRL-Verbindungen unter den konfigurierten Grenzwert für dieses Chassis fällt, werden alle Schnittstellen des Chassis aufgrund eines Fehlers deaktiviert und deaktiviert. Dadurch wird das betroffene Chassis isoliert, und es wird sichergestellt, dass der gesamte Datenverkehr durch das andere Chassis fließt.
Hinweis: Die Standardkonfiguration entspricht nv edge data minimum 1 backup-rack-interfaces. Das bedeutet, dass, wenn sich kein IRL im Weiterleitungsstatus befindet, der DSC (Designated Shelf Controller) für die Sicherung isoliert wird.
Szenarien für geteilte Knoten
In diesem Unterabschnitt finden Sie die verschiedenen Fehlerszenarien, die bei der Behandlung von ASR9k-Clustern auftreten können:
IRL Down
Dies ist das einzige Split-Node-Szenario, das während des Declusterns erwartet werden kann, oder wenn eines der Chassis unter den IRL-Schwellenwert fällt und infolgedessen isoliert wird.
EOBC Down
Die beiden Chassis des ASR9k können ohne die erweiterte Kontrollebene, die von den EOBC-Verbindungen bereitgestellt wird, nicht als Einheit agieren. Es gibt regelmäßige Beacons, die über die IRL-Verbindungen ausgetauscht werden, sodass jedes Chassis erkennt, dass das andere Chassis aktiv ist. Folglich wird eines der Chassis, in der Regel das Chassis mit dem Backup-DSC, außer Betrieb genommen und neu gestartet. Das Backup-DSC-Gehäuse bleibt in der Bootschleife, solange es die Beacons des Primary-DSC-Gehäuses über die IRL empfängt.
Split Brain
Im Split Brain-Szenario sind die IRL- und EOBC-Verbindungen ausgefallen, und jedes Chassis deklariert sich als Primary-DSC. Benachbarte Netzwerkgeräte erkennen plötzlich doppelte Router-IDs für IGP und BGP, was schwerwiegende Probleme im Netzwerk verursachen kann.
Pakete
Viele Kunden verwenden Edge- und Core-Pakete, um die Einrichtung des ASR9K-Clusters zu vereinfachen und in Zukunft Bandbreitenerweiterungen zu ermöglichen. Dies kann beim Entclustern zu Problemen führen, da verschiedene Paketmitglieder eine Verbindung mit verschiedenen Chassis herstellen. Diese Ansätze sind möglich:
- Erstellen Sie neue Pakete für alle Schnittstellen, die an Chassis 1 (Backup-DSC) angeschlossen sind.
- Multichassis Link Aggregation (MCLAG)
L2-Domäne
Eine Aufspaltung des Clusters könnte die L2-Domäne möglicherweise trennen, wenn es im Zugriff keinen Switch gibt, der die beiden eigenständigen Chassis miteinander verbindet. Um keinen Datenverkehr in schwarzen Löchern zu blockieren, müssen Sie die L2-Domäne erweitern. Dies ist möglich, wenn Sie L2-Verbindungen auf der vorherigen IRL konfigurieren, Pseudo-Wires (PW) zwischen den Chassis verwenden oder eine andere L2VPN-Technologie (Virtual Private Network) für Layer 2 verwenden. Wenn sich die Bridge-Domänen-Topologie mit der Entclusterung ändert, denken Sie an die mögliche Loop-Erstellung, wenn Sie die gewünschte L2VPN-Technologie auswählen.
Statisches Routing beim Zugriff auf eine Bridge-Group Virtual Interface (BVI)-Schnittstelle am ASR9K-Cluster wird wahrscheinlich zu einer Hot Standby Router Protocol (HSRP)-basierten Lösung, bei der die vorherige BVI-IP-Adresse als virtuelle IP verwendet wird.
Single-Homed Services
Bei Single-Homed-Diensten kommt es während des Entclusterungsvorgangs zu längeren Ausfallzeiten.
Managementzugriff
Während des Entclusterungsvorgangs gibt es eine kurze Zeit, in der beide Chassis isoliert sind, zumindest beim Übergang von statischem Routing (BVI) zu statischem Routing (HSRP), um ein unerwartetes und asymmetrisches Routing zu vermeiden.
Bevor Sie sich selbst ausschalten, müssen Sie überprüfen, wie die Konsole und der Out-of-Band-Managementzugriff funktionieren.
ASR9000-Entclusterungsverfahren
Der Ausgangsstatus
Es wird angenommen, dass Chassis 0 im ursprünglichen Zustand aktiv ist, während Chassis 1 ein Backup ist (der Einfachheit halber). In der Praxis könnte es umgekehrt sein, oder sogar RSP1 im Chassis 0 könnte aktiv sein.
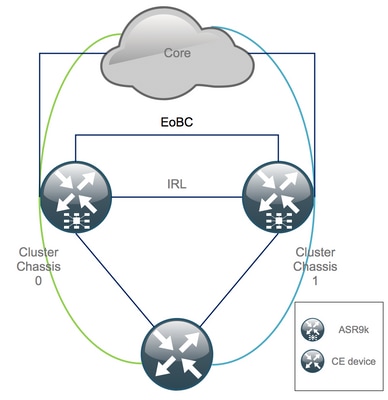
Checkliste vor Wartungsfenster (MW)
- Vorbereiten der neuen ASR9K-Konfigurationen für Chassis 0 und Chassis 1 (Admin-Config + Config)
- Bereiten Sie die neuen Systemkonfigurationen vor (Customer Edge (CE), Firewall (FW), Switches usw.).
- Vorbereiten der neuen Core-Systemkonfigurationen (P-Knoten, Provider Edge (PE)-Knoten, Routen-Reflektor (RR) usw.)
- Überprüfen Sie die neuen Konfigurationen, speichern Sie sie auf dem Gerät und remote auf einem Trivial File Transfer Protocol (TFTP)-Server.
- Erreichbarkeitstests definieren, die vor/während/nach der MW durchgeführt werden müssen.
- Sammeln Sie die Kontrollebenenausgaben für Interior Gateway Protocol (IGP), Border Gateway Protocol (BGP), Multiprotocol Label Switching (MPLS), Label Distribution Protocol (LDP) usw. für einen Vergleich vor/nach dem Vergleich.
- Öffnen Sie eine proaktive Serviceanfrage bei Cisco.
Schritt 1: Melden Sie sich beim ASR9000-Cluster an, und überprüfen Sie die aktuelle Konfiguration
1. Überprüfen Sie den Speicherort von Primary (Primär) - Backup-Gehäuse. In diesem Beispiel ist das primäre Chassis 0:
RP/0/RSP0/CPU0:Cluster(admin)# show dsc --------------------------------------------------------- Node ( Seq) Role Serial# State --------------------------------------------------------- 0/RSP0/CPU0 ( 1279475) ACTIVE FOX1441GPND PRIMARY-DSC <<< Primary DSC in Ch1 0/RSP1/CPU0 ( 1223769) STANDBY FOX1432GU2Z NON-DSC 1/RSP0/CPU0 ( 0) ACTIVE FOX1432GU2Z BACKUP-DSC 1/RSP1/CPU0 ( 1279584) STANDBY FOX1441GPND NON-DSC
2. Überprüfen Sie, ob alle Line Cards (LC)/RSPs den Status "IOS XR RUN" aufweisen:
RP/0/RSP0/CPU0:Cluster# sh platform Node Type State Config State ----------------------------------------------------------------------------- 0/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 0/RSP1/CPU0 A9K-RSP440-TR(Standby) IOS XR RUN PWR,NSHUT,MON 0/0/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 0/0/0 A9K-MPA-4X10GE OK PWR,NSHUT,MON 0/0/1 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/1/CPU0 A9K-MOD80-TR IOS XR RUN PWR,NSHUT,MON 0/1/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/2/CPU0 A9K-40GE-E IOS XR RUN PWR,NSHUT,MON 1/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 1/RSP1/CPU0 A9K-RSP440-SE(Standby) IOS XR RUN PWR,NSHUT,MON 1/1/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/1/1 A9K-MPA-2X10GE OK PWR,NSHUT,MON 1/2/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/2/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 1/2/1 A9K-MPA-4X10GE OK PWR,NSHUT,MON
Schritt 2: IRL-Mindestschwellenwert für das Standby-Chassis konfigurieren
Das Standby-Gehäuse ist das Gehäuse mit dem BACKUP-DSC und wird außer Betrieb genommen und zuerst entclustert. In diesem Beispiel befindet sich der BACKUP-DSC im Gehäuse 1.
Wenn bei dieser Konfiguration die Anzahl der IRLs unter den konfigurierten Mindestschwellenwert (in diesem Fall 1) fällt, werden alle Schnittstellen am angegebenen Rack (in diesem Fall Backup-Rack - Chassis 1) heruntergefahren:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data min 1 spec rack 1 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
Schritt 3: Fahren Sie alle IRL herunter, und überprüfen Sie, ob die Schnittstellen zur Fehlerdeaktivierung in Chassis 1 fehlerhaft sind.
1. Schließen Sie alle vorhandenen IRL. In diesem Beispiel wird eine manuelle Schnittstellenabschaltung in beiden Chassis angezeigt (aktiv Ten0/x/x/x und Standby Ten1/x/x/x):
RP/0/RSP0/CPU0:Cluster(config)# interface Ten0/x/x/x shut interface Ten0/x/x/x shut […] interface Ten1/x/x/x shut interface Ten1/x/x/x shut […] commit
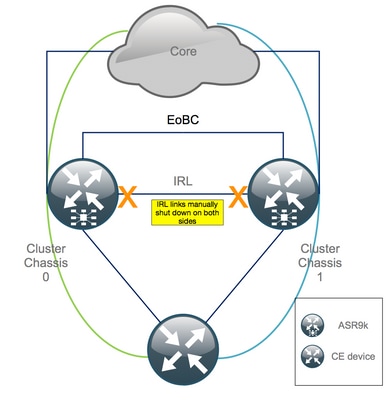
2. Überprüfen Sie, ob alle konfigurierten IRLs ausgefallen sind:
RP/0/RSP0/CPU0:Cluster# show nv edge data forwarding location
Ein Beispiel für <location> ist 0/RSP0/CPU0.
Nach dem Abschalten aller IRLs muss das Chassis 1 vollständig von der Datenebene isoliert werden, indem alle externen Schnittstellen in den Status "error-disabled" (Fehlerdeaktiviert) versetzt werden.
3. Stellen Sie sicher, dass alle externen Schnittstellen in Chassis 1 deaktiviert sind und der gesamte Datenverkehr durch Chassis 0 fließt:
RP/0/RSP0/CPU0:Cluster# show error-disable
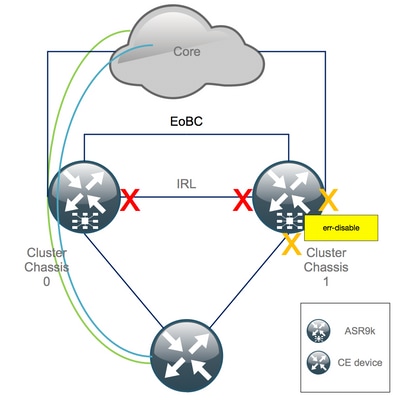
Schritt 4: Alle EOBC-Verbindungen herunterfahren und ihren Status überprüfen

1. Schließen Sie die EOBC-Verbindungen auf allen RSPs:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge control control-link disable 0 loc 0/RSP0/CPU0 nv edge control control-link disable 1 loc 0/RSP0/CPU0 nv edge control control-link disable 0 loc 1/RSP0/CPU0 nv edge control control-link disable 1 loc 1/RSP0/CPU0 nv edge control control-link disable 0 loc 0/RSP1/CPU0 nv edge control control-link disable 1 loc 0/RSP1/CPU0 nv edge control control-link disable 0 loc 1/RSP1/CPU0 nv edge control control-link disable 1 loc 1/RSP1/CPU0 commit
2. Stellen Sie sicher, dass alle EOBC-Verbindungen ausgefallen sind:
RP/0/RSP0/CPU0:Cluster# show nv edge control control-link-protocols location 0/RSP0/CPU0
Danach sind die Cluster-Chassis hinsichtlich der Kontroll- und Datenebene vollständig voneinander isoliert. Chassis 1 hat alle Links im Status "err-disable".
Hinweis: Ab sofort müssen Konfigurationen auf Chassis 1 über die RSP-Konsole vorgenommen werden und betreffen nur noch das lokale Chassis!
Schritt 5: Anmelden beim aktiven RSP von Chassis 1 und Entfernen der alten Konfiguration
Löschen Sie die vorhandene Konfiguration für Chassis 1:
RP/1/RSP0/CPU0:Cluster(config)# commit replace RP/1/RSP0/CPU0:Cluster(admin-config)# commit replace
Hinweis: Sie müssen zuerst die Konfiguration für die aktuelle Konfiguration ersetzen und erst danach die laufende Admin-Konfiguration löschen. Dies liegt daran, dass das Entfernen des IRL-Grenzwerts in der admin-Konfiguration "no shutdown" für alle externen Schnittstellen bewirkt. Dies kann zu Problemen aufgrund doppelter Router-IDs usw. führen.
Schritt 6: Booten von Chassis 1 in den ROMMON-Modus
1. Konfigurieren Sie das Register so, dass es in ROMMON startet:
RP/1/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Überprüfen Sie die Boot-Variablen:
RP/1/RSP0/CPU0:Cluster(admin)# show variables boot
3. Laden Sie beide RSPs des Chassis 1 neu:
RP/1/RSP0/CPU0:Cluster# admin reload location all
Nach diesem Schritt bootet Chassis 1 normalerweise in ROMMON.
Schritt 7. Cluster-Variablen auf Chassis 1 in ROMMON auf beiden RSPs aufheben
Warnung: Außendiensttechniker müssen alle EOBC-Verbindungen entfernen, bevor Sie fortfahren.
Tipp: Es gibt auch eine Alternative zum Festlegen von System-Cluster-Variablen. Abschnitt prüfen Anlage 2: Cluster-Variable festlegen, ohne das System in ROM zu booten.
1. Das Standardverfahren erfordert das Anschließen des Konsolenkabels an den aktiven RSP am Gehäuse 1 und das Entfernen und Synchronisieren der Cluster-ROMMON-Variable:
unset CLUSTER_RACK_ID sync
2. Setzen Sie die Konfigurationsregister auf 0x102 zurück:
confreg 0x102 reset
Der aktive RSP ist festgelegt.
3. Verbinden Sie das Konsolenkabel mit dem Standby-RSP des Gehäuses 1. Im Idealfall haben alle 4 RSP des Clusters Konsolenzugriff während des Wartungsfensters.
Hinweis: Die in diesem Schritt beschriebenen Aktionen müssen auf beiden RSPs des Chassis 1 durchgeführt werden. Der aktive RSP muss zuerst gestartet werden.
Schritt 8: Booten des Chassis 1 als eigenständiges System und entsprechende Konfiguration
Im Idealfall werden die neue Konfiguration oder mehrere Konfigurationsbausteine auf jedem ASR9k-Chassis gespeichert und nach dem Entclustern geladen. Die richtige Konfigurationssyntax muss zuvor in der Übung getestet werden. Falls nicht, konfigurieren Sie zuerst die Konsolen- und MGMT-Schnittstellen, bevor Sie die Konfiguration für Chassis 1 abschließen. Verwenden Sie dazu entweder Copy and Paste on Virtual Teletype (VTY), oder laden Sie die Konfiguration remote von einem TFTP-Server.
Hinweis: Die Befehle load config und commit halten alle Schnittstellen heruntergefahren, was einen kontrollierten Service-Ramp-up ermöglicht. load config und commit replace, ersetzt die Konfiguration vollständig und aktiviert die Schnittstellen. Es wird daher empfohlen, die Lastkonfiguration und den Commit zu verwenden.
Anpassung der Konfiguration angeschlossener Endsysteme (FW, Switches usw.) und Core-Geräte (P, PE, RR usw.) an Chassis 1
Schritt 9. Wiederherstellung der Kerndienste in Chassis 1
- Zuerst die Kernschnittstellen manuell wieder ausschalten.
- Überprüfung von LDP, Intermediate System to Intermediate System (IS-IS oder ISIS), BGP-Adjacencies/Peerings
- Überprüfen Sie die Routing-Tabellen, und stellen Sie sicher, dass alle Präfixe ausgetauscht wurden.
Warnung: Achten Sie auf Timer wie das ISIS Overload (OL)-Bit, HSRP-Verzögerung, BGP-Update-Verzögerung usw., bevor Sie zum Failover übergehen!
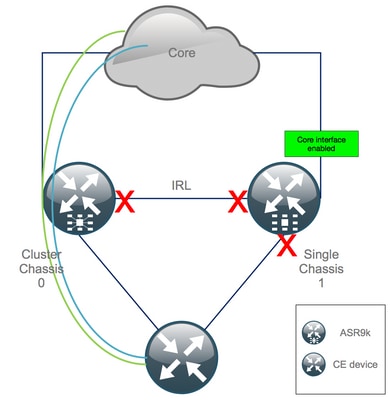
Schritt 10. Failover: Anmeldung beim aktiven RSP von Chassis 0 und Versetzen aller Schnittstellen in den Fehlerdeaktivierungsstatus
Vorsicht: Die nächsten Schritte führen zu Serviceunterbrechungen. Southbound-Schnittstellen für Chassis 1 sind weiterhin deaktiviert, während Chassis 0 isoliert ist

Die Standardhaltezeit beträgt 180 s (3 x 60 s) und stellt den schlechtesten Fall für BGP-Konvergenz dar. Es gibt verschiedene Designoptionen und BGP-Funktionen, die eine wesentlich schnellere Konvergenz ermöglichen, z. B. BGP Next-Hop Tracking. Angenommen, es gibt im Kern verschiedene Drittanbieter, die sich anders verhalten als Cisco IOS XR, Sie müssen die BGP-Konvergenz schließlich manuell beschleunigen, indem Sie die BGP-Nachbarschaften zwischen Chassis 0 und RR oder ähnlich schließen, bevor Sie das Failover auslösen:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data minimum 1 specific rack 0 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
Da alle IRL ausgefallen sind, muss Chassis 0 isoliert werden, und alle externen Schnittstellen müssen in den Status "error-disabled" (Fehlerdeaktivierung) versetzt werden.
Stellen Sie sicher, dass alle externen Schnittstellen des Chassis 0 deaktiviert sind:
RP/0/RSP0/CPU0:Cluster# show error-disable
Chassis 1 wurde als eigenständiges Gerät neu konfiguriert, sodass keine Schnittstellen erneut deaktiviert werden dürfen. Chassis 1 muss lediglich noch die Schnittstellen am Edge aktivieren.
Schritt 11. Südseite von Chassis 1 wiederherstellen
1. nicht alle Zugriffsschnittstellen herunterfahren.

Bewahren Sie die Verbindung (vorherige IRL) vorerst auf.
2. Überprüfen Sie IGP- und BGP-Adjacencies/Peering/DB. Während die IGPs und das BGP konvergieren, erwarten Sie einige Datenverluste in Ihren Pings vom Remote-PE.
Schritt 12: Melden Sie sich beim aktiven RSP von Chassis 0 an, und entfernen Sie die Konfiguration.
Löschen Sie die vorhandene Konfiguration auf dem aktiven Chassis:
RP/0/RSP0/CPU0:Cluster(config)# commit replace RP/0/RSP0/CPU0:Cluster(admin-config)# commit replace
Hinweis: Sie müssen zuerst die Konfiguration für die aktuelle Konfiguration ersetzen und erst danach die admin running-configuration löschen. Dies liegt daran, dass das Entfernen des IRL-Grenzwerts in der admin-Konfiguration nicht alle externen Schnittstellen ausschaltet. Dies kann zu Problemen aufgrund doppelter Router-IDs usw. führen.
Schritt 13: Booten von Chassis 0 in ROMMON
1. Konfigurieren Sie das Register so, dass es in ROMMON startet:
RP/0/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Überprüfen Sie die Boot-Variablen:
RP/0/RSP0/CPU0:Cluster# admin show variables boot
3. Laden Sie beide RSPs des Standby-Chassis neu:
RP/0/RSP0/CPU0:Cluster# admin reload location all
Nach diesem Schritt bootet Chassis 0 normalerweise im ROMMON-Modus.
Schritt 14: Cluster-Variablen auf Chassis 0 in ROMMON auf beiden RSPs aufheben
1. Verbinden Sie das Konsolenkabel mit dem aktiven RSP im Chassis 0.
2. Cluster-ROMMON-Variable entfernen und synchronisieren:
unset CLUSTER_RACK_ID sync
3. Setzen Sie die Konfigurationsregister auf 0x102 zurück:
confreg 0x102 reset
Der aktive RSP ist festgelegt.
4. Verbinden Sie das Konsolenkabel mit dem Standby-RSP des Chassis 0.
Hinweis: Die in diesem Schritt beschriebenen Aktionen müssen auf beiden RSPs des Chassis 1 durchgeführt werden. Der aktive RSP muss zuerst gestartet werden.
Schritt 15: Booten des Chassis 0 als eigenständiges System und entsprechende CO-Konfiguration
Im Idealfall werden die neue Konfiguration oder mehrere Konfigurationsbausteine auf jedem ASR9k-Chassis gespeichert und nach dem Entclustern geladen. Die richtige Konfigurationssyntax muss zuvor in der Übung getestet werden. Falls nicht, konfigurieren Sie zuerst die Konsolen- und MGMT-Schnittstellen, bevor Sie die Konfiguration auf Chassis 0 entweder über VTY (Kopieren und Einfügen) abschließen oder die Konfiguration remote von einem TFTP-Server laden.
Hinweis: Die Befehle load config und commit halten alle Schnittstellen heruntergefahren, was einen kontrollierten Service-Ramp-up ermöglicht. load config und commit replace, ersetzt die Konfiguration vollständig und aktiviert die Schnittstellen. Es wird daher empfohlen, die Lastkonfiguration und den Commit zu verwenden.
Anpassung der Konfiguration angeschlossener Endsysteme (FW, Switches usw.) und Core-Geräte (P, PE, RR usw.) an Chassis 0
Schritt 16: Wiederherstellung der Kerndienste in Chassis 0
- Zuerst die Kernschnittstellen manuell wieder ausschalten.
- Überprüfung von LDP-, ISIS-, BGP-Adjacencies/Peerings
- Überprüfen Sie die Routing-Tabellen, und stellen Sie sicher, dass alle Präfixe ausgetauscht wurden.
Warnung: Achten Sie auf Timer wie ISIS OL-Bit, HSRP-Verzögerung, BGP-Update-Verzögerung usw., bevor Sie zum Failover übergehen!
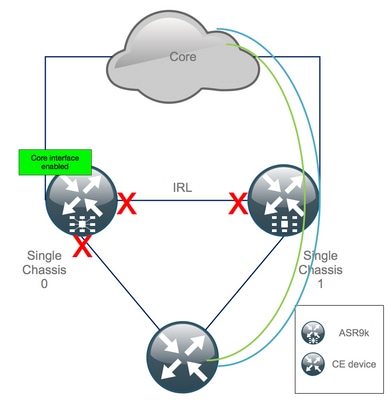
Schritt 17: Südseite von Chassis 0 wiederherstellen
1. nicht alle Zugriffsschnittstellen herunterfahren.
2. Überprüfung von IGP- und BGP-Adjacencies/Peers/DB
3. Stellen Sie sicher, dass die Chassis-übergreifende Verbindung (vorherige IRL) aktiviert ist, falls für die L2-Erweiterung erforderlich usw.

Anhang 1: Konfiguration mit einem Chassis
Allgemeine Konfigurationsänderungen
Diese Router-Konfiguration muss in einem der folgenden Chassis geändert werden:
- Loopback-Schnittstellenadressen
- Nummerierung der Schnittstellen (z. B. Te1/x/x/x -> Te0/x/x/x).
- Schnittstellenbeschreibungen
- Schnittstellenadressierung (bei Aufteilung bestehender Pakete).
- Neue BVIs (wenn die L2-Domäne dual-homed ist)
- L2-Erweiterung (wenn die L2-Domäne dual-homed ist).
- HSRP für statisches Routing im Access Switch
- BGP/Open Shortest Path First (OSPF)/LDP-Router-ID
- BGP-Route-Distinguisher.
- BGP-Peerings
- OSPF-Netzwerktyp.
- Simple Network Management Protocol (SNMP)-IDs usw.
- Zugriffskontrollliste (ACL), Präfix-Sets, Routing-Protokoll für LLN (Low-Power and Lossy Networks, RPL) usw.
- Hostname.
Paketübersicht
Stellen Sie sicher, dass alle Pakete geprüft und auf die neue duale PE-Konfiguration angewendet werden. Möglicherweise benötigen Sie keine Pakete mehr und die Dual-Homed-Customer-Premises Equipment (CPE)-Geräte passen in Ihre Konfiguration, oder Sie benötigen MCLAG auf PE-Geräten und behalten die Pakete für CPEs bei.
Anhang 2: Festlegen einer Cluster-Variablen ohne Starten des Systems in ROMMON
Es gibt auch eine Alternative zum Festlegen der Clustervariablen. Cluster-Variablen können mit diesem Verfahren im Voraus festgelegt werden:
RP/0/RSP0/CPU0:xr#run Wed Jul 5 10:19:32.067 CEST # cd /nvram: # ls cepki_key_db classic-rommon-var powerup_info.puf sam_db spm_db classic-public-config license_opid.puf redfs_ocb_force_sync samlog sysmgr.log.timeout.Z # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , CLUSTER_RACK_ID = 1, TFTP_RETRY_COUNT = 4, confreg = 0x2102 # nvram_rommonvar CLUSTER_RACK_ID 0 <<<<<<< to set CLUSTER_RACK_ID=0 # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , TFTP_RETRY_COUNT = 4, CLUSTER_RACK_ID = 0, confreg = 0x2102 #exit RP/0/RSP0/CPU0:xr#
Laden Sie den Router neu, und starten Sie ihn als Standalone-Box. Mit diesem Schritt können Sie überspringen, den Router von ROMMON aus zu starten.
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
05-Apr-2019 |
Erstveröffentlichung |
Beigetragen von
- Robert VerlicAdvanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)