Timeouts für Astro/Lemans/NiceR bei Catalyst Switches der Serien 4000 und 4500 und Fehlerbehebung
Inhalt
Einführung
Die Switch-Serie Catalyst 4000/4500 verwendet ein Stub-ASIC-Design in der Switch-Architektur. Der Switch verwaltet diese Linecard-Stub-ASICs (Astro/Leman/NiceR) über ein internes Verwaltungsprotokoll. Wenn diese internen Verwaltungsanforderungen und -antworten verloren gehen oder sich verzögern, werden Konsolen- und Syslog-Meldungen generiert. Da die Gründe für diese Kommunikationsverluste variieren, ist die Ursache bei diesen Fehlermeldungen nicht offensichtlich.
Dieses Dokument soll Ihnen helfen, die auf der Cat4000-Plattform generierte Astro/Leman/Nicer-Timeout-Meldung zu verstehen und mithilfe des Cisco TAC zu beheben. Künftige Versionen von CatOS und Cisco IOS® bieten verbesserte Fehlermeldungen und identifizieren, wenn möglich, die Ursache des Problems.
Wenn ein ASIC-Timeout (Astro/Lemans/Nicer) auftritt, werden auf einem Catalyst 4000/4500-Switch auf CatOS-Basis ähnliche Meldungen gemeldet:
%SYS-4-P2_WARN: 1/Astro(4/3) - timeout occurred %SYS-4-P2_WARN: 1/Astro(4/3) - timeout is persisting
Bitte beachten Sie, dass der Wortlaut der Fehlermeldung je nach Softwareversion variieren kann. Astro, Lemans und Nicer beziehen sich auf verschiedene Stub-ASIC-Typen. Weitere Einzelheiten finden Sie im Abschnitt zur Hintergrundtheorie dieses Dokuments.
Bei Cisco IOS-basierten Supervisoren (Supervisor II+, III und IV) wird die Fehlermeldung wie folgt angezeigt:
%C4K_LINECARDMGMTPROTOCOL-4-INITIALTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - management request timed out. %C4K_LINECARDMGMTPROTOCOL-4-ONGOINGTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - consecutive management requests timed out.
Hinweis: Dieses Dokument behandelt hauptsächlich die Fehlerbehebung bei CatOS-basierten Supervisoren oder Switches. Einige der Informationen gelten für Cisco IOS-basierte Supervisor, wenn darauf hingewiesen wird.
Hinweis: Dieses Dokument behandelt auch Astro-Stub-ASIC, aber die meisten Abschnitte gelten für andere Stub-ASIC-Line Cards (Lemans und Nicer) und werden daher in den entsprechenden Abschnitten aufgeführt.
Nach dem Lesen dieses Dokuments verstehen die Leser Folgendes:
-
Die Funktion von Stub-ASICs in Catalyst 4000/4500.
-
Die Bedingungen, die zu Timeouts für interne Managementpakete führen können.
-
Die Schritte und Befehle, die bei der Behebung dieses Problems für das Cisco TAC erforderlich sind.
Die Abschnitte Astro Timeout und Fehlerbehebung enthalten Hintergrundinformationen und detaillierte Erläuterungen zu jedem Problem. Alternativ dazu können Sie direkt zum Abschnitt "Einfache Methoden zur Fehlerbehebung" in diesem Dokument springen.
Bevor Sie beginnen
Konventionen
Weitere Informationen zu Dokumentkonventionen finden Sie in den Cisco Technical Tips Conventions.
Voraussetzungen
Für dieses Dokument bestehen keine besonderen Voraussetzungen.
Verwendete Komponenten
Dieses Dokument ist spezifisch für Catalyst 4000/4500 Supervisor- oder Line Cards, die Stub-ASICs verwenden.
Hintergrundtheorie
Der ASIC der Astro-Stub bezieht sich auf die 10/100-Stub-ASICs, die eine Gruppe von acht benachbarten 10/100-Ports steuern, die über eine Gigabit-Bandbreitenverbindung mit der Backplane mit dem Supervisor kommunizieren (siehe Abbildung unten).
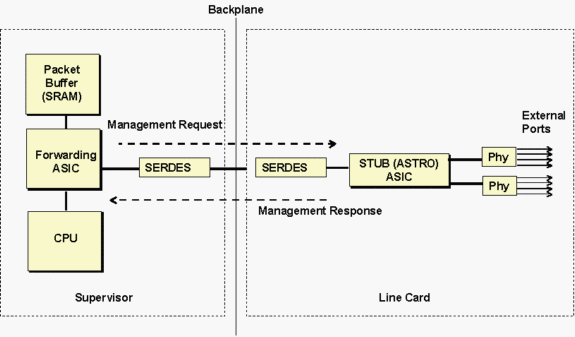
Die Supervisoren kommunizieren über die SERDES-Komponente (SERealizer-DESerializer) mit dem Line Card-Stub-ASIC. Auf der Supervisor-Seite befindet sich eine SERDES-Komponente, die mit der Backplane verbunden ist, und eine weitere SERDES-Komponente auf der Linecard für jeden Stub-ASIC für die Verbindung mit der Backplane.
Das obige Diagramm kann im Allgemeinen zur Fehlerbehebung bei verschiedenen Linecard-Typen verwendet werden. Die in den Timeout-Meldungen angegebene Stub-ASIC ist je nach Line Card-Typ unterschiedlich. Eine Liste der ASIC-Namen und deren Beschreibung finden Sie in der nachfolgenden Tabelle.
| Stub-ASICs | Beschreibung | Beispiel |
|---|---|---|
| Astro | 10/100-Controller-Stub ASIC mit 8 Ports | WS-X4148-RJ45V |
| NiceR | 1000-Controller-Stub ASIC mit 4 Ports | WS-X4418-GB(Ports 3-18) |
| Lemane | 10/100/1000-Controller-Stub mit 8 Ports, ASIC | WS-X448-GB-RJ |
Der interne Verwaltungsdatenverkehr fließt sowohl über die SERDES-Komponente als auch den normalen Datenverkehr. Der interne Verwaltungsdatenverkehr wird zum Lesen/Schreiben der Stub-ASIC- und Phy-Register verwendet. Zu den häufigsten Vorgängen gehören das Lesen des Linkstatus und Statistiken.
Einfache Fehlerbehebung
In den folgenden Abschnitten werden die Bedeutung und mögliche Ursachen von %SYS-4-P2_WARN erläutert: 1/(Stub)(module_number/) Stub_reference - Timeout ist bei der Catalyst Serie 4000/4500 aufgetreten.
Die Astro-Timeout-Meldungen (Stub) wurden der Softwareversion ab 6.2.3 und 6.3.1 hinzugefügt und später in 6.4.4 (CSCea73908) verbessert, um anzuzeigen, dass der Supervisor interne Managementkontrollpakete bei der Kommunikation mit dem Astro-Stub-ASIC auf 10/100-Linecards verloren hat. Es gibt mehrere Ursachen für diesen Kommunikationsverlust, wie im Abschnitt Fehlerbehebung unten ausführlich erläutert.
Das folgende Flussdiagramm zur Fehlerbehebung bietet eine schnelle und einfache Möglichkeit, das Problem zwischen den möglichen Ursachen zu isolieren:
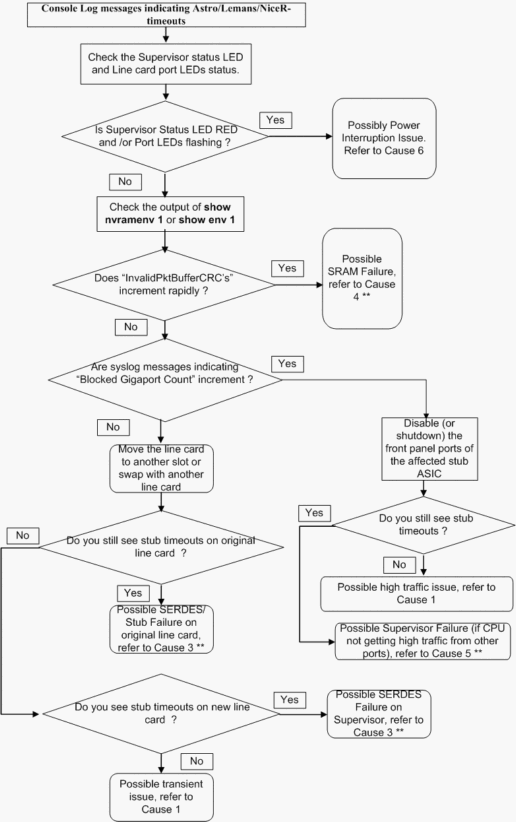
** Verschiedene Ursachen können ähnliche Symptome aufweisen. Wenden Sie sich für weitere Fehlerbehebung an das TAC.
ASIC-Timeouts (Astro/Lemans/NiceR)
Astro-/Lemans-/Nicer-Timeouts werden gemeldet, wenn die Supervisor-Software nicht mehrere interne Managementantworten von der Line Card Stub ASIC erhält. Dies kann geschehen, wenn:
-
Verwaltungsanfrage geht verloren oder verzögert
-
Management-Antwort geht verloren oder verzögert
Beim Warten auf die Managementpaketantwort wird eine Meldung ausgegeben, wonach ein Timeout aufgetreten ist... (Timeout aufgetreten..), sobald die Software zehnmal hintereinander abgelaufen ist. Die folgenden Zeitüberschreitungen führen zum Ausdruck "Konsekutivverwaltung ..." oder "..timeout persistent.." Nachrichten, abhängig von der Softwareversion.
Diese Protokollmeldung ist auf einmal pro 10 Minuten beschränkt. Die Paketweiterleitung an die betroffenen Stub-ASICs wird fortgesetzt, wenn Zeitüberschreitungen auftreten. Änderungen an der Link-/Auto-Geschwindigkeit/Duplex-Funktion werden jedoch nicht angezeigt, da die Software die Management-Paketantworten nicht erhält. Bei Zeitüberschreitungen wird auch die Aktualisierung der Datenverkehrsstatistiken für die Schnittstellengruppe betroffen.
Fehlerbehebung
Es gibt verschiedene Ursachen dafür, dass die Timeout-Meldungen Astro/Lemans/Nicer angezeigt werden. Jeder dieser Bereiche wird nachfolgend beschrieben.
Ursache 1: Hohe Datenverkehrslast, Layer-2-Schleife oder übermäßiger Netzwerkverkehr zu CPU
Folgendes kann STUB-Timeout-Bedingungen verursachen:
-
Netzwerkprobleme
-
Konfigurationsprobleme
-
Nachbarelemente
-
Andere Faktoren außerhalb eines Catalyst-Switches
Layer-2-Schleifen oder Broadcast-Stürme, die zu hoher Datenverkehrslast führen, können den Verlust von internen Management-Kontrollpaketen verursachen. Dies geschieht in der Regel, weil die CPU belegt ist (CPU-Hog) und ihre Warteschlangen nicht verarbeiten kann.
Der interne Verwaltungskontrolldatenverkehr führt den gleichen Datenpfad zum Supervisor wie der normale Datenverkehr vom Astro (oder einem anderen Stub-Chip). Daher können die Kontrollpakete aufgrund von Überlastung verloren gehen.
Mit der Behebung der Cisco Bug ID CSCea73908 (nur registrierte Kunden) wird die Zeitüberschreitung für interne Verwaltungsanfragen in CatOS Version 6.4(4) und höheren Versionen besser gehandhabt. Diese Erweiterung kann viele Zeitüberschreitungen bei vorübergehenden Kontrollpaketen verhindern, die durch CPU-Auslastung verursacht werden.
Aktion: Fehlerbehebung für die Layer-2-Schleife oder die Konfiguration ändern, um Datenverkehrsmuster zu beheben.
Problemumgehung: Verschieben Sie die Switch-Management-Schnittstelle (sc0) in ein VLAN für Nicht-Benutzerdatenverkehr auf CatOS-basierten Switches. Verwenden Sie den Befehl set interface sc0 <vlan-id>, um das VLAN der Schnittstelle sc0 zu verschieben.
Hinweis: Ab Cisco IOS 12.1(20)EW bieten Cisco IOS-basierte Supervisoren eine verbesserte Handhabung des internen Paketverwaltungsmechanismus durch die CPU. Diese Erweiterung trägt dazu bei, den Verlust von internen Managementkontrollpaketen aufgrund von versehentlichem Datenverkehr mit niedriger Priorität, der die CPU belastet, zu verhindern.
Lösung: Siehe Workaround oben.
Ursache 2: Halbes Duplex/Typ 1A-Kabel
Benutzerports an der Vorderseite werden im Halbduplex-Modus konfiguriert. Die Kollisionen des ausgehenden Datenverkehrs mit dem eingehenden Datenverkehr im Stub-ASIC können dazu führen, dass der Stub-Puffer sehr langsam abfließt. Dies kann dazu führen, dass der Supervisor tx-Warteschlangen füllt und neue interne Verwaltungsanfragen verworfen werden, was zu Timeout-Fehlermeldungen führt.
Ein Netzwerk mit Typ1A-Verkabelung kann dieses Problem ebenfalls verursachen. Wenn eine Workstation, die mit einem Typ1A Baluns mit einem RJ-45-Patch verbunden ist, getrennt wird, schleift der Balun intern zurück und veranlasst, dass der ausgehende Datenverkehr zurückkehrt. Diese Situation simuliert die Verbindung eines externen Loopbacks am Port an der Vorderseite. Bevor der Port in den Blockierungsstatus wechselt, wird ausgehender Datenverkehr zurück in den Switch geleitet. Dies kann dazu führen, dass die Stub-Puffer je nach Datenverkehrsrate überlaufen.
Aktion: Problemumgehung anzeigen.
Problemumgehung: Vermeiden Sie Halbduplex-Konfigurationen. Vermeiden Sie es, bei einem Kabel vom Typ 1A das RJ-45-Patchkabel vom Typ 1A Balun auszustecken, um die Bildung eines internen Loopbacks im Balun zu vermeiden.
Lösung: Problemumgehung anzeigen.
Ursache 3: SERDES-Komponentenfehler
Wenn die Fehler nur auf einem Astro (oder einem anderen Stub-ASIC) auf einem Modul auftreten und keine Layer-2-Schleife auftritt, ist das Problem höchstwahrscheinlich eine fehlerhafte SERDES-Komponente auf dem Supervisor oder der Line Card. Wenn die Fehlermeldung z. B. immer auf Astro 4 auf Modul 3 angezeigt wird, ist entweder die SERDES-Komponente auf Modul 3 oder die SERDES-Komponente auf dem Supervisor defekt.
%SYS-4-P2_WARN: 1/Astro(3/4) – timeout occurred
In der obigen Fehlermeldung bezieht sich die Nummer "4" in Klammern auf die Astro-Nr. und nicht auf den tatsächlichen Port 3/4. Diese Nummer bezieht sich auf eine Gruppe von acht Ports (3/33-3/40), da es sich um das vierte Astro auf Modul 3 handelt.
Eine fehlerhafte SERDES-Komponente kann zu intermittierender Konnektivität für die Steuerung des Datenverkehrs und des Datenverkehrs zum Astro/Lemans/NiceR führen, was zu Timeouts führt. In der Regel wird die Fehlermeldung jedoch fortlaufend angezeigt, wenn der SERDES fehlerhaft ist.
Aktion: So bestimmen Sie, welche SERDES (Supervisor oder Linecard) fehlerhaft sind:
-
Setzen Sie die Linecard in einen freien Steckplatz im Gehäuse oder in ein anderes Chassis ein. Wenn ein freier Steckplatz verfügbar ist, wechseln Sie die Steckplätze durch ein zweifelsfrei funktionierendes Modul.
-
Wenn Sie weiterhin Astro/Lemans/Nicer-Zeitüberschreitungen auf dem gleichen Astro/Lemans/Nicer im neuen Steckplatz haben, dann sind höchstwahrscheinlich die SERDES oder die Astro/Lemans/Nicer auf der Linecard fehlerhaft, und die Linecard muss ersetzt werden.
Hinweis: Wenn das Modul erneut in einen freien Steckplatz eingesetzt wird, wird die Online-Diagnose für die Linecard durchgeführt. Wenn ein fehlerhafter SERDES oder Astro/Lemans/Nicer gefunden wird, kennzeichnet der Switch den Port als fehlerhaft.
-
Wenn die Timeouts nicht weiterhin auf der ursprünglichen Linecard Astro/Lemans/Nicer auftreten, ist es möglich, dass die Supervisor-SERDES fehlerhaft sind. Führen Sie zur Überprüfung dieses Vorgangs ein zweifelsfrei funktionierendes Modul in den ursprünglichen Steckplatz ein, und prüfen Sie, ob die Timeouts mit dem neuen Modul auftreten.
Wenn es funktioniert, ist es möglicherweise eine SERDES auf dem Supervisor. Eine Liste der betroffenen Seriennummern mit der fehlerhaften SERDES-Komponente finden Sie im Feld Catalyst WS-X4013 Supervisor Exhibits Partial Loss of Connectivity (Catalyst WS-X4013-Supervisor Exhibits teilweise Verbindungsverlust).
Problemumgehung: Keine
Lösung: Wenden Sie sich für weitere Fehlerbehebung an das TAC.
Ursache 4: Übergangsfunktion/Festplattenausfall
Bei Geräten, die mit einem Catalyst 4000 mit einer Supervisor I-, II-, III- oder IV-Engine oder Catalyst 2948G- oder Cat2980G-Serie verbunden sind, kann es zu einem teilweisen oder vollständigen Verlust der Netzwerkverbindung kommen. Einige oder alle Ports können betroffen sein. Diese Symptome gehen mit einer raschen Zunahme von ungültigen CRC-verlorenen Paketen auf dem CatOS-basierten Supervisor und STUB-ASIC-Timeout-Fehlermeldungen einher.
Das Problem ist auf einen Packet Buffer Memory (SRAM)-Fehler zurückzuführen, der entweder ein fester oder ein vorübergehender Typ ist.
Aktion: Wählen Sie die gewünschte Aktion aus, je nachdem, welche der beiden Signaturen für den vorübergehenden Paketpuffer-Speicherfehler aufgetreten sind:
-
Signatur für vorübergehenden Paketpuffer-Speicher-Ausfall für SUP I, SUP II, 2948G, 2980G
Die folgenden Symptome dieses Problems sind:
-
InvalidPktBufferCRCs werden schnell um eine Nachricht erweitert, die der folgenden ähnelt:
%SYS-4-P2_WARN: 1/Invalid crc, dropped packet, count = xxxx
-
Ein Soft Reset mit dem Befehl reset würde dazu führen, dass der Supervisor den POST-Test nicht bestanden hat.
-
Wenn ein hartes Zurücksetzen (Aus- und Wiedereinschalten) durchgeführt wird, besteht der Supervisor den POST-Test nicht mehr, und es tritt kein Fehler mehr auf.
Hinweis: Bei einem Ausfall des Festplattenpuffers für den Supervisor I, II, 2948G und 2980G würde ein hartes Zurücksetzen das Problem nicht beheben, und der Supervisor oder Switch würde den POST-Test weiterhin nicht bestehen.
Weitere Informationen zu diesem Problem finden Sie unter Cisco Bug ID CSCdy46288 (nur registrierte Kunden) für Supervisor II, Cisco Bug ID CSCeb56266 (nur registrierte Kunden) für Supervisor I/2948G/298. G und Cisco Bug ID CSCeb56325 (nur registrierte Kunden) für WS-C2980G-A.
-
-
Signatur des vorübergehenden Paketpufferspeicher-Fehlers für SUP III, SUP IV
Die folgenden Symptome dieses Problems sind:
-
Der VlanZeroBadCrc-Zähler erhöht sich schnell und wird in der Befehlsausgabe der folgenden Elemente angezeigt:
show platform cpuport all (prior to 12.1(11b)EW1 ) or show platform cpu packet statistics all (Since 12.1(11b)EW1) depending upon the software version. Starting from 12.1(19)EW, you should also see the following error message rapidly incrementing errors: %C4K_SWITCHINGENGINEMAN-2-PACKETMEMORYERROR3: Persistent Errors in Packet Memory xxxx
-
Bei einem weichen Zurücksetzen kann der Supervisor den POST-Test nicht durchführen. Verwenden Sie den Befehl show diagnostics power-on, um den Fehler zu überprüfen.
-
Ein hartes Zurücksetzen (Aus- und Wiedereinschalten) stellt den Supervisor wieder her und führt den POST-Test durch.
Hinweis: Bei einem Festplattenausfall des SRAM für Supervisor III/IV würde ein hartes Zurücksetzen den Supervisor nicht wiederherstellen, und der POST-Test würde trotzdem fehlschlagen.
Weitere Informationen zu diesem Problem bei Supervisor III/IV finden Sie unter Cisco Bug ID CSCdz57255 (nur registrierte Kunden).
-
Problemumgehung: Schalten Sie den Switch aus oder setzen Sie ihn bei einem vorübergehenden SRAM-Problem fest zurück. Das Problem mit dem Festplatten-RAM hat keine Problemumgehung.
Lösung: Wenden Sie sich für weitere Fehlerbehebung an das TAC.
Ursache 5: Ausfall der Supervisor-Uhr
Wenn Astro/Lemans/NiceR Timeout-Fehlermeldungen angezeigt werden, die sich auf mehrere Modulnummern oder mehrere Astro/Lemans/Nicer beziehen, könnte dies auf einen möglichen Uhrenfehler auf dem Supervisor hinweisen. Im Allgemeinen wird ein Uhrenfehler sowohl von der Astro/Lemans/Nicer-Timeout-Fehlermeldung als auch von den Fehlermeldungen BlockTXQueue und BlockedGigaport begleitet, wie unten gezeigt:
%SYS-4-P2_WARN: 1/Blocked queue on gigaport ...
Aktion: Wenden Sie sich an das TAC, um weitere Fehlerbehebungen bezüglich der Cisco Bug ID CSCdp89537 (nur registrierte Kunden) und CSCdp93187 (nur registrierte Kunden) zu erhalten.
Problemumgehung: Keine
Lösung: Wenden Sie sich für weitere Fehlerbehebung an das TAC.
Ursache 6: Kurze Stromunterbrechung
Ein Catalyst Switch der Serie 4000 mit Supervisor II (WS-X4013) kann in einen Zustand übergehen, in dem der Supervisor und die Linecards nicht ordnungsgemäß miteinander kommunizieren können. Wenn der Switch in diesen Status wechselt, leuchten die Modulstatus-LEDs rot (blinkt nicht) und/oder die Port-LEDs blinken ähnlich wie ein Modul oder ein Switch-Reset. Begleitet wird dies von den Timeout-Meldungen Astro/Lemans/NiceR.
Dieses Problem wird durch eine temporäre Unterbrechung der Stromversorgung des Switches (unter 500 ms) verursacht. Die vorübergehende Unterbrechung der Stromversorgung kann auf instabile Stromeingänge in einer Produktionsumgebung zurückzuführen sein.
Aktion: Siehe Workaround unten.
Problemumgehung: Setzen Sie den Switch (Soft oder Hard (Aus- und Wiedereinschalten) zurück.
Lösung: Aktualisieren Sie auf das Software-Image mit der Behebung für Cisco Bug ID CSCea14710 (nur registrierte Kunden) oder spätere Versionen.
Zugehörige Informationen
- Häufige CatOS-Fehlermeldungen bei Catalyst Switches der Serie 4000
- Hardware-Fehlerbehebung für Catalyst Switches der Serien 4000/4912G/2980G/2948G
- Fehlerbehebung bei Hardware- und verwandten Problemen mit Catalyst 4000 und 4500 Supervisor III und IV
- Support-Seiten für Catalyst Switches der Serien 4000 und 4500
- Unterstützung der LAN Switching-Technologie
- Produkt-Support für Catalyst LAN- und ATM-Switches
- Technischer Support und Dokumentation - Cisco Systems
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)