Einleitung
In diesem Dokument wird die Fehlerbehebung für sessmgr oder aaamgr beschrieben, die sich im Warn- oder Überschreibungsstatus befinden.
Überblick
Session Manager (Sessmgr) - Ein Subscriber-Verarbeitungssystem, das mehrere Sitzungstypen unterstützt und für die Verarbeitung von Subscriber-Transaktionen zuständig ist. Sessmgr wird normalerweise mit AAAManagers gepaart.
Authorization, Authentication, and Accounting Manager (Aaamgr) - Ist für die Durchführung aller AAA-Protokollvorgänge und -funktionen für Teilnehmer und administrative Benutzer innerhalb des Systems verantwortlich.
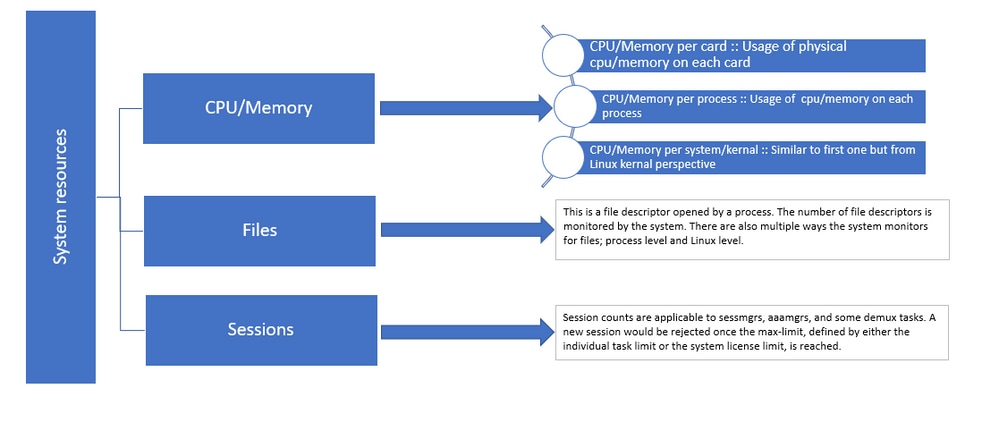 Abbildung 1: Staros-Ressourcenverteilung
Abbildung 1: Staros-Ressourcenverteilung
Protokolle/grundlegende Prüfungen
Grundlegende Prüfungen
Um weitere Details über das Problem zu erhalten, müssen Sie diese Informationen mit dem Benutzer überprüfen:
- Wie lange ist der Status von sessmgr/aaamgr schon "gewarnt" oder "beendet"?
- Wie viele sessmgrs/aaamgrs sind von diesem Problem betroffen?
- Sie müssen bestätigen, ob sich der Status "sessmgr/aaamgr" aufgrund von Speicher oder CPU im Warn- oder Überlaufstatus befindet.
- Sie müssen auch überprüfen, ob ein plötzlicher Anstieg des Datenverkehrs aufgetreten ist. Dies können Sie beurteilen, indem Sie die Anzahl der Sitzungen pro Sessmgr überprüfen.
Wenn Sie diese Informationen erhalten, können Sie das jeweilige Problem besser verstehen und beheben.
Protokolle
-
Rufen Sie Show Support Details (SSD) und Syslogs ab, die den problematischen Zeitstempel erfassen. Es wird empfohlen, diese Protokolle mindestens 2 Stunden vor Beginn des Problems zu sammeln, um den Auslösungspunkt zu identifizieren.
-
Erfassen Sie Core-Dateien für problematische und unproblematische sessmgr/aaamgr. Weitere Informationen hierzu finden Sie im Abschnitt "Analyse".
Analyse
Schritt 1: Um den Status des betroffenen sessmgr/aaamgr durch Befehle zu überprüfen.
show task resources -
--------- to check detail of sessmgr/aamgr into warn/over state and from the same you also get to know current memory/cpu utlization
Output ::
******** show task resources *******
Monday May 29 08:30:54 IST 2023
task cputime memory files sessions
cpu facility inst used alloc used alloc used allc used allc S status
----------------------- ----------- ------------- --------- ------------- ------
2/0 sessmgr 297 6.48% 100% 604.8M 900.0M 210 500 1651 12000 I good
2/0 sessmgr 300 5.66% 100% 603.0M 900.0M 224 500 1652 12000 I good
2/1 aaamgr 155 0.90% 95% 96.39M 260.0M 21 500 -- -- - good
2/1 aaamgr 170 0.89% 95% 96.46M 260.0M 21 500 -- -- - good

Hinweis: Die Anzahl der Sitzungen pro Sessmgr kann mit diesem Befehl überprüft werden, wie in der Befehlsausgabe gezeigt.
Mit beiden Befehlen kann die maximale Speichernutzung seit dem Neuladen des Knotens überprüft werden:
show task resources max
show task memory max
******** show task memory max *******
Monday May 29 08:30:53 IST 2023
task heap physical virtual
cpu facility inst max max alloc max alloc status
----------------------- ------ ------------------ ------------------ ------
2/0 sessmgr 902 548.6M 66% 602.6M 900.0M 29% 1.19G 4.00G good
2/0 aaamgr 913 68.06M 38% 99.11M 260.0M 17% 713.0M 4.00G good
Hinweis: Der Befehl "memory max" gibt den maximalen seit dem erneuten Laden des Knotens verwendeten Speicher an. Mit diesem Befehl können wir alle Muster identifizieren, die mit dem Problem in Zusammenhang stehen, z. B. ob das Problem nach einem kürzlich erfolgten Neuladen begonnen hat oder ob es vor kurzem einen Neuladen gegeben hat, mit dem wir den maximalen Speicherwert überprüfen können. Auf der anderen Seite liefern "show task resources" und "show task resources max" ähnliche Ausgaben, mit dem Unterschied, dass der Befehl max die maximalen Werte von Speicher, CPU und Sitzungen anzeigt, die von einem bestimmten sessmgr/aaamgr seit dem Neuladen verwendet werden.
show subscriber summary apn <apn name> smgr-instance <instance ID> | grep Total
-------------- to check no of subscribers for that particular APN in sessmg
Aktionsplan
Szenario 1. Aufgrund der hohen Speicherauslastung
1. Erfassen Sie SSD, bevor Sie die Sessmgr-Instanz neu starten/beenden.
2. Sammeln Sie den Core Dump für einen der betroffenen Sessmgr.
task core facility sessmgr instance <instance-value>
3. Sammeln Sie die Heap-Ausgabe mit diesen Befehlen im ausgeblendeten Modus für die gleichen betroffenen sessmgr und aaamgr.
show session subsystem facility sessmgr instance <instance-value> debug-info verbose
show task resources facility sessmgr instance <instance-value>
Heap outputs:
show messenger proclet facility sessmgr instance <instance-value> heap depth 9
show messenger proclet facility sessmgr instance <instance-value> system heap depth 9
show messenger proclet facility sessmgr instance <instance-value> heap
show messenger proclet facility sessmgr instance <instance-value> system
show snx sessmgr instance <instance-value> memory ldbuf
show snx sessmgr instance <instance-value> memory mblk
4. Starten Sie den sessmgr-Task mit folgendem Befehl neu:
task kill facility sessmgr instance <instance-value>

Vorsicht: Wenn sich mehrere Sessmgrs im Warn- oder Überschreibungsstatus befinden, wird empfohlen, die Sessmgrs mit einem Intervall von 2 bis 5 Minuten neu zu starten. Beginnen Sie zunächst mit einem Neustart von nur 2 bis 3 Sessmgrs, und warten Sie dann bis zu 10 bis 15 Minuten, um festzustellen, ob diese Sessmgrs wieder in den Normalzustand zurückkehren. Dieser Schritt hilft bei der Bewertung der Auswirkungen des Neustarts und bei der Überwachung des Wiederherstellungsfortschritts.
5. Überprüfen Sie den Status des Sessmgr.
show task resources facility sessmgr instance <instance-value> -------- to check if sessmgr is back in good state
6. Holen Sie ein anderes SSD ein.
7. Sammeln Sie die Ausgabe aller in Schritt 3 genannten CLI-Befehle.
8. Sammeln Sie den Core Dump für eine der fehlerfreien Sessmgr-Instanzen mit dem in Schritt 2 genannten Befehl.
Hinweis: Um Kerndateien für problematische und unproblematische Anlagen zu erhalten, haben Sie zwei Möglichkeiten. Zum einen können Sie die Kerndatei desselben Sessmgr sammeln, nachdem sie nach einem Neustart wieder normal ist. Alternativ können Sie die Kerndatei von einem anderen gesunden Sessmgr erfassen. Beide Ansätze liefern wertvolle Informationen für die Analyse und Fehlerbehebung.
Sobald Sie die Heap-Ausgaben gesammelt haben, wenden Sie sich an das Cisco TAC, um die genaue Tabelle zur Heap-Nutzung zu erhalten.
Von diesen Heap-Ausgängen müssen Sie die Funktion überprüfen, die mehr Speicher benötigt. Auf dieser Grundlage untersucht das TAC den beabsichtigten Zweck der Funktionsauslastung und ermittelt, ob diese mit dem erhöhten Datenverkehr-/Transaktionsvolumen oder einem anderen problematischen Grund übereinstimmt.
Heap-Ausgaben können mithilfe eines Tools sortiert werden, auf das über den Link Memory-CPU-data-sort-tool zugegriffen wird.
Hinweis: In diesem Tool gibt es mehrere Optionen für verschiedene Einrichtungen. Sie müssen jedoch "Heap Consumption Table" auswählen, in die Sie Heap-Ausgaben hochladen und das Tool ausführen, um die Ausgabe in einem sortierten Format zu erhalten.
Szenario 2. Aufgrund der hohen CPU-Auslastung
1. Erfassen Sie SSD, bevor Sie die Sessmgr-Instanz neu starten oder beenden.
2. Sammeln Sie den Core Dump für einen der betroffenen Sessmgr.
task core facility sessmgr instance <instance-value>
3. Sammeln Sie die Heapausgabe dieser Befehle im ausgeblendeten Modus für den gleichen betroffenen sessmgr/aamgr.
show session subsystem facility sessmgr instance <instance-value> debug-info verbose
show task resources facility sessmgr instance <instance-value>
show cpu table
show cpu utilization
show cpu info ------ Display detailed info of CPU.
show cpu info verbose ------ More detailed version of the above
Profiler output for CPU
This is the background cpu profiler. This command allows checking which functions consume
the most CPU time. This command requires CLI test command password.
show profile facility <facility instance> instance <instance ID> depth 4
show profile facility <facility instance> active facility <facility instance> depth 8
4. Starten Sie den Sessmgr-Task mit dem folgenden Befehl neu:
task kill facility sessmgr instance <instance-value>
5. Überprüfen Sie den Status des Sessmgr.
show task resources facility sessmgr instance <instance-value> -------- to check if sessmgr is back in good state
6. Holen Sie ein anderes SSD ein.
7. Sammeln Sie die Ausgabe aller in Schritt 3 genannten CLI-Befehle.
8. Sammeln Sie den Core Dump für eine der fehlerfreien Sessmgr-Instanzen mit dem in Schritt 2 genannten Befehl.
Um Szenarien mit hohem Arbeitsspeicher und hoher CPU zu analysieren, untersuchen Sie bulkstats, um festzustellen, ob es einen legitimen Anstieg der Datenverkehrstrends gibt.
Überprüfen Sie außerdem die bulkstats für Statistiken auf Karten-/CPU-Ebene.
 Feedback
Feedback