Fehlerbehebung für Common Data Layer (CDL)
Download-Optionen
-
ePub (312.9 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
1. Einleitung
In diesem Artikel werden die Grundlagen der Fehlerbehebung für Common Data Layer (CDL) in SMF-Umgebungen behandelt. Eine Dokumentation finden Sie unter diesem Link.
2. Überblick
Die Cisco Common Data Layer (CDL) ist eine hochleistungsfähige KV-Datenspeicherschicht (Key-Value) der nächsten Generation für alle Cloud Native-Anwendungen.
CDL wird derzeit als Zustandsverwaltungskomponente mit HA- (High Availability) und Geo HA-Funktionen verwendet.
Der CDL bietet:
- Eine gemeinsame Datenspeicherebene für verschiedene Netzwerkfunktionen (NFs).
- Lese- und Schreibvorgänge mit niedriger Latenz (im Speicher für Arbeitssitzungen)
- Benachrichtigen Sie die NFs, den Subscriber zu blockieren, wenn ein DoS-Angriff (Denial of Service) auf dieselbe Sitzung gemeldet wird.
- Hohe Verfügbarkeit - lokale Redundanz mit mindestens 2 Replikaten
- Geo-Redundanz mit 2 Standorten
- Kein primäres/sekundäres Konzept alle Steckplätze für Schreibvorgänge verfügbar. Verbessert die Failover-Zeit, da keine primäre Auswahl stattfindet.
3. Komponenten
- Endgerät: (cdl-ep-session-c1-d0-7c79c87d65-xpm5v)
- Der CDL-Endpunkt ist ein Kubernetes (K8s) POD. Sie wird bereitgestellt, um gRPC über die HTTP2-Schnittstelle für den NF-Client verfügbar zu machen, dient der Verarbeitung von Datenbankdienstanforderungen und fungiert als Einstiegspunkt für die Northbound-Anwendungen.
- Steckplatz: (cdl-slot-session-c1-m1-0)
- Der CDL-Endpunkt unterstützt mehrere Mikrodienste mit Steckplätzen. Bei diesen Mikroservices handelt es sich um K8s-PODs, die für die Bereitstellung der internen gRPC-Schnittstelle für den Cisco Data Store bereitgestellt werden.
- Jeder Steckplatz-POD enthält eine begrenzte Anzahl von Sitzungen. Diese Sitzungen sind die eigentlichen Sitzungsdaten im Byte-Array-Format.
- Index: (cdl-index-session-c1-m1-0)
- Der Index-Mikrodienst enthält die indizierungsbezogenen Daten
- Diese Indizierungsdaten werden dann verwendet, um die eigentlichen Sitzungsdaten aus den Steckplatz-Microservices abzurufen
- ETCD: (etd-smf-etd-cluster-0)
- CDL verwendet ETCD (ein Open-Source-Schlüsselwertspeicher) als DB-Diensterkennung. Wenn das Cisco Data Store-EP gestartet, beendet oder heruntergefahren wird, wird dem Veröffentlichungsstatus ein Ereignis hinzugefügt. Aus diesem Grund werden Benachrichtigungen an jeden POD gesendet, der für diese Ereignisse registriert ist. Außerdem wird beim Hinzufügen oder Entfernen eines Schlüsselereignisses die lokale Zuordnung aktualisiert.
- Kafka: (kafka-0)
- Der Kafka-POD repliziert Daten zwischen den lokalen Replikaten und standortübergreifend zum Indizieren. Für die standortübergreifende Replikation verwendet Kafak MirrorMaker.
- Spiegelhersteller: (Spiegelhersteller-0)
- Der Mirror Maker POD repliziert die Indizierungsdaten in den Remote-CDL-Standorten. Es nimmt Daten von den Remote-Standorten und veröffentlicht sie auf der lokalen Kafka-Website, damit die entsprechenden Indizierungsinstanzen übernommen werden können.
Beispiel:
master-1:~$ kubectl get pods -n smf-smf -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cdl-ep-session-c1-d0-7889db4d87-5mln5 1/1 Running 0 80d 192.168.16.247 smf-data-worker-5 <none> <none> cdl-ep-session-c1-d0-7889db4d87-8q7hg 1/1 Running 0 80d 192.168.18.108 smf-data-worker-1 <none> <none> cdl-ep-session-c1-d0-7889db4d87-fj2nf 1/1 Running 0 80d 192.168.24.206 smf-data-worker-3 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z6c2z 1/1 Running 0 34d 192.168.4.164 smf-data-worker-2 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z7c89 1/1 Running 0 80d 192.168.7.161 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-0 1/1 Running 0 80d 192.168.7.172 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-1 1/1 Running 0 80d 192.168.24.241 smf-data-worker-3 <none> <none> cdl-index-session-c1-m2-0 1/1 Running 0 49d 192.168.18.116 smf-data-worker-1 <none> <none> cdl-index-session-c1-m2-1 1/1 Running 0 80d 192.168.7.173 smf-data-worker-4 <none> <none> cdl-index-session-c1-m3-0 1/1 Running 0 80d 192.168.24.197 smf-data-worker-3 <none> <none> cdl-index-session-c1-m3-1 1/1 Running 0 80d 192.168.18.107 smf-data-worker-1 <none> <none> cdl-index-session-c1-m4-0 1/1 Running 0 80d 192.168.7.158 smf-data-worker-4 <none> <none> cdl-index-session-c1-m4-1 1/1 Running 0 49d 192.168.16.251 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m1-0 1/1 Running 0 80d 192.168.18.117 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m1-1 1/1 Running 0 80d 192.168.24.201 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m2-0 1/1 Running 0 80d 192.168.16.245 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m2-1 1/1 Running 0 80d 192.168.18.123 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m3-0 1/1 Running 0 34d 192.168.4.156 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m3-1 1/1 Running 0 80d 192.168.18.78 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m4-0 1/1 Running 0 34d 192.168.4.170 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m4-1 1/1 Running 0 80d 192.168.7.177 smf-data-worker-4 <none> <none> cdl-slot-session-c1-m5-0 1/1 Running 0 80d 192.168.24.246 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m5-1 1/1 Running 0 34d 192.168.4.163 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m6-0 1/1 Running 0 80d 192.168.18.119 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m6-1 1/1 Running 0 80d 192.168.16.228 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-0 1/1 Running 0 80d 192.168.16.215 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-1 1/1 Running 0 49d 192.168.4.167 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m8-0 1/1 Running 0 49d 192.168.24.213 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m8-1 1/1 Running 0 80d 192.168.16.253 smf-data-worker-5 <none> <none> etcd-smf-smf-etcd-cluster-0 2/2 Running 0 80d 192.168.11.176 smf-data-master-1 <none> <none> etcd-smf-smf-etcd-cluster-1 2/2 Running 0 48d 192.168.7.59 smf-data-master-2 <none> <none> etcd-smf-smf-etcd-cluster-2 2/2 Running 1 34d 192.168.11.66 smf-data-master-3 <none> <none> georeplication-pod-0 1/1 Running 0 80d 10.10.1.22 smf-data-master-1 <none> <none> georeplication-pod-1 1/1 Running 0 48d 10.10.1.23 smf-data-master-2 <none> <none> grafana-dashboard-cdl-smf-smf-77bd69cff7-qbvmv 1/1 Running 0 34d 192.168.7.41 smf-data-master-2 <none> <none> kafka-0 2/2 Running 0 80d 192.168.24.245 smf-data-worker-3 <none> <none> kafka-1 2/2 Running 0 49d 192.168.16.200 smf-data-worker-5 <none> <none> mirror-maker-0 1/1 Running 1 80d 192.168.18.74 smf-data-worker-1 <none> <none> zookeeper-0 1/1 Running 0 34d 192.168.11.73 smf-data-master-3 <none> <none> zookeeper-1 1/1 Running 0 48d 192.168.7.47 smf-data-master-2 <none> <none> zookeeper-2
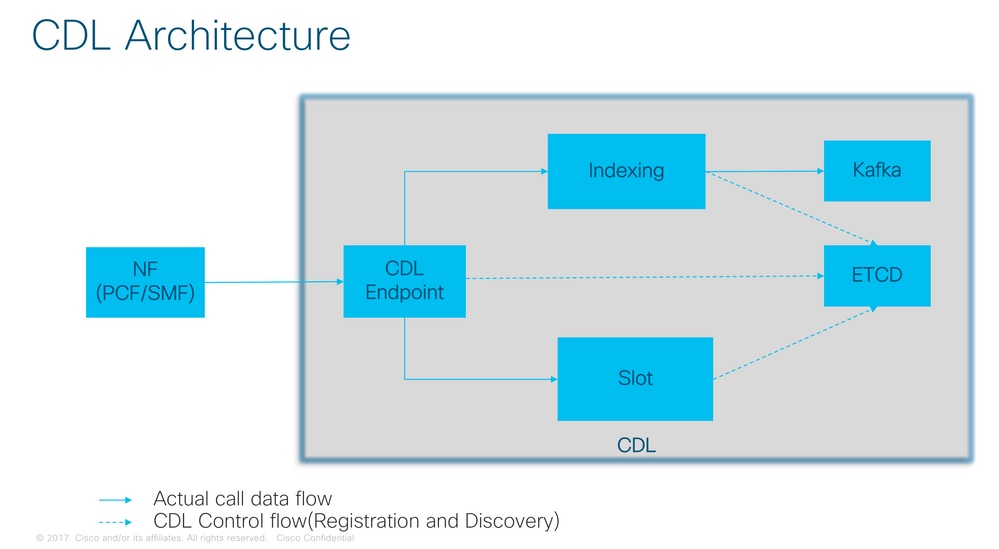 CDL-Architektur
CDL-Architektur
Anmerkung: Kein primäres/sekundäres Konzept alle Steckplätze für Schreibvorgänge verfügbar. Verbessert die Failover-Zeit, da keine primäre Auswahl stattfindet.
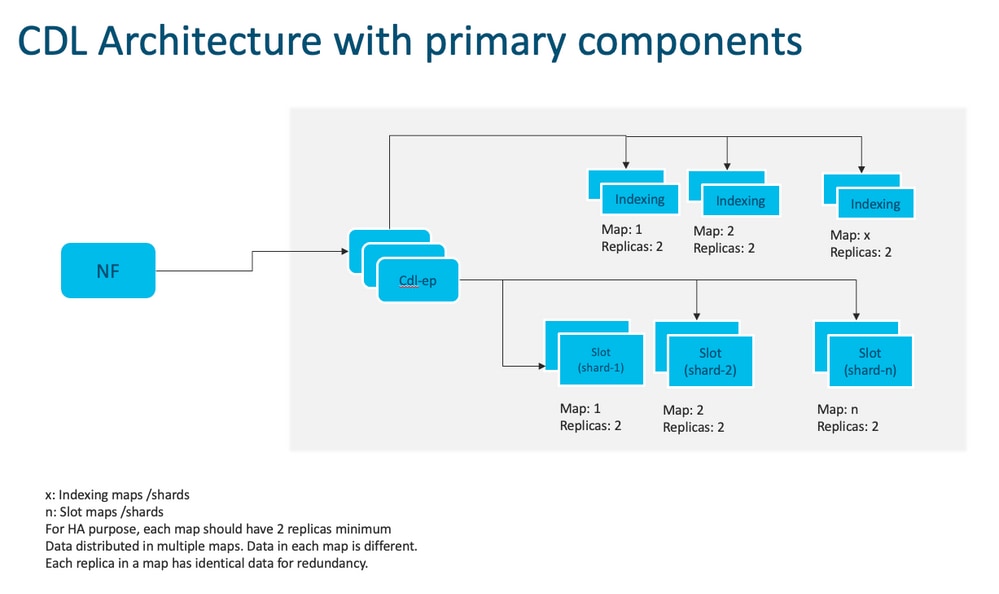
Anmerkung: Standardmäßig wird CDL mit 2 Replikaten für db-ep, 1 Slot Map (2 Replikate pro Map) und 1 Index Map (2 Replikate pro Map) bereitgestellt.
4. Konfigurationsanleitung
smf# show running-config cdl cdl system-id 1 /// unique across the site, system-id 1 is the primary site ID for sliceNames SMF1 SMF2 in HA GR CDL deploy cdl node-type db-data /// node label to configure the node affinity cdl enable-geo-replication true /// CDL GR Deployment with 2 RACKS cdl remote-site 2 db-endpoint host x.x.x.x /// Remote site cdl-ep configuration on site-1 db-endpoint port 8882 kafka-server x.x.x.x 10061 /// Remote site kafka configuration on site-1 exit kafka-server x.x.x.x 10061 exit exit cdl label-config session /// Configures the list of label for CDL pods endpoint key smi.cisco.com/node-type-3 endpoint value session slot map 1 key smi.cisco.com/node-type-3 value session exit slot map 2 key smi.cisco.com/node-type-3 value session exit slot map 3 key smi.cisco.com/node-type-3 value session exit slot map 4 key smi.cisco.com/node-type-3 value session exit slot map 5 key smi.cisco.com/node-type-3 value session exit slot map 6 key smi.cisco.com/node-type-3 value session exit slot map 7 key smi.cisco.com/node-type-3 value session exit slot map 8 key smi.cisco.com/node-type-3 value session exit index map 1 key smi.cisco.com/node-type-3 value session exit index map 2 key smi.cisco.com/node-type-3 value session exit index map 3 key smi.cisco.com/node-type-3 value session exit index map 4 key smi.cisco.com/node-type-3 value session exit exit cdl datastore session /// unique with in the site label-config session geo-remote-site [ 2 ] slice-names [ SMF1 SMF2 ] endpoint cpu-request 2000 endpoint go-max-procs 16 endpoint replica 5 /// number of cdl-ep pods endpoint external-ip x.x.x.x endpoint external-port 8882 index cpu-request 2000 index go-max-procs 8 index replica 2 /// number of replicas per mop for cdl-index, can not be changed after CDL deployement.
NOTE: If you need to change number of index replica, set the system mode to shutdown from respective ops-center CLI, change the replica and set the system mode to running index map 4 /// number of mops for cdl-index index write-factor 1 /// number of copies to be written before a successful response slot cpu-request 2000 slot go-max-procs 8 slot replica 2 /// number of replicas per mop for cdl-slot slot map 8 /// number of mops for cdl-slot slot write-factor 1 slot metrics report-idle-session-type true features instance-aware-notification enable true /// This enables GR failover notification features instance-aware-notification system-id 1 slice-names [ SMF1 ] exit features instance-aware-notification system-id 2 slice-names [ SMF2 ] exit exit cdl kafka replica 2 cdl kafka label-config key smi.cisco.com/node-type-3 cdl kafka label-config value session cdl kafka external-ip x.x.x.x 10061 exit cdl kafka external-ip x.x.x.x 10061 exit
5. Fehlerbehebung
5.1 Pod-Fehler
Der Betrieb der CDL ist einfach Schlüssel > Wert db.
- Alle Anfragen werden an die cdl-endpoint PODs gesendet.
- In cdl-index pods speichern wir Schlüssel, Round Robin.
- In cdl-slot speichern wir Wert (Session Info), Round Robin.
- Wir definieren Backup (Anzahl der Replikate) für jeden PoD-Map (Typ).
- Kafka pod wird als Transportbus verwendet.
- mirror maker wird als Transportbus zu verschiedenen Racks eingesetzt (Geo Redundanz).
Fehler für jeden konnte als übersetzt werden, das heißt, wenn alle Pods dieses Typs/dieser Karte zur gleichen Zeit ausfielen:
- cdl-endpoint - Fehler bei der Kommunikation mit CDL
- cdl-index - Schlüssel für Sitzungsdaten werden gelöscht
- cdl-slot - Sitzungsdaten gehen verloren
- Kafka - Synchronisationsoption zwischen den Pod-Typ-Maps wird unterbrochen
- Mirror Maker - Synchronisation mit anderen Geo-Redundanz-Knoten wird unterbrochen
Wir können immer Protokolle von relevanten Pods sammeln, da cdl pod-Protokolle nicht so schnell übertragen werden, sodass es einen zusätzlichen Wert gibt, sie zu sammeln.
Remamber tac-debug sammelt Snapshots in der Zeit, während Protokolle alle Daten ausdrucken, da sie gespeichert sind.
PODs beschreiben
kubectl describe pod cdl-ep-session-c1-d0-7889db4d87-5mln5 -n smf-rcdn
POD-Protokolle sammeln
kubectl logs cdl-ep-session-c1-d0-7c79c87d65-xpm5v -n smf-rcdn
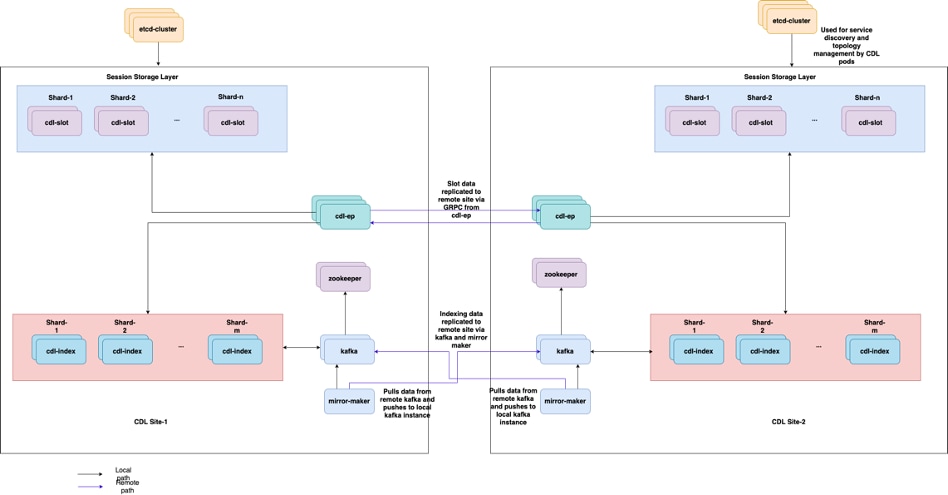
5.2 CDL Abrufen von Sitzungsinformationen von Sitzungsschlüsseln
In CDL enthält jede Sitzung ein Feld mit der Bezeichnung "unique-keys", das diese Sitzung identifiziert.
Wenn wir den Sitzungsausdruck von show participant supi und cdl show sessions summary slice-name slice1 db-name session filter vergleichen
- ipv4-Sitzungsadresse kombiniert mit supi = "1#/#imsi-123969789012404:10.0.0.3"
- ddn + ip4 address = "1#/#lab:10.0.0.3"
- ipv6 session address combined with supi = "1#/#imsi-123969789012404:2001:db0:0:2::"
- ddn + ipv6 address from session = "1#/#lab:2001:db0:0:2::"
- smfTeid auch N4 Session Key = "1#/#293601283" Dies ist wirklich nützlich, wenn Fehlerbehebung auf UPF, können Sie durch Sitzungsprotokolle suchen und sitzungsbezogene Informationen zu finden.
- supi + ebi = "1#/#imsi-123969789012404:ebi-5"
- supi + ddn= "1#/#imsi-123969789012404:lab"
[smf/data] smf# cdl show sessions summary slice-name slice1 db-name session filter { condition match key 1#/#293601283 }
Sun Mar 19 20:17:41.914 UTC+00:00
message params: {session-summary cli session {0 100 1#/#293601283 0 [{0 1#/#293601283}] [] 0 0 false 4096 [] [] 0} slice1}
session {
primary-key 1#/#imsi-123969789012404:1
unique-keys [ "1#/#imsi-123969789012404:10.0.0.3" "1#/#lab:10.0.0.3" "1#/#imsi-123969789012404:2001:db0:0:2::" "1#/#lab:2001:db0:0:2::" "1#/#293601283" "1#/#imsi-123969789012404:ebi-5" "1#/#imsi-123969789012404:lab" ]
non-unique-keys [ "1#/#roaming-status:visitor-lbo" "1#/#ue-type:nr-capable" "1#/#supi:imsi-123969789012404" "1#/#gpsi:msisdn-22331010101010" "1#/#pei:imei-123456789012381" "1#/#psid:1" "1#/#snssai:001000003" "1#/#dnn:lab" "1#/#emergency:false" "1#/#rat:nr" "1#/#access:3gpp" access "1#/#connectivity:5g" "1#/#udm-uecm:10.10.10.215" "1#/#udm-sdm:10.10.10.215" "1#/#auth-status:unauthenticated" "1#/#pcfGroupId:PCF-dnn=lab;" "1#/#policy:2" "1#/#pcf:10.10.10.216" "1#/#upf:10.10.10.150" "1#/#upfEpKey:10.10.10.150:10.10.10.202" "1#/#ipv4-addr:pool1/10.0.0.3" "1#/#ipv4-pool:pool1" "1#/#ipv4-range:pool1/10.0.0.1" "1#/#ipv4-startrange:pool1/10.0.0.1" "1#/#ipv6-pfx:pool1/2001:db0:0:2::" "1#/#ipv6-pool:pool1" "1#/#ipv6-range:pool1/2001:db0::" "1#/#ipv6-startrange:pool1/2001:db0::" "1#/#id-index:1:0:32768" "1#/#id-value:2/3" "1#/#chfGroupId:CHF-dnn=lab;" "1#/#chf:10.10.10.218" "1#/#amf:10.10.10.217" "1#/#peerGtpuEpKey:10.10.10.150:20.0.0.1" "1#/#namespace:smf" ]
flags [ flag3:peerGtpuEpKey:10.10.10.150:20.0.0.1 session-state-flag:smf_active ]
map-id 2
instance-id 1
app-instance-id 1
version 1
create-time 2023-03-19 20:14:14.381940117 +0000 UTC
last-updated-time 2023-03-19 20:14:14.943366502 +0000 UTC
purge-on-eval false
next-eval-time 2023-03-26 20:14:14 +0000 UTC
session-types [ rat_type:NR wps:non_wps emergency_call:false pdu_type:ipv4v6 dnn:lab qos_5qi_1_rat_type:NR ssc_mode:ssc_mode_1 always_on:disable fourg_only_ue:false up_state:active qos_5qi_5_rat_type:NR dcnr:disable smf_roaming_status:visitor-lbo dnn:lab:rat_type:NR ]
data-size 2866
}
[smf/data] smf#
Wenn wir es mit dem Ausdruck aus der SMF vergleichen:
[smf/data] smf# show subscriber supi imsi-123969789012404 gr-instance 1 namespace smf
Sun Mar 19 20:25:47.816 UTC+00:00
subscriber-details
{
"subResponses": [
[
"roaming-status:visitor-lbo",
"ue-type:nr-capable",
"supi:imsi-123969789012404",
"gpsi:msisdn-22331010101010",
"pei:imei-123456789012381",
"psid:1",
"snssai:001000003",
"dnn:lab",
"emergency:false",
"rat:nr",
"access:3gpp access",
"connectivity:5g",
"udm-uecm:10.10.10.215",
"udm-sdm:10.10.10.215",
"auth-status:unauthenticated",
"pcfGroupId:PCF-dnn=lab;",
"policy:2",
"pcf:10.10.10.216",
"upf:10.10.10.150",
"upfEpKey:10.10.10.150:10.10.10.202",
"ipv4-addr:pool1/10.0.0.3",
"ipv4-pool:pool1",
"ipv4-range:pool1/10.0.0.1",
"ipv4-startrange:pool1/10.0.0.1",
"ipv6-pfx:pool1/2001:db0:0:2::",
"ipv6-pool:pool1",
"ipv6-range:pool1/2001:db0::",
"ipv6-startrange:pool1/2001:db0::",
"id-index:1:0:32768",
"id-value:2/3",
"chfGroupId:CHF-dnn=lab;",
"chf:10.10.10.218",
"amf:10.10.10.217",
"peerGtpuEpKey:10.10.10.150:20.0.0.1",
"namespace:smf",
"nf-service:smf"
]
]
}
CDL-Status auf SMF überprüfen:
cdl show status
cdl show sessions summary slice-name <slice name> | more
5.3 CDL-Pods funktionieren nicht
Identifizierung
Überprüfen Sie die Ausgabe der beschreibenden PODs (Container/Mitglied/Bundesland/Grund, Ereignisse).
kubectl describe pods -n <namespace> <failed pod name>
Wie zu beheben
- PODs befinden sich im Wartezustand Überprüfen Sie, ob ein k8s-Knoten mit den Labelwerten gleich dem Wert von cdl/node-type Anzahl von Replikaten kleiner oder gleich der Anzahl von k8s-Knoten ist, wobei die Labelwerte gleich dem Wert von cdl/node-type sind.
kubectl get nodes -l smi.cisco.com/node-type=<value of cdl/node-type, default value is 'session' in multi node setup)
- Pods befinden sich im CrashLoopBackOff-Fehlerstatus Überprüfen Sie den Status der Pods. Wenn die ETD-Pods nicht ausgeführt werden, beheben Sie die ETD-Probleme.
kubectl describe pods -n <namespace> <etcd pod name>
- Pods befinden sich im ImagePullBack-Fehlerstatus Überprüfen Sie, ob auf das Helm-Repository und die Image-Registrierung zugegriffen werden kann. Überprüfen Sie, ob die erforderlichen Proxy- und DNS-Server konfiguriert sind.
5.4 Mirror Maker PODs befinden sich im Initialzustand
Überprüfen Sie die Pods-Ausgabe und die POD-Protokolle.
kubectl describe pods -n <namespace> <failed pod name> kubectl logs -n <namespace> <failed pod name> [-c <container name>]
Wie zu beheben
- Überprüfen Sie, ob die für Kafka konfigurierten externen IPs korrekt sind.
- Überprüfen Sie die Verfügbarkeit des Remote-Standorts kafka über externe IPs.
5.5 CDL-Index nicht ordnungsgemäß repliziert
Identifizierung
Auf Daten, die an einem Standort hinzugefügt werden, kann von einem anderen Standort aus nicht zugegriffen werden.
Wie zu beheben
- Überprüfen Sie die Konfiguration der lokalen System-ID und des Remote-Standorts.
- Überprüfen Sie die Erreichbarkeit von CDL-Endpunkten und Kafka zwischen den einzelnen Standorten.
- Überprüfen Sie die Karte, Replik des Index und Steckplatz auf jedem Standort. Sie kann standortübergreifend identisch sein.
5.6 CDL-Vorgänge sind fehlgeschlagen, aber Verbindung erfolgreich
Wie zu beheben
- Stellen Sie sicher, dass alle PODs betriebsbereit sind.
- Index-PODs sind nur dann bereit, wenn die Synchronisierung mit dem Peer-Replikat abgeschlossen ist (lokal oder remote, falls verfügbar).
- Steckplatz-PODs sind nur bereit, wenn sie vollständig mit Peer-Replikat synchronisiert werden (lokal oder remote, falls verfügbar).
- Endgeräte sind NICHT bereit, wenn mindestens ein Steckplatz und ein Index POD nicht verfügbar sind. Auch wenn es nicht bereit ist, wird die grpc-Verbindung vom Client akzeptiert.
5.7 Benachrichtigung zum Löschen des Datensatzes kam zu früh/verspätet von CDL
Wie zu beheben
- In einem k8s Cluster können alle Knoten zeitlich synchronisiert werden
- Überprüfen Sie den NTP-Synchronisierungsstatus auf allen k8s-Knoten. Wenn es irgendwelche Probleme zu beheben.
chronyc tracking chronyc sources -v chronyc sourcestats -v
6. Warnungen
| WARNUNG |
schweregrad |
zusammenfassung |
|---|---|---|
| cdlLocalRequestFailure |
Critical (Kritisch) |
Wenn die Erfolgsquote bei lokalen Anfragen für mehr als 5 Minuten unter 90 % liegt, wird eine Warnmeldung ausgelöst. |
| cdlRemoteVerbindungsfehler |
Critical (Kritisch) |
Wenn aktive Verbindungen vom Endpunkt-POD zum Remote-Standort länger als 5 Minuten 0 erreicht haben, wird ein Alarm ausgelöst (nur bei GR-aktiviertem System). |
| cdlRemoteRequestFailure |
Critical (Kritisch) |
Wenn die Erfolgsrate für eingehende Remote-Anfragen mehr als 5 Minuten lang unter 90 % liegt, wird der Alarm ausgelöst (nur bei GR-aktiviertem System) |
| cdlReplikationsfehler |
Critical (Kritisch) |
Wenn das Verhältnis zwischen ausgehenden Replikationsanforderungen und lokalen Anforderungen im cdl-global-Namespace länger als 5 Minuten unter 90 % gefallen ist (nur für GR-aktiviertes System). Diese Warnungen werden während der Aktualisierungsaktivität erwartet und können daher ignoriert werden. |
| cdlKafkaRemoteReplikationVerzögerung |
Critical (Kritisch) |
Wenn die Verzögerung der kafka-Replikation zum Remote-Standort länger als 5 Minuten 10 Sekunden überschreitet, wird der Alarm ausgelöst (nur bei GR-aktiviertem System) |
| cdlOverloaded - Hauptversion |
Major (Schwerwiegend) |
Wenn das CDL-System den konfigurierten Prozentsatz (standardmäßig 80 %) seiner Kapazität erreicht, löst das System den Alarm aus (nur bei aktivierter Überlastungsschutzfunktion). |
| cdlOverloaded - kritisch |
Critical (Kritisch) |
Wenn das CDL-System den konfigurierten Prozentsatz (Standard: 90 %) seiner Kapazität erreicht, löst das System den Alarm aus (nur bei aktivierter Überlastungsschutzfunktion). |
| cdlKafkaVerbindungsfehler |
Critical (Kritisch) |
Wenn CDL-Index-Pods länger als 5 Minuten von Kafka getrennt sind |
7. Die häufigsten Probleme
7.1 cdlReplicationError
Diese Warnmeldung wird in der Regel beim Hochfahren des Betriebszentrums oder bei einem System-Upgrade angezeigt. Versuchen Sie, CR dafür zu finden, und überprüfen Sie, ob eine CEE-Warnmeldung aufgetreten ist. Die Warnmeldung wurde bereits gelöscht.
7.2 cdlRemoteConnectionFailure & GRPC_Connections_Remote_Site
Die Erklärung gilt für alle Warnmeldungen "cdlRemoteConnectionFailure" und "GRPC_Connections_Remote_Site".
Für cdlRemoteConnectionFailure-Warnungen:
Aus CDL-Endgeräteprotokollen wird deutlich, dass die Verbindung zum Remotehost vom CDL-Endpunkt-POD unterbrochen wurde:
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
Der CDL-Endpunkt-POD versucht, eine Verbindung zum Remote-Server herzustellen, was vom Remote-Host jedoch abgelehnt wurde:
2022/01/20 01:37:08.730 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.732 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.752 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.754 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
Da der Remote-Host 5 Minuten lang nicht erreichbar war, wurde die Warnung wie folgt ausgelöst:
alerts history detail cdlRemoteConnectionFailure f5237c750de6
severity critical
type "Processing Error Alarm"
startsAt 2025-01-21T01:41:26.857Z
endsAt 2025-01-21T02:10:46.857Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes"
labels [ "alertname: cdlRemoteConnectionFailure" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" ]
annotations [ "summary: CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes" "type: Processing Error Alarm" ]
Die Verbindung zum Remotehost wurde um 02:10:32 Uhr erfolgreich hergestellt:
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
Konfiguration in SMF für CDL-Remote-Standort vorhanden:
cdl remote-site 2
db-endpoint host 10.10.10.141
db-endpoint port 8882
kafka-server 10.10.19.139 10061
exit
kafka-server 10.10.10.140 10061
exit
exit
Für Alert GRPC_Connections_Remote_Site:
Dieselbe Erklärung gilt auch für "GRPC_Connections_Remote_Site", da es ebenfalls vom gleichen CDL-Endpunkt-POD stammt.
alerts history detail GRPC_Connections_Remote_Site f083cb9d9b8d
severity critical
type "Communications Alarm"
startsAt 2025-01-21T01:37:35.160Z
endsAt 2025-01-21T02:11:35.160Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "GRPC connections to remote site are not equal to 4"
labels [ "alertname: GRPC_Connections_Remote_Site" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" "systemId: 2" ]
Aus CDL-Endpunkt-POD-Protokollen: Die Warnung wurde gestartet, als die Verbindung zum Remotehost abgelehnt wurde:
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
Die Warnung wurde gelöscht, als die Verbindung zum Remote-Standort erfolgreich hergestellt wurde:
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
8. Grafana
Das CDL Dashboard ist Teil jeder SMF-Bereitstellung.
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
04-Oct-2023 |
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Nebojsa KosanovicTechnical Leader
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)