Einleitung
In diesem Dokument werden die Probleme mit dem Redundancy Configuration Manager (RCM) und der Benutzerebenenfunktion (User Plane Function, UPF) beschrieben, die den Status des Sessmgr-Servers verursachen.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen:
Verwendete Komponenten
Die Informationen in diesem Dokument basierend auf folgenden Software- und Hardware-Versionen:
- RCM-CheckpointManager
- UPF-Sessmgr
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
Es bietet auch eine detaillierte Anleitung zur Fehlerbehebung bei Problemen mit dem Sessmgr-Serverstatus, wodurch der Datenverkehr und die Anrufverarbeitung behindert werden. Außerdem gibt es einen Bereich für Labortests zur Wiederherstellung.
Grundlegende Informationen
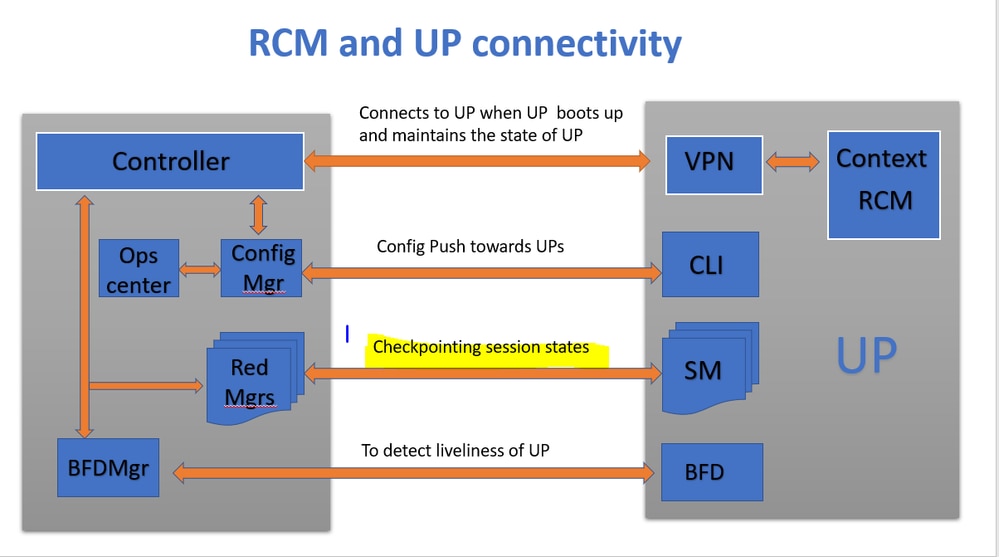
Wie in der Abbildung dargestellt, können Sie die direkten Verbindungen zwischen Redundanzmanagern (so genannte CheckpointMgrs) im RCM und Sessmgrs in UPFs für die Checkpoint-Verfolgung beobachten.
Redmgrs- und Sessmgrs-Zuordnung
1. Jedes UP hat eine "N"-Nummer von sessmgr.
2. Der RCM verfügt über eine "M"-Anzahl von Redmgrs, die von der Anzahl von Sessmgrs in UPF abhängt.
3. Sowohl redmgrs als auch sessmgrs verfügen über eine 1:1-Zuordnung basierend auf ihren IDs, wobei es für jeden sessmgr separate redmgrs gibt.
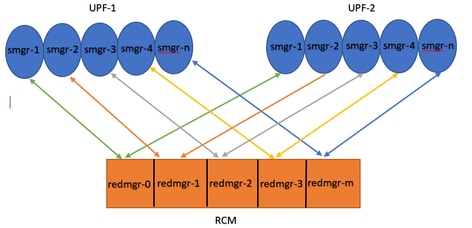
Note :: Redmgr IDs (m) = sessmgr instance ID (n-1)
For example :: smgr-1 is mapped with redmgr 0;smgr-2 is mapped with redmgr-1,
smgr-n is mapped with redmgr(m) = (n-1)
This is important to understand proper IDs of redmgr because we need to have proper logs to be checked
Erforderliche Protokolle
RCM-Protokolle - Befehlsausgänge:
rcm show-statistics checkpointmgr-endpointstats
RCM controller and checkpointmgr logs (refer this link)
Log collection
UPF:
Command outputs (hidden mode)
show rcm checkpoint statistics verbose
show session subsystem facility sessmgr all debug-info | grep Mode
If you see any sessmgr in server state check the sessmgr instance IDs and no of sessmgr
show task resources facility sessmgr all
Fehlerbehebung
In der Regel gibt es 21 Sessmgr-Instanzen in UPF, die aus 20 aktiven Sessmgr-Instanzen und einer Standby-Instanz bestehen (diese Anzahl kann jedoch je nach Design variieren).
Beispiel:
- Um inaktive Sitzungen zu identifizieren, können Sie den folgenden Befehl verwenden:
show task resources facility sessmgr all
-
In diesem Szenario führt der Versuch, das Problem durch Neustarten der problematischen Sessmgrs und sogar Neustarten von sessctrl zu beheben, nicht zur Wiederherstellung der betroffenen Sessmgrs.
-
Darüber hinaus wurde beobachtet, dass die betroffenen Sessmgrs im Servermodus feststecken und nicht im erwarteten Clientmodus, eine Bedingung, die mit den bereitgestellten Befehlen überprüft werden kann.
show rcm checkpoint statistics verbose
show rcm checkpoint statistics verbose
Tuesday August 29 16:27:53 IST 2023
smgr state peer recovery pre-alloc chk-point rcvd chk-point sent
inst conn records calls full micro full micro
---- ------- ----- ------- -------- ----- ----- ----- ----
1 Actv Ready 0 0 0 0 61784891 1041542505
2 Actv Ready 0 0 0 0 61593942 1047914230
3 Actv Ready 0 0 0 0 61471304 1031512458
4 Actv Ready 0 0 0 0 57745529 343772730
5 Actv Ready 0 0 0 0 57665041 356249384
6 Actv Ready 0 0 0 0 57722829 353213059
7 Actv Ready 0 0 0 0 61992022 1044821794
8 Actv Ready 0 0 0 0 61463665 1043128178
Here in above command all the connection can be seen as Actv Ready state which is required
show session subsystem facility sessmgr all debug-info | grep Mode
[local]
# show session subsystem facility sessmgr all debug-info | grep Mode
Tuesday August 29 16:28:56 IST 2023
Mode: UNKNOWN State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Hier sollten sich alle Sessmgrs idealerweise im Client-Modus befinden. In diesem Problem befinden sie sich jedoch im Servermodus, wodurch sie den Datenverkehr nicht verarbeiten können.
Sessmgr Wechselt in den Servermodus
-
Um die Kommunikation und die Übertragung von Checkpoints zu erleichtern, stellt jeder Session-Manager (sessmgr) eine TCP Peer-Verbindung mit dem entsprechenden Redundanz-Manager (redmgr) her.
-
Sobald die TCP-Peer-Verbindung hergestellt ist, kann der redmgr alle Subscriber-Kontexte aus dem sessmgr überprüfen und speichern. Dies ermöglicht einen nahtlosen Switchover, da die Checkpoints mit ihren jeweiligen Sessmgr-Instanzen an andere Benutzerebenenfunktionen (User Plane Functions, UPF) übertragen werden können.
-
Es ist wichtig, dass sich der Sessmgr immer im CLIENT-Modus befindet. Wenn der Sessmgr aus irgendeinem Grund im Servermodus erkannt wird, weist er auf eine unterbrochene TCP-Peer-Verbindung mit dem zugehörigen Redmgr hin. In diesem Szenario findet kein Checkpointing statt.
-
Wenn Sessmgr in diesem Zustand innerhalb des UPF feststecken, führt das Durchführen eines ungeplanten Switchovers zu einem anderen UPF, ohne den Zustand des Sessmgr zu berücksichtigen, zu demselben Problem. Der Sessmgr kann in dieser Situation keinen Datenverkehr verarbeiten.

Anmerkung: Es gibt bestimmte Probleme, bei denen checkpointmgr selbst auf den Prüfpunkt wartet, bei dem der RCM den Prüfpunkt initiiert hat, und auf die Antwort von UPF wartet. Wenn jedoch kein Antwortkontrollpunkt vorhanden ist, kann der mgr selbst nicht kommunizieren, was zu einer Verzögerung des Abschlusses des den Switchover-Timer-Wert überschreitenden Switchover-Vorgangs führt. In solchen Fällen bleibt UP sogar im Zustand PendActive stecken.
Dies kann in RCM-Statistiken und Redmgr-Protokollen überprüft werden. Außerdem können Sie mit diesem Befehl herausfinden, welcher checkpointmgr ein Problem mit welchem UPF hat.
rcm show-statistics checkpointmgr-endpointstats
4. Es kann mehrere Gründe geben, warum sessmgr lokal in den Servermodus wechselt, aber einer der Hauptgründe dafür ist, wie hier erläutert.
Grund für das Wechseln des Sessmgr in den Servermodus
1. Basierend auf der Anzahl der Sitzungsmanager in der Benutzerebenenfunktion (UPF) werden Replikate für den Redundanz-Manager (redmgr) erstellt und im Ressourcenkontroll-Manager (RCM) konfiguriert. Diese Konfiguration stellt sicher, dass jeder Redmgr mit einer Session-Manager-Instanz verbunden ist.
2. Wenn es eine 1:1-Zuordnung zwischen redmgr und sessmgr gibt, was geschieht, wenn die Sitzungsmanager-Instanz-ID einen Wert überschreitet, der höher ist als die Anzahl der Sitzungsmanager?
For example :::
Sessmgr instance ID :: 1 to 20
Redmgr IDs :: 0 to 19
In this example somehow if my sessmgr instance ID goes beyond the mentioned limit i.e say 21/22/23/24/25 so in this case redmgr is already mapped with instance IDs 0 to 19 and would be unaware about this new sessmgr instance ID created by UPF from 21 to 25 and in such a case sessmgr with this instance IDs :: 21/22/23/24/25 will not be able to form any TCP peer connection with RCM redmgr leading to no checkpoint sync and since there won’t be any checkpoint sync sessmgr will get stuck into server mode and won’t take any traffic.
Refer this diagram
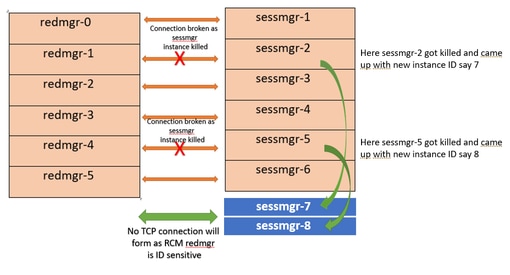
Both this sessmgr instance-7/8 have no TCP peer connection since for RCM redmgr-1 was
connected with instance-2 and redmgr-2 was connected to instance-5 so even though sessmgr
came up with new instance ID value which is beyond defined limit it wont have connection
back with redmgrs which is still just pointing to previous instance but connection is broken
Problemumgehung
Die Lösung für dieses Problem besteht darin, die Anzahl der Sessmgr-Instanz-IDs auf die Anzahl der Sessmgrs in UPF und die Anzahl der Redmgrs im RCM zu begrenzen, wie durch den genannten Befehl angegeben.
Max value of sessmgr instance ID = no of checkpointmgr – 1
Entsprechend dieser Logik muss die Anzahl der Sessmgrs definiert werden, einschließlich der Standby-Sessmgrs.
task facility sessmgr max <no of max sessmgrs>
Note :: Implementation of this command needs node reload to enable full functionality of this command
Wenn dieser Befehl ausgeführt wird, wird unabhängig davon, wie oft sessmgr abgesetzt wird, immer ein Wert für die Instanz-ID generiert, der kleiner oder gleich der maximalen Anzahl von sessmgr ist. Dies hilft, Checkpointprobleme mit dem RCM zu vermeiden und verhindert, dass sessmgr aus diesem Grund in den Servermodus wechselt.
 Feedback
Feedback