Ersatz des OSPD-Servers UCS 240M4 - vEPC
Download-Optionen
-
ePub (955.9 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einführung
In diesem Dokument werden die erforderlichen Schritte beschrieben, um einen fehlerhaften Server zu ersetzen, der den OpenStack Platform Director (OSPD) in einer Ultra-M-Konfiguration hostet.
Hintergrundinformationen
Ultra-M ist eine vorkonfigurierte und validierte Kernlösung für virtualisierte mobile Pakete, die die Bereitstellung von VNFs vereinfacht. OpenStack ist der Virtualized Infrastructure Manager (VIM) für Ultra-M und besteht aus den folgenden Knotentypen:
- Computing
- Object Storage Disk - Computing (OSD - Computing)
- Controller
- OSPD
Die High-Level-Architektur von Ultra-M und die beteiligten Komponenten sind in diesem Bild dargestellt:
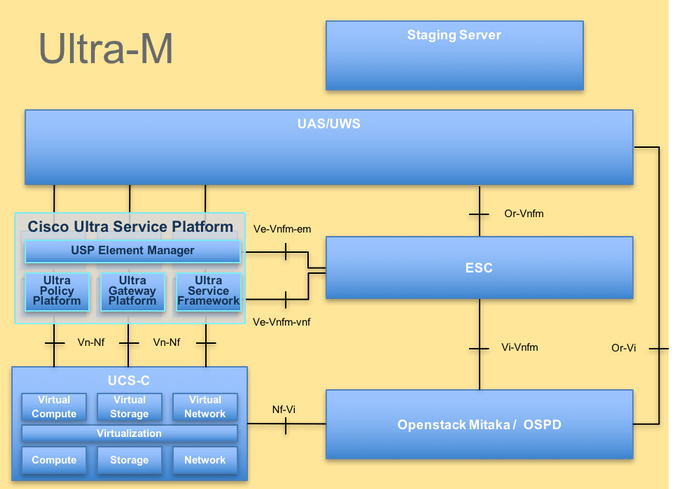 UltraM-Architektur
UltraM-Architektur
Dieses Dokument richtet sich an Mitarbeiter von Cisco, die mit der Cisco Ultra-M-Plattform vertraut sind. Es beschreibt die Schritte, die erforderlich sind, um auf der OpenStack-Ebene beim Austausch des OSPD-Servers ausgeführt zu werden.
Hinweis: Ultra M 5.1.x wird zur Definition der Verfahren in diesem Dokument berücksichtigt.
Abkürzungen
| VNF | Virtuelle Netzwerkfunktion |
| CF | Kontrollfunktion |
| SF | Servicefunktion |
| WSA | Elastic Service Controller |
| MOP | Verfahrensweise |
| OSD | Objektspeicherdatenträger |
| HDD | Festplattenlaufwerk |
| SSD | Solid-State-Laufwerk |
| VIM | Virtueller Infrastrukturmanager |
| VM | Virtuelles System |
| EM | Element Manager |
| USA | Ultra-Automatisierungsservices |
| UUID | Universell eindeutige IDentifier |
Workflow des MoP
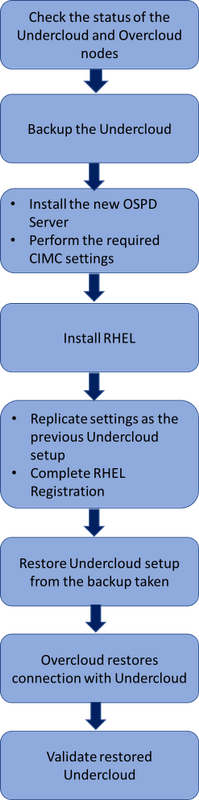 Umfassender Workflow des Austauschverfahrens
Umfassender Workflow des Austauschverfahrens
Voraussetzungen
Statusprüfung
Bevor Sie einen OSPD-Server ersetzen, ist es wichtig, den aktuellen Zustand der Red Hat OpenStack Platform-Umgebung zu überprüfen und sicherzustellen, dass dieser fehlerfrei ist, um Komplikationen zu vermeiden, wenn der Austauschprozess eingeschaltet ist.
Überprüfen Sie den Status des OpenStack-Stacks und der Knotenliste:
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
Stellen Sie sicher, dass alle unterCloud-Services über den OSP-D-Knoten in den Status "geladen", "aktiv" und "ausgeführt" verwickelt sind:
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
Sicherung
Stellen Sie sicher, dass genügend Speicherplatz zur Verfügung steht, bevor Sie den Backup-Vorgang durchführen. Dieser Tarball soll mindestens 3,5 GB umfassen.
[stack@director ~]$df -h
Führen Sie diesen Befehl als Root-Benutzer aus, um die Daten vom unterCloud-Knoten in eine Datei mit dem Namen undercloud-backup-[timestamp].tar.gz zu sichern.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Neuen OSPD-Knoten installieren
UCS-Serverinstallation
Die Schritte zur Installation eines neuen UCS C240 M4 Servers sowie die Schritte zur Ersteinrichtung können im Cisco UCS C240 M4 Server Installations- und Serviceleitfaden beschrieben werden.
Melden Sie sich mit der CIMC IP-Adresse beim Server an.
Führen Sie ein BIOS-Upgrade durch, wenn die Firmware nicht der zuvor verwendeten empfohlenen Version entspricht. Schritte für BIOS-Upgrades finden Sie hier: BIOS-Upgrade-Leitfaden für Cisco UCS Rackmount-Server der C-Serie.
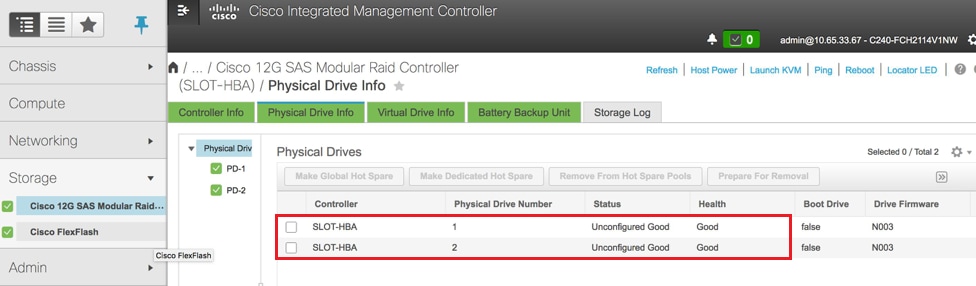
Überprüfen Sie den Status der physischen Laufwerke. Es muss nicht konfiguriert sein Gut:
Navigieren Sie zu Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info (Informationen zum physischen Laufwerk), wie hier im Bild gezeigt.
Erstellen Sie eine virtuelle Festplatte von den physischen Laufwerken mit RAID Level 1:
Navigieren Sie zu Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives (Virtuelles Laufwerk aus nicht verwendeten physischen Laufwerken erstellen), wie im Bild gezeigt.
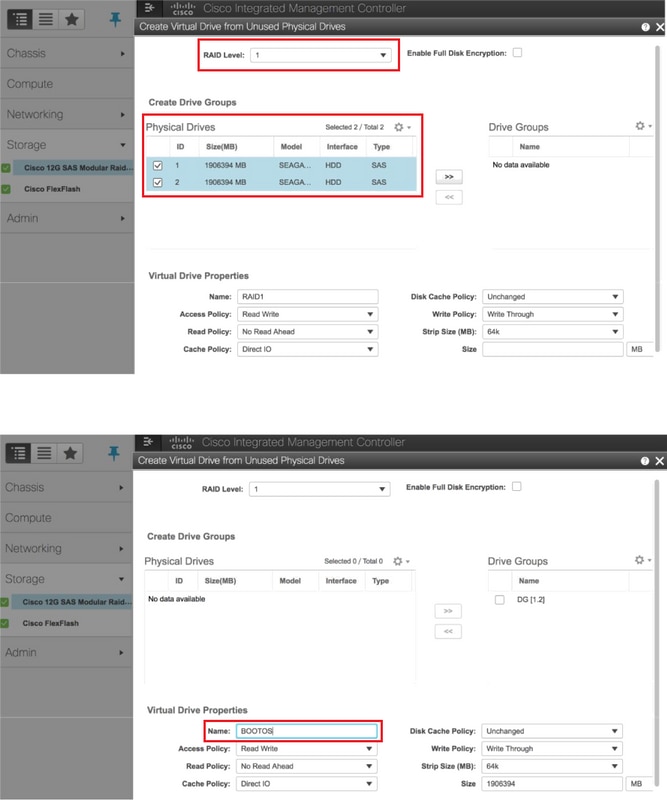
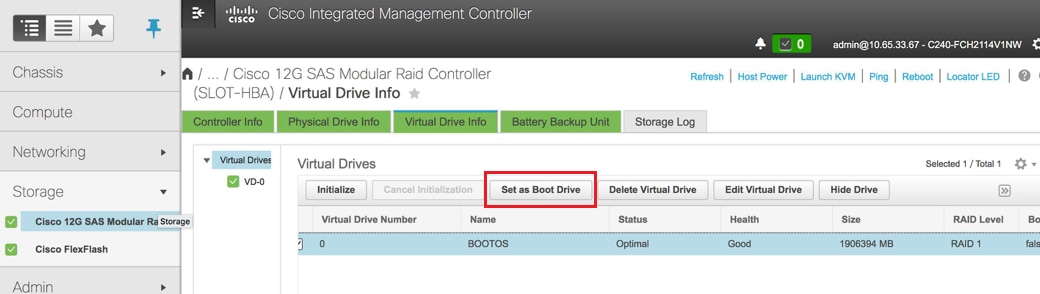
Wählen Sie die VD aus, und konfigurieren Sie Set as Boot Drive (Als Startlaufwerk festlegen) wie im Bild gezeigt.
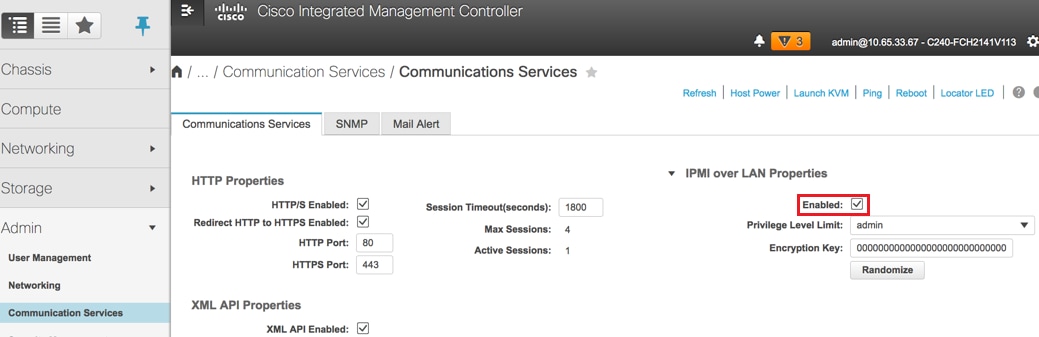
IPMI over LAN aktivieren:
Navigieren Sie zu Admin > Communication Services > Communication Services (Verwaltung > Kommunikationsdienste > Kommunikationsdienste), wie im Bild gezeigt.
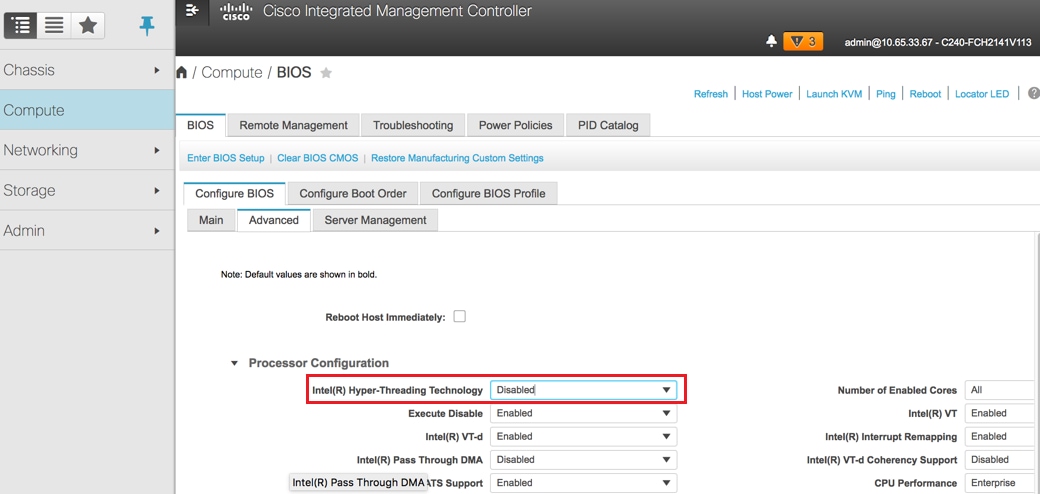
Hyperthreading deaktivieren:
Navigieren Sie zu Compute > BIOS > Configure BIOS > Advanced > Processor Configuration wie im Bild gezeigt.
Hinweis: Das hier abgebildete Image und die in diesem Abschnitt beschriebenen Konfigurationsschritte beziehen sich auf die Firmware-Version 3.0(3e). Wenn Sie an anderen Versionen arbeiten, kann es zu geringfügigen Abweichungen kommen.
Red Hat-Installation
Mount the Red Hat ISO Image
1. Melden Sie sich beim OSP-D-Server an.
2. Starten Sie die KVM Console.
3. Navigieren zu Virtual Media > Virtuelle Geräte aktivieren. Akzeptieren Sie die Sitzung, und aktivieren Sie das Speichern Ihrer Einstellung für zukünftige Verbindungen.
4. Auswählen Virtual Media > Karte CD/DVDund ordnen Sie das Red Hat ISO-Image zu.
5. Auswählen Stromversorgung > System zurücksetzen (Warmstart) um das System neu zu starten.
6. Drücken Sie nach dem Neustart die F6und wählen Sie Cisco vKVM-Mapped vDVD1.22und drücken Sie Geben Sie ein.
Installieren von Red Hat Enterprise Linux
Hinweis: Die Prozedur in diesem Abschnitt stellt eine vereinfachte Version des Installationsprozesses dar, die die Mindestanzahl der zu konfigurierenden Parameter angibt.
1. Wählen Sie die Option Red Hat Enterprise Linux (RHEL) zu installieren, um mit der Installation zu beginnen.
2. Wählen Sie Softwareauswahl > Nur Mindestinstallation aus.
3. Konfigurieren von Netzwerkschnittstellen (eno1 und eno2)
4. Klicken Sie auf Netzwerk und Hostname.
- Wählen Sie die Schnittstelle aus, die für die externe Kommunikation verwendet wird (entweder eno1 oder eno2).
- Klicken Sie auf Konfigurieren
- Wählen Sie die IPv4-Einstellungstab aus, wählen Sie die manuelle Methode aus, und klicken Sie auf Hinzufügen
- Legen Sie die folgenden Parameter wie zuvor fest: Adresse, Netzmaske, Gateway, DNS-Server
5. Wählen Sie Datum und Uhrzeit aus, und geben Sie Ihre Region und Ihre Stadt an.
6. Aktivieren Sie die Netzwerkzeit, und konfigurieren Sie NTP-Server.
7. Wählen Sie Installationsziel aus, und verwenden Sie das ext4-Dateisystem.
Hinweis: Löschen /Zuhause/und Neuzuweisen der Kapazität unter Root /.
8. Deaktivieren Sie Kdump.
9. Nur Root-Kennwort festlegen.
10. Beginnen Sie mit der Installation.
Wiederherstellen der Untercloud
Untercloud-Installation basierend auf Backup vorbereiten
Wenn der Computer mit RHEL 7.3 installiert wurde und sich in einem sauberen Zustand befindet, aktivieren Sie alle Abonnements/Repositories, die für die Installation und Ausführung von Director erforderlich sind, erneut.
Hostnamenkonfiguration:
[root@director ~]$sudo hostnamectl set-hostname <FQDN_hostname>
[root@director ~]$sudo hostnamectl set-hostname --transient <FQDN_hostname>
Datei bearbeiten /etc/hosts:
[root@director ~]$ vi /etc/hosts
<ospd_external_address> <server_hostname> <FQDN_hostname>
10.225.247.142 pod1-ospd pod1-ospd.cisco.com
Hostnamen validieren:
[root@director ~]$ cat /etc/hostname
pod1-ospd.cisco.com
DNS-Konfiguration validieren:
[root@director ~]$ cat /etc/resolv.conf
#Generated by NetworkManager
nameserver <DNS_IP>
Ändern Sie die Bereitstellungsnic-Schnittstelle:
[root@director ~]$ cat /etc/sysconfig/network-scripts/ifcfg-eno1
DEVICE=eno1
ONBOOT=yes
HOTPLUG=no
NM_CONTROLLED=no
PEERDNS=no
DEVICETYPE=ovs
TYPE=OVSPort
OVS_BRIDGE=br-ctlplane
BOOTPROTO=none
MTU=1500
Schließen Sie die Red Hat-Registrierung ab
Laden Sie dieses Paket herunter, um den Abonnement-Manager so zu konfigurieren, dass rh-satellit verwendet wird:
[root@director ~]$ rpm -Uvh http:///pub/katello-ca-consumer-latest.noarch.rpm
[root@director ~]$ subscription-manager config
Registrieren Sie sich mit diesem Aktivierungsschlüssel für RHEL 7.3 beim rh-satelliten.
[root@director ~]$subscription-manager register --org="<ORG>" --activationkey="<KEY>"
So zeigen Sie das Abonnement an:
[root@director ~]$ subscription-manager list –consumed
Aktivieren Sie die Repositorys ähnlich den alten OSPD-Repos:
[root@director ~]$ sudo subscription-manager repos --disable=*
[root@director ~]$ subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rh
el-7-server-openstack-10-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpm
Führen Sie ein Update Ihres Systems durch, um sicherzustellen, dass Sie die neuesten Basissystem-Pakete haben, und starten Sie das System neu:
[root@director ~]$sudo yum update -y
[root@director ~]$sudo reboot
UnterCloud-Wiederherstellung
Nachdem Sie das Abonnement aktiviert haben, importieren Sie die gesicherte Undercloud-TAR-Datei unter Cloud-backup-date +%F`.tar.gz in das neue OSP-D-Serverroot-Verzeichnis /root.
Installieren Sie den Mariadb-Server:
[root@director ~]$ yum install -y mariadb-server
Extrahieren Sie die MariaDB-Konfigurationsdatei und die Datenbank-Sicherung. Führen Sie diesen Vorgang als root-Benutzer aus.
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/my.cnf.d/server.cnf
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz root/undercloud-all-databases.sql
Bearbeiten Sie /etc/my.cnf.d/server.cnf, und kommentieren Sie ggf. den Eintrag für bind-address:
[root@tb3-ospd ~]# vi /etc/my.cnf.d/server.cnf
Starten Sie den MariaDB-Dienst, und aktualisieren Sie vorübergehend die Einstellung max_allowed_paket:
[root@director ~]$ systemctl start mariadb
[root@director ~]$ mysql -uroot -e"set global max_allowed_packet = 16777216;"
Bereinigen bestimmter Berechtigungen (wird später neu erstellt):
[root@director ~]$ for i in ceilometer glance heat ironic keystone neutron nova;do mysql -e "drop user $i";done
[root@director ~]$ mysql -e 'flush privileges'
Hinweis: Wenn der Dienst Deckenmesser zuvor in der Konfiguration deaktiviert wurde, führen Sie diesen Befehl aus, und entfernen Sie den Deckenmesser.
Erstellen Sie das Stackuser-Konto:
[root@director ~]$ sudo useradd stack
[root@director ~]$ sudo passwd stack << specify a password
[root@director ~]$ echo "stack ALL=(root) NOPASSWD:ALL" | sudo tee -a /etc/sudoers.d/stack
[root@director ~]$ sudo chmod 0440 /etc/sudoers.d/stack
Stellen Sie das Stammverzeichnis des Stapelbenutzers wieder her:
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz home/stack
Installieren Sie die Pakete "swift" und "glance", und stellen Sie dann die zugehörigen Daten wieder her:
[root@director ~]$ yum install -y openstack-glance openstack-swift
[root@director ~]$ tar --xattrs -xzC / -f undercloud-backup-$DATE.tar.gz srv/node var/lib/glance/images
Bestätigen Sie, dass die Daten dem richtigen Benutzer gehören:
[root@director ~]$ chown -R swift: /srv/node
[root@director ~]$ chown -R glance: /var/lib/glance/images
Stellen Sie die SSL-Zertifikate unter der Cloud wieder her (optional - nur bei Verwendung von SSL-Zertifikaten).
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/instack-certs/undercloud.pem
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/ca-trust/source/anchors/ca.crt.pem
Führen Sie die Undercloud-Installation erneut als Stackuser aus und stellen Sie sicher, dass sie im Stack-Benutzer-Home-Verzeichnis ausgeführt wird:
[root@director ~]$ su - stack
[stack@director ~]$ sudo yum install -y python-tripleoclient
Vergewissern Sie sich, dass der Hostname korrekt in /etc/hosts eingestellt ist.
Installieren Sie die Untercloud neu:
[stack@director ~]$ openstack undercloud install
<snip>
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and must be
secured.
#############################################################################
Schließen Sie die Wiederhergestellte Undercloud wieder an die Overcloud an.
Wenn Sie diese Schritte abgeschlossen haben, kann davon ausgegangen werden, dass die Unterwolke ihre Verbindung automatisch wieder in die Cloud einstellt. Die Knoten werden weiterhin Orchestrierung (Wärme) für ausstehende Aufgaben abfragen, wobei eine einfache HTTP-Anfrage verwendet wird, die alle paar Sekunden erstellt wird.
Überprüfen der abgeschlossenen Wiederherstellung
Verwenden Sie diese Befehle, um eine Integritätsprüfung der neu wiederhergestellten Umgebung durchzuführen:
[root@director ~]$ su - stack
Last Log in: Tue Nov 28 21:27:50 EST 2017 from 10.86.255.201 on pts/0
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| b1f5294a-629e-454c-b8a7-d15e21805496 | pod1-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.119 |
| 9106672e-ac68-423e-89c5-e42f91fefda1 | pod1-compute-1 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
| b3ed4a8f-72d2-4474-91a1-b6b70dd99428 | pod1-compute-2 | ACTIVE | - | Running | ctlplane=192.200.0.124 |
| 677524e4-7211-4571-ac35-004dc5655789 | pod1-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.107 |
| 55ea7fe5-d797-473c-83b1-d897b76a7520 | pod1-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.122 |
| c34c1088-d79b-42b6-9306-793a89ae4160 | pod1-compute-5 | ACTIVE | - | Running | ctlplane=192.200.0.108 |
| 4ba28d8c-fb0e-4d7f-8124-77d56199c9b2 | pod1-compute-6 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| d32f7361-7e73-49b1-a440-fa4db2ac21b1 | pod1-compute-7 | ACTIVE | - | Running | ctlplane=192.200.0.106 |
| 47c6a101-0900-4009-8126-01aaed784ed1 | pod1-compute-8 | ACTIVE | - | Running | ctlplane=192.200.0.121 |
| 1a638081-d407-4240-b9e5-16b47e2ff6a2 | pod1-compute-9 | ACTIVE | - | Running | ctlplane=192.200.0.112 |
<snip>
[stack@director ~]$ ssh heat-admin@192.200.0.107
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.1.10.10 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.97 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-192.200.0.106 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.95 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.98 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.92 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Stopped
Failed Actions:
* my-ipmilan-for-controller-0_start_0 on pod1-controller-1 'unknown error' (1): call=190, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-1 'unknown error' (1): call=192, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-1 'unknown error' (1): call=188, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-0 'unknown error' (1): call=210, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-0 'unknown error' (1): call=207, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-0 'unknown error' (1): call=206, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20006ms
* ip-192.200.0.106_monitor_10000 on pod1-controller-0 'not running' (7): call=197, status=complete, exitreason='none',
last-rc-change='Wed Nov 22 13:51:31 2017', queued=0ms, exec=0ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-2 'unknown error' (1): call=183, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=1ms, exec=20006ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-2 'unknown error' (1): call=184, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-2 'unknown error' (1): call=177, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:02 2017', queued=0ms, exec=20005ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[heat-admin@pod1-controller-0 ~]$ sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v1245812: 704 pgs, 6 pools, 542 GB data, 352 kobjects
1625 GB used, 11767 GB / 13393 GB avail
704 active+clean
client io 21549 kB/s wr, 0 op/s rd, 120 op/s wr
Identitätsdienst (Keystone) überprüfen
In diesem Schritt werden Identitätsdienstvorgänge validiert, indem nach einer Liste von Benutzern abgefragt wird.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack user list
+----------------------------------+------------------+
| ID | Name |
+----------------------------------+------------------+
| 69ac2b9d89414314b1366590c7336f7d | admin |
| f5c30774fe8f49d0a0d89d5808a4b2cc | glance |
| 3958d852f85749f98cca75f26f43d588 | heat |
| cce8f2b7f1a843a08d0bb295a739bd34 | ironic |
| ce7c642f5b5741b48a84f54d3676b7ee | ironic-inspector |
| a69cd42a5b004ec5bee7b7a0c0612616 | mistral |
| 5355eb161d75464d8476fa0a4198916d | neutron |
| 7cee211da9b947ef9648e8fe979b4396 | nova |
| f73d36563a4a4db482acf7afc7303a32 | swift |
| d15c12621cbc41a8a4b6b67fa4245d03 | zaqar |
| 3f0ed37f95544134a15536b5ca50a3df | zaqar-websocket |
+----------------------------------+------------------+
[stack@director ~]$
[stack@director ~]$ source <overcloudrc>
[stack@director ~]$ openstack user list
+----------------------------------+------------+
| ID | Name |
+----------------------------------+------------+
| b4e7954942184e2199cd067dccdd0943 | admin |
| 181878efb6044116a1768df350d95886 | neutron |
| 6e443967ee3f4943895c809dc998b482 | heat |
| c1407de17f5446de821168789ab57449 | nova |
| c9f64c5a2b6e4d4a9ff6b82adef43992 | glance |
| 800e6b1163b74cc2a5fab4afb382f37d | cinder |
| 4cfa5a2a44c44c678025842f080e5f53 | heat-cfn |
| 9b222eeb8a58459bb3bfc76b8fff0f9f | swift |
| 815f3f25bcda49c290e1b56cd7981d1b | core |
| 07c40ade64f34a64932129175150fa4a | gnocchi |
| 0ceeda0bc32c4d46890e53adef9a193d | aodh |
| f3caab060171468592eab376a94967b8 | ceilometer |
+----------------------------------+------------+
[stack@director ~]$
Bilder hochladen, um zukünftigen Node-Überblick zu erhalten
Validieren Sie /httpboot und alle diese Dateien inspector.ipxe, agent.kernel, agent.ramdisk, wenn Sie nicht mit diesen Schritten fortfahren.
[stack@director ~]$ ls /httpboot
inspector.ipxe
[stack@director ~]$ source stackrc
[stack@director ~]$ cd images/
[stack@director images]$ openstack overcloud image upload --image-path /home/stack/images
Image "overcloud-full-vmlinuz" is up-to-date, skipping.
Image "overcloud-full-initrd" is up-to-date, skipping.
Image "overcloud-full" is up-to-date, skipping.
Image "bm-deploy-kernel" is up-to-date, skipping.
Image "bm-deploy-ramdisk" is up-to-date, skipping.
[stack@director images]$ ls /httpboot
agent.kernel agent.ramdisk inspector.ipxe
[stack@director images]$
Neustarten der Wiedergabe
Nach der OSPD-Wiederherstellung wird die Fenzierung gestoppt. Dieses Verfahren wird eine Zähmung ermöglichen.
[heat-admin@pod1-controller-0 ~]$ sudo pcs property set stonith-enabled=true
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
[heat-admin@pod1-controller-0 ~]$sudo pcs stonith show
Zugehörige Informationen
Beiträge von Cisco Ingenieuren
- Padmaraj RamanoudjamCisco Advanced Services
- Partheeban RajagopalCisco Advanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)