Introduction
This document describes how to troubleshoot common reasons for the Server Inaccessible fault that can be seen for most types of UCS Servers.
Prerequisites
Requirements
Cisco recommends you have knowledge of managing servers in Unified Computing System Manager (UCSM) and Intersight Managed Mode (IMM).
Components Used
This document is not restricted to specific software and hardware versions.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
Background Information
There is a common fault users can receive in their UCS domain and that is to notify you that a server is inaccessible. This can be for a number of reasons and the fault can look a few different ways depending on monitoring tools and UCSM/IMM versions.
System Notification from [UCSM Domain Name] - diagnostic:GOLD-minor - 2023-05-25 01:56:41 GMT-04:00 Recovered : Server x/y (service profile: org-root/ls-[service_profile]) inaccessible
Serial number: [Server Serial]
Alert: System Name: [UCSM Domain Name]
Time of Event:2022-08-31 03:15:04 GMT-05:00 Event Description:Server x (service profile: org-root/ls-[service_profile]) inaccessible Severity Level:4
If IMM is in use, a Connection to Server was lost message can possibly be seen in the GUI. Disconnection from Intersight faults can also be observed.
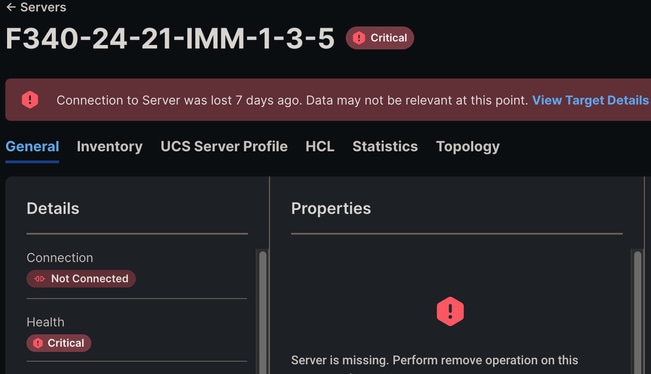 Connection to Server Was Lost IMM
Connection to Server Was Lost IMM
This alert can be seen when the Cisco Integrated Management Controller (CIMC) on a blade encounters an issue and either reboots or attempts to reboot. This triggers a Server Inaccessible alert because while the management plane of the blade is rebooting, UCSM/IMM can not communicate with the blade thus it thinks it is inaccessible. Once the CIMC reboots, the blades state returns to normal.
This is why you can receive this alert, then when you check the domain, the server looks up and healthy.
Common Defect Reference
Cisco bug ID CSCwe19822 - Applies to M5/M6 servers after 4.2(2c)/After 5.0(1c) for X series
Cisco bug ID CSCwa85667 - Applies to M5/M6 servers between 4.1(3e) - 4.2(2a) Also includes X series after 5.0(1b)
Cisco bug ID CSCvz62711 - Applies to M5/M6 servers between 4.1(3d) - 4.2(2a)
Cisco bug ID CSCwi50991 - Applies to M5/M6 Series blades on code before 4.3(2e)
Cisco bug ID CSCvv79912 - Applies to M5/M6 servers between 4.0(4h) and 4.2(1a)/4.1(3d)
Cisco bug ID CSCvh25786 - Applies to M4/M5 servers after 2.0(13f) and 3.0(4a)
Troubleshooting
Scenario 1
The first and most common situation is receiving the alert then when checking UCSM/IMM the server appears operable, healthy, and with no (new) faults. When checking the operating system, it appears to have been up and running with no disruptions.
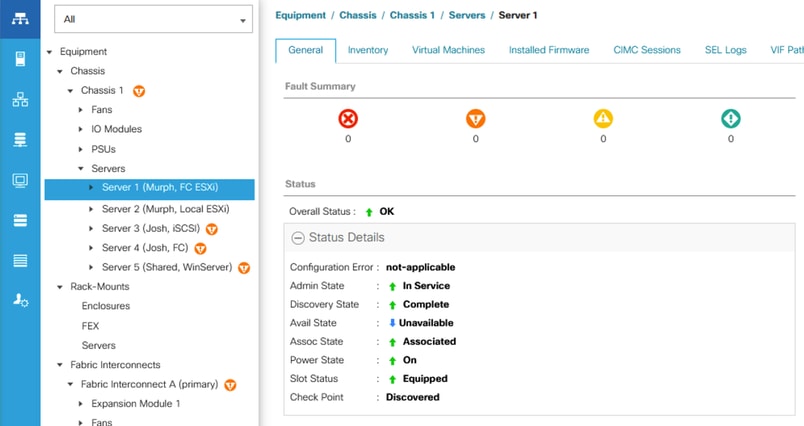 Healthy Server in UCSM
Healthy Server in UCSM
Log bundles show this message in one of the OBFL logs that can be found at CIMCx_TechSupport.tar.gz > obfl > obfl-log.
3:2022 Sep 8 10:54:33 UTC:+0000:(4.2(2d)):kernel:-:[watchdog_init]:976:BMC Watchdog resetted BMC.
This tells us that CIMC crashed and rebooted on its own.
In this scenario, no further action is required as CIMC successfully rebooted and there are no problems with the server.
Scenario 2
The next situation is receiving the alert then when checking UCSM/IMM the server still shows as inaccessible if using UCSM or disconnected if using IMM. When checking the operating system, it appears to be up and running with no disruptions.
As the OS is up and running but UCSM/IMM cant communicate with the blade, that means CIMC either did not reboot or stalled in the process.
The first step in this scenario is to SSH or Console to the Fabric Interconnects (FI) and run this command replacing x/y with the affected chassis/blade. There are three different outcomes.
1) Connection to CIMC is successful.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
Trying 127.5.1.1...
Connected to 127.5.1.1.
Escape character is '^]'.
CIMC Debug Firmware Utility Shell [ support ]
[ help ]#
If this output is seen, then there is still some life on CIMC and you can try resetting CIMC to recover the blade.
If UCSM is in use, navigate to Equipment > Chassis > Chassis Number > Servers > Server Number > Recover Server > Reset CIMC.
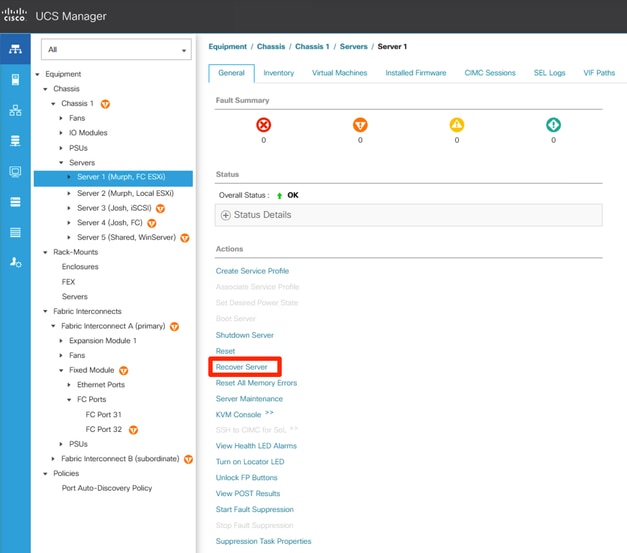 Location of Recover Server for Blade
Location of Recover Server for Blade
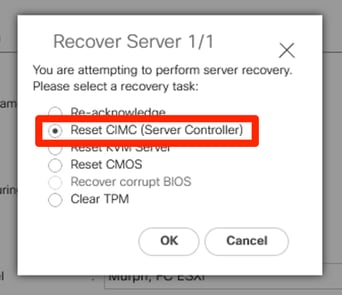 Reset CIMC
Reset CIMC
If IMM is in use, navigate to the affected server and select Actions > System > Reboot Management Controller.
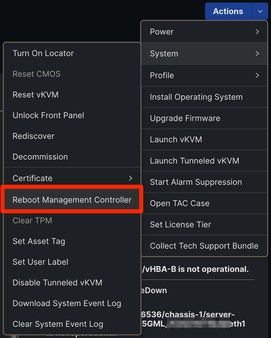 Reboot Management Controller IMM
Reboot Management Controller IMM
If after rebooting CIMC the server returns to normal, then the issue is resolved and no further action is required.
If the fault persists, proceed with the troubleshooting steps of the next connect cimc output.
2) Connection to CIMC fails.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
Trying 127.5.1.8...
telnet: Unable to connect to remote host: No route to host
3) Connection to CIMC stalls. In this case, nothing happens after running the command and when trying to escape (Ctrl + C) this is observed.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
^C
Console escape. Commands are:
l go to line mode
c go to command mode
z suspend telnet
e exit telent
continuing...
The troubleshooting for either of the last two outputs is the same. In these cases CIMC is completely down and unable to communicate with the Fabric Interconnects. A reboot of the server is required to recover CIMC. It is always recommended to take a maintenance window when rebooting blades.
If UCSM is in use, you can simulate physically reseating the blade by SSHing to the Fabric Interconnects and running this command replacing x/y with the affected chassis/server. It is imperative you enter the correct chassis/server as this command does not prompt you for confirmation.
UCSM-A# reset slot x/y

Note: The reset slot command reboots the blade in the designated slot x/y immediately. Please ensure the sever is safe to reboot if the OS is still running.
This command does not return anything if successful. If the command failed to execute, a message is shown.
If IMM is in use, or the reset slot command did not resolve the inaccessible issue, then the only other option is to physically reseast the blade.
If after physically reseating the blade, the issue continues contact TAC for further troubleshooting.
Scenario 3
The final situation is receiving the alert then when checking UCSM/IMM the server still shows as inaccessible if using UCSM or disconnected if using IMM. When checking the operating system, it is down and also inaccessible.
In this situation, all that can be done is a reboot of the server. If a reboot is not possible, then physically reseat the server.
If after physically reseating the blade, the issue continues contact TAC for further troubleshooting.
Conclusion
There can be many reasons to receive Server Inaccessible faults, some more impactful than others. The steps here are a good place to start to assess if any troubleshooting is required or if your domain is healthy and no action is needed.
 Feedback
Feedback