Understanding and Troubleshooting Astro/Lemans/NiceR Timeouts on Catalyst 4000/4500 Series Switches
Available Languages
Contents
Introduction
The Catalyst 4000/4500 switch series uses a stub ASIC design in the switch architecture. Switch manages these linecard stub ASICs (Astro/Leman/NiceR) through internal management control protocol. When these internal management requests and responses are lost or delayed, console and syslog messages are generated. Since the reasons for these losses of communication vary, the root cause is not obvious with these error messages.
The intention of this document is to help understand the Astro/Leman/Nicer Timeout message generated on the Cat4000 platform and to resolve them with assistance from Cisco TAC. Future versions of CatOS and Cisco IOS® will offer improved error messages, and if possible, identify the root cause of the problem.
When stub ASIC (Astro/Lemans/Nicer) timeout occurs, messages similar to following get reported on a CatOS based Catalyst 4000/4500 switch:
%SYS-4-P2_WARN: 1/Astro(4/3) - timeout occurred %SYS-4-P2_WARN: 1/Astro(4/3) - timeout is persisting
Please note that depending upon the software versions, the wording of the error message may vary. Astro, Lemans and Nicer refer to different type of stub ASIC. More details is described in the Background Theory section of this document.
For Cisco IOS based Supervisors (Supervisor II+, III and IV), the error message appears as follows:
%C4K_LINECARDMGMTPROTOCOL-4-INITIALTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - management request timed out. %C4K_LINECARDMGMTPROTOCOL-4-ONGOINGTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - consecutive management requests timed out.
Note: This document primarily addresses troubleshooting on CatOS-based Supervisors or switches. Some of the information is applicable to Cisco IOS based Supervisor when noted.
Note: This document also addresses Astro stub ASIC, but most of the sections are applicable to other type of stub ASIC (Lemans and Nicer) line cards and as such will be noted in appropriate sections.
After reading this document, the reader will understand the following:
-
The function of stub ASICs in the Catalyst 4000/4500.
-
The conditions that may lead to the internal management packets timeouts messages.
-
The steps to take and commands to gather for Cisco TAC when troubleshooting this condition.
The Astro timeout and troubleshooting sections provides background and detailed explanation about each issue. Alternatively, one may jump directly to the Simple Ways to Troubleshoot section of this document.
Before You Begin
Conventions
For more information on document conventions, see the Cisco Technical Tips Conventions.
Prerequisites
There are no specific prerequisites for this document.
Components Used
This document is specific to Catalyst 4000/4500 Supervisor or line-cards using stub ASICs.
Background Theory
Astro stub ASIC refers to the 10/100 stub ASICs controls a group of eight adjacent 10/100 ports communicating to the Supervisor through a Gigabit bandwidth connection to the backplane, as shown in Figure below.
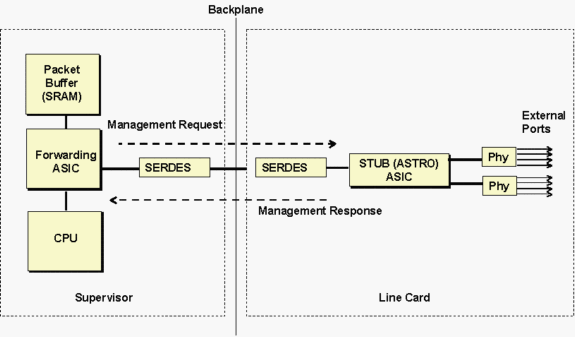
The Supervisors communicate to the Line Card stub ASIC through the SERDES (SERealizer-DESerializer) component. There is a SERDES component on the Supervisor side connecting to the backplane and another SERDES on the line card for each stub ASIC for connecting to the backplane.
The above diagram can be used in general to troubleshoot different type of line cards. The stub ASIC referred in the timeout messages would be different depending on the type of line card. See the table below for a list of ASIC names and their description.
| Stub ASICs | Description | Example |
|---|---|---|
| Astro | 8 port 10/100 controller stub ASIC | WS-X4148-RJ45V |
| NiceR | 4 port 1000 controller stub ASIC | WS-X4418-GB(ports 3-18) |
| Lemans | 8 port 10/100/1000 controller stub ASIC | WS-X4448-GB-RJ |
The internal management traffic flows through both the SERDES component along with the normal data traffic. The internal management traffic is used to read/write the stub ASIC and Phy registers. The most common operations include reading link status and statistics.
Simple Ways to Troubleshoot
The following sections explain the meaning and possible causes of the %SYS-4-P2_WARN: 1/(Stub)(module_number/) Stub_reference – timeout occurred error message on the Catalyst 4000/4500.
The Astro (stub) timeout messages were added to software version starting in 6.2.3 and 6.3.1 and later enhanced in 6.4.4 (CSCea73908) to indicate that Supervisor has lost internal management control packets in communicating to the Astro stub ASIC on a 10/100 line cards. There are multiple causes for this loss of communication as explained in detail in the Troubleshooting section below.
The following troubleshooting flowchart presents a quick and easy way to isolate the problem between the possible root-causes:
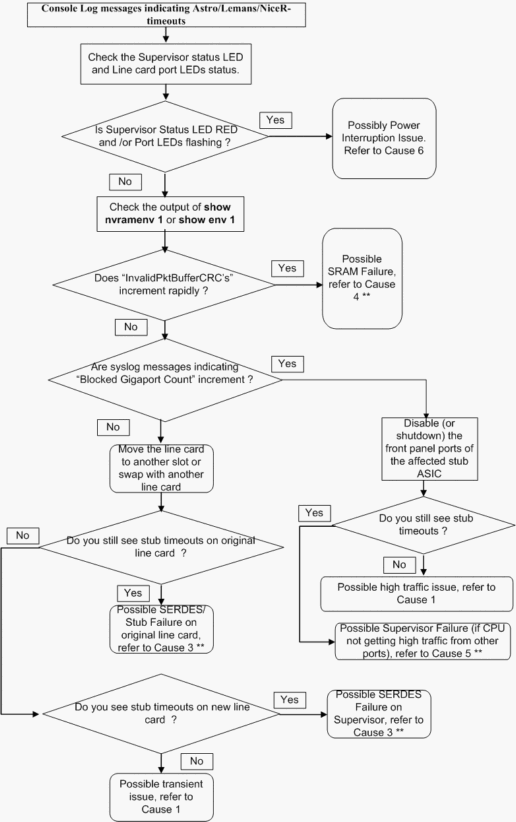
** Various root causes may exhibit similar symptoms. Please contact TAC for further troubleshooting.
Stub (Astro/Lemans/NiceR) ASIC Timeouts
Astro/Lemans/Nicer timeouts are reported when the Supervisor software does not receive multiple internal management responses from the line card stub ASIC. This can happen if:
-
Management request is lost or delayed
-
Management response is lost or delayed
A“timeout occurred…” message is printed once the software has timed out 10 consecutive times while waiting for the management packet response. The consequent timeouts result in printing “consecutive management ….” or “..timeout persisting..” messages, depending upon the version of the software.
This log message is rate-limited to once per 10 minutes. The packet forwarding to the affected stub ASICs continues when the timeouts are occurring. However any changes to the link / autoneg speed / duplex are not seen as the software does not receive the management packet responses. Also, the process of updating of traffic statistics for the group of interface is affected when timeouts occur.
Troubleshooting
There are various causes for the Astro/Lemans/Nicer timeout messages to appear. Each are described below.
Cause 1: High Traffic Load, Layer 2 Loop, or Excessive Network Traffic Towards CPU
The following can cause stub timeout conditions:
-
Network problems
-
Configuration problems
-
Neighbor elements
-
Other factors outside of a Catalyst switch
Layer 2 Loop or broadcast storm that results in high traffic load may causes loss of internal management control packets. This usually happens due to the CPU being busy (CPU hog) and not able to process its queues.
Internal management control traffic takes the same data path to the Supervisor as normal data traffic from the Astro (or any other Stub chip). Thus, the control packets may get lost due to congestion.
With the fix for Cisco bug ID CSCea73908 (registered customers only) , internal management request timeout period is handled better in CatOS version 6.4(4) and later releases. This enhancement may prevent many transient control packets timeouts caused by the CPU being busy.
Action: Troubleshoot the Layer 2 Loop; or change configuration to resolve traffic patterns.
Workaround: Move the switch management interface (sc0) to non-user traffic VLAN on CatOS based switches. Use the set interface sc0 <vlan-id> command to move the vlan of the interface sc0.
Note: Starting with Cisco IOS 12.1(20)EW, Cisco IOS based Supervisors introduces an enhanced in handling of the internal management packet handling mechanism by the CPU. This enhancement will help to prevent loss of internal management control packets due to inadvertent low priority traffic hogging the CPU.
Solution: See workaround above.
Cause 2: Half Duplex/ Type 1A Cabling
Front panel user ports are configured in half-duplex. The collisions of the outgoing traffic with the incoming traffic at the stub ASIC may cause the stub buffer to drain very slowly. This can cause tx-queues on Supervisor to fill up and new internal management requests could be dropped which would result in timeout error messages.
A network with Type1A cabling can also cause this problem. When a workstation connected to a Type1A Baluns with an RJ-45 patch is disconnected, the Balun loops back internally and causes the outgoing traffic to return. This situation simulates connecting an external loopback on the front-panel port. Before the port moves to blocking state, outgoing traffic is looped back into the switch. This can cause the stub buffers to overflow, depending on the rate of traffic.
Action: See workaround.
Workaround: Avoid half-duplex configuration. In the case of Type1A cabling, avoid plugging out the RJ-45 patch cord from the Type 1A Balun to avoid forming an internal loopback in the Balun.
Solution: See workaround.
Cause 3: SERDES Component Failure
If the errors are seen only on one Astro (or other stub ASIC) on one module, and a layer 2 loop is not occurring, the problem is most likely a faulty SERDES component on either the Supervisor or Line Card. For example, if the error message is always on Astro 4 on Module 3 as shown below, then either the SERDES component on module 3 or the SERDES component on the Supervisor is faulty.
%SYS-4-P2_WARN: 1/Astro(3/4) – timeout occurred
In the above error message, the number "4" in parenthesis refers to the Astro #, and not the actual port 3/4. This number references a group of eight ports (3/33-3/40), as it is the fourth Astro on module 3.
A faulty SERDES component can cause intermittent connectivity for control traffic and data traffic to the Astro/Lemans/NiceR, resulting in timeouts. Typically, however, the error message will be continuously displayed if the SERDES is faulty.
Action: In order to determine which (Supervisor or line card) SERDES is bad, perform the following steps:
-
Move the line-card to a spare slot in the chassis or another chassis. If free slot is available, swap slots with known working module.
-
If you continue to get Astro/Lemans/Nicer timeouts on the same Astro/Lemans/Nicer in the new slot, then most likely the SERDES or the Astro/Lemans/Nicer on the linecard has failed and the linecard needs to be replaced
Note: By re-inserting the module in a spare slot, online diagnostics is performed on the line card. If a faulty SERDES or Astro/Lemans/Nicer is found, then the switch will mark the port as faulty.
-
If the timeouts do not continue to occur on the original line card Astro/Lemans/Nicer, it is possible that the Supervisor SERDES is faulty. To verify this, insert a known good working module in the original slot and see if the timeouts occur with the new module.
If it does work, it is possibly a SERDES is on the Supervisor. Refer to the Catalyst WS-X4013 Supervisor Exhibits Partial Loss of Connectivity field notice for a list of affected serial numbers with the failing SERDES component.
Workaround: None
Solution: Contact TAC for further troubleshooting.
Cause 4: Transient /Hard SRAM Failure
Devices connected to a Catalyst 4000 with a Supervisor I or II or III or IV Engine or Catalyst 2948G, Cat2980G may experience partial or full loss of network connectivity. Some or all ports could be affected. These symptoms will be accompanied by rapidly increasing Invalid CRC dropped packets on the CatOS based Supervisor and stub ASIC timeout error messages.
The problem is due to a Packet Buffer Memory (SRAM) failure, which is either a hard or a transient type.
Action: Select the course of action depending on which of the two Transient Packet Buffer Memory Failure Signatures below have occurred:
-
Transient Packet Buffer Memory failure Signature for SUP I , SUP II, 2948G, 2980G
The following are symptoms of this problem:
-
InvalidPktBufferCRC’s rapidly increments with a message similar to the following
%SYS-4-P2_WARN: 1/Invalid crc, dropped packet, count = xxxx
-
A soft reset using the reset command would cause the Supervisor to fail the POST.
-
If a hard reset (power cycle) is performed, Supervisor will pass POST and will no-longer experience failure.
Note: In case of a hard packet buffer memory failure for Supervisor I, II, 2948G, 2980G, a hard reset would not resolve the problem and Supervisor or switch would still fail the POST..
For more information about this issue, please refer to Cisco Bug ID CSCdy46288 (registered customers only) for Supervisor II , Cisco Bug ID CSCeb56266 (registered customers only) for Supervisor I/2948G/2980G and Cisco Bug ID CSCeb56325 (registered customers only) for the WS-C2980G-A.
-
-
Transient Packet Buffer Memory Failure Signature for SUP III, SUP IV
The following are symptoms of this problem:
-
VlanZeroBadCrc counter rapidly increments and is displayed in the command output of the following:
show platform cpuport all (prior to 12.1(11b)EW1 ) or show platform cpu packet statistics all (Since 12.1(11b)EW1) depending upon the software version. Starting from 12.1(19)EW, you should also see the following error message rapidly incrementing errors: %C4K_SWITCHINGENGINEMAN-2-PACKETMEMORYERROR3: Persistent Errors in Packet Memory xxxx
-
A soft reset would cause the Supervisor to fail the POST. Use show diagnostics power-on command to verify the failure.
-
A hard reset (power cycle) will recover the Supervisor and it will pass the POST.
Note: In case of a hard SRAM failure for Supervisor III / IV, a hard reset would not recover the Supervisor and would still fail the POST.
For more information about this issue on Supervisor III/IV, please refer to Cisco bug ID CSCdz57255 (registered customers only)
-
Workaround: Power cycle or hard reset the switch in the case of transient SRAM problem. Hard SRAM problem has no workaround.
Solution: Contact TAC for further troubleshooting.
Cause 5: Supervisor Clock Failure
If Astro/Lemans/NiceR timeout error messages are seen that refer to multiple module numbers or multiple Astro/Lemans/Nicer, then this could indicate a possible clock failure on the Supervisor. Generally, a clock failure is accompanied by both the Astro/Lemans/Nicer timeout error message and BlockTXQueue and BlockedGigaport error messages as shown below:
%SYS-4-P2_WARN: 1/Blocked queue on gigaport ...
Action: Contact TAC for further troubleshooting referring to Cisco bug ID CSCdp89537 (registered customers only) and CSCdp93187 (registered customers only) .
Workaround: None
Solution: Contact TAC for further troubleshooting.
Cause 6: Short Power Interruption
A Catalyst 4000 Series switch with a Supervisor II (WS-X4013) may enter a state in which the Supervisor and line cards are unable to communicate properly with each other. When the switch enters this state, the module status LEDs will be red (not flashing) and/or the port LEDs will flash in sequence similar to a module or switch reset. This will be accompanied by the Astro/Lemans/NiceR timeout messages.
This problem is caused by a temporary interruption of power to the switch (less than 500 ms). The temporary power interruption may be due to unstable power feeds in a production environment.
Action: See workaround below.
Workaround: Reset (soft or hard (power-cycle)) the switch.
Solution: Upgrade to software image with the fix for Cisco bug ID CSCea14710 (registered customers only) or later releases.
Related Information
- Common CatOS Error Messages on Catalyst 4000 Series Switches
- Hardware Troubleshooting for Catalyst 4000/4912G/2980G/2948G Series Switches
- Troubleshooting Hardware and Related Issues on Catalyst 4000 and 4500 Supervisor III and IV
- Catalyst 4000/4500 Series Switches Support Pages
- LAN Switching Technology Support
- Catalyst LAN and ATM Switches Product Support
- Technical Support & Documentation - Cisco Systems
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)