Replacement of OSPD Server UCS 240M4 - vEPC
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Contents
Introduction
This document describes the steps required in order to replace a faulty server that hosts the OpenStack Platform Director (OSPD) in an Ultra-M setup.
Background Information
Ultra-M is a pre-packaged and validated virtualized mobile packet core solution that is designed in order to simplify the deployment of VNFs. OpenStack is the Virtualized Infrastructure Manager (VIM) for Ultra-M and consists of these node types:
- Compute
- Object Storage Disk - Compute (OSD - Compute)
- Controller
- OSPD
The high-level architecture of Ultra-M and the components involved are depicted in this image:
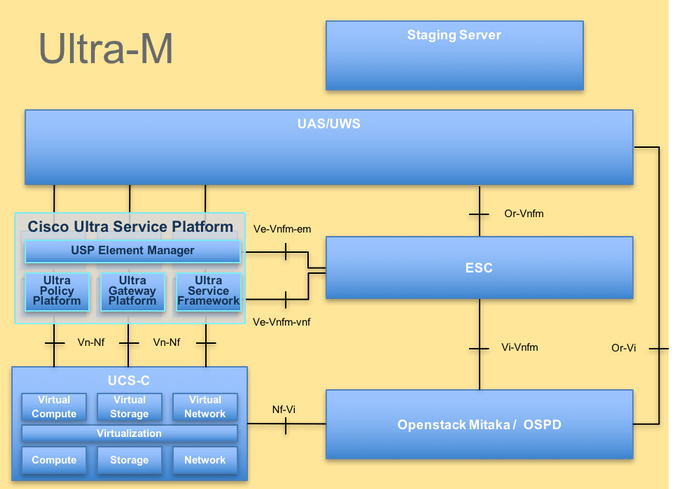 UltraM Architecture
UltraM Architecture
This document is intended for the Cisco personnel who are familiar with Cisco Ultra-M platform and it details the steps that are required in order to be carried out at the OpenStack level at the time of the OSPD Server replacement.
Note: Ultra M 5.1.x release is considered in order to define the procedures in this document.
Abbreviations
| VNF | Virtual Network Function |
| CF | Control Function |
| SF | Service Function |
| ESC | Elastic Service Controller |
| MOP | Method of Procedure |
| OSD | Object Storage Disks |
| HDD | Hard Disk Drive |
| SSD | Solid State Drive |
| VIM | Virtual Infrastructure Manager |
| VM | Virtual Machine |
| EM | Element Manager |
| UAS | Ultra Automation Services |
| UUID | Universally Unique IDentifier |
Workflow of the MoP
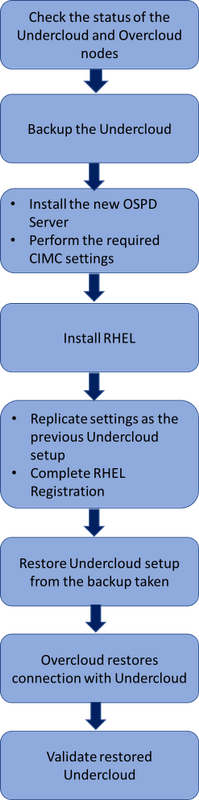 High level workflow of the replacement procedure
High level workflow of the replacement procedure
Prerequisites
Status Check
Before you replace an OSPD server, it is important to check the current state of the Red Hat OpenStack Platform environment and ensure that it is healthy in order to avoid complications when the replacement process is on.
Check the status of OpenStack stack and the node list:
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
Ensure if all the undercloud services are in loaded, active and running state from the OSP-D node:
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
Backup
Ensure that you have sufficient disk space available before you perform the backup process. This tarball is expected to be at least 3.5 GB.
[stack@director ~]$df -h
Run this command as the root user in order to backup the data from the undercloud node to a file named undercloud-backup-[timestamp].tar.gz.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Install the New OSPD Node
UCS Server Installation
The steps in order to install a new UCS C240 M4 server as well as the initial setup steps can be referred from Cisco UCS C240 M4 Server Installation and Service Guide.
Log in to server with the use of the CIMC IP.
Perform BIOS upgrade if the firmware is not as per the recommended version used previously. Steps for BIOS upgrade are given here: Cisco UCS C-Series Rack-Mount Server BIOS Upgrade Guide.
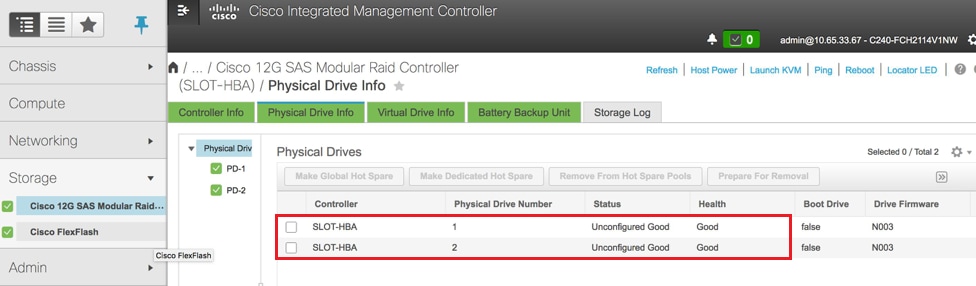
Verify the status of Physical Drives. It must be Unconfigured Good:
Navigate to Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info as shown here in the image.
Create a virtual drive from the physical drives with RAID Level 1:
Navigate to Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives as shown in the image.
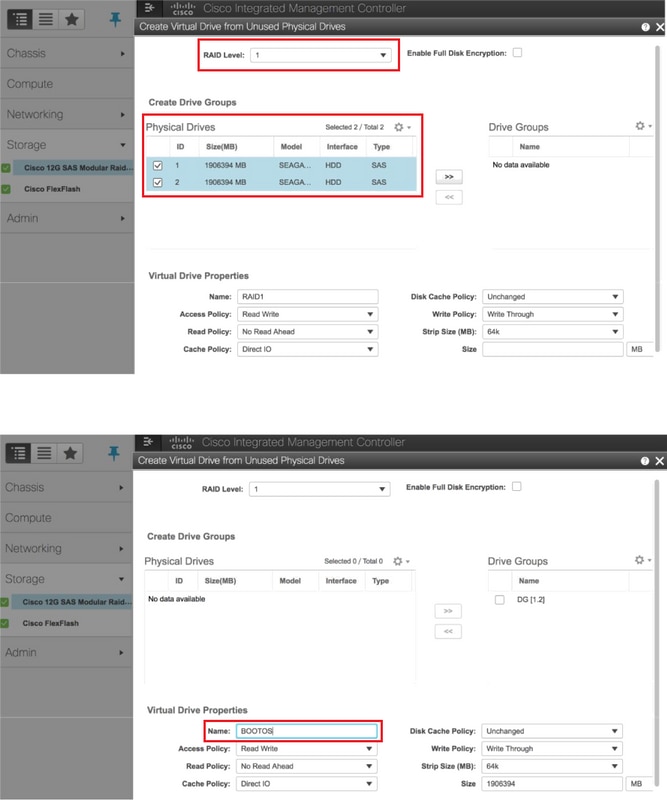
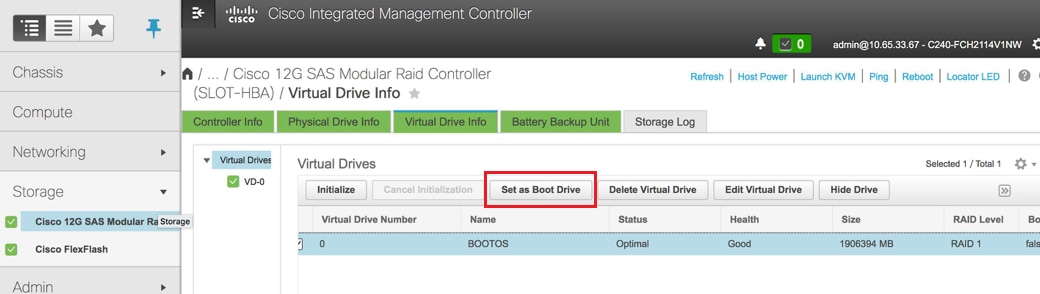
Select the VD and configure Set as Boot Drive as shown in the image.
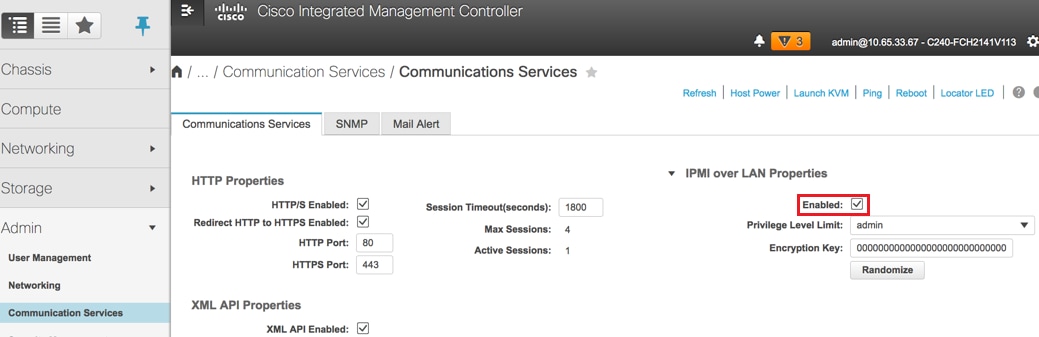
Enable IPMI over LAN:
Navigate to Admin > Communication Services > Communication Services as shown in the image.
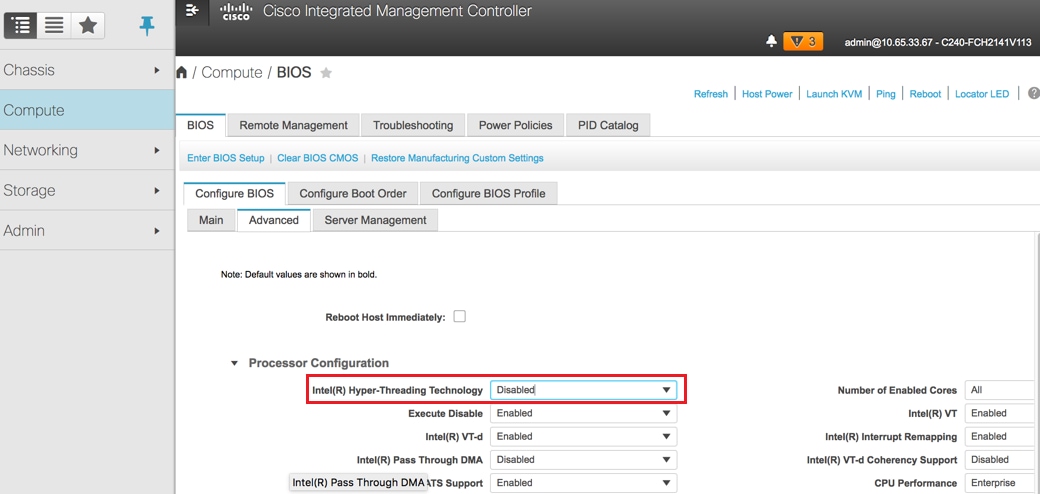
Disable hyperthreading:
Navigate to Compute > BIOS > Configure BIOS > Advanced > Processor Configuration as shown in the image.
Note: The image shown here and the configuration steps mentioned in this section are with reference to the firmware version 3.0(3e) and there might be slight variations if you work on other versions.
Red Hat Installation
Mount the Red Hat ISO Image
1. Log in to OSP-D Server.
2. Launch KVM Console.
3. Navigate to Virtual Media > Activate Virtual Devices. Accept the session and enable remembering your setting for future connections.
4. Select Virtual Media > Map CD/DVDand map the Red Hat ISO image.
5. Select Power > Reset System (Warm Boot) to reboot the system.
6. Upon restart, press F6and select Cisco vKVM-Mapped vDVD1.22and press Enter.
Install Red Hat Enterprise Linux
Note: The procedure in this section represents a simplified version of the installation process that identifies the minimum number of parameters that must be configured.
1. Select the option to install Red Hat Enterprise Linux (RHEL) in order to begin the installation.
2. Select Software Selection > Minimum Install Only.
3. Configure Network Interfaces (eno1 and eno2).
4. Click on Network and Hostname.
- Select the interface that would be used for external communication (either eno1 or eno2)
- Click Configure
- Select the IPv4 Settingstab, select the Manual method and click on Add
- Set these parameters as used previously: Address, Netmask, Gateway, DNS server
5. Select Date and Time and specify your Region and City.
6. Enable Network Time and configure NTP Servers.
7. Select Installation Destination and use ext4 file system .
Note: Delete /home/ and reallocate the capacity under root /.
8. Disable Kdump.
9. Set Root password only.
10. Begin the installation
.
Restore the Undercloud
Prepare undercloud Installation Based on Backup
Once the machine installed with RHEL 7.3 and is in a clean state, re-enable all the subscriptions/repositories needed to install and run director.
Hostname Configuration:
[root@director ~]$sudo hostnamectl set-hostname <FQDN_hostname>
[root@director ~]$sudo hostnamectl set-hostname --transient <FQDN_hostname>
Edit /etc/hosts file:
[root@director ~]$ vi /etc/hosts
<ospd_external_address> <server_hostname> <FQDN_hostname>
10.225.247.142 pod1-ospd pod1-ospd.cisco.com
Validate hostname:
[root@director ~]$ cat /etc/hostname
pod1-ospd.cisco.com
Validate DNS configuration:
[root@director ~]$ cat /etc/resolv.conf
#Generated by NetworkManager
nameserver <DNS_IP>
Modify the provisioning nic interface:
[root@director ~]$ cat /etc/sysconfig/network-scripts/ifcfg-eno1
DEVICE=eno1
ONBOOT=yes
HOTPLUG=no
NM_CONTROLLED=no
PEERDNS=no
DEVICETYPE=ovs
TYPE=OVSPort
OVS_BRIDGE=br-ctlplane
BOOTPROTO=none
MTU=1500
Complete the Red Hat Registration
Download this package in order to configure subscription-manager in order to use rh-satellite:
[root@director ~]$ rpm -Uvh http://<satellite-server>/pub/katello-ca-consumer-latest.noarch.rpm
[root@director ~]$ subscription-manager config
Register with rh-satellite with the use of this activationkey for RHEL 7.3.
[root@director ~]$subscription-manager register --org="<ORG>" --activationkey="<KEY>"
In order to see the subscription:
[root@director ~]$ subscription-manager list –consumed
Enable the repositories similar to the old OSPD repos:
[root@director ~]$ sudo subscription-manager repos --disable=*
[root@director ~]$ subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rh
el-7-server-openstack-10-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpm
Perform an update on your system in order to ensure you have the latest base system packages and reboot the system:
[root@director ~]$sudo yum update -y
[root@director ~]$sudo reboot
Undercloud Restoration
After you enable the subscription, import the backed up undercloud tar file undercloud-backup-date +%F`.tar.gz to new OSP-D server root directory /root.
Install the mariadb server:
[root@director ~]$ yum install -y mariadb-server
Extract the MariaDB configuration file and Database (DB) backup. Perform this operation as root user.
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/my.cnf.d/server.cnf
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz root/undercloud-all-databases.sql
Edit /etc/my.cnf.d/server.cnf and comment out the bind-address entry if present:
[root@tb3-ospd ~]# vi /etc/my.cnf.d/server.cnf
Start the MariaDB service and temporarily update the max_allowed_packet setting:
[root@director ~]$ systemctl start mariadb
[root@director ~]$ mysql -uroot -e"set global max_allowed_packet = 16777216;"
Clean up certain permissions (to be recreated later):
[root@director ~]$ for i in ceilometer glance heat ironic keystone neutron nova;do mysql -e "drop user $i";done
[root@director ~]$ mysql -e 'flush privileges'
Note: If ceilometer service has been previously disabled in the setup, execute this command and remove ceilometer.
Create the stackuser account:
[root@director ~]$ sudo useradd stack
[root@director ~]$ sudo passwd stack << specify a password
[root@director ~]$ echo "stack ALL=(root) NOPASSWD:ALL" | sudo tee -a /etc/sudoers.d/stack
[root@director ~]$ sudo chmod 0440 /etc/sudoers.d/stack
Restore the stack user home directory:
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz home/stack
Install the swift and glance base packages, and then restore their data:
[root@director ~]$ yum install -y openstack-glance openstack-swift
[root@director ~]$ tar --xattrs -xzC / -f undercloud-backup-$DATE.tar.gz srv/node var/lib/glance/images
Confirm that the data is owned by the correct user:
[root@director ~]$ chown -R swift: /srv/node
[root@director ~]$ chown -R glance: /var/lib/glance/images
Restore the undercloud SSL certificates (optional - to be done only if the setup uses SSL certificates).
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/instack-certs/undercloud.pem
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/ca-trust/source/anchors/ca.crt.pem
Re-run the undercloud installation as the stackuser and ensure to run it in the stack user home directory:
[root@director ~]$ su - stack
[stack@director ~]$ sudo yum install -y python-tripleoclient
Confirm that the hostname is correctly set in /etc/hosts.
Reinstall the undercloud:
[stack@director ~]$ openstack undercloud install
<snip>
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and must be
secured.
#############################################################################
Reconnect the Restored Undercloud to the Overcloud
After you complete these steps, the undercloud can be expected to automatically restore its connection to the overcloud. The nodes will continue to poll Orchestration (heat) for pending tasks, with the use of a simple HTTP request that is issued every few seconds.
Validate the Completed Restore
Use these commands in order to perform a health check of the newly restored environment:
[root@director ~]$ su - stack
Last Log in: Tue Nov 28 21:27:50 EST 2017 from 10.86.255.201 on pts/0
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| b1f5294a-629e-454c-b8a7-d15e21805496 | pod1-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.119 |
| 9106672e-ac68-423e-89c5-e42f91fefda1 | pod1-compute-1 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
| b3ed4a8f-72d2-4474-91a1-b6b70dd99428 | pod1-compute-2 | ACTIVE | - | Running | ctlplane=192.200.0.124 |
| 677524e4-7211-4571-ac35-004dc5655789 | pod1-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.107 |
| 55ea7fe5-d797-473c-83b1-d897b76a7520 | pod1-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.122 |
| c34c1088-d79b-42b6-9306-793a89ae4160 | pod1-compute-5 | ACTIVE | - | Running | ctlplane=192.200.0.108 |
| 4ba28d8c-fb0e-4d7f-8124-77d56199c9b2 | pod1-compute-6 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| d32f7361-7e73-49b1-a440-fa4db2ac21b1 | pod1-compute-7 | ACTIVE | - | Running | ctlplane=192.200.0.106 |
| 47c6a101-0900-4009-8126-01aaed784ed1 | pod1-compute-8 | ACTIVE | - | Running | ctlplane=192.200.0.121 |
| 1a638081-d407-4240-b9e5-16b47e2ff6a2 | pod1-compute-9 | ACTIVE | - | Running | ctlplane=192.200.0.112 |
<snip>
[stack@director ~]$ ssh heat-admin@192.200.0.107
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.1.10.10 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.97 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-192.200.0.106 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.95 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.98 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.92 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Stopped
Failed Actions:
* my-ipmilan-for-controller-0_start_0 on pod1-controller-1 'unknown error' (1): call=190, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-1 'unknown error' (1): call=192, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-1 'unknown error' (1): call=188, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-0 'unknown error' (1): call=210, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-0 'unknown error' (1): call=207, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-0 'unknown error' (1): call=206, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20006ms
* ip-192.200.0.106_monitor_10000 on pod1-controller-0 'not running' (7): call=197, status=complete, exitreason='none',
last-rc-change='Wed Nov 22 13:51:31 2017', queued=0ms, exec=0ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-2 'unknown error' (1): call=183, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=1ms, exec=20006ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-2 'unknown error' (1): call=184, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-2 'unknown error' (1): call=177, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:02 2017', queued=0ms, exec=20005ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[heat-admin@pod1-controller-0 ~]$ sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v1245812: 704 pgs, 6 pools, 542 GB data, 352 kobjects
1625 GB used, 11767 GB / 13393 GB avail
704 active+clean
client io 21549 kB/s wr, 0 op/s rd, 120 op/s wr
Check Identity Service (Keystone) Operation
This step validates Identity Service operations by querying for a list of users.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack user list
+----------------------------------+------------------+
| ID | Name |
+----------------------------------+------------------+
| 69ac2b9d89414314b1366590c7336f7d | admin |
| f5c30774fe8f49d0a0d89d5808a4b2cc | glance |
| 3958d852f85749f98cca75f26f43d588 | heat |
| cce8f2b7f1a843a08d0bb295a739bd34 | ironic |
| ce7c642f5b5741b48a84f54d3676b7ee | ironic-inspector |
| a69cd42a5b004ec5bee7b7a0c0612616 | mistral |
| 5355eb161d75464d8476fa0a4198916d | neutron |
| 7cee211da9b947ef9648e8fe979b4396 | nova |
| f73d36563a4a4db482acf7afc7303a32 | swift |
| d15c12621cbc41a8a4b6b67fa4245d03 | zaqar |
| 3f0ed37f95544134a15536b5ca50a3df | zaqar-websocket |
+----------------------------------+------------------+
[stack@director ~]$
[stack@director ~]$ source <overcloudrc>
[stack@director ~]$ openstack user list
+----------------------------------+------------+
| ID | Name |
+----------------------------------+------------+
| b4e7954942184e2199cd067dccdd0943 | admin |
| 181878efb6044116a1768df350d95886 | neutron |
| 6e443967ee3f4943895c809dc998b482 | heat |
| c1407de17f5446de821168789ab57449 | nova |
| c9f64c5a2b6e4d4a9ff6b82adef43992 | glance |
| 800e6b1163b74cc2a5fab4afb382f37d | cinder |
| 4cfa5a2a44c44c678025842f080e5f53 | heat-cfn |
| 9b222eeb8a58459bb3bfc76b8fff0f9f | swift |
| 815f3f25bcda49c290e1b56cd7981d1b | core |
| 07c40ade64f34a64932129175150fa4a | gnocchi |
| 0ceeda0bc32c4d46890e53adef9a193d | aodh |
| f3caab060171468592eab376a94967b8 | ceilometer |
+----------------------------------+------------+
[stack@director ~]$
Upload Images for Future Node Introspection
Validate /httpboot and all these files inspector.ipxe, agent.kernel, agent.ramdisk, if not proceed to these steps.
[stack@director ~]$ ls /httpboot
inspector.ipxe
[stack@director ~]$ source stackrc
[stack@director ~]$ cd images/
[stack@director images]$ openstack overcloud image upload --image-path /home/stack/images
Image "overcloud-full-vmlinuz" is up-to-date, skipping.
Image "overcloud-full-initrd" is up-to-date, skipping.
Image "overcloud-full" is up-to-date, skipping.
Image "bm-deploy-kernel" is up-to-date, skipping.
Image "bm-deploy-ramdisk" is up-to-date, skipping.
[stack@director images]$ ls /httpboot
agent.kernel agent.ramdisk inspector.ipxe
[stack@director images]$
Restart Fencing
Fencing will be in stopped state after OSPD recovery. This procedure will enable fencing.
[heat-admin@pod1-controller-0 ~]$ sudo pcs property set stonith-enabled=true
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
[heat-admin@pod1-controller-0 ~]$sudo pcs stonith show
Related Information
Contributed by Cisco Engineers
- Padmaraj RamanoudjamCisco Advanced Services
- Partheeban RajagopalCisco Advanced Services
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)