Utilizar metadatos para informes personalizados con API y Python
Opciones de descarga
-
ePub (170.4 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (231.5 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe cómo utilizar los metadatos junto con las API para el informe personalizado dentro de un script python.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- CloudCenter
- Python
Componentes Utilizados
Este documento no tiene restricciones específicas en cuanto a versiones de software y de hardware.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Antecedentes
CloudCenter proporciona algunos informes de forma inmediata, pero no permite informes basados en filtros personalizados. Para utilizar las API para obtener la información directamente de la base de datos, junto con los metadatos asociados a los trabajos, puede permitir informes personalizados.
Configuración de los metadatos
Los metadatos se deben agregar en un nivel por aplicación, de modo que se tendrán que modificar todas las aplicaciones a las que se debe realizar un seguimiento con el uso del informe personalizado.
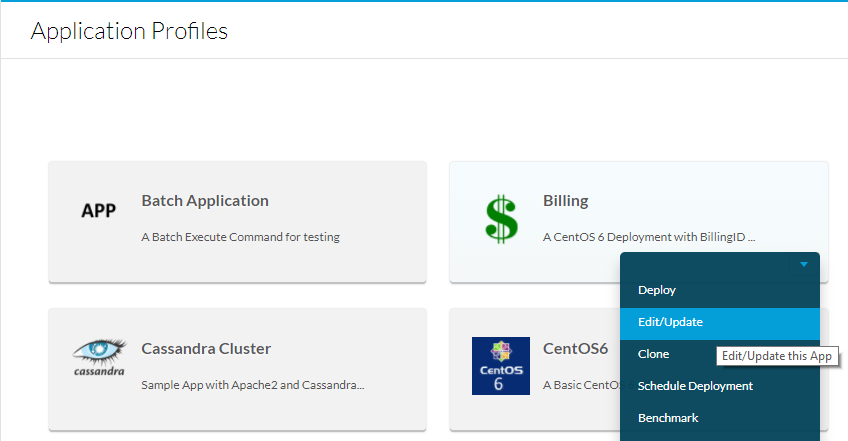
Para hacerlo, navegue hasta Perfiles de aplicación, luego seleccione el menú desplegable de la aplicación que se editará y luego seleccione Editar/Actualizar como se muestra en la imagen.
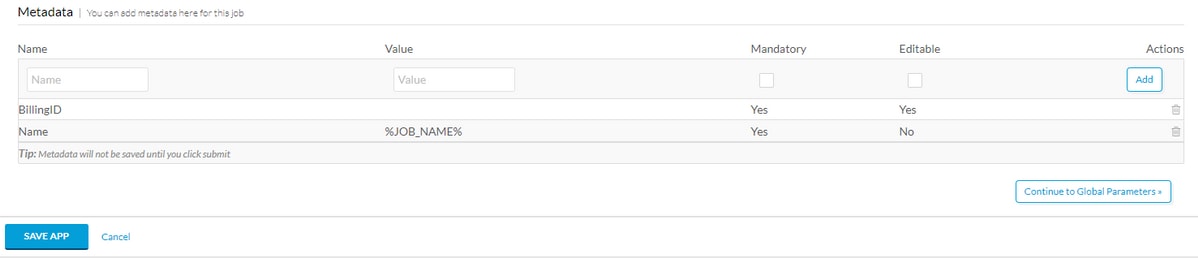
Desplácese hasta la parte inferior de Información básica y agregue una etiqueta de metadatos, por ejemplo BillingID, si el usuario va a rellenar estos metadatos, será obligatorio y editable. Si es sólo una macro, rellene el valor predeterminado y no la haga editable. Después de completar los metadatos, seleccione Agregar y Guardar aplicación como se muestra en la imagen.
Recopilación de claves API
Para procesar las llamadas de la API, se necesitarán claves de nombre de usuario y API. Estas claves proporcionan el mismo nivel de acceso que el usuario, por lo que si se añaden todas las implementaciones de usuarios en el informe, se recomienda para obtener el administrador de las claves API de los arrendatarios. Si se van a registrar varios subarrendatarios juntos, el arrendatario raíz necesita acceso a todos los entornos de implementación, o se necesitarán las claves API de todos los administradores de subarrendatarios.
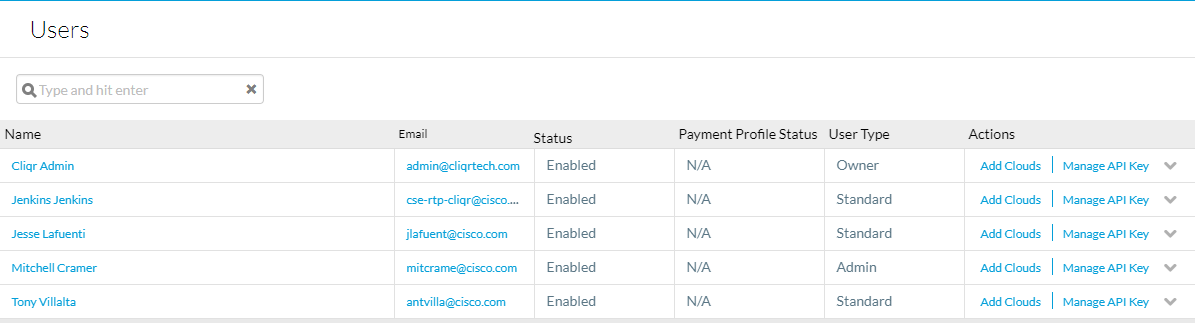
Para obtener las claves de API navegue hasta Admin > Users > Manage API Key, copie el nombre de usuario y la clave para los usuarios requeridos.
Crear el informe personalizado
Antes de crear el script python que crea el informe, asegúrese de que python y pip se han instalado en él. A continuación, ejecute la tabla de instalación de pip, la tabla es una biblioteca que controla el formato del informe automáticamente.
Se adjuntan dos informes de ejemplo a esta guía; el primero simplemente recopila información sobre todas las implementaciones y, a continuación, la envía en una tabla. El segundo utiliza la misma información para crear un informe personalizado con el uso de metadatos de BillingID. Este script se explica en detalle para utilizarlo como guía.
import datetime import json import sys import requests ##pip install tabulate from tabulate import tabulate from operator import itemgetter from decimal import Decimal
datetime se utiliza para calcular con precisión la fecha, esto se hace para crear un informe de los X días más recientes.
json se utiliza para ayudar a analizar los datos json, el resultado de las llamadas api.
sys se utiliza para las llamadas del sistema.
las solicitudes se utilizan para simplificar la realización de solicitudes web para las llamadas API.
tabulado se utiliza para formatear automáticamente la tabla.
itemgetter se utiliza como iterador para ordenar una tabla 2D.
Decimal se utiliza para redondear el costo a dos decimales.
if(len(sys.argv)==1):
days = -1
elif(len(sys.argv)==2):
try:
days = int(sys.argv[1])
if(days < 1):
raise ValueError('Less than 1')
start=datetime.datetime.now()+datetime.timedelta(days*-1)
except ValueError:
print("Number of days must be an integer greater than 0")
exit()
else:
print("Enter number of days to report on, or leave blank to report all time")
exit()
Esta parte se utiliza para analizar el parámetro de línea de comandos del número de días.
Si no hay parámetros de línea de comandos (sys.argv ==1), los informes se realizarán siempre.
Si hay un parámetro de línea de comandos verifique si es un entero mayor o igual a 1, si se informa sobre ese número de días, si no, devuelva un error.
Si hay más de un parámetro, devuelva un error.
departments = [] users = ['user1','user2','user3'] passwords = ['user1Key','user2Key','user3Key']
departamentos es la lista que contendrá el resultado final.
usuarios es una lista de todos los usuarios que realizarán las llamadas de la API, si hay varios subarrendatarios cada usuario sería el administrador de un subarrendatario diferente.
password es una lista de las claves API de los usuarios, el orden de los usuarios y las claves debe ser idéntico para que se utilice la clave correcta.
for j in xrange(0,len(users)):
jobs = []
r = requests.get('https://ccm2.cisco.com/v1/jobs', auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data = r.json()
for i in xrange(0,len(data["jobs"])):
test = datetime.datetime.strptime((data["jobs"][i]["startTime"]), '%Y-%m-%d %H:%M:%S.%f')
if(days != -1):
if(start < test):
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
else:
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
for id in jobs:
q = requests.get('https://ccm2.cisco.com/v1/jobs/'+id[0], auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data2 = q.json()
id[2]=round(id[2],2)
for i in xrange(0,len(data2["metadatas"])):
if('BillingID' == data2["metadatas"][i]["name"]):
id[1]=data2["metadatas"][i]["value"]
added=0
for i in xrange(0,len(departments)):
if(departments[i][0]==id[1]):
departments[i][1]+= 1
departments[i][2]+=id[2]
added=1
if(added==0):
departments.append([id[1],1,id[2]])
para j en xrange(0,len(users)): es para que el bucle itere a través de cada usuario definido en el fragmento de código anterior, este es el bucle principal que maneja todas las llamadas API.
trabajos es una lista temporal que se utilizará para guardar la información de los trabajos mientras se coteja en la lista.
r = solicitudes.get.... es la primera llamada de API, esta enumera todos los trabajos. Para obtener más información, consulte Lista de trabajos.
Los resultados se almacenan en formato json en datos.
para i en xrange(0,len(data["job"]): recorre en iteración todos los trabajos devueltos desde la llamada API anterior.
El tiempo para cada trabajo se extrae de la json y se convierte en un objeto datetime, luego se compara con el parámetro de línea de comandos ingresado para ver si está dentro de los límites.
Si es así, es esta información del json la que se agrega a la lista de trabajos: id, totalCost, status, nombre, hora de inicio. No se utiliza toda esta información, ni esta es toda la información que se puede devolver. List Jobs muestra toda la información devuelta que se puede agregar de la misma manera.
Después de recorrer en iteración todos los trabajos devueltos por ese usuario, se mueve a para id en trabajos: que recorre en iteración todos los trabajos realizados después de comprobar la fecha de inicio.
q = requests.get(..... es la segunda llamada de API, esta enumera toda la información relacionada con la ID del trabajo que se tomó de la primera llamada de API. Para obtener más información, vea Obtener detalles del trabajo.
A continuación, el archivo json se almacena en data2.
El coste, que se almacena en id[2] se redondea a dos decimales.
para i en xrange(0,len(data2["metadatos"]): recorre en iteración todos los metadatos asociados al trabajo.
Si hay metadatos denominados BillingID, se almacena en la información del trabajo.
agregar es un indicador utilizado para determinar si el ID de facturación ya se ha agregado a la lista de departamentos o no.
para i en xrange(0,len(departamentos)): recorre en iteración todos los departamentos que se han agregado.
Si este trabajo forma parte de un departamento que ya existe, el recuento de puestos se divide en uno y el coste se agrega al coste total de ese departamento.
De lo contrario, se agrega una nueva línea a los departamentos con un recuento de puestos de 1 y un coste total igual al coste de este trabajo.
departments = sorted(departments, key=itemgetter(1)) print(tabulate(departments,headers=['Department','Number of Jobs','Total Cost']))
departamentos = ordenados(departamentos, clave=elemento(1)) ordenan los departamentos por el número de trabajos.
print(tabulate(departamentos,encabezados=['Departamento','Número de trabajos', 'Costo total'])) imprime una tabla creada por tabulado con tres encabezados.
Información Relacionada
Con la colaboración de ingenieros de Cisco
- Jesse LafuentiCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)