Introducción
Este documento describe los pasos que puede utilizar para resolver problemas de montaje en Hyperflex Datastore.
Prerequisites
Requirements
No hay requisitos específicos para este documento.
Componentes Utilizados
Este documento no tiene restricciones específicas en cuanto a versiones de software y de hardware.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes:
De forma predeterminada, los almacenes de datos Hyperflex se montan en NFS v3.
NFS (sistema de archivos de red) es un protocolo de intercambio de archivos utilizado por el hipervisor para comunicarse con un servidor NAS (almacenamiento conectado a la red) a través de una red TCP/IP estándar.
Esta es una descripción de los componentes NFS utilizados en un entorno vSphere:
- Servidor NFS: un dispositivo de almacenamiento o un servidor que utiliza el protocolo NFS para hacer que los archivos estén disponibles en la red. En el mundo de Hyperflex, cada VM del controlador ejecuta una instancia del servidor NFS. La IP del servidor NFS para los almacenes de datos es la IP de interfaz eth1:0.
- Almacén de datos NFS: una partición compartida en el servidor NFS que se puede utilizar para almacenar archivos de máquina virtual.
- Cliente NFS - ESXi incluye un cliente NFS integrado que se utiliza para acceder a dispositivos NFS.
Además de los componentes regulares NFS, hay un VIB instalado en el ESXi llamado IOVisor. Esta VIB proporciona un punto de montaje de sistema de archivos de red (NFS) para que el hipervisor ESXi pueda acceder a las unidades de disco virtual conectadas a máquinas virtuales individuales. Desde el punto de vista del hipervisor, simplemente se conecta a un sistema de archivos de red.
Problema
Los síntomas de los problemas de montaje pueden aparecer en el host ESXi como almacén de datos inaccesible.
Almacenes de datos inaccesibles en vCenter
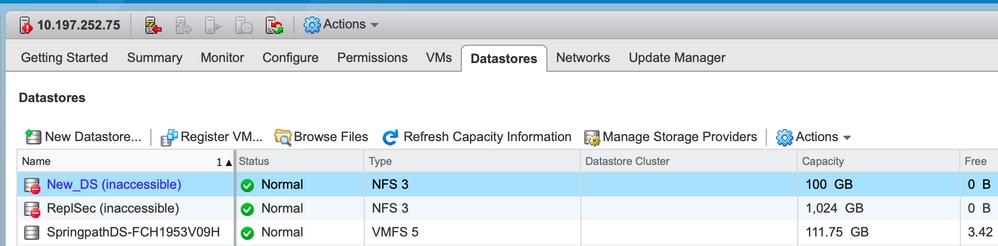
Nota: Cuando los almacenes de datos aparecen como inaccesibles en vCenter, se consideran que no están disponibles en la CLI de ESX. Esto significa que los almacenes de datos se montaron previamente en el host.
Verifique los almacenes de datos a través de CLI:
- SSH al host ESXi e ingrese el comando:
[root@node1:~] esxcfg-nas -l
test1 is 10.197.252.106:test1 from 3203172317343203629-5043383143428344954 mounted unavailable
test2 is 10.197.252.106:test2 from 3203172317343203629-5043383143428344954 mounted unavailable
Almacenes de datos no disponibles en vCenter/CLI
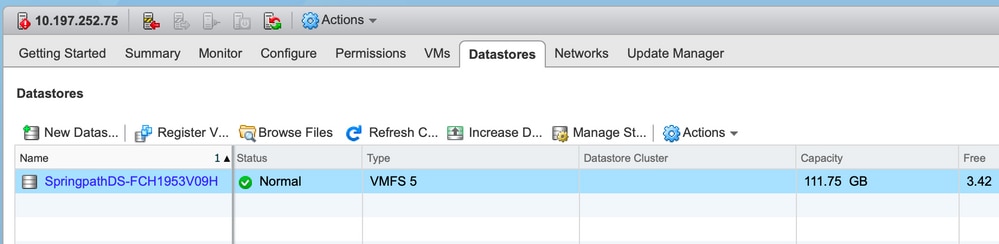
Nota: Cuando los almacenes de datos no están presentes en vCenter o CLI. Esto indica que el almacén de datos nunca se montó correctamente en el host anteriormente.
- Verifique los almacenes de datos mediante CLI
SSH al host ESXi e ingrese el comando:
[root@node1:~] esxcfg-nas -l
[root@node1:~]
Solución
Los motivos del problema de montaje pueden ser diferentes, verifique la lista de comprobaciones para validar y corregir si las hay.
Comprobación de disponibilidad de la red
Lo primero que se debe verificar en caso de cualquier problema con el almacén de datos es si el host puede alcanzar la IP del servidor NFS.
La IP del servidor NFS en el caso de Hyperflex es la IP asignada a la interfaz virtual eth1:0, que está presente en una de las SCVM.
Si los hosts ESXi no pueden hacer ping a la IP del servidor NFS, hace que los almacenes de datos se vuelvan inaccesibles.
Busque la IP eth1:0 con el comando ifconfig en todas las SCVM.
Nota: Eth1:0 es una interfaz virtual y está presente en una sola de las SCVM.
root@SpringpathControllerGDAKPUCJLE:~# ifconfig eth1:0
eth1:0 Link encap:Ethernet HWaddr 00:50:56:8b:62:d5
inet addr:10.197.252.106 Bcast:10.197.252.127 Mask:255.255.255.224
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Para el host ESXi con problemas de montaje del almacén de datos y verifique si puede alcanzar la IP del servidor NFS.
[root@node1:~] ping 10.197.252.106
PING 10.197.252.106 (10.197.252.106): 56 data bytes
64 bytes from 10.197.252.106: icmp_seq=0 ttl=64 time=0.312 ms
64 bytes from 10.197.252.106: icmp_seq=1 ttl=64 time=0.166 m
Si puede hacer ping, continúe con los pasos para solucionar los problemas en la siguiente sección.
Si no puede hacer ping, debe comprobar su entorno para solucionar el problema de disponibilidad. hay algunos indicadores que se pueden ver:
- Configuración de vSwitch de almacenamiento-datos de hx:
Nota: De forma predeterminada, el instalador realiza toda la configuración durante la implementación del clúster. Si se ha cambiado manualmente después de eso, verifique la configuración
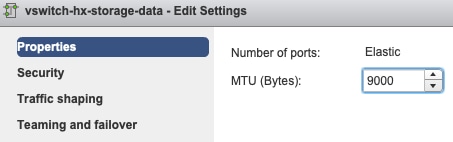
Configuración de MTU: si ha activado la MTU Jumbo durante la implementación del clúster, la MTU en el vSwitch también debe ser 9000. En caso de que no utilice MTU Jumbo, ésta debe ser 1500.
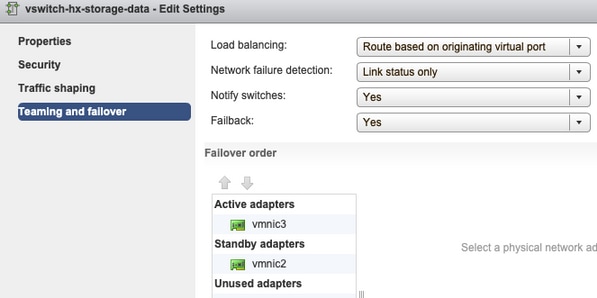
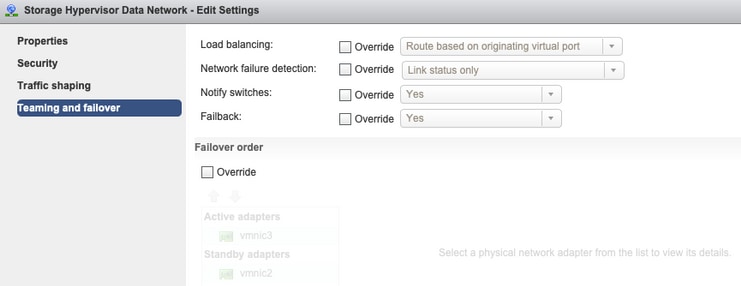
Teaming and Failover - De forma predeterminada, el sistema intenta asegurarse de que el tráfico de datos de almacenamiento sea conmutado localmente por el FI. Por lo tanto, los adaptadores activos y en espera en todos los hosts deben ser los mismos.
Configuración de VLAN de grupo de puertos: la VLAN de datos de almacenamiento se debe especificar en los grupos de puertos Red de datos de controlador de almacenamiento y Red de datos de hipervisor de almacenamiento.
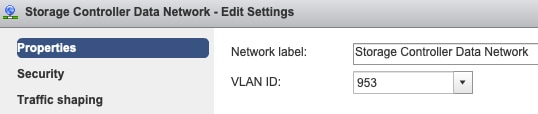
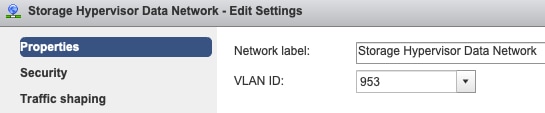
Sin reemplazos en el nivel de grupo de puertos: la configuración Teaming & Failover realizada en el nivel de vSwitch se aplica a los grupos de puertos de forma predeterminada, por lo que se recomienda no invalidar la configuración en el nivel de grupo de puertos.
- Configuración de UCS vNIC:
Nota: De forma predeterminada, el instalador realiza toda la configuración durante la implementación del clúster. Si se ha cambiado manualmente después de eso, verifique la configuración
Configuración de MTU: asegúrese de que el tamaño de MTU y la política de QoS estén correctamente configurados en la plantilla de vnic de datos de almacenamiento. Los vnics de datos de almacenamiento utilizan la política QoS Platinum y la MTU debe configurarse según su entorno.

Configuración de VLAN: la VLAN de datos de almacenamiento de hx creada durante la implementación del clúster se debe permitir en la plantilla vnic. asegúrese de que no esté marcado como nativo
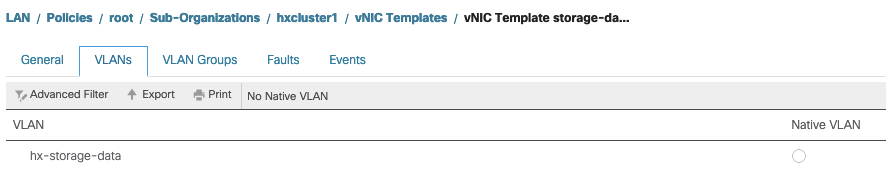
Comprobación del estado del proxy de Evisor/SCVMclient/NFS
La vib SCVMclient de ESXI actúa como proxy NFS. Intercepta la E/S de la máquina virtual, la envía a la SCVM respectiva y las devuelve con la información necesaria.
Asegúrese de que el VIB esté instalado en nuestros hosts, para este ssh a uno de los ESXI y ejecute los comandos:
[root@node1:~] esxcli software vib list | grep -i spring
scvmclient 3.5.2b-31674 Springpath VMwareAccepted 2019-04-17
stHypervisorSvc 3.5.2b-31674 Springpath VMwareAccepted 2019-05-20
vmware-esx-STFSNasPlugin 1.0.1-21 Springpath VMwareAccepted 2018-11-23
Verifique el estado del scvmclient en el esxi ahora y asegúrese de que se esté ejecutando, si se detiene, por favor comience con el comando /etc/init.d/scvmclient start
[root@node1:~] /etc/init.d/scvmclient status
+ LOGFILE=/var/run/springpath/scvmclient_status
+ mkdir -p /var/run/springpath
+ trap mv /var/run/springpath/scvmclient_status /var/run/springpath/scvmclient_status.old && cat /var/run/springpath/scvmclient_status.old |logger -s EXIT
+ exec
+ exec
Scvmclient is running
UUID del clúster que se puede resolver a la IP de bucle invertido de ESXI
Hyperflex asigna el UUID del clúster a la interfaz de loopback del ESXi, de modo que el ESXI pase las solicitudes NFS a su propio scvmclient. Si esto no está, puede enfrentar problemas con el montaje de los almacenes de datos en el host. Para verificar esto, envíe al host que tiene los datastores montados, y envíe al host con problemas, y realice el cat del archivo /etc/hosts
Si ve que el host no funcional no tiene la entrada en /etc/hosts, puede copiarla de un host funcional en el /etc/hosts del host no funcional.
Host no funcional
[root@node1:~] cat /etc/hosts
# Do not remove these lines, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
10.197.252.75 node1
Host funcional
[root@node2:~] cat /etc/hosts
# Do not remove these lines, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
10.197.252.76 node2
127.0.0.1 3203172317343203629-5043383143428344954.springpath 3203172317343203629-5043383143428344954
Entradas del almacén de datos obsoletas en /etc/vmware/esx.conf
Si el clúster de HX se ha recreado sin la reinstalación de ESXI, es posible que tenga entradas antiguas del almacén de datos en el archivo esx.conf.
Esto no le permite montar los nuevos almacenes de datos con el mismo nombre. Puede verificar todos los almacenes de datos HX en esx.conf desde el archivo:
[root@node1:~] cat /etc/vmware/esx.conf | grep -I nas
/nas/RepSec/share = "10.197.252.106:RepSec"
/nas/RepSec/enabled = "true"
/nas/RepSec/host = "5983172317343203629-5043383143428344954"
/nas/RepSec/readOnly = "false"
/nas/DS/share = "10.197.252.106:DS"
/nas/DS/enabled = "true"
/nas/DS/host = "3203172317343203629-5043383143428344954"
/nas/DS/readOnly = "false"
si en el resultado, verá que el almacén de datos antiguo que se mapea y utiliza el UUID de clúster antiguo, por lo tanto ESXi no le permite montar el almacén de datos con el mismo nombre con el nuevo UUID.
Para resolver esto, es necesario quitar la entrada del almacén de datos antiguo con el comando - esxcfg-nas -d RepSec
Una vez eliminado, vuelva a intentar el montaje del almacén de datos desde HX-Connect
Comprobar reglas de firewall en ESXi
Comprobar la configuración de activación del firewall
Se establece en False, causa problemas.
[root@node1:~] esxcli network firewall get
Default Action: DROP
Enabled: false
Loaded: true
Actívelo con los comandos:
[root@node1:~] esxcli network firewall set –e true
[root@node1:~] esxcli network firewall get
Default Action: DROP
Enabled: true
Loaded: true
Comprobar la configuración de la regla de conexión:
Se establece en False, causa problemas.
[root@node1:~] esxcli network firewall ruleset list | grep -i scvm
ScvmClientConnectionRule false
Actívelo con los comandos:
[root@node1:~] esxcli network firewall ruleset set –e true –r ScvmClientConnectionRule
[root@node1:~] esxcli network firewall ruleset list | grep -i scvm
ScvmClientConnectionRule true
Verifique Reglas Imponibles En El SCVM
Verifique y haga coincidir el número de reglas en todas las SCVM. Si no coinciden, abra un caso TAC para corregirlo.
root@SpringpathControllerI51U7U6QZX:~# iptables -L | wc -l
48
Información Relacionada
 Comentarios
Comentarios