Comprensión de los errores de verificación de redundancia cíclica en switches Nexus
Opciones de descarga
-
ePub (647.4 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (401.9 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
En este documento se describen los errores de verificación de redundancia cíclica (CRC, Cyclic Redundancy Check) que se observan en los contadores de interfaz y las estadísticas de los switches Cisco Nexus.
Prerequisites
Requirements
Cisco recomienda que comprenda los aspectos básicos de switching de Ethernet y la interfaz de línea de comandos (CLI) de Cisco NX-OS. Para obtener más información, consulte uno de estos documentos aplicables:
- Guía de configuración de aspectos fundamentales de Cisco Nexus 9000 NX-OS, versión 10.2(x)
- Guía de configuración de aspectos fundamentales de Cisco Nexus Serie 9000 NX-OS, versión 9.3(x)
- Guía de configuración de aspectos fundamentales de Cisco Nexus Serie 9000 NX-OS, versión 9.2(x)
- Guía de configuración de aspectos fundamentales de Cisco Nexus Serie 9000 NX-OS, versión 7.x
Componentes Utilizados
La información que contiene este documento se basa en las siguientes versiones de software y hardware.
- Switches Nexus Serie 9000 a partir de la versión 9.3(8) del software NX-OS
- Switches Nexus Serie 3000 a partir de la versión 9.3(8) del software NX-OS
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
En este documento se describen los detalles sobre los errores de verificación de redundancia cíclica (CRC) que se observan en los contadores de interfaz de los switches de la serie Cisco Nexus. En este documento se describe qué es una CRC, cómo se usa en el campo de la secuencia de verificación de tramas (FCS, Frame Check Sequence) de las tramas de Ethernet, cómo se manifiestan los errores de CRC en los switches Nexus y cómo interactúan los errores de CRC en el switching de almacenamiento y reenvío. En este artículo también se describen las situaciones de switching por método de atajo, las causas raíz más probables de los errores de CRC y cómo solucionar los problemas de CRC.
Hardware aplicable
La información de este documento se aplica a todos los switches de la serie Cisco Nexus. Parte de la información de este documento también puede aplicarse a otras plataformas de routing y switching de Cisco, como los routers y switches Cisco Catalyst.
Definición de CRC
Se denomina CRC al mecanismo de detección de errores que se usa comúnmente en redes informáticas y de almacenamiento para identificar los datos modificados o dañados durante la transmisión. Cuando un dispositivo conectado a la red necesita transmitir datos, el dispositivo ejecuta un algoritmo de cálculo basado en códigos cíclicos contra los datos que resultan en un número de longitud fija. Este número de longitud fija se denomina valor de CRC, pero coloquialmente, a menudo se denomina CRC para abreviar. Este valor de CRC se agrega a los datos y se transmite a través de la red hacia otro dispositivo. Este dispositivo remoto ejecuta el mismo algoritmo de código cíclico contra los datos y compara el valor que se obtiene con la CRC adjunta a los datos. Si ambos valores coinciden, el dispositivo remoto supone que los datos se transmitieron a través de la red de forma correcta. Si los valores no coinciden, el dispositivo remoto asume que los datos se dañaron en la transmisión a través de la red. Estos datos dañados no son confiables y se descartan.
Las CRC se usan para la detección de errores en varias tecnologías de redes informáticas, como Ethernet (variantes cableadas e inalámbricas), Token Ring, modo de transferencia asíncrona (ATM, asynchronous transfer mode) y retransmisión de tramas. Las tramas Ethernet tienen un campo de secuencia de verificación de tramas (FCS) de 32 bits al final de la trama (inmediatamente después de la carga útil de la trama) donde se inserta un valor CRC de 32 bits.
Por ejemplo, considere una situación en la que dos hosts denominados Host-A y Host-B están conectados directamente entre sí a través de sus tarjetas de interfaz de red (NIC, Network Interface Card). El Host-A debe enviar la oración “Este es un ejemplo” al Host-B a través de la red. El Host-A crea una trama de Ethernet destinada al Host-B con una carga útil de “Este es un ejemplo” y calcula que el valor de CRC de la trama es un valor hexadecimal de 0xABCD. El Host-A inserta el valor de CRC de 0xABCD en el campo de FCS de la trama de Ethernet y luego transmite la trama de Ethernet fuera de la NIC del Host-A hacia el Host-B.
Cuando el Host-B recibe esta trama, puede calcular el valor de CRC de la trama usando exactamente el mismo algoritmo que el Host-A. El Host-B calcula que el valor de CRC de la trama es un valor hexadecimal de 0xABCD, lo que indica al Host-B que la trama de Ethernet no se dañó mientras la trama se transmitía al Host-B.
Definición de error de CRC
Un error de CRC se produce cuando un dispositivo (ya sea un dispositivo de red o un host conectado a la red) recibe una trama de Ethernet con un valor de CRC en el campo de FCS de la trama que no coincide con el valor de CRC calculado por el dispositivo para la trama.
Este concepto se demuestra mejor con un ejemplo. Considere una situación en la que dos hosts denominados Host-A y Host-B están conectados directamente entre sí a través de sus tarjetas de interfaz de red (NIC). El Host-A debe enviar la oración “Este es un ejemplo” al Host-B a través de la red. El Host-A crea una trama de Ethernet destinada al Host-B con una carga útil de “Este es un ejemplo” y calcula que el valor de CRC de la trama es el valor hexadecimal 0xABCD. El Host-A inserta el valor de CRC de 0xABCD en el campo de FCS de la trama de Ethernet y luego transmite la trama de Ethernet fuera de la NIC del Host-A hacia el Host-B.
Sin embargo, los daños en los medios físicos que conectan el Host-A con el Host-B corrompen el contenido de la trama de modo que la oración dentro de la trama cambia a “Este fue un ejemplo” en lugar de la carga útil deseada de “Este es un ejemplo”.
Cuando el Host-B recibe esta trama, puede calcular el valor de CRC de la trama e incluir la carga útil dañada en el cálculo. El Host-B calcula que el valor de CRC de la trama es un valor hexadecimal de 0xDEAD, que es diferente del valor de CRC de 0xABCD dentro del campo de FCS de la trama de Ethernet. Esta diferencia en los valores de CRC le indica al Host-B que la trama de Ethernet se dañó mientras se transmitía al Host-B. Como resultado, el Host-B no puede confiar en el contenido de esta trama de Ethernet, por lo que puede descartarla. Por lo general, el Host-B también puede incrementar algún tipo de contador de errores en su tarjeta de interfaz de red (NIC), como los contadores de “errores de entrada”, “errores de CRC” o “errores de recepción”.
Síntomas comunes de los errores de CRC
Los errores de CRC suelen manifestarse en una de estas dos formas:
- Contadores de errores incrementales o distintos de cero en las interfaces de dispositivos conectados a la red
- Pérdida de paquetes/tramas para el tráfico que atraviesa la red debido a que los dispositivos conectados a la red descartan tramas dañadas
Estos errores se manifiestan de maneras ligeramente diferentes dependiendo del dispositivo con el que esté trabajando. Estas subsecciones se detallan para cada tipo de dispositivo.
Errores recibidos en hosts de Windows
Los errores de CRC en los hosts de Windows generalmente se manifiestan como un contador de errores recibidos distinto de cero que se muestra en la salida del comando netstat -e de la petición de ingreso de comando. A continuación, se muestra un ejemplo de un contador de errores recibidos distinto de cero desde la petición de ingreso de comando de un host de Windows:
>netstat -e
Interface Statistics
Received Sent
Bytes 1116139893 3374201234
Unicast packets 101276400 49751195
Non-unicast packets 0 0
Discards 0 0
Errors 47294 0
Unknown protocols 0
La NIC y su respectivo controlador deben ser compatibles con la contabilización de los errores de CRC recibidos por la NIC para que la cantidad de errores recibidos informados por el comando netstat -e sea precisa. La mayoría de las NIC modernas y sus respectivos controladores son compatibles con la contabilización precisa de los errores de CRC recibidos por la NIC.
Errores de recepción en hosts de Linux
Los errores de CRC en los hosts de Linux generalmente se manifiestan como un contador de “errores de recepción” distinto de cero que se muestra en la salida del comando ifconfig. A continuación, se incluye un ejemplo de un contador de errores de recepción distinto de cero de un host de Linux:
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.0.2.10 netmask 255.255.255.128 broadcast 192.0.2.255
inet6 fe80::10 prefixlen 64 scopeid 0x20<link>
ether 08:62:66:be:48:9b txqueuelen 1000 (Ethernet)
RX packets 591511682 bytes 214790684016 (200.0 GiB)
RX errors 478920 dropped 0 overruns 0 frame 0
TX packets 85495109 bytes 288004112030 (268.2 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Los errores de CRC en los hosts de Linux también pueden manifestarse como un contador de “errores de recepción” distinto de cero que se muestra en la salida del comando ip -s link show. A continuación, se incluye un ejemplo de un contador de errores de recepción distinto de cero de un host de Linux:
$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 08:62:66:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
La NIC y su respectivo controlador deben ser compatibles con la contabilización de los errores de CRC recibidos por la NIC para que la cantidad de errores de recepción informados por los comandos ifconfig o ip -s link show sea precisa. La mayoría de las NIC modernas y sus respectivos controladores son compatibles con la contabilización precisa de los errores de CRC recibidos por la NIC.
Errores de CRC en dispositivos de red
Los dispositivos de red funcionan en uno de los dos modos de reenvío:
- Modo de reenvío de almacenamiento y reenvío
- Modo de reenvío por método de atajo
La forma en que un dispositivo de red maneja un error de CRC recibido varía según sus modos de reenvío. En las subsecciones se describe el comportamiento específico de cada modo de reenvío.
Errores de entrada en dispositivos de red de almacenamiento y reenvío
Cuando un dispositivo de red que funciona en modo de reenvío de almacenamiento y reenvío recibe una trama, el dispositivo de red puede almacenar en búfer toda la trama (“Almacenamiento”) antes de que valide el valor de CRC de la trama y que tome una decisión de reenvío en la trama, y transmitir la trama fuera de una interfaz (“Reenvío”). Por lo tanto, cuando un dispositivo de red que funciona en modo de reenvío de almacenamiento y reenvío recibe una trama dañada con un valor de CRC incorrecto en una interfaz específica, puede descartar la trama e incrementar el contador de “errores de entrada” en la interfaz.
En otras palabras, los dispositivos de red no reenvían las tramas de Ethernet dañadas que funcionan en el modo de reenvío de almacenamiento y reenvío; se descartan al ingresar.
Los switches Cisco Nexus Series 7000 y 7700 funcionan en el modo de reenvío de almacenamiento y reenvío. A continuación, se incluye un ejemplo de un contador de errores de entrada distinto de cero y un contador de CRC/FCS diferente de cero de un switch Nexus Series 7000 o 7700:
switch# show interface
<snip>
Ethernet1/1 is up
RX
241052345 unicast packets 5236252 multicast packets 5 broadcast packets
245794858 input packets 17901276787 bytes
0 jumbo packets 0 storm suppression packets
0 runts 0 giants 579204 CRC/FCS 0 no buffer
579204 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
Los errores de CRC también pueden manifestarse como un contador “FCS-Err” distinto de cero en la salida de los errores show interface counters. El contador “Rcv-Err” en la salida de este comando también puede tener un valor distinto de cero, que es la suma de todos los errores de entrada (CRC o de otro tipo) que recibe la interfaz. A continuación, se muestra un ejemplo:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 579204 0 579204 0 0
Errores de entrada y salida en dispositivos de red de atajo
Cuando un dispositivo de red que funciona en modo de reenvío por método de atajo comienza a recibir una trama, el dispositivo de red puede tomar una decisión de reenvío en el encabezado de la trama y comenzar a transmitir la trama fuera de una interfaz tan pronto como reciba suficiente de la trama para tomar una decisión de reenvío válida. Como la trama y los encabezados de los paquetes se encuentran al comienzo de la trama, esta decisión de reenvío generalmente se toma antes de recibir la carga útil de la trama.
El campo de FCS de una trama de Ethernet se encuentra al final de la trama, inmediatamente después de la carga útil de la trama. Por lo tanto, un dispositivo de red que funciona en modo de reenvío por método de atajo ya puede haber comenzado a transmitir la trama desde otra interfaz para cuando pueda calcular la CRC de la trama. Si la CRC calculada por el dispositivo de red para la trama no coincide con el valor de CRC presente en el campo de FCS, eso significa que el dispositivo de red reenvió una trama dañada a la red. Cuando esto sucede, el dispositivo de red puede incrementar dos contadores:
- El contador de “errores de entrada” en la interfaz en la que se recibió originalmente la trama dañada
- El contador de “errores de salida” en todas las interfaces en las que se transmitió la trama dañada. En el caso del tráfico de unidifusión, suele tratarse de una única interfaz; sin embargo, en el caso del tráfico de difusión, multidifusión o unidifusión desconocido, puede tratarse de una o varias interfaces.
A continuación se muestra un ejemplo de esto, donde la salida del comando show interface indica que se recibieron varias tramas dañadas en Ethernet1/1 del dispositivo de red y se transmitieron fuera de Ethernet1/2 debido al modo de reenvío por método de atajo del dispositivo de red:
switch# show interface
<snip>
Ethernet1/1 is up
RX
46739903 unicast packets 29596632 multicast packets 0 broadcast packets
76336535 input packets 6743810714 bytes
15 jumbo packets 0 storm suppression bytes
0 runts 0 giants 47294 CRC 0 no buffer
47294 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
Ethernet1/2 is up
TX
46091721 unicast packets 2852390 multicast packets 102619 broadcast packets
49046730 output packets 3859955290 bytes
50230 jumbo packets
47294 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Los errores de CRC también pueden manifestarse como un contador “FCS-Err” distinto de cero en la interfaz de entrada y contadores “Xmit-Err” distintos de cero en las interfaces de salida en la salida de errores show interface counters. El contador “Rcv-Err” en la interfaz de entrada en la salida de este comando también puede tener un valor distinto de cero, que es la suma de todos los errores de entrada (CRC o de otro tipo) que recibe la interfaz. A continuación, se muestra un ejemplo:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 47294 0 47294 0 0
Eth1/2 0 0 47294 0 0 0
El dispositivo de red también puede modificar el valor de CRC en el campo de FCS de la trama de una manera específica que indica a los dispositivos de red ascendentes que esta trama está dañada. Este comportamiento se conoce como “pisotear” la CRC. La manera precisa en que se modifica el CRC varía de una plataforma a otra, pero generalmente, calcula el valor CRC de la trama dañada, luego invierte ese valor e lo inserta en el campo FCS de la trama. A continuación, se presenta un ejemplo de esto:
Original Frame's CRC: 0xABCD (1010101111001101)
Corrupted Frame's CRC: 0xDEAD (1101111010101101)
Corrupted Frame's Stomped CRC: 0x2152 (0010000101010010)
Como resultado de este comportamiento, los dispositivos de red que funcionan en modo de reenvío por método de atajo pueden propagar una trama dañada por toda la red. Si una red consta de varios dispositivos de red que funcionan en un modo de reenvío por método de atajo, una sola trama dañada puede hacer que los contadores de errores de entrada y de salida se incrementen en varios dispositivos de red dentro de la red.
Seguimiento y aislamiento de errores de CRC
El primer paso para identificar y resolver la causa raíz de los errores de CRC es aislar el origen de los errores de CRC en un enlace específico entre dos dispositivos dentro de la red. Un dispositivo conectado a este enlace puede tener un contador de errores de salida de interfaz con un valor de cero o no incremental, mientras que el otro dispositivo conectado a este enlace puede tener un contador de errores de entrada de interfaz incremental o distinto de cero. Esto sugiere que el tráfico que sale intacto de la interfaz de un dispositivo está dañado en el momento de la transmisión al dispositivo remoto y es contabilizado como un error de entrada por la interfaz de entrada del otro dispositivo del enlace.
Identificar este enlace en una red que consta de dispositivos de red que funcionan en modo de reenvío de almacenamiento y reenvío es una tarea sencilla. Sin embargo, si identifica este enlace en una red que consta de dispositivos de red que funcionan en un modo de reenvío por método de atajo es más difícil, ya que muchos dispositivos de red pueden tener contadores de errores de entrada y salida distintos de cero. Un ejemplo de este fenómeno se puede ver en la topología, en la que el enlace resaltado en rojo está dañado de modo que el tráfico que atraviesa el enlace está dañado. Las interfaces etiquetadas con una “I” roja indican interfaces que podrían tener errores de entrada distintos de cero, mientras que las interfaces etiquetadas con una “O” azul indican interfaces que podrían tener errores de salida distintos de cero.

En este documento se describen los errores de verificación de redundancia cíclica (CRC, Cyclic Redundancy Check) que se observan en los contadores de interfaz y las estadísticas de los switches Cisco Nexus.
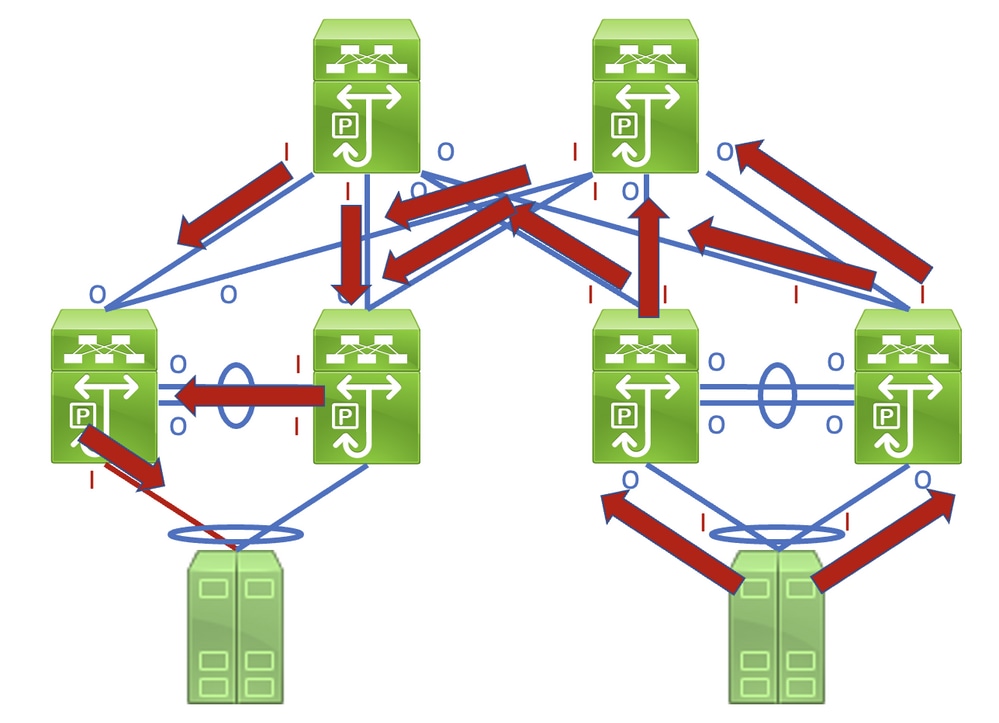
Un proceso detallado para identificar y hacer un seguimiento del enlace dañado se demuestra mejor con un ejemplo. Considere la topología aquí:

En esta topología, la interfaz Ethernet1/1 de un switch Nexus denominado Switch-1 se conecta a un host denominado Host-1 a través de la tarjeta de interfaz de red (NIC) eth0 del Host-1. La interfaz Ethernet1/2 del Switch-1 se conecta a un segundo switch Nexus, denominado Switch-2, a través de la interfaz Ethernet1/2 del Switch-2. La interfaz Ethernet1/1 del Switch-2 está conectada a un host denominado Host-2 a través de la NIC eth0 del Host-2.
El enlace entre el Host-1 y el Switch-1 a través de la interfaz Ethernet1/1 del Switch-1 está dañado y hace que el tráfico que atraviesa el enlace se dañe intermitentemente. Sin embargo, se desconoce si el enlace está dañado en este momento. Debe hacer un seguimiento de la ruta que dejan las tramas dañadas en la red a través de contadores de errores de entrada y salida incrementales o distintos de cero para ubicar el enlace dañado en esta red.
En este ejemplo, la NIC del Host-2 informa que está recibiendo errores de CRC.
Host-2$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
Sabe que la NIC del Host-2 se conecta al Switch-2 a través de la interfaz Ethernet1/1. Puede confirmar que la interfaz Ethernet1/1 tiene un contador de errores de salida distinto de cero con el comando show interface.
Switch-2# show interface
<snip>
Ethernet1/1 is up
admin state is up, Dedicated Interface
RX
30184570 unicast packets 872 multicast packets 273 broadcast packets
30185715 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
444907944 unicast packets 932 multicast packets 102 broadcast packets
444908978 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Dado que el contador de errores de salida de la interfaz Ethernet1/1 no es cero, lo más probable es que haya otra interfaz del Switch-2 que tenga un contador de errores de entrada distinto de cero. Puede usar el comando show interface counters errors non-zero para identificar si alguna de las interfaces del Switch-2 tiene un contador de errores de entrada distinto de cero.
Switch-2# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 0 478920 0 0 0 Eth1/2 0 478920 0 478920 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
Puede ver que Ethernet1/2 del Switch-2 tiene un contador de errores de entrada distinto de cero. Esto sugiere que el Switch-2 recibe tráfico dañado en esta interfaz. Puede confirmar qué dispositivo está conectado a Ethernet1/2 del Switch-2 a través de las funciones del Cisco Discovery Protocol (CDP) o del protocolo de detección local de enlaces (LLDP, Link Local Discovery Protocol). A continuación, se muestra un ejemplo con el comando show cdp neighbors.
Switch-2# show cdp neighbors
<snip>
Capability Codes: R - Router, T - Trans-Bridge, B - Source-Route-Bridge
S - Switch, H - Host, I - IGMP, r - Repeater,
V - VoIP-Phone, D - Remotely-Managed-Device,
s - Supports-STP-Dispute
Device-ID Local Intrfce Hldtme Capability Platform Port ID
Switch-1(FDO12345678)
Eth1/2 125 R S I s N9K-C93180YC- Eth1/2
Ahora sabe que el Switch-2 recibe tráfico dañado en su interfaz Ethernet1/2 desde la interfaz Ethernet1/2 del Switch-1, pero aún no sabe si el enlace entre Ethernet1/2 del Switch-1 y Ethernet1/2 del Switch-2 está dañado y causa el error, o si el Switch-1 es un switch por método de atajo que reenvía el tráfico dañado que recibe. Debe iniciar sesión en el Switch-1 para verificarlo.
Puede confirmar que la interfaz Ethernet1/2 del Switch-1 tiene un contador de errores de salida distinto de cero con el comando show interfaces.
Switch-1# show interface
<snip>
Ethernet1/2 is up
admin state is up, Dedicated Interface
RX
30581666 unicast packets 178 multicast packets 931 broadcast packets
30582775 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
454301132 unicast packets 734 multicast packets 72 broadcast packets
454301938 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Puede ver que Ethernet1/2 del Switch-1 tiene un contador de errores de salida distinto de cero. Esto sugiere que el enlace entre Ethernet1/2 del Switch-1 y Ethernet1/2 del Switch-2 no está dañado; en su lugar, el Switch-1 es un switch por método de atajo que reenvía el tráfico dañado que recibe en alguna otra interfaz. Como se demostró anteriormente con el Switch-2, puede usar el comando para identificar si alguna interfaz del Switch-1 tiene un contador de errores de entrada distinto de cero.show interface counters errors non-zero
Switch-1# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 478920 0 478920 0 0 Eth1/2 0 0 478920 0 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
Puede ver que Ethernet1/1 del Switch-1 tiene un contador de errores de entrada distinto de cero. Esto sugiere que el Switch-1 recibe tráfico dañado en esta interfaz. Sabemos que esta interfaz se conecta a la NIC eth0 del Host-1. Podemos revisar las estadísticas de la interfaz de la NIC eth0 del Host-1 para confirmar si el Host-1 envía tramas dañadas fuera de esta interfaz.
Host-1$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
73146816142 423112898 0 0 0 437368817
TX: bytes packets errors dropped carrier collsns
3312398924 37942624 0 0 0 0
altname enp11s0
Las estadísticas de la NIC eth0 del Host-1 indican que el host no transmite tráfico dañado. Esto sugiere que el enlace entre eth0 del Host-1 y Ethernet1/1 del Switch-1 está dañado y es el origen de este error de tráfico. Debe solucionar los problemas de este enlace para identificar el componente defectuoso que causa este error y reemplazarlo.
Causas raíz de los errores de CRC
La causa raíz más común de los errores de CRC es un componente dañado o defectuoso de un enlace físico entre dos dispositivos. Entre los ejemplos, se encuentran los siguientes:
- Medio físico defectuoso o dañado (cobre o fibra) o cables de conexión directa (DAC, Direct Attach Cables)
- Transceptores u ópticas defectuosas o dañadas
- Puertos del panel de conexiones defectuosos o dañados
- Hardware de dispositivos de red defectuoso (esto incluye puertos específicos, circuitos integrados de aplicaciones específicas [ASIC] de tarjeta de línea, controles de acceso a medios [MAC], módulos de estructura, etc.)
- Tarjeta de interfaz de red defectuosa insertada en un host
También es posible que uno o varios dispositivos mal configurados provoquen de forma involuntaria errores de CRC en una red. Un ejemplo de esto es la incompatibilidad en la configuración de la unidad de transmisión máxima (MTU, Maximum Transmission Unit) entre dos o más dispositivos dentro de la red que hace que los paquetes grandes se trunquen incorrectamente. Cuando se identifica y se resuelve este problema de configuración, también se pueden corregir los errores de CRC dentro de una red.
Resolución de errores de CRC
Se puede identificar el componente defectuoso específico mediante un proceso de eliminación:
- Reemplace el medio físico (cobre o fibra) o el DAC con un medio físico en buen estado del mismo tipo.
- Reemplace el transceptor insertado en la interfaz de un dispositivo con un transceptor en buen estado del mismo modelo. Si esto no resuelve los errores de CRC, reemplace el transceptor insertado en la interfaz del otro dispositivo con un transceptor en buen estado del mismo modelo.
- Si se usa algún panel de conexiones como parte del enlace dañado, mueva el enlace a un puerto en buen estado del panel de conexiones. De otro modo, puede eliminar el panel de conexiones como posible causa raíz conectando el enlace sin el panel de conexiones, si es posible.
- Mueva el enlace dañado a un puerto diferente y en buen estado de cada dispositivo. Es posible que deba probar varios puertos diferentes para aislar una falla del MAC, del ASIC o de la tarjeta de línea.
- Si el enlace dañado implica a un host, mueva el enlace a una NIC diferente en el host. De otro modo, conecte el enlace dañado a un host en buen estado para aislar una falla de la NIC del host.
Si el componente defectuoso es un producto de Cisco (como un dispositivo de red o transceptor de Cisco) que está cubierto por un contrato de soporte activo, puede abrir un caso de soporte con Cisco TAC, incluir los detalles del problema y solicitar que el componente defectuoso se reemplace a través de una autorización de devolución de materiales (RMA, Return Material Authorization).
Información Relacionada
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
3.0 |
10-Nov-2021 |
Mejorar el formato secundario del documento |
2.0 |
10-Nov-2021 |
Versión inicial |
1.0 |
10-Nov-2021 |
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Christopher HartCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)