Cómo elegir la mejor ruta de switching de router para su red
Contenido
Introducción
Hay una gran cantidad de trayectorias de conmutación disponibles para diversos routers de Cisco y versiones de Cisco IOS®. ¿Cuál es el mejor para su red, y cómo funcionan todos ellos? Este informe oficial intenta explicar cada uno de los siguientes trayectos de conmutación para que pueda tomar la mejor decisión en cuanto a qué trayecto de conmutación se adecua a su red.
Primero, examine el proceso de reenvío en sí. Hay tres pasos para reenviar un paquete a través de un router:
-
Determine si el destino del paquete es alcanzable.
-
Determine el salto siguiente hacia el destino y la interfaz a través de la cual se puede alcanzar ese salto siguiente.
-
Reescriba el encabezado de Control de acceso de medios (MAC) en el paquete de modo que llegue correctamente a su salto siguiente.
Cada uno de estos pasos es crítico para lograr que el paquete llegue a destino.
Nota: A lo largo de este documento, la trayectoria de IP Switching se utiliza como ejemplo; casi toda la información proporcionada aquí se aplica a trayectos de conmutación equivalentes para otros protocolos, en caso de que éstos existan.
Proceso de Switching
El switching de procesos es el denominador común más bajo en trayectos de conmutación; está disponible en cada versión del IOS, en cada plataforma y para cada tipo de tráfico que se conmuta. El switching de procesos se define por dos conceptos esenciales:
-
La decisión de reenvío y la información utilizada para volver a escribir el encabezado MAC en el paquete se toman de la tabla de ruteo (de la base de información de ruteo o RIB) y de la memoria caché del Protocolo de resolución de dirección (ARP); o bien, de alguna otra tabla que incluya la información del encabezado MAC correlacionada con la dirección IP de cada host que está conectado directamente al router.
-
El paquete es conmutado por un proceso normal que se ejecuta dentro del IOS. En otras palabras, la decisión de reenvío es tomada por un proceso programado a través del planificador del IOS y que se ejecuta como peer a otros procesos en el router, como los protocolos de ruteo. Los procesos que normalmente se ejecutan en el router no se interrumpen para procesar el switch de un paquete.
La siguiente figura ilustra la trayectoria de conmutación del proceso.
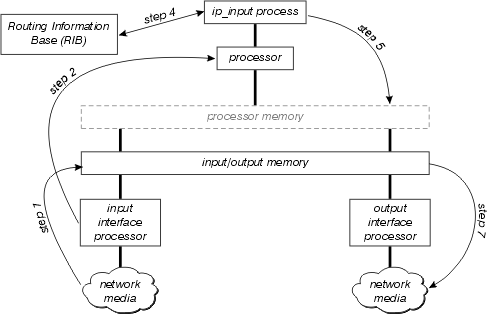
Examine este diagrama con mayor detenimiento:
-
El procesador de interfaz primero detecta si hay algún paquete en los medios de la red y transfiere este paquete a la memoria de entrada/salida del router.
-
El procesador de interfaz genera una interrupción de recepción. Durante esta interrupción, el procesador central determina qué tipo de paquete es (suponga que es un paquete IP) y lo copia en la memoria del procesador si es necesario (esta decisión depende de la plataforma). Finalmente, el procesador coloca el paquete en la cola de entrada del proceso apropiado y se libera la interrupción.
-
La próxima vez que el programador se ejecuta, advierte el paquete en la cola de entrada de ip_input (entrada de ip) y programa este proceso para su ejecución.
-
Cuando ip_input se ejecuta, consulta a la RIB para determinar el salto siguiente y la interfaz de salida, luego consulta la memoria caché ARP para determinar la dirección de capa física correcta para este salto siguiente.
-
ip_input luego reescribe el paquete del encabezado MAC y lo ubica en la cola de salida de la interfaz de salida correcta.
-
El paquete se copia de la cola de salida de la interfaz de salida a la cola de transmisión de la interfaz de salida; cualquier calidad de servicio de salida tiene lugar entre estas dos colas.
-
El procesador de interfaz de salida detecta el paquete en la cola de transmisión y transfiere el paquete al medio de red.
Casi todas las funciones que afectan al switching de paquetes, como la traducción de direcciones de red (NAT) y el routing de políticas, hacen su debut en la ruta de switching del proceso. Una vez que se han probado y optimizado, estas funciones pueden o no aparecer en interrupt context switching.
Conmutación de contexto de la interrupción
La conmutación de contexto de interrupción es el segundo de los métodos de conmutación principales utilizados por los routers de Cisco. Las principales diferencias entre el switching de contexto de interrupción y el switching de procesos son:
-
El proceso que se ejecuta actualmente en el procesador se interrumpe para conmutar el paquete. Los paquetes se conmutan a demanda, en lugar de conmutarse sólo cuando el proceso ip_input se puede programar.
-
El procesador utiliza algún tipo de memoria caché de ruta para encontrar toda la información necesaria para conmutar el paquete.
Esta figura ilustra interrupt context switching:
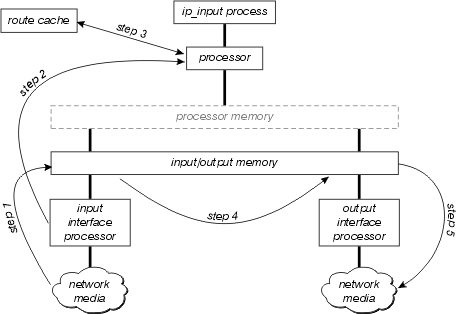
Examine este diagrama con mayor detenimiento:
-
El procesador de interfaz primero detecta si hay algún paquete en los medios de la red y transfiere este paquete a la memoria de entrada/salida del router.
-
El procesador de interfaz genera una interrupción de recepción. Durante esta interrupción, el procesador central determina qué tipo de paquete es (suponga que es un paquete IP) y luego comienza a conmutar el paquete.
-
El procesador busca en la memoria caché de ruta para determinar si el destino del paquete es alcanzable, cuál debería ser la interfaz de salida, cuál es el salto siguiente hacia este destino y, finalmente, qué encabezado MAC debe tener el paquete para alcanzar con éxito el salto siguiente. El procesador utiliza esta información para reescribir el encabezado MAC del paquete.
-
El paquete se copia ahora en la cola de transmisión o de salida de la interfaz de salida (dependiendo de varios factores). La interrupción de recepción ahora vuelve y el proceso que se ejecutaba en el procesador antes de que se produjera la interrupción continúa ejecutándose.
-
El procesador de interfaz de salida detecta el paquete en la cola de transmisión y transfiere el paquete al medio de red.
La primera pregunta que viene a la mente después de leer esta descripción es "¿Qué hay en la memoria caché?" Hay tres respuestas posibles, dependiendo del tipo de conmutación de contexto de interrupción:
Fast Switching
Fast Switching almacena la información de reenvío y la cadena de reescritura del encabezado MAC mediante un árbol binario para una búsqueda y referencia rápidas. Esta figura ilustra un árbol binario:
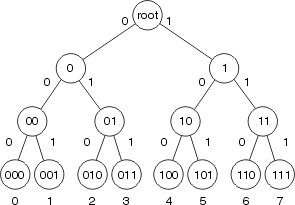
En Fast Switching, la información de alcance se indica por la existencia de un nodo en el árbol binario para el destino del paquete. El encabezado MAC y la interfaz saliente para cada destino se almacenan como parte de la información del nodo dentro del árbol. El árbol binario puede en realidad tener 32 niveles (el árbol anterior es extremadamente abreviado para el propósito de la ilustración).
Para buscar un árbol binario, simplemente empieza desde la izquierda (con el dígito más significativo) en el número (binario) que está buscando, y bifurque hacia la derecha o hacia la izquierda en el árbol basado en ese número. Por ejemplo, si está buscando la información relacionada con el número 4 en este árbol, empezaría bifurcando a la derecha, porque el primer dígito binario es 1. Debe seguir el árbol hacia abajo, comparando en dígito siguiente en el número (binario), hasta alcanzar el final.
Características de Fast Switching
Fast Switching tiene varias características que son resultado de la estructura de árbol binario y el almacenamiento de la información de reescritura del encabezado MAC como parte de los nodos de árbol.
-
Debido a que no hay correlación entre la tabla de ruteo y el contenido de la memoria caché rápida (por ejemplo, reescritura del encabezado MAC), la generación de entradas de memoria caché implica todo el procesamiento que se debe hacer en la ruta de conmutación del proceso. Por lo tanto, las entradas de memoria caché rápidas se generan a medida que los paquetes se conmutan por proceso.
-
Debido a que no hay correlación entre los encabezados MAC (utilizados para las reescrituras) en la memoria caché ARP y la estructura de la memoria caché rápida, cuando cambia la tabla ARP, se debe invalidar parte de la memoria caché rápida (y volver a crearla a través del proceso de conmutación de paquetes).
-
La memoria caché rápida sólo puede generar entradas a una profundidad (una longitud de prefijo) para cualquier destino en la tabla de ruteo.
-
No hay manera de apuntar de una entrada a otra dentro de la memoria caché rápida (se espera que la información del encabezado MAC y de la interfaz saliente esté dentro del nodo), por lo que todas las recursiones de ruteo deben resolverse mientras se genera una entrada de memoria caché rápida. En otras palabras, las rutas recursivas no se pueden resolver dentro de la memoria caché rápida misma.
Entradas Desactualizadas de Fast Switching
Para evitar que las entradas de fast switching pierdan su sincronización con la tabla de ruteo y la memoria caché ARP, y para evitar que las entradas no usadas en la memoria caché rápida consuman indebidamente memoria en el router, 1/20 de la memoria caché rápida se invalida, aleatoriamente, cada minuto. Si la memoria de los routers cae por debajo de una marca de agua muy baja, 1/5 de las entradas de memoria caché rápida se invalidan cada minuto.
Longitud de Prefijo de Fast Switching
¿Para qué longitud de prefijo el fast switching construye entradas si únicamente puede construir una longitud de prefijo para cada destino? Dentro de los términos de fast switching, un destino es un único destino alcanzable dentro de la tabla de ruteo, o una red principal. Las reglas para decidir qué longitud de prefijo se generará una entrada de caché dada son:
-
Si se construye una entrada de política rápida , siempre almacene en la memoria caché a /32
-
Si construye una entrada contra un Multiprotocolo en un circuito virtual ATM (MPOA VC), siempre almacene en memoria caché a /32.
-
Si la red no está constituida en subredes (es una entrada de red principal):
-
Si está conectado directamente, utilice /32;
-
De lo contrario, utilice la máscara de red principal.
-
-
Si es una superred utilice la máscara de superred.
-
Si la red está conectada en subredes:
-
Si está conectado directamente, utilice /32;
-
Si hay múltiples trayectos para esta subred, utilice /32;
-
En todos los otros casos, utilice la longitud de prefijo más larga en esta red principal.
-
Carga a compartir
Fast Switching se basa completamente en el destino; el uso compartido de la carga se realiza por destino. Si hay varias trayectorias de igual costo para una red de destino determinada, la memoria caché rápida tiene una entrada para cada host al que se puede acceder dentro de esa red, pero todo el tráfico destinado a un host determinado sigue un link.
Optimum Switching
Optimum switching almacena la información de reenvío y la información de reescritura del encabezado MAC en un árbol de múltiples vías de 256 vías (árbol de 256 vías). El uso de un árbol reduce el número de pasos que se deben realizar al buscar un prefijo, como se muestra en la siguiente figura.
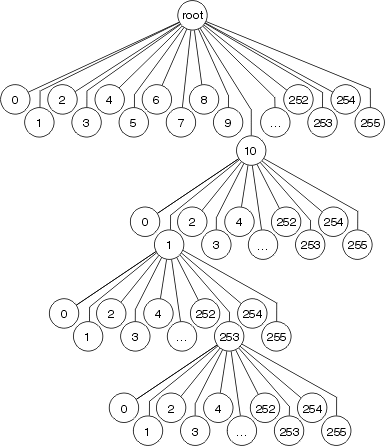
Cada octeto se utiliza para determinar cuáles de las 256 ramas que se van a tomar en cada nivel del árbol, lo que significa que hay, como máximo, 4 búsquedas involucradas en la búsqueda de cualquier destino. En el caso de longitudes de prefijo más cortas, es posible que sólo se requieran una o tres búsquedas. La información de la interfaz de reescritura y de salida del encabezado MAC se almacena como parte del nodo de árbol, por lo que la invalidación y el envejecimiento de la memoria caché siguen ocurriendo como en el fast switching.
Optimum switching también determina la longitud del prefijo para cada entrada de caché de la misma manera que fast switching.
Cisco Express Forwarding
Cisco Express Forwarding también utiliza una estructura de datos de 256 modos para almacenar información de reenvío y reescritura de encabezado MAC, pero no utiliza un árbol. Cisco Express Forwarding utiliza una prueba, lo que significa que la información real que se busca no está en la estructura de datos; en su lugar, los datos se almacenan en una estructura de datos independiente y el trío simplemente apunta a ellos. En otras palabras, en lugar de almacenar la interfaz saliente y la reescritura del encabezado MAC dentro del propio árbol, Cisco Express Forwarding almacena esta información en una estructura de datos independiente llamada tabla de adyacencia.
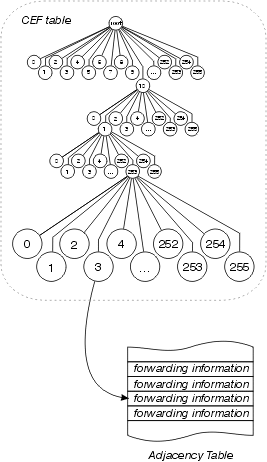
Esta separación de la información de alcance (en la tabla de Cisco Express Forwarding) y de la información de envío (en la tabla de adyacencia), otorga varios beneficios:
-
La tabla de adyacencia puede crearse independientemente de la tabla Cisco Express de reenvío, lo que permite crearla sin el proceso de conmutar paquetes.
-
La reescritura del encabezado MAC utilizada para reenviar un paquete no se almacena en las entradas de caché, por lo que los cambios en una cadena de reescritura del encabezado MAC no requieren la invalidación de las entradas de caché.
-
Puede apuntar directamente a la información de reenvío, en lugar del siguiente salto recurrido, para resolver las rutas recursivas.
Básicamente, se elimina todo el envejecimiento de la memoria caché, y la memoria caché se genera previamente en función de la información contenida en la tabla de ruteo y la memoria caché ARP. No es necesario procesar el switch de ningún paquete para generar una entrada de caché.
Otras entradas en la Tabla de Adyacencia.
La tabla de adyacencia puede contener entradas que no sean cadenas de reescritura de encabezado MAC e información de interfaz saliente. Algunos de los diversos tipos de entradas que se pueden colocar en la tabla de adyacencia incluyen:
-
cache: una cadena de reescritura de encabezado MAC y una interfaz de salida que se utiliza para alcanzar un host o router adyacente determinado.
-
receive: El router debe recibir los paquetes destinados a esta dirección IP. Esto incluye las direcciones y direcciones de broadcast configuradas en el propio router.
-
drop: los paquetes destinados a esta dirección IP deben eliminarse. Esto se podría utilizar para el tráfico denegado por una lista de acceso o enrutado a una interfaz NULA.
-
punt: Cisco Express Forwarding no puede conmutar este paquete; derívelo al siguiente mejor método de switching (generalmente fast switching) para el procesamiento.
-
glean: el salto siguiente está directamente conectado, pero no hay cadenas de reescritura de encabezado MAC actualmente disponibles.
Adyacencias de Glean
Una entrada de adyacencia glean indica que un salto siguiente determinado debería estar conectado directamente, pero no hay información de reescritura de encabezado MAC disponible. ¿Cómo se crean y utilizan? Un router que está ejecutando Cisco Express Forwarding y está conectado a una red de transmisión, como se muestra en la figura ubicada a continuación, crea de forma predeterminada una cantidad de entradas de tabla de adyacencia.
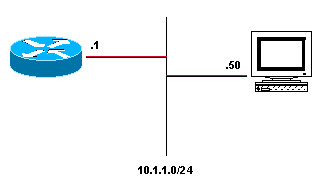
Las cuatro entradas de la tabla de adyacencia generadas de forma predeterminada son:
10.1.1.0/24, version 17, attached, connected
0 packets, 0 bytes
via Ethernet2/0, 0 dependencies
valid glean adjacency
10.1.1.0/32, version 4, receive
10.1.1.1/32, version 3, receive
10.1.1.255/32, version 5, receive
Tenga en cuenta que hay cuatro entradas: tres reciben y una glean. Cada entrada de recepción representa una dirección de broadcast o una dirección configurada en el router, mientras que la entrada de luz representa el resto del espacio de dirección en la red conectada. Si se recibe un paquete para el host 10.1.1.50, el router intenta conmutarlo y lo encuentra resuelto a esta adyacencia global. Cisco Express Forwarding luego señala que se necesita una entrada de memoria caché ARP para 10.1.1.50, el proceso ARP envía un paquete ARP y la entrada de la tabla de adyacencia apropiada se genera a partir de la nueva información de memoria caché ARP. Después de completar este paso, la tabla de adyacencia tiene una entrada para 10.1.1.50.
10.1.1.0/24, version 17, attached, connected
0 packets, 0 bytes
via Ethernet2/0, 0 dependencies
valid glean adjacency
10.1.1.0/32, version 4, receive
10.1.1.1/32, version 3, receive
10.1.1.50/32, version 12, cached adjacency 208.0.3.2
0 packets, 0 bytes
via 208.0.3.2, Ethernet2/0, 1 dependency
next hop 208.0.3.2, Ethernet2/0
valid cached adjacency
10.1.1.255/32, version 5, receive
El próximo paquete destinado a 10.1.1.50 que recibe el router se conmuta mediante esta nueva adyacencia.
Carga a compartir
Cisco Express Forwarding también aprovecha la separación entre la tabla Cisco Express Forwarding y la tabla de adyacencia para proporcionar una mejor forma de distribución de carga que cualquier otro modo de conmutación de contexto de interrupción. Se inserta una tabla de carga compartida entre la tabla Cisco Express Forwarding y la tabla de adyacencia, como se muestra en esta figura:
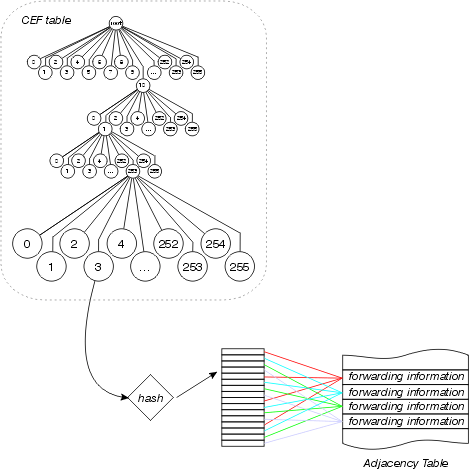
La tabla Cisco Express Forwarding señala a esta tabla de carga compartida, que contiene punteros a las diversas entradas de la tabla de adyacencia para las trayectorias paralelas disponibles. Las direcciones de origen y de destino se pasan a través de un algoritmo hash para determinar qué entrada de tabla de carga compartida se utilizará para cada paquete. Se puede configurar el uso compartido de carga por paquete, en cuyo caso cada paquete utiliza una entrada de tabla de carga compartida diferente.
Cada tabla de carga compartida tiene 16 entradas entre las cuales las trayectorias disponibles se dividen en función del contador de tráfico compartido en la tabla de ruteo. Si los contadores de tráfico compartido en la tabla de ruteo son todos 1 (como en el caso de varias trayectorias de igual costo), cada salto siguiente posible recibe un número igual de punteros de la tabla de carga compartida. Si el número de trayectos disponibles no se puede dividir uniformemente en 16 (ya que hay 16 entradas de tabla de loadshare), algunas trayectorias tendrán más entradas que otras.
A partir de Cisco IOS Software Release 12.0, el número de entradas en la tabla loadshare se reduce para asegurarse de que cada trayectoria tenga un número proporcional de entradas de la tabla loadshare. Por ejemplo, si hay tres trayectos de igual costo en la tabla de ruteo, sólo se utilizan 15 entradas de tabla de loadshare.
¿Qué Trayecto de Switching es mejor?
Siempre que sea posible, desea que los routers estén conmutando en el contexto de interrupción porque es al menos un orden de magnitud más rápido que el switching de nivel de proceso. El switching de Cisco Express Forwarding es definitivamente más rápido y mejor que cualquier otro modo de conmutación. Le recomendamos que utilice Cisco Express Forwarding si el protocolo y el IOS que está ejecutando lo soportan. Esto es particularmente cierto si tiene varios links paralelos a través de los cuales se debería cargar el tráfico compartido. Acceda a la página Cisco Feature Navigator (sólo clientes registrados) para determinar qué IOS necesita para el soporte de CEF.
Información Relacionada
- Cómo Verificar Cisco Express Forwarding Switching
- Resolución de problemas de equilibrio de carga sobre enlaces paralelos por medio de Cisco Express Forwarding
- Balanceo de Carga con CEF
- Página de soporte de Cisco Express Forwarding
- Página de Soporte de IP Routing
- Guía de Configuración de Servicios de Switching de Cisco IOS, Versión 12.1
- Soporte Técnico - Cisco Systems
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)