Uso del agente de la garantía de servicio de Cisco e Internetwork Performance Monitor para administrar la calidad del servicio en redes de voz sobre IP
Contenido
Introducción
Este documento describe el uso de Cisco Service Assurance Agent (SAA) y Internetwork Performance Monitor (IPM) para medir la calidad del servicio (QoS) en redes de voz sobre IP (VoIP). Esta información se basa en un proyecto de telefonía IP real. Este documento se centra en la aplicación de los productos, no en los propios productos. Ya debería estar familiarizado con Cisco SAA e IPM y tener acceso a la documentación del producto requerida. Vea la Información Relacionada para las referencias de otra documentación.
Nota: La funcionalidad de Cisco SAA en el software Cisco IOS® se conocía anteriormente como Response Time Reporter (RTR).
Cuando gestiona una red VoIP a gran escala, debe disponer de las herramientas necesarias para supervisar de forma objetiva la calidad de voz en la red e informar al respecto. No es factible confiar únicamente en los comentarios de los usuarios, ya que a menudo son subjetivos e incompletos. Los problemas de calidad de voz provienen generalmente de problemas de red de QoS. Por lo tanto, cuando identifica problemas de calidad de voz, necesita una segunda herramienta para administrar y monitorear la QoS de red. El ejemplo de este documento utiliza Cisco SAA e IPM con este fin.
Cisco Voice Manager (CVM) se utiliza con Telemate.net para gestionar la calidad de la voz. Informa sobre la calidad de voz de las llamadas a través del factor de discapacidad de planificación calculada (ICPIF) que calcula una gateway de Cisco IOS para cada llamada. Esto permite que el administrador de red identifique los sitios que padecen una calidad de voz deficiente. Consulte Administración de Calidad de Voz con Cisco Voice Manager (CVM) y Telemate para obtener más información.
Prerequisites
Requirements
No hay requisitos específicos para este documento.
Componentes Utilizados
Este documento no se limita a versiones específicas de software o hardware, pero los ejemplos de este documento utilizan estas versiones de software y hardware:
-
Versión 12.1(4) del software Cisco IOS
-
IPM 2.5 para Windows NT
-
Catalyst 4500 Series Switch
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Problemas de QoS en una red VoIP
Varios factores pueden degradar la calidad de voz en una red de voz empaquetada:
-
Pérdida del paquete
-
Retraso excesivo
-
Fluctuación excesiva
Es especialmente importante que supervise estas cifras de forma continua, si se utilizan servicios de conmutación de paquetes en la WAN (por ejemplo, ATM, Frame Relay o IP Virtual Private Network). Hay numerosos escenarios donde la congestión en la red de la portadora, el modelado de tráfico mal configurado en los dispositivos de borde o la regulación mal configurada en el lado de la portadora pueden causar pérdida de paquetes o almacenamiento en búfer excesivo. Cuando la portadora está descartando paquetes, no hay evidencia obvia en los dispositivos de borde. Por lo tanto, necesita una herramienta de extremo a extremo como Cisco SAA que pueda inyectar tráfico en el ingreso y validar su correcta llegada al egreso.
Administración de QoS con Cisco SAA e IPM
Hay tres componentes de Cisco SAA e IPM:
-
sonda RTR
-
respondedor RTR
-
Consola IPM
El sondeo de RTR envía una ráfaga de paquetes al receptor de RTR. El respondedor RTR les da la vuelta y las devuelve para que sean sondeadas. Esta simple operación permite a la sonda medir la pérdida de paquetes y el retraso del viaje de ida y vuelta. Para medir la fluctuación, la sonda envía un paquete de control al respondedor antes de iniciar la ráfaga de paquetes. El paquete de control informa al respondedor cuántos milisegundos (ms) esperar entre cada paquete en la ráfaga. El respondedor mide el retraso entre paquetes durante la ráfaga y cualquier desvío del intervalo esperado se graba como fluctuación.
La consola IPM controla la supervisión de calidad de servicio (QoS). Programas las sondas RTR con la información relevante a través del protocolo simple de administración de red (SNMP). También recoge los resultados vía SNMP. No se requiere ninguna interfaz de línea de comandos de configuración de Cisco IOS en las sondas RTR.
Ejecute el comando de configuración global rtr responder para configurar manualmente los respondedores RTR.
Las sondas y los respondedores RTR deben ejecutar Cisco IOS Software Release 12.0(5)T o posterior. Se recomienda la última versión estándar de mantenimiento 12.1. Las sondas y los respondedores RTR en los ejemplos de este documento están ejecutando la versión 12.1(4). La versión IPM en uso es IPM 2.5 para Windows NT. Hay un parche disponible en Cisco.com para esta versión. Este parche es importante, ya que soluciona un problema en el que IPM configura las sondas RTR con una configuración de precedencia IP incorrecta.
Diseño
Antes de implementar una solución Cisco SAA e IPM, debe realizar algunos trabajos de diseño teniendo en cuenta estas consideraciones:
-
Colocación de las sondas y de los respondedores RTR
-
Tipo de tráfico enviado desde la sonda al respondedor
Hay una serie de cosas que debe tener en cuenta al decidir la colocación de sondas y respondedores. En primer lugar, necesita que la medición QoS cubra cada sitio no sólo los sitios con problemas. Esto se debe a que los números de retraso y fluctuación que IPM informa para un sitio determinado son más útiles cuando se los compara con otros sitios en la misma red. Por lo tanto, desea medir los sitios con buena QoS y calidad de servicio deficiente. Además, un sitio de buen rendimiento puede convertirse mañana en un sitio de bajo rendimiento debido a cambios en los patrones de tráfico o cambios en la red. Deberá detectar esto antes de que afecte a la calidad de voz y los usuarios informen al respecto.
En segundo lugar, el uso de la CPU es importante. Es posible que un router que ya está ocupado no pueda atender el componente RTR de manera oportuna, y esto puede sesgar los resultados. Además, si coloca demasiadas instancias de sonda en un solo router, puede crear problemas de uso elevado de la CPU aunque antes no existiera ninguno. El enfoque elegido para la red de ejemplo en este documento (y esto debería funcionar en la mayoría de las redes) es colocar las sondas RTR en los routers remotos/de sucursales. Estos routers típicamente conectan un solo LAN a un servicio del WAN relativamente lento. Por lo tanto, los routers de rama a menudo utilizan muy poco la CPU y se adaptan fácilmente a RTR. La otra ventaja de este diseño es que distribuye la carga entre tantos routers como sea posible. Tenga en cuenta que es más trabajo ser una sonda que responder, ya que las sondas toman una cierta cantidad de sondeo SNMP.
Con este diseño, los respondedores RTR deben ubicarse en el núcleo. Los respondedores estarán más ocupados que las sondas, porque responderán a muchas sondas. Por lo tanto, un diseño robusto implementa routers dedicados que actúan únicamente como respondedores. La mayoría de las organizaciones tienen routers retirados en el estante que pueden realizar esta función. Cualquier router con una interfaz Ethernet será suficiente. Alternativamente, los routers de núcleo/distribución pueden duplicarse como respondedores. El diagrama de red de esta sección muestra ambos escenarios.
Extienda la carga a través de tantos routers como sea posible, y monitoree el uso de la CPU RTR con este comando:
Router# show processes cpu | i Rtt|PID PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process 67 0 7 0 0.00% 0.00% 0.00% 0 Rtt Responder

Cuando está haciendo coincidir sondas con respondedores, se recomienda mantener una topología uniforme entre sonda y respondedor. Por ejemplo, todos los sondeos y los receptores deben estar separados por la misma cantidad de routers, switches y links WAN. Sólo entonces se pueden comparar los resultados de IPM directamente entre los sitios.
En este ejemplo, hay 200 sitios remotos y cuatro sitios de núcleo/distribución. Un Catalyst 4500 en cada sitio de distribución actúa como respondedor RTR dedicado. Cada uno de los 200 routers remotos actúa como sonda RTR. Cada sonda se dirige al respondedor que se encuentra en el sitio de distribución conectado directamente.
La red debe asignar a las ráfagas de tráfico enviadas por las sondas a los respondedores los mismos niveles de QoS que proporciona a la voz. Esto puede significar que debe ajustar las configuraciones de prioridad de almacenamiento en cola de baja latencia (LLQ) o protocolo de tabla de routing (RTP) en el router, de modo que el tráfico de las sondas RTR esté sujeto a colas de prioridad estricta. Cuando configura la sonda para los paquetes RTP, sólo se puede controlar el puerto de destino del protocolo de datagramas de usuario (UDP) y no el puerto de origen. Una configuración típica del router LLQ en este ejemplo de red tiene listas de acceso que clasifican específicamente los paquetes RTR en la misma cola que la voz:
class-map VoiceRTP
match access-group name IP-RTP
policy-map 192Kbps_site
class VoiceRTP
priority 110
ip access-list extended IP-RTP
deny ip any any fragments
permit udp 10.0.16.0 0.255.239.255
range 16384 32768 10.0.16.0 0.255.239.255
range 16384 32768 precedence critical
permit udp any any eq 20000 precedence critical
permit udp any eq 20000 any precedence critical
La lista de acceso IP-RTP tiene estas líneas de clasificación:
-
deny ip any any fragments
Denegar cualquier fragmento de IP, como una lista de acceso de capa 4 implícitamente lo permite.
-
permit udp 10.0.16.0 0.255.239.255 range 16384 32768 10.0.16.0 0.255.239.255 range 16384 3276 8 críticas de precedencia
Paquetes con licencia RTP de los subnets de la voz con la prioridad IP fijada a 5.
-
permit udp any any eq 20000 precedence Critical
Paquetes con licencia RTP de la sonda RTR que va al respondedor RTR.
-
permit udp any eq 20000 any precedence Critical
Paquetes con licencia RTP del respondedor RTR que va de regreso a la sonda RTR.
Tenga cuidado de que la adición del tráfico RTR no haga que las colas LLQ se sobresuscriban y haga que se descarten los paquetes de voz reales. La operación IPM Default60ByteVoice estándar envía ráfagas de paquetes RTP con estos parámetros:
-
Carga útil de la solicitud: 60 bytes
Nota: Éste es el encabezado RTP y la voz. Agregue 28 bytes (IP/UDP) para obtener el tamaño del datagrama L3.
-
Intervalo: 20 ms
-
Número de paquetes: 10
Esto significa que, durante una ráfaga, el RTR consume 35,2 Kbs de ancho de banda LLQ. Si el ancho de banda no es suficiente para LLQ, cree una nueva operación IPM e incremente el intervalo del paquete. Con los parámetros mostrados en esta ventana de configuración de IPM, una ráfaga consume sólo 1 Kbps de ancho de banda:

Resultados
La tabla de esta sección es un ejemplo de un informe IPM. Este informe contiene tres instancias de sonda RTR. Tenga en cuenta que una sonda física se puede configurar con varias instancias de sonda RTR que tienen como objetivo diferentes respondedores o utilizan diferentes cargas útiles.
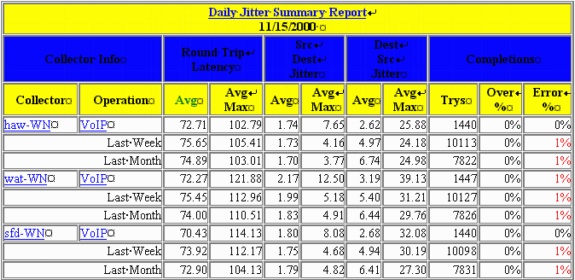
Estos son los significados de cada una de las columnas:
Promedio:
IPM calcula un promedio para cada hora de muestreo. Estos promedios horarios luego son promediados en un período más largo para así obtener los promedios diario, semanal y mensual. En otras palabras, para el informe diario, IPM calcula el promedio de cada hora durante las últimas 24 horas. Luego calcula el promedio diario como el promedio de estos 24 promedios.
Máximo promedio:
Este valor es el promedio de todos los máximos por hora para cada día, semana y mes del gráfico. En otras palabras, para el informe diario, el IPM toma la muestra más grande comunicada en cada una de las últimas 24 horas. A continuación, calcula la media máxima diaria como la media de estas 24 muestras.
Más del %:
Este es el porcentaje de muestras que superaron el umbral configurado para el colector.
Error %:
Éste es el porcentaje de paquetes con errores. Una sonda de fluctuación informa varios tipos de errores:
-
Pérdida de paquetes SD: paquetes perdidos entre el origen y el destino
-
Pérdida de paquetes DS: paquetes perdidos entre el destino y el origen
-
Ocupaciones: el número de ocasiones en las que no se pudo iniciar una operación de tiempo de ida y vuelta (RTT) porque no se había completado una operación de RTT anterior.
-
Secuencia: el número de finalizaciones de la operación RTT recibidas con un identificador de secuencia inesperado. Estas son algunas de las posibles razones por las que esto podría ocurrir:
-
Se recibió un paquete duplicado.
-
Se recibió una respuesta luego que se agotó el tiempo de espera.
-
Se recibió un paquete dañado y no se detectó.
-
-
Drops (Caídas): el número de ocasiones en las que se produjo alguno de estos eventos:
-
No se pudo iniciar una operación de RTT porque no se disponía de algún recurso interno necesario (por ejemplo, memoria o subsistema de arquitectura de red de sistemas [SNA])
-
No se pudo reconocer la finalización de la operación.
-
-
MIA (Falta en acción): el número de paquetes perdidos para los que no se puede determinar ninguna dirección.
-
Tarde: el número de paquetes que llegaron después del tiempo de espera.
La pregunta que surge de esta información es qué valores de error, fluctuación y retraso son aceptables en una red VoIP. Lamentablemente, no hay una respuesta sencilla a esta pregunta. Los valores aceptables dependen del tipo de códec, del tamaño del búfer de fluctuación y de otros factores. Además, hay interdependencias entre estas variables. Una mayor pérdida de paquetes puede significar que se tolerará un menor nivel de fluctuación.
El mejor método para obtener cifras de retardo y fluctuación factibles es comparar sitios similares en la misma red. Si todos los sitios conectados a 192 Kbps pero uno informa de valores de fluctuación de alrededor de 50 ms y el sitio restante informa de fluctuación de 100 ms, entonces hay un problema, independientemente de los valores nominales. IPM puede proporcionar una medición continua de la demora y la fluctuación las 24 horas del día, los 7 días de la semana para toda la red, y puede proporcionar una línea de base para utilizarla como referencia para las comparaciones de la demora y la fluctuación.
Sin embargo, los errores son diferentes. En principio, cualquier porcentaje de error distinto de cero es un indicador rojo. A los paquetes RTR se les da el mismo tratamiento QoS que a los paquetes de voz. Si la red QoS y el control de la admisión de llamada es robusta, ningún nivel de congestión debería causar la pérdida de paquetes o un retardo excesivo para los paquetes de voz o RTR. Por lo tanto, puede esperar que el error IPM contará como cero. Los únicos errores que se pueden considerar "normales" son los errores de verificación por redundancia cíclica (CRC), pero éstos deberían ser poco frecuentes en una infraestructura de calidad. Si son frecuentes, constituyen un riesgo para la calidad de la voz.
Información Relacionada
- Bibliografía recomendada: Troubleshooting de Cisco IP Telephony

- Soporte Técnico y Documentación - Cisco Systems
 Comentarios
Comentarios