Introducción
Este documento describe Cisco Express Forwarding (CEF) switching y cómo se implementa en el router de Internet de la serie 12000 de Cisco.
Prerequisites
Requirements
No hay requisitos específicos para este documento.
Componentes Utilizados
Este documento no tiene restricciones específicas en cuanto a versiones de software y de hardware.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Convenciones
Para obtener más información sobre las convenciones del documento, consulte Convenciones de Consejos Técnicos de Cisco.
Overview
El switching de Cisco Express Forwarding (CEF) es una forma propietaria de switching escalable diseñada para abordar los problemas asociados con el almacenamiento en caché de la demanda. Con switching CEF, la información guardada de modo convencional en una memoria caché de ruta se divide en varias estructuras de datos. El código CEF es capaz de mantener estas estructuras de datos en el Procesador de ruta Gigabit (GRP), y también en procesadores secundarios como las tarjetas de línea en los routers 12000. Las estructuras de datos que proporcionan una búsqueda optimizada para un reenvío de paquetes eficiente incluyen:
-
La tabla de base de información de reenvío (FIB): CEF usa una FIB para tomar decisiones relativas a la conmutación basada en prefijos de destino IP. El FIB es conceptualmente similar a una tabla de ruteo o base de información. Mantiene una imagen réplica de la información de transmisión contenida en la tabla de IP Routing Cuando se producen modificaciones en el ruteo o la topología de la red, la tabla de IP Routing se actualiza y estos cambios son reflejados en el FIB. La FIB mantiene la información sobre la dirección next-hop teniendo en cuenta la información de la tabla de IP Routing. Dado que existe correlación “uno a uno” entre las entradas de la FIB (base de reenvío de información) y las entradas de la tabla de ruteo, la FIB comprende todos los trayectos conocidos y elimina la necesidad de mantenimiento de la memoria caché del router que está asociada con los trayectos de switching, tales como el fast switching y el optimum switching.
-
Tabla de adyacencia – Se dice que los nodos de la red son adyacentes si pueden alcanzarse entre sí con un solo salto en una capa de link. Además de la FIB, CEF utiliza tablas de adyacencia para anexar información de direccionamiento de Capa 2. La tabla de adyacencia mantiene las direcciones next-hop de la capa 2 para todas las entradas de FIB.
CEF puede habilitarse en uno de los siguientes modos:
-
Modo central CEF – Cuando el modo CEF está habilitado, la FIB de CEF y las tablas adyacentes residen en el procesador de rutas y éste ejecuta el reenvío expreso. Puede utilizar el modo CEF cuando las tarjetas de línea no están disponibles para switching de CEF o cuando necesita utilizar características no compatibles con switching distribuido de CEF.
-
Modo CEF (dCEF) distribuido - Cuando dCEF está habilitado, las tarjetas de línea mantienen copias idénticas de las tablas de adyacencia y del FIB. Las tarjetas de línea pueden realizar el reenvío rápido por sí mismas, y esto libera al procesador principal -Gigabit Route Processor (GRP)- de la implicación en la operación de conmutación. Este es el único método de conmutación disponible en el router de la serie 12000 de Cisco.
dCEF utiliza un mecanismo de comunicación interprocesos (IPC) para garantizar la sincronización de FIB y las tablas de adyacencia en el procesador de rutas y las tarjetas de línea.
Para más información acerca de la conmutación de CEF, consulte el informe oficial Cisco Express Forwarding (CEF).
Operaciones de CEF
Actualización de las Tablas de Ruteo de GRPs
La Figura 1 ilustra el proceso por el cual un paquete de actualización de ruteo se envía al Procesador de ruta Gigabit (GRP) y los mensajes de actualización de reenvío resultantes se envían a las tablas FIB en las tarjetas de línea.
Para mayor claridad, la numeración de los párrafos siguientes corresponde a la de la figura 1.
El siguiente proceso ocurre durante la inicialización de la tabla de rutas o en cualquier momento en que cambia la topología de la red (cuando se agregan, eliminan o cambian las rutas). El proceso que se muestra en la Figura 1 incluye cinco pasos principales:
-
Se coloca un datagrama IP en los búfers de entrada de las tarjetas de línea receptoras (ingresar tarjeta de línea) y el motor de reenvío L2/L3 accede a la información de la Capa 2 y Capa 3 en el paquete y la envía al procesador de reenvío. El procesador de reenvío determina que el paquete contiene información de ruteo. El procesador de reenvío envía el puntero a la cola de salida virtual (VOQ) de GRP e indica que el paquete en la memoria intermedia debe enviarse al GRP.
-
La tarjeta de línea envía un pedido a las Tarjetas de reloj y programación (CSC). La tarjeta del planificador emite una concesión y el paquete se envía a través del entramado de conmutación al GRP.
-
El GRP procesa la información de ruteo. El R5000 (procesador) en el GRP actualiza la tabla de ruteo de la red. Dependiendo de la información de ruteo en el paquete, el procesador de Capa 3 puede tener que inundar la información de estado de link a los routers adyacentes (si el protocolo de ruteo interno es Open Shortest Path First [OSPF]). El procesador genera los paquetes IP que llevan la información del estado del link y la actualización interna para las tablas FIB. Además, el GRP calcula todas las rutas recursivas que se producen cuando se proporciona soporte para un protocolo interior y protocolos de gateway externos (por ejemplo, el protocolo de gateway fronterizo [BGP]).
La información de ruta recursiva calculada se envía a los FIB en cada tarjeta de línea. Esto acelera significativamente el proceso de reenvío, porque el procesador de capa 3 en la tarjeta de línea puede centrarse en reenviar el paquete y no calcula la ruta recursiva.
-
El GRP envía actualizaciones internas a las tablas FIB en todas las tarjetas de línea e incluye las ubicadas en el GRP. Las actualizaciones FIB a las tarjetas de línea se monitorean y necesitan aceleradores. El GRP tiene una copia de cada tabla FIB de tarjeta de línea, por lo que si se inserta una nueva tarjeta de línea en el chasis, el GRP descarga la información de reenvío más reciente a la nueva tarjeta una vez que la tarjeta se activa.
-
Cada vez que un router vecino nuevo se conecta al router 12000, las tarjetas de línea notifican al GRP. El procesador de la tarjeta de línea envía un paquete al GRP que contiene la nueva información de capa 2 (normalmente información de encabezado del protocolo punto a punto (PPP)). GRP utiliza esta información de capa 2 para actualizar la tabla de adyacencia ubicada en el GRP y en las tarjetas de línea. Cada tarjeta de línea agrega esta información de la capa 2 a cada paquete a medida que éstos son enviados desde el router 12000. Se mantiene una copia de la tabla de adyacencia en el GRP para realizar inicializaciones.
Figura 1: Diagrama de Switching de Capa 3 y Determinación de Trayectoria
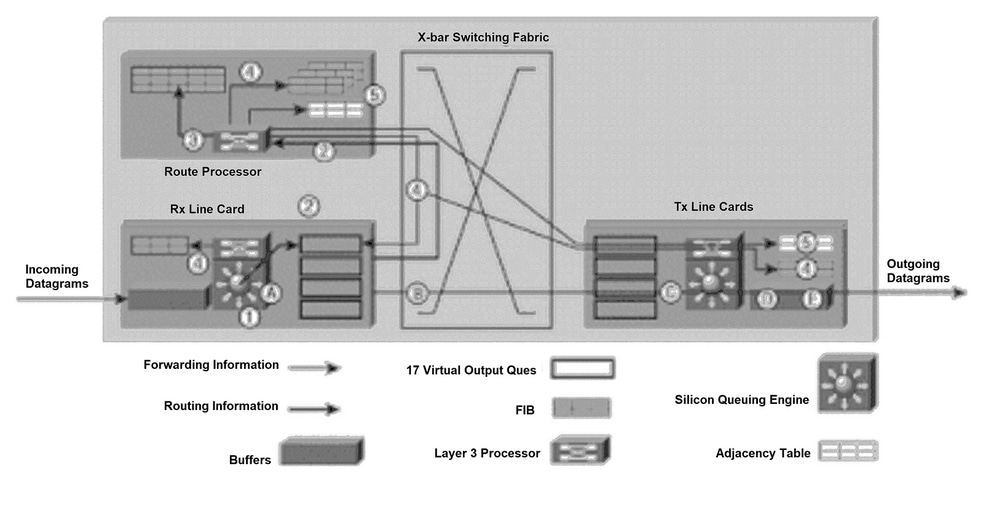 Diagrama de Switching de Capa 3 y Determinación de Trayectos
Diagrama de Switching de Capa 3 y Determinación de Trayectos
Reenvío de paquetes para todas las tarjetas de línea excepto OC48 y QOC12
Una vez que las tarjetas de línea tengan suficiente información de reenvío para determinar el trayecto a través de los recursos físicos de conmutación (por ejemplo, el destino del siguiente salto), el router 12000 estará listo para el reenvío de paquetes. Los siguientes pasos describen la técnica de reenvío simple y rápido utilizada por el router 12000 (consulte la Figura 1). Para una mayor claridad, las letras de los párrafos corresponden a aquéllas de la Figura 1.
-
R. Se coloca un datagrama IP en los búferes de entrada de la tarjeta de línea receptora (tarjeta de línea Rx), y el motor de reenvío L2/L3 accede a la información de Capa 2 y Capa 3 en el paquete y la envía al procesador de reenvío. El procesador de reenvío determina que el paquete incluye datos y que no se trata de una actualización de ruteo. Según la información de Capa 2 y Capa 3 en la tabla FIB, el procesador de reenvío envía el puntero a la VOQ de la tarjeta de línea apropiada que indica que el paquete en la memoria del búfer debe enviarse a esa tarjeta de línea.
-
B.El planificador de la tarjeta de línea emite una solicitud al planificador. El programador emite un permiso y el paquete se envía desde la memoria intermedia a través del entramado de switches hasta la tarjeta de línea (tarjeta de línea Tx).
-
C.La tarjeta de línea Tx almacena en el búfer los paquetes entrantes.
-
D. El procesador de Capa 3 y los circuitos integrados específicos de la aplicación (ASIC) asociados en la tarjeta de línea Tx adjuntan la información de Capa 2 (una dirección PPP) a cada paquete transmitido. El paquete se duplica para cada puerto en la tarjeta de línea (si es necesario)
-
E.Los transmisores de tarjeta de línea Tx envían el paquete a través de la interfaz de fibra.
La ventaja de este sencillo proceso de reenvío es que la mayoría de las tareas de transmisión de datos se pueden realizar en ASIC y permite que 12000 funcione a velocidades de gigabit. Además, los paquetes de datos nunca se envían al GRP.
Reenvío de paquetes para tarjetas de línea OC48 y QOC12
Cuando las tarjetas de línea tengan suficiente información de reenvío para determinar el trayecto a través de los recursos físicos de conmutación (por ejemplo, el destino del siguiente salto), el router 12000 estará listo para el reenvío de paquetes. Los siguientes pasos conforman la técnica de reenvío simple e hiperrápido utilizada por 12000 (consulte la Figura 2). Para una mayor claridad, las letras de los párrafos corresponden a aquéllas de la Figura 2.
-
R. Se recibe un datagrama IP (no una actualización de ruteo, protocolo de mensajes de control de Internet (ICMP) y paquetes IP con opciones) en la tarjeta de línea y pasa por el procesamiento de capa 2. De acuerdo con la información de la capa 2 y de la capa 3 en la tabla de FIB local, el procesador del paquete rápido determina el destino del paquete y modifica el encabezado de paquete. En función del destino, el paquete se coloca en la VOQ de la tarjeta de línea apropiada.
-
B. En el raro caso de que el procesador de paquetes rápidos no pueda reenviar correctamente el paquete, el procesador de reenvío procesa el paquete. El procesador de reenvío, basado en la información de la capa 2 y la capa 3 de su tabla FIB local, envía el puntero a la VOQ de la tarjeta de línea apropiada, que indica que el paquete en la memoria del búfer debe enviarse a esa tarjeta de línea.
-
C. Una vez que el paquete está en el VOQ apropiado, el planificador de la tarjeta de línea emite una solicitud al planificador. El programador emite un permiso y el paquete se envía desde la memoria intermedia a través del entramado de switches hasta la tarjeta de línea (tarjeta de línea Tx).
-
D. La tarjeta de línea Tx almacena en el búfer los paquetes entrantes.
-
E. El procesador de Capa 3 y los ASIC asociados en la tarjeta de línea Tx adjuntan la información de Capa 2 (una dirección PPP) a cada paquete transmitido. El paquete se duplica para cada puerto en la tarjeta de línea (si es necesario)
-
F. Los transmisores de tarjeta de línea Tx envían el paquete a través de la interfaz de fibra.
La ventaja del nuevo proceso de reenvío es que optimiza la tarjeta específicamente para velocidades superiores, como el OC48/STM16.
Figura 2: Conmutación de paquetes para tarjetas de línea más rápidas
 Switching de Paquetes para Tarjetas de Línea Rápidas
Switching de Paquetes para Tarjetas de Línea Rápidas
Información Relacionada
 Comentarios
Comentarios