Solución de problemas de CPU alta en el router serie ASR1000
Opciones de descarga
-
ePub (422.9 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (289.7 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe cómo resolver problemas de CPU altos en un router de la serie ASR1000.
Requisito previo
Requirements
Cisco recomienda que entienda la arquitectura ASR1000 para interpretar y utilizar este documento.
Descripción
La CPU alta en un router Cisco puede definirse como la condición en la que el uso de la CPU en el router está por encima del uso normal. En algunos escenarios se espera un mayor uso de la CPU, mientras que en otros podría indicar un problema. Se puede ignorar el alto uso de la CPU transitoria en el router debido al cambio de la red o al cambio de configuración, y se espera un comportamiento.
Sin embargo, un router que experimenta una alta utilización de la CPU durante periodos prolongados sin ningún cambio en la red o la configuración es inusual y necesita ser analizado. Por lo tanto, cuando se utiliza en exceso, la CPU no puede prestar servicio activo a todos los demás procesos, lo que da como resultado una línea de comandos lenta, latencia del plano de control, caídas de paquetes y la falla de los servicios.
Las causas del uso excesivo de CPU son:
- La CPU del plano de control recibe demasiado tráfico puntual
- Un proceso que se comporta de forma inesperada y da lugar a una utilización excesiva de la CPU
- El procesador del plano de datos está sobreutilizado/sobresuscrito
- Demasiadas interrupciones del procesador
El uso elevado de la CPU no siempre es un problema del router serie ASR1000, ya que el uso de la CPU del router es directamente proporcional a la carga en el router. Por ejemplo, si se produce un cambio en la red, esto provocará una gran cantidad de tráfico del plano de control a medida que la red vuelva a converger. Por lo tanto, necesitamos determinar la causa raíz de la utilización excesiva de la CPU para determinar si se espera un comportamiento o un problema.
A continuación se muestra un diagrama que detalla un proceso paso a paso sobre cómo resolver un problema de CPU alta:
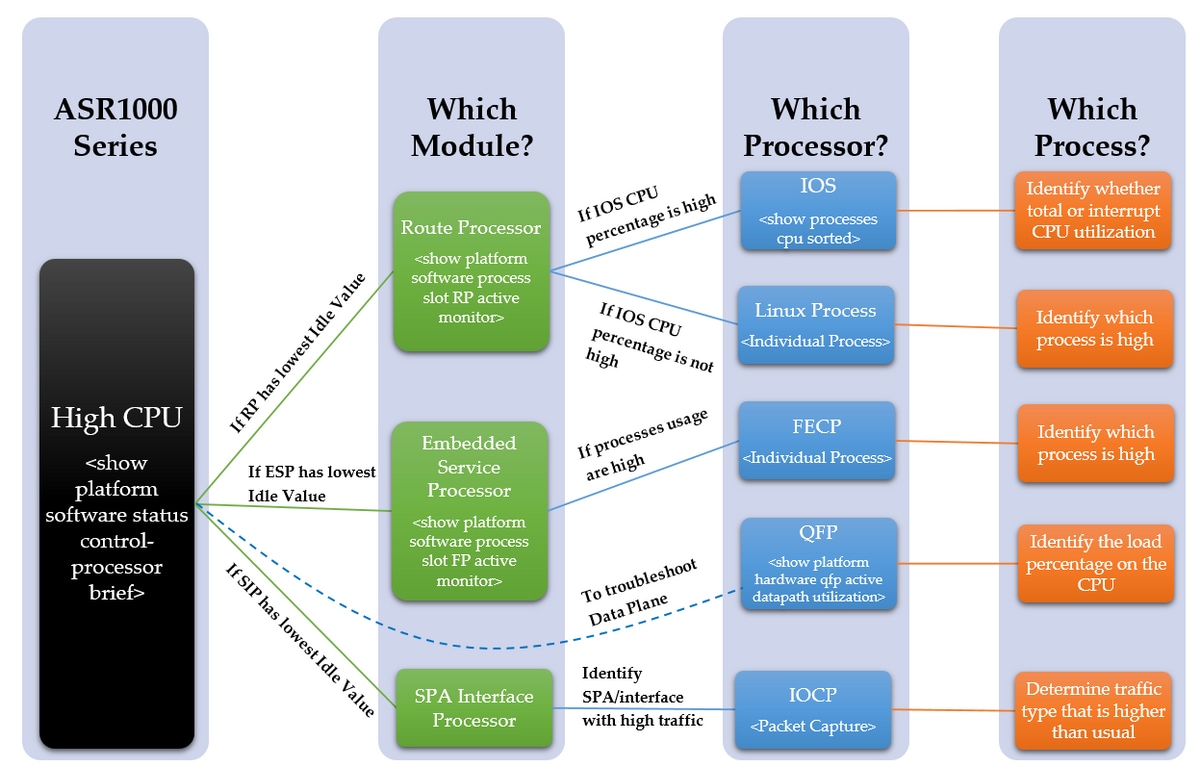
Solución de problemas de pasos
Paso 1: Identifique el módulo con CPU alta
ASR 1000 tiene varias CPU diferentes en los diferentes módulos. Por lo tanto, necesitamos ver qué módulo muestra un uso mayor de lo normal. Esto se puede ver a través del valor Inactivo, como cuanto menor es el valor inactivo, mayor es la utilización de la CPU de ese módulo. Todas estas CPU diferentes reflejan el plano de control de los módulos.
Determine qué módulo dentro del dispositivo se observa que experimenta un uso elevado de la CPU. ¿Se trata del RP, ESP o SIP con el siguiente comando?
show platform software status control-processor brief
Consulte la siguiente salida para ver la columna resaltada
Si el RP tiene un valor bajo de inactividad, continúe con el Paso 2 Punto 1
Si el ESP tiene un valor de inactividad bajo, vaya al paso 3, punto 2
Si el SIP tiene un valor de inactividad bajo, continúe con el paso 4, punto 3
Router#show platform software status control-processor brief
Promedio de carga
Estado de ranura 1-min 5-min 15-min
RP0 Sano 0.00 0.02 0.00
ESP0 Sano 0.01 0.02 0.00
SIP0 Sano 0.00 0.01 0.00
Memoria (kB)
Estado De Ranura Total Utilizado (Pct) Libre (Pct) Comprometido (Pct)
RP0 Sano 2009376 1879196 (94%) 130180 ( 6%) 1432748 (71%)
ESP0 Sano 2009400 692100 (34%) 1317300 (66%) 472536 (24%)
SIP0 Sano 471804 284424 (60%) 187380 (40%) 193148 (41%)
Utilización de la CPU
Slot CPU User System Nice IRQ SIRQ IOwait inactivo
RP0 0 2.59 2.49 0.00 94.80 0.00 0.09 0.00
ESP0 0 2.30 17.90 0.00 79.80 0.00 0.00 0.00
SIP0 0 1.29 4.19 0.00 94.41 0.09 0.00 0.00
Si todos los valores inactivos son relativamente altos, es posible que no sea un problema del plano de control. Para resolver problemas del plano de datos, es necesario observar el QFP del ESP. Todavía se pueden observar síntomas de "CPU alta" debido a un QFP excesivamente utilizado, que no dará como resultado un uso excesivo de la CPU en los procesadores del plano de control. Proceda al Paso 6.
Paso 2 - Análisis del módulo
- Procesador de ruteo
Confirme dentro del RP qué procesador se observa que tiene un uso elevado de la CPU con el siguiente comando. ¿Es el proceso Linux o el IOS?
show platform software process slot RP active monitor
Si el porcentaje de CPU del IOS es alto (linux_iosd-imag), entonces es el IOS del RP. Proceda al Paso 3
Si el porcentaje de CPU de otros procesos es alto, entonces es probable que sea el Proceso Linux. Proceda al Paso 4
- Procesador de servicios integrados
Confirme dentro del ESP si se observa que el procesador del plano de control tiene un uso elevado de la CPU. ¿Es el FECP?
show platform software process slot FP active monitor
Si los procesos son altos, entonces es el FECP, continúe con el PASO 5
Si no es el FECP, no es un problema relacionado con los procesos del plano de control dentro del ESP. Si todavía se observan síntomas como la latencia de la red o las caídas de la cola, es posible que sea necesario revisar el plano de datos para detectar la utilización excesiva. Proceda al Paso 6
- Procesador de interfaz SPA
Si se observa que el SIP tiene una alta utilización de la CPU, se observará que el IOCP tiene una CPU alta. Determine qué procesos o procesos dentro del IOCP se observan que tienen un uso elevado de la CPU.
Realice una captura de paquetes e identifique qué tráfico es mayor de lo habitual y qué procesos están asociados con este tipo de tráfico. Proceda al Paso 7
Paso 3 - Procesos IOS
Consulte la siguiente salida, el primer porcentaje es la utilización total de la CPU y el segundo porcentaje es la utilización de la CPU de interrupción, que es la cantidad de CPU utilizada para procesar los paquetes perforados.
Si el porcentaje de interrupción es alto, significa que una gran cantidad de tráfico se impulsa al RP, (esto puede confirmarse con el comando show platform software infrastructure punt)
Si el porcentaje de interrupción es bajo, pero la CPU total es alta, entonces hay un proceso o procesos que se observarán para utilizar la CPU durante un período prolongado.
Confirme dentro del IOS qué procesos o procesos se observan que tienen un uso elevado de la CPU con el siguiente comando.
show processes cpu
Identifique qué porcentaje es alto (CPU total o CPU de interrupción) y, si es necesario, identifique el proceso o los procesos individuales. Proceda al Paso 7
Router#show processes cpu clasificado
Utilización de la CPU durante cinco segundos: 0% / 0%; un minuto: 1%; cinco minutos: 1%
Tiempo de ejecución de PID(ms) activado uSecs 5Sec 1 Min 5 Min TTY Proceso
Tiempo de ejecución de PID(ms) activado uSecs 5Sec 1 Min 5 Min TTY Proceso
188 8143 434758 18 0,15% 0,18% 0,19% 0 Ethernet Msec Ti
515 380 7050 53 0,07% 0,00% 0,00% 0 proceso principal SBC
3 2154 215 10018 0,07% 0,00% 0,19% 0 Exec
380 1783 55002 32 0,07% 0,06% 0,06% 0 MMA DB TIMER
63 3132 11143 281 0,07% 0,07% 0,07% 0 IOSD tareas ipc
5 1 2 500 0,00% 0,00% 0,00% 0 envío ISSU IPC
6 19 12 1583 0.00% 0.00% 0.00% 0 RF Esclavo Principal
8 0 1 0 0,00% 0,00% 0,00% 0 RO Notificar temporizadores
7 0 1 0 0,00% 0,00% 0,00% 0 EDDRI_MAIN
10 6 75 80 0,00% 0,00% 0,00% 0 Pool Manager
9 5671 538 10540 0,00% 0,14% 0,12% 0 Hojas de comprobación
Paso 4 - Procesos Linux
Si se observa que el IOS ha sobreutilizado la CPU, entonces necesitamos observar la utilización de la CPU para el proceso linux individual. Estos procesos son los otros procesos enumerados del show platform software process slot RP active monitor. Identifique qué procesos o procesos se observan para experimentar un uso elevado de la CPU y, a continuación, vaya al PASO 7.
Paso 5 - Procesos FECP
Si un proceso o procesos son altos, es probable que esos sean los procesos dentro del FECP responsables de la alta utilización de la CPU, continúe con el PASO 7
Paso 6 - Utilización de QFP
El procesador de flujo cuántico es el ASIC de reenvío. Para determinar la carga en el motor de reenvío, se puede monitorear el QFP. El siguiente comando enumera los paquetes de entrada y salida (prioridad y no prioridad) en los paquetes por segundo y los bits por segundo. La línea final muestra la cantidad total de carga de CPU debido al reenvío de paquetes en un porcentaje.
show platform hardware qfp active datapath usage
Identifique si la entrada o la salida son altas y vea la carga del proceso y después continúe con el PASO 7
Router#show platform hardware qfp active datapath usage
CPP 0: Subdev 0 5 segundos 1 min 5 min 60 min
Entrada: Prioridad (pps) 0 0 0
(bps) 208 176 176 176
No prioritaria (pps) 0 2 2 2
(bps) 64 784 784 784
Total (pps) 0 2 2 2
(bps) 272 960 960 960
Salida: Prioridad (pps) 0 0 0
(bps) 192 160 160 160
No prioritaria (pps) 0 1 1 1
(bps) 0 6488 6496 6488
Total (pps) 0 1 1 1
(bps) 192 6648 6656 6648
Procesando: Cargar (pct) 0 0 0 0
Paso 7 - Determine la causa raíz e identifique la corrección
Con el proceso o los procesos que se observa que han sobreutilizado la CPU identificados, existe una imagen más clara de por qué se ha producido un uso excesivo de la CPU. Para continuar, investigue las funciones realizadas por el proceso identificado. Esto ayudará a determinar un plan de acción sobre cómo abordar el problema. Por ejemplo: si el proceso es responsable de un protocolo determinado, puede que desee ver la configuración relacionada con este protocolo.
Si todavía experimenta problemas relacionados con la CPU, se recomienda ponerse en contacto con el TAC para que un ingeniero le ayude a resolver problemas adicionales. Los pasos anteriores para la resolución de problemas ayudarán al ingeniero a aislar el problema de manera más eficiente.
Ejemplo de Troubleshooting
En este ejemplo, ejecutaremos el proceso para resolver problemas e intentaremos identificar mejor una causa raíz posible para la alta CPU del router. Para comenzar, determinar qué módulo se observa para experimentar la CPU alta, tenemos el siguiente resultado:
Router#show platform software status control-processor brief
Promedio de carga
Estado de ranura 1-min 5-min 15-min
RP0 Sano 0.66 0.15 0.05
ESP0 Sano 0.00 0.00 0.00
SIP0 Sano 0.00 0.00 0.00
Memoria (kB)
Estado De Ranura Total Utilizado (Pct) Libre (Pct) Comprometido (Pct)
RP0 Sano 2009376 1879196 (94%) 130180 ( 6%) 1432756 (71%)
ESP0 Sano 2009400 692472 (34%) 1316928 (66%) 472668 (24%)
SIP0 Sano 471804 284556 (60%) 187248 (40%) 193148 (41%)
Utilización de la CPU
Slot CPU User System Nice Idle IRQ SIRQ IOwait
RP0 0 57.11 14.42 0.00 0.00 28.25 0.19 0.00
ESP0 0 2.10 17.91 0.00 79.97 0.00 0.00 0.00
SIP0 0 1.20 6.00 0.00 92.80 0.00 0.00 0.00
Como la cantidad de inactividad dentro del RP0 es muy baja, sugiere un problema de CPU alto dentro del Procesador de ruta. Por lo tanto, para resolver problemas adicionales, identificaremos qué procesador dentro del RP se observa que experimenta una alta CPU.
Router#show processes cpu clasificado
Utilización de la CPU durante cinco segundos: 84% / 36%; un minuto: 34%; cinco minutos: 9%
Tiempo de ejecución de PID(ms) activado uSecs 5Sec 1 Min 5 Min TTY Proceso
107 303230 50749 5975 46,69% 18,12% 4,45% 0 IOSXE-RP Punt Se
63 105617 540091 195 0,23% 0,10% 0,08% 0 tarea IPC IOSD
159 74792 2645991 28 0,15% 0,06% 0,06% 0 VRRS Hilo principal
116 53685 169683 316 0,15% 0,05% 0,01% 0 por segundo
9 305547 26511 11525 0,15% 0,28% 0,16% 0 Hojas de comprobación
188 362507 20979154 17 0,15% 0,15% 0,19% 0 Ethernet Msec Ti
3 147 186 790 0,07% 0,08% 0,02% 0 Exec
2 32126 33935 946 0,07% 0,03% 0,00% 0,00% 0 Meter de carga
446 416 33932 12 0,07% 0,00% 0,00% 0 proceso VDC
164 59945 5261819 11 0,07% 0,04% 0,02% 0 IP ARP Retry Age
43 1703 16969 100 0,07% 0,00% 0,00% 0 IPC Mantener activo M
A partir de esta salida, se puede observar que el porcentaje total de CPU y el porcentaje de interrupción son superiores a lo esperado. El proceso superior que utiliza la CPU es el "IOSXE-RP Punt Se", que es el proceso que maneja el tráfico para la CPU RP, por lo tanto podemos mirar más allá en este tráfico que se impulsa al RP.
Router#show platform software infrastructure punt
Estadísticas internas de la interfaz LSMPI:
enabled=0, disabled=0, throttled=0, unthrottled=0, el estado está listo
Búfers de entrada = 90100722
Búfers de salida = 100439
recuento de rxdone = 90100722
recuento de txdone = 100436
Rx sin recuento de partículas = 0
Tx no particletype count = 0
Txbuf desde el recuento de sombras = 0
No hay inicio del paquete = 0
Sin fin del paquete = 0
Punt drop stats:
Versión errónea 0
Tipo 0 incorrecto
Tenía encabezado de función 0
Tenía encabezado de plataforma 0
Falta 0 en el encabezado de la función
Discordancia de encabezado común 0
Longitud total incorrecta 0
Longitud del paquete errónea 0
Desplazamiento de red incorrecto 0
Encabezado no punt 0
Tipo de enlace desconocido 0
No swidb 1
Encabezado de la función ESS 0 incorrecto
Sin función ESS 0
No hay función SSLVPN 0
Punt. para nosotros tipo desconocido 0
Puntar causa fuera del intervalo 0
El paquete IOSXE-RP Punt causa:
62 210226 paquetes heredados y control de capa 2
147 paquetes de solicitud o respuesta ARP
27801234 Paquetes de datos para ee.uu.
Paquetes keepalive 84426 RP<->QFP
6 paquetes de adyacencia Glean
1647 Paquetes de control For-us
FOR_US Control IPv4 Protocol stats:
1647 paquetes OSPF
Histograma del paquete (500 bytes/bin), tamaño promedio en 92, salida 56:
Recuento de salida en tamaño de paquete
0+: 90097805 98790
+ de 500: 0 7
A partir de esta salida, podemos ver que hay una gran cantidad de paquetes en los "paquetes de datos para us" que indican el tráfico dirigido hacia el router, se confirmó que este contador se incrementó desde la observación del comando varias veces en varios minutos. Esto confirma que la CPU está excesivamente utilizada por una gran cantidad de tráfico puntuado, que a menudo es tráfico del plano de control. El tráfico del plano de control puede incluir ARP, SSH, SNMP, actualizaciones de ruta (BGP, EIGRP, OSPF), etc. A partir de esta información, podemos identificar la causa potencial de la CPU elevada y esto ayuda a resolver problemas para la causa raíz. Por ejemplo, se podría implementar una captura de paquetes o un monitor de tráfico diferente para ver el tráfico exacto dirigido al RP que permitiría identificar y resolver la causa raíz para evitar un problema similar en el futuro.
Una vez que se completa una captura de paquetes, algunos ejemplos de tráfico punteado potencial son:
- ARP: Esto podría deberse a un número excesivo de solicitudes ARP, que ocurriría si varias direcciones IP enviaran solicitudes ARP a través de la configuración de una ruta IP a una interfaz de broadcast. Esto también podría deberse a las entradas vaciadas de la tabla ARP y tendrá que volver a aprenderse en función de las entradas de dirección MAC que se desactualizan o de las interfaces de entrada y salida.
- SSH: Esto podría causar un uso excesivo de la CPU debido a un comando show de gran tamaño (show tech-support) o cuando se habilitan muchos comandos debug, lo que obliga a que se envíe una gran cantidad de CLI a través de la sesión SSH.
- SNMP (Protocolo de administración de red simple): Esto podría deberse al agente SNMP que tarda mucho tiempo en procesar una solicitud y, por lo tanto, provoca el uso excesivo de la CPU. A menudo, dos causas probables son las MIB que se sondean, o las tablas de ruta y/o ARP que son sondeadas por el NMS.
- Actualizaciones de ruta: A menudo, una afluencia de actualizaciones de ruta se debe a una reconvergencia de la red o a inestabilidades de link. Esto podría indicar rutas que se inhabilitan dentro de la red, o dispositivos enteros que se inundan, lo que obliga a la red a converger y a recalcular las mejores rutas, lo que depende del protocolo de ruteo que se utilice.
Esto resalta cómo la causa raíz se puede aislar mediante la identificación de la causa de la CPU alta, cuando se reduce a un nivel de proceso individual. Desde aquí, el proceso o protocolo individual se puede analizar de forma aislada para identificar si se trata de un problema de configuración, un problema de software, un diseño de red o una práctica prevista.
Comandos adicionales
A continuación se muestra una lista de otros comandos útiles adicionales que se utilizan y se ordenan por qué procesador se relacionan con:
Procesador de ruteo
- <show process cpu history>
- Proporciona un gráfico del historial de la CPU durante los últimos 60 segundos, minutos y 72 horas
- <show process process_ID>
- Información detallada sobre la memoria de proceso individual y las asignaciones de CPU
- <show platform software infrastructure punt>
- Proporciona información sobre todo el tráfico dirigido al RP
- <show platform software status control-processor brief>
- Detalla la carga y el "estado" de la CPU, así como detalles de las estadísticas de memoria y módulo
- <show platform software process slot r0|r1 monitor>
- Detalla los diferentes procesos y sus asignaciones de CPU y memoria en el módulo seleccionado
- <monitor platform software process r0|r1>
- Proporciona una fuente en directo que actualiza los procesos a medida que utilizan la CPU
- Requiere que el comando "terminal terminal-type" se ingrese primero en el modo de configuración global para funcionar correctamente
Procesador de servicios integrados
- <show platform software process list fp active summary>
- Detalla un resumen de todos los procesos que se ejecutan en la CPU, así como la carga media
- <show platform software process slot f0|f1 monitor>
- Detalla los diferentes procesos y sus asignaciones de CPU y memoria en el módulo seleccionado
- <monitor platform software process f0|f1>
- Proporciona una fuente en directo que actualiza los procesos a medida que utilizan la CPU
- Requiere que el comando "terminal terminal-type" se ingrese primero en el modo de configuración global para funcionar correctamente
Con la colaboración de ingenieros de Cisco
- Chris CourtelisCisco Systems
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)