Resolución de problemas de rutas de datos de fabric Punt serie ASR 9000
Opciones de descarga
-
ePub (608.4 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (614.1 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los mensajes de falla de la trayectoria de datos del fabric de punt observados durante el funcionamiento del Cisco Aggregation Services Router (ASR) 9000 Series.
El mensaje aparece con este formato:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
Este documento está dirigido a cualquier persona que desee comprender el mensaje de error y las acciones que se deben realizar si se detecta el problema.
Prerequisites
Requirements
Cisco recomienda tener un conocimiento de alto nivel de estos temas:
- Tarjetas de línea ASR 9000
- Tarjetas de fabric
- Procesadores de ruta
- Arquitectura de chasis
Sin embargo, este documento no requiere que los lectores estén familiarizados con los detalles de hardware. Se proporciona la información básica necesaria antes de explicar el mensaje de error. Este documento describe el error en las tarjetas de línea basadas en Trident y Typhoon. Consulte Comprensión de los tipos de tarjetas de línea de la serie ASR 9000 para obtener una explicación de estos términos.
Componentes Utilizados
Este documento no tiene restricciones específicas en cuanto a versiones de software y de hardware.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Utilización de este documento
Tenga en cuenta estas sugerencias sobre cómo utilizar este documento para obtener detalles esenciales y como guía de referencia en el proceso de solución de problemas:
- Cuando no hay urgencia para causar una falla en la trayectoria de datos de la estructura de punt, lea todas las secciones de este documento. Este documento genera los antecedentes necesarios para aislar un componente defectuoso cuando se produce un error de este tipo.
- Utilice la sección Preguntas frecuentes si tiene una pregunta específica en mente para la cual se necesita una respuesta rápida. Si la pregunta no se incluye en la sección Preguntas frecuentes, verifique si el documento principal aborda la pregunta.
- Utilice todas las secciones de Analizar fallas en para aislar el problema en un componente defectuoso cuando un router experimenta una falla o para verificar si es un problema conocido.
Antecedentes
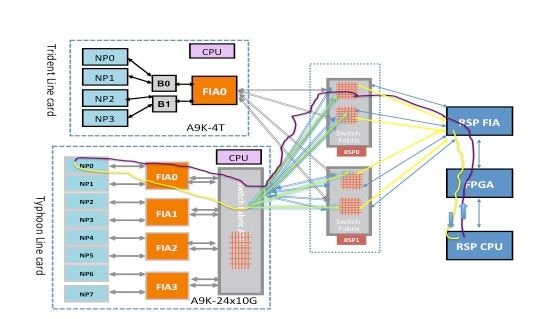
Un paquete puede atravesar dos o tres saltos a través del entramado del switch según el tipo de tarjeta de línea. Las tarjetas de línea de generación Typhoon añaden un elemento de fabric de switch adicional, mientras que las tarjetas de línea basadas en Trident conmutan todo el tráfico con el fabric solo en la tarjeta de procesador de routing. Estos diagramas muestran elementos de fabric para estos dos tipos de tarjetas de línea, así como conectividad de fabric a la tarjeta del procesador de routing:

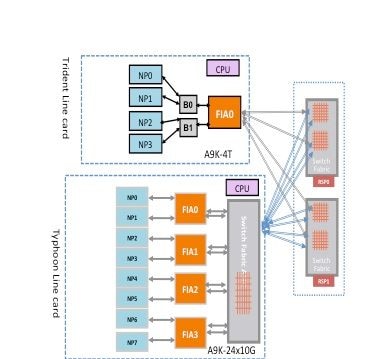
Ruta del paquete de diagnóstico de tejido Punt
La aplicación de diagnóstico que se ejecuta en la CPU de la tarjeta del procesador de ruta inyecta periódicamente paquetes de diagnóstico destinados a cada procesador de red (NP). El paquete de diagnóstico se devuelve en loop dentro del NP y se reinyecta hacia la CPU de la tarjeta del procesador de ruta que originó el paquete. Esta comprobación de estado periódica de cada NP con un paquete único por NP por parte de la aplicación de diagnóstico en la tarjeta del procesador de ruta proporciona una alerta para cualquier error funcional en la trayectoria de datos durante el funcionamiento del router. Es esencial tener en cuenta que la aplicación de diagnóstico tanto en el procesador de ruta activo como en el procesador de ruta en espera inyecta un paquete por NP periódicamente y mantiene un conteo de fallas o éxitos por NP. Cuando se alcanza un umbral de paquetes de diagnóstico descartados, la aplicación genera un error.
Vista conceptual de la ruta de diagnóstico
Antes de que el documento describa la trayectoria de diagnóstico en las tarjetas de línea basadas en Trident y Typhoon, esta sección proporciona un esquema general de la trayectoria de diagnóstico de fabric desde las tarjetas de procesador de ruta activas y en espera hacia el NP en la tarjeta de línea.
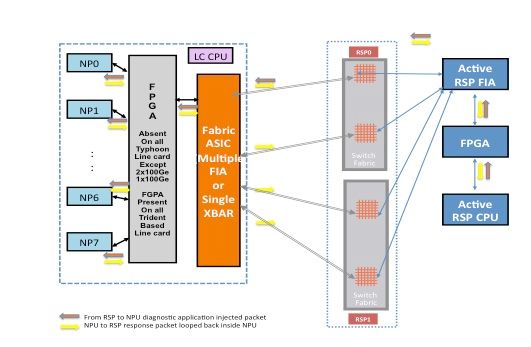
Ruta de paquetes entre la tarjeta de procesador de ruta activa y la tarjeta de línea
Los paquetes de diagnóstico inyectados desde el procesador de ruta activo en el fabric hacia el NP son tratados como paquetes de unidifusión por el fabric de switch. Con los paquetes de unidifusión, el switch fabric elige el link de salida en función de la carga de tráfico actual del link, lo que ayuda a someter los paquetes de diagnóstico a la carga de tráfico en el router. Cuando hay múltiples links salientes hacia el NP, el ASIC de estructura de switch elige un link que actualmente está menos cargado.
Este diagrama representa la trayectoria de paquete de diagnóstico originada en el procesador de ruta activo.
Nota: El primer link que conecta el Fabric Interface ASIC (FIA) en la tarjeta de línea a la barra cruzada (XBAR) en la tarjeta del procesador de ruta se elige todo el tiempo para los paquetes destinados a la NP. Los paquetes de respuesta del NP están sujetos a un algoritmo de distribución de carga de link (si la tarjeta de línea está basada en Typhoon). Esto significa que el paquete de respuesta del NP hacia el procesador de ruta activo puede elegir cualquiera de los links de entramado que conectan las tarjetas de línea a la tarjeta del procesador de ruta basada en la carga del link de entramado.
Ruta de paquetes entre la tarjeta de procesador de ruta en espera y la tarjeta de línea
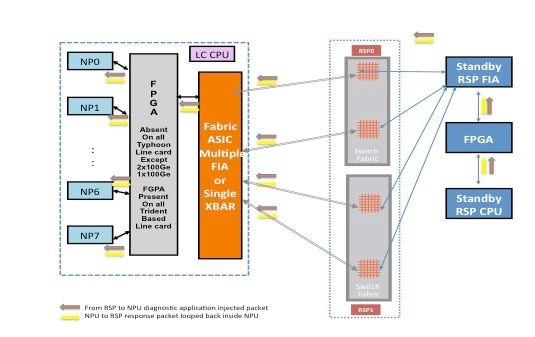
Los paquetes de diagnóstico inyectados desde el procesador de ruta en espera en el fabric hacia el NP son tratados como paquetes multicast por el fabric de switch. Aunque se trata de un paquete de multidifusión, no hay replicación dentro del fabric. Cada paquete de diagnóstico originado desde el procesador de ruta en espera alcanza solamente un NP a la vez. El paquete de respuesta del NP hacia el procesador de ruta también es un paquete de multidifusión sobre el fabric sin replicación. Por lo tanto, la aplicación de diagnóstico en el procesador de ruta en espera recibe un solo paquete de respuesta de los NP, un paquete a la vez. La aplicación de diagnóstico realiza un seguimiento de cada NP en el sistema, porque inyecta un paquete por NP y espera respuestas de cada NP, un paquete a la vez. Con un paquete de multidifusión, el switch fabric elige el link de salida en función de un valor de campo en el encabezado del paquete, lo que ayuda a inyectar paquetes de diagnóstico en cada link de fabric entre la tarjeta del procesador de ruta y la tarjeta de línea. El procesador de routing en espera realiza un seguimiento del estado de NP en cada enlace de fabric que se conecta entre la tarjeta del procesador de routing y la ranura de la tarjeta de línea.
El diagrama anterior representa la trayectoria de paquete de diagnóstico originada en el procesador de ruta en espera. Observe que, a diferencia del caso del procesador de rutas activo, todos los links que conectan la tarjeta de línea a la XBAR en el procesador de rutas se utilizan. Los paquetes de respuesta del NP toman el mismo link de fabric que fue utilizado por el paquete en el procesador de ruta a la dirección de la tarjeta de línea. Esta prueba garantiza que todos los links que conectan el procesador de ruta en espera a la tarjeta de línea sean monitoreados continuamente.
Punt Fabric Diagnostic Packet Path en la tarjeta de línea basada en Trident
Este diagrama representa los paquetes de diagnóstico originados en el procesador de ruta destinados a un NP que se reenvía en bucle hacia el procesador de ruta. Es importante tener en cuenta los links de trayectoria de datos y los ASIC que son comunes a todos los NP, así como los links y componentes que son específicos de un subconjunto de NP. Por ejemplo, el Bridge ASIC 0 (B0) es común a NP0 y NP1, mientras que FIA0 es común a todos los NP. En el extremo del procesador de routing, todos los links, los ASIC de ruta de datos y la matriz de puertas programables en campo (FPGA) son comunes a todas las tarjetas de línea y, por lo tanto, a todas las NP de un chasis.
Punt Fabric Diagnostic Packet Path en la tarjeta de línea basada en Typhoon
Este diagrama representa los paquetes de diagnóstico originados en la tarjeta del procesador de ruta destinados a un NP que está en loop hacia el procesador de ruta. Es importante tener en cuenta los links de trayectoria de datos y los ASIC que son comunes a todos los NP, así como los links y componentes que son específicos de un subconjunto de NP. Por ejemplo, FIA0 es común a NP0 y NP1. En el extremo de la tarjeta del procesador de ruta, todos los links, los ASIC de trayectoria de datos y el FGPA son comunes a todas las tarjetas de línea y, por lo tanto, a todos los NP en un chasis.
Ruta de paquetes de diagnóstico de tejido Punt en la tarjeta de línea basada en Tomahawk, Lightspeed y LightspeedPlus
En las tarjetas de línea Tomahawk hay conectividad 1:1 entre el FIA y el NP.
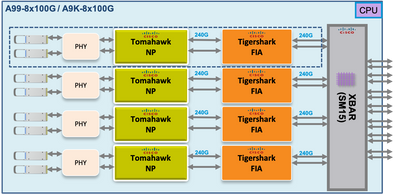
En las tarjetas de línea Lightspeed y LightspeedPlus, el FIA está integrado en el chip NP.

Las siguientes secciones intentan representar la trayectoria del paquete a cada NP. Esto es necesario para comprender el mensaje de error de la trayectoria de datos del fabric de punt y también para localizar el punto de falla.
Informes de fallos y alarmas de diagnóstico de tejido Punt
Si no se obtienen respuestas de un NP en un router basado en ASR 9000, se genera una alarma. La decisión de generar una alarma por parte de la aplicación de diagnóstico en línea que se ejecuta en el procesador de ruta ocurre cuando hay tres fallas consecutivas. La aplicación de diagnóstico mantiene una ventana de falla de tres paquetes para cada NP. El procesador de ruta activo y el procesador de ruta en espera diagnostican independientemente y en paralelo. El procesador de ruta activo, el procesador de ruta en espera o ambas tarjetas de procesador de ruta podrían informar del error. La ubicación de la falla y la pérdida de paquetes determinan qué procesador de ruta informa la alarma.
La frecuencia predeterminada del paquete de diagnóstico hacia cada NP es un paquete por 60 segundos o uno por minuto.
Este es el formato del mensaje de alarma:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
El mensaje muestra un error al alcanzar NP 1, 2, 3, 4, 5, 6 y 7 en la tarjeta de línea 0/7/cpu0 desde el procesador de ruta 0/rsp0/cpu0.
En la lista de pruebas de diagnóstico en línea, puede ver los atributos de la prueba de loopback del fabric de punt con este comando:
RP/0/RSP0/CPU0:iox(admin)#show diagnostic content location 0/RSP0/CPU0
RP 0/RSP0/CPU0:
Diagnostics test suite attributes:
M/C/* - Minimal bootup level test / Complete bootup level test / NA
B/O/* - Basic ondemand test / not Ondemand test / NA
P/V/* - Per port test / Per device test / NA
D/N/* - Disruptive test / Non-disruptive test / NA
S/* - Only applicable to standby unit / NA
X/* - Not a health monitoring test / NA
F/* - Fixed monitoring interval test / NA
E/* - Always enabled monitoring test / NA
A/I - Monitoring is active / Monitoring is inactive
Test Interval Thre-
ID Test Name Attributes (day hh:mm:ss.ms shold)
==== ================================== ============ ================= =====
1) PuntFPGAScratchRegister ---------- *B*N****A 000 00:01:00.000 1
2) FIAScratchRegister --------------- *B*N****A 000 00:01:00.000 1
3) ClkCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
4) IntCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
5) CPUCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
6) FabSwitchIdRegister -------------- *B*N****A 000 00:01:00.000 1
7) EccSbeTest ----------------------- *B*N****I 000 00:01:00.000 3
8) SrspStandbyEobcHeartbeat --------- *B*NS***A 000 00:00:05.000 3
9) SrspActiveEobcHeartbeat ---------- *B*NS***A 000 00:00:05.000 3
10) FabricLoopback ------------------- MB*N****A 000 00:01:00.000 3
11) PuntFabricDataPath --------------- *B*N****A 000 00:01:00.000 3
12) FPDimageVerify ------------------- *B*N****I 001 00:00:00.000 1
RP/0/RSP0/CPU0:ios(admin)#
El resultado muestra que la frecuencia de prueba de PuntFabricDataPath es de un paquete cada minuto, y el umbral de falla es de tres, lo que implica que la pérdida de tres paquetes consecutivos no se tolera y da lugar a una alarma. Los atributos de prueba mostrados son valores predeterminados. Para cambiar los valores predeterminados, ingrese el diagnostic monitor interval y diagnostic monitor threshold en el modo de configuración de administración.
Ruta del paquete de diagnóstico de tarjeta de línea basada en Trident
Falla de diagnóstico NP0
Ruta de diagnóstico de fabric
Este diagrama representa la trayectoria del paquete entre la CPU del procesador de ruta y la tarjeta de línea NP0. El link que conecta B0 y NP0 es el único link específico para NP0. Todos los demás enlaces se encuentran en la ruta común.
Anote el trayecto del paquete desde el procesador de ruta hacia NP0. Aunque hay cuatro links para utilizar para los paquetes destinados hacia NP0 desde el procesador de ruta, el primer link entre el procesador de ruta y la ranura de tarjeta de línea se utiliza para el paquete desde el procesador de ruta hacia la tarjeta de línea. El paquete devuelto desde NP0 se puede enviar de vuelta al procesador de ruta activo a través de cualquiera de las dos trayectorias de link de entramado entre la ranura de tarjeta de línea y el procesador de ruta activo. La elección de uno de los dos links a utilizar depende de la carga del link en ese momento. El paquete de respuesta de NP0 hacia el procesador de ruta en espera utiliza ambos links, pero un link a la vez. La elección del enlace se basa en el campo de encabezado que rellena la aplicación de diagnóstico.

Análisis de fallos de diagnóstico NP0
Escenario de falla única
Si se detecta una sola alarma de falla de trayecto de datos de fabric de punt de Platform Fault Manager (PFM) con solo NP0 en el mensaje de falla, la falla está solamente en el trayecto de fabric que conecta el procesador de ruta y la tarjeta de línea NP0. Esto es un solo fallo. Si el fallo se detecta en más de un NP, consulte la sección Escenario de Falla Múltiple.
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 0)
Nota: esta sección del documento se aplica a cualquier ranura de tarjeta de línea de un chasis, independientemente del tipo de chasis. Por lo tanto, esto se puede aplicar a todas las ranuras de tarjetas de línea.
Como se ilustró en el diagrama de trayectoria de datos anterior, el fallo debe estar en una o más de estas ubicaciones:
- Enlace que conecta NP0 y B0
- Dentro de las colas B0 dirigidas hacia NP0
- NP0 interno
Escenario de falla múltiple
Múltiples fallas NP
Cuando se observan otros fallos en NP0 o otros NP de la misma tarjeta de línea informan de la falla PUNT_FABRIC_DATA_PATH_FAILED, el aislamiento de fallos se realiza correlacionando todos los fallos. Por ejemplo, si tanto la falla PUNT_FABRIC_DATA_PATH_FAILED como la falla LC_NP_LOOPBACK_FAILED ocurren en NP0, entonces el NP ha detenido el procesamiento de paquetes. Refiérase a la sección Ruta de Diagnóstico de Loopback NP para comprender el error de loopback. Esto podría ser una indicación temprana de una falla crítica dentro de NP0. Sin embargo, si ocurre solamente uno de los dos fallos, el fallo se localiza en la trayectoria de datos de la estructura de punt o en la CPU de la tarjeta de línea a la trayectoria NP.
Si más de un NP en una tarjeta de línea tiene una falla de trayectoria de datos de la estructura de punt, debe subir la trayectoria de árbol de los links de la estructura para aislar un componente defectuoso. Por ejemplo, si tanto NP0 como NP1 tienen una falla, la falla debe estar en B0 o en el link que conecta B0 y FIA0. Es menos probable que tanto NP0 como NP1 encuentren un error interno crítico al mismo tiempo. Aunque es menos probable, es posible que NP0 y NP1 encuentren un error crítico debido al procesamiento incorrecto de un tipo particular de paquete o un paquete incorrecto.
Ambas tarjetas de procesador de ruta informan un fallo
Si tanto las tarjetas de procesador de ruta activas como en espera informan un fallo a uno o más NPs en una tarjeta de línea, verifique todos los links y componentes comunes en la trayectoria de datos entre los NPs afectados y ambas tarjetas de procesador de ruta.
Fallo de diagnóstico de NP1
Este diagrama representa la trayectoria del paquete entre la CPU de la tarjeta del procesador de ruta y la tarjeta de línea NP1. El link que conecta el Bridge ASIC 0 (B0) y NP1 es el único link específico de NP1. Todos los demás enlaces se encuentran en la ruta común.
Anote el trayecto del paquete desde la tarjeta del procesador de ruta hacia NP1. Aunque hay cuatro links para utilizar para los paquetes destinados hacia NP0 desde el procesador de ruta, el primer link entre el procesador de ruta y la ranura de tarjeta de línea se utiliza para el paquete desde el procesador de ruta hacia la tarjeta de línea. El paquete devuelto desde NP1 se puede enviar de vuelta al procesador de ruta activo a través de cualquiera de las dos trayectorias de link de entramado entre la ranura de tarjeta de línea y el procesador de ruta activo. La elección de uno de los dos links a utilizar depende de la carga del link en ese momento. El paquete de respuesta de NP1 hacia el procesador de ruta en espera utiliza ambos links, pero un link a la vez. La elección del enlace se basa en el campo de encabezado que rellena la aplicación de diagnóstico.
Ruta de diagnóstico de fabric
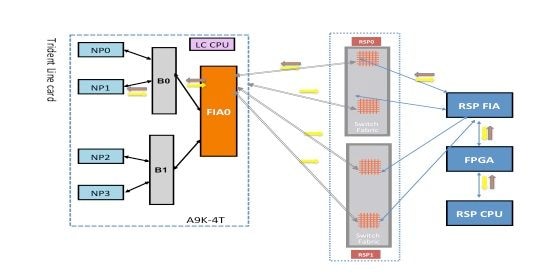
Análisis de fallos de diagnóstico NP1
Consulte la sección Análisis de fallas de diagnóstico NP0, pero aplique el mismo razonamiento para NP1 (en lugar de NP0).
Fallo de diagnóstico de NP2
Este diagrama representa la trayectoria del paquete entre la CPU de la tarjeta del procesador de ruta y la tarjeta de línea NP2. El link que conecta B1 y NP2 es el único link específico para NP2. Todos los demás enlaces se encuentran en la ruta común.
Tome nota de la trayectoria del paquete desde la tarjeta del procesador de ruta hacia NP2. Aunque hay cuatro links para utilizar para los paquetes destinados hacia NP2 desde el procesador de ruta, el primer link entre el procesador de ruta y la ranura de tarjeta de línea se utiliza para el paquete desde el procesador de ruta hacia la tarjeta de línea. El paquete devuelto desde NP2 se puede enviar de vuelta al procesador de ruta activo a través de cualquiera de las dos trayectorias de link de entramado entre la ranura de tarjeta de línea y el procesador de ruta activo. La elección de uno de los dos links a utilizar depende de la carga del link en ese momento. El paquete de respuesta de NP2 hacia el procesador de ruta en espera utiliza ambos links, pero un link a la vez. La elección del enlace se basa en el campo de encabezado que rellena la aplicación de diagnóstico.
Ruta de diagnóstico de fabric
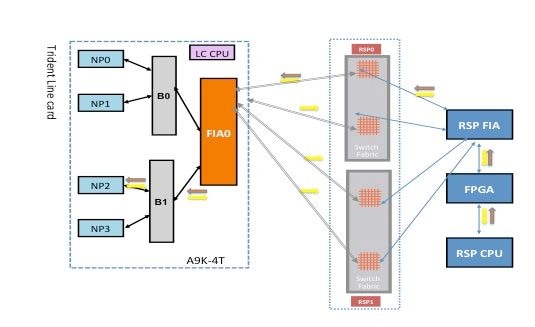
Análisis de fallos de diagnóstico NP2
Consulte la sección Análisis de fallas de diagnóstico NP0, pero aplique el mismo razonamiento para NP2 (en lugar de NP0).
Fallo de diagnóstico de NP3
Este diagrama representa la trayectoria del paquete entre la CPU de la tarjeta del procesador de ruta y la tarjeta de línea NP3. El link que conecta el Bridge ASIC 1 (B1) y NP3 es el único link específico de NP3. Todos los demás enlaces se encuentran en la ruta común.
Tome nota de la trayectoria del paquete desde la tarjeta del procesador de ruta hacia NP3. Aunque hay cuatro links para utilizar para los paquetes destinados hacia NP3 desde el procesador de ruta, el primer link entre el procesador de ruta y la ranura de tarjeta de línea se utiliza para el paquete desde el procesador de ruta hacia la tarjeta de línea. El paquete devuelto desde NP3 se puede enviar de vuelta al procesador de ruta activo a través de cualquiera de las dos trayectorias de link de entramado entre la ranura de tarjeta de línea y el procesador de ruta activo. La elección de uno de los dos links a utilizar depende de la carga del link en ese momento. El paquete de respuesta de NP3 hacia el procesador de ruta en espera utiliza ambos links, pero un link a la vez. La elección del enlace se basa en el campo de encabezado que rellena la aplicación de diagnóstico.
Ruta de diagnóstico de fabric
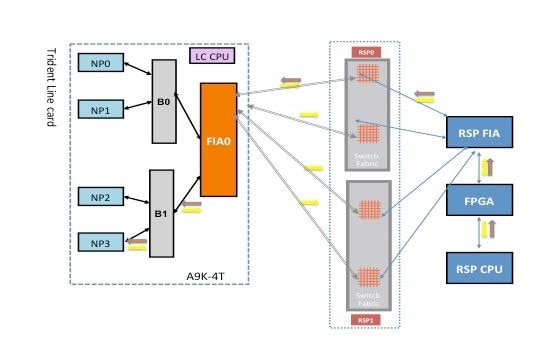
Análisis de fallos de diagnóstico NP3
Consulte la sección Análisis de fallas de diagnóstico NP0, pero aplique el mismo razonamiento para NP3 (en lugar de NP0).
Ruta de paquete de diagnóstico de tarjeta de línea basada en Typhoon
Esta sección proporciona dos ejemplos para establecer el fondo para los paquetes de punt de entramado con tarjetas de línea basadas en Typhoon. El primer ejemplo utiliza NP1 y el segundo utiliza NP3. La descripción y el análisis se pueden ampliar a otras NP en cualquier tarjeta de línea basada en Typhoon.
Falla de diagnóstico de Typhoon NP1
El siguiente diagrama representa la trayectoria del paquete entre la CPU de la tarjeta del procesador de ruta y la tarjeta de línea NP1. El link que conecta FIA0 y NP1 es el único link específico de la trayectoria NP1. Todos los otros links entre la ranura de tarjeta de línea y la ranura de tarjeta de procesador de ruta se encuentran en la trayectoria común. Los links que conectan el ASIC XBAR de fabric en la tarjeta de línea con los FIA en la tarjeta de línea son específicos de un subconjunto de NP. Por ejemplo, ambos links entre FIA0 y el ASIC XBAR de la estructura local en la tarjeta de línea se utilizan para el tráfico a NP1.
Anote el trayecto del paquete desde la tarjeta del procesador de ruta hacia NP1. Aunque hay ocho links que se utilizan para los paquetes destinados hacia NP1 desde la tarjeta del procesador de ruta, se utiliza una sola trayectoria entre la tarjeta del procesador de ruta y la ranura de la tarjeta de línea. El paquete devuelto desde NP1 se puede enviar de vuelta a la tarjeta del procesador de ruta a través de ocho trayectorias de link de entramado entre la ranura de la tarjeta de línea y el procesador de ruta. Cada uno de estos ocho links se ejerce uno a la vez cuando el paquete de diagnóstico se dirige de nuevo a la CPU de la tarjeta de procesador de ruta.
Ruta de diagnóstico de fabric

Falla de diagnóstico del Typhoon NP3
Este diagrama representa la trayectoria del paquete entre la CPU de la tarjeta del procesador de ruta y la tarjeta de línea NP3. El link que conecta FIA1 y NP3 es el único link específico de la trayectoria NP3. Todos los otros links entre la ranura de tarjeta de línea y la ranura de tarjeta de procesador de ruta se encuentran en la trayectoria común. Los links que conectan el ASIC XBAR de fabric en la tarjeta de línea con los FIA en la tarjeta de línea son específicos de un subconjunto de NP. Por ejemplo, ambos links entre FIA1 y el ASIC XBAR de la estructura local en la tarjeta de línea se utilizan para el tráfico a NP3.
Tome nota de la trayectoria del paquete desde la tarjeta del procesador de ruta hacia NP3. Aunque hay ocho links que se utilizan para los paquetes destinados hacia NP3 desde la tarjeta del procesador de ruta, se utiliza una sola trayectoria entre la tarjeta del procesador de ruta y la ranura de la tarjeta de línea. El paquete devuelto desde NP1 se puede enviar de vuelta a la tarjeta del procesador de ruta a través de ocho trayectorias de link de entramado entre la ranura de la tarjeta de línea y el procesador de ruta. Cada uno de estos ocho links se ejerce uno a la vez cuando el paquete de diagnóstico se dirige de nuevo a la CPU de la tarjeta de procesador de ruta.
Ruta de diagnóstico de fabric

Ruta del paquete de diagnóstico de la tarjeta de línea basada en Tomahawk
Debido a la conectividad 1:1 entre el FIA y NP, el único tráfico que atraviesa FIA0 es hacia/desde NP0.
Trayecto de paquete de diagnóstico de tarjeta de línea basada en Lightspeed y LightspeedPlus
Como el FIA está integrado en el chip NP, el único tráfico que atraviesa FIA0 es hacia/desde NP0.
Analizar fallos
Esta sección clasifica los fallos en casos difíciles y transitorios, y enumera los pasos utilizados para identificar si un fallo es un fallo duro o transitorio. Una vez que se determina el tipo de falla, el documento especifica los comandos que se pueden ejecutar en el router para comprender la falla y qué acciones correctivas son necesarias.
Falla transitoria
Si un mensaje PFM set es seguido por un mensaje PFM clear, entonces se ha producido una falla y el router ha corregido la falla en sí. Pueden producirse fallos transitorios debido a condiciones ambientales y fallos recuperables en los componentes de hardware. A veces puede ser difícil asociar fallas transitorias a un evento en particular.
A continuación se incluye un ejemplo de un fallo de fabric transitorio para mayor claridad:
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
RP/0/RSP0/CPU0:Feb 5 05:05:46.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Acciones Correctivas de Fallas Transitorias
El enfoque sugerido para los errores transitorios es monitorear solamente la aparición de tales errores. Si un fallo transitorio ocurre más de una vez, trate el fallo transitorio como un fallo grave y utilice las recomendaciones y los pasos para analizar dichos fallos descritos en la siguiente sección.
Fallo grave
Si un mensaje PFM configurado no va seguido de un mensaje PFM claro, se ha producido un error y el router no ha corregido el error por sí mismo mediante el código de gestión de errores, o la naturaleza del error de hardware no es recuperable. Pueden producirse fallos graves debido a condiciones ambientales y fallos irrecuperables en los componentes de hardware. El enfoque sugerido para los fallos graves es utilizar las directrices mencionadas en la sección Análisis de Fallos.
Aquí se incluye un ejemplo de fallo de fabric duro para mayor claridad. Para este mensaje de ejemplo, no hay un mensaje PFM claro correspondiente.
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Acciones Correctivas de Fallos Graves
En una situación de error grave, recopile todos los comandos mencionados en la sección Datos que se deben recopilar antes de la creación de la solicitud de servicio y abra una solicitud de servicio. En casos urgentes, después de recopilar toda la salida del comando de troubleshooting, inicie una tarjeta de procesador de ruta o una recarga de tarjeta de línea basada en el aislamiento de fallas. Después de la recarga, si el error no se recupera, inicie una autorización de devolución de mercancía (RMA).
Análisis de fallos transitorios
Complete estos pasos para analizar los fallos transitorios.
- Escriba el
show logging | inc “PUNT_FABRIC_DATA_PATH"para descubrir si el error ocurrió una o varias veces. - Escriba el
show pfm location allpara determinar el estado actual (SET o CLEAR). ¿Está pendiente o se ha borrado el error? Si el estado del error cambia entre SET y CLEAR, se producen repetidamente uno o más fallos en la ruta de datos del fabric y se rectifican mediante software o hardware. - Aprovisione trampas del protocolo simple de administración de red (SNMP) o ejecute un script que recopile
show pfm location ally busca la cadena de error periódicamente para monitorear la ocurrencia futura del fallo (cuando el último estado del error es CLEAR, y no ocurren nuevos fallos).
Comandos a utilizar
Ingrese estos comandos para analizar los fallos transitorios:
show logging | inc “PUNT_FABRIC_DATA_PATH”show pfm location all
Análisis de fallos graves
Si ve los links de trayectoria de datos de fabric en una tarjeta de línea como un árbol (donde los detalles se describen en la sección Información de fondo), entonces debe inferir -según el punto de falla- si uno o más NP son inaccesibles. Cuando ocurren múltiples fallas en múltiples NPs, utilice los comandos listados en esta sección para analizar fallas.
Comandos a utilizar
Ingrese estos comandos para analizar los errores graves:
show logging | inc “PUNT_FABRIC_DATA_PATH”
El resultado podría contener uno o más NP (por ejemplo: NP2, NP3).show controller fabric fia link-status location
Dado que tanto NP2 como NP3 (en la sección Typhoon NP3 Diagnostic Failure) reciben y envían a través de un solo FIA, es razonable inferir que el fallo se encuentra en un FIA asociado en el trayecto.show controller fabric crossbar link-status instance <0 and 1> location
Si todos los NP en la tarjeta de línea no son accesibles para la aplicación de diagnóstico, entonces es razonable inferir que los links que conectan la ranura de tarjeta de línea con la tarjeta de procesador de ruta podrían tener un error en cualquiera de los ASIC que reenvían tráfico entre la tarjeta de procesador de ruta y la tarjeta de línea.show controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 0 location 0/rsp1/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp1/cpu0show controller fabric fia link-status location 0/rsp*/cpu0show controller fabric fia link-status location 0/rsp0/cpu0show controller fabric fia link-status location 0/rsp1/cpu0show controller fabric fia bridge sync-status location 0/rsp*/cpu0show controller fabric fia bridge sync-status location 0/rsp0/cpu0show controller fabric fia bridge sync-status location 0/rsp1/cpu0show tech fabric terminal
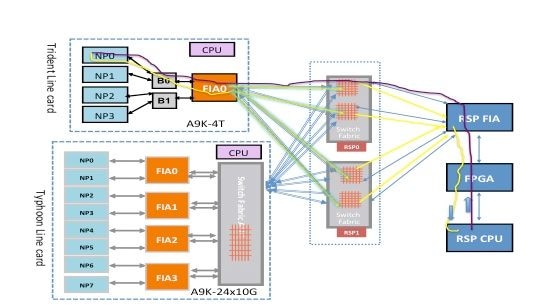
Nota: Si todos los NP en todas las tarjetas de línea informan un fallo, entonces el fallo es más probable en la tarjeta de procesador de ruta (tarjeta de procesador de ruta activa o tarjeta de procesador de ruta en espera). Consulte el link que conecta la CPU de la tarjeta de procesador de ruta con el FPGA y la tarjeta de procesador de ruta FIA en la sección Información de Fondo.
Fallos anteriores
Históricamente, el 99% de los fallos son recuperables y, en la mayoría de los casos, la acción de recuperación iniciada por software corrige los fallos. Sin embargo, en casos muy raros, se observan errores irrecuperables que solo pueden corregirse con la RMA de las tarjetas.
En las siguientes secciones se identifican algunos fallos anteriores que se han producido para servir de guía en caso de que se observen errores similares.
Error transitorio debido a sobresuscripción de NP
Estos mensajes se muestran si el error se debe a una sobresuscripción de NP.
RP/0/RP1/CPU0:Jun 26 13:08:28.669 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0, 0)
RP/0/RP1/CPU0:Jun 26 13:09:28.692 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0,0)
Los fallos transitorios pueden ser más difíciles de confirmar. Un método para determinar si una NP está actualmente sobresuscrita o ha sido sobresuscrita en el pasado es verificar un cierto tipo de caída dentro de la NP y para las caídas de cola en la FIA. Las caídas de Ingress Front Direct Memory Access (IFDMA) dentro del NP ocurren cuando el NP está sobresuscrito y no puede mantenerse al día con el tráfico entrante. Las caídas de cola FIA se producen cuando un NP de salida afirma el control de flujo (pide a la tarjeta de línea de entrada que envíe menos tráfico). En el escenario de control de flujo, el FIA de ingreso tiene caídas de cola.
Aquí tiene un ejemplo:
RP/0/RSP0/CPU0:RP/0/RSP0/CPU0:ASR9006-C#show controllers np counters all
Wed Feb 19 13:10:11.848 EST
Node: 0/1/CPU0:
----------------------------------------------------------------
Show global stats counters for NP0, revision v3
Read 93 non-zero NP counters:
Offset Counter FrameValue Rate (pps)
-----------------------------------------------------------------------
22 PARSE_ENET_RECEIVE_CNT 46913080435 118335
23 PARSE_FABRIC_RECEIVE_CNT 40175773071 5
24 PARSE_LOOPBACK_RECEIVE_CNT 5198971143966 0
<SNIP>
Show special stats counters for NP0, revision v3
Offset Counter CounterValue
----------------------------------------------------------------------------
524032 IFDMA discard stats counters 0 8008746088 0 <<<<<
Aquí tiene un ejemplo:
RP/0/RSP0/CPU0:ASR9006-C#show controllers fabric fia drops ingress location 0/1/cPU0
Wed Feb 19 13:37:27.159 EST
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 0
Tail Drop-0 0 <<<<<<<
Tail Drop-1 0 <<<<<<<
Tail Drop-2 0 <<<<<<<
Tail Drop-3 0 <<<<<<<
Tail Drop DE-0 0
Tail Drop DE-1 0
Tail Drop DE-2 0
Tail Drop DE-3 0
Hard Drop-0 0
Hard Drop-1 0
Hard Drop-2 0
Hard Drop-3 0
Hard Drop DE-0 0
Hard Drop DE-1 0
Hard Drop DE-2 0
Hard Drop DE-3 0
WRED Drop-0 0
WRED Drop-1 0
WRED Drop-2 0
WRED Drop-3 0
WRED Drop DE-0 0
WRED Drop DE-1 0
WRED Drop DE-2 0
WRED Drop DE-3 0
Mc No Rep 0
Falla de hardware debido al reinicio rápido de NP
Cuando se produce PUNT_FABRIC_DATA_PATH_FAILED, y si la falla se debe a un reinicio rápido NP, los registros similares a los que se enumeran aquí aparecen para una tarjeta de línea basada en Typhoon. El mecanismo de supervisión de estado está disponible en tarjetas de línea basadas en Typhoon, pero no en tarjetas de línea basadas en Trident.
LC/0/2/CPU0:Aug 26 12:09:15.784 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:18.798 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:21.812 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST:
prm_server_ty[303]: NP-DIAG health monitoring failure on NP0
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST: pfm_node_lc[291]:
%PLATFORM-NP-0-NP_DIAG : Set|prm_server_ty[172112]|
Network Processor Unit(0x1008000)| NP diagnostics warning on NP0.
LC/0/2/CPU0:Aug 26 12:09:40.492 CEST: prm_server_ty[303]:
Starting fast reset for NP 0 LC/0/2/CPU0:Aug 26 12:09:40.524 CEST:
prm_server_ty[303]: Fast Reset NP0 - successful auto-recovery of NP
Para las tarjetas de línea basadas en Trident, este registro se ve con un reinicio rápido de un NP:
LC/0/1/CPU0:Mar 29 15:27:43.787 test:
pfm_node_lc[279]: Fast Reset initiated on NP3
Fallas entre los procesadores de ruta RSP440 y las tarjetas de línea Typhoon
Cisco ha solucionado un problema en el que rara vez se vuelven a formar los enlaces de fabric entre el procesador de switch de ruta (RSP) 440 y las tarjetas de línea basadas en Typhoon en la placa base. Los enlaces de fabric se vuelven a formar porque la potencia de la señal no es óptima. Este problema está presente en las versiones de software Cisco IOS® XR 4.2.1, 4.2.2, 4.2.3, 4.3.0, 4.3.1 y 4.3.2 de la base. Una actualización de mantenimiento de software (SMU) para cada una de estas versiones se publica en Cisco Connection Online y se realiza un seguimiento con el identificador de error de Cisco CSCuj10837 y el identificador de error de Cisco CSCul39674.
Cuando este problema ocurre en el router, cualquiera de estos escenarios puede ocurrir:
- El link se desactiva y se activa. (Transitorio)
- El link se desactiva permanentemente.
Cisco bug ID CSCuj10837 - Reentrenamiento de estructura entre RSP y LC (Dirección TX)
Para confirmar, recopile los resultados ltrace de LC y de ambos RSP (show controller fabric crossbar ltrace location <>) y verifique si este resultado se ve en los seguimientos RSP:
SMU ya está disponible
Aquí tiene un ejemplo:
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain:
destslot:0 fmlgrp:3 rc:0
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (2,0,7) initiated
Oct 1 08:22:58.969 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (2,1,0),(2,2,0),0.
El término dirección TX se refiere a la dirección desde el punto de vista de la interfaz de estructura de barras cruzadas de RSP hacia una interfaz de barras cruzadas de estructura en una tarjeta de línea basada en Typhoon.
El Id. de bug Cisco CSCuj10837 se caracteriza por la detección por parte de la tarjeta de línea Typhoon de un problema en el link RX desde el RSP y el inicio de un reentrenamiento de link. Cualquiera de los lados (LC o RSP) puede iniciar el evento de reciclaje. En el caso del ID de bug de Cisco CSCuj10837, la LC inicia el reentrenamiento y puede ser detectada por el mensaje init xbar_trigger_link_retrain: en los seguimientos de la LC.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain: destslot:
0 fmlgrp:3 rc:0
Cuando la LC inicia el reentrenamiento, el RSP informa un link_retrain recibido en el resultado de seguimiento.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
ID de bug de Cisco CSCul39674 - Reentrenamiento de estructura entre RSP y LC (Dirección RX)
Para confirmar, recopile las salidas ltrace de la tarjeta de línea y de ambos RSP (show controller fabric crossbar ltrace location <>) y verifique si este resultado se ve en los seguimientos RSP:
Aquí tiene un ejemplo:
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain:
destslot:4 fmlgrp:3 rc:0
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (5,1,11) initiated
Jan 8 17:28:39.256 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (5,1,1),(0,1,0),0.
El término dirección RX se refiere a la dirección desde el punto de vista de la interfaz de fabric de barras cruzadas RSPs desde una interfaz de barras cruzadas de fabric en una tarjeta de línea basada en Typhoon.
El Id. de bug Cisco CSCul39674 se caracteriza por la detección por parte del RSP de un problema en el link RX desde la tarjeta de línea Typhoon y el inicio de un reentrenamiento de link. Cualquiera de los lados (LC o RSP) puede iniciar el evento de reciclaje. En el caso del ID de bug de Cisco CSCul39674, el RSP inicia el reentrenamiento y puede ser detectado por el mensaje init xbar_trigger_link_retrain: en los seguimientos del RSP.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain: destslot:4 fmlgrp:
3 rc:0
Cuando el RSP inicia el reentrenamiento, la LC informa un evento link_retrain recibido en el resultado del seguimiento.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
Diferencias en la actualización del entramado en la versión 4.3.2 y posteriores
Se ha realizado un trabajo importante para reducir el tiempo que se tarda en volver a entrenar un link de fabric en Cisco IOS XR Release 4.3.2 y posteriores. El reacondicionamiento del fabric ahora se produce en menos de un segundo y es imperceptible a los flujos de tráfico. En Cisco IOS XR Release 4.3.2, solo se ven estos mensajes de syslog cuando se produce un reentrenamiento del link de entramado.
%PLATFORM-FABMGR-5-FABRIC_TRANSIENT_FAULT : Fabric backplane crossbar link
underwent link retraining to recover from a transient error: Physical slot 1
Fallo debido a desbordamiento FIFO de Fabric ASIC
Cisco ha corregido un problema por el que el Fabric ASIC (FIA) podía restablecerse debido a una condición de desbordamiento irrecuperable FIFO (First In First Out). Esto se resuelve con el ID de bug de Cisco CSCul6510. Este problema sólo afecta a las tarjetas de línea basadas en Trident y sólo se encuentra en casos raros con una congestión excesiva de la ruta de ingreso. Si se encuentra este problema, este mensaje de syslog se muestra antes de restablecer la tarjeta de línea para recuperarse de la condición.
RP/0/RSP0/CPU0:asr9k-2#show log
LC/0/3/CPU0:Nov 13 03:46:38.860 utc: pfm_node_lc[284]:
%FABRIC-FIA-0-ASIC_FATAL_FAULT Set|fialc[159814]
|Fabric Interface(0x1014000)|Fabric interface asic ASIC1 encountered fatal
fault 0x1b - OC_DF_INT_PROT_ERR_0
LC/0/3/CPU0:Nov 13 03:46:38.863 utc: pfm_node_lc[284]:
%PLATFORM-PFM-0-CARD_RESET_REQ : pfm_dev_sm_perform_recovery_action,
Card reset requested by: Process ID:159814 (fialc), Fault Sev: 0, Target node:
0/3/CPU0, CompId: 0x10, Device Handle: 0x1014000, CondID: 2545, Fault Reason:
Fabric interface asic ASIC1 encountered fatal fault 0x1b - OC_DF_INT_PROT_ERR_0
Fallo debido a la acumulación de una cola de salida virtual (VOQ) intensa como consecuencia de la congestión del fabric
Cisco ha solucionado un problema en el que una gran congestión podría provocar el agotamiento de los recursos de fabric y la pérdida de tráfico. La pérdida de tráfico puede incluso ocurrir en flujos no relacionados. Este problema se resuelve con el ID de bug Cisco CSCug90300 y se resuelve en Cisco IOS XR Release 4.3.2 y posterior. La corrección también se entrega en Cisco IOS XR Release 4.2.3 CSMU#3, Id. de error de Cisco CSCui3805. Este raro problema se puede encontrar en tarjetas de línea basadas en Trident o Typhoon.
Comandos relevantes
Recopile el resultado de estos comandos:
show tech-support fabricshow controller fabric fia bridge flow-control location<=== Obtener este resultado para todas las LCshow controllers fabric fia q-depth location
A continuación se muestran algunos ejemplos de resultados:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia q-depth location 0/6/CPU0
Sun Dec 29 23:10:56.307 UTC
********** FIA-0 **********
Category: q_stats_a-0
Voq ddr pri pktcnt
11 0 2 7
********** FIA-0 **********
Category: q_stats_b-0
Voq ddr pri pktcnt
********** FIA-1 **********
Category: q_stats_a-1
Voq ddr pri pktcnt
11 0 0 2491
11 0 2 5701
********** FIA-1 **********
Category: q_stats_b-1
Voq ddr pri pktcnt
RP/0/RSP0/CPU0:asr9k-1#
RP/0/RSP0/CPU0:asr9k-1#show controllers pm location 0/1/CPU0 | in "switch|if"
Sun Dec 29 23:37:05.621 UTC
Ifname(2): TenGigE0_1_0_2, ifh: 0x2000200 : <==Corresponding interface ten 0/1/0/2
iftype 0x1e
switch_fabric_port 0xb <==== VQI 11
parent_ifh 0x0
parent_bundle_ifh 0x80009e0
RP/0/RSP0/CPU0:asr9k-1#
En condiciones normales, es muy improbable ver un VOQ con paquetes en cola. Este comando es una instantánea rápida en tiempo real de las colas FIA. Es común que este comando no muestre ningún paquete en cola.
Impacto en el tráfico debido a errores de software de Bridge/FPGA en tarjetas de línea basadas en Trident
Los errores de software son errores no permanentes que provocan que la máquina de estado no esté sincronizada. Estos se consideran como verificación por redundancia cíclica (CRC), secuencia de verificación de tramas (FCS) o paquetes con errores en el lado del fabric del NP o en el lado de entrada del FIA.
A continuación se muestran algunos ejemplos de cómo se puede ver este problema:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia drops ingress location 0/3/CPU0
Fri Dec 6 19:50:42.135 UTC
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 32609856 <=== Errors
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia errors ingress location 0/3/CPU0
Fri Dec 6 19:50:48.934 UTC
********** FIA-0 **********
Category: in_error-0
DDR Rx CRC-0 0
DDR Rx CRC-1 32616455 <=== Errors
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/0/CPU0
Ingress Drop Stats (MC & UC combined)
**************************************
PriorityPacket Error Threshold
Direction Drops Drops
--------------------------------------------------
LP NP-3 to Fabric 0 0
HP NP-3 to Fabric 1750 0
RP/0/RSP1/CPU0:asr9k-1#
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/6/CPU0
Sat Jan 4 06:33:41.392 CST
********** FIA-0 **********
Category: bridge_in-0
UcH Fr Np-0 16867506
UcH Fr Np-1 115685
UcH Fr Np-2 104891
UcH Fr Np-3 105103
UcL Fr Np-0 1482833391
UcL Fr Np-1 31852547525
UcL Fr Np-2 3038838776
UcL Fr Np-3 30863851758
McH Fr Np-0 194999
McH Fr Np-1 793098
McH Fr Np-2 345046
McH Fr Np-3 453957
McL Fr Np-0 27567869
McL Fr Np-1 12613863
McL Fr Np-2 663139
McL Fr Np-3 21276923
Hp ErrFrNp-0 0
Hp ErrFrNp-1 0
Hp ErrFrNp-2 0
Hp ErrFrNp-3 0
Lp ErrFrNp-0 0
Lp ErrFrNp-1 0
Lp ErrFrNp-2 0
Lp ErrFrNp-3 0
Hp ThrFrNp-0 0
Hp ThrFrNp-1 0
Hp ThrFrNp-2 0
Hp ThrFrNp-3 0
Lp ThrFrNp-0 0
Lp ThrFrNp-1 0
Lp ThrFrNp-2 0
Lp ThrFrNp-3 0
********** FIA-0 **********
Category: bridge_eg-0
UcH to Np-0 779765
UcH to Np-1 3744578
UcH to Np-2 946908
UcH to Np-3 9764723
UcL to Np-0 1522490680
UcL to Np-1 32717279812
UcL to Np-2 3117563988
UcL to Np-3 29201555584
UcH ErrToNp-0 0
UcH ErrToNp-1 0
UcH ErrToNp-2 129 <==============
UcH ErrToNp-3 0
UcL ErrToNp-0 0
UcL ErrToNp-1 0
UcL ErrToNp-2 90359 <==========
Comandos para recopilar errores de software Bridge/FPGA en tarjetas de línea basadas en Trident
Recopile el resultado de estos comandos:
show tech-support fabricshow tech-support npshow controller fabric fia bridge stats location <>(obtener varias veces)
Recuperación de errores de software de Bridge/FPGA
El método de recuperación es recargar la tarjeta de línea afectada.
RP/0/RSP0/CPU0:asr9k-1#hw-module location 0/6/cpu0 reload
Informe de pruebas de diagnóstico en línea
show diagnostic result location
proporciona un resumen de todas las pruebas de diagnóstico y fallas en línea, así como la última marca de tiempo cuando una prueba pasó. El ID de prueba para el fallo de la ruta de datos del fabric de punt es diez. Se puede ver una lista de todas las pruebas junto con la frecuencia de los paquetes de prueba con el show diagnostic content location
comando.
El resultado de la prueba de ruta de datos del fabric de punt es similar a este ejemplo de resultado:
RP/0/RSP0/CPU0:ios(admin)#show diagnostic result location 0/rsp0/cpu0 test 10 detail
Current bootup diagnostic level for RP 0/RSP0/CPU0: minimal
Test results: (. = Pass, F = Fail, U = Untested)
___________________________________________________________________________
10 ) FabricLoopback ------------------> .
Error code ------------------> 0 (DIAG_SUCCESS)
Total run count -------------> 357
Last test execution time ----> Sat Jan 10 18:55:46 2009
First test failure time -----> n/a
Last test failure time ------> n/a
Last test pass time ---------> Sat Jan 10 18:55:46 2009
Total failure count ---------> 0
Consecutive failure count ---> 0
Mejoras en la recuperación automática
Como se describe en el Id. de bug Cisco CSCuc04493, ahora existe una manera de hacer que el router apague automáticamente todos los puertos que están asociados con los errores PUNT_FABRIC_DATA_PATH generados en RP/RSP activo.
El primer método se rastrea a través del identificador de bug Cisco CSCuc04493. Para la versión 4.2.3, esto se incluye en el ID de bug de Cisco CSCui33805. En esta versión, está configurado para apagar automáticamente todos los puertos que están asociados con los NP afectados.
Aquí hay un ejemplo que muestra cómo aparecerían los syslogs:
RP/0/RSP0/CPU0:Jun 10 16:11:26 BKK: pfm_node_rp[359]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System
Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/1/CPU0, 0)
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/1, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/1, changed state to Down
El controlador indica que la razón por la cual la interfaz está fuera de servicio es debido a DATA_PATH_DOWN. Aquí tiene un ejemplo:
RP/0/RSP0/CPU0:ASR9006-E#show controllers gigabitEthernet 0/0/0/13 internal
Wed Dec 18 02:42:52.221 UTC
Port Number : 13
Port Type : GE
Transport mode : LAN
BIA MAC addr : 6c9c.ed08.3cbd
Oper. MAC addr : 6c9c.ed08.3cbd
Egress MAC addr : 6c9c.ed08.3cbd
Port Available : true
Status polling is : enabled
Status events are : enabled
I/F Handle : 0x04000400
Cfg Link Enabled : tx/rx enabled
H/W Tx Enable : no
UDLF enabled : no
SFP PWR DN Reason : 0x00000000
SFP Capability : 0x00000024
MTU : 1538
H/W Speed : 1 Gbps
H/W Duplex : Full
H/W Loopback Type : None
H/W FlowCtrl type : None
H/W AutoNeg Enable: Off
H/W Link Defects : (0x00080000) DATA_PATH_DOWN <<<<<<<<<<<
Link Up : no
Link Led Status : Link down -- Red
Input good underflow : 0
Input ucast underflow : 0
Output ucast underflow : 0
Input unknown opcode underflow: 0
Pluggable Present : yes
Pluggable Type : 1000BASE-LX
Pluggable Compl. : (Service Un) - Compliant
Pluggable Type Supp.: (Service Un) - Supported
Pluggable PID Supp. : (Service Un) - Supported
Pluggable Scan Flg: false
En las versiones 4.3.1 y posteriores, este comportamiento debe estar habilitado. Hay un nuevo comando admin-config que se utiliza para lograr esto. Como el comportamiento predeterminado ya no es apagar los puertos, esto debe configurarse manualmente.
RP/0/RSP1/CPU0:ASR9010-A(admin-config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
En Cisco IOS XR de 64 bits, el comando de configuración está disponible en la máquina virtual XR (no en la máquina virtual Sysadmin):
RP/0/RSP0/CPU0:CORE-TOP(config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
El ID de bug de Cisco CSCui15435 se ocupa de los errores de software que se observan en las tarjetas de línea basadas en Trident, como se describe en la sección Impacto del Tráfico Debido a los Errores de Software Bridge/FPGA en las Tarjetas de Línea Basadas en Trident. Esto utiliza un método de detección diferente del método de diagnóstico habitual que se describe en el Id. de error de Cisco CSCuc04493.
Este error también introdujo un nuevo comando admin-config CLI:
(admin-config)#fabric fia soft-error-monitor <1|2> location
1 = shutdown the ports
2 = reload the linecard
Default behavior: no action is taken.
Cuando se encuentra este error, se puede observar este syslog:
RP/0/RSP0/CPU0:Apr 30 22:17:11.351 : config[65777]: %MGBL-SYS-5-CONFIG_I : Configured
from console by root
LC/0/2/CPU0:Apr 30 22:18:52.252 : pfm_node_lc[283]:
%PLATFORM-BRIDGE-1-SOFT_ERROR_ALERT_1 : Set|fialc[159814]|NPU
Crossbar Fabric Interface Bridge(0x1024000)|Soft Error Detected on Bridge instance 1
RP/0/RSP0/CPU0:Apr 30 22:21:28.747 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/2/CPU0, 2) (0/2/CPU0, 3)
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINK-3-UPDOWN :
Interface TenGigE0/2/0/2, changed state to Down
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINEPROTO-5-UPDOWN :
Line protocol on Interface TenGigE0/2/0/2, changed state to Down
RP/0/RSP1/CPU0:Apr 30 22:21:35.086 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED :
Set|online_diag_rsp[237646]|System Punt/Fabric/data Path Test(0x2000004)|failure
threshold is 3, (slot, NP) failed: (0/2/CPU0, 2) (0/2/CPU0, 3)
Cuando se cierran los puertos afectados, permite que la redundancia de red tome el control y evite un agujero negro del tráfico. Para recuperarse, la tarjeta de línea debe ser recargada.
Preguntas frecuentes
P. ¿La tarjeta de procesador de ruta primaria o en espera envía los paquetes de diagnóstico en línea o keepalives a cada NP del sistema?
R. Sí. Ambas tarjetas de procesador de ruta envían paquetes de diagnóstico en línea a cada NP.
P. ¿Es la misma ruta cuando la tarjeta de procesador de routing uno (RSP1) está activa?
A. La ruta de diagnóstico es la misma para RSP0 o RSP1. La trayectoria depende del estado del RSP. Consulte la sección Ruta de paquete de diagnóstico de Punt Fabric de este documento para obtener más detalles.
P. ¿Con qué frecuencia los RSP envían paquetes de diagnóstico y cuántos paquetes de diagnóstico deben perderse antes de que se active una alarma?
R. Cada RSP envía independientemente un paquete de diagnóstico a cada NP una vez por minuto. Cualquiera de los RSP puede activar una alarma si no se reconocen tres paquetes de diagnóstico.
P. ¿Cómo determina si un NP está o ha estado sobresuscrito?
R. Una manera de verificar si un NP está actualmente sobresuscrito o ha sido sobresuscrito en el pasado es verificar si hay un cierto tipo de caída dentro del NP y si hay caídas de cola en el FIA. Las caídas de Ingress Front Direct Memory Access (IFDMA) dentro del NP ocurren cuando el NP está sobresuscrito y no puede mantenerse al día con el tráfico entrante. Las caídas de cola FIA se producen cuando un NP de salida afirma el control de flujo (pide a la tarjeta de línea de entrada que envíe menos tráfico). En el escenario de control de flujo, el FIA de ingreso tiene caídas de cola.
P. ¿Cómo determina si un NP sufre una falla que requiere que se reinicie?
R. Típicamente, una falla NP se borra mediante un reinicio rápido. El motivo de un reinicio rápido se muestra en los registros.
P. ¿Es posible restablecer manualmente un NP?
A. Sí, de la tarjeta de línea KSH:
run attach 0/[x]/CPU0 #show_np -e [np#] -d fast_reset
P. ¿Qué se muestra si un NP tiene una falla de hardware no recuperable?
R. Se observa un error en la ruta de datos del fabric de punt para ese NP, así como un error en la prueba de loopback de NP. El mensaje de falla de la prueba de loopback NP se analiza en la sección Apéndice de este documento.
P. ¿Volverá a la misma un paquete de diagnóstico que se obtiene de una tarjeta de procesador de ruta?
R. Dado que los paquetes de diagnóstico se originan en ambas tarjetas de procesador de ruta y se siguen en base a una tarjeta de procesador de ruta, el NP vuelve a colocar un paquete de diagnóstico originado en una tarjeta de procesador de ruta a la misma tarjeta de procesador de ruta.
P. El ID de bug de Cisco CSCuj10837 SMU proporciona una solución para el evento de reentrenamiento del link de entramado. ¿Es esta la causa y la solución para muchos fallos de ruta de datos de fabric de punt?
R. Sí, es necesario cargar el SMU que reemplaza al Id. de error de Cisco CSCul39674 para evitar eventos de reciclaje de link de fabric.
P. ¿Cuánto tiempo se tarda en volver a entrenar los links de fabric una vez que se toma la decisión de hacerlo?
R. La decisión de volver a entrenar se toma tan pronto como se detecta una falla de link. Antes de la versión 4.3.2, el reentrenamiento podría tardar varios segundos. Después de la versión 4.3.2, el tiempo de reentrenamiento se ha mejorado significativamente y tarda menos de un segundo.
P. ¿En qué momento se toma la decisión de volver a entrenar un enlace de fabric?
R. Tan pronto como se detecta la falla de link, la decisión de volver a entrenar la toma el controlador ASIC de fabric.
P. ¿Es sólo entre el FIA en una tarjeta de procesador de ruta activa y el entramado que utiliza el primer link, y luego es el link menos cargado cuando hay varios links disponibles?
A. Correcto. El primer link que se conecta a la primera instancia XBAR en el procesador de ruta activo se utiliza para inyectar tráfico en el entramado. El paquete de respuesta de la NP puede llegar de nuevo a la tarjeta de procesador de ruta activa en cualquiera de los links que se conectan a la tarjeta de procesador de ruta. La elección del link depende de la carga del link.
P. Durante el reentrenamiento, ¿se pierden todos los paquetes que se envían a través de ese link de entramado?
R. Sí, pero con las mejoras de la versión 4.3.2 y posteriores, el reentrenamiento es prácticamente indetectable. Sin embargo, en el código anterior, podía tomar varios segundos volver a entrenar, lo que resultaba en paquetes perdidos para ese marco de tiempo.
P. ¿Con qué frecuencia espera ver un evento de reciclaje de link de fabric XBAR después de actualizar a una versión o SMU con la corrección para el ID de bug de Cisco CSCuj10837?
R. Incluso con la corrección para el ID de bug de Cisco CSCuj10837, todavía es posible ver reentrenamientos de link de entramado debido al ID de bug de Cisco CSCul39674. Pero una vez que tenga la solución para el ID de bug de Cisco CSCul39674, el reentrenamiento de link de entramado en los links de backplane de entramado entre el RSP440 y las tarjetas de línea basadas en Typhoon nunca deberían ocurrir. Si es así, envíe una solicitud de servicio al centro de asistencia técnica Cisco Technical Assistance Center (TAC) para solucionar el problema.
P. ¿El ID de bug de Cisco CSCuj10837 y el ID de bug de Cisco CSCul39674 afectan el RP en el ASR 9922 con tarjetas de línea basadas en Typhoon?
A. Sí
P. ¿El ID de bug de Cisco CSCuj10837 y el ID de bug de Cisco CSCul39674 afectan a los routers ASR-9001 y ASR-9001-S?
A. No
P. Si detecta un error en una ranura que no existe con este mensaje, "PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[237686]|Prueba de ruta de datos/fabric/sistema(0x2000004)|el umbral de error es 3, (slot, NP) failed: (8, 0)", en un chasis de 10 ranuras, ¿qué ranura tiene el problema?
R. En las versiones anteriores, debe tener en cuenta las asignaciones físicas y lógicas como se muestra aquí. En este ejemplo, el slot 8 corresponde a 0/6/CPU0.
For 9010 (10 slot chassis)
L P
#0 --- #0
#1 --- #1
#2 --- #2
#3 --- #3
RSP0 --- #4
RSP1 --- #5
#4 --- #6
#5 --- #7
#6 --- #8
#7 --- #9
For 9006 (6 slot chassis)
L P
RSP0 --- #0
RSP1 --- #1
#0 --- #2
#1 --- #3
#2 --- #4
#3 --- #5
Datos que se deben recopilar antes de crear la solicitud de servicio
Estos son los comandos mínimos para recopilar resultados antes de realizar cualquier acción:
show loggingshow pfm location alladmin show diagn result loc 0/rsp0/cpu0 test 8 detailadmin show diagn result loc 0/rsp1/cpu0 test 8 detailadmin show diagn result loc 0/rsp0/cpu0 test 9 detailadmin show diagn result loc 0/rsp1/cpu0 test 9 detailadmin show diagn result loc 0/rsp0/cpu0 test 10 detailadmin show diagn result loc 0/rsp1/cpu0 test 10 detailadmin show diagn result loc 0/rsp0/cpu0 test 11 detailadmin show diagn result loc 0/rsp1/cpu0 test 11 detailshow controller fabric fia link-status locationshow controller fabric fia link-status locationshow controller fabric fia bridge sync-status locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 1 locationshow controller fabric ltrace crossbar locationshow controller fabric ltrace crossbar locationshow tech fabric locationshow tech fabric locationfile
Comandos de diagnóstico útiles
Esta es una lista de comandos que son útiles para fines de diagnóstico:
show diagnostic ondemand settingsshow diagnostic content location < loc >show diagnostic result location < loc > [ test {id|id_list|all} ] [ detail ]show diagnostic statusadmin diagnostic start location < loc > test {id|id_list|test-suite}admin diagnostic stop location < loc >- admin diagnostic ondemand iterations < iteration-count >
admin diagnostic ondemand action-on-failure {continue failure-count|stop}- admin-config#
[ no ] diagnostic monitor location < loc > test {id | test-name} [disable] - admin-config#
[ no ] diagnostic monitor interval location < loc > test {id | test-name} day hour:minute:second.millisec - admin-config#
[ no ] diagnostic monitor threshold location < loc > test {id | test-name} failure count
Conclusión
A partir del intervalo de tiempo de la versión 4.3.4 del software Cisco IOS XR, se solucionan la mayoría de los problemas relacionados con las fallas de la trayectoria de datos del fabric de punt. Para los routers afectados por el ID de bug de Cisco CSCuj10837 y el ID de bug de Cisco CSCul39674, cargue el SMU de reemplazo para el ID de bug de Cisco CSCul39674 para evitar los eventos de reentrenamiento de link de entramado.
El equipo de la plataforma ha instalado una gestión de fallos de última generación para que el router se recupere en subsegundos en caso de que se produzca algún error recuperable de la ruta de datos. Sin embargo, se recomienda este documento para entender este problema, incluso si no se observa tal falla.
Appendix
Ruta de diagnóstico de loopback NP
La aplicación de diagnóstico que se ejecuta en la CPU de la tarjeta de línea realiza un seguimiento del estado de cada NP con comprobaciones periódicas del estado de funcionamiento del NP. Se inyecta un paquete desde la CPU de la tarjeta de línea destinada a la NP local, que la NP debe retroceder en bucle y volver a la CPU de la tarjeta de línea. Cualquier pérdida en estos paquetes periódicos se marca con un mensaje de registro de la plataforma. Aquí hay un ejemplo de un mensaje de este tipo:
LC/0/7/CPU0:Aug 18 19:17:26.924 : pfm_node[182]:
%PLATFORM-PFM_DIAGS-2-LC_NP_LOOPBACK_FAILED : Set|online_diag_lc[94283]|
Line card NP loopback Test(0x2000006)|link failure mask is 0x8
Este mensaje de registro significa que esta prueba no pudo recibir el paquete de loopback de NP3. La máscara de falla de link es 0x8 (el bit 3 está configurado), lo que indica una falla entre la CPU de la tarjeta de línea para la ranura 7 y NP3 en la ranura 7.
Para obtener más detalles, recopile el resultado de estos comandos:
admin show diagnostic result location 0//cpu0 test 9 detail show controllers NP counter NP<0-3> location 0//cpu0
Comandos de depuración de fabric
Los comandos enumerados en esta sección se aplican a todas las tarjetas de línea basadas en Trident, así como a la tarjeta de línea de 100 GE basada en Typhoon. El Bridge FPGA ASIC no está presente en las tarjetas de línea basadas en Typhoon (excepto en las tarjetas de línea basadas en Typhoon de 100 GE). Por lo tanto, show controller fabric fia bridge Los comandos no se aplican a las tarjetas de línea basadas en Typhoon, excepto para las versiones 100GE.
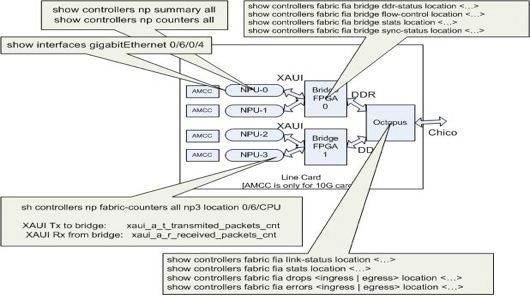
Esta representación gráfica ayuda a asignar cada comando show a la ubicación en la ruta de datos. Utilice estos comandos show para aislar las caídas de paquetes y los fallos.
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
2.0 |
26-Jun-2023 |
Se actualizó la sección Mejoras en la recuperación automática para el ID de bug de Cisco CSCuc04493 y se actualizó la sección Preguntas frecuentes. |
1.0 |
29-Oct-2013 |
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Mahesh ShirshyadCisco TAC Engineer
- David PowersCisco TAC Engineer
- Jean-Christophe RodeCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)