Introducción
Este documento describe los pasos de troubleshooting para manejar los errores de memoria en los servidores UCS.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas.
- Conocimientos básicos de UCS.
- Comprensión básica de la arquitectura de memoria.
Componentes Utilizados
La información que contiene este documento se basa en las siguientes versiones de software y hardware.
- Servidores de la familia UCS M5, M6, M7 y superiores.
- UCS Manager
- Cisco Integrated Management Controller (CIMC)
- Modo gestionado de Cisco Intersight (IMM)
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
Errores de memoria
Se encuentran errores de memoria cuando se intenta leer una ubicación de memoria. El valor leído de la memoria no coincide con el valor que se supone que está allí. Estos errores se clasifican en dos tipos:
1. Errores de software
Los errores de software son transitorios y no se repiten. Estos son temporales y a menudo se pueden corregir reintentando la lectura o reescribiendo la ubicación de la memoria.
2. Errores graves
Los defectos físicos permanentes causan esto. La reescritura de la ubicación de la memoria y el reintento del acceso de lectura no eliminan un error de hardware. Como resultado, este error de memoria es incorregible y la memoria necesita ser reemplazada ya que el error continúa repitiéndose.
Errores corregibles
Si se detectan y corrigen errores, se consideran corregibles. Esto se puede lograr reintentando la lectura o calculando el contenido correcto de la memoria utilizando los datos del Código de corrección de errores (ECC) y escribiendo los datos adecuados de nuevo en la memoria. Después de que se detecte y corrija un error, Cisco Integrated Management Controller (IMC) registra el evento en el registro de eventos del sistema.
Normalmente, los errores corregibles son el resultado de errores de software. Si los errores corregibles persisten en la misma ubicación de memoria durante un período prolongado, podría indicar un posible error grave.
Corrección de datos adaptable de doble dispositivo (ADDC)
ADDDC Sparing puede corregir dos fallas DRAM sucesivas si residen en la misma región. ADDC mueve dinámicamente los datos de los bits fallidos a la memoria de reserva, evitando que los errores corregibles se vuelvan incorregibles. Se requiere un umbral de errores ECC corregibles para activar el mecanismo.
ADDDC ayuda en algunos escenarios donde los errores ECC corregibles preceden a los errores ECC incorregibles.
Reparación posterior al paquete (PPR)
Post Package Repair (PPR) puede reparar permanentemente las regiones de memoria defectuosa dentro de un DIMM aprovechando las filas de DRAM redundantes. Esta reparación permanente in situ permite una rápida recuperación de errores de hardware sin necesidad de reemplazar el módulo DIMM. Para realizar una reparación, el sistema debe experimentar un evento ADDC y pasar al menos por un ciclo de reinicio. Esta actividad de reparación no afecta al rendimiento ni a la memoria total disponible para el SO.
PPR y ADDDC están habilitados de forma predeterminada; sin embargo, pueden configurarse. PPR también requiere que se habilite el modo ADDC Sparing RAS. Si la configuración de RAS es distinta de ADDC Sparing o Platform Default, PPR no está operativo. El único modo PPR admitido es PPR duro, lo que significa que las reparaciones son permanentes.
Repuesto de línea de caché parcial (PCLS)
Hay un mecanismo de prevención de errores en el controlador de memoria. Funciona identificando pequeñas porciones defectuosas de datos en la memoria. Estas ubicaciones defectuosas se registran en un directorio especial, junto con datos de copia de seguridad que pueden reemplazarlas. Cuando se accede a la memoria, si hay un error en esos puntos defectuosos, el controlador utiliza los datos de respaldo del directorio para asegurarse de que todo funciona sin problemas.
Nota: Las funciones están disponibles en función de la arquitectura de la CPU y de la versión del firmware que se ejecute en el servidor. Asegúrese de que está en la última versión recomendada para manejar mejor los errores de memoria.
Troubleshooting de Fallas RAS
UCS Manager
Por lo general, estos fallos se ven en UCS Manager como un evento RAS.
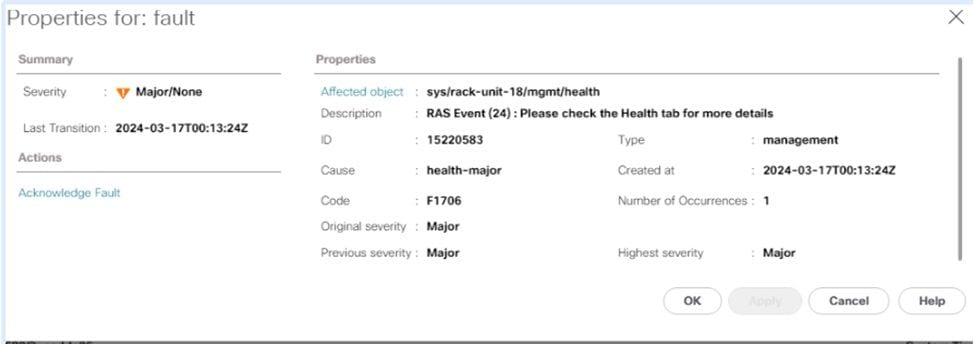
En el resumen de estado, puede encontrar más información sobre el error, si se activó PCLS o PPR.
ejemplo de PCLS
En los servidores M6 y en los más recientes, tiene la opción de habilitar la reserva de línea de caché parcial (PCLS) como opción del BIOS, que es un mecanismo de prevención de errores. El servidor debe reiniciarse tan pronto como sea posible, de modo que PPR pueda iniciar y reparar el DIMM. Una vez reiniciado el servidor, supervise si hay fallos adicionales de UCS Manager para el mismo DIMM.
Como menciona la alerta, se recomienda reiniciar el servidor lo antes posible, ya que existe el riesgo asociado de experimentar un error incorregible y, en consecuencia, un tiempo de inactividad inesperado del servidor.
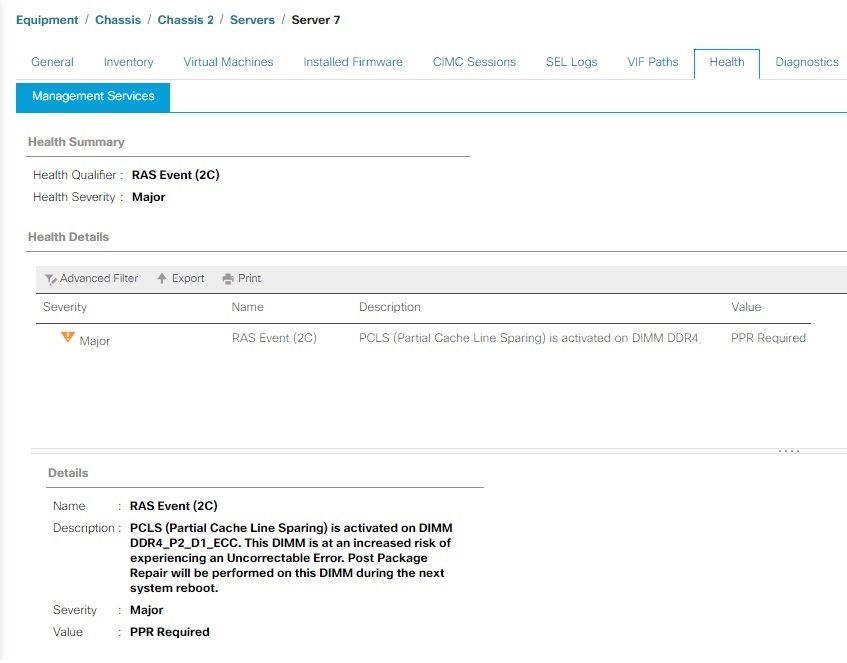
ejemplo de PPR
El servidor tiene ADDC y PPR habilitados, y se produjo un evento RAS. La falla sugiere que se reinicie PPR para reparar el DIMM. El servidor debe reiniciarse lo antes posible para que PPR inicie y repare el DIMM.
Una vez reiniciado el servidor, supervise si hay fallos adicionales de UCS Manager para el mismo DIMM.
Como menciona la alerta, se recomienda reiniciar el servidor lo antes posible, ya que existe el riesgo asociado de experimentar un error incorregible y, en consecuencia, un tiempo de inactividad inesperado del servidor.
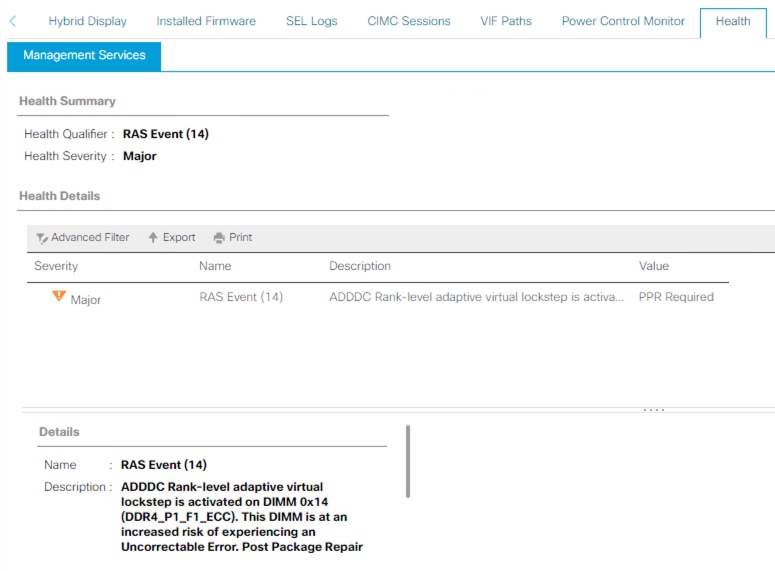
Modo gestionado de intercambio
El servidor tiene ADDC habilitado y se ha producido un evento BANK VLS, lo que crea el error que se ve. En este escenario, el siguiente paso es realizar un reinicio del servidor lo antes posible para permitir que se ejecute PPR.

Cisco Integrated Management Controller (CIMC)
El fallo aparece como se muestra cuando se utiliza Cisco Integrated Management Controller. Si el servidor tiene ADDDC y se ha producido un evento VLS, esto funciona de la forma diseñada para evitar errores incorregibles.
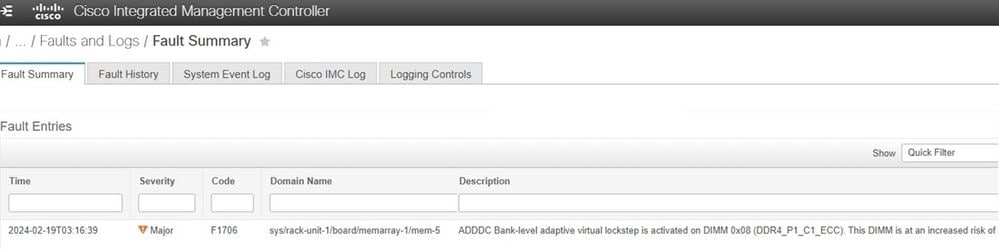
Pasos para la resolución de problemas
- Verifique que no haya otros fallos de DIMM presentes, por ejemplo, y que no haya errores incorregibles.
- Programe una ventana de mantenimiento.
- Coloque un host en modo de mantenimiento y reinicie el servidor para intentar la reparación permanente del DIMM mediante Post Package Repair (PPR).
Pasos del reinicio de UCSM
Nota: También puede reiniciar el servidor desde el sistema operativo. En este ejemplo se utiliza la opción de reinicio de la interfaz de usuario del servidor.
Vaya a la interfaz web de UCS Manager.
Servidor blade
Vaya a Equipo > Chasis > Servidor X.
Servidor integrado
Vaya a Equipo > Montajes en rack > Servidor X.
Haga clic en Consola KVM.
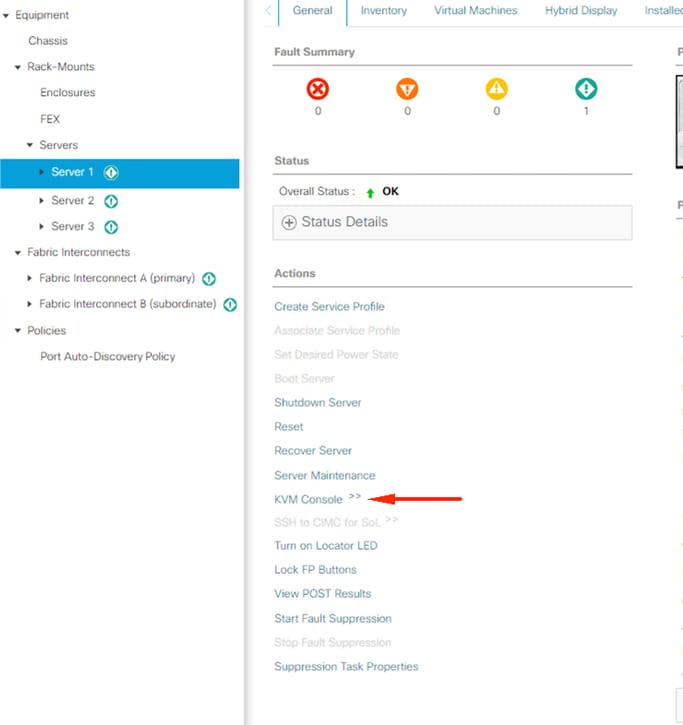
en las ventanas KVM, haga clic en acciones del servidor, seleccione Restablecer y haga clic en Aceptar.
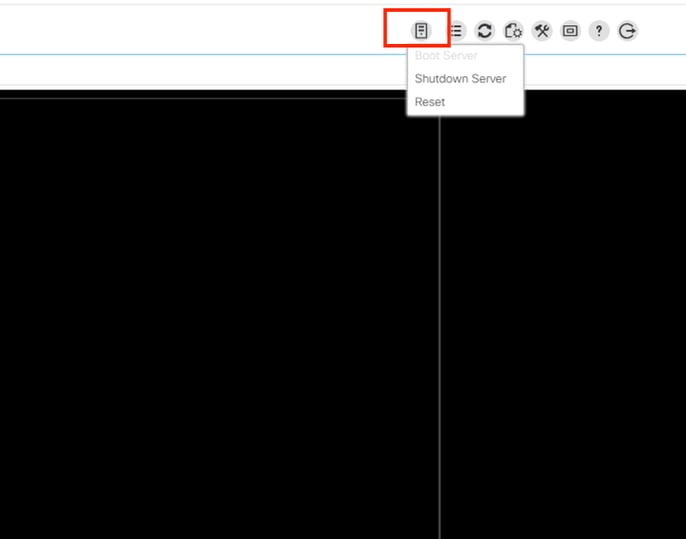
Supervise en el KVM el proceso de reinicio y asegúrese de que el sistema operativo se inicie correctamente.
Pasos de reinicio de IMM
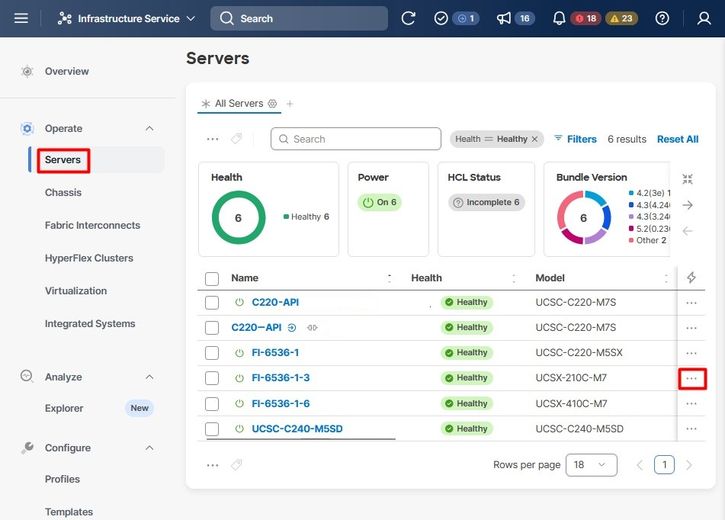
Vaya a la pestaña Servers, identifique el servidor y haga clic en el menú Action (tres puntos).
A continuación, seleccione el menú Power y luego la opción Power Cycle.
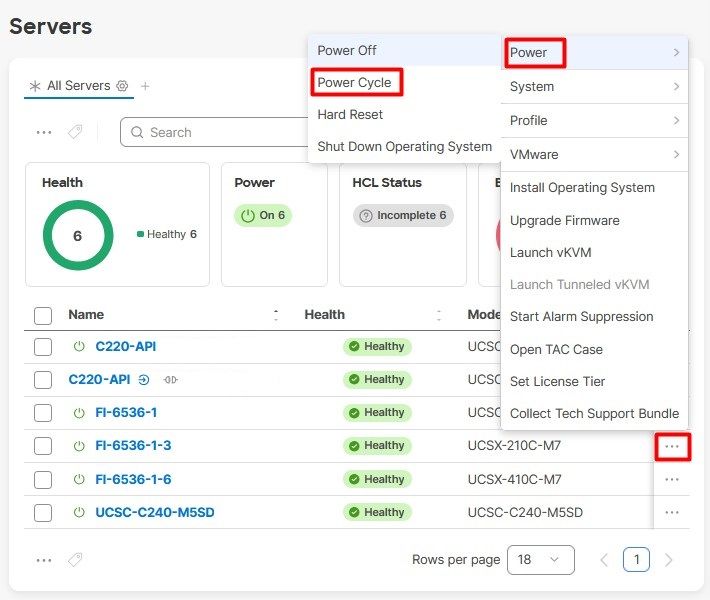
Haga clic en el botón Power Cycle para confirmar la acción.
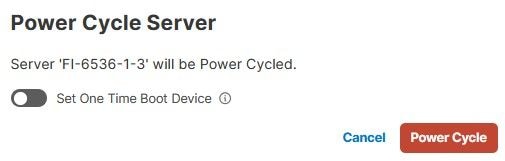
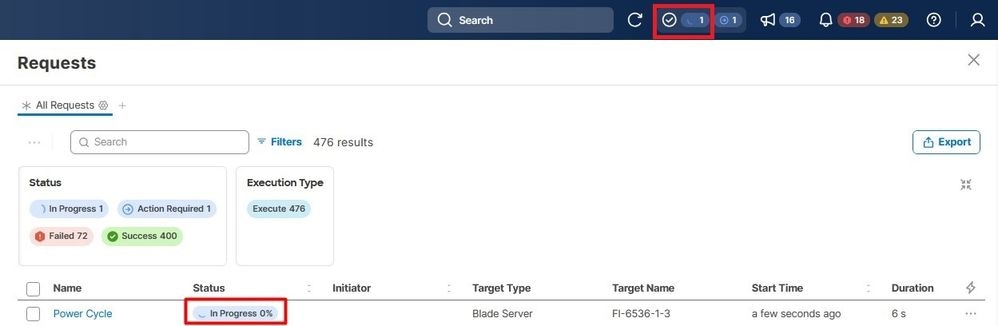
Valide el progreso en el menú Solicitudes.
Pasos de reinicio de CIMC
Navegue hasta la opción Host Power y seleccione Power Cycle.
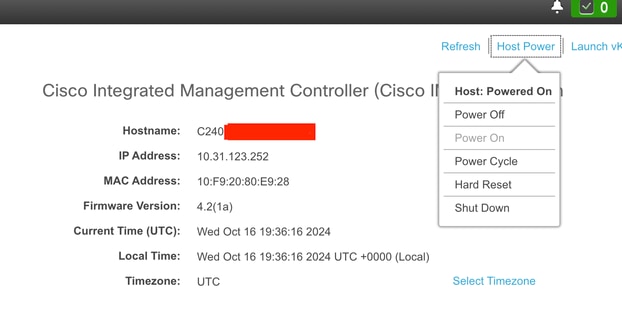
Inicie el KVM para supervisar el proceso de reinicio y asegúrese de que el sistema operativo se inicie correctamente.
Supervisar para detectar nuevos fallos
Si no se produce ningún error después del reinicio, lo que significa que no hay ningún otro evento RAS o fallo relacionado con el DIMM, el PPR se realizó correctamente y el servidor se puede volver a utilizar.
Si se producen nuevos eventos ADDC, repita el proceso de reinicio descrito en los pasos anteriores para realizar reparaciones permanentes adicionales con PPR.
Si se produce un error incorregible o un error inoperable después del reinicio, el error indica que es necesario reemplazar una memoria.
Nota: Abra un caso con Cisco TAC para reemplazar el DIMM si encuentra alguno de estos fallos.
Error de memoria incorregible de UCS Manager
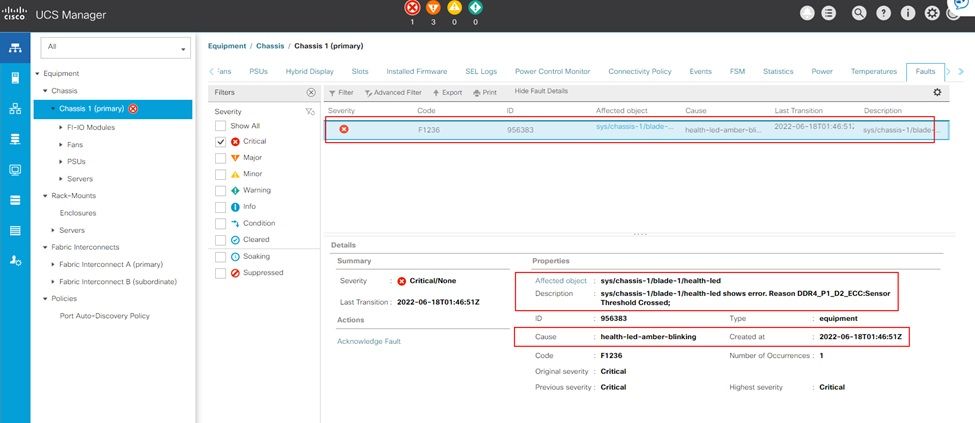
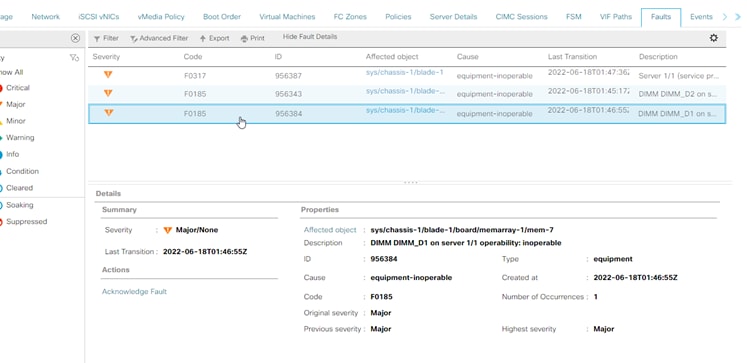
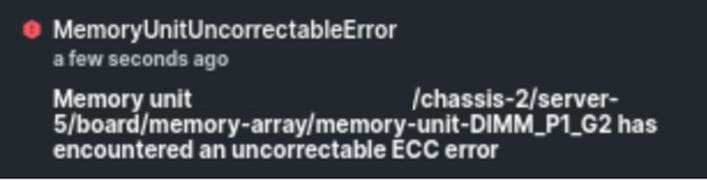
Error incorregible de memoria IMM
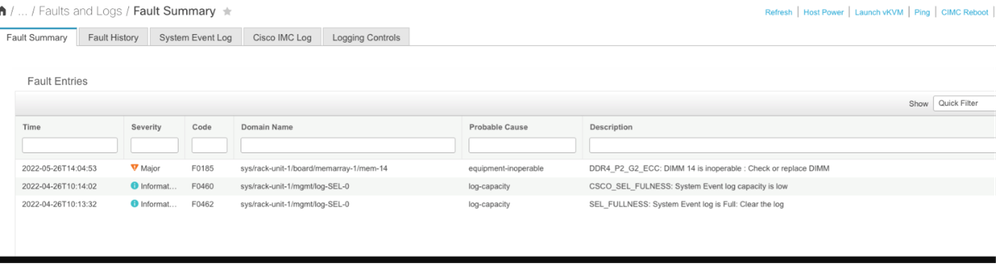
Error incorregible. La falla indica que el DIMM tiene un error incorregible y necesita ser reemplazado.
Error de memoria incorregible de CIMC
Información Relacionada
 Comentarios
Comentarios