Introducción
Este documento describe cómo resolver problemas comunes de los fallos de servidor inaccesible que pueden observarse en la mayoría de los tipos de servidores UCS.
Prerequisites
Requirements
Cisco recomienda que tenga conocimientos sobre la gestión de servidores en Unified Computing System Manager (UCSM) y en el modo gestionado de información (IMM).
Componentes Utilizados
Este documento no tiene restricciones específicas en cuanto a versiones de software y de hardware.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
Existe un error común que los usuarios pueden recibir en su dominio UCS y que consiste en notificarle que no se puede acceder a un servidor. Esto puede deberse a una serie de razones y el fallo puede verse de varias maneras, según las herramientas de supervisión y las versiones de UCSM/IMM.
System Notification from [UCSM Domain Name] - diagnostic:GOLD-minor - 2023-05-25 01:56:41 GMT-04:00 Recovered : Server x/y (service profile: org-root/ls-[service_profile]) inaccessible
Serial number: [Server Serial]
Alert: System Name: [UCSM Domain Name]
Time of Event:2022-08-31 03:15:04 GMT-05:00 Event Description:Server x (service profile: org-root/ls-[service_profile]) inaccessible Severity Level:4
Si IMM está en uso, es posible que se vea un mensaje Connection to Server was lost en la GUI. También se puede observar la desconexión de los fallos de Intersight.
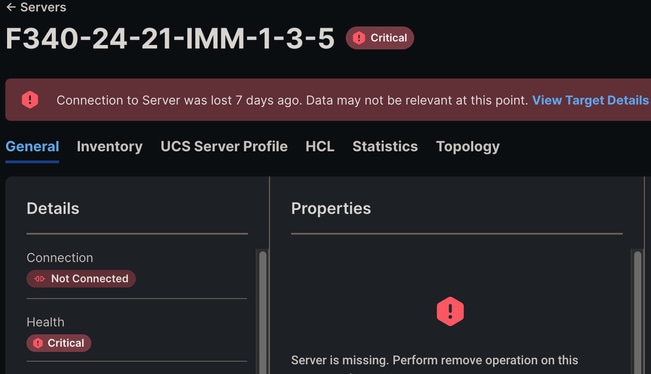 Se perdió la conexión con el servidor IMM
Se perdió la conexión con el servidor IMM
Esta alerta se puede ver cuando el Cisco Integrated Management Controller (CIMC) de un servidor blade encuentra un problema y se reinicia o intenta reiniciarse. Esto activa una alerta de servidor inaccesible porque mientras el plano de administración del blade se está reiniciando, UCSM/IMM no puede comunicarse con el blade y, por lo tanto, cree que es inaccesible. Una vez que CIMC se reinicia, el estado de los servidores blade vuelve a la normalidad.
Es por esto que puede recibir esta alerta, entonces cuando usted verifica el dominio, el servidor busca y saludable.
Referencia de defecto común
ID de error de Cisco CSCwe19822: se aplica a los servidores M5/M6 después de 4.2(2c)/después de 5.0(1c) para la serie X
ID de error de Cisco CSCwa8567: se aplica a servidores M5/M6 entre 4.1(3e) - 4.2(2a) También incluye la serie X después de 5.0(1b)
Cisco bug ID CSCvz62711 - Se aplica a servidores M5/M6 entre 4.1(3d) - 4.2(2a)
ID de error de Cisco CSCwi50991: se aplica a los blades serie M5/M6 en el código anterior a la versión 4.3(2e)
Cisco bug ID CSCvv79912 - Se aplica a servidores M5/M6 entre 4.0(4h) y 4.2(1a)/4.1(3d)
Cisco bug ID CSCvh25786 - Se aplica a los servidores M4/M5 después de 2.0(13f) y 3.0(4a)
Resolución de problemas
Escenario 1
La primera situación, y la más común, es recibir la alerta y, a continuación, cuando se comprueba UCSM/IMM, el servidor aparece operativo, en buen estado y sin errores (nuevos). Al comprobar el sistema operativo, parece que se ha puesto en marcha sin interrupciones.
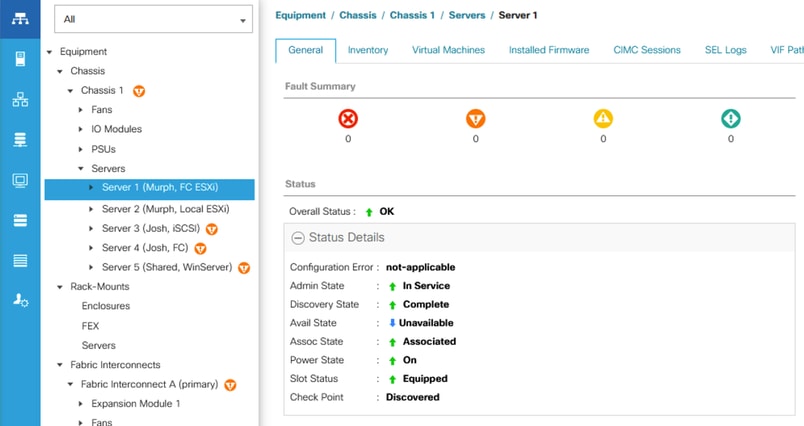 Servidor saludable en UCSM
Servidor saludable en UCSM
Los paquetes de registro muestran este mensaje en uno de los registros de OBFL que se pueden encontrar en CIMCx_TechSupport.tar.gz > obfl > obfl-log.
3:2022 Sep 8 10:54:33 UTC:+0000:(4.2(2d)):kernel:-:[watchdog_init]:976:BMC Watchdog resetted BMC.
Esto nos dice que el CIMC se estrelló y reinició por sí solo.
En este escenario, no se requiere ninguna acción adicional ya que CIMC se reinició correctamente y no hay problemas con el servidor.
Escenario 2
La siguiente situación es recibir la alerta y, al comprobar UCSM/IMM, el servidor sigue mostrándose como inaccesible si se usa UCSM o desconectado si se usa IMM. Al comprobar el sistema operativo, parece que está activo y en ejecución sin interrupciones.
Dado que el SO está en funcionamiento, pero UCSM/IMM no puede comunicarse con el blade, esto significa que CIMC no se ha reiniciado o se ha detenido en el proceso.
El primer paso en este escenario es conectar SSH o la consola a las Fabric Interconnects (FI) y ejecutar este comando reemplazando x/y con el chasis/blade afectado. Hay tres resultados diferentes.
1) La conexión a CIMC se ha realizado correctamente.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
Trying 127.5.1.1...
Connected to 127.5.1.1.
Escape character is '^]'.
CIMC Debug Firmware Utility Shell [ support ]
[ help ]#
Si se ve este resultado, entonces todavía hay algo de vida en CIMC y puede intentar restablecer CIMC para recuperar el blade.
Si UCSM está en uso, navegue hasta Equipo > Chasis > Número de chasis > Servidores > Número de servidor > Recuperar servidor > Restablecer CIMC.
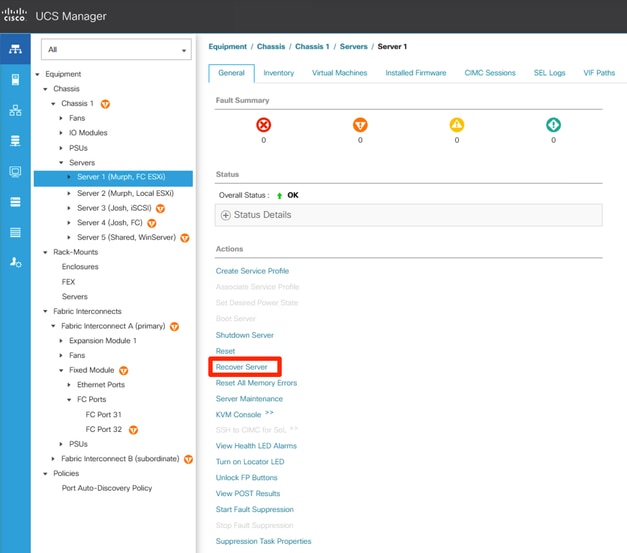 Ubicación del servidor de recuperación para el blade
Ubicación del servidor de recuperación para el blade
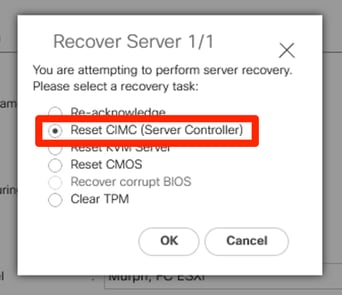 Restablecer CIMC
Restablecer CIMC
Si IMM está en uso, navegue hasta el servidor afectado y seleccione Actions > System > Reboot Management Controller.
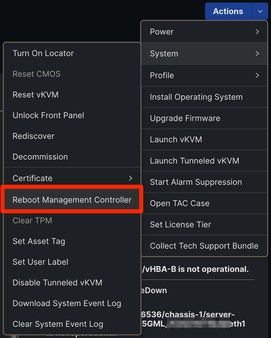 Reiniciar controlador de administración IMM
Reiniciar controlador de administración IMM
Si después de reiniciar CIMC el servidor vuelve a la normalidad, el problema se resuelve y no se requiere ninguna otra acción.
Si el fallo persiste, continúe con los pasos de troubleshooting de la siguiente salida connect cimc.
2) La conexión a CIMC falla.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
Trying 127.5.1.8...
telnet: Unable to connect to remote host: No route to host
3) Conexión a los puestos del CIMC. En este caso, no sucede nada después de ejecutar el comando y al intentar escapar (Ctrl + C) se observa esto.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
^C
Console escape. Commands are:
l go to line mode
c go to command mode
z suspend telnet
e exit telent
continuing...
La resolución de problemas para cualquiera de las dos últimas salidas es la misma. En estos casos, CIMC está completamente fuera de servicio y no puede comunicarse con las Fabric Interconnects. Es necesario reiniciar el servidor para recuperar CIMC. Siempre se recomienda tomar una ventana de mantenimiento al reiniciar los servidores blade.
Si UCSM está en uso, puede simular volver a colocar físicamente el blade mediante SSH en las Fabric Interconnects y ejecutar este comando reemplazando x/y por el chasis/servidor afectado. Es imprescindible que introduzca el chasis/servidor correcto, ya que este comando no le solicita confirmación.
UCSM-A# reset slot x/y

Nota: El comando reset slot reinicia el blade en la ranura designada x/y inmediatamente. Asegúrese de que el servidor se puede reiniciar de forma segura si el sistema operativo aún se está ejecutando.
Este comando no devuelve nada si es exitoso. Si el comando no se pudo ejecutar, se muestra un mensaje.
Si IMM está en uso, o el comando reset slot no resolvió el problema inaccesible, entonces la única otra opción es reinicializar físicamente el blade.
Si después de volver a colocar físicamente el blade, el problema continúa, póngase en contacto con el TAC para obtener más información sobre la solución de problemas.
Escenario 3
La situación final es la recepción de la alerta, entonces cuando la verificación de UCSM/IMM el servidor todavía se muestra como inaccesible si se utiliza UCSM o desconectado si se utiliza IMM. Al comprobar el sistema operativo, que está fuera de servicio y también inaccesible.
En esta situación, todo lo que se puede hacer es reiniciar el servidor. Si no es posible reiniciar, vuelva a colocar físicamente el servidor.
Si después de volver a colocar físicamente el blade, el problema continúa, póngase en contacto con el TAC para obtener más información sobre la solución de problemas.
Conclusión
Puede haber muchas razones para recibir fallos de servidor inaccesible, algunas más impactantes que otras. Estos pasos son un buen punto de partida para evaluar si se requiere alguna solución de problemas o si su dominio está en buen estado y no es necesario realizar ninguna acción.
 Comentarios
Comentarios