Comprensión y solución de problemas de tiempo de espera Astro/Lemans/NiceR en los routers Catalyst de la serie 4000/4500
Contenido
Introducción
El switch series Catalyst 4000/4500 usa un diseño ASIC stub en la arquitectura del switch. El switch administra estos ASIC stub de tarjeta de línea (Astro/Leman/NiceR) a través del protocolo de control de administración interna. Cuando estas solicitudes y respuestas de administración interna se pierden o retrasan, se generan los mensajes de consola y syslog. Debido a que los motivos de estas pérdidas varían, la causa raíz no es obvia con estos mensajes de error.
El fin de este documento es contribuir a la comprensión del mensaje Astro/Leman/Nicer Timeout que se genera en la plataforma Cat4000 y resolverlos con la asistencia del TAC de Cisco. Las versiones futuras de CatOS y Cisco IOS® ofrecerán mensajes de error mejorados y, si es posible, identificarán la causa raíz del problema.
Cuando se produce un tiempo de espera ASIC stub (Astro/Lemans/Nicer), se informan mensajes similares a los siguientes en un switch Catalyst 4000/4500 basado en CatOS:
%SYS-4-P2_WARN: 1/Astro(4/3) - timeout occurred %SYS-4-P2_WARN: 1/Astro(4/3) - timeout is persisting
Por favor tenga en cuenta que dependiendo de la versión de software, puede variar el texto del mensaje de error. Astro, Lemans y Nicer son referencias a diferentes tipos de Stub ASIC. En la sección Teoría precedente de este documento se brindan más detalles.
Para los Supervisor basados en el IOS de Cisco (Supervisor II+, III y IV), el mensaje de error aparece de la siguiente manera:
%C4K_LINECARDMGMTPROTOCOL-4-INITIALTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - management request timed out. %C4K_LINECARDMGMTPROTOCOL-4-ONGOINGTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - consecutive management requests timed out.
Nota: Este documento aborda principalmente la resolución de problemas en los supervisores o switches basados en CatOS. Parte de la información se aplica al Supervisor basado en Cisco IOS cuando se indica.
Nota: Este documento también aborda el ASIC Stub Astro, pero la mayoría de las secciones son aplicables a otro tipo de tarjetas de línea ASIC stub (Lemans and Nicer) y como tales se mencionarán en las secciones correspondientes.
Luego de leer este documento, el lector comprenderá lo siguiente:
-
La función de los ASIC stub en los Catalyst 4000/4500.
-
Condiciones que pueden generar mensajes por tiempo de espera de paquetes de administración interna.
-
Los pasos que se deben seguir y los comandos que se deben reunir para el TAC de Cisco al resolver esta condición.
Las secciones de tiempo de espera y de resolución de errores de Astro proporcionan explicaciones generales y detalladas sobre cada problema. Por otro lado, puede consultar directamente la sección Formas sencillas de resolver problemas en este documento.
Antes de comenzar
Convenciones
Para obtener más información sobre las convenciones del documento, consulte Convenciones de Consejos Técnicos de Cisco.
Prerequisites
No hay requisitos previos específicos para este documento.
Componentes Utilizados
Este documento es específico de Catalyst 4000/4500 Supervisor o tarjetas de línea que utilizan ASIC stub.
Teoría Precedente
ASIC Stub Astro hace referencia al ASIC Stub 10/100 que controla un grupo de ocho puertos 10/100 adyacentes que comunican al Supervisor a través de una conexión de ancho de banda Gigabit a la placa de interconexiones, como se muestra en la figura a continuación.
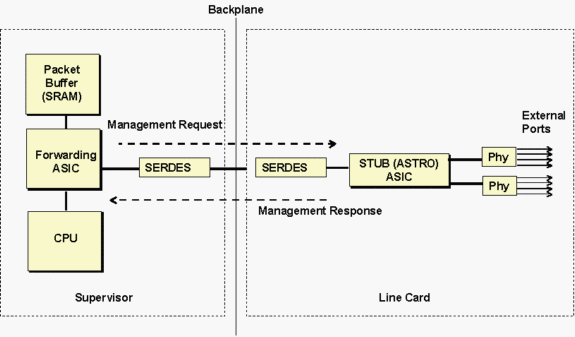
Los Supervisores se comunican con el ASIC Stub de la tarjeta de línea mediante el componente SERDES (SERealizer-DESerializer). Hay un componente SERDES en el lado del Supervisor que conecta a la placa de interconexiones y otro SERDES en la tarjeta de línea por cada ASIC de stub para la conexión a la placa de interconexiones.
El diagrama anterior se puede utilizar en general para resolver problemas de diferentes tipos de tarjetas de línea. El ASIC stub mencionado en los mensajes de tiempo de espera sería diferente según el tipo de tarjeta de línea. Consulte la tabla siguiente para ver una lista de nombres ASIC y su descripción.
| ASIC stub | Descripción | Ejemplo: |
|---|---|---|
| Astro | ASIC stub de controlador 10/100 de 8 puertos | WS-X4148-RJ45V |
| NiceR | ASIC stub de controlador 1000 de 4 puertos | WS-X4418-GB(puertos 3-18) |
| Lemans | ASIC stub de controlador 10/100/1000 de 8 puertos | WS-X4448-GB-RJ |
El tráfico de administración interna fluye a través del componente SERDES junto con el tráfico de datos normal. El tráfico de administración interna se utiliza para leer/escribir los registros stub ASIC y Phy. Las operaciones más comunes incluyen la lectura del estado y estadísticas de los links.
Maneras sencillas de resolución de problemas
En las secciones siguientes se explica el significado y las posibles causas de %SYS-4-P2_WARN: 1/(Stub)(module_number/) Stub_reference - Se produjo un mensaje de error de tiempo de espera en el Catalyst 4000/4500.
Los mensajes de tiempo de espera Astro (stub) se agregaron a partir de las versiones de software 6.2.3 y 6.3.1 y posteriormente se mejoraron en 6.4.4 (CSCea73908) para indicar que Supervisor perdió paquetes de control de administración interna en la comunicación con el ASIC stub Astro en las tarjetas de líneas de 10/100. Hay varios motivos para esta pérdida de comunicación, como se explica en detalle en la sección Resolución de problemas, a continuación.
El siguiente diagrama de flujo de resolución de problemas presenta una manera rápida y fácil de aislar el problema entre las posibles causas de raíz:
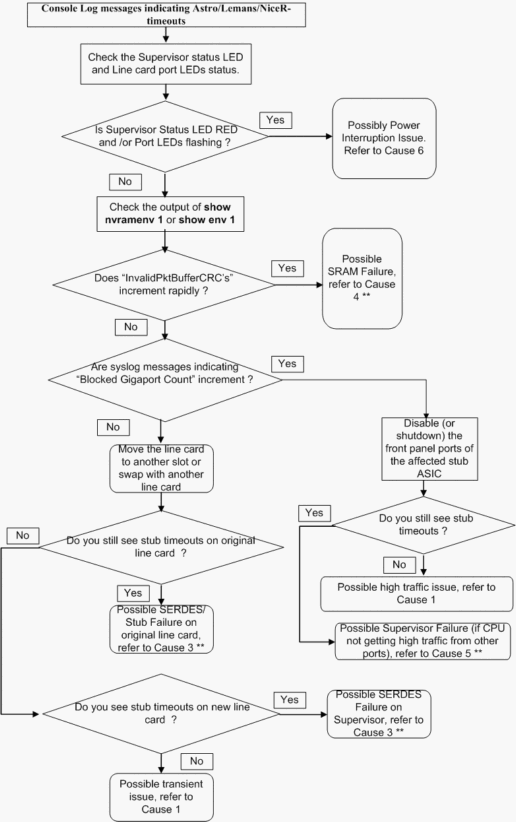
** Diversas causas profundas pueden presentar síntomas similares. Póngase en contacto con el TAC para obtener más información sobre la solución de problemas.
Tiempos de espera ASIC (Astro/Lemans/NiceR) fragmentados
Los tiempos de espera Astro/Lemans/Nicer se notifican cuando el software Supervisor no recibe múltiples respuestas de administración interna del ASIC stub de tarjeta de línea. Esto puede ocurrir si:
-
Se ha perdido o retrasado la petición de administración
-
Se ha perdido o retrasado la respuesta de administración
Se imprime un mensaje de "tiempo de espera agotado.." una vez que el software ha agotado el tiempo de espera 10 veces consecutivas mientras espera la respuesta del paquete de administración. Los tiempos de espera consiguientes dan como resultado la impresión de "gestión consecutiva..." o "..timeout persisting.." en función de la versión del software.
El mensaje de registro está limitado por velocidad a una vez cada 10 minutos. El reenvío de paquetes a los ASIC stub afectados continúa cuando se producen los tiempos de espera. Sin embargo, no se ve ningún cambio en el link / velocidad automática / dúplex ya que el software no recibe las respuestas del paquete de administración. Además, el proceso de actualización de las estadísticas de tráfico para el grupo de interfaz queda afectado cuando ocurren tiempos de espera.
Resolución de problemas
Hay varias causas para que aparezcan los mensajes de tiempo de espera Astro/Lemans/Nicer. A continuación, explicaremos cada una de ellas.
Causa 1: Alta carga de tráfico, loop de capa 2 o tráfico de red excesivo en dirección a la CPU
Lo siguiente puede causar condiciones de tiempo de espera stub:
-
Problemas de red
-
Problemas de configuración
-
Elementos vecinos
-
Otros factores fuera del switch Catalyst
Un loop de Capa 2 o una tormenta de difusión que ocasiona una alta carga de tráfico pueden provocar la pérdida de paquetes de control de administración interna. Esto sucede usualmente debido a que la CPU está ocupada (CPU hog) y no puede procesar sus colas.
Él tráfico de control de administración interna toma el mismo trayecto de datos al Supervisor que el tráfico de datos normal desde Astro (o cualquier otro chip Stub). Por lo tanto, los paquetes de control pueden perderse debido a la congestión.
Con el arreglo del Id de falla de funcionamiento de Cisco CSCea73908 (sólo para clientes registrados), el período de tiempo de espera de solicitud interna de la administración se maneja mejor en la versión 6.4(4) y posteriores. Esta mejora puede evitar muchos tiempos de retardo de paquetes de control transitorio debido a que la CPU está ocupada.
Acción: Solución de problemas del loop de Capa 2; o cambiar la configuración para resolver patrones de tráfico.
Solución alternativa: Cambie la interfaz de administración del switch (sc0) a VLAN de tráfico no de usuario en switches basados en CatOS. Utilice el comando set interface sc0 <vlan-id> para mover la vlan de la interfaz sc0.
Nota: A partir de Cisco IOS 12.1(20)EW, los supervisores basados en Cisco IOS introducen una mejora en la gestión del mecanismo de administración interna de paquetes por parte de la CPU. Esta mejora ayudará a evitar la pérdida de paquetes de control de administración interna ocasionado por el tráfico de baja prioridad que monopoliza de forma inadvertida la CPU.
Solución: Consulte la siguiente solución alternativa.
Causa 2: Cableado tipo 1A/medio dúplex
Los puertos de usuario de panel frontal están configurados como semidúplex. Las colisiones del tráfico saliente con el tráfico entrante en el stub ASIC pueden hacer que el búfer stub se vacíe muy lentamente. Esto puede hacer que las colas tx en Supervisor se llenen y que las nuevas solicitudes de administración interna se descarten, lo que provocaría mensajes de error de tiempo de espera.
Este problema también puede ser provocado por una red con un cableado de Tipo1A. Cuando se desconecta una estación de trabajo conectada a un bloque tipo1A con un parche RJ-45, el Balun vuelve a bucear internamente y hace que el tráfico saliente regrese. Esta situación pretende conectar un loopback externo en el puerto del panel frontal. Antes de que el puerto pase al estado de bloqueo, se produce un loopback del tráfico saliente en el switch. Esto puede hacer que las memorias intermedias stub se desborden, dependiendo de la velocidad del tráfico.
Acción: Consulte la solución alternativa.
Solución alternativa: Evite la configuración semidúplex. En el caso del cableado de tipo 1A, evite enchufar el cable de conexión RJ-45 del Balun de tipo 1A para evitar formar un loopback interno en el Balun.
Solución: Consulte la solución alternativa.
Causa 3: Falla de componente SERDES
Si los errores se ven sólo en un Astro (u otro ASIC stub) en un módulo y no se produce un loop de capa 2, es muy probable que el problema sea un componente SERDES defectuoso en el Supervisor o en la Tarjeta de línea. Por ejemplo, si el mensaje de error está siempre en Astro 4 en el Módulo 3 como se muestra a continuación, el componente SERDES en el módulo 3 o el componente SERDES en el Supervisor son defectuosos.
%SYS-4-P2_WARN: 1/Astro(3/4) – timeout occurred
En el mensaje de error anterior, el número "4" entre paréntesis se refiere al número Astro y no al puerto real 3/4. Este número hace referencia a un grupo de ocho puertos (3/33-3/40), ya que es el cuarto Astro del módulo 3.
Un componente SERDES defectuoso puede causar una conectividad intermitente para controlar el tráfico y el tráfico de la información hacia Astro/Lemans/NiceR, lo que provocará tiempos de espera. Por lo general, sin embargo, el mensaje de error se mostrará continuamente si el SERDES es defectuoso.
Acción: Para determinar qué (Supervisor o tarjeta de línea) SERDES es incorrecto, realice los siguientes pasos:
-
Mueva la tarjeta de línea a una ranura libre en el chasis o a otro chasis. Si hay una ranura libre disponible, intercambie ranuras con un módulo de trabajo conocido.
-
Si continúa obteniendo tiempos de espera Astro/Lemans/Nicer en el mismo Astro/Lemans/Nicer en la nueva ranura, lo más probable es que el SERDES o el Astro/Lemans/Nicer en la tarjeta de línea haya fallado y la tarjeta de línea deba reemplazarse
Nota: Al volver a insertar el módulo en una ranura de repuesto, el diagnóstico en línea se realiza en la tarjeta de línea. Si se encuentra un SERDES o Astro/Lemans/Nicer defectuoso, el switch marcará el puerto como defectuoso.
-
Si los tiempos de espera no continúan en la tarjeta de línea original Astro/Lemans/Nicer, es posible que el Supervisor SERDES esté dañado. Para verificar esto, inserte un módulo en buen funcionamiento en la ranura original y observe si los tiempos de espera agotados ocurren con el nuevo módulo.
Si funciona, es posible que un SERDES esté en el Supervisor. Refiérase al aviso de campo Exposiciones de Pérdida Parcial de Conectividad del Supervisor Catalyst WS-X4013 para ver una lista de números de serie afectados con el componente SERDES que falla.
Solución alternativa: Ninguno
Solución: Comuníquese con el TAC para más información acerca de la resolución de problemas.
Causa 4: Falla transitoria/permanente de SRAM
Los dispositivos conectados a un Catalyst 4000 con un Supervisor I, II, III o IV Engine o Catalyst 2948G, Cat2980G pueden experimentar una pérdida parcial o total de conectividad de red. Algunos o todos los puertos podrían verse afectados. Estos síntomas serán acompañados por una cantidad creciente de paquetes CRC inválidos descartados en el Supervisor basado en CatOS y mensajes de error de tiempo de espera ASIC del stub.
El problema se debe a una falla de la Memoria del búfer del paquete (SRAM), que es un tipo duro o transitorio.
Acción: Seleccione el curso de acción dependiendo de cuál de las dos firmas de error de memoria intermedia de paquetes transitorios se han producido a continuación:
-
Firma de la falla de memoria de la memoria intermedia del paquete transitorio para SUP I, SUP II, 2948G, 2980G
A continuación se enumeran síntomas de este problema:
-
InvalidPktBufferCRC’s aumenta rápidamente con un mensaje similar al siguiente
%SYS-4-P2_WARN: 1/Invalid crc, dropped packet, count = xxxx
-
Un reinicio suave usando el comando reset haría que el Supervisor no pueda ejecutar la POST.
-
Si se realiza una restauración de hardware, Supervisor aprobará POST y no volverá a fallar.
Nota: En el caso de una falla de memoria intermedia de paquetes duros para los Supervisor I, II, 2948G, 2980G, un reinicio de hardware no resolvería el problema y el Supervisor o el switch seguiría fallando el POST.
Para más información acerca de este problema, consulte ID de falla de funcionamiento Cisco CSCdy46288 (sólo para clientes registrados) para Supervisor II, ID de falla de funcionamiento de Cisco CSCeb56266 (sólo para clientes registrados) para Supervisor I/2948G/2980G y el ID de falla de Cisco CSCeb56325 (sólo para clientes registrados) para el WS-C2980G-A.
-
-
Firma de falla de memoria del búfer de paquetes transitorios para SUP III, SUP IV
A continuación se enumeran síntomas de este problema:
-
El contador VlanZeroBadCrc aumenta rápidamente y se muestra en el resultado de los siguientes comandos:
show platform cpuport all (prior to 12.1(11b)EW1 ) or show platform cpu packet statistics all (Since 12.1(11b)EW1) depending upon the software version. Starting from 12.1(19)EW, you should also see the following error message rapidly incrementing errors: %C4K_SWITCHINGENGINEMAN-2-PACKETMEMORYERROR3: Persistent Errors in Packet Memory xxxx
-
Un reinicio por software haría que el Supervisor fallara el POST. Utilice el comando show diagnostics power-on para verificar la falla.
-
Un reinicio duro (apagar y encender la alimentación) recuperará el Supervisor y superará el POST.
Nota: En el caso de una falla de SRAM dura para el Supervisor III / IV, un reinicio de hardware no recuperaría el Supervisor y seguiría fallando el POST.
Si desea más información sobre este tema en Supervisor III/IV, consulte la Id. de error de funcionamiento CSCdz57255 de Cisco (sólo para clientes registrados)
-
Solución alternativa: Si hay un problema de SRAM transitorio realice el ciclo de apagado y encendido o reinicie el switch. El problema de SRAM de hardware no tiene solución.
Solución: Comuníquese con el TAC para más información acerca de la resolución de problemas.
Causa 5: Falla de reloj del supervisor
Si se ven mensajes de error de tiempo de espera Astro/Lemans/NiceR que se refieren a varios números de módulo o a varios Astro/Lemans/Nicer, esto podría indicar una posible falla de reloj en el Supervisor. Generalmente, una falla del reloj es acompañada tanto por mensajes de error de tiempo de espera Astro/Lemans/Nicer como por mensajes de error BlockTXQueue y BlockedGigaport, tal como se muestra a continuación:
%SYS-4-P2_WARN: 1/Blocked queue on gigaport ...
Acción: Comuníquese con el TAC para mayor información sobre la resolución de problemas haciendo referencia al ID del depurador de Cisco: CSCdp89537 (clientes registrados únicamente) y CSCdp93187 (clientes registrados únicamente).
Solución alternativa: Ninguno
Solución: Comuníquese con el TAC para más información acerca de la resolución de problemas.
Causa 6: Interrupción de energía breve
Un switch Catalyst serie 4000 con un Supervisor II (WS-X4013) puede ingresar un estado en el que el supervisor y las tarjetas de línea no pueden comunicarse correctamente entre sí. Cuando el switch ingresa en este estado, los LED de estado del módulo serán rojos (sin parpadear) y/o los LED del puerto parpadearán en secuencia similar a un reinicio del módulo o del switch. Esto será acompañado por el tiempo de espera de Astro/Lemans/NiceR
Este problema es originado por un corte temporario del suministro de energía al switch (menos de 500 ms). La interrupción temporal de la alimentación eléctrica puede deberse a fuentes de alimentación inestables en un entorno de producción.
Acción: Consulte la siguiente solución alternativa.
Solución alternativa: Reinicie (suave o duro (ciclo de alimentación)) el switch.
Solución: Actualice a la imagen del software con el arreglo para el ID de falla de funcionamiento de Cisco CSCea14710 (sólo clientes registrados), o versiones posteriores.
Información Relacionada
- Mensajes de Error Comunes de CatOS en Catalyst 4000 Series Switches
- Resolución de problemas de switches de la serie Catalyst 4000/4912G/2980G/2948G
- Resolución de problemas de hardware y problemas relacionados en Catalyst 4000 y 4500 Supervisor III y IV
- Páginas de soporte de los switches de las series Catalyst 4000/4500
- Soporte de Tecnología de LAN Switching
- Soporte de Producto para Switches de ATM y Catalyst de LAN
- Soporte Técnico y Documentación - Cisco Systems
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)