Introducción
Este documento describe el procedimiento para recuperar el Cluster Manager desde el servidor de inicio en la configuración de la plataforma de implementación nativa en la nube (CNDP).
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- Cisco Subscriber Microservices Infrastructure (SMI)
- Arquitectura 5G CNDP o SMI-Bare-metal (BM)
- Dispositivo de bloque replicado distribuido (DRBD)
Componentes Utilizados
La información que contiene este documento se basa en las siguientes versiones de software y hardware.
- SMI 2020.2.2.35
- Kubernetes v1.21.0
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
¿Qué es SMI Cluster Manager?
Un administrador de clústeres es un clúster keepalived de 2 nodos que se utiliza como punto inicial para la implementación de clústeres tanto en el plano de control como en el plano de usuario. Ejecuta un clúster de Kubernetes de un solo nodo y un conjunto de POD que son responsables de toda la configuración del clúster. Sólo el administrador de clústeres principal está activo y el secundario asume el control sólo en caso de error o se desactiva manualmente para mantenimiento.
¿Qué es un servidor de inicio?
Este nodo realiza la gestión del ciclo de vida del Administrador de clústeres (CM) subyacente y desde aquí puede insertar la configuración de día 0.
Este servidor se suele implementar por región o en el mismo Data Center que la función de orquestación de nivel superior (por ejemplo, NSO) y normalmente se ejecuta como una VM.
Problema
El administrador de clústeres se aloja en un clúster de 2 nodos con el dispositivo de bloque replicado distribuido (DRBD) y se mantiene activo como principal del Administrador de clústeres y secundario del Administrador de clústeres. En este caso, el secundario del Administrador de clústeres pasa al estado de apagado automáticamente mientras se inicia o instala el SO en UCS, lo que indica que el SO está dañado.
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 WFConnection Primary/Unknown UpToDate/DUnknown /mnt/stateful_partition ext4 568G 369G 170G 69%
Procedimiento de mantenimiento
Este proceso ayuda a reinstalar el sistema operativo en el servidor CM.
Identificar hosts
Inicie sesión en el Administrador de clústeres e identifique los hosts:
cloud-user@POD-NAME-cm-primary:~$ cat /etc/hosts | grep 'deployer-cm'
127.X.X.X POD-NAME-cm-primary POD-NAME-cm-primary
X.X.X.X POD-NAME-cm-primary
X.X.X.Y POD-NAME-cm-secondary
Identificar detalles de clúster desde el servidor de inicio
Inicie sesión en el servidor de inicio y entre en el implementador y verifique el nombre del clúster con hosts-IP de Cluster-Manager.
Después de iniciar sesión correctamente en el servidor de inicio, inicie sesión en el centro de operaciones como se muestra aquí.
user@inception-server: ~$ ssh -p 2022 admin@localhost
Verifique el nombre del clúster desde el SSH-IP del Administrador de clústeres (ssh-ip = IP-address del SSH del nodo = ip-address del cimc del servidor de ucs).
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tab
SSH
NAME NAME IP SSH IP IP ADDRESS
------------------------------------------------------------------------------
POD-NAME-deployer cm-primary - X.X.X.X 10.X.X.X ---> Verify Name and SSH IP if Cluster is part of inception server SMI.
cm-secondary - X.X.X.Y 10.X.X.Y
Compruebe la configuración del clúster de destino.
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME-deployer
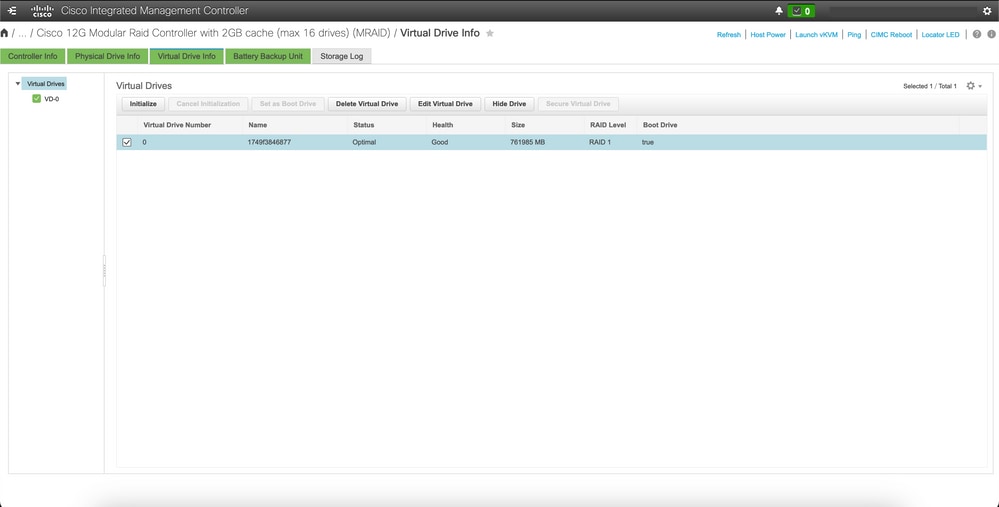
Quite la unidad virtual para borrar el sistema operativo del servidor
Conéctese al CIMC del host afectado, borre la unidad de arranque y elimine la unidad virtual (VD).
a) CIMC > Storage > Cisco 12G Modular Raid Controller > Storage Log > Clear Boot Drive
b) CIMC > Storage > Cisco 12G Modular Raid Controller > Virtual drive > Select the virtual drive > Delete Virtual Drive
Ejecutar sincronización de clúster
Ejecute la sincronización predeterminada del clúster para el Administrador de clústeres desde el servidor de inicio.
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Si falla la sincronización predeterminada del clúster, realice la sincronización del clúster con la opción de reimplementación force-vm para la reinstalación completa (la actividad de sincronización del clúster puede tardar entre 45 y 55 minutos en completarse, según el número de nodos alojados en el clúster)
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true force-vm-redeploy true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Supervisar los registros de sincronización del clúster
[inception-server] SMI Cluster Deployer# monitor sync-logs POD-NAME-deployer
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Cluster name: POD-NAME
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Force VM Redeploy: true
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: Force partition Redeploy: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: reset_k8s_nodes: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: purge_data_disks: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: upgrade_strategy: auto
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: sync_phase: all
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: debug: true
...
...
...
El servidor se vuelve a aprovisionar e instalar mediante la sincronización correcta del clúster.
PLAY RECAP *********************************************************************
cm-primary : ok=535 changed=250 unreachable=0 failed=0 skipped=832 rescued=0 ignored=0
cm-secondary : ok=299 changed=166 unreachable=0 failed=0 skipped=627 rescued=0 ignored=0
localhost : ok=59 changed=8 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
Thursday 23 February 2023 13:17:24 +0000 (0:00:00.109) 0:56:20.544 *****. ---> ~56 mins to complete cluster sync
===============================================================================
2023-02-23 13:17:24.539 DEBUG cluster_sync.POD-NAME: Cluster sync successful
2023-02-23 13:17:24.546 DEBUG cluster_sync.POD-NAME: Ansible sync done
2023-02-23 13:17:24.546 INFO cluster_sync.POD-NAME: _sync finished. Opening lock
Verificación
Verifique que el Cluster Manager afectado sea accesible y que la descripción general de DRBD de los Cluster Manager Primario y Secundario esté en estado Actualizado.
cloud-user@POD-NAME-cm-primary:~$ ping X.X.X.Y
PING X.X.X.Y (X.X.X.Y) 56(84) bytes of data.
64 bytes from X.X.X.Y: icmp_seq=1 ttl=64 time=0.221 ms
64 bytes from X.X.X.Y: icmp_seq=2 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=3 ttl=64 time=0.151 ms
64 bytes from X.X.X.Y: icmp_seq=4 ttl=64 time=0.154 ms
64 bytes from X.X.X.Y: icmp_seq=5 ttl=64 time=0.172 ms
64 bytes from X.X.X.Y: icmp_seq=6 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=7 ttl=64 time=0.174 ms
--- X.X.X.Y ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 6150ms
rtt min/avg/max/mdev = 0.151/0.171/0.221/0.026 ms
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 Connected Primary/Secondary UpToDate/UpToDate /mnt/stateful_partition ext4 568G 17G 523G 4%
El administrador de clústeres afectado se ha instalado correctamente y se ha vuelto a aprovisionar en la red.
2.2 Verifique el nombre del clúster desde el SSH-IP del Administrador de clústeres.
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tabulación
SSH
NAME NAME IP SSH IP ADDRESS
------------------------------------------------------------------------------
POD-NAME cm-primary - 192.X.X.X 10.192.X.X
cm-secondary - 192.X.X.Y 10.192.X.Y
*SSH IP = IP SSH de nodo
*IP ADDRESS = ucs-server cimc ip-address
2.3 Verifique la configuración del clúster de destino.
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME Inicie sesión en el servidor de iniciación y entre en Deployer y verifique el nombre del clúster con hosts-IP de Cluster-Manager. Inicie sesión en el servidor de inicio, entre en el implementador y verifique el nombre del clúster con la dirección IP de los hosts desde el Administrador de clústeres.
 Comentarios
Comentarios