Procedimiento de recuperación para el error del racimo de Ultra-M AutoVNF - vEPC
Opciones de descarga
-
ePub (350.9 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (278.5 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos requeridos para recuperar ultra los servicios de la automatización (UAS) o el error del racimo de AutoVNF en un Ultra-M puesto que funciona la red virtual de StarOS de los host (VNFs).
Antecedentes
Ultra-M es una solución móvil virtualizada preembalada y validada de la base del paquete que se diseña para simplificar el despliegue de VNFs.
La solución de Ultra-M consiste en los tipos mentoned de la máquina virtual (VM):
- LAS AUTO-TIC
- Auto-despliegue
- UAS o AutoVNF
- Encargado del elemento (EM)
- El elástico mantiene el regulador (salida)
- Función de control (CF)
- Función de la sesión (SF)
La arquitectura de alto nivel de Ultra-M y los componentes implicados se representan en esta imagen:
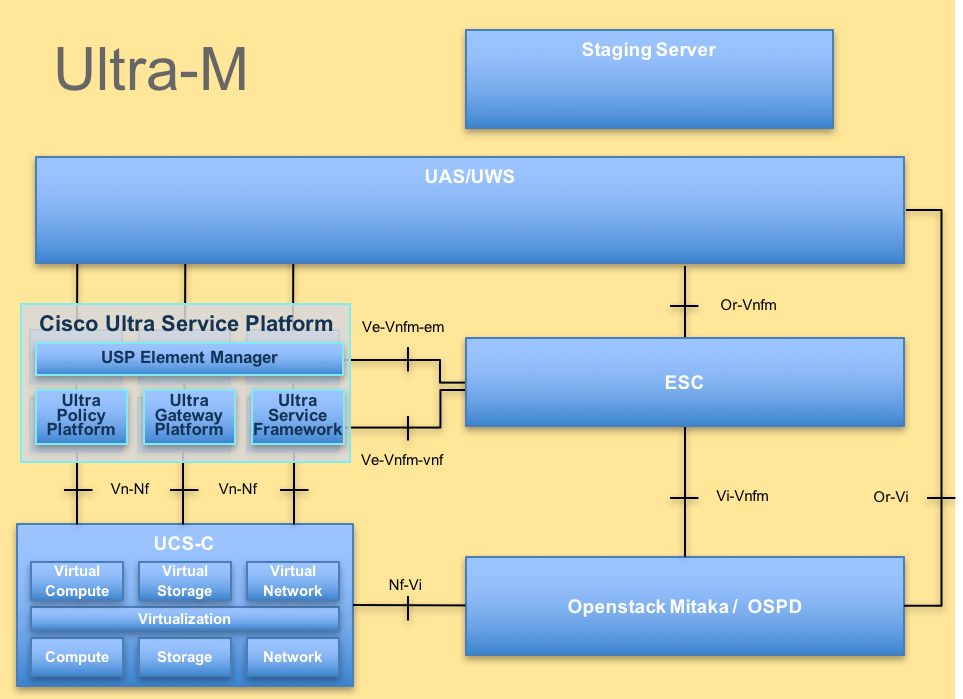 Arquitectura de UltraM
Arquitectura de UltraM
Este documento se piensa para el personal de Cisco que es familiar con la plataforma de Cisco Ultra-M.
Nota: Ultra la versión M 5.1.x se considera para definir los procedimientos en este documento.
Abreviaturas
| VNF | Función de la red virtual |
| CF | Función de control |
| SF | Función de servicio |
| Salida | Regulador elástico del servicio |
| FREGONA | Método de procedimiento |
| OSD | Discos del almacenamiento del objeto |
| HDD | Unidad de disco duro |
| SSD | Unidad de estado sólido |
| VIM | Encargado virtual de la infraestructura |
| VM | Máquina virtual |
| EM | Encargado del elemento |
| UAS | Servicios de ultra automatización |
| UUID | Universal Identificador único |
Flujo de trabajo de la fregona
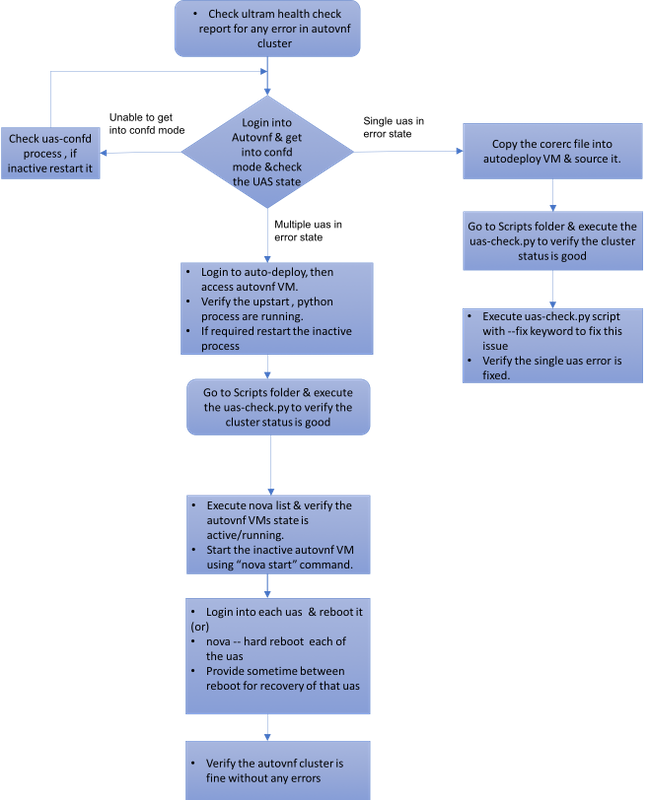
Recuperación del caso 1. del solo error de racimo UAS
Revisión de estado
1. El encargado de Ultra-M realiza la revisión médica del nodo de Ultra-M. Navegue al directorio y al grep de /var/log/cisco/ultram-health/ de los informes para el informe UAS.
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. El estatus previsto del racimo UAS estará según lo representado, donde están vivos todos los tres UAS.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
Error conectar con el servidor de Confd cuando usted intenta conectar con UAS
1. En algunos casos, usted no podrá conectar con el servidor del confd.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. Controle el estatus del proceso del uas-confd.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. Si el servidor del confd no se ejecuta, recomience el servicio.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
Recupere UAS del estado de error
1. En caso del error de un AutoVNF entre el racimo, el racimo UAS muestra uno del UAS en el estado de error.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. Copie el fichero del corerc (fichero del rc de su VNF) de /home/stack en el servidor OSPD a AutoDeploy y a la fuente él.
3. Controle el estatus de su UAS/AutoVNF con el uso del script uas-check.py. autovnf1is el nombre de AutoVNF.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. Recupere el UAS con el uso del script uas-check.py y agregue --fije la palabra clave.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. Usted verá que el UAS creado recientemente es vivo y parte del racimo.
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Caso 2. Los tres UAS (AutoVNF) están en el estado de error
1. El encargado de Ultra-M realiza la revisión médica del nodo de Ultra-M.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Según lo observado en la salida, el encargado de Ultra-M señala que hay un error para AutoVNF y muestra que todos los tres UAS del racimo están en el estado de error.
Controle la salud UAS con el script uas-check.py
1. Clave al Auto-desplegar y al control si usted puede tener acceso al AutoVNF UAS y conseguir el estatus.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. De Auto-despliegue, Secure Shell (SSH) al nodo de AutoVNF y ingrese en el modo del confd. Controle el estatus con los uas de la demostración.
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. Se recomienda para controlar el estatus en los tres Nodos UAS.
Controle el estado de las VM en el nivel de OpenStack
Controle el estatus del AutoVNF VM en la lista de la Nova. Si procede, realice el comienzo de la Nova para comenzar el cierre VM.
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Controle la opinión del Zookeeper
1. Controle el estado del zookeeper para verificar el modo como arranque de cinta.
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. El Zookeeper normalmente debe estar para arriba.
Resuelva problemas el AutoVNF - Procesos y tareas
1. Identifique la razón del estado de error de los Nodos. Para que AutoVNF se ejecute, hay un conjunto de procesos que debe ser en servicio como se muestra:
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. Verifique que estos procesos del pitón se estén ejecutando:
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. Si los procesos previstos uces de los no son adentro comienzo/estado de ejecución, recomience el proceso y controle el estatus. Si todavía muestra en el estado de error después siga el procedimiento mencionado en la siguiente sección para fijar este problema.
Arreglo para UAS múltiple en el estado de error
1. Nova --el <name duro de la reinicialización del VM> de OSPD, da un cierto tiempo para la recuperación de esta VM antes de que usted proceda al UAS siguiente. Hágalo en todo el UAS VM.
or
2.Log adentro a cada uno de la reinicialización del sudo UAS y del uso. Espere la recuperación y después proceda al otro UAS VM.
Para los registros de transacciones, controle:
/var/log/upstart/autovnf.log
show logs xxx | display xml
Esto fijará el problema y recuperará el UAS del estado de error.
1. Verifique lo mismo con el uso del informe del ultram_health_check.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
Con la colaboración de ingenieros de Cisco
- Partheeban RajagopalAdvanced Services de Cisco
- Padmaraj RamanoudjamAdvanced Services de Cisco
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)