Gestion de niveau de service : Livre blanc sur les pratiques recommandées
Contenu
Introduction
Ce document décrit la gestion de niveau de services et les accords de niveau de service (SLA) pour des réseaux à haute disponibilité. Cela inclut des facteurs de succès capital pour que la gestion et les indicateurs de performances de niveau de services aident à évaluer le succès. Le document fournit également le détail significatif pour les SLA qui suivent les indications des pratiques recommandées identifiées par l'équipe de service de haute disponibilité.
Présentation de la gestion des niveaux de service
Les organisations réseau ont toujours répondu aux besoins croissants du réseau en construisant une infrastructure réseau solide et en travaillant de manière réactive pour gérer les problèmes de service individuels. Lorsqu'une panne survient, l'entreprise crée de nouveaux processus, capacités de gestion ou infrastructure qui empêchent une panne particulière de se reproduire. Cependant, en raison d'un taux de changement plus élevé et de l'augmentation des besoins en disponibilité, nous avons désormais besoin d'un modèle amélioré pour éviter de manière proactive les temps d'arrêt imprévus et réparer rapidement le réseau. De nombreuses entreprises et fournisseurs de services ont tenté de mieux définir le niveau de service requis pour atteindre les objectifs commerciaux.
Facteurs critiques de réussite
Les facteurs de réussite critiques pour les contrats de niveau de service sont utilisés pour définir les éléments clés permettant de créer des niveaux de service pouvant être obtenus et de maintenir les contrats de niveau de service. Pour être considéré comme un facteur de réussite critique, un processus ou une étape de processus doit améliorer la qualité du contrat de niveau de service (SLA) et bénéficier de la disponibilité du réseau en général. Le facteur de réussite critique doit également être mesurable afin que l'organisation puisse déterminer le degré de réussite par rapport à la procédure définie.
Voir Mise en oeuvre de la gestion des niveaux de service pour plus de détails.
Indicateurs de performance
Les indicateurs de rendement fournissent le mécanisme par lequel une organisation mesure les facteurs de succès critiques. En règle générale, vous les passez en revue tous les mois pour vous assurer que les définitions de niveau de service ou les contrats de niveau de service fonctionnent correctement. Le groupe d'opérations réseau et les groupes d'outils nécessaires peuvent effectuer les mesures suivantes.
Remarque : Pour les organisations sans SLA, nous vous recommandons d'effectuer des définitions de niveau de service et des examens de niveau de service en plus des indicateurs.
Les indicateurs de rendement sont les suivants :
-
Définition de niveau de service ou SLA documentée qui inclut la disponibilité, les performances, le temps de réponse réactif, les objectifs de résolution des problèmes et l'escalade des problèmes.
-
Réunions mensuelles d'examen du niveau de service des réseaux pour examiner la conformité au niveau de service et mettre en oeuvre des améliorations.
-
Indicateurs de performance, notamment disponibilité, performances, temps de réponse du service par priorité, temps de résolution par priorité et autres paramètres SLA mesurables.
Pour plus d'informations, reportez-vous à Mise en oeuvre de la gestion au niveau des services.
Flux de processus de gestion au niveau des services
Le flux de processus de haut niveau pour la gestion des niveaux de service comprend deux grands groupes :
Cliquez sur les objets du schéma suivant pour afficher les détails de cette étape.
Mise en oeuvre de la gestion au niveau des services
La mise en oeuvre de la gestion des niveaux de service se compose de seize étapes réparties en deux grandes catégories :
Définition des niveaux de service réseau
Les administrateurs réseau doivent définir les principales règles par lesquelles le réseau est pris en charge, géré et mesuré. Les niveaux de service fournissent des objectifs pour l’ensemble du personnel du réseau et peuvent être utilisés comme une mesure de la qualité du service global. Vous pouvez également utiliser les définitions de niveau de service comme outil de budgétisation des ressources réseau et comme preuve de la nécessité de financer une qualité de service supérieure. Ils permettent également d'évaluer les performances des fournisseurs et des opérateurs.
Sans définition et mesure du niveau de service, l'organisation n'a pas d'objectifs clairs. La satisfaction des services peut être régie par des utilisateurs qui se différencient peu des applications, des opérations serveur/client ou de l'assistance réseau. La budgétisation peut être plus difficile, car le résultat final n'est pas clair pour l'entreprise et, finalement, l'organisation du réseau tend à être plus réactive, et non proactive, dans l'amélioration du réseau et du modèle d'assistance.
Nous recommandons les étapes suivantes pour la création et la prise en charge d'un modèle de niveau de service :
-
Créer des profils d'application détaillant les caractéristiques réseau des applications critiques.
-
Définir les normes de disponibilité et de performances et définir des termes communs.
-
Collecter des métriques et surveiller la définition du niveau de service.
Étape 1 : Analyser les objectifs techniques et les contraintes
La meilleure façon de commencer à analyser les objectifs et les contraintes techniques est de faire des remue-méninges ou de faire des recherches sur les objectifs et les exigences techniques. Il est parfois utile d'inviter d'autres interlocuteurs techniques IT à participer à cette discussion, car ces personnes ont des objectifs spécifiques liés à leurs services. Les objectifs techniques incluent les niveaux de disponibilité, le débit, la gigue, le délai, le temps de réponse, les exigences d'évolutivité, les nouvelles fonctionnalités, les nouvelles applications introduites, la sécurité, la facilité de gestion et même le coût. L'organisation devrait alors étudier les obstacles à la réalisation de ces objectifs compte tenu des ressources disponibles. Vous pouvez créer des feuilles de calcul pour chaque objectif avec une explication des contraintes. Au départ, il peut sembler que la plupart des objectifs ne sont pas réalisables. Ensuite, commencez à hiérarchiser les objectifs ou à réduire les attentes qui peuvent toujours répondre aux besoins de l'entreprise.
Par exemple, votre niveau de disponibilité peut être de 99,999 %, soit 5 minutes d'arrêt par an. Il existe de nombreuses contraintes pour atteindre cet objectif, telles que les points de défaillance uniques du matériel, le temps moyen de réparation (MTTR) du matériel défectueux dans des sites distants, la fiabilité de l'opérateur, les fonctionnalités proactives de détection des pannes, les taux de changement élevés et les limitations actuelles de la capacité du réseau. Par conséquent, vous pouvez ajuster l'objectif à un niveau plus réalisable. Le modèle de disponibilité de la section suivante peut vous aider à définir des objectifs réalistes.
Vous pouvez également envisager de fournir une disponibilité plus élevée dans certaines zones du réseau qui ont moins de contraintes. Lorsque l'organisation réseau publie des normes de service pour la disponibilité, les groupes d'entreprises au sein de l'organisation peuvent trouver le niveau inacceptable. Il s'agit alors d'un point naturel pour entamer des discussions sur les contrats de niveau de service ou des modèles de financement/budgétisation qui peuvent répondre aux besoins de l'entreprise.
Identifier toutes les contraintes ou tous les risques associés à la réalisation de l'objectif technique. Hiérarchiser les contraintes en fonction du risque ou de l'impact le plus élevé vers l'objectif souhaité. Cela aide l'entreprise à hiérarchiser les initiatives d'amélioration du réseau et à déterminer la facilité avec laquelle les contraintes peuvent être résolues. Il existe trois types de contraintes :
-
Technologie, résilience et configuration du réseau
-
Pratiques du cycle de vie, y compris la planification, la conception, la mise en oeuvre et le fonctionnement
-
Charge de trafic actuelle ou comportement des applications
La technologie réseau, la résilience et les contraintes de configuration sont des limitations ou des risques associés à la technologie, au matériel, aux liaisons, à la conception ou à la configuration actuelle. Les limitations technologiques couvrent toute contrainte posée par la technologie elle-même. Par exemple, aucune technologie actuelle ne permet des temps de convergence inférieurs à la seconde dans les environnements réseau redondants, ce qui peut être essentiel pour assurer la continuité des connexions vocales sur le réseau. Un autre exemple peut être la vitesse brute que les données peuvent traverser sur des liaisons terrestres, soit environ 100 milles par milliseconde.
Les enquêtes sur les risques de résilience du matériel réseau doivent se concentrer sur la topologie du matériel, la hiérarchie, la modularité, la redondance et le MTBF le long de chemins définis dans le réseau. Les contraintes de liaison réseau doivent se concentrer sur les liaisons réseau et la connectivité des opérateurs pour les entreprises. Les contraintes de liaison peuvent inclure la redondance et la diversité des liaisons, les limitations des supports, l'infrastructure de câblage, la connectivité en boucle locale et la connectivité longue distance. Les contraintes de conception sont liées à la conception physique ou logique du réseau et incluent tout, de l’espace disponible pour l’équipement à l’évolutivité de la mise en oeuvre du protocole de routage. Toutes les conceptions de protocoles et de supports doivent être prises en compte en fonction de la configuration, de la disponibilité, de l'évolutivité, des performances et de la capacité. Les contraintes de service réseau telles que DHCP (Dynamic Host Configuration Protocol), DNS (Domain Name System), les pare-feu, les traducteurs de protocole et les traducteurs d’adresses réseau doivent également être prises en compte.
Les pratiques de cycle de vie définissent les processus et la gestion du réseau utilisés pour déployer des solutions de manière cohérente, détecter et réparer les problèmes, prévenir les problèmes de capacité ou de performances et configurer le réseau pour assurer la cohérence et la modularité. Vous devez considérer ce domaine car l'expertise et les processus sont généralement les principaux contributeurs à la non-disponibilité. Le cycle de vie du réseau fait référence au cycle de planification, de conception, de mise en oeuvre et d'exploitation. Dans chacun de ces domaines, vous devez comprendre les fonctionnalités de gestion du réseau telles que la gestion des performances, la gestion de la configuration, la gestion des pannes et la sécurité. Une évaluation du cycle de vie du réseau est disponible auprès des services HAS (High-Availability Services) de Cisco NSA, qui indiquent les contraintes actuelles de disponibilité du réseau associées aux pratiques du cycle de vie du réseau.
Les contraintes actuelles de charge de trafic ou d'application se réfèrent simplement à l'impact du trafic et des applications actuels.
Malheureusement, de nombreuses applications présentent des contraintes importantes qui nécessitent une gestion soignée. La gigue, le délai, le débit et la bande passante requis pour les applications actuelles sont généralement soumis à de nombreuses contraintes. La manière dont l'application a été écrite peut également créer des contraintes. Le profilage des applications vous aide à mieux comprendre ces problèmes ; la section suivante couvre cette fonctionnalité. L'étude globale de la disponibilité, du trafic, de la capacité et des performances actuelles aide également les administrateurs réseau à comprendre les attentes et les risques liés aux niveaux de service actuels. Cela s'effectue généralement par le biais d'un processus appelé mise en réseau de base, qui permet de définir les moyennes des performances, de la disponibilité ou de la capacité du réseau pour une période définie, généralement d'environ un mois. Ces informations sont normalement utilisées pour la planification des capacités et les tendances, mais elles peuvent également être utilisées pour comprendre les problèmes de niveau de service.
La feuille de calcul suivante utilise la méthode de contrainte/objectif ci-dessus pour l'exemple d'objectif d'empêcher une attaque de sécurité ou de déni de service (DoS). Vous pouvez également utiliser cette feuille de calcul pour déterminer la couverture de service afin de réduire au minimum les attaques de sécurité.
| Risque ou contrainte | Type de contrainte | Impact potentiel |
|---|---|---|
| Les outils de détection de déni de service disponibles ne peuvent pas détecter tous les types d'attaques de déni de service. | Technologie/résilience | Élevé |
| Ne pas avoir le personnel et le processus requis pour réagir aux alertes. | Pratiques du cycle de vie | Élevé |
| Les politiques d'accès réseau actuelles ne sont pas en place. | Pratiques du cycle de vie | Moyen |
| La connexion Internet à faible bande passante actuelle peut être un facteur d'attaque si l'encombrement de la bande passante est utilisé. | Capacité du réseau | Moyen |
| Actuellement, la configuration de la sécurité pour prévenir les attaques peut ne pas être complète. | Technologie/résilience | Moyen |
Étape 2 : Déterminer le budget de disponibilité
Un budget de disponibilité correspond à la disponibilité théorique attendue du réseau entre deux points définis. Des informations théoriques précises sont utiles de plusieurs façons :
-
L'entreprise peut s'en servir comme objectif de disponibilité interne et les écarts peuvent être rapidement définis et corrigés.
-
Ces informations peuvent être utilisées par les planificateurs de réseau pour déterminer la disponibilité du système afin de s'assurer que la conception répond aux besoins de l'entreprise.
Les facteurs qui contribuent à la non-disponibilité ou à la durée d'arrêt incluent la défaillance matérielle, la défaillance logicielle, les problèmes d'alimentation et d'environnement, la défaillance de liaison ou de porteuse, la conception du réseau, l'erreur humaine ou l'absence de processus. Vous devez évaluer attentivement chacun de ces paramètres lors de l'évaluation du budget de disponibilité global du réseau.
Si l'organisation mesure actuellement la disponibilité, il se peut que vous n'ayez pas besoin d'un budget de disponibilité. Utilisez la mesure de disponibilité comme base pour estimer le niveau de service actuel utilisé pour une définition de niveau de service. Cependant, vous pouvez être intéressé à comparer les deux pour comprendre la disponibilité théorique potentielle par rapport au résultat réel mesuré.
La disponibilité est la probabilité qu'un produit ou service fonctionne au besoin. Reportez-vous aux définitions suivantes :
-
Disponibilité
-
1 - (durée totale d'interruption de connexion) / (durée totale de connexion en service)
-
1 - [Sigma(nombre de connexions affectées en panne i X durée de panne i)] / (nombre de connexions en service X durée de fonctionnement)
-
-
Indisponibilité
1 - Disponibilité ou temps total d'arrêt de connexion dû à (panne matérielle, panne logicielle, problèmes d'environnement et d'alimentation, panne de liaison ou de porteuse, conception du réseau, erreur utilisateur et panne de processus)
-
Disponibilité matérielle
Le premier domaine à étudier est la défaillance potentielle du matériel et l'effet sur la non-disponibilité. Pour le déterminer, l'entreprise doit comprendre le MTBF de tous les composants du réseau et le MTTR pour les problèmes matériels de tous les périphériques sur un chemin entre deux points. Si le réseau est modulaire et hiérarchique, la disponibilité du matériel sera la même entre presque deux points. Les informations MTBF sont disponibles pour tous les composants Cisco et sont disponibles sur demande auprès d'un responsable de compte local. Le programme Cisco NSA HAS utilise également un outil pour déterminer la disponibilité du matériel le long des chemins réseau, même lorsque la redondance des modules, la redondance du châssis et la redondance des chemins existent dans le système. Le MTTR est l'un des principaux facteurs de fiabilité du matériel. Les entreprises doivent évaluer la rapidité avec laquelle elles peuvent réparer le matériel défectueux. Si l'entreprise n'a pas de plan de remplacement et s'appuie sur un contrat Cisco SMARTnet™ standard, le délai moyen de remplacement potentiel est d'environ 24 heures. Dans un environnement LAN classique avec redondance de coeur de réseau et aucune redondance d'accès, la disponibilité approximative est de 99,99 % avec un MTTR de 4 heures.
-
Disponibilité logicielle
L'enquête suivante porte sur les pannes de logiciels. À des fins de mesure, Cisco définit les pannes logicielles comme des pannes de démarrage à froid de périphérique dues à des erreurs logicielles. Cisco a réalisé des progrès importants en matière de compréhension de la disponibilité des logiciels ; cependant, les nouvelles versions prennent du temps à mesurer et sont considérées comme moins disponibles que les logiciels de déploiement général. Les logiciels de déploiement général, tels que IOS version 11.2(18), ont été mesurés à plus de 99,9999 % de disponibilité. Ce calcul est basé sur les redémarrages réels des routeurs Cisco en utilisant six minutes comme temps de réparation (temps de rechargement du routeur). Les entreprises disposant de plusieurs versions devraient bénéficier d'une disponibilité légèrement plus faible en raison de la complexité, de l'interopérabilité et de l'augmentation des temps de dépannage. Les entreprises disposant des dernières versions logicielles devraient connaître une plus grande indisponibilité. La distribution pour la non-disponibilité est également assez large, ce qui signifie que les clients peuvent connaître une non-disponibilité significative ou une disponibilité proche d'une version générale de déploiement.
-
Disponibilité de l'environnement et de l'énergie
Vous devez également tenir compte des problèmes d'environnement et d'énergie dans la disponibilité. Les problèmes environnementaux sont liés à la panne des systèmes de refroidissement nécessaires pour maintenir l'équipement à une température de fonctionnement spécifiée. De nombreux périphériques Cisco s'arrêtent simplement lorsqu'ils ne sont pas conformes aux spécifications, au lieu de risquer d'endommager tout le matériel. Aux fins d'un budget de disponibilité, l'alimentation sera utilisée car elle est la principale cause de non-disponibilité dans cette zone.
Bien que les pannes d'alimentation soient un aspect important de la détermination de la disponibilité du réseau, cette discussion est limitée car l'analyse théorique de l'alimentation ne peut pas être effectuée avec précision. L'évaluation d'une entreprise consiste en une mesure approximative de la disponibilité de l'alimentation de ses périphériques en fonction de l'expérience acquise dans sa zone géographique, des capacités de sauvegarde de l'alimentation et du processus mis en oeuvre pour garantir une alimentation de qualité homogène à tous les périphériques.
Pour une évaluation prudente, nous pouvons dire qu'une entreprise disposant de générateurs de secours, de systèmes d'alimentation sans coupure (UPS) et de processus de mise en oeuvre de l'alimentation de qualité peut connaître six 99 % de disponibilité, soit 99,999 %, alors que les entreprises ne disposant pas de ces systèmes peuvent connaître une disponibilité de 99,99 %, soit environ 36 minutes d'interruption par an. Bien sûr, vous pouvez ajuster ces valeurs à des valeurs plus réalistes en fonction de la perception de l'organisation ou des données réelles.
-
Panne de liaison ou de porteuse
Les pannes de liaison et de porteuse sont des facteurs majeurs de disponibilité dans les environnements WAN. Gardez à l'esprit que les environnements WAN sont simplement d'autres réseaux soumis aux mêmes problèmes de disponibilité que le réseau de l'entreprise, notamment la défaillance matérielle, la défaillance logicielle, l'erreur utilisateur et la panne d'alimentation.
De nombreux réseaux d’opérateurs ont déjà établi un budget de disponibilité sur leurs systèmes, mais il peut être difficile d’obtenir ces informations. Gardez à l'esprit que les transporteurs ont souvent des niveaux de garantie de disponibilité qui n'ont que peu ou pas de base sur un budget de disponibilité réel. Ces niveaux de garantie sont parfois simplement des méthodes de marketing et de vente utilisées pour promouvoir le transporteur. Dans certains cas, ces réseaux publient également des statistiques de disponibilité qui semblent extrêmement bonnes. Gardez à l'esprit que ces statistiques peuvent s'appliquer uniquement aux réseaux principaux totalement redondants et ne pas tenir compte de la non-disponibilité en raison de l'accès en boucle locale, ce qui contribue grandement à la non-disponibilité des réseaux WAN.
La création d'une estimation de la disponibilité pour les environnements WAN doit être basée sur les informations réelles de l'opérateur et le niveau de redondance pour la connectivité WAN. Si une entreprise dispose de plusieurs installations d'entrée de bâtiments, de fournisseurs de boucle locale redondants, d'un accès local SONET (Synchronous-Optical-Network) et de transporteurs longue distance redondants présentant une diversité géographique, la disponibilité du WAN sera considérablement améliorée.
Le service téléphonique est un budget de disponibilité relativement précis pour la connectivité réseau non redondante dans les environnements WAN. La connectivité de bout en bout pour les téléphones a un budget de disponibilité approximatif de 99,94 % en utilisant une méthodologie budgétaire de disponibilité similaire à celle décrite dans cette section. Cette méthodologie a été utilisée avec succès dans les environnements de données avec de légères variations, et est actuellement utilisée comme cible dans la spécification de câblage de paquets pour les réseaux de câblage de fournisseur de services. Si nous appliquons cette valeur à un système entièrement redondant, nous pouvons supposer que la disponibilité du WAN sera proche de 99,9999 % disponible. Bien sûr, très peu d'entreprises ont des systèmes WAN totalement redondants et dispersés géographiquement en raison des dépenses et de la disponibilité, donc faites preuve d'un jugement approprié concernant cette fonctionnalité.
Les pannes de liaison dans un environnement LAN sont moins probables. Cependant, les planificateurs peuvent prendre un temps d'arrêt limité en raison de connecteurs rompus ou mal branchés. Pour les réseaux LAN, une estimation prudente est d'environ 99,9999 % de disponibilité, soit environ 30 secondes par an.
-
Conception réseau
La conception du réseau est un autre facteur important de disponibilité. Les conceptions non évolutives, les erreurs de conception et le temps de convergence du réseau ont tous un impact négatif sur la disponibilité.
Remarque : Pour les besoins de ce document, des erreurs de conception ou de conception non évolutives sont incluses dans la section suivante.
La conception du réseau est alors limitée à une valeur mesurable en fonction de la défaillance logicielle et matérielle du réseau qui entraîne le routage du trafic. Cette valeur est généralement appelée « temps de commutation du système » et est un facteur des capacités de protocole d'autoréparation du système.
Calculez la disponibilité en utilisant simplement les mêmes méthodes pour les calculs système. Toutefois, cette valeur n'est pas valide, sauf si le temps de commutation du réseau répond aux exigences des applications réseau. Si le temps de basculement est acceptable, supprimez-le du calcul. Si le temps de basculement n'est pas acceptable, vous devez l'ajouter aux calculs. Par exemple, la voix sur IP (VoIP) dans un environnement où le temps de commutation estimé ou réel est de 30 secondes. Dans cet exemple, les utilisateurs vont simplement raccrocher le téléphone et peut-être réessayer. Les utilisateurs verront certainement cette période comme non disponible, mais elle n'a pas été estimée dans le budget de disponibilité.
Calculez la non-disponibilité en raison du temps de commutation système en examinant la disponibilité théorique du logiciel et du matériel le long des chemins redondants, car la commutation se produira dans cette zone. Vous devez connaître le nombre de périphériques qui peuvent échouer et provoquer la commutation sur le chemin redondant, le MTBF de ces périphériques et le temps de commutation. Un exemple simple serait un MTBF de 35 433 heures pour chacun des deux périphériques redondants identiques et un temps de commutation de 30 secondes. En divisant 35 433 par 8 766 (heures par an en moyenne pour inclure les années bissextiles), nous voyons que l'appareil échouera une fois tous les quatre ans. Si nous utilisons 30 secondes comme temps de commutation, nous pouvons alors supposer que chaque périphérique connaîtra en moyenne 7,5 secondes par an de non-disponibilité en raison de la commutation. Comme les utilisateurs peuvent traverser l'un ou l'autre des chemins, le résultat est alors doublé pour atteindre 15 secondes par an. Lorsque ce calcul est effectué en secondes par an, la quantité de disponibilité due à la commutation peut être calculée comme étant de 99,99999785 % de disponibilité dans ce système simple. Cela peut être plus élevé dans d'autres environnements en raison du nombre de périphériques redondants dans le réseau où la commutation est potentielle.
-
Erreur utilisateur et processus
Les erreurs des utilisateurs et les problèmes de disponibilité des processus sont les principales causes de non-disponibilité dans les réseaux des entreprises et des opérateurs. Environ 80 % de la non-disponibilité se produit en raison de problèmes tels que la non-détection des erreurs, des défaillances de modification et des problèmes de performances.
Les entreprises ne voudront tout simplement pas utiliser quatre fois plus que toutes les autres indisponibilités théoriques pour déterminer le budget de disponibilité. Pourtant, les données indiquent constamment que c'est le cas dans de nombreux environnements. La section suivante traite plus en détail de cet aspect de la non-disponibilité.
Puisque vous ne pouvez pas théoriquement calculer le montant de non-disponibilité en raison d'erreurs et de processus utilisateur, nous vous recommandons de supprimer ce montant du budget de disponibilité et que les organisations s'efforcent de le perfectionner. La seule mise en garde est que les entreprises doivent comprendre le risque actuel de disponibilité dans leurs propres processus et niveaux d'expertise. Une fois que vous avez mieux compris ces risques et ces inhibiteurs, les planificateurs de réseau peuvent vouloir tenir compte d'une certaine quantité de non-disponibilité en raison de ces problèmes. Le programme Cisco NSA HAS analyse ces problèmes et peut aider les entreprises à comprendre la non-disponibilité potentielle en raison de problèmes de processus, d'erreur utilisateur ou d'expertise.
-
Détermination du budget de disponibilité final
Vous pouvez déterminer le budget de disponibilité global en multipliant la disponibilité pour chacune des zones précédemment définies. Cela est généralement fait pour des environnements homogènes où la connectivité est similaire entre deux points, comme un environnement LAN modulaire hiérarchique ou un environnement WAN standard hiérarchique.
Dans cet exemple, le budget de disponibilité est établi pour un environnement LAN modulaire hiérarchique. L'environnement utilise des générateurs de secours et des systèmes UPS pour tous les composants du réseau et gère correctement l'alimentation. L'entreprise n'utilise pas la VoIP et ne souhaite pas prendre en compte le temps de commutation logicielle. Les estimations sont les suivantes :
-
Disponibilité du chemin matériel entre deux points d'extrémité = disponibilité de 99,99 %
-
Disponibilité logicielle utilisant la fiabilité du logiciel GD comme référence = disponibilité de 99,9999 %
-
Disponibilité environnementale et énergétique avec systèmes de sauvegarde = disponibilité de 99,999 %
-
Panne de liaison dans un environnement LAN = disponibilité de 99,9999 %
-
Temps de commutation système non pris en compte = disponibilité à 100 %
-
Erreur utilisateur et disponibilité des processus supposés parfaite = disponibilité à 100 %
Le budget de disponibilité final que les organisations doivent s'efforcer d'atteindre est égal à 0,99999 X 0,999999 X 0,99999 X 0,999999 = 0,999896, soit une disponibilité de 99,9896 %. Si nous prenons en compte la non-disponibilité potentielle en raison d'une erreur d'utilisateur ou de processus et supposons que la non-disponibilité est 4 fois supérieure à la disponibilité en raison de facteurs techniques, nous pouvons supposer que le budget de disponibilité est de 99,95 %.
Cette analyse d'exemple indique que la disponibilité du réseau local diminuerait en moyenne entre 99,95 et 99,989 %. Ces numéros peuvent désormais servir d'objectif de niveau de service pour l'organisation réseau. Vous pouvez obtenir une valeur supplémentaire en mesurant la disponibilité dans le système et en déterminant le pourcentage de non-disponibilité dû à chacune des six zones ci-dessus. Cela permet à l'entreprise d'évaluer correctement les fournisseurs, les opérateurs, les processus et le personnel. Ce nombre peut également être utilisé pour définir les attentes au sein de l'entreprise. Si le nombre est inacceptable, alors budgétisez des ressources supplémentaires pour obtenir les niveaux souhaités.
Il peut s’avérer utile pour les administrateurs réseau de comprendre la durée d’indisponibilité à un niveau de disponibilité particulier. Le temps d'arrêt en minutes pendant une période d'un an, quel que soit le niveau de disponibilité, est le suivant :
Minutes d'indisponibilité en un an = 525600 - (niveau de disponibilité X 5256)
Si vous utilisez le niveau de disponibilité de 99,95 %, cela revient à 525600 - (99,95 X 5256), soit 262,8 minutes d'arrêt. Pour la définition de disponibilité ci-dessus, ceci est égal à la durée moyenne d'arrêt de toutes les connexions en service au sein du réseau.
-
Étape 3 : Créer des profils d'application
Les profils d'application aident l'organisation réseau à comprendre et à définir les exigences de niveau de service réseau pour les applications individuelles. Cela permet de s'assurer que le réseau prend en charge les besoins individuels des applications et les services réseau dans leur ensemble. Les profils d'application peuvent également servir de base documentée pour la prise en charge des services réseau lorsque des groupes d'applications ou de serveurs pointent le problème sur le réseau. En fin de compte, les profils d'application permettent d'aligner les objectifs de service réseau avec les exigences des applications ou de l'entreprise en comparant les exigences des applications telles que les performances et la disponibilité avec des objectifs réalistes de service réseau ou les limites actuelles. Cela est important non seulement pour la gestion des niveaux de service, mais également pour la conception globale du réseau descendant.
Créez des profils d'application chaque fois que vous introduisez de nouvelles applications sur le réseau. Il se peut que vous ayez besoin d'un accord entre le groupe d'applications informatiques, les groupes d'administration des serveurs et la mise en réseau pour appliquer la création de profils d'application pour les services nouveaux et existants. Complétez les profils d'application pour les applications métier et les applications système. Les applications métier peuvent inclure le courrier électronique, le transfert de fichiers, la navigation sur le Web, l'imagerie médicale ou la fabrication. Les applications système peuvent inclure la distribution de logiciels, l'authentification des utilisateurs, la sauvegarde du réseau et la gestion du réseau.
Un analyste réseau et une application de support d'application ou de serveur doivent créer le profil d'application. Les nouvelles applications peuvent nécessiter l'utilisation d'un analyseur de protocole et d'un émulateur de réseau étendu avec émulation de délai pour caractériser correctement les exigences des applications. Cela permet d'identifier la bande passante nécessaire, le délai maximal d'utilisation des applications et les besoins en gigue. Cela peut être fait dans un environnement de travaux pratiques tant que vous disposez des serveurs requis. Dans d'autres cas, comme pour la VoIP, les exigences réseau, notamment la gigue, le délai et la bande passante, sont bien publiées et les tests en laboratoire ne seront pas nécessaires. Un profil d'application doit inclure les éléments suivants :
-
Nom de l'application
-
Type d'application
-
Nouvelle application ?
-
Importance de l'entreprise
-
Exigences de disponibilité
-
Protocoles et ports utilisés
-
Bande passante utilisateur estimée (kbits/s)
-
Nombre et emplacement des utilisateurs
-
Configuration requise pour le transfert de fichiers (temps, volume et terminaux compris)
-
Impact des pannes de réseau
-
Délai, gigue et exigences de disponibilité
L'objectif du profil d'application est de comprendre les besoins de l'entreprise en termes d'applications, de criticité de l'entreprise et de réseau, tels que la bande passante, le délai et la gigue. En outre, l’organisation réseau doit comprendre l’impact des temps d’arrêt du réseau. Dans certains cas, vous aurez besoin de redémarrages d'applications ou de serveurs qui augmentent considérablement les temps d'arrêt globaux des applications. Une fois le profil d'application terminé, vous pouvez comparer les capacités globales du réseau et vous aider à aligner les niveaux de service réseau sur les exigences de l'entreprise et des applications.
Étape 4 : Définir les normes de disponibilité et de performances
Les normes de disponibilité et de performances définissent les attentes en matière de service pour l'entreprise. Elles peuvent être définies pour différentes zones du réseau ou pour des applications spécifiques. Les performances peuvent également être définies en termes de délai aller-retour, de gigue, de débit maximal, d'engagements de bande passante et d'évolutivité globale. En plus de définir les attentes en matière de service, l'entreprise doit également prendre soin de définir chacune des normes de service afin que les utilisateurs et les groupes informatiques travaillant sur le réseau comprennent parfaitement la norme de service et son lien avec leurs exigences en matière d'administration des applications ou des serveurs. Les groupes d'utilisateurs et d'informaticiens doivent également comprendre comment mesurer la norme de service.
Les résultats des étapes précédentes de définition du niveau de service aideront à créer la norme. À ce stade, l'organisation réseau doit avoir une compréhension claire des risques et des contraintes actuels du réseau, une compréhension du comportement des applications et une analyse théorique de la disponibilité ou de la base de disponibilité.
-
Définissez les zones géographiques ou les zones d'application où les normes de service seront appliquées.
Cela peut inclure des domaines tels que le LAN du campus, le WAN domestique, l'extranet ou la connectivité des partenaires. Dans certains cas, l'organisation peut avoir des objectifs de niveau de service différents dans un domaine. Cela n'est pas rare pour les entreprises ou les fournisseurs de services. Dans ces cas, il n'est pas rare de créer des normes de niveau de service différentes en fonction des besoins de chaque service. Ils peuvent être classés comme étalons de service en or, en argent et en bronze dans une zone géographique ou une zone de service.
-
Définissez les paramètres de la norme de service.
La disponibilité et le délai aller-retour sont les normes de service réseau les plus courantes. Le débit maximal, l'engagement de bande passante minimale, la gigue, les taux d'erreur acceptables et les capacités d'évolutivité peuvent également être inclus selon les besoins. Soyez prudent lorsque vous examinez le paramètre de service pour les méthodes de mesure. Que le paramètre passe ou non à un SLA, l'entreprise doit réfléchir à la façon dont le paramètre de service peut être mesuré ou justifié en cas de problèmes ou de désaccords de service.
Après avoir défini les zones de service et les paramètres de service, utilisez les informations des étapes précédentes pour créer une matrice de normes de service. L'entreprise devra également définir des domaines qui peuvent prêter à confusion pour les utilisateurs et les groupes informatiques. Par exemple, le temps de réponse maximal sera très différent pour une requête ping aller-retour que pour appuyer sur la touche Entrée à un emplacement distant pour une application spécifique. Le tableau ci-dessous présente les objectifs de performance aux États-Unis.
| Zone réseau | Cible de disponibilité | Méthode de mesure | Temps de réponse moyen du réseau | Délai de réponse max. accepté | Méthode de mesure du temps de réponse |
|---|---|---|---|---|---|
| LAN | 99.99% | Minutes utilisateur affectées | Moins de 5 ms | 10 ms | Réponse ping aller-retour |
| Réseau WAN | 99.99% | Minutes utilisateur affectées | Moins de 100 ms (ping aller-retour) | 150 ms | Réponse ping aller-retour |
| WAN et extranet critiques | 99.99% | Minutes utilisateur affectées | Moins de 100 ms (ping aller-retour) | 150 ms | Réponse ping aller-retour |
Étape 5 : Définir un service réseau
Il s'agit de la dernière étape vers la gestion de base du niveau de service ; il définit les processus réactifs et proactifs et les capacités de gestion du réseau que vous mettez en oeuvre pour atteindre les objectifs de niveau de service. Le document final est généralement appelé plan de soutien des opérations. La plupart des plans d'assistance d'applications ne comportent que des exigences d'assistance réactives. Dans les environnements à haute disponibilité, l'entreprise doit également envisager des processus de gestion proactive qui seront utilisés pour isoler et résoudre les problèmes réseau avant le lancement des appels de service utilisateur. Dans l'ensemble, le document final devrait :
-
Décrire le processus réactif et proactif utilisé pour atteindre l'objectif de niveau de service
-
Gestion du processus de service
-
Comment l'objectif de service et le processus de service seront mesurés.
Cette section contient des exemples de définitions de services réactifs et de services proactifs à prendre en compte pour de nombreuses entreprises et fournisseurs de services. L'objectif de la définition des niveaux de service est de créer un service qui réponde aux objectifs de disponibilité et de performances. Pour ce faire, l'entreprise doit concevoir le service en tenant compte des contraintes techniques actuelles, du budget de disponibilité et des profils d'application. Plus précisément, l'entreprise doit définir et créer un service qui identifie et résout rapidement et de manière cohérente les problèmes dans les délais alloués par le modèle de disponibilité. L'entreprise doit également définir un service capable d'identifier et de résoudre rapidement les problèmes de service potentiels qui auront un impact sur la disponibilité et les performances si ignorés.
Vous n'atteindrez pas le niveau de service souhaité du jour au lendemain. Des lacunes telles que le manque d'expertise, les limites actuelles des processus ou des niveaux de dotation insuffisants peuvent empêcher l'organisation d'atteindre les normes ou les objectifs souhaités, même après les étapes précédentes de l'analyse des services. Il n'existe pas de méthode précise permettant de faire correspondre exactement le niveau de service requis aux objectifs souhaités. Pour ce faire, l'organisation doit mesurer les normes de service et les paramètres de service utilisés pour appuyer les normes de service. Lorsque l'entreprise ne répond pas aux objectifs de service, elle doit alors se tourner vers les indicateurs de service pour mieux comprendre le problème. Dans de nombreux cas, des augmentations budgétaires peuvent être apportées pour améliorer les services d'appui et apporter les améliorations nécessaires pour atteindre les objectifs de service souhaités. Au fil du temps, l'entreprise peut effectuer plusieurs ajustements, soit à l'objectif du service, soit à la définition du service, afin d'aligner les besoins en services réseau et commerciaux.
Par exemple, une entreprise peut atteindre une disponibilité de 99 % lorsque l'objectif est beaucoup plus élevé avec une disponibilité de 99,9 %. Lorsqu'ils ont examiné les indicateurs de service et d'assistance, les représentants de l'organisation ont constaté que le remplacement du matériel prenait environ 24 heures, soit beaucoup plus que l'estimation initiale, car l'organisation n'en avait prévu que quatre. En outre, l'entreprise a constaté que les capacités de gestion proactive étaient ignorées et que les périphériques réseau redondants n'étaient pas réparés. Ils ont également constaté qu'ils n'avaient pas le personnel nécessaire pour apporter des améliorations. Par conséquent, après avoir envisagé de réduire les objectifs actuels en matière de services, l'organisation a prévu des ressources supplémentaires pour atteindre le niveau de service souhaité.
Les définitions de service doivent inclure à la fois des définitions de support réactif et des définitions proactives. Les définitions réactives définissent la manière dont l'organisation réagira aux problèmes une fois qu'ils auront été identifiés à partir des plaintes des utilisateurs ou des capacités de gestion du réseau. Des définitions proactives décrivent comment l'entreprise identifiera et résoudra les problèmes réseau potentiels, notamment la réparation des composants réseau en veille défectueux, la détection des erreurs, les seuils de capacité et les mises à niveau. Les sections suivantes fournissent des exemples de définitions de niveaux de service réactifs et proactifs.
Définitions des niveaux de service réactifs
Les zones de niveau de service suivantes sont généralement mesurées à l'aide de statistiques de base de données du centre d'assistance et d'audits périodiques. Ce tableau présente un exemple de gravité de problème pour une organisation. Notez que le tableau ne montre pas comment traiter les demandes de nouveau service, qui peuvent être traitées par un contrat de niveau de service ou par une analyse détaillée des performances et du profilage des applications supplémentaires. Généralement, la gravité 5 peut être une demande de nouveau service si elle est traitée via le même processus d'assistance.
| Gravité 1 | Gravité 2 | Gravité 3 | Gravité 4 |
|---|---|---|---|
| Impact important sur l'entreprise Utilisateur LAN ou segment de serveur sur le site WAN critique désactivé | Impact important sur l'entreprise en cas de perte ou de dégradation, solution de contournement possible sur le réseau local du campus ; 5 à 99 utilisateurs ont affecté le site de réseau étendu domestique sur le site de réseau étendu international en panne Impact critique sur les performances | Certaines fonctionnalités réseau spécifiques sont perdues ou dégradées, telles que la perte de redondance, les performances LAN du campus ont affecté la perte de redondance LAN. | Requête ou erreur fonctionnelle sans impact sur l'entreprise |
Lorsque la gravité du problème a été définie, définissez ou analysez le processus d'assistance pour créer des définitions de réponse de service. En règle générale, les définitions de la réponse aux services nécessitent une structure d'assistance à plusieurs niveaux associée à un système d'assistance logicielle du centre d'assistance pour suivre les problèmes via des tickets d'incident. Des mesures doivent également être disponibles sur le temps de réponse et le temps de résolution pour chaque priorité, le nombre d'appels par priorité et la qualité de réponse/résolution. Pour définir le processus d'assistance, il permet de définir les objectifs de chaque niveau d'assistance dans l'organisation, ainsi que leurs rôles et responsabilités. Cela aide l'entreprise à comprendre les besoins en ressources et les niveaux d'expertise pour chaque niveau d'assistance. Le tableau suivant présente un exemple d'organisation d'assistance à plusieurs niveaux avec des directives de résolution des problèmes.
| Niveau d'assistance | Responsabilité | Objectifs |
|---|---|---|
| Assistance de niveau 1 | Assistance technique à temps plein Répondre aux appels d'assistance, passer des tickets d'incident, résoudre le problème pendant 15 minutes maximum, documenter le ticket et passer à l'assistance de niveau 2 appropriée | Résolution de 40 % des appels entrants |
| Assistance de niveau 2 | Surveillance de la file d'attente, gestion du réseau, surveillance de la station Placer des dossiers d'incident pour les problèmes identifiés par le logiciel Implémenter Prendre des appels de niveau 1, fournisseur et niveau 3 Assumer la propriété de l'appel jusqu'à la résolution | Résolution de 100 % des appels au niveau 2 |
| Assistance de niveau 3 | Doit fournir une assistance immédiate à la couche 2 pour tous les problèmes de priorité 1 Accepter d'aider à résoudre tous les problèmes non résolus par la couche 2 au cours de la période de résolution SLA | Pas de propriété de problème direct |
L'étape suivante consiste à créer la matrice pour la définition de service de réponse et de résolution de service. Cela définit les objectifs de la rapidité avec laquelle les problèmes sont résolus, y compris le remplacement du matériel. Il est important de définir des objectifs dans ce domaine, car le temps de réponse et le temps de récupération des services affectent directement la disponibilité du réseau. Les délais de résolution des problèmes doivent également être alignés sur le budget de disponibilité. Si le budget de disponibilité ne tient pas compte d'un grand nombre de problèmes de grande gravité, l'organisation peut alors chercher à comprendre la source de ces problèmes et une solution possible. Reportez-vous au tableau suivant :
| Gravité du problème | Réponse du centre d'assistance | Réponse de niveau 2 | Niveau 2 sur site | Remplacement de matériel | Résolution des problèmes |
|---|---|---|---|---|---|
| 1 | Transfert immédiat vers le niveau 2, responsable des opérations réseau | 5 minutes | 2 heures | 2 heures | 4 heures |
| 2 | Transfert immédiat vers le niveau 2, responsable des opérations réseau | 5 minutes | 4 heures | 4 heures | 8 heures |
| 3 | 15 minutes | 2 heures | 12 heures | 24 heures | 36 heures |
| 4 | 15 minutes | 4 heures | 3 jours | 3 jours | 6 jours |
En plus de la réponse au service et de la résolution du service, créez une matrice pour l'escalade. La matrice d'escalade permet de s'assurer que les ressources disponibles sont concentrées sur les problèmes qui affectent gravement le service. En général, lorsque les analystes se concentrent sur la résolution des problèmes, ils se concentrent rarement sur l'apport de ressources supplémentaires sur le problème. La définition du moment où des ressources supplémentaires doivent être notifiées contribue à promouvoir la sensibilisation aux problèmes dans la gestion et peut généralement aider à mener à des mesures proactives ou préventives futures. Reportez-vous au tableau suivant :
| Temps écoulé | Gravité 1 | Gravité 2 | Gravité 3 | Gravité 4 |
|---|---|---|---|---|
| 5 minutes | Responsable des opérations réseau, support de niveau 3, directeur des réseaux | |||
| 1 heure | Mise à jour vers le responsable des opérations réseau, support de niveau 3, directeur des réseaux | Mise à jour vers le responsable des opérations réseau, support de niveau 3, directeur des réseaux | ||
| 2 heures | Transférer au vice-président, mettre à jour au directeur, responsable des opérations | |||
| 4 heures | Analyse des causes premières pour le vice-président, le directeur, le responsable des opérations, l'assistance de niveau 3, non résolu nécessite une notification du PDG | Transférer au vice-président, mettre à jour au directeur, responsable des opérations | ||
| 24 heures | Responsable des opérations réseau | |||
| 5 jours | Responsable des opérations réseau |
Jusqu'à présent, les définitions des niveaux de service ont porté sur la manière dont l'organisation d'appui opérationnel réagit aux problèmes après leur identification. Depuis des années, les organisations opérationnelles ont élaboré des plans de soutien opérationnel contenant des renseignements semblables à ceux qui précèdent. Toutefois, il manque dans ces cas la façon dont l'organisation identifiera les problèmes et les problèmes qu'elle identifiera. Les organisations réseau plus sophistiquées ont tenté de résoudre ce problème en se contentant de créer des objectifs pour le pourcentage de problèmes identifiés de manière proactive, par opposition aux problèmes identifiés de manière réactive par le rapport de problèmes ou la plainte des utilisateurs.
Le tableau suivant montre comment une entreprise peut vouloir mesurer les capacités d'assistance proactive et l'assistance proactive dans son ensemble.
| Zone réseau | Rapport proactif d'identification des problèmes | Taux d'identification des problèmes réactifs |
|---|---|---|
| LAN | 80 % | 20 % |
| Réseau WAN | 80 % | 20 % |
C'est un bon début pour définir des définitions d'assistance plus proactives car il est simple et assez facile à mesurer, surtout si les outils proactifs génèrent automatiquement des tickets de pannes. Cela permet également de concentrer les outils/informations de gestion du réseau sur la résolution proactive des problèmes plutôt que de les aider à résoudre la cause première. Cependant, le principal problème de cette méthode est qu'elle ne définit pas les besoins de support proactif. Cela crée généralement des lacunes dans les capacités de gestion proactive de l'assistance et entraîne des risques de disponibilité supplémentaires.
Définitions proactives des niveaux de service
Une méthodologie plus complète pour la création de définitions de niveau de service inclut des informations plus détaillées sur la manière dont le réseau est surveillé et comment l'organisation opérationnelle réagit aux seuils définis de station de gestion de réseau (NMS) sur une base 7 x 24. Cela peut sembler impossible étant donné le nombre de variables de base MIB (Management Information Base) et la quantité d'informations de gestion du réseau disponibles qui sont pertinentes pour l'intégrité du réseau. Il pourrait également être extrêmement coûteux et gourmand en ressources. Malheureusement, ces objections empêchent de nombreux utilisateurs de mettre en oeuvre une définition de service proactive qui, par nature, doit être simple, assez facile à suivre et applicable uniquement aux risques de disponibilité ou de performances les plus élevés du réseau. Si une organisation voit alors de la valeur dans les définitions de base des services proactifs, il est possible d'ajouter plus de variables au fil du temps sans impact significatif, à condition de mettre en oeuvre une approche progressive.
Inclure le premier domaine des définitions de services proactifs dans tous les plans d'assistance des opérations. La définition de service indique simplement comment le groupe d'opérations identifiera et réagira proactivement aux conditions de réseau ou de liaison dans différentes zones du réseau. Sans cette définition (ou prise en charge de la gestion), l'entreprise peut s'attendre à une prise en charge variable, à des attentes irréalistes de l'utilisateur et, en fin de compte, à une disponibilité du réseau réduite.
Le tableau suivant montre comment une organisation peut créer une définition de service pour les conditions de liaison/désactivation de périphérique. L'exemple montre une organisation d'entreprise qui peut avoir des besoins de notification et de réponse différents en fonction de l'heure et de la zone du réseau.
| Périphérique réseau ou liaison inactive | Méthode de détection | Notification 5 x 8 | Notification 7 x 24 | Résolution 5 x 8 | Résolution 7 x 24 |
|---|---|---|---|---|---|
| LAN principal | Intervalles de liaison et de périphérique SNMP | NOC crée un rapport d'incident, page LAN-service pager | Pager de service LAN de la page automatique, le responsable LAN crée un rapport d'incident pour la file d'attente LAN principale | Analyste LAN affecté dans les 15 minutes par NOC, réparation conformément à la définition de réponse de service | Priorités 1 et 2 Recherche et résolution immédiates Priorités 3 et 4 File d'attente pour résolution matinale |
| WAN domestique | Intervalles de liaison et de périphérique SNMP | NOC crée un rapport d'incident, page Pager de service WAN | Pager d'utilisation WAN de page automatique, responsable WAN, création d'un rapport d'incident pour la file d'attente WAN | Analyste WAN affecté dans un délai de 15 minutes par NOC, réparation conformément à la définition de réponse de service | Priorités 1 et 2 Recherche et résolution immédiates Priorités 3 et 4 File d'attente pour résolution matinale |
| Extranet | Intervalles de liaison et de périphérique SNMP | NOC crée un rapport d'incident, pager de service pour les partenaires de page | Pager de service pour les partenaires de la page automatique, le responsable des services pour les partenaires crée un rapport d'incident pour la file d'attente des partenaires | Analyste partenaire affecté dans un délai de 15 minutes par centre d'exploitation de réseau (NOC), réparation conformément à la définition de réponse de service | Priorités 1 et 2 : enquête et résolution immédiates ; File d'attente des priorités 3 et 4 pour la résolution matinale |
Les autres définitions de niveau de service proactif peuvent être divisées en deux catégories : erreurs réseau et problèmes de capacité/performances. Seul un faible pourcentage des organisations réseau disposent de définitions de niveau de service dans ces domaines. Par conséquent, ces questions sont ignorées ou traitées de manière sporadique. Cela peut être correct dans certains environnements réseau, mais les environnements à haute disponibilité nécessitent généralement une gestion proactive des services cohérente.
Les organisations de réseau ont tendance à éprouver des difficultés à définir des services proactifs pour plusieurs raisons. Cela s'explique principalement par le fait qu'ils n'ont pas effectué d'analyse des besoins pour les définitions de services proactifs en fonction des risques de disponibilité, du budget de disponibilité et des problèmes d'applications. Il en résulte des exigences floues en matière de définitions proactives des services et des avantages incertains, en particulier parce que des ressources supplémentaires peuvent être nécessaires.
La deuxième raison consiste à équilibrer la quantité de gestion proactive qui peut être effectuée avec les ressources existantes ou nouvellement définies. Générer uniquement les alertes qui ont un impact potentiel important sur la disponibilité ou les performances. Vous devez également prendre en compte la gestion ou les processus de corrélation des événements pour vous assurer que plusieurs dossiers d'incidents proactifs ne sont pas générés pour le même problème. La dernière raison pour laquelle les entreprises peuvent éprouver des difficultés est que la création d'un nouvel ensemble d'alertes proactives peut souvent générer un flux initial de messages qui n'ont pas été détectés auparavant. Le groupe opérationnel doit être préparé pour ce flot initial de problèmes et de ressources supplémentaires à court terme afin de corriger ou de résoudre ces conditions non détectées auparavant.
La première catégorie de définitions de niveau de service proactif est constituée d’erreurs réseau. Les erreurs réseau peuvent être subdivisées en erreurs système comprenant des erreurs logicielles ou matérielles, des erreurs de protocole, des erreurs de contrôle des supports, des erreurs de précision et des avertissements environnementaux. L'élaboration d'une définition du niveau de service commence par une compréhension générale de la manière dont ces conditions de problème seront détectées, de qui les examinera et de ce qui se produira lorsqu'elles surviendront. Ajoutez des messages ou des problèmes spécifiques à la définition du niveau de service si besoin est. Vous pouvez également avoir besoin de travail supplémentaire dans les domaines suivants pour garantir la réussite :
-
Responsabilités d'assistance des niveaux 1, 2 et 3
-
Équilibrer la priorité des informations de gestion du réseau avec la quantité de travail proactif que le groupe opérationnel peut gérer efficacement
-
Besoins en formation pour garantir que le personnel d'assistance peut gérer efficacement les alertes définies
-
Méthodes de corrélation des événements pour s'assurer que plusieurs tickets d'incident ne sont pas générés pour la même cause racine du problème
-
Documentation sur des messages ou des alertes spécifiques qui aident à identifier les événements au niveau d'assistance de niveau 1
Le tableau suivant présente un exemple de définition de niveau de service pour les erreurs réseau qui permet de comprendre clairement qui est responsable des alertes d'erreur réseau proactives, comment le problème sera identifié et ce qui se passera lorsque le problème se produira. Il se peut que l'organisation ait encore besoin d'efforts supplémentaires tels que définis ci-dessus pour assurer son succès
art.
| Catégorie d'erreur | Méthode de détection | Seuil | Mesure prise |
|---|---|---|---|
| Erreurs logicielles (plantages forcés par le logiciel) | Examen quotidien des messages syslog à l'aide de la visionneuse syslog Terminé par la prise en charge de niveau 2 | Toute occurrence de priorité 0, 1 et 2 Plus de 100 occurrences de niveau 3 ou supérieur | Examiner le problème, créer un rapport d'incident et envoyer le message si une nouvelle occurrence ou un problème nécessite une attention particulière |
| Erreurs matérielles (plantages forcés par le matériel) | Examen quotidien des messages syslog à l'aide de la visionneuse syslog Terminé par la prise en charge de niveau 2 | Toute occurrence de priorité 0, 1 et 2 Plus de 100 occurrences de niveau 3 ou supérieur | Examiner le problème, créer un rapport d'incident et envoyer le message si une nouvelle occurrence ou un problème nécessite une attention particulière |
| Erreurs de protocole (protocoles de routage IP uniquement) | Examen quotidien des messages syslog à l'aide de la visionneuse syslog Terminé par la prise en charge de niveau 2 | Dix messages par jour de priorités 0, 1 et 2 Plus de 100 occurrences de niveau 3 ou supérieur | Examiner le problème, créer un rapport d'incident et envoyer le message si une nouvelle occurrence ou un problème nécessite une attention particulière |
| Erreurs de contrôle de support (FDDI, POS et Fast Ethernet uniquement) | Examen quotidien des messages syslog à l'aide de la visionneuse syslog Terminé par la prise en charge de niveau 2 | Dix messages par jour de priorités 0, 1 et 2 Plus de 100 occurrences de niveau 3 ou supérieur | Examiner le problème, créer un rapport d'incident et envoyer le message si une nouvelle occurrence ou un problème nécessite une attention particulière |
| Messages environnementaux (puissance et température) | Examen quotidien des messages syslog à l'aide de la visionneuse syslog Terminé par la prise en charge de niveau 2 | Tout message | Créer un rapport d'incident et envoyer pour les nouveaux problèmes |
| Erreurs de précision (erreurs d'entrée de liaison) | Interrogation SNMP à intervalles de 5 minutes Événements de seuil reçus par le NOC | Erreurs d'entrée ou de sortie Une erreur dans un intervalle de 5 minutes sur une liaison | Créer un rapport d'incident pour les nouveaux problèmes et envoyer le dossier à l'assistance de niveau 2 |
L'autre catégorie de définitions de niveau de service proactif s'applique aux performances et à la capacité. La véritable gestion des performances et des capacités inclut la gestion des exceptions, la mise en base et les tendances, ainsi que l'analyse des scénarios. La définition du niveau de service définit simplement les seuils d'exception de performances et de capacité et les seuils moyens qui déclencheront une enquête ou une mise à niveau. Ces seuils peuvent ensuite s'appliquer d'une manière ou d'une autre aux trois processus de gestion des performances et des capacités.
Les définitions des niveaux de capacité et de performance peuvent être réparties en plusieurs catégories : les liaisons réseau, les périphériques réseau, les performances de bout en bout et les performances des applications. L'élaboration de définitions de niveau de service dans ces domaines nécessite des connaissances techniques approfondies sur des aspects spécifiques de la capacité des périphériques, de la capacité des supports, des caractéristiques de QoS et des exigences des applications. C'est pourquoi nous recommandons aux architectes réseau de développer des définitions de niveaux de service liées aux performances et aux capacités avec l'apport du fournisseur.
Comme pour les erreurs réseau, l'élaboration d'une définition de niveau de service pour la capacité et les performances commence par une compréhension générale de la manière dont ces conditions de problème seront détectées, de qui les examinera et de ce qui se passera lorsqu'elles se produiront. Vous pouvez ajouter des définitions d'événements spécifiques à la définition de niveau de service si nécessaire. Vous pouvez également avoir besoin de travail supplémentaire dans les domaines suivants pour garantir la réussite :
-
Compréhension claire des exigences en matière de performances applicatives
-
Étude technique approfondie sur les valeurs de seuil qui conviennent à l'entreprise en fonction des besoins de l'entreprise et des coûts globaux
-
Besoins en termes de cycle budgétaire et de mise à niveau hors cycle
-
Responsabilités d'assistance des niveaux 1, 2 et 3
-
Priorité et importance des informations de gestion du réseau, en équilibre avec la quantité de travail proactif que le groupe opérationnel peut gérer efficacement
-
Exigences en matière de formation pour s'assurer que le personnel d'assistance comprend les messages ou les alertes et peut traiter efficacement la condition définie
-
Méthodes ou processus de corrélation d'événements pour s'assurer que plusieurs dossiers d'incident ne sont pas générés pour la même cause racine du problème
-
Documentation sur des messages ou alertes spécifiques qui aident à identifier les événements au niveau d'assistance de niveau 1
Le tableau suivant présente un exemple de définition de niveau de service pour l'utilisation des liaisons qui permet de comprendre clairement qui est responsable des alertes d'erreur réseau proactives, comment le problème sera identifié et ce qui se produira lorsque le problème se produira. Il se peut que l'organisation ait encore besoin d'efforts supplémentaires tels que définis ci-dessus pour assurer le succès.
| Zone réseau/support | Méthode de détection | Seuil | Mesure prise |
|---|---|---|---|
| Réseau fédérateur LAN du campus et liaisons de distribution | Interrogation SNMP à intervalles de 5 minutes Interruptions d'exception RMON sur les liaisons principales et de distribution | 50 % d'utilisation par intervalles de 5 minutes 90 % d'utilisation via le déroutement d'exception | Notification par e-mail au groupe d'alias de messagerie de performance pour évaluer les exigences de QoS ou planifier la mise à niveau pour les problèmes récurrents |
| Liaisons WAN nationales | Interrogation SNMP à intervalles de 5 minutes | Utilisation de 75 % par intervalles de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance pour évaluer les exigences de QoS ou planifier la mise à niveau pour les problèmes récurrents |
| Liaisons WAN extranet | Interrogation SNMP à intervalles de 5 minutes | Utilisation de 60 % par intervalles de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance pour évaluer les exigences de QoS ou planifier la mise à niveau pour les problèmes récurrents |
Le tableau suivant définit les définitions de niveau de service pour les seuils de capacité et de performances des périphériques. Assurez-vous de créer des seuils utiles et utiles pour prévenir les problèmes de réseau ou de disponibilité. Il s'agit d'un domaine très important, car les problèmes de ressources du plan de contrôle des périphériques non vérifiés peuvent avoir un impact important sur le réseau.
| Cisco 7500 | CPU, mémoire, tampons | Interrogation SNMP à intervalles de -5 minutes Notification RMON pour CPU | Processeur à 75 % pendant les intervalles de 5 minutes, 99 % via la mémoire de notification RMON à 50 % pendant les intervalles de 5 minutes Tampons à 99 % d'utilisation | Notification par e-mail au groupe d'alias de messagerie de performances et de capacité pour résoudre les problèmes ou planifier la mise à niveau du CPU RMON à 99 %, placer le rapport d'incident et le pager d'assistance de niveau 2 de la page |
| Cisco 2600 | CPU, mémoire | Interrogation SNMP à intervalles de 5 minutes | Processeur à 75 % pendant les intervalles de 5 minutes Mémoire à 50 % pendant les intervalles de 5 minutes | Notification par e-mail au groupe d'alias d'e-mails de performances et de capacité pour résoudre les problèmes ou planifier la mise à niveau |
| Catalyst 5000 | Utilisation du fond de panier, mémoire | Interrogation SNMP à intervalles de 5 minutes | Fond de panier à 50 % d'utilisation Mémoire à 75 % d'utilisation | Notification par e-mail au groupe d'alias d'e-mails de performances et de capacité pour résoudre les problèmes ou planifier la mise à niveau |
| Commutateur ATM LightStream® 1010 | CPU, mémoire | Interrogation SNMP à intervalles de 5 minutes | CPU à 65 % utilisation Mémoire à 50 % utilisation | Notification par e-mail au groupe d'alias d'e-mails de performances et de capacité pour résoudre les problèmes ou planifier la mise à niveau |
Le tableau suivant définit les définitions de niveau de service pour les performances et la capacité de bout en bout. Ces seuils sont généralement basés sur les exigences des applications, mais peuvent également être utilisés pour indiquer un type de problème de performances ou de capacité du réseau. La plupart des entreprises disposant de définitions de niveau de service pour les performances ne créent qu'une poignée de définitions de performances, car la mesure des performances de chaque point du réseau à chaque autre point nécessite des ressources importantes et crée une forte surcharge du réseau. Ces problèmes de performances de bout en bout peuvent également être pris en compte dans les seuils de capacité des liaisons ou des périphériques. Nous recommandons des définitions générales par zone géographique. Certains sites ou liens critiques peuvent être ajoutés si nécessaire.
| Zone réseau/support | Méthode de mesure | Seuil | Mesure prise |
|---|---|---|---|
| LAN du campus | Aucun problème attendu Difficile de mesurer l’ensemble de l’infrastructure LAN | Temps de réponse aller-retour de 10 millisecondes ou moins en tout temps | Notification par e-mail au groupe d'alias de messagerie de performances et de capacité pour résoudre le problème ou planifier la mise à niveau |
| Liaisons WAN nationales | Mesure actuelle de SF à NY et SF à Chicago uniquement à l'aide de l'écho ICMP IPM (Internet Performance Monitor) | Temps moyen de réponse aller-retour de 75 millisecondes sur une période de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance afin d'évaluer les exigences de QoS ou de planifier la mise à niveau pour les problèmes récurrents |
| San Francisco à Tokyo | Mesure actuelle de San Francisco à Bruxelles à l’aide de l’écho IPM et ICMP | Temps moyen de réponse aller-retour de 250 millisecondes sur une période de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance afin d'évaluer les exigences de QoS ou de planifier la mise à niveau pour les problèmes récurrents |
| San Francisco à Bruxelles | Mesure actuelle de San Francisco à Bruxelles à l’aide de l’écho IPM et ICMP | Temps moyen de réponse de 175 millisecondes sur une période de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance afin d'évaluer les exigences de QoS ou de planifier la mise à niveau pour les problèmes récurrents |
La dernière zone des définitions de niveau de service concerne les performances des applications. Les définitions de niveau de service des performances des applications sont normalement créées par l'application ou le groupe d'administration des serveurs, car les performances et la capacité des serveurs eux-mêmes sont probablement le facteur le plus important dans les performances des applications. Les entreprises réseau peuvent tirer un grand avantage de la création de définitions de niveau de service pour les performances des applications réseau, car :
-
les définitions et les mesures des niveaux de service peuvent aider à éliminer les conflits entre les groupes.
-
Les définitions de niveau de service pour les applications individuelles sont importantes si la QoS est configurée pour les applications clés et si d'autres trafics sont considérés comme facultatifs.
Si vous choisissez de créer et de mesurer les performances des applications, il est probablement préférable de ne pas mesurer les performances sur le serveur lui-même. Cela permet ensuite de distinguer les problèmes de réseau des problèmes d'application ou de serveur. Utilisez des sondes ou le logiciel de l'agent de disponibilité du système exécuté sur les routeurs Cisco et le module Cisco IPM contrôlant le type de paquet et la fréquence de mesure.
Le tableau suivant présente une définition simple du niveau de service pour les performances des applications.
| Application | Méthode de mesure | Seuil | Mesure prise |
|---|---|---|---|
| Application ERP (Enterprise Resource Planning) Port TCP 1529 Bruxelles vers SF | Bruxelles à San Francisco à l'aide de l'IPM mesurant les performances du port 1529 aller-retour passerelle Bruxelles vers passerelle SFO 2 | Temps moyen de réponse de 175 millisecondes sur une période de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance pour évaluer le problème ou planifier la mise à niveau pour les problèmes récurrents |
| Port TCP d'application ERP 1529 Tokyo vers SF | Bruxelles à San Francisco à l'aide de l'IPM mesurant les performances du port 1529 aller-retour passerelle Bruxelles vers passerelle SFO 2 | Temps moyen de réponse de 200 millisecondes sur une période de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance pour évaluer le problème ou planifier la mise à niveau pour les problèmes récurrents |
| Application d'assistance à la clientèle Port TCP 1702 Sydney vers SF | Sydney-San Francisco à l’aide du port de mesure IPM 1702, performances aller-retour Passerelle Sydney-passerelle SFO 1 | Temps moyen de réponse aller-retour de 250 millisecondes sur une période de 5 minutes | Notification par e-mail au groupe d'alias de messagerie de performance pour évaluer le problème ou planifier la mise à niveau pour les problèmes récurrents |
Étape 6 : Collecter les mesures et surveiller
les définitions de niveau de service ne valent rien à elles seules, à moins que l'organisation ne recueille des indicateurs et ne surveille la réussite. Lors de la création d'une définition de niveau de service critique, définissez comment le niveau de service sera mesuré et signalé. La mesure du niveau de service détermine si l'organisation atteint ses objectifs et identifie également la cause première des problèmes de disponibilité ou de performances. Tenez également compte de l'objectif lors du choix d'une méthode pour mesurer la définition du niveau de service. Reportez-vous à Création et maintenance des SLA pour plus d'informations.
Le suivi des niveaux de service suppose la tenue d'une réunion d'examen périodique, normalement tous les mois, pour examiner le service périodique. Discutez de tous les indicateurs et de leur conformité aux objectifs. S'ils ne sont pas conformes, déterminez la cause première du problème et mettez en oeuvre des améliorations. Vous devriez également couvrir les initiatives actuelles et les progrès réalisés dans l'amélioration des situations individuelles.
Création et maintenance des SLA
les définitions de niveau de service constituent un excellent élément de base en ce sens qu'elles contribuent à créer une qualité de service cohérente dans l'ensemble de l'entreprise et à améliorer la disponibilité. L'étape suivante est celle des contrats de niveau de service, qui constituent une amélioration car ils alignent directement les objectifs commerciaux et les exigences de coût sur la qualité de service. Le contrat de niveau de service bien conçu sert ensuite de modèle pour l'efficacité, la qualité et la synergie entre la communauté d'utilisateurs et le groupe d'assistance en maintenant des processus et des procédures clairs pour les problèmes ou problèmes de réseau.
Les SLA offrent plusieurs avantages :
-
Les SLA établissent une responsabilité bidirectionnelle pour le service, ce qui signifie que les utilisateurs et les groupes d'applications sont également responsables du service réseau. S'ils n'aident pas à créer un SLA pour un service spécifique et à communiquer l'impact commercial avec le groupe réseau, ils peuvent être responsables du problème.
-
Les contrats de niveau de service permettent de déterminer les outils et les ressources standard nécessaires pour répondre aux besoins de l'entreprise. Décider du nombre de personnes et des outils à utiliser sans SLA est souvent une estimation budgétaire. Le service peut être surexploité, ce qui conduit à des dépenses excessives, ou sous-conçu, ce qui conduit à des objectifs commerciaux non atteints. Le réglage des SLA permet d'atteindre ce niveau optimal équilibré.
-
Le contrat de niveau de service documenté crée un moyen plus clair de définir les attentes en matière de niveau de service.
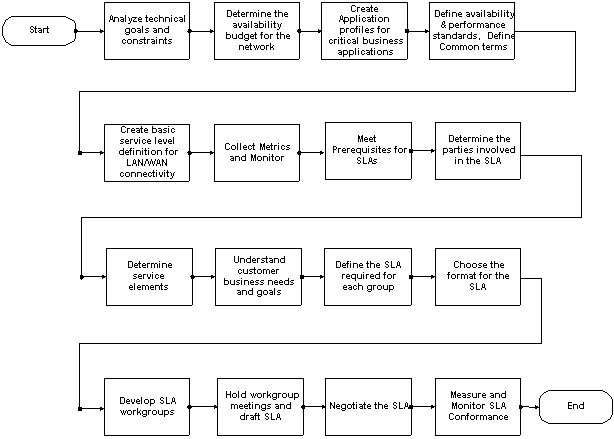
Nous recommandons les étapes suivantes pour créer des SLA après la création de définitions de niveau de service : Nous recommandons les étapes suivantes pour créer des SLA après la création de définitions de niveau de service :
7. Respectez les conditions requises pour les contrats de niveau de service.
8. Déterminez les parties impliquées dans le SLA.
9. Déterminer les éléments de service.
10. Comprendre les besoins et les objectifs des clients
11. Définissez le contrat de niveau de service requis pour chaque groupe.
12. Choisir le format du contrat de niveau de service
13. Développement de groupes de travail SLA
14. Organiser des réunions de groupe de travail et rédiger le contrat de niveau de service.
15. Négociez le SLA.
16. Mesurer et surveiller la conformité SLA.
Étape 7 : Répondre aux conditions requises pour les contrats de niveau de service
Les experts en développement de contrats de niveau de service (SLA) ont identifié trois conditions préalables à la réussite d'un contrat de niveau de service (SLA). Malheureusement, les entreprises qui ne répondent pas à ces objectifs peuvent s'attendre à des problèmes liés au processus SLA et doivent tenir compte des problèmes potentiels liés au processus SLA. Ne pas mettre en oeuvre de SLA n'est pas préjudiciable si l'organisation réseau peut créer des définitions de niveau de service répondant aux exigences générales de l'entreprise. Les conditions requises pour le processus SLA sont les suivantes :
-
Votre entreprise doit avoir une culture axée sur les services.
L'entreprise doit d'abord répondre aux besoins des clients. Vous avez besoin d'un engagement prioritaire et descendant en matière de service, qui vous permettra de comprendre parfaitement les besoins et les perceptions des clients. Mener des enquêtes de satisfaction client et des initiatives de service axées sur le client.
Un autre indicateur de service peut être que l'organisation définit le service ou la satisfaction du support comme un objectif de l'entreprise. Cela n'est pas rare car les départements IT sont désormais liés de manière critique à la réussite globale de l'entreprise.
La culture de service est importante car le processus SLA consiste essentiellement à apporter des améliorations en fonction des besoins des clients et des besoins de l'entreprise. Si les entreprises ne l'ont pas fait par le passé, le processus SLA leur sera difficile.
-
Les initiatives des clients et des entreprises doivent mener toutes les activités informatiques.
La vision ou les énoncés de mission de l'entreprise doivent être alignés sur les initiatives des clients et des entreprises, qui dirigent ensuite toutes les activités informatiques, y compris les contrats de niveau de service. Trop souvent, un réseau est mis en place pour atteindre un objectif particulier, mais le groupe réseau perd de vue cet objectif et les exigences commerciales qui en découlent. Dans ces cas, un budget fixe est alloué au réseau, ce qui peut surréagir aux besoins actuels ou sous-estimer grossièrement les besoins, ce qui entraîne des échecs.
Lorsque les initiatives des clients et des entreprises sont alignées sur les activités informatiques, l'organisation réseau peut plus facilement être en phase avec les nouveaux déploiements d'applications, les nouveaux services ou d'autres exigences commerciales. La relation et l'accent général commun sur la réalisation des objectifs de l'entreprise sont présents et tous les groupes s'exécutent en équipe.
-
Vous devez vous engager dans le processus et le contrat SLA.
Tout d'abord, il faut s'engager à apprendre le processus des accords de niveau de service pour élaborer des accords efficaces. Deuxièmement, vous devez respecter les exigences de service du contrat. Ne vous attendez pas à créer des contrats de niveau de service puissants sans la participation et l'engagement importants de toutes les personnes concernées. Cet engagement doit également provenir de la direction et de toutes les personnes associées au processus SLA.
Étape 8 : Déterminer les parties impliquées dans l'accord de niveau de service
Les contrats de niveau de service de réseau d'entreprise dépendent fortement des éléments réseau, des éléments d'administration des serveurs, de l'assistance technique, des éléments d'application et des besoins de l'entreprise ou de l'utilisateur. Normalement, la gestion de chaque zone est impliquée dans le processus SLA. Ce scénario fonctionne bien lorsque l'entreprise crée des contrats de niveau de service de support réactif de base. Les entreprises ayant des besoins de disponibilité plus élevés peuvent avoir besoin d'une assistance technique pendant le processus SLA pour résoudre des problèmes tels que la budgétisation de la disponibilité, les limitations de performances, le profilage des applications ou les capacités de gestion proactive. Pour des aspects SLA de gestion plus proactifs, nous recommandons une équipe technique d'architectes réseau et d'architectes d'applications. L'assistance technique peut être beaucoup plus proche de la disponibilité et des performances du réseau et de ce qui serait nécessaire pour atteindre des objectifs spécifiques.
Les contrats de niveau de service des fournisseurs de services n'incluent généralement pas les entrées utilisateur car ils sont créés dans le seul but d'obtenir un avantage concurrentiel sur les autres fournisseurs de services. Dans certains cas, la haute direction créera ces contrats de niveau de service à très haute disponibilité ou à hautes performances pour promouvoir leur service et fournir des objectifs internes aux employés internes. D'autres fournisseurs de services se concentreront sur les aspects techniques de l'amélioration de la disponibilité en créant de solides définitions de niveaux de service mesurés et gérés en interne. Dans d'autres cas, les deux efforts se font simultanément, mais pas nécessairement ensemble ou avec les mêmes objectifs.
Le choix des parties impliquées dans l'accord de niveau de service doit alors être basé sur les objectifs de l'accord de niveau de service. Voici quelques objectifs possibles :
-
Atteindre les objectifs commerciaux du support réactif
-
Fournir le niveau de disponibilité le plus élevé en définissant des SLA proactifs
-
Promotion ou vente d'un service
Étape 9 : Déterminer les éléments de service
Les contrats de niveau de service/d'assistance principaux comportent généralement de nombreux composants, notamment le niveau d'assistance, la manière dont il sera mesuré, le chemin d'escalade pour le rapprochement des contrats de niveau de service et les préoccupations budgétaires globales. Les éléments de service pour les environnements haute disponibilité doivent inclure des définitions de service proactives ainsi que des objectifs réactifs. Les détails supplémentaires sont les suivants :
-
Heures d'ouverture de l'assistance sur site et procédures d'assistance en dehors des heures d'ouverture
-
Définitions des priorités, notamment le type de problème, le délai maximal pour commencer à travailler sur le problème, le délai maximal pour résoudre le problème et les procédures d'escalade
-
Produits ou services à prendre en charge, classés par ordre de priorité commerciale
-
Prise en charge des attentes en matière d'expertise, des attentes en matière de performances, des rapports d'état et des responsabilités des utilisateurs pour la résolution des problèmes
-
Problèmes et exigences liés au niveau d'assistance géographique ou d'unité commerciale
-
Méthodologie et procédures de gestion des problèmes (système de suivi des appels)
-
Objectifs du centre d'assistance
-
Détection des erreurs réseau et réponse du service
-
Mesure et reporting de la disponibilité du réseau
-
Mesure et reporting de la capacité et des performances du réseau
-
Procédures de résolution des conflits
-
Financement du contrat de niveau de service mis en oeuvre
Les SLA d'applications ou de services en réseau peuvent avoir des besoins supplémentaires en fonction des besoins des groupes d'utilisateurs et de l'importance stratégique de l'entreprise. L'organisation du réseau doit être à l'écoute de ces exigences commerciales et développer des solutions spécialisées qui s'intègrent dans la structure d'assistance globale. Il est essentiel de s'intégrer à la culture globale du soutien, car il est important de ne pas créer un service de premier ordre destiné uniquement à certains individus ou groupes. Dans de nombreux cas, ces exigences supplémentaires peuvent être classées dans les catégories « solutions ». Un exemple peut être une solution platine, or et argent basée sur les besoins de l'entreprise. Reportez-vous aux exemples suivants des exigences SLA pour les besoins spécifiques de l'entreprise.
Remarque : La structure d'assistance, la trajectoire d'escalade, les procédures d'assistance, les mesures et les définitions des priorités doivent rester largement identiques pour maintenir et améliorer une culture de service cohérente.
-
Besoins en bande passante et fonctionnalités pour les rafales
-
Exigences en matière de performances
-
Exigences et définitions de QoS
-
Besoins en disponibilité et redondance pour créer une matrice de solutions
-
Exigences, méthodologie et procédures en matière de suivi et de rapports
-
Critères de mise à niveau pour les éléments d'application/de service
-
Financement hors budget ou méthode de refacturation
Par exemple, vous pouvez créer des catégories de solutions pour la connectivité de site WAN. La solution platine serait fournie avec des services T1 jumeaux au site. Chaque ligne T1 est fournie par un opérateur différent. Deux routeurs sont configurés sur le site de sorte que, en cas de défaillance d’un routeur ou d’un T1, le site ne connaisse pas de panne. Le service Gold aurait deux routeurs, mais le relais de trames de secours serait utilisé. Cette solution peut avoir une bande passante limitée pendant toute la durée de la panne. La solution Silver ne disposerait que d'un seul routeur et d'un seul service d'opérateur. Chacune de ces solutions serait prise en compte pour différents niveaux de priorité pour les tickets de problème. Certaines organisations peuvent avoir besoin d'une solution platine ou or si un ticket de priorité 1 ou 2 est requis pour une panne. Les organisations de clients peuvent ensuite financer le niveau de service dont elles ont besoin. Le tableau suivant présente un exemple d'organisation offrant trois niveaux de service, selon les besoins de l'entreprise en matière de connectivité extranet.
| Solution | Platine | Or | Argent |
|---|---|---|---|
| Périphériques | Routeurs redondants pour la connectivité WAN | Routeur redondant pour la sauvegarde sur le site principal | Aucune redondance de périphérique |
| Réseau WAN | Connectivité T1 redondante, plusieurs opérateurs | Connectivité T1 avec sauvegarde Frame Relay | Pas de redondance WAN |
| Bande passante requise et rafale | T1 redondant avec partage de charge pour rafale | Partage sans charge, sauvegarde Frame Relay pour les applications critiques uniquement ; Frame Relay CIR 64 000 uniquement | Jusqu'à T1 |
| Performances | Temps de réponse aller-retour de 100 ms ou moins | Temps de réponse 100 ms ou moins prévu 99,9 % | Temps de réponse 100 ms ou moins attendu 99 % |
| Exigences de disponibilité | 99.99% | 99.95% | 99.9% |
| Priorité du centre d'assistance en cas de panne | Priorité 1: arrêt du service critique pour l'entreprise | Priorité 2: service ayant un impact sur l'activité | Priorité 3: connectivité de l'entreprise arrêtée |
Étape 10 : Comprendre les besoins et les objectifs commerciaux des clients
Cette étape donne beaucoup de crédibilité au développeur SLA. En comprenant les besoins des différents groupes d'entreprises, le document SLA initial sera beaucoup plus proche des besoins commerciaux et du résultat souhaité. Essayez de comprendre le coût des temps d'arrêt pour le service client. Estimez la perte de productivité, de revenus et de bonne volonté des clients. Gardez à l'esprit que même des connexions simples avec quelques personnes peuvent avoir un impact sérieux sur les revenus. Dans ce cas, assurez-vous d'aider le client à comprendre les risques de disponibilité et de performances qui peuvent survenir afin que l'entreprise comprenne mieux le niveau de service dont elle a besoin. Si cette étape ne vous convient pas, de nombreux clients peuvent demander une disponibilité à 100 %.
Le développeur SLA doit également comprendre les objectifs commerciaux et la croissance de l'entreprise afin de prendre en charge les mises à niveau du réseau, la charge de travail et la budgétisation. Il est également utile de comprendre les applications qui seront utilisées. Il est à espérer que l'entreprise dispose de profils d'application sur chaque application, mais si ce n'est pas le cas, envisagez de faire une évaluation technique de l'application pour déterminer les problèmes liés au réseau.
Étape 11 : Définir le contrat de niveau de service requis pour chaque groupe
Les contrats de niveau de service de support principal doivent inclure les unités commerciales critiques et la représentation des groupes fonctionnels, tels que les opérations réseau, les opérations de serveur et les groupes de support d'applications. Ces groupes doivent être reconnus en fonction des besoins de l'entreprise et de leur rôle dans le processus d'assistance. La représentation de nombreux groupes contribue également à créer une solution de soutien global équitable sans préférence ou priorité de groupe individuel. Cela peut amener une organisation de soutien à fournir un service de premier ordre à des groupes individuels, un scénario qui peut compromettre la culture générale de service de l'organisation. Par exemple, un client peut insister sur le fait que son application est la plus importante au sein de l'entreprise lorsque, en réalité, le coût des temps d'arrêt de cette application est nettement inférieur à d'autres en termes de perte de revenus, de productivité et de bonne volonté du client.
Différentes unités commerciales au sein de l'organisation auront des besoins différents. L’un des objectifs de l’accord de niveau de service du réseau doit être d’adopter un format global qui tienne compte des différents niveaux de service. Ces exigences sont généralement la disponibilité, la qualité de service, les performances et le MTTR. Dans le contrat de niveau de service du réseau, ces variables sont gérées en hiérarchisant les applications métier pour le réglage de la qualité de service potentiel, en définissant les priorités du centre d'assistance pour le MTTR des différents problèmes affectant le réseau et en développant une matrice de solutions qui aidera à gérer les différentes exigences de disponibilité et de performances. Un exemple de matrice de solution simple pour une société de fabrication d'entreprise peut ressembler au tableau suivant. Vous pouvez ajouter des informations sur la disponibilité, la qualité de service et les performances.
| Unité commerciale | Applications | Coût des temps d'arrêt | Priorité du problème en cas de panne | Configuration serveur/réseau requise |
|---|---|---|---|---|
| Fabrication | ERP | Élevé | 1 | Redondance la plus élevée |
| Assistance client | Service client | Élevé | 1 | Redondance la plus élevée |
| Ingénierie | Serveur de fichiers, conception ASIC | Moyen | 2 | Redondance du coeur de réseau local |
| Marketing | Serveur de fichiers | Moyen | 2 | Redondance du coeur de réseau local |
Étape 12: Sélectionnez le format du contrat de niveau de service
Le format du contrat de niveau de service peut varier en fonction des souhaits de groupe ou des exigences organisationnelles. Voici un exemple de plan recommandé pour le contrat de niveau de service réseau :
-
Objet de l'accord
-
Parties participant à l'accord
-
Objectifs et objectifs de l'accord
-
-
Services fournis et produits pris en charge
-
Service d'assistance et suivi des appels
-
Définitions de la gravité du problème en fonction de l'impact commercial des définitions de MTTR
-
Priorités de service critiques pour les définitions de QoS
-
Catégories de solutions définies en fonction des exigences de disponibilité et de performances
-
Exigences en matière de formation
-
Besoins en matière de planification des capacités
-
Exigences de remontée
-
Rapports
-
Solutions réseau fournies
-
Nouvelles demandes de solution
-
Produits ou applications non pris en charge
-
-
Politiques commerciales
-
Assistance pendant les heures de bureau
-
Définitions d'assistance après-heure
-
Couverture des vacances
-
Numéros de téléphone du contact
-
Prévision de la charge de travail
-
Résolution des griefs
-
Critères d'admissibilité au service
-
Responsabilités de sécurité des utilisateurs et des groupes
-
-
Procédures de gestion des problèmes
-
Lancement des appels (utilisateur et automatisé)
-
Taux de réponse de premier niveau et de réparation des appels
-
Suivi et enregistrement des appels
-
Responsabilités de l'appelant
-
Diagnostic des problèmes et exigences de fermeture d'appel
-
Détection des problèmes de gestion du réseau et réponse aux services
-
Catégories ou définitions de résolution de problème
-
Gestion des problèmes chroniques
-
Gestion des problèmes critiques/exceptions
-
-
Objectifs de qualité de service
-
Définitions de qualité
-
Définitions des mesures
-
Objectifs de qualité
-
Temps moyen nécessaire pour résoudre les problèmes par priorité de problème
-
Temps moyen de résolution du problème par priorité de problème
-
Temps moyen de remplacement du matériel par priorité de problème
-
Disponibilité et performances du réseau
-
Gestion de la capacité
-
Gérer la croissance
-
Rapports qualité
-
-
Effectifs et budgets
-
Modèles de dotation en personnel
-
Budget des opérations
-
-
Maintenance des contrats
-
Calendrier d'examen de conformité
-
Rapports et examens sur les résultats
-
Rapprochement des mesures de rapport
-
Mises à jour SLA périodiques
-
-
Approbations
-
Pièces jointes et pièces justificatives
-
Schémas de flux d'appels
-
Matrice d'escalade
-
Matrice de solutions réseau
-
Exemples de rapports
-
Étape 13 : Développer des groupes de travail SLA
L'étape suivante consiste à identifier les participants au groupe de travail SLA, y compris un responsable de groupe. Le groupe de travail peut comprendre des utilisateurs ou des gestionnaires d'unités commerciales ou de groupes fonctionnels ou des représentants d'une base géographique. Ces personnes communiquent les problèmes de SLA à leurs groupes de travail respectifs. Les responsables et les décideurs qui peuvent s'entendre sur les éléments clés de l'accord de niveau de service doivent y participer. Ces personnes peuvent comprendre des cadres et des techniciens qui peuvent aider à définir des problèmes techniques liés au contrat de niveau de service et à prendre des décisions au niveau informatique (c.-à-d., responsable du centre d'assistance, responsable des opérations des serveurs, responsables des applications et responsable des opérations réseau).
Le groupe de travail des SLA réseau doit également être composé d'une large représentation des applications et des activités afin d'obtenir un accord sur un SLA réseau qui englobe de nombreuses applications et services. Le groupe de travail doit être habilité à classer les processus et les services critiques pour le réseau, ainsi que les exigences de disponibilité et de performances pour les services individuels. Ces informations seront utilisées pour créer des priorités pour différents types de problèmes ayant un impact sur l'entreprise, hiérarchiser le trafic stratégique sur le réseau et créer des solutions réseau standard futures en fonction des besoins de l'entreprise.
Étape 14 : Tenir des réunions de groupe de travail et rédiger le contrat de niveau de service
Le groupe de travail doit initialement créer une charte de groupe de travail. La charte doit énoncer les objectifs, les initiatives et les délais de l'accord de niveau de service. Ensuite, le groupe devrait élaborer des plans de tâches spécifiques et déterminer les calendriers et les calendriers pour l'élaboration et la mise en oeuvre de l'accord de niveau de service. Le groupe devrait également élaborer un processus de rapport pour mesurer le niveau d'appui par rapport aux critères d'appui. La dernière étape consiste à créer le projet d'accord SLA.
Le groupe de travail SLA de mise en réseau doit initialement se réunir une fois par semaine pour développer le SLA. Une fois le contrat de niveau de service créé et approuvé, le groupe peut se réunir tous les mois, voire tous les trimestres, pour les mises à jour du contrat de niveau de service.
Étape 15 : Négocier le SLA
La dernière étape de la création du contrat de niveau de service est la négociation finale et la validation. Cette étape comprend :
-
Examen du projet
-
Négociation du contenu
-
Modification et révision du document
-
Obtention de l'approbation finale
Ce cycle d'examen du projet, de négociation du contenu et de révision peut prendre plusieurs cycles avant que la version finale ne soit envoyée à la direction pour approbation.
Du point de vue du gestionnaire de réseau, il est important de négocier des résultats réalisables qui peuvent être mesurés. Essayez de sauvegarder les accords de performances et de disponibilité avec ceux d'autres organisations apparentées. Cela peut inclure des définitions de qualité, des définitions de mesure et des objectifs de qualité. N'oubliez pas que l'ajout de services équivaut à des dépenses supplémentaires. Assurez-vous que les groupes d'utilisateurs comprennent que des niveaux de service supplémentaires coûteront plus cher et qu'ils peuvent prendre la décision si c'est une exigence commerciale essentielle. Vous pouvez facilement effectuer une analyse des coûts sur de nombreux aspects du contrat de niveau de service, tels que le temps de remplacement du matériel.
Étape 16 : Mesurer et surveiller la conformité SLA
La mesure de la conformité aux SLA et des résultats de rapport sont des aspects importants du processus SLA qui contribuent à assurer la cohérence et les résultats à long terme. Nous recommandons généralement que tout élément majeur d'un ANS soit mesurable et qu'une méthodologie de mesure soit mise en place avant la mise en oeuvre de l'ANS. Organisez ensuite des réunions mensuelles entre les groupes d'utilisateurs et d'assistance pour examiner les mesures, identifier les causes profondes des problèmes et proposer des solutions pour répondre ou dépasser les exigences de niveau de service. Cela permet de rendre le processus SLA similaire à tout programme moderne d'amélioration de la qualité.
La section suivante fournit des détails supplémentaires sur la manière dont la direction d'une organisation peut évaluer ses SLA et sa gestion globale des niveaux de service.
Indicateurs de performance de la gestion des niveaux de service
Les indicateurs de performance de la gestion des niveaux de service fournissent un mécanisme permettant de surveiller et d'améliorer les niveaux de service comme mesure de la réussite. Cela permet à l'entreprise de réagir plus rapidement aux problèmes de service et de comprendre plus facilement les problèmes qui affectent le service ou le coût des temps d'arrêt dans son environnement. Ne pas mesurer les définitions des niveaux de service annule également tout travail proactif positif effectué parce que l'organisation est forcée de réagir. Personne ne dira que le service fonctionne bien, mais de nombreux utilisateurs diront que le service ne répond pas à leurs besoins.
Les indicateurs de performance de la gestion du niveau de service sont donc une exigence essentielle de la gestion du niveau de service, car ils fournissent les moyens de bien comprendre les niveaux de service existants et de procéder à des ajustements en fonction des problèmes actuels. C'est sur cette base qu'il faut fournir un soutien proactif et améliorer la qualité. Lorsque l'entreprise analyse les causes profondes des problèmes et améliore la qualité, il se peut que ce soit la meilleure méthode pour améliorer la disponibilité, les performances et la qualité de service.
Prenons par exemple le scénario réel suivant. L’entreprise X recevait de nombreuses plaintes de l’utilisateur selon lesquelles le réseau était souvent arrêté pendant de longues périodes. En mesurant la disponibilité, l'entreprise a trouvé que le problème principal était lié à quelques sites WAN. Une étude plus approfondie de ces sites a révélé que la plupart des problèmes se trouvaient sur quelques sites WAN. La cause première a été trouvée et l'organisation a résolu le problème. L'organisation a ensuite défini des objectifs de niveau de service pour la disponibilité et a conclu des accords avec des groupes d'utilisateurs. Des mesures ultérieures ont rapidement identifié des problèmes en raison d'une non-conformité au SLA. Le groupe de réseau a ensuite été considéré comme ayant un professionnalisme, une expertise et un atout global pour l'entreprise. Le groupe est passé d'une activité réactive à une activité proactive et a contribué à la rentabilité de l'entreprise.
Malheureusement, la plupart des entreprises réseau disposent aujourd'hui de définitions de niveau de service limitées et d'aucun indicateur de performance. Par conséquent, ils passent la plupart de leur temps à réagir aux plaintes ou aux problèmes des utilisateurs au lieu d'identifier de manière proactive la cause première et de créer un service réseau répondant aux besoins de l'entreprise.
Utilisez les indicateurs de performances SLA suivants pour déterminer la réussite du processus de gestion des niveaux de service :
-
Définition de niveau de service ou SLA documentée qui inclut la disponibilité, les performances, le temps de réponse réactif, les objectifs de résolution des problèmes et l'escalade des problèmes
-
Indicateurs de performances, notamment disponibilité, performances, temps de réponse du service par priorité, temps de résolution par priorité et autres paramètres SLA mesurables
-
Réunions mensuelles de gestion des niveaux de service réseau pour examiner la conformité des niveaux de service et mettre en oeuvre des améliorations
Contrat de niveau de service documenté ou définition de niveau de service
Le premier indicateur de performance est simplement un document détaillant la définition du SLA ou du niveau de service. Les principaux objectifs de la définition du niveau de service doivent être la disponibilité et les performances, car il s'agit des besoins principaux des utilisateurs.
Les objectifs secondaires sont importants car ils permettent de définir comment les niveaux de disponibilité ou de performance seront atteints. Par exemple, si l'organisation a des objectifs de disponibilité et de rendement agressifs, il sera important d'éviter les problèmes et de les résoudre rapidement lorsqu'ils surviennent. Les objectifs secondaires permettent de définir les processus nécessaires pour atteindre les niveaux de disponibilité et de performances souhaités.
Les objectifs secondaires réactifs sont les suivants :
-
Temps de réponse du service réactif par priorité d'appel
-
Objectifs de résolution des problèmes ou MTTR
-
Procédures d'escalade des problèmes.
Les objectifs secondaires proactifs sont les suivants :
-
Détection de périphérique hors service ou de liaison hors service
-
Détection des erreurs réseau
-
Détection des problèmes de capacité ou de performances.
La définition du niveau de service pour les principaux objectifs, la disponibilité et les performances doit inclure :
Le but
-
Comment mesurer l'objectif
-
Parties chargées de mesurer la disponibilité et les performances
-
Parties responsables de la disponibilité et des objectifs de performance
-
Processus de non-conformité
Si possible, nous recommandons que les parties responsables de la mesure et les parties responsables des résultats soient différentes pour éviter un conflit d'intérêts. De temps à autre, il se peut que vous deviez également ajuster les numéros de disponibilité en raison d'erreurs d'ajout/déplacement/modification, d'erreurs non détectées ou de problèmes de mesure de la disponibilité. La définition du niveau de service peut également inclure un processus de modification des résultats afin d'améliorer la précision et d'éviter des ajustements inappropriés. Voir la section suivante pour les méthodologies permettant de mesurer la disponibilité et les performances.
La définition du niveau de service pour les objectifs secondaires réactifs définit la manière dont l'entreprise réagira aux problèmes réseau ou informatiques une fois identifiés, notamment :
-
Définitions des priorités du problème
-
Temps de réponse du service réactif par priorité d'appel
-
Objectifs de résolution des problèmes, ou MTTR
-
Procédures d'escalade des problèmes
En général, ces objectifs définissent qui sera responsable des problèmes à un moment donné et dans quelle mesure les responsables devraient abandonner leurs tâches actuelles pour travailler sur les problèmes définis. À l'instar d'autres définitions de niveau de service, le document sur le niveau de service doit décrire en détail la façon dont les objectifs seront mesurés, les parties responsables de la mesure et les processus de non-conformité.
La définition de service pour les objectifs secondaires proactifs définit la manière dont l'entreprise fournit une assistance proactive, y compris l'identification des conditions de panne du réseau, de panne de liaison ou de périphérique, des conditions d'erreur du réseau et des seuils de capacité du réseau. Définissez des objectifs qui favorisent une gestion proactive car une gestion proactive de qualité permet d'éliminer les problèmes et de les résoudre plus rapidement. Pour ce faire, il convient généralement de définir un objectif de création et de résolution de dossiers proactifs sans notification de l'utilisateur. De nombreuses organisations ont mis en place un indicateur dans le logiciel de centre d'assistance pour identifier les cas proactifs par rapport aux cas réactifs à cette fin. Le document sur le niveau de service doit également contenir des renseignements sur la façon dont l'objectif sera mesuré, les parties responsables de la mesure et les processus de non-conformité.
Indicateurs de performances
Nous recommandons toujours que tout objectif de niveau de service défini soit mesurable, ce qui permet à l'entreprise de mesurer les niveaux de service, d'identifier les problèmes de service à l'origine qui entravent l'objectif principal de disponibilité et de performances, et d'apporter des améliorations qui visent des cibles spécifiques. Dans l'ensemble, les mesures sont simplement un outil qui permet aux administrateurs réseau de gérer la cohérence des niveaux de service et d'apporter des améliorations en fonction des besoins de l'entreprise.
Malheureusement, de nombreuses entreprises ne collectent pas de données sur la disponibilité, les performances et d'autres indicateurs. Les entreprises attribuent cela à l'incapacité à fournir une précision, un coût, une surcharge réseau et des ressources disponibles complets. Ces facteurs peuvent influer sur la capacité de mesurer les niveaux de service, mais l'organisation doit se concentrer sur les objectifs généraux de gestion et d'amélioration des niveaux de service. De nombreuses entreprises ont été en mesure de créer des indicateurs à faible coût et à faible surcharge qui peuvent ne pas fournir une précision complète, mais qui répondent à ces objectifs principaux.
La mesure de la disponibilité et des performances est souvent négligée dans les mesures du niveau de service. Les entreprises qui réussissent avec ces indicateurs utilisent deux méthodes assez simples. Une méthode consiste à envoyer des paquets ping ICMP (Internet Control Message Protocol) d'un emplacement central du réseau vers les bords. Vous pouvez également obtenir des performances à l'aide de cette méthode. Les entreprises qui réussissent avec cette méthode regroupent également des périphériques similaires dans des groupes de disponibilité, tels que des périphériques LAN ou des bureaux locaux. Cela est également intéressant car les entreprises ont généralement des objectifs de niveau de service différents pour différentes zones géographiques ou stratégiques du réseau. Cela permet au groupe de mesures de moyenne de tous les périphériques du groupe de disponibilité pour obtenir un résultat raisonnable.
L'autre méthode de calcul de la disponibilité est d'utiliser des tickets d'incident et une mesure appelée minutes utilisateur affectées (IUM). Cette méthode calcule le nombre d'utilisateurs affectés par une panne et la multiplie par le nombre de minutes de la panne. Lorsqu'il est exprimé en pourcentage du nombre total de minutes dans la période, il est facile de le convertir en disponibilité. Dans les deux cas, il peut également être utile d'identifier et de mesurer la cause première des temps d'arrêt afin que l'amélioration puisse être plus facilement ciblée. Les catégories de causes premières incluent les problèmes matériels, logiciels, de liaison ou de porteuse, les problèmes d'alimentation ou d'environnement, les pannes de modification et les erreurs d'utilisateur.
Les objectifs mesurables de support réactif sont les suivants :
-
Temps de réponse du service réactif par priorité d'appel
-
Objectifs de résolution des problèmes, ou MTTR
-
Délai de remontée des problèmes
Mesurer les objectifs d'assistance réactifs en générant des rapports à partir des bases de données du centre d'assistance, notamment dans les champs suivants :
-
Heure à laquelle un appel a été initialement signalé (ou saisi dans la base de données)
-
Heure à laquelle l'appel a été accepté par une personne travaillant sur le problème
-
Heure à laquelle le problème a été signalé
-
Heure de fermeture du problème
Ces mesures peuvent nécessiter une influence de la direction pour saisir systématiquement les problèmes dans la base de données et les mettre à jour en temps réel. Dans certains cas, les entreprises peuvent générer automatiquement des dossiers d'incident pour les événements réseau ou les demandes de messagerie. Cela permet d'identifier avec précision l'heure de début d'un problème. Les rapports générés à partir de ce type de mesure trient normalement les problèmes par priorité, groupe de travail et individu pour aider à déterminer les problèmes potentiels.
Il est plus difficile de mesurer les processus d'assistance proactifs, car il vous faut surveiller le travail proactif et calculer une certaine mesure de son efficacité. Peu de travail a été fait dans ce domaine. Il est toutefois clair que seul un faible pourcentage de personnes signalent les problèmes réseau à un centre d'assistance et que lorsqu'elles signalent le problème, il faut clairement du temps pour expliquer le problème ou l'isoler comme étant lié au réseau. Tous les cas proactifs n'auront pas d'effet immédiat sur la disponibilité et les performances, soit en raison d'une défaillance de périphériques ou de liaisons redondants, soit en raison de leur faible impact sur les utilisateurs finaux.
Les entreprises qui mettent en oeuvre des définitions ou des contrats de niveau de service proactifs le font en raison des besoins de l'entreprise et des risques potentiels de disponibilité. La mesure est ensuite effectuée en fonction de la quantité ou du pourcentage de cas proactifs, par opposition aux cas réactifs générés par les utilisateurs. Il est judicieux de mesurer également le nombre de cas proactifs dans chaque domaine. Ces catégories incluent les périphériques hors service, les liaisons hors service, les erreurs réseau et les violations de capacité. Certains travaux peuvent également être effectués à l'aide de modèles de disponibilité et de cas proactifs pour déterminer l'effet de la disponibilité obtenue par la mise en oeuvre de définitions de services proactives.
Examen de la gestion des niveaux de service
Un autre indicateur du succès de la gestion des niveaux de service est l'examen de la gestion des niveaux de service. Cela doit être fait que des SLA soient en place ou non. Réaliser l'examen de la gestion des niveaux de service lors d'une réunion mensuelle avec les personnes responsables de mesurer et de fournir des niveaux de service définis. Des groupes d'utilisateurs peuvent également être présents lorsque des SLA sont impliqués. La réunion a pour but d'examiner ensuite le rendement des définitions mesurées des niveaux de service et d'apporter des améliorations.
Chaque réunion doit avoir un ordre du jour défini comprenant :
-
Examen des niveaux de service mesurés pour la période donnée
-
Examen des initiatives d'amélioration définies pour chaque domaine
-
Indicateurs actuels du niveau de service
-
Une discussion sur les améliorations à apporter en fonction de l'ensemble actuel de mesures.
Au fil du temps, l'organisation peut également évoluer vers la conformité des niveaux de service pour déterminer l'efficacité du groupe. Ce processus ressemble à un cercle de qualité ou à un processus d'amélioration de la qualité. La réunion permet de cibler des problèmes individuels et de déterminer des solutions en fonction de la cause première.
Résumé de la gestion des niveaux de service
En résumé, la gestion des niveaux de service permet à une entreprise de passer d'un modèle d'assistance réactive à un modèle d'assistance proactive où la disponibilité et les niveaux de performances du réseau sont déterminés par les besoins de l'entreprise et non par les derniers problèmes. Ce processus contribue à créer un environnement d'amélioration continue du niveau de service et d'accroissement de la compétitivité de l'entreprise. La gestion du niveau de service est également le composant de gestion le plus important pour la gestion proactive du réseau. Pour cette raison, la gestion du niveau de service est fortement recommandée dans toute phase de planification et de conception du réseau et doit commencer par toute nouvelle architecture réseau. Cela permet à l'entreprise de mettre en oeuvre les solutions correctement la première fois, avec le moins de temps d'arrêt ou de reconfiguration.
Informations connexes
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)