Utiliser des métadonnées pour des rapports personnalisés avec des API et Python
Options de téléchargement
-
ePub (172.8 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (234.6 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit comment utiliser des métadonnées en conjonction avec des API afin de créer un rapport personnalisé dans un script python.
Conditions préalables
Conditions requises
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- CloudCenter
- Python
Components Used
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Informations générales
CloudCenter fournit des rapports prêts à l'emploi, mais il ne permet pas de générer des rapports basés sur des filtres personnalisés. Afin d'utiliser des API afin de récupérer les informations directement de la base de données, en conjonction avec les métadonnées attachées aux tâches, vous pouvez autoriser des rapports personnalisés.
Configurer les métadonnées
Les métadonnées doivent être ajoutées au niveau de chaque application, de sorte que chaque application qui doit être suivie avec l'utilisation du rapport personnalisé devra être modifiée.
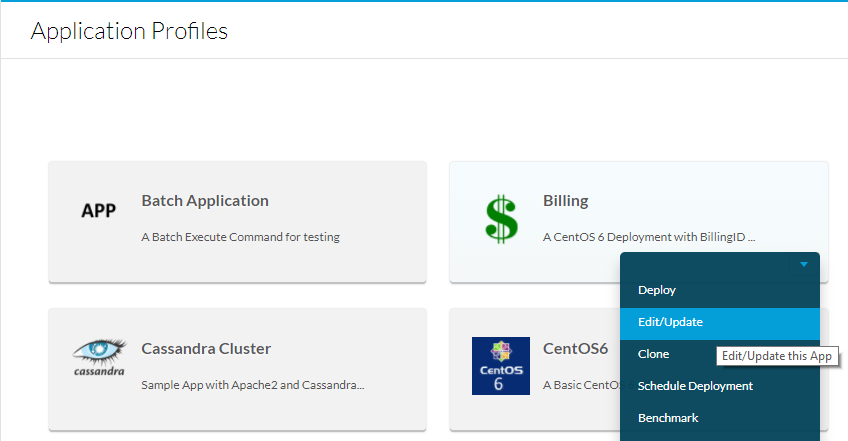
Pour ce faire, accédez à Profils d'application, sélectionnez la liste déroulante de l'application à modifier, puis sélectionnez Modifier/Mettre à jour comme indiqué dans l'image.
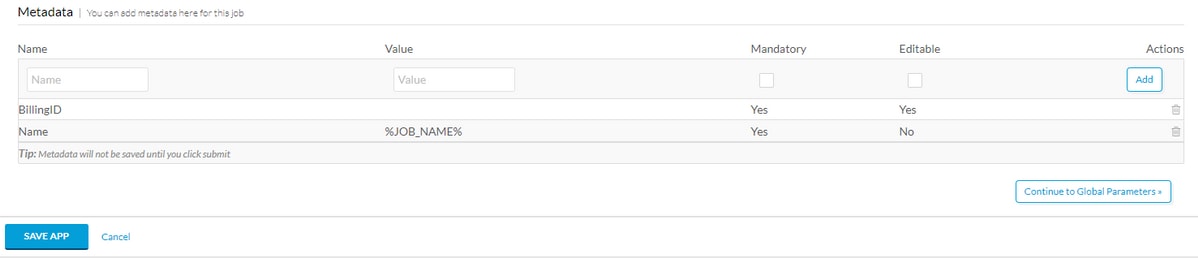
Faites défiler jusqu'au bas de Basic Information et ajoutez une balise Metadata, par exemple BillingID, si cette métadonnées doit être remplie par l'utilisateur, la rendre obligatoire et modifiable. S'il ne s'agit que d'une macro, remplissez la valeur par défaut et ne la modifiez pas. Après avoir rempli les métadonnées, sélectionnez Ajouter, puis Enregistrer l'application comme indiqué dans l'image.
Collecte des clés API
Pour traiter les appels API, des clés de nom d'utilisateur et d'API sont requises. Ces clés fournissent le même niveau d'accès que l'utilisateur. Par conséquent, si tous les déploiements d'utilisateurs doivent être ajoutés dans le rapport, il est recommandé d'obtenir l'administrateur des clés API des locataires. Si plusieurs sous-locataires doivent être enregistrés ensemble, soit le locataire racine doit avoir accès à tous les environnements de déploiement, soit les clés API de tous les administrateurs de sous-locataires seront nécessaires.
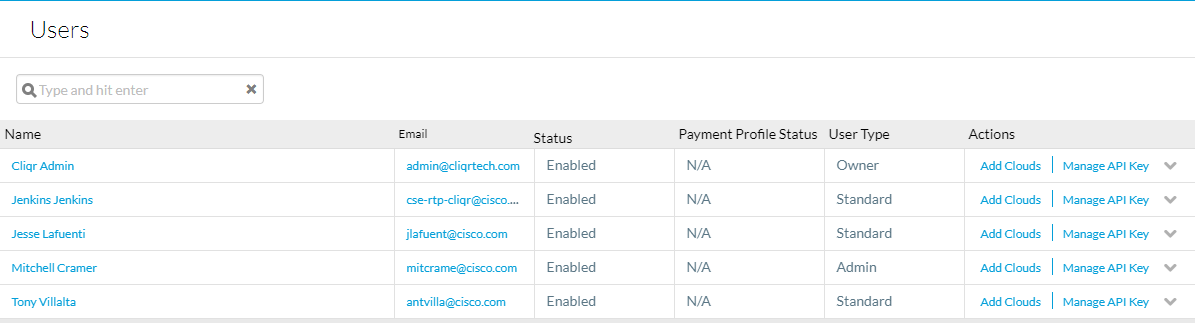
Pour obtenir les clés API, accédez à Admin > Users > Manage API Key, copiez le nom d'utilisateur et la clé des utilisateurs requis.
Créer un rapport personnalisé
Avant de créer le script python qui crée le rapport, assurez-vous que python et pip ont été installés dessus. Exécutez ensuite pip install tabulate, tabulate est une bibliothèque qui gère le formatage automatique du rapport.
Deux exemples de rapports sont joints à ce guide. Le premier collecte simplement des informations sur tous les déploiements, puis les affiche dans un tableau. La seconde utilise les mêmes informations pour créer un rapport personnalisé avec l'utilisation des métadonnées BillingID. Ce script est expliqué en détail à utiliser comme guide.
import datetime import json import sys import requests ##pip install tabulate from tabulate import tabulate from operator import itemgetter from decimal import Decimal
datetime est utilisé pour calculer précisément la date, ceci est fait pour créer un rapport des X jours les plus récents.
json est utilisé pour aider à analyser les données json, la sortie des appels api.
sys est utilisé pour les appels système.
les requêtes sont utilisées pour simplifier l'envoi de requêtes web pour les appels API.
tabulate est utilisé pour formater automatiquement le tableau.
itemgetter est utilisé comme itérateur pour trier une table 2D.
La valeur décimale est utilisée pour arrondir le coût à deux décimales.
if(len(sys.argv)==1):
days = -1
elif(len(sys.argv)==2):
try:
days = int(sys.argv[1])
if(days < 1):
raise ValueError('Less than 1')
start=datetime.datetime.now()+datetime.timedelta(days*-1)
except ValueError:
print("Number of days must be an integer greater than 0")
exit()
else:
print("Enter number of days to report on, or leave blank to report all time")
exit()
Cette partie est utilisée pour analyser le paramètre de ligne de commande du nombre de jours.
S'il n'y a aucun paramètre de ligne de commande (sys.argv ==1), la création de rapports sera effectuée à tout moment.
S'il y a un paramètre de ligne de commande, vérifiez s'il s'agit d'un entier supérieur ou égal à 1, s'il est signalé sur ce nombre de jours, sinon, retournez une erreur.
S'il y a plus d'un paramètre retourne une erreur.
departments = [] users = ['user1','user2','user3'] passwords = ['user1Key','user2Key','user3Key']
ministères est la liste qui contiendra le résultat final.
users est une liste de tous les utilisateurs qui passeront les appels de l'API, s'il y a plusieurs sous-locataires, chaque utilisateur sera l'administrateur d'un sous-locataire différent.
mots de passe est une liste des clés API des utilisateurs, l'ordre des utilisateurs et des clés doit être identique pour que la clé correcte soit utilisée.
for j in xrange(0,len(users)):
jobs = []
r = requests.get('https://ccm2.cisco.com/v1/jobs', auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data = r.json()
for i in xrange(0,len(data["jobs"])):
test = datetime.datetime.strptime((data["jobs"][i]["startTime"]), '%Y-%m-%d %H:%M:%S.%f')
if(days != -1):
if(start < test):
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
else:
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
for id in jobs:
q = requests.get('https://ccm2.cisco.com/v1/jobs/'+id[0], auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data2 = q.json()
id[2]=round(id[2],2)
for i in xrange(0,len(data2["metadatas"])):
if('BillingID' == data2["metadatas"][i]["name"]):
id[1]=data2["metadatas"][i]["value"]
added=0
for i in xrange(0,len(departments)):
if(departments[i][0]==id[1]):
departments[i][1]+= 1
departments[i][2]+=id[2]
added=1
if(added==0):
departments.append([id[1],1,id[2]])
pour j dans xrange(0, len(users)) : est que la boucle doit itérer à travers chaque utilisateur défini dans le bloc de code précédent, c'est la boucle principale qui gère tous les appels API.
jobs est une liste temporaire qui sera utilisée pour conserver les informations des jobs pendant qu'ils sont collés dans la liste.
r = requêtes.get... est le premier appel API, celui-ci répertorie tous les travaux, pour plus d'informations voir Liste des travaux.
Les résultats sont ensuite stockés au format json dans les données.
pour i dans xrange(0, len(data[« jobs »]) : itère toutes les tâches renvoyées par l'appel API précédent.
L'heure de chaque tâche est extraite du json et convertie en objet datetime, puis elle est comparée au paramètre de ligne de commande entré pour voir si elle est dans les limites.
Si c'est le cas, ce sont les informations de la tâche qui sont ajoutées à la liste des tâches : id, totalCost, status, name, start time. Toutes ces informations ne sont pas utilisées, pas plus que toutes les informations qui peuvent être retournées. Tâches de liste affiche toutes les informations renvoyées qui peuvent être ajoutées de la même manière.
Après avoir itéré toutes les tâches retournées par cet utilisateur, vous passez à pour les tâches ID : qui effectue une itération de toutes les tâches effectuées après avoir vérifié la date de début.
q = requêtes.get(.... est le deuxième appel API, celui-ci répertorie toutes les informations relatives à l'ID de travail qui a été pris du premier appel API. Pour plus d'informations, consultez Obtenir les détails du travail.
Le fichier json est ensuite stocké dans data2.
Le coût, stocké dans id[2] est arrondi à deux décimales.
pour i dans xrange(0, len(data2[« metadatas »]) : itère toutes les métadonnées associées à la tâche.
S'il existe des métadonnées appelées BillingID, elles sont stockées dans les informations du travail.
ajouté est un indicateur utilisé pour déterminer si l'ID de facturation a déjà été ajouté à la liste des services ou non.
pour i dans xrange(0,len(départements)) : effectue une itération dans tous les services qui ont été ajoutés.
Si ce travail fait partie d'un service qui existe déjà, le nombre de tâches est itéré par un, et le coût est ajouté au coût total de ce service.
Si ce n'est pas le cas, une nouvelle ligne est ajoutée aux ministères dont le nombre de tâches est égal à 1 et le coût total est égal au coût de cette tâche.
departments = sorted(departments, key=itemgetter(1)) print(tabulate(departments,headers=['Department','Number of Jobs','Total Cost']))
départements = triés(départements, key=itemgetter(1)) trie les départements par Nombre d'emplois.
print(tabulate(départements, headers=['Department','Number of Jobs', 'Total Cost'])) imprime un tableau créé par tabulate avec trois en-têtes.
Informations connexes
Contribution d’experts de Cisco
- Jesse LafuentiCisco TAC Engineer
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)