Introduction
Ce document décrit les étapes que vous pouvez utiliser pour résoudre les problèmes de montage du magasin de données Hyperflex.
Conditions préalables
Conditions requises
Aucune spécification déterminée n'est requise pour ce document.
Components Used
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales:
Par défaut, les data stores Hyperflex sont montés dans NFS v3.
NFS (Network File System) est un protocole de partage de fichiers utilisé par l'hyperviseur pour communiquer avec un serveur NAS (Network Attached Storage) sur un réseau TCP/IP standard.
Voici une description des composants NFS utilisés dans un environnement vSphere :
- Serveur NFS : périphérique de stockage ou serveur qui utilise le protocole NFS pour rendre les fichiers disponibles sur le réseau. Dans le monde Hyperflex, chaque machine virtuelle de contrôleur exécute une instance de serveur NFS. L'adresse IP du serveur NFS pour les data stores est l'adresse IP de l'interface eth1:0.
- Datastore NFS : partition partagée sur le serveur NFS qui peut être utilisée pour stocker des fichiers de machines virtuelles.
- Client NFS - ESXi inclut un client NFS intégré utilisé pour accéder aux périphériques NFS.
En plus des composants NFS standard, il y a une VIB installée sur l'ESXi appelée IOVisor. Cette carte d'interface virtuelle fournit un point de montage NFS (Network File System) pour que l'hyperviseur ESXi puisse accéder aux disques virtuels connectés à des machines virtuelles individuelles. Du point de vue de l'hyperviseur, il est simplement relié à un système de fichiers réseau.
Problème
Les symptômes des problèmes de montage peuvent apparaître sur l'hôte ESXi comme étant inaccessibles au data store.
Datastores inaccessibles dans vCenter
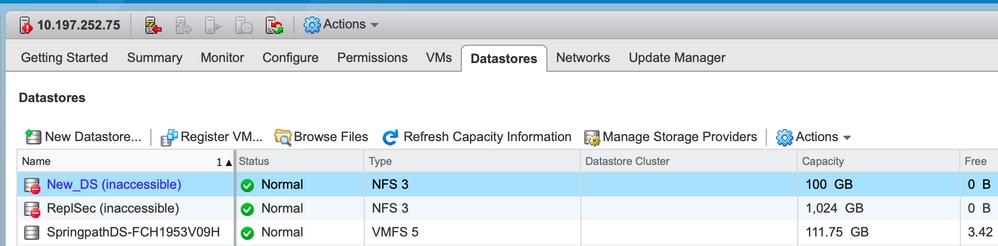
Note: Lorsque vos data stores apparaissent comme inaccessibles dans vCenter, ils sont considérés comme étant montés non disponibles dans l'interface de ligne de commande ESX. Cela signifie que les data stores étaient précédemment montés sur l'hôte.
Vérifiez les data stores via CLI :
- SSH à l’hôte ESXi, puis entrez la commande suivante :
[root@node1:~] esxcfg-nas -l
test1 is 10.197.252.106:test1 from 3203172317343203629-5043383143428344954 mounted unavailable
test2 is 10.197.252.106:test2 from 3203172317343203629-5043383143428344954 mounted unavailable
Datastores indisponibles dans vCenter/CLI
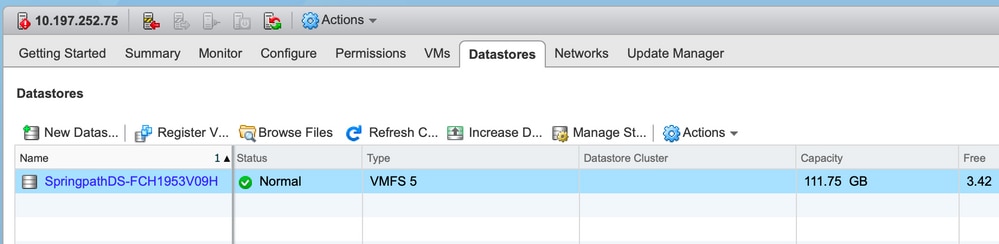
Note: Lorsque vos data stores ne sont pas présents dans vCenter ou CLI. Cela indique que le data store n'a jamais été correctement monté sur l'hôte précédemment.
- Vérifier les data stores via CLI
SSH à l’hôte ESXi et entrez la commande suivante :
[root@node1:~] esxcfg-nas -l
[root@node1:~]
Solution
Les raisons du problème de montage peuvent être différentes. Consultez la liste des vérifications pour valider et corriger le problème, le cas échéant.
Vérification de l'accessibilité du réseau
La première chose à vérifier en cas de problème de data store est de savoir si l'hôte est en mesure d'atteindre l'IP du serveur NFS.
L'adresse IP du serveur NFS dans le cas d'Hyperflex est l'adresse IP attribuée à l'interface virtuelle eth1:0, qui est présente sur l'un des SCVM.
Si les hôtes ESXi ne peuvent pas envoyer de requête ping à l'adresse IP du serveur NFS, cela rend les datastores inaccessibles.
Recherchez l'adresse IP eth1:0 à l'aide de la commande ifconfig sur tous les SCVM.
Note: L'Eth1:0 est une interface virtuelle et n'est présente que sur l'un des SCVM.
root@SpringpathControllerGDAKPUCJLE:~# ifconfig eth1:0
eth1:0 Link encap:Ethernet HWaddr 00:50:56:8b:62:d5
inet addr:10.197.252.106 Bcast:10.197.252.127 Mask:255.255.255.224
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Afin d'atteindre l'hôte ESXi avec des problèmes de montage du data store et vérifier s'il est capable d'atteindre l'IP du serveur NFS.
[root@node1:~] ping 10.197.252.106
PING 10.197.252.106 (10.197.252.106): 56 data bytes
64 bytes from 10.197.252.106: icmp_seq=0 ttl=64 time=0.312 ms
64 bytes from 10.197.252.106: icmp_seq=1 ttl=64 time=0.166 m
Si vous pouvez envoyer une requête ping, suivez les étapes de dépannage décrites dans la section suivante.
Si vous ne pouvez pas envoyer de requête ping, vous devez vérifier votre environnement pour corriger l'accessibilité. il y a quelques points qui peuvent être examinés :
- hx-storage-data vSwitch Settings :
Note: Par défaut, toute la configuration est effectuée par le programme d'installation lors du déploiement du cluster. S'il a été modifié manuellement après cela, vérifiez les paramètres
Paramètres MTU - Si vous avez activé le MTU jumbo pendant le déploiement du cluster, le MTU sur le vSwitch doit également être de 9000. Si vous n'utilisez pas la MTU jumbo, cette valeur doit être 1500.
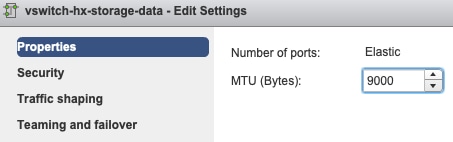
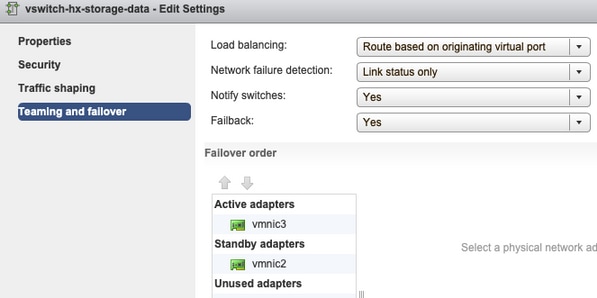
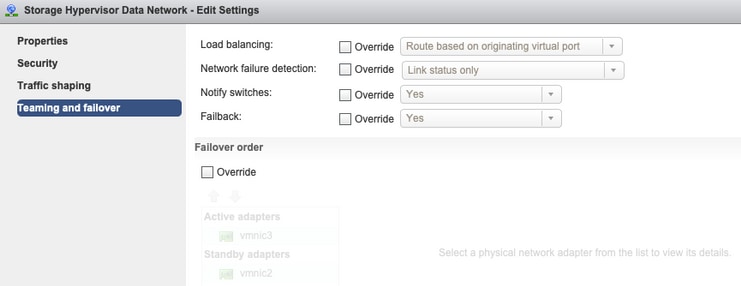
Association et basculement - Par défaut, le système tente de s'assurer que le trafic de données de stockage est commuté localement par l'interface de ligne de commande. Par conséquent, les cartes actives et de secours doivent être identiques sur tous les hôtes.
Paramètres du VLAN de groupe de ports - Le VLAN de données de stockage doit être spécifié sur les groupes de ports Storage Controller Data Network et Storage Hypervisor Data Network.
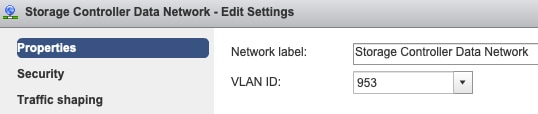
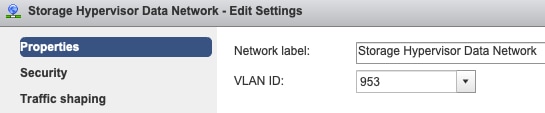
Aucun remplacement au niveau du groupe de ports : les paramètres de collaboration et de basculement effectués au niveau du vSwitch sont appliqués aux groupes de ports par défaut. Il est donc recommandé de ne pas remplacer les paramètres au niveau du groupe de ports.
- Paramètres de la vNIC UCS :
Note: Par défaut, toute la configuration est effectuée par le programme d'installation lors du déploiement du cluster. S'il a été modifié manuellement après cela, vérifiez les paramètres
Paramètres MTU - assurez-vous que la taille MTU et la stratégie QoS sont configurées correctement dans le modèle de carte réseau de données de stockage. Les volumes de données de stockage utilisent la stratégie QoS Platinum et le MTU doit être configuré en fonction de votre environnement.

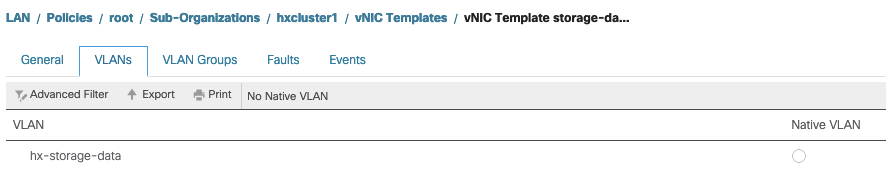
VLAN Settings - Le VLAN hx-storage-data créé lors du déploiement du cluster doit être autorisé dans le modèle vnic. s'assurer qu'il n'est pas marqué comme natif
Vérification de l'état du proxy IOvisor/SCVMclient/NFS
La vib SCVMclient de l'ESXI agit en tant que proxy NFS. Il intercepte l'E/S de la machine virtuelle, l'envoie au SCVM correspondant et les renvoie avec les informations nécessaires.
Assurez-vous que la VIB est installée sur nos hôtes, pour ce ssh à l'un des ESXI et exécutez les commandes suivantes :
[root@node1:~] esxcli software vib list | grep -i spring
scvmclient 3.5.2b-31674 Springpath VMwareAccepted 2019-04-17
stHypervisorSvc 3.5.2b-31674 Springpath VMwareAccepted 2019-05-20
vmware-esx-STFSNasPlugin 1.0.1-21 Springpath VMwareAccepted 2018-11-23
Vérifiez maintenant l'état du client scvmclient sur le serveur esxi et assurez-vous qu'il est en cours d'exécution, s'il est arrêté, démarrez-le à l'aide de la commande /etc/init.d/scvmclient start
[root@node1:~] /etc/init.d/scvmclient status
+ LOGFILE=/var/run/springpath/scvmclient_status
+ mkdir -p /var/run/springpath
+ trap mv /var/run/springpath/scvmclient_status /var/run/springpath/scvmclient_status.old && cat /var/run/springpath/scvmclient_status.old |logger -s EXIT
+ exec
+ exec
Scvmclient is running
UUID de cluster résolvable à l'IP de bouclage ESXI
Hyperflex mappe l'UUID du cluster à l'interface de bouclage de l'ESXi, de sorte qu'ESXI passe les requêtes NFS à son propre client scvmclient. Si ce n'est pas le cas, vous pouvez rencontrer des problèmes avec le montage des data stores sur l'hôte. Afin de vérifier ceci, envoyez une requête SSH à l'hôte sur lequel les data stores sont montés, et SSH à l'hôte avec des problèmes, et envoyez le fichier /etc/hosts
Si vous voyez que l'hôte non fonctionnel n'a pas l'entrée dans /etc/hosts, vous pouvez la copier à partir d'un hôte fonctionnel dans /etc/hosts de l'hôte non fonctionnel.
Hôte non fonctionnel
[root@node1:~] cat /etc/hosts
# Do not remove these lines, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
10.197.252.75 node1
Hôte fonctionnel
[root@node2:~] cat /etc/hosts
# Do not remove these lines, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
10.197.252.76 node2
127.0.0.1 3203172317343203629-5043383143428344954.springpath 3203172317343203629-5043383143428344954
Entrées De Datastore Stables Dans /etc/vmware/esx.conf
Si le cluster HX a été recréé sans la réinstallation d'ESXI, vous pouvez avoir d'anciennes entrées de data store dans le fichier esx.conf.
Cela ne vous permet pas de monter les nouveaux data stores avec le même nom. Vous pouvez vérifier tous les data stores HX dans esx.conf à partir du fichier :
[root@node1:~] cat /etc/vmware/esx.conf | grep -I nas
/nas/RepSec/share = "10.197.252.106:RepSec"
/nas/RepSec/enabled = "true"
/nas/RepSec/host = "5983172317343203629-5043383143428344954"
/nas/RepSec/readOnly = "false"
/nas/DS/share = "10.197.252.106:DS"
/nas/DS/enabled = "true"
/nas/DS/host = "3203172317343203629-5043383143428344954"
/nas/DS/readOnly = "false"
si dans le résultat, vous voyez que l'ancien data store mappé et utilisant l'ancien UUID de cluster, ESXi ne vous permet donc pas de monter le data store du même nom avec le nouvel UUID.
Pour résoudre ce problème, est nécessaire pour supprimer l'ancienne entrée de data store avec la commande - esxcfg-nas -d RepSec
Une fois retiré, recommencez le montage du data store à partir de HX-Connect
Vérifier les règles de pare-feu dans ESXi
Vérifier les paramètres d'activation du pare-feu
Elle a la valeur False, elle cause des problèmes.
[root@node1:~] esxcli network firewall get
Default Action: DROP
Enabled: false
Loaded: true
Activez-le à l'aide des commandes suivantes :
[root@node1:~] esxcli network firewall set –e true
[root@node1:~] esxcli network firewall get
Default Action: DROP
Enabled: true
Loaded: true
Vérifier les paramètres de la règle de connexion :
Elle a la valeur False, elle cause des problèmes.
[root@node1:~] esxcli network firewall ruleset list | grep -i scvm
ScvmClientConnectionRule false
Activez-le à l'aide des commandes suivantes :
[root@node1:~] esxcli network firewall ruleset set –e true –r ScvmClientConnectionRule
[root@node1:~] esxcli network firewall ruleset list | grep -i scvm
ScvmClientConnectionRule true
Vérifier les règles iptable sur la SCVM
Vérifier et faire correspondre le nombre de règles sur tous les SCVM. S'ils ne correspondent pas, ouvrez un dossier TAC pour le corriger.
root@SpringpathControllerI51U7U6QZX:~# iptables -L | wc -l
48
Informations connexes
 Commentaires
Commentaires