Dépannage des échecs du contrôle d'intégrité Intersight pour les clusters HX
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Table des matières
Introduction
Ce document décrit comment dépanner les échecs courants du bilan de santé d'Intersight pour les clusters Hyperflex.
Conditions préalables
Exigences
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- Compréhension de base du protocole NTP (Network Time Protocol) et du système DNS (Domain Name System).
- Compréhension de base de la ligne de commande Linux.
- Compréhension de base de VMware ESXi.
- Compréhension de base de VI text editor.
- Opérations de cluster Hyperflex.
Composants utilisés
Les informations contenues dans ce document sont basées sur :
Hyperflex Data Platform (HXDP) 5.0.(2a) et versions ultérieures
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
Cisco Intersight offre la possibilité d'exécuter une série de tests sur un cluster Hyperflex afin de s'assurer que l'état du cluster est optimal pour les opérations quotidiennes et les tâches de maintenance.
À partir de HX 5.0(2a), Hyperflex introduit un compte utilisateur diag avec des privilèges de dépannage progressifs dans la ligne de commande Hyperflex. Connectez-vous à Hyperflex Cluster Management IP (CMIP) en utilisant SSH en tant qu'utilisateur administratif, puis passez à diag user.
HyperFlex StorageController 5.0(2d)
admin@192.168.202.30's password:
This is a Restricted shell.
Type '?' or 'help' to get the list of allowed commands.
hxshell:~$ su diag
Password:
____ __ _____ _ _ _ _____
| ___| / /_ _ | ____(_) __ _| |__ | |_ |_ _|_ _____
|___ \ _____ | '_ \ _| |_ | _| | |/ _` | '_ \| __| _____ | | \ \ /\ / / _ \
___) | |_____| | (_) | |_ _| | |___| | (_| | | | | |_ |_____| | | \ V V / (_) |
|____/ \___/ |_| |_____|_|\__, |_| |_|\__| |_| \_/\_/ \___/
|___/
Enter the output of above expression: 5
Valid captcha
diag#Dépannage
Correction de la vérification ESXi VIB « Certains des VIB installés utilisent des vmkAPI déconseillées »
Lors de la mise à niveau vers ESXi 7.0 et versions ultérieures, Intersight garantit que les hôtes ESXi d'un cluster Hyperflex ne disposent pas de pilotes qui sont construits avec des dépendances sur des versions vmkapi plus anciennes. VMware fournit une liste des ensembles d'installation vSphere (VIB) affectés et décrit ce problème dans cet article : KB 78389
Connectez-vous à l'interface utilisateur Web d'Hyperflex Connect et accédez à Informations système. Cliquez sur Noeuds et sélectionnez le noeud Hyperflex (HX). Cliquez ensuite sur Enter HX Maintenance Mode.
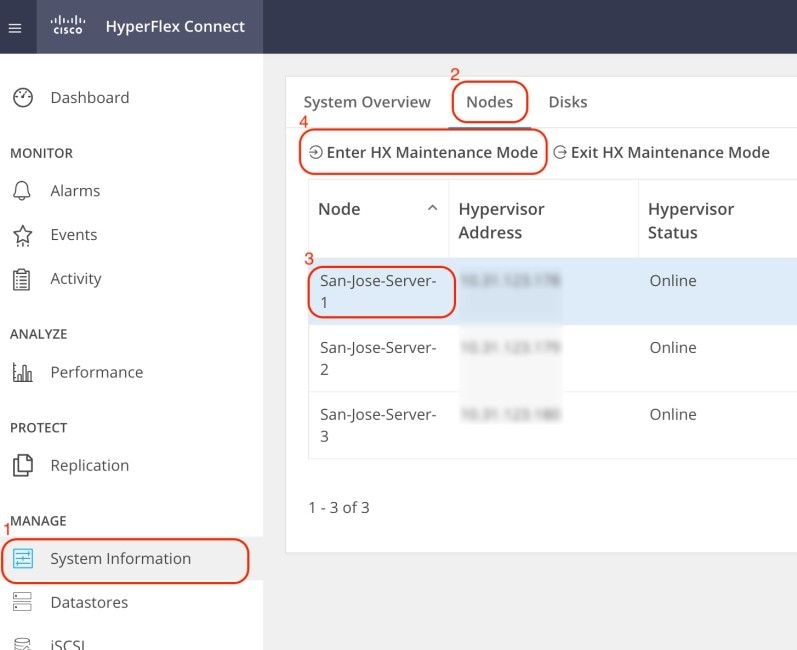
Utilisez un client SSH pour vous connecter à l'adresse IP de gestion de l'hôte ESXi. Puis, confirmez les VIB sur l'hôte ESXi avec cette commande :
esxcli software vib listSupprimez le VIB à l'aide de cette commande :
esxcli software vib remove -n driver_VIB_nameRedémarrez l'hôte ESXi. Quand il revient en ligne, à partir de HX Connect, sélectionnez le noeud HX et cliquez sur Exit HX Maintenance Mode.
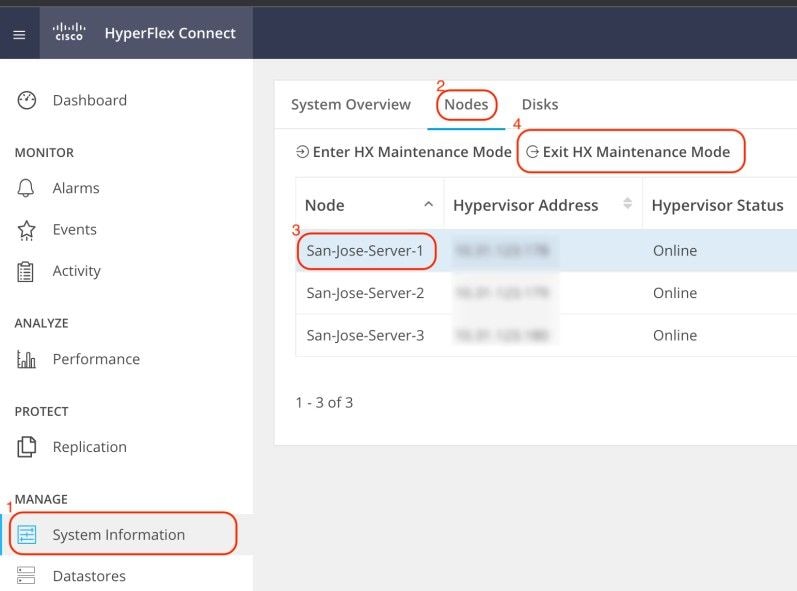
Attendez que le cluster HX devienne sain. Exécutez ensuite les mêmes étapes pour les autres noeuds du cluster.
Fix vMotion Enabled "VMotion est désactivé sur l'hôte ESXi"
Cette vérification garantit que vMotion est activé sur tous les hôtes ESXi du cluster HX. À partir de vCenter, chaque hôte ESXi doit disposer d'un commutateur virtuel (vSwitch) ainsi que d'une interface vmkernel pour vMotion.
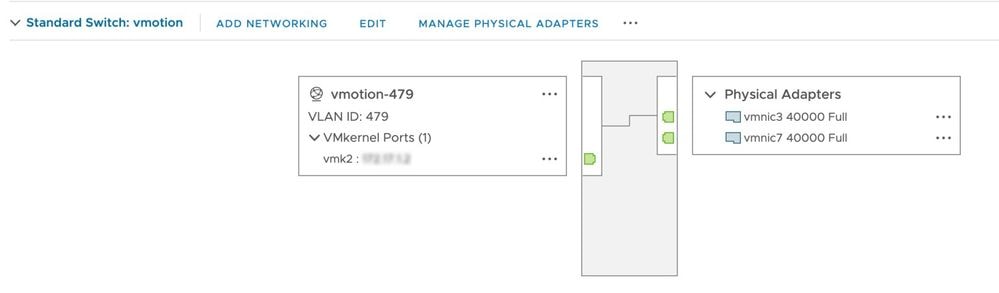
Connectez-vous à Hyperflex Cluster Management IP (CMIP) en utilisant SSH en tant qu'utilisateur administratif, puis exécutez cette commande :
hx_post_installSélectionnez l'option 1pour configurer vMotion :
admin@SpringpathController:~$ hx_post_install
Select hx_post_install workflow-
1. New/Existing Cluster
2. Expanded Cluster (for non-edge clusters)
3. Generate Certificate
Note: Workflow No.3 is mandatory to have unique SSL certificate in the cluster. By Generating this certificate, it will replace your current certificate. If you're performing cluster expansion, then this option is not required.
Selection: 1
Logging in to controller HX-01-cmip.example.com
HX CVM admin password:
Getting ESX hosts from HX cluster...
vCenter URL: 192.168.202.35
Enter vCenter username (user@domain): administrator@vsphere.local
vCenter Password:
Found datacenter HX-Clusters
Found cluster HX-01
post_install to be run for the following hosts:
HX-01-esxi-01.example.com
HX-01-esxi-02.example.com
HX-01-esxi-03.example.com
Enter ESX root password:
Enter vSphere license key? (y/n) n
Enable HA/DRS on cluster? (y/n) y
Successfully completed configuring cluster HA.
Disable SSH warning? (y/n) y
Add vmotion interfaces? (y/n) y
Netmask for vMotion: 255.255.254.0
VLAN ID: (0-4096) 208
vMotion MTU is set to use jumbo frames (9000 bytes). Do you want to change to 1500 bytes? (y/n) y
vMotion IP for HX-01-esxi-01.example.com: 192.168.208.17
Adding vmotion-208 to HX-01-esxi-01.example.com
Adding vmkernel to HX-01-esxi-01.example.com
vMotion IP for HX-01-esxi-02.example.com: 192.168.208.18
Adding vmotion-208 to HX-01-esxi-02.example.com
Adding vmkernel to HX-01-esxi-02.example.com
vMotion IP for HX-01-esxi-03.example.com: 192.168.208.19
Adding vmotion-208 to HX-01-esxi-03.example.com
Adding vmkernel to HX-01-esxi-03.example.com
Remarque : pour les clusters Edge déployés avec HX Installer, le script hx_post_install doit être exécuté à partir de l'interface de ligne de commande de HX Installer.
Correction de la vérification de la connectivité vCenter « La vérification de la connectivité vCenter a échoué »
Connectez-vous à Hyperflex Cluster Management IP (CMIP) en utilisant SSH en tant qu'utilisateur administrateur et passez à diag user. Assurez-vous que le cluster HX est enregistré dans vCenter avec cette commande :
diag# hxcli vcenter info
Cluster Name : San_Jose
vCenter Datacenter Name : MX-HX
vCenter Datacenter ID : datacenter-3
vCenter Cluster Name : San_Jose
vCenter Cluster ID : domain-c8140
vCenter URL : 10.31.123.186L'URL vCenter doit afficher l'adresse IP ou le nom de domaine complet (FQDN) du serveur vCenter. S'il n'affiche pas les informations correctes, réenregistrez le cluster HX avec vCenter à l'aide de cette commande :
diag# stcli cluster reregister --vcenter-datacenter MX-HX --vcenter-cluster San_Jose --vcenter-url 10.31.123.186 --vcenter-user administrator@vsphere.local
Reregister StorFS cluster with a new vCenter ...
Enter NEW vCenter Administrator password:
Cluster reregistration with new vCenter succeededVérifiez la connectivité entre HX CMIP et vCenter à l'aide des commandes suivantes :
diag# nc -uvz 10.31.123.186 80
Connection to 10.31.123.186 80 port [udp/http] succeeded!
diag# nc -uvz 10.31.123.186 443
Connection to 10.31.123.186 443 port [udp/https] succeeded!Correction de la vérification d'état du nettoyeur « La vérification du nettoyeur a échoué »
Connectez-vous à Hyperflex CMIP en utilisant SSH en tant qu'utilisateur administratif, puis passez à diag user. Exécutez cette commande pour identifier le noeud où le service de nettoyage n'est pas en cours d'exécution :
diag# stcli cleaner info
{ 'type': 'node', 'id': '7e83a6b2-a227-844b-87fb-f6e78e6a59be', 'name': '172.16.1.6' }: ONLINE
{ 'type': 'node', 'id': '8c83099e-b1e0-6549-a279-33da70d09343', 'name': '172.16.1.8' }: ONLINE
{ 'type': 'node', 'id': 'a697a21f-9311-3745-95b4-5d418bdc4ae0', 'name': '172.16.1.7' }: OFFLINEDans ce cas, 172.16.1.7 est l'adresse IP de la machine virtuelle du contrôleur de stockage (SCVM) où le nettoyeur n'est pas en cours d'exécution. Connectez-vous à l'adresse IP de gestion de chaque SCVM du cluster à l'aide de SSH, puis recherchez l'adresse IP de eth1 à l'aide de la commande suivante :
diag# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 00:0c:29:38:2c:a7
inet addr:172.16.1.7 Bcast:172.16.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
RX packets:1036633674 errors:0 dropped:1881 overruns:0 frame:0
TX packets:983950879 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:723797691421 (723.7 GB) TX bytes:698522491473 (698.5 GB)Démarrez le service de nettoyage sur le noeud affecté avec cette commande :
diag# sysmtool --ns cleaner --cmd startRéparer l'état du service NTP « L'état du service NTPD est ARRÊTÉ »
Connectez-vous à HX CMIP en utilisant SSH en tant qu'utilisateur administratif, puis passez à diag user. Exécutez cette commande pour confirmer que le service NTP est arrêté.
diag# service ntp status
* NTP server is not runningSi le service NTP n'est pas en cours d'exécution, exécutez cette commande pour démarrer le service NTP.
diag# priv service ntp start
* Starting NTP server
...done.Correction de l'accessibilité des serveurs NTP « Échec de la vérification de l'accessibilité des serveurs NTP »
Connectez-vous à HX CMIP en utilisant SSH en tant qu'utilisateur administratif, puis passez à diag user. Assurez-vous que le cluster HX dispose de serveurs NTP accessibles configurés. Exécutez cette commande pour afficher la configuration NTP dans le cluster.
diag# stcli services ntp show
10.31.123.226Assurez-vous qu'il y a une connectivité réseau entre chaque SCVM dans le cluster HX et le serveur NTP sur le port 123.
diag# nc -uvz 10.31.123.226 123
Connection to 10.31.123.226 123 port [udp/ntp] succeeded!Si le serveur NTP configuré dans le cluster n'est plus utilisé, vous pouvez configurer un autre serveur NTP dans le cluster.
stcli services ntp set NTP-IP-Address
Avertissement : stcli services ntp set écrase la configuration NTP actuelle dans le cluster.
Correction de l'accessibilité du serveur DNS « Échec de la vérification de l'accessibilité DNS »
Connectez-vous à HX CMIP en utilisant SSH en tant qu'utilisateur administratif, puis passez à diag user. Assurez-vous que le cluster HX dispose de serveurs DNS accessibles configurés. Exécutez cette commande pour afficher la configuration DNS dans le cluster.
diag# stcli services dns show
10.31.123.226Assurez-vous qu'il existe une connectivité réseau entre chaque SCVM dans le cluster HX et le serveur DNS sur le port 53.
diag# nc -uvz 10.31.123.226 53
Connection to 10.31.123.226 53 port [udp/domain] succeeded!Si le serveur DNS configuré dans le cluster n'est plus utilisé, vous pouvez configurer un autre serveur DNS dans le cluster.
stcli services dns set DNS-IP-AdrressAvertissement : la définition dns des services stcli écrase la configuration DNS actuelle dans le cluster.
Correction de la version de la VM du contrôleur « La valeur de la version de la VM du contrôleur est manquante dans le fichier de paramètres sur l'hôte ESXi »
Cette vérification garantit que chaque SCVM inclut guestinfo.stctlvm.version = "3.0.6-3" dans le fichier de configuration.
Connectez-vous à HX Connect et assurez-vous que le cluster est sain.
Connectez-vous à chaque hôte ESXi du cluster à l'aide de SSH avec le compte racine. Exécutez ensuite cette commande
[root@San-Jose-Server-1:~] grep guestinfo /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx
guestinfo.stctlvm.version = "3.0.6-3"
guestinfo.stctlvm.configrdm = "False"
guestinfo.stctlvm.hardware.model = "HXAF240C-M4SX"
guestinfo.stctlvm.role = "storage"
Attention : le nom du data store et le nom SCVM peuvent être différents sur votre cluster. Vous pouvez taper Spring, puis appuyer sur la touche Tab pour compléter automatiquement le nom du data store. Pour le nom SCVM, vous pouvez taper stCtl, puis appuyer sur la touche Tab pour compléter automatiquement le nom SCVM.
Si le fichier de configuration du SCVM n'inclut pas guestinfo.stctlvm.version = "3.0.6-3", connectez-vous à vCenter et sélectionnez le SCVM. Cliquez sur Actions, accédez à Power (Alimentation) et sélectionnez Shut Down Guest OS (Arrêter le système d'exploitation invité) pour mettre le SCVM hors tension.
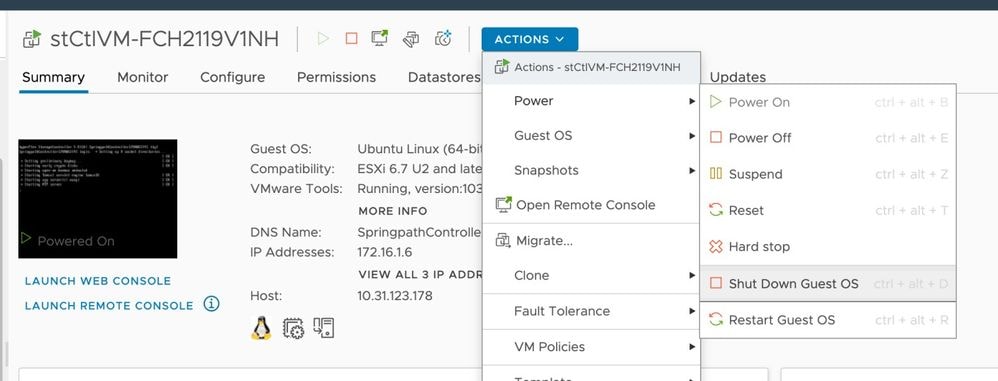
À partir de l'interface de ligne de commande (CLI) ESXi, créez une sauvegarde du fichier de configuration SCVM à l'aide de cette commande :
cp /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx.bakExécutez ensuite cette commande pour ouvrir le fichier de configuration de la SCVM :
[root@San-Jose-Server-1:~] vi /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmxAppuyez sur la touche I pour modifier le fichier, puis accédez à la fin du fichier et ajoutez cette ligne :
guestinfo.stctlvm.version = "3.0.6-3"Appuyez sur la touche ÉCHAP et tapez :wq pour enregistrer les modifications.
Identifiez l'ID de machine virtuelle (VMID) du SCVM à l'aide de la commande vim-cmd vmsvc/getallvms et rechargez le fichier de configuration du SCVM :
[root@San-Jose-Server-1:~] vim-cmd vmsvc/getallvms
Vmid Name File Guest OS Version Annotation
1 stCtlVM-FCH2119V1NH [SpringpathDS-FCH2119V1NH] stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx ubuntu64Guest vmx-15
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1Rechargez et mettez le SCVM sous tension à l'aide des commandes suivantes :
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1
[root@San-Jose-Server-1:~] vim-cmd vmsvc/power.on 1Avertissement : dans cet exemple, le VMID est 1.
Vous devez attendre que le cluster HX soit à nouveau sain avant de passer à la prochaine SCVM.
Répétez la même procédure sur les SCVM concernées une par une.
Enfin, connectez-vous à chaque SCVM à l'aide de SSH et du commutateur pour diagnostiquer le compte utilisateur. Redémarrez stMgr un noeud à la fois avec cette commande :
diag# priv restart stMgr
stMgr start/running, process 22030Avant de passer à la prochaine SCVM, assurez-vous que stMgr est pleinement opérationnel avec cette commande :
diag# stcli about
Waiting for stmgr management server on port 9333 to get ready . .
productVersion: 5.0.2d-42558
instanceUuid: EXAMPLE
serialNumber: EXAMPLE,EXAMPLE,EXAMPLE
locale: English (United States)
apiVersion: 0.1
name: HyperFlex StorageController
fullName: HyperFlex StorageController 5.0.2d
serviceType: stMgr
build: 5.0.2d-42558 (internal)
modelNumber: HXAF240C-M4SX
displayVersion: 5.0(2d)Informations connexes
- Vérification du fonctionnement des clusters HyperFlex
- Assistance et documentation techniques - Cisco Systems
Attention : dans cet exemple, le VMID est 1.
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
2.0 |
06-Nov-2023 |
Première publication |
1.0 |
11-Oct-2023 |
Première publication |
Contribution d’experts de Cisco
- Carlos RazoIngénieur TAC Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)