Comment choisir le meilleur chemin de commutation de routeur pour votre réseau
Contenu
Introduction
Il existe une pléthore de chemins de commutation disponibles pour divers routeurs Cisco et versions de Cisco IOS®. Quel est le plus adapté pour votre réseau, et comment fonctionnent-ils? Ce livre blanc tente d'expliquer chacun des trajets de commutation suivants, de sorte que vous puissiez prendre une décision éclairée au sujet du trajet de commutation le plus adapté à votre réseau.
Tout d’abord, examinez le processus de transfert lui-même. Trois étapes permettent de transférer un paquet via un routeur :
-
Déterminez si la destination du paquet est accessible.
-
Déterminez le tronçon suivant vers la destination et l’interface par laquelle ce tronçon suivant est accessible.
-
Réécrivez l'en-tête MAC (Media Access Control) sur le paquet afin qu'il atteigne son prochain saut.
Chacune de ces étapes est essentielle pour que le paquet atteigne sa destination.
Remarque : Dans ce document, le chemin de commutation IP est utilisé comme exemple ; pratiquement toutes les informations fournies ici s’appliquent à des chemins de commutation équivalents pour d’autres protocoles, s’ils existent.
Commutation de processus
La commutation de processus est le plus petit dénominateur commun des chemins de commutation ; il est disponible sur toutes les versions d’IOS, sur toutes les plates-formes et pour tous les types de trafic commutés. La commutation de processus est définie par deux concepts essentiels :
-
La décision de transfert et les informations utilisées pour réécrire l’en-tête MAC sur le paquet proviennent de la table de routage (à partir de la base d’informations de routage ou RIB) et du cache ARP (Address Resolution Protocol), ou d’une autre table qui contient les informations d’en-tête MAC mappées à l’adresse IP de chaque hôte directement connecté au routeur.
-
Le paquet est commuté par un processus normal exécuté dans IOS. En d’autres termes, la décision de transfert est prise par un processus planifié via le planificateur IOS et exécuté en tant qu’homologue à d’autres processus sur le routeur, tels que les protocoles de routage. Les processus qui s’exécutent normalement sur le routeur ne sont pas interrompus pour traiter un commutateur.
La figure ci-dessous illustre le chemin de commutation de processus.
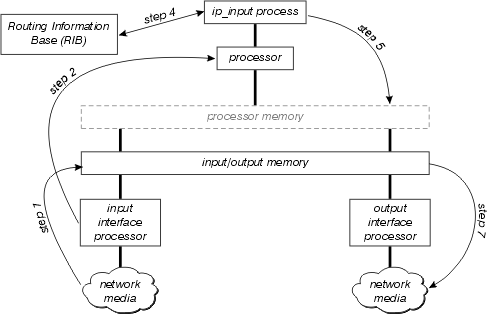
Examinez ce schéma plus en détail :
-
Le processeur d’interface détecte tout d’abord qu’il y a un paquet sur le support réseau et transfère ce paquet à la mémoire d’entrée/sortie du routeur.
-
Le processeur d'interface génère une interruption de réception. Au cours de cette interruption, le processeur central détermine le type de paquet (en supposant qu'il s'agit d'un paquet IP) et le copie dans la mémoire du processeur si nécessaire (cette décision dépend de la plate-forme). Enfin, le processeur place le paquet sur la file d'attente d'entrée du processus approprié et l'interruption est libérée.
-
La prochaine fois que le planificateur s'exécute, il prend note du paquet dans la file d'attente d'entrée ip_input et planifie l'exécution de ce processus.
-
Lorsque ip_input s'exécute, il consulte le RIB pour déterminer le saut suivant et l'interface de sortie, puis consulte le cache ARP pour déterminer l'adresse de couche physique correcte pour ce saut suivant.
-
ip_input réécrit ensuite l'en-tête MAC du paquet et place le paquet sur la file d'attente de sortie de l'interface sortante correcte.
-
Le paquet est copié de la file d’attente de sortie de l’interface de sortie vers la file d’attente de transmission de l’interface de sortie ; toute qualité de service sortante se produit entre ces deux files d'attente.
-
Le processeur d’interface de sortie détecte le paquet sur sa file d’attente de transmission et le transfère sur le support réseau.
Presque toutes les fonctionnalités qui affectent la commutation de paquets, telles que la traduction d'adresses de réseau (NAT) et le routage de stratégie, font leurs débuts dans le chemin de commutation de processus. Une fois qu'elles ont été testées et optimisées, ces fonctionnalités peuvent apparaître ou non dans la commutation de contexte d'interruption.
Commutation de contexte d'interruption
La commutation de contexte d’interruption est la deuxième des principales méthodes de commutation utilisées par les routeurs Cisco. Les principales différences entre la commutation de contexte d'interruption et la commutation de processus sont les suivantes :
-
Le processus en cours d'exécution sur le processeur est interrompu pour commuter le paquet. Les paquets sont commutés à la demande, plutôt que commutés uniquement lorsque le processus ip_input peut être planifié.
-
Le processeur utilise une forme quelconque de cache de route pour trouver toutes les informations nécessaires pour commuter le paquet.
Cette figure illustre la commutation de contexte d'interruption :
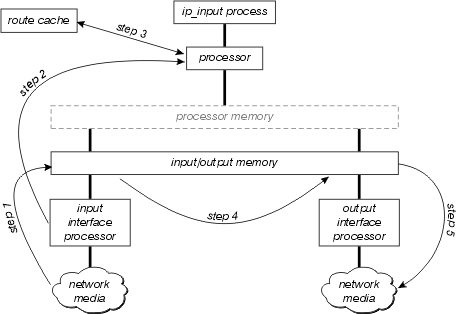
Examinez ce schéma plus en détail :
-
Le processeur d’interface détecte tout d’abord qu’il y a un paquet sur le support réseau et transfère ce paquet à la mémoire d’entrée/sortie du routeur.
-
Le processeur d'interface génère une interruption de réception. Au cours de cette interruption, le processeur central détermine le type de paquet (en supposant qu'il s'agit d'un paquet IP), puis commence à commuter le paquet.
-
Le processeur recherche le cache de route pour déterminer si la destination du paquet est accessible, quelle interface de sortie doit être, quel est le prochain saut vers cette destination, et enfin, quel en-tête MAC le paquet doit avoir pour atteindre le saut suivant. Le processeur utilise ces informations pour réécrire l'en-tête MAC du paquet.
-
Le paquet est maintenant copié dans la file d'attente de transmission ou de sortie de l'interface sortante (selon différents facteurs). L'interruption de réception revient maintenant et le processus qui était en cours d'exécution sur le processeur avant l'interruption continue d'être en cours d'exécution.
-
Le processeur d’interface de sortie détecte le paquet sur sa file d’attente de transmission et le transfère sur le support réseau.
La première question qui vient à l'esprit après avoir lu cette description est « Qu'y a-t-il dans le cache ? » Il existe trois réponses possibles, selon le type de commutation de contexte d'interruption :
Commutation rapide
La commutation rapide stocke les informations de transfert et la chaîne de réécriture de l’en-tête MAC à l’aide d’une arborescence binaire pour une recherche et une référence rapides. Cette figure illustre une arborescence binaire :
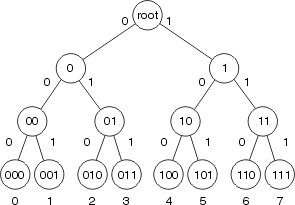
Dans la commutation rapide, les informations d’accessibilité sont indiquées par l’existence d’un noeud sur l’arborescence binaire pour la destination du paquet. L'en-tête MAC et l'interface de sortie de chaque destination sont stockés dans le cadre des informations du noeud dans l'arborescence. L'arborescence binaire peut en fait avoir 32 niveaux (l'arborescence ci-dessus est extrêmement abrégée à des fins d'illustration).
Pour rechercher une arborescence binaire, il vous suffit de commencer à partir de la gauche (avec le chiffre le plus significatif) dans le nombre (binaire) que vous recherchez, puis de vous diriger vers la droite ou vers la gauche dans l'arborescence en fonction de ce nombre. Par exemple, si vous recherchez les informations relatives au nombre 4 dans cette arborescence, vous commencez par brancher à droite, car le premier chiffre binaire est 1. Vous devez suivre l'arborescence, en comparant le chiffre suivant dans le nombre (binaire), jusqu'à ce que vous atteigniez la fin.
Caractéristiques de la commutation rapide
La commutation rapide présente plusieurs caractéristiques résultant de la structure de l’arborescence binaire et du stockage des informations de réécriture de l’en-tête MAC dans le cadre des noeuds de l’arborescence.
-
Comme il n'existe aucune corrélation entre la table de routage et le contenu du cache rapide (réécriture de l'en-tête MAC, par exemple), les entrées du cache de construction impliquent tous les traitements qui doivent être effectués dans le chemin de commutation de processus. Par conséquent, les entrées de cache rapide sont construites lorsque les paquets sont commutés par processus.
-
Comme il n'y a aucune corrélation entre les en-têtes MAC (utilisés pour les réécritures) dans le cache ARP et la structure du cache rapide, lorsque la table ARP change, une partie du cache rapide doit être invalidée (et recréée par la commutation de processus des paquets).
-
Le cache rapide ne peut générer des entrées qu'à une profondeur (une longueur de préfixe) pour une destination particulière de la table de routage.
-
Il n'y a aucun moyen de pointer d'une entrée à une autre dans le cache rapide (l'en-tête MAC et les informations d'interface sortante sont censées se trouver dans le noeud), de sorte que toutes les récursions de routage doivent être résolues lors de la création d'une entrée de cache rapide. En d'autres termes, les routes récursives ne peuvent pas être résolues dans le cache rapide lui-même.
Entrées de commutation rapide vieillissante
Afin d'éviter que les entrées de commutation rapide ne perdent leur synchronisation avec la table de routage et le cache ARP, et pour empêcher les entrées inutilisées dans le cache rapide de consommer indûment de la mémoire sur le routeur, 1/20e du cache rapide est invalidé, de manière aléatoire, chaque minute. Si la mémoire des routeurs tombe sous un seuil très bas, 1/5 des entrées de cache rapide sont invalidées chaque minute.
Longueur du préfixe de commutation rapide
Pour quelle longueur de préfixe la commutation rapide génère-t-elle des entrées s'il ne peut construire qu'une seule longueur de préfixe pour chaque destination ? Dans les termes de la commutation rapide, une destination est une destination accessible unique dans la table de routage, ou un réseau principal. Les règles permettant de déterminer la longueur de préfixe à créer une entrée de cache donnée sont les suivantes :
-
Si vous créez une entrée de stratégie rapide, mettez toujours en cache /32.
-
Si vous créez une entrée sur un circuit virtuel MPOA (Multiprotocol over ATM Virtual Circuit), mettez toujours en cache /32.
-
Si le réseau n’est pas divisé en sous-réseaux (il s’agit d’une entrée réseau majeure) :
-
S'il est directement connecté, utilisez /32 ;
-
Sinon, utilisez le masque de réseau principal.
-
-
S'il s'agit d'un super-réseau, utilisez le masque du super-réseau.
-
Si le réseau est divisé en sous-réseaux :
-
Si vous êtes connecté directement, utilisez /32 ;
-
S'il existe plusieurs chemins vers ce sous-réseau, utilisez /32 ;
-
Dans tous les autres cas, utilisez la longueur de préfixe la plus longue dans ce réseau principal.
-
Partage de charge
La commutation rapide est entièrement basée sur la destination ; le partage de charge se produit par destination. S’il existe plusieurs chemins de coût égal pour un réseau de destination particulier, le cache rapide a une entrée pour chaque hôte accessible dans ce réseau, mais tout le trafic destiné à un hôte particulier suit une liaison.
Commutation optimale
La commutation optimale stocke les informations de transfert et les informations de réécriture de l'en-tête MAC dans une arborescence multidirectionnelle à 256 voies (arborescence à 256 voies). L'utilisation d'une arborescence réduit le nombre d'étapes à effectuer lors de la recherche d'un préfixe, comme illustré dans la figure suivante.
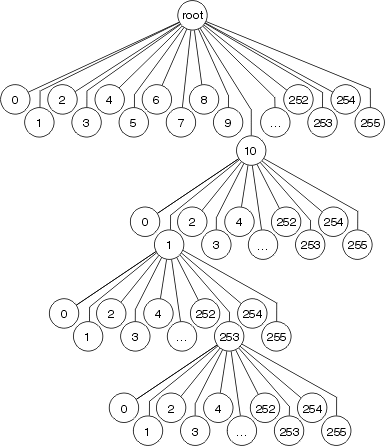
Chaque octet est utilisé pour déterminer laquelle des 256 branches à prendre à chaque niveau de l'arbre, ce qui signifie qu'il y a au maximum 4 recherches impliquées dans la recherche d'une destination. Pour des longueurs de préfixe plus courtes, une ou trois recherches peuvent être nécessaires. Les informations d'interface de réécriture et de sortie de l'en-tête MAC sont stockées dans le noeud d'arborescence, de sorte que l'invalidation et le vieillissement du cache se produisent toujours comme dans la commutation rapide.
La commutation optimale détermine également la longueur de préfixe de chaque entrée de cache de la même manière que la commutation rapide.
Cisco Express Forwarding
Cisco Express Forwarding utilise également une structure de données à 256 voies pour stocker les informations de transfert et de réécriture d'en-tête MAC, mais il n'utilise pas d'arborescence. Cisco Express Forwarding utilise un tri, ce qui signifie que les informations réelles recherchées ne se trouvent pas dans la structure de données ; au lieu de cela, les données sont stockées dans une structure de données distincte, et le tri y fait simplement référence. En d'autres termes, plutôt que de stocker l'interface sortante et l'en-tête MAC réécrire dans l'arborescence elle-même, Cisco Express Forwarding stocke ces informations dans une structure de données distincte appelée table de contiguïté.
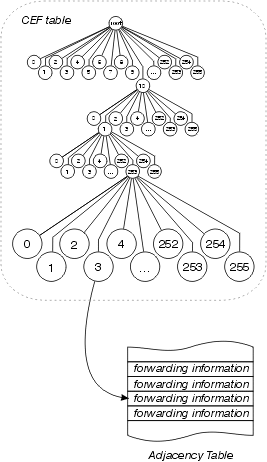
Cette séparation des informations d'accessibilité (dans la table Cisco Express Forwarding) et des informations de transmission (dans la table de contiguïté) offre plusieurs avantages :
-
La table de contiguïté peut être créée séparément de la table Cisco Express Forwarding, ce qui permet à ces deux tables de créer des paquets sans commutation de processus.
-
La réécriture de l'en-tête MAC utilisée pour transférer un paquet n'est pas stockée dans les entrées du cache, de sorte que les modifications apportées à une chaîne de réécriture de l'en-tête MAC ne nécessitent pas l'invalidation des entrées du cache.
-
Vous pouvez pointer directement vers les informations de transmission, plutôt que vers le saut suivant récursif, afin de résoudre les routes récursives.
Essentiellement, tout vieillissement du cache est éliminé et le cache est préconstruit en fonction des informations contenues dans la table de routage et le cache ARP. Il n'est pas nécessaire de traiter un paquet de commutation pour créer une entrée de cache.
Autres entrées de la table de contiguïté
La table de contiguïté peut contenir des entrées autres que les chaînes de réécriture d'en-tête MAC et les informations d'interface sortante. Voici quelques-uns des différents types d'entrées pouvant être placés dans la table de contiguïté :
-
cache : chaîne de réécriture d'en-tête MAC et interface de sortie utilisée pour atteindre un hôte ou un routeur adjacent particulier.
-
Receive : les paquets destinés à cette adresse IP doivent être reçus par le routeur. Cela inclut les adresses et adresses de diffusion configurées sur le routeur lui-même.
-
drop : les paquets destinés à cette adresse IP doivent être supprimés. Ceci peut être utilisé pour le trafic refusé par une liste d'accès, ou routé vers une interface NULL.
-
punt - Cisco Express Forwarding ne peut pas commuter ce paquet ; passez-le à la meilleure méthode de commutation suivante (généralement la commutation rapide) pour le traitement.
-
glean : le saut suivant est directement attaché, mais aucune chaîne de réécriture d'en-tête MAC n'est actuellement disponible.
Adjacences de la géolocalisation
Une entrée de contiguïté en étoile indique qu'un saut suivant particulier doit être directement connecté, mais aucune information de réécriture d'en-tête MAC n'est disponible. Comment les construire et les utiliser ? Un routeur exécutant Cisco Express Forwarding et connecté à un réseau de diffusion, comme illustré dans la figure ci-dessous, génère un certain nombre d'entrées de table de contiguïté par défaut.
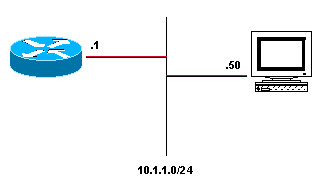
Les quatre entrées de table de contiguïté créées par défaut sont les suivantes :
10.1.1.0/24, version 17, attached, connected
0 packets, 0 bytes
via Ethernet2/0, 0 dependencies
valid glean adjacency
10.1.1.0/32, version 4, receive
10.1.1.1/32, version 3, receive
10.1.1.255/32, version 5, receive
Notez qu'il existe quatre entrées : trois reçoivent, et un brille. Chaque entrée de réception représente une adresse de diffusion ou une adresse configurée sur le routeur, tandis que l’entrée de réception représente le reste de l’espace d’adressage sur le réseau connecté. Si un paquet est reçu pour l’hôte 10.1.1.50, le routeur tente de le commuter et le trouve résolu à cette contiguïté de glan. Cisco Express Forwarding signale ensuite qu'une entrée de cache ARP est nécessaire pour 10.1.1.50, que le processus ARP envoie un paquet ARP et que l'entrée de table de contiguïté appropriée est créée à partir des nouvelles informations de cache ARP. Une fois cette étape terminée, la table de contiguïté a une entrée pour 10.1.1.50.
10.1.1.0/24, version 17, attached, connected
0 packets, 0 bytes
via Ethernet2/0, 0 dependencies
valid glean adjacency
10.1.1.0/32, version 4, receive
10.1.1.1/32, version 3, receive
10.1.1.50/32, version 12, cached adjacency 208.0.3.2
0 packets, 0 bytes
via 208.0.3.2, Ethernet2/0, 1 dependency
next hop 208.0.3.2, Ethernet2/0
valid cached adjacency
10.1.1.255/32, version 5, receive
Le paquet suivant que le routeur reçoit et destiné à 10.1.1.50 est commuté via cette nouvelle contiguïté.
Partage de charge
Cisco Express Forwarding tire également parti de la séparation entre la table Cisco Express Forwarding et la table de contiguïté pour fournir une meilleure forme de partage de charge que tout autre mode de commutation de contexte d'interruption. Une table de partage de charge est insérée entre la table Cisco Express Forwarding et la table de contiguïté, comme illustré dans cette figure :
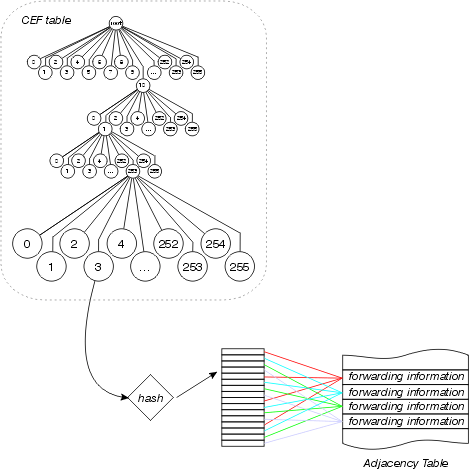
La table Cisco Express Forwarding pointe vers cette table de partage de charge, qui contient des pointeurs vers les différentes entrées de la table de contiguïté pour les chemins parallèles disponibles. Les adresses source et de destination sont transmises via un algorithme de hachage afin de déterminer quelle entrée de table de partage de charge utiliser pour chaque paquet. Le partage de charge par paquet peut être configuré, auquel cas chaque paquet utilise une entrée de table de partage de charge différente.
Chaque table de partage de charge comporte 16 entrées parmi lesquelles les chemins disponibles sont divisés en fonction du compteur de partage de trafic de la table de routage. Si les compteurs de partage de trafic de la table de routage sont tous 1 (comme dans le cas de plusieurs chemins de coût égal), chaque saut suivant possible reçoit un nombre égal de pointeurs de la table de partage de charge. Si le nombre de chemins disponibles n'est pas divisible uniformément en 16 (puisqu'il y a 16 entrées de table de partage de charge), certains chemins auront plus d'entrées que d'autres.
À partir de la version 12.0 du logiciel Cisco IOS, le nombre d'entrées dans la table de partage de charge est réduit afin de s'assurer que chaque chemin a un nombre proportionné d'entrées de table de partage de charge. Par exemple, s'il existe trois chemins de coût égal dans la table de routage, seules 15 entrées de table de partage de charge sont utilisées.
Quel est le meilleur chemin de commutation ?
Dans la mesure du possible, vous souhaitez que vos routeurs commutent dans le contexte d'interruption, car il s'agit d'un ordre de grandeur au moins plus rapide que la commutation au niveau du processus. La commutation Cisco Express Forwarding est certainement plus rapide et meilleure que tout autre mode de commutation. Nous vous recommandons d'utiliser Cisco Express Forwarding si le protocole et l'IOS que vous exécutez le prennent en charge. Ceci est particulièrement vrai si vous avez un certain nombre de liaisons parallèles à travers lesquelles le trafic doit être partagé. Accédez à la page Cisco Feature Navigator (clients enregistrés uniquement) pour déterminer l'IOS dont vous avez besoin pour la prise en charge CEF.
Informations connexes
- Comment vérifier la commutation Cisco Express Forwarding
- Dépannage de l'équilibrage de charge sur des liens parallèles utilisant Cisco Express Forwarding
- Équilibrage de charge avec CEF
- Page d'assistance Cisco Express Forwarding
- Page de support pour le routage IP
- Guide de configuration des services de commutation Cisco IOS, version 12.1
- Support technique - Cisco Systems
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)