Arborescence des erreurs de parité du routeur Internet de la gamme Cisco 12000
Contenu
Introduction
Ce document décrit les étapes du dépannage et du repérage d'une pièce ou d'une composante défectueuse du routeur Internet Cisco de série 12000 lors de l'affichage de divers messages d'erreur de parité.
Remarque : Ce document ne couvre pas la cause des erreurs de parité. Si vous êtes intéressé par une définition plus concise des erreurs de parité (également appelée Upsets d'événement unique - SEU) et leur cause possible, nous vous recommandons de lire les documents liés à partir de l'augmentation de la disponibilité du réseau.
Avant de commencer
Conventions
Pour plus d'informations sur les conventions des documents, référez-vous aux Conventions utilisées pour les conseils techniques de Cisco.
Conditions préalables
Avant de poursuivre avec ce document, nous vous recommandons de lire les documents suivants :
Components Used
Les informations dans ce document sont basées sur les versions de logiciel et de matériel ci-dessous.
-
Routeur Internet de la gamme Cisco 12000
-
Toutes les versions du logiciel Cisco IOS®
Les informations présentées dans ce document ont été créées à partir de périphériques dans un environnement de laboratoire spécifique. All of the devices used in this document started with a cleared (default) configuration. Si vous travaillez dans un réseau opérationnel, assurez-vous de bien comprendre l'impact potentiel de toute commande avant de l'utiliser.
Aperçu
La plupart des processeurs de routage et des cartes de ligne des routeurs Internet de la gamme Cisco 12000 incluent la fonctionnalité ECC (Error Code Correction). Cependant, certaines cartes de ligne existantes ne disposent pas de la fonctionnalité ECC. La fonctionnalité ECC couvre uniquement la mémoire RAM ou SDRAM (Synchronous Dynamic RAM) des cartes. Le reste n'est pas protégé par ECC.
Voici une comparaison des fonctionnalités ECC des cartes de ligne utilisées avec le Cisco 12000 :
-
Toutes les cartes du moteur 2 et des versions ultérieures ont une fonctionnalité ECC.
-
Les cartes du moteur 1 sont passées à ECC après FCS.
-
Les cartes du moteur 0 n'ont pas de fonctionnalité ECC.
-
Certaines cartes peuvent être mises à niveau vers des produits similaires qui intègrent la fonctionnalité ECC.
Le tableau ci-dessous répertorie les produits dotés de la fonctionnalité ECC :
| Produits non ECC | Produits ECC |
|---|---|
| GRP(=) | GRP-B(=) |
| GE-SX/LH-SC(=) | GE-GBIC-SC-B(=) |
| GE-GBIC-SC-A(=) | GE-GBIC-SC-B(=) |
| 8FE-FX-SC(=) | 8FE-FX-SC-B(=) |
| 8FE-TX-RF45(=) | 8FE-TX-RJ45-B(=) |
| 6DS3-SMB(=) | 6DS3-SMB-B(=) |
| 12DS3-SBM(=) | 12DS3-SMB-B(=) |
| OC12/SRP-IR-SC(=) | OC12/SRP-IR-SC-B(=) |
| OC12/SRP-MM-SC(=) | OC12/SRP-mm-SC-B(=) |
| OC12/SRP-LR-SC(=) | OC12/SRP-LR-SC-B(=) |
Note : -B et ECC sont indépendants. -B signifie que le produit est une deuxième révision importante de la carte. Dans certains cas, il s'agissait de la révision de la CEC.
Cisco propose un plan de migration technologique (TMP) qui vous permet de mettre à niveau une carte non ECC vers une nouvelle carte ECC. Un crédit sera appliqué à l'achat du nouveau conseil ECC en échange du conseil non ECC.
Analyse de l'arbre des erreurs de parité du processeur de routage Gigabit (GRP)
L'organigramme ci-dessous vous aide à déterminer quel composant du routeur Internet de la gamme Cisco 12000 est responsable des messages d'erreur ECC (Parity/Error Code Correction) sur le processeur de routage Gigabit (GRP).

Remarque : Capturez et enregistrez les journaux de sortie et de console show tech-support, et collectez tous les fichiers crashinfo lors des événements d'erreur de parité/ECC.
Analyse de l'arborescence des erreurs de parité des cartes de ligne
L'organigramme ci-dessous vous aide à déterminer quel composant d'une carte de ligne de routeur Internet de la gamme Cisco 12000 est responsable des messages d'erreur ECC (Parity/Error Code Correction) :
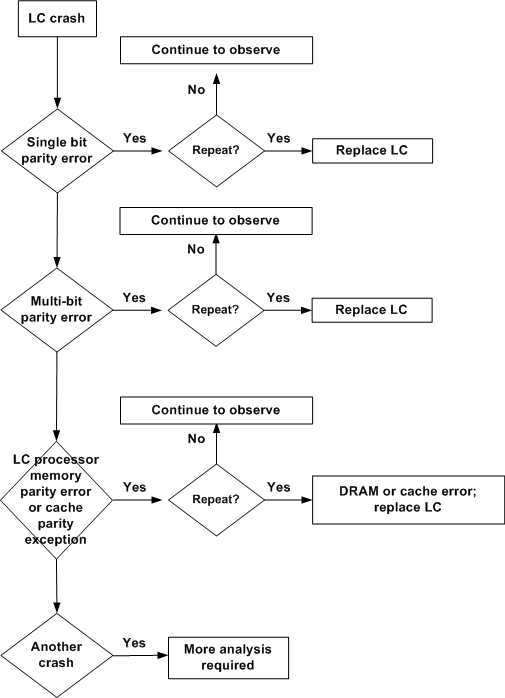
Remarque : chaque fois qu'une carte de ligne rencontre un événement d'erreur de parité/ECC, collectez autant d'informations que possible (pour plus d'informations, consultez Dépannage des pannes de cartes de ligne sur le routeur Internet de la gamme Cisco 12000).
Le routeur Internet de la gamme Cisco 12000 récupère des erreurs de parité dans d'autres mémoires de cartes de ligne (SDRAM et SRAM) sans s'écraser.
Erreurs de parité/ECC dans le processeur de routage Gigabit de la gamme Cisco 12000
Les données présentant une parité incorrecte peuvent être signalées par plusieurs périphériques de contrôle de parité pour toute opération de lecture ou d'écriture sur le routeur Internet de la gamme Cisco 12000.
Le GRP-B et le PRP utilisent la mémoire SDRAM (Single Bit Error Correction) et ECC (Multi-bit Error Detection) ECC à mémoire partagée (Single Bit Error Correction). Une erreur de bit unique dans la SDRAM est corrigée automatiquement et le système continue à fonctionner normalement.
Erreurs à un bit (SBE)
PRP et GRP-B ont le contrôleur DRAM (Dynamic RAM) amélioré qui prend en charge ECC. Par conséquent, ils peuvent corriger des erreurs monoctet et signaler des erreurs multibit. La correction d'une erreur de bit unique ressemble à ceci :
%Tiger-3-SBE: Single bit error detected and corrected at <address>
Les SBE sont corrigés par le circuit de correction d'erreurs et n'affectent pas la fonctionnalité du GRP-B ou du PRP. Aucune action n'est requise pour les erreurs monoctet, sauf si elles se produisent fréquemment. Dans ce cas, il est conseillé de remplacer la carte processeur.
Erreurs multibits (MBE)
La détection d'une erreur multibit est signalée par une exception d'erreur de bus ou une exception d'erreur de parité de cache du processeur.
Erreurs de parité de mémoire processeur (PMPE)
Un message d'erreur de parité de la mémoire du processeur est signalé si le processeur détecte une erreur de parité lors de l'accès au cache externe du processeur (L3 sur le GRP) via le bus SysAD, ou l'un ou l'autre des mémoires cache internes du processeur (L1 ou L2). Le tableau 1 répertorie des exemples de messages qui seraient imprimés pour chaque type d'erreur de parité de cache :
Tableau 1 : Emplacement des erreurs de parité du cache
| Emplacement de l'erreur de parité | Message d'erreur |
|---|---|
| Cache d'instructions L1 | Erreur : Principal, cache, champs : données |
| Cache de données L1 | Erreur : Principal, cache de données, champs : données |
| Cache d'instructions L2 | Erreur : SysAD, cache d'état, champs : données |
| Cache de données de couche 2 | Erreur : SysAD, cache de données, champs : données |
| Cache d'instructions L3 | Erreur : SysAD, cache d'état, champs : 1ère épée |
| Cache de données C3 | Erreur : SysAD, cache de données, champs : 1ère épée |
Exemple :
La première ligne du message d'erreur indique l'emplacement de l'erreur de parité et peut être n'importe quel emplacement indiqué dans le tableau 1. Dans cet exemple, l'emplacement est L3 Instruction Cache.
Error: SysAD, instr cache, fields: data, 1st dword
Physical addr(21:3) 0x000000,
virtual addr 0x6040BF60, vAddr(14:12) 0x3000
virtual address corresponds to main:text, cache word 0
Low Data High Data Par Low Data High Data Par
L1 Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
Low Data High Data Par Low Data High Data Par
DRAM Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
La sortie de la version show doit être similaire à ceci :
...System was restarted by processor memory parity error at PC 0x602310D0, address 0x0 at 03:18:21 GMT Sun Oct 27 2002 ...
Dans la sortie show context, vous pouvez voir que le système a été redémarré par une exception de parité de cache :
Router#show context slot 11 CRASH INFO: Slot 11, Index 1, Crash at 19:08:07 CST Thu Nov 14 2002 VERSION: GS Software (GSR-P-M), Version 12.0(22)S1, EARLY DEPLOYMENT RELEASE SOFTWARE (fc1) TAC Support: http://www.cisco.com/tac Compiled Mon 16-Sep-02 17:36 by nmasa Card Type: Route Processor, S/N LC uptime was 0 minutes. System exception: sig=20, code=0xE42F3E4B, context=0x52CF3D44 System restarted by a Cache Parity Exception STACK TRACE: -Traceback= 5020453C 500E5E24 5010E6DC 5015F89C 501E9F6C 501E9F58 ...
Remplacer le protocole GRP ou le PRP après une deuxième défaillance.
Message d'erreur %GRP-3-PARITYERR
Le message suivant peut apparaître dans le résultat de la console :
SEC 7: %GRP-3-PARITYERR: Parity error detected in the fabric buffers. Data (8)
Ce message signifie qu'une erreur de parité a été détectée par le matériel de l'interface de fabric sur le protocole GRP. Le nombre hexadécimal indique le vecteur d'interruption d'erreur. Ceci indique généralement un problème matériel sur le GRP qui signale l'erreur (dans ce cas, le logement 7). Le GRP défectueux doit être remplacé lors de la deuxième occurrence d'un problème similaire.
%PRP-3-SBE_DATA : Données incorrectes [hex] [hex] ECC rec [hex] calc [hex]
Ce message d'erreur s'affiche lorsque le routeur reçoit des données présentant une parité incorrecte.
Les données présentant une parité incorrecte sont signalées par plusieurs périphériques de contrôle de parité pour toute opération de lecture ou d'écriture effectuée sur le routeur Internet de la gamme Cisco 12000.
Le PRP utilise la fonction de correction d'erreurs à un bit et la fonction ECC de détection d'erreurs à plusieurs bits pour partager la mémoire (SDRAM). Une erreur de bit unique dans la SDRAM est corrigée automatiquement et le système continue à fonctionner normalement.
Les erreurs à un bit (SBE) sont corrigées par le circuit de correction d'erreurs (ECC) et n'affectent pas la fonctionnalité du PRP. Aucune action n'est requise pour les erreurs monoctet, sauf si elles se produisent fréquemment.
Si l'erreur se produit fréquemment, il est conseillé de remplacer la carte processeur.
Erreurs de parité/ECC dans les cartes de ligne de la gamme Cisco 12000
Erreurs ECC SDRAM
-
Erreurs ECC (Single Bit Error-Correction Code) SDRAM
Une erreur à un seul bit est un seul bit de données qui est incorrect dans un mot lu à partir de la mémoire. Pour les SBE, l'erreur peut être corrigée sans interruption des opérations.
Des erreurs monobbits sont détectées et les données corrigées sont présentées. Par exemple, les erreurs monobbits sont signalées comme suit sur le moteur 4/4+ :
SLOT 6:Jul 19 07:37:34: %TX192-3-SDRAM_SBE: Error=0x2 - DIMM1 Syndrome=0x7600 Addr=0xBEA09 Data bit80-Traceback= 401C8C9C 401C9508 401CDE08 401CDE40 4007F674 4009ED0C 4009ECF8
Les SBE sont corrigés par le circuit de correction d'erreurs et n'affectent pas le fonctionnement de la carte de ligne. Aucune action n'est requise pour les erreurs monoctet, sauf si elles se produisent fréquemment. Dans ce cas, il est conseillé de remplacer la carte de ligne.
-
Erreurs ECC multibits SDRAM
Une erreur multibit est survenue lorsque plusieurs bits sont incorrects dans le même mot. Pour les MBE, l'erreur est détectée et la carte de ligne tombe en panne. La présence de SBE et de MBE est très rare.
Voici un exemple du message imprimé sur la console en réponse à une erreur ECC multibits dans la mémoire SDRAM :
SLOT 5:Jul 25 16:58:51: %MCC192-3-SDRAM_SBE: Error=0x808 - DIMM0 Syndrome=0x31000000 Addr=0x81034 Data bit120 -Traceback= 401C8C9C 401C9508 40450018 400BF7D4 SLOT 5:Jul 25 16:58:51: %MCC192-3-SDRAM_MBE: Error=0x808 - DIMM0 Syndrome=0x18000000 Addr=0x80834 -Traceback= 401C8D88 401C9508 40450018 400BF7D4
Les MBE ne peuvent pas être corrigés par ECC et provoquent le plantage de la carte de ligne. La carte de ligne sera ensuite rechargée et rétablie en fonctionnement normal par le processeur de routage.
Les diagnostics sur site peuvent être utilisés pour vérifier la mémoire des cartes de ligne pour les MBE. Les MBE sont détectés par les diagnostics sur site comme des erreurs de mémoire. Voici un exemple de carte qui a rencontré une erreur multibit sur la SDRAM TX et qui a échoué aux diagnostics sur site :
FDIAG_STAT_IN_PROGRESS(5): test #12 TX SDRAM Marching Pattern FD 5> RIM: FD 5> TX Registers FD 5> INT_CAUSE_REG = 0x00000680 FD 5> Unexpected L3FE Interrupt occured. FD 5> ERROR: TX BMA Asic Interrupt Occured FD 5> *** 0-INT: External Interrupt *** FDIAG_STAT_DONE_FAIL(5) test_num 12, error_code 1 Field Diagnostic: ****TEST FAILURE**** slot 5: last test run 12, TX SDRAM Marching Pattern, error 1 Field Diag eeprom values: run 5 fail mode 1 (TEST FAILURE) slot 5 last test failed was 12, error code 1
Si vous avez une carte de ligne QOC48 ou OC192, reportez-vous à cet avis de champ : QOC48/OC192 SBE/MBE. Sinon, vous devez remplacer la carte de ligne après une deuxième défaillance.
Exceptions de parité du cache
Vérifiez la valeur du champ sig= dans la sortie show context slot [slot#] :
Router#show context slot 4
CRASH INFO: Slot 4, Index 1, Crash at 04:28:56 EDT Tue Apr 20 1999
VERSION:
GS Software (GLC1-LC-M), Version 11.2(15)GS1a, EARLY DEPLOYMENT RELEASE
SOFTWARE (fc1)
Compiled Mon 28-Dec-98 14:53 by tamb
Card Type: 1 Port Packet Over SONET OC-12c/STM-4c, S/N CAB020500AL
System exception: SIG=20, code=0xA414EF5A,
context=0x40337424
System restarted by a Cache Parity Exception
Certaines cartes basées sur le moteur de transfert du moteur 1 sont susceptibles d'être endommagées par le cache interne lorsqu'elles fonctionnent à des conditions de tension et de température très spécifiques.
La fonctionnalité de récupération des erreurs de cache (CERF) est une fonctionnalité logicielle des cartes de ligne Engine1 qui détecte et corrige les erreurs de parité de cache en supprimant les erreurs du cache du processeur externe et en actualisant la ligne de cache à partir de la DRAM. Cette fonctionnalité fournit de l'intelligence dans l'algorithme de gestion du cache du processeur qui permet au processeur de se rétablir d'une erreur de parité de mémoire cache, empêchant ainsi un plantage de carte de ligne sans subir un choc de performances.
Remarque : le CERF est activé par défaut. L'activité de ce code de correction d'erreur logiciel (ECC) peut être surveillée par la commande show controller cerf. Pour désactiver la fonction, utilisez la commande de configuration globale no service cerf.
Voir Avis de champ : Erreur de parité du cache sur la carte GSR 1GE pour plus d'informations.
Pour déterminer sur quel moteur de transfert la carte de ligne est basée, voir Comment puis-je déterminer quelle carte moteur fonctionne dans la boîte ? à partir du routeur Internet de la gamme Cisco 12000 : Document Foire aux questions.
Si la carte de ligne est basée sur le moteur 1, la solution de contournement consiste à mettre à niveau le logiciel Cisco IOS vers une version qui contient la fonctionnalité de récupération des erreurs de cache (CERF). Cette fonctionnalité a été disponible pour la première fois dans le logiciel Cisco IOS Version 12.0(21)S3. Si elle est toujours bloquée par l'exception de parité du cache, la carte de ligne doit être remplacée.
Si la carte de ligne est basée sur un autre type de moteur, vous devez remplacer la carte de ligne lors de la deuxième occurrence d'un crash similaire.
Messages d'erreur de la carte de ligne basée sur le moteur 0
Vous pouvez voir le message suivant dans les journaux de console :
SLOT 2:Oct 23 17:07:45.531 EST: %LC-3-L3FEERRS: L3FE DRAM error 12 address 41E9B9A0 SLOT 2:Oct 23 17:07:45.531 EST: %LC-3-L3FEERR: L3FE error: rxbma 0 addr 0 txbma 0 addr 0 dram 12 addr 41E9B9A0 io 0 addr 0 SLOT 2:Oct 23 17:07:45.531 EST: %GSR-3-INTPROC: Process Traceback= 40080BAC -Traceback= 40357084 40495D30 40496EE0 400CCF98
Ce message signale une erreur de parité d'écriture DRAM du processeur. L3FE désigne le moteur de transfert de couche 3. La carte de ligne doit être remplacée lors de la deuxième occurrence d'un problème similaire.
Messages d'erreur de la carte de ligne basée sur le moteur 1
Voici quelques messages d'erreur que vous pouvez rencontrer :
-
Dans les journaux d'une carte de ligne Gigabit à un port :
SLOT 5: %LCGE-3-INTR: TX GigaTranslator external interface parity error
Pour les cartes plus récentes, une correction a été de remplacer l'ASIC GigaTranslator TX par un FPGA (field-programmable gate array). À la deuxième occurrence d'une question similaire, le conseil devrait être remplacé.
-
Dans le résultat de la console :
SLOT 6: %LC-3-ECC: Salsa ECC: About to handle ECC single bit error, ECC status = 2 DRAM error status = = 21 SLOT 6: %LC-3-L3FEERR: L3FE error: rxbma 0 addr 0 txbma 0 addr 0 dram 21 addr 200020 io 0 addr 0 SLOT 6: %LC-3-ECC: Salsa ECC: Addresses: Salsa returned =429BFDE8 correcting on = 429BFDE8 SLOT 6: %MEM_ECC-3-SBE: Single bit error detected and corrected at 0x429BFDE8 SLOT 6: %MEM_ECC-3-SYNDROME_SBE: 8-bit Syndrome for the detected Single-bit error: 0x8A SLOT 4: %MEM_ECC-3-SBE_HARD: Single bit *hard* error detected at 0x6299FB60 SLOT 1:Jun 10 05:29:47.690 EDT: %LC-3-ECC: Salsa ECC: About to handle ECC single bit error,ECC status = 0 DRAM error status =12 SLOT 6:Sep 26 15:18:01: %LC-3-SWECC: L2 event cleared: EPC = 0x40631CCC, CERR = 0xE40BB933, SysAD Addr = 1, total = 1 SLOT 0:Dec 7 13:48:11.480: %LC-3-SWECC_DATA: L2 event cleared: EPC = 0x400A8040, CERR = 0xA01DCE58, l1v = 0x41E3C20441E3C1C5, dv =0x41E3C1C441E3C204, SysAD Addr = 0, total = 1
Ces messages peuvent être répartis en plusieurs parties :
-
%LC-3-ECC : ECC Salsa - Une erreur s'est produite dans l'ASIC L3FE de la carte de ligne.
-
%LC-3-L3FEERR - Une erreur s'est produite dans l'enregistrement ASIC L3FE de la carte de ligne. informations.
-
%MEM_ECC-3-SBE - Une erreur corrigable à un seul bit a été détectée sur une lecture à partir de la DRAM. La commande show memory ecc peut être utilisée pour vider les erreurs monoctet enregistrées jusqu'à présent. Il s'agit du même message d'erreur %MEM_ECC-3-SBE_LIMIT.
-
%MEM_ECC-3-SYNDROME_SBE - Syndrome de 8 bits pour erreur de bit unique détectée. Cette valeur n'indique pas les positions exactes des bits en erreur, mais peut être utilisée pour approximer leurs positions. Il s'agit du même message d'erreur %MEM_ECC-3-SYNDROME_SBE_LIMIT.
En gros, la carte de ligne a signalé une erreur d’un seul bit et l’a corrigée automatiquement. Aucune action n'est requise de votre part, sauf si cela se produit fréquemment. Dans ce cas, il est conseillé de remplacer la carte de ligne.
-
%LC-3-SWECC_DATA - Indique qu'un événement de cache a été corrigé au niveau LC dans le LOGEMENT 0 par le code de correction d'erreur logicielle (SWECC).
-
-
Voici un autre message que vous pourriez rencontrer :
SLOT 4: %MEM_ECC-3-SBE_HARD: Single bit *hard* error detected at 0x6299FB60
Ce message signifie qu'une erreur incorrigible à un seul bit [erreur matérielle] a été détectée sur un processeur lu à partir de la DRAM. La commande show memory ecc supprime les erreurs monoctet enregistrées jusqu'à présent et indique les emplacements d'adresse d'erreur matérielle détectés.
Surveillez le système à l'aide de la commande show memory ecc et remplacez la DRAM si ces erreurs sont trop nombreuses.
Messages d'erreur de la carte de ligne basée sur le moteur 2
Vous pouvez voir l'erreur suivante dans la sortie de console :
SLOT 6: %LC-6-PSAECC: An TLU SDRAM ECC correctable error occurred address 19C49FD SLOT 2:035610: Feb 26 13:09:13.628 UTC: %LC-6-PSAECC: An PLU SDRAM ECC correctable error occurred address 1956059
Cela signifie que la mémoire SDRAM protégée par l’algorithme PSA (Packet Switching ASIC) ECC a identifié une erreur de bit corrigible. Aucune action n'est requise de votre part, à moins que ces messages ne se produisent fréquemment. Dans ce cas, il est conseillé de remplacer la carte de ligne.
Messages d'erreur de la carte de ligne basée sur le moteur 3
Vous pouvez voir ces erreurs dans la sortie de console :
SLOT 6:00:03:53: %PM622-3-SAR_SRAM_PARITY_ERR: (6/0): Parity error in Reassembly SAR SRAM address: 80000000.Resetting the port SLOT 3:00:00:53: %PM622-3- SAR_MULTIBIT_ECC_ERR: (3/0): Multi-bit ECC Uncorrectable error in SAR SDRAM address: 80000000. Resseting the port. SLOT 4:00:00:53: %PM622-3 SAR_SINGLE_BIT_ECC_ERR: (3/0): ECC corrected an error in SAR SDRAM address: 800000. SLOT 0:Jun 25 20:45:53 KST: %EE48-6-ALPHAECC: RX ALPHA: An PLU SDRAM ECC correctable error occured address 1000C254 SLOT 0:Jun 25 20:45:53 KST: %EE48-6-ALPHAECC2: RX ALPHA: An PLU SDRAM ECC multibit error occured at address 1000E254 SLOT 5:Nov 17 09:46:30.171: %EE48-6-ALPHA_PARITY: TX ALPHA: Transient SRAM64 parity corrected error 3E Data 0 100000 Parity bits 0 SLOT 10:Feb 21 16:55:36: %EE48-3-ALPHA_SRAM64_ERR: TX ALPHA: ALPHA_PST_RANGE_ERR error 11003F Data 0 0 Parity bits 0 SLOT 4:Jan 15 06:30:00.942 UTC: %EE48-2-GULF_TX_SRAM_ERROR: ASIC GULF: TX SRAM uncorrectable error detected. Details=0x0000 SLOT 0:Mar 16 19:50:22.464 cst: %EE48-4-QM_ZBT_PARITY: ToFab Address 0xB95E Data 0x1 SLOT 5:May 17 06:17:35.507: %EE48-4-QM_NON_ZBT_PARITY: ToFab Error 0x10000028 SLOT 5:May 17 06:17:53.883: %EE48-4-QM_ZBT_PARITY_TRANSIENT: FrFab Address 0x0 Data 0x7E SLOT 5:May 17 06:17:53.883: %EE48-4- GULF_RX_TB_PARITY_ERROR: ASIC GULF: RX telecom bus parity error on port 0 SLOT 1:Dec 13 00:27:42: %EE48-3-SRAM_PARITY: SRAM parity: Unable to find shadow 281B9EB4 SLOT 0:Aug 4 08:55:37: %EE48-3-QM_PARITY: FrFab Address 0x1859E Data 0x10 SLOT 0:Aug 4 08:55:37: %EE48-3-QM_ERROR: FrFab error register 0x80000.
Messages d'erreur de la carte de ligne basée sur le moteur 4/4+
-
Vous pouvez rencontrer les messages suivants sur les cartes de ligne basées sur le moteur 4/4+ :
SLOT 4: %RX192-3-HINTR: status = 0x4000000, mask = 0x3FFFFFFF - Parity error on rx_pbc_mem. -Traceback= 401C37C0 403D8814 400BE1EC SLOT 4: %LC-3-ERR_INTR: Error interrupt occurred -Traceback= 400CE028 400C8DF0 40010A24
ou
SLOT 3: %RX192-3-HINTR: status = 0x4000000, mask = 0x3FFFFFFF - Parity error on rx_pbc_mem. -Traceback= 406012E0 406972A0 400C555C %FIB-3-FIBDISABLE: Fatal error, slot 3: IPC failure
ou
SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_SBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 2:00:03:41: %MCC192-6-RED_PARAM1_SBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 2:00:03:41: %MCC192-6-RED_PARAM2_SBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 5:Apr 26 11:56:08.160: %MCC192-3-SDRAM_MBE: Error=0x200 - DIMM1 Syndrome=0x3000 Addr=0x811C3 SLOT 10:Mar 6 05:05:26.965: %RX192-3-ADJ_MEM_MBE: phy addr 0x7905E648, offset 0xBCC9, old ecc 0x0, new ecc 0x0, bit -1, value 0x0 - MBE on Adjacency Memory.. SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_MBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 2:00:03:41: %MCC192-6-RED_PARAM1_MBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 2:00:03:41: %MCC192-3-RED: Error=0x80000 - RED PARAM 1 ECC SBE Error. -Traceback= 405AF5E0 405B1CEC 406DFF7C 406E057C 400FC7E SLOT 2:00:03:41: %MCC192-6-RED_PARAM2_MBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No Sep 8 14:32:09 jst: %MEM_ECC-3-SYNDROME_SBE_LIMIT: 8-bit Syndrome for the detected Single-bit error: 0xD5
Les symptômes de ce problème sont les suivants :
-
Cisco Express Forwarding sur cette carte de ligne est désactivé
-
Les ports associés restent actifs/actifs
-
La carte de ligne peut être automatiquement réinitialisée
Si la carte de ligne ne se réinitialise pas, la solution de contournement consiste à exécuter la commande microcode reload <slot> :
Ce message n'indique pas toujours un problème matériel avec le module RX192. Certains bogues du logiciel Cisco IOS peuvent produire ce message d'erreur comme effet secondaire. Si ce message ne s'affiche qu'une seule fois, continuez à surveiller la carte. Le périphérique sera réinitialisé. Si le problème persiste, la carte est automatiquement réinitialisée. Contactez votre représentant du support technique Cisco pour obtenir de l'aide si ce message persiste.
-
-
Les événements SBE peuvent être vérifiés sur E4/E4+ à l'aide de la commande show controllers mcc192 ecc :
LC-Slot4#show controllers mcc192 ecc MCC192 SDRAM ECC Counters SBE = 0x0, MBE = 0x0 TX192 SDRAM ECC Counters SBE = 0x0, MBE = 0x0Ce rapport porte sur la mémoire RX et TX.
Messages d'erreur de la carte de ligne basée sur le moteur 5/5+
Vous pouvez voir ces erreurs dans la sortie de console :
SLOT 1:Jun 26 20:45:53 KST: %EE192-6-WAHOOECC: RX WAHOO: An PLU SDRAM ECC correctable error occured address 20000254 SLOT 9:Sep 2 21:27:49.680 GMT+8: %MCC192-3-PKTMEM_SBE: Single bit error detected and corrected SLOT 14:Jul 18 07:19:24.637: RX_XBMA: 1-bit CPUIM_ECCERR1 error 0x2 SLOT 15:Jan 4 16:53:16.591: TX_XBMA: (1) QSRAM qinfo SBE detected. info: 0x82605455 SLOT 12:Dec 12 22:34:15: %EE192-4-BM_ERRSSS: FrFab BM BADDR ECC ERR info single bit error(s) corrected, error 8250F63E count: 2 SLOT 1:Nov 22 13:40:02 JST: %EE192-3-QM_ERROR: RX_XBMA OQLLM error error register 0x1 -Traceback= 40AE71AC 406078C4 405F5EC0 SLOT 7:001113: Oct 24 10:50:28.520 BST: %EE192-3-WAHOOERRS: RX WAHOO: WAHOO_CSRAM_CNTRL_INT PIPE0 error 8 SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRSSS: RX WAHOO: WAHOO_FFCRAM_CNTRL_INT PIPE0 error 4 addr 3FBFAB8 agent 94 SLOT 7:001114: Oct 24 10:50:28.520 BST: %EE192-3-WAHOOERRSSSS: RX WAHOO: WAHOO_PPC_INT PIPE1 error pl_ctl 4000226 pl_aa_avl F9F7B pl_aa_end 7FF9 pl_aa_fatal 4800000 SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: RX WAHOO WAHOO_NFC_SRAM_MULTI_ECC_ERR multi-bit CSSRAM error SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_CTCAM_CNTRL_INT multi-bit CSRAM error SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_FFCRAM_CNTRL_INT MBE SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: FSRAM not OK WAHOO_FSRAM_CNTRL_INT ECC_1_BIT_EE | ECC_UNCORR_EE SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_CTCAM_CNTRL_INT multi-bit CSRAM error SLOT 1:00:01:14: WEEKLY_THROTTLE_SOCKEYE_SBE: SOCKEYE SBE: addr: 0xC2A007C0, synd: 0xC4 SLOT 1:00:01:14: WEEKLY_THROTTLE_CBSRAM_SBE_TX+i: CBSRAM SBE TX: 1-bit CBSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CBSRAM_SBE_RX+i: CBSRAM SBE RX: 1-bit CBSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSSRAM_SBE_TX+i: CSSRAM SBE TX: 1-bit CSSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSSRAM_SBE_RX+i: CSSRAM SBE RX: 1-bit CSSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSRAM_SBE_TX+i: CSRAM SBE TX: 1-bit CSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSRAM_SBE_RX+i: CSRAM SBE RX: 1-bit CSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FW_TCAM_PRTY_TX+throttle_i: TX FTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FW_TCAM_PRTY_RX+throttle_i: RX FTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_CL_TCAM_PRTY_TX+throttle_i: TX CLTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_CL_TCAM_PRTY_RX+throttle_i: RX CLTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_NF_TCAM_PRTY_TX+throttle_i: TX NFTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_NF_TCAM_PRTY_RX+throttle_i: RX NFTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_TCAM_PRTY_VMR: TCAM PRTY VMR error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_TCAM_PRTY_NO-VMR: TCAM PRTY NO-VMR error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_SBE_TX: FCRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_SBE_RX: FCRAM SBE TX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_PER_CHIP_SBE_TX: FCRAM CHIP SBE error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FCRAM_PER_CHIP_SBE_RX: FCRAM CHIP SBE error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FSRAM_SBE_TX: FSRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FSRAM_SBE_RX: FSRAM SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FSRAM_MBE_TX: FSRAM MBE RX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FSRAM_MBE_RX: FSRAM MBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_ISERR_TX: ISERR TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_ISERR_RX: ISERR RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_FCRAM_SBE_TX: FCRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_FCRAM_SBE_RX: FCRAM SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_LINK_SBE_TX: QSRAM LINK SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_LINK_SBE_RX: QSRAM LINK SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_QEINFO_SBE_TX: QSRAM queue info sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_QEINFO_SBE_TX: QSRAM queue info sbe rx error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_BADDR_SBE_TX: qsram bad addr sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_ QM_QSRAM_BADDR_SBE_RX: qsram bad addr sbe rx error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_OQLLM_SBE_TX: oqllm sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_OQLLM_SBE_RX: oqllm sbe rx error status = 0x3
Messages d'erreur de la carte de ligne basée sur le moteur 6
Vous pouvez voir ces erreurs dans la sortie de console :
SLOT 0:Jan 14 08:53:44.581 GMT: %FIA-3-RAMECCERR: To Fabric ECC error was detected Single Bit Error RAM2 status = 0x8000 Syndrome = 0x0 addr = 0x0 SLOT 6:Apr 29 09:36:12: %E6LC-4-ECC_THRESHOLD: HERMES VID SBE exceeded threshold, possible memory failure SLOT 4:*Mar 13 23:38:19.295: %E6_RX192-3-MTRIE_SBE: Head1 Syndrome=0x94 Addr=0xFFF2B -Traceback= 40544830 40546A90 40688C94 400EDC18 SLOT 7:*Mar 4 1234:19.295: %E6_RX192-3-ADJ_SBE: Syndrome=0x59 Addr=0xFFF2B -Traceback= 40000830 40036A90 40555D44 400ddd23 SLOT 14:Dec 9 20:02:29: %E6_RX192-6-PBC_SBE: Single bit error detected and corrected RLDRAM Syndrome=0x61 Addr=0xF855 Dec 9 20:02:33: %GRP-4-RSTSLOT: Resetting the card in the slot: 14,Event: linecard error report SLOT 4:06:21:43: %E6_RX192-3-ACL_SBE: ACTION MEM Syndrome=0x7 Addr=0x0 -Traceback= 40549740 4054A7E0 4068D814 400EE018 SLOT 6:Mar 28 03:30:19: %RX192-3-HINTR: status = 0x1000000000000, mask = 0x7FFFFF0FA320F - L3X SBE error. -Traceback= 405816DC 406A1010 406A1650 400F70E8 SLOT 6:Mar 28 03:30:19: %E6_RX192-6-VID_SBE: Single bit error detected and corrected VID memory Syndrome=0x19 Addr=0xE51B SLOT 6:Nov 27 23:32:36: %HERA-3-PKTMEM_SBE: Single bit error detected and corrected Error=0x80 – Syndrome=0x5100000000000000 Addr=0x894620 Data bit116 SLOT 7:Oct 2 23:32:36: %HERA-6- MCD_SBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 1:Jun 22 03:32:36: %HERA-6- MRW_SBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 12:May 24 03:03:36: %HERA-6- UPF_SBE: Single bit error detected and corrected Error=0x60 – Syndrome=0x4100000000000000 Addr=0x451140 Data bit216 SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_SBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 9:May 5 18:52:14: %HERA-6-QM_FBF_SBE: Free Block FIFO - Single Bit Error detected and corrected Syndrom = 0x10, Addr = 0x778, samebit Yes, diffbit No SLOT 9:May 5 18:52:14: %HERA-3-QM: Error=0x40 - FBF RAM ECC SBE. -Traceback= 405AD4CC 405AF5D0 405F2E80 406DCDB8 406DD434 400FC500 SLOT 3:Aug 16 00:45:14: %MCC192-6-RED_AQD_SBE: Average Queue Depth - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x89, samebit No, diffbit No SLOT 2:Jan 23 06:29:56 KST: %MCC192-6-RED_STAT_SBE: Statistics - Single Bit Error detected and corrected Syndrome = 0x38, Address = 0xFF, samebit No, diffbit No SLOT 4:*Mar 13 23:38:19.295: %E6_RX192-3-MTRIE_MBE: Single bit error detected and corrected Head1 Syndrome=0x94 Addr=0xFFF2B SLOT 7:*Mar 4 1234:19.295: %E6_RX192-3-ADJ_MBE: Syndrome=0x59 Addr=0xFFF2B -Traceback= 40000830 40036A90 40555D44 400ddd23 00:00:18: %E6_RX192-3-PBC_MBE: ADJ OBANK LO Syndrome=0xE5 Addr=0x142 -Traceback= 405BF8B0 405C0F08 406E8D78 406E93B8 400FCCE0 SLOT 6:Mar 28 03:30:19: %E6_RX192-6-VID_MBE: Single bit error detected and corrected VID memory Syndrome=0x19 Addr=0xE51B SLOT 0:Apr 18 06:44:53.751 GMT: %HERA-3-PKTMEM_MBE: Error=0x1010 - Syndrome=0x9900000000 SLOT 7:Oct 2 23:32:36: %HERA-6- MCD_MBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 1:Jun 22 03:32:36: %HERA-6- MRW_MBE: Single bit error detected and corrected Error=0x50 - Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_MBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 9:May 5 18:52:14: %HERA-6-QM_FBF_MBE: Free Block FIFO - Single Bit Error detected and corrected Syndrome = 0x10, Addr = 0x778, samebit Yes, diffbit No SLOT 3:Aug 16 00:45:14: %MCC192-6-RED_AQD_MBE: Average Queue Depth - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x89, samebit No, diffbit No SLOT 2:Jan 23 06:29:56 KST: %MCC192-6-RED_STAT_MBE: Statistics - Single Bit Error detected and corrected Syndrome = 0x38, Address = 0xFF, samebit No, diffbit No
Messages d'erreur SPA
Vous pouvez voir ces erreurs dans la sortie de console :
SLOT 7:Jan 4 02:04:00.487: %SPA_CHOC_DSX-3-UNCOR_PARITY_ERR: SPA4/0: CHOC SPA parity error(s) encountered SLOT 7:Jan 4 02:04:00.487: %MCT1E1-3-UNCOR_PARITY_ERR: SPA5/0: T1E1 SPA parity error(s) encountered SLOT 3: 00:33:48: %MCT1E1-3-UNCOR_MEM_ERR: SPA3/0: 1 uncorrectable HDLC SRAM memory error(s) encountered. SLOT 1:Oct 3 14:42:45.727: %SPA_PLIM-4-SBE_ECC: SPA-4XT3/E3[1/2] reports 2 SBE occurrence at 1 addresses SLOT 1: Jul 22 05:26:29.613 UTC: %SPA_DATABUS-3-SPI4_SINGLE_DIP4_PARITY: SIP Sbslt 0 Ingress Sink - A single DIP4 parity error has occurred on the data bus. SLOT 4: Dec 2 22:44:05: %SPA_DATABUS-3-SPI4_SINGLE_DIP2_PARITY: SIP Sbslt 0 Egress Source - A single DIP 2 parity error on the FIFO status bus has occurred. SLOT 1:Oct 3 14:42:45.727: %SPA_PLIM-4-SBE_OVERFLOW: SPA-4XT3/E3[1/2] reports SBE table (2 elements) overflows SLOT 1:Oct 3 14:42:45.727: % SPA_PLUGIN-3-SPI4_SETCB: SPA-4XT3/E3[1/2] : IPC SPI4 set callback failed(status 2).
Erreurs de parité dans les cartes de matrice de commutation de la gamme Cisco 12000
Tous les messages d'erreur de parité relatifs aux cartes de matrice de commutation sont traités en détail dans le Dépannage matériel du routeur Internet de la gamme Cisco 12000. Ces messages incluent (liste non exhaustive) :
%FABRIC-3-PARITYERR: To Fabric parity error was detected. Grant parity error Data = 0x2. SLOT 1:%FABRIC-3-PARITYERR: To Fabric parity error was detected. Grant parity error Data = 0x1
 Commentaires
Commentaires