procédure de dégroupage nV ASR 9000
Options de téléchargement
-
ePub (826.9 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (526.6 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Introduction
Ce document décrit certaines des fonctionnalités de cluster nV de l'ASR 9000 et comment les dégrouper.
La procédure a été testée dans un environnement réel avec des clients Cisco qui ont déjà décidé d'utiliser le processus de déclustering expliqué dans ce document.
Conditions préalables
Exigences
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- IOS XR
- Plate-forme ASR 9000
- fonctionnalité de cluster nV
Composants utilisés
Les informations contenues dans ce document sont basées sur la plate-forme ASR 9000 exécutant IOS XR 5.x.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
L'unité commerciale de produit (BU) a annoncé la fin de commercialisation (EOS) de nV Cluster sur la plate-forme ASR 9000 : Annonce de fin de commercialisation et de fin de vie pour le cluster Cisco nV
Comme vous pouvez le lire dans l'annonce, le dernier jour de commande de ce produit est le 15 janvier 2018 et la dernière version prise en charge pour le cluster nV est IOS-XR 5.3.x.
Les jalons à prendre en compte sont répertoriés dans ce tableau :

ASR9k nV Cluster - Notions de base et considérations
L'objectif de cette section est de fournir une brève mise à jour sur les configurations et les concepts de cluster nécessaires pour comprendre les sections suivantes de ce document.

Canal hors bande Ethernet (EOBC)
Le canal hors bande Ethernet étend le plan de contrôle entre les deux châssis ASR9k et se compose idéalement de 4 interconnexions qui établissent un maillage entre le processeur de commutation de route (RSP) de différents châssis. Cette configuration offre une redondance supplémentaire en cas de défaillance de la liaison EOBC. Le protocole UDLD (Unidirectional Link Detection Protocol) assure le transfert bidirectionnel des données et détecte rapidement les défaillances de liaison. Le mauvais fonctionnement de toutes les liaisons EOBC affecte sérieusement le système de cluster et peut avoir de graves conséquences qui sont présentées plus loin dans la section Scénarios de noeud partagé.
Liaisons entre racks (IRL)
Les liaisons inter-racks étendent le plan de données entre les deux châssis ASR9k. Idéalement, seuls les paquets de point et d'injection de protocole traversent l'IRL, à l'exception des services à hébergement unique ou lors de pannes de réseau. En théorie, tous les systèmes d'extrémité sont à double hébergement avec une liaison aux deux châssis ASR9K. Tout comme les liaisons EOBC, UDLD s'exécute au-dessus de l'IRL pour surveiller l'état de transfert bidirectionnel des liaisons.
Un seuil IRL peut être défini pour empêcher l'IRL congestionné d'abandonner des paquets en cas de défaillance LC, par exemple. Si le nombre de liaisons IRL est inférieur au seuil configuré pour ce châssis, toutes les interfaces du châssis sont désactivées en raison d'erreurs et arrêtées. Cela isole fondamentalement le châssis affecté et s'assure que tout le trafic passe par l'autre châssis.
Remarque : la configuration par défaut est équivalente à nv edge data minimum 1 backup-rack-interfaces, ce qui signifie que si aucune IRL n'est à l'état forwarding, le contrôleur DSC (Designated Shelf Controller) de sauvegarde est isolé.
Scénarios de noeud partagé
Dans cette sous-section, vous pouvez trouver les différents scénarios de défaillance qui peuvent être rencontrés lors de l'utilisation de clusters ASR9k :
IRL Down
Il s'agit du seul scénario de noeud partagé qui peut être prévu lors du dégroupage, ou si l'un des châssis tombe sous le seuil IRL et devient isolé en conséquence.
EOBC Down
Les deux châssis de l'ASR9k ne peuvent pas fonctionner comme un seul châssis sans le plan de contrôle étendu fourni par les liaisons EOBC. Des balises périodiques sont échangées sur les liaisons IRL de sorte que chaque châssis sache que l'autre châssis est actif. Par conséquent, l'un des châssis, généralement celui équipé du contrôleur DSC de secours, se met hors service et redémarre. Le châssis Backup-DSC reste dans la boucle d'amorçage tant qu'il reçoit les balises du châssis Primary-DSC sur l'IRL.
Split Brain
Dans le scénario Split Brain, les liaisons IRL et EOBC sont désactivées et chaque châssis se déclare Primary-DSC. Les périphériques réseau voisins voient soudainement des ID de routeur en double pour les protocoles IGP et BGP, ce qui peut provoquer de graves problèmes sur le réseau.
Ensembles
De nombreux clients utilisent des bundles côté périphérie et coeur de réseau pour simplifier la configuration du cluster ASR9K et faciliter l'augmentation de la bande passante à l'avenir. Cela peut entraîner des problèmes lors du dégroupage en raison de la connexion de différents membres du bundle à différents châssis. Ces approches sont possibles :
- Créez de nouveaux bundles pour toutes les interfaces connectées au châssis 1 (Backup-DSC).
- Introduisez l'agrégation de liaisons multichâssis (MCLAG).
Domaine L2
La division du cluster peut potentiellement séparer le domaine de couche 2, s'il n'y a pas de commutateur dans l'accès qui interconnecte les deux châssis autonomes. Afin de ne pas bloquer le trafic, vous devez étendre le domaine L2, ce qui peut être fait si vous configurez des connexions locales L2 sur l'IRL précédente, des pseudo-fils (PW) entre le châssis, ou si vous utilisez toute autre technologie de réseau privé virtuel de couche 2 (L2VPN). À mesure que la topologie du domaine de pont évolue avec le dégroupage, gardez à l'esprit la possibilité de créer une boucle lorsque vous sélectionnez la technologie L2VPN de votre choix.
Le routage statique dans l'accès vers une interface virtuelle de groupe de ponts (BVI) sur le cluster ASR9K est susceptible de se transformer en une solution basée sur le protocole HSRP (Hot Standby Router Protocol) utilisant l'adresse IP BVI précédente comme adresse IP virtuelle.
Services à domicile unique
Les services à hébergement unique ont un temps d'arrêt prolongé pendant la procédure de dégroupage.
Accès de gestion
Pendant le processus de dégroupage, les deux châssis sont isolés pendant une courte période, du moins lors de la transition du routage statique (BVI) au routage statique (HSRP) afin de ne pas avoir de routage inattendu et asymétrique.
Vous devez vérifier le fonctionnement de la console et de l'accès de gestion hors bande avant de vous verrouiller.
procédure de dégroupage ASR9000
L'état initial
Supposons qu'à l'état initial, le châssis 0 est actif, tandis que le châssis 1 est de secours (pour des raisons de simplicité). Dans la vie réelle, cela peut être l'inverse ou même RSP1 dans le châssis 0 peut être actif.
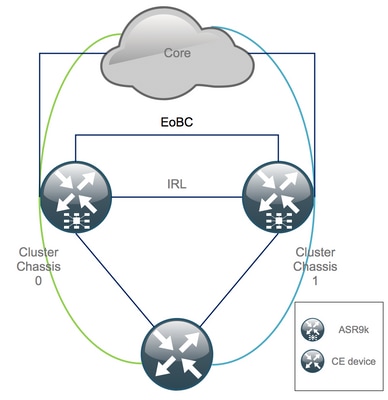
Liste de contrôle avant la fenêtre de maintenance (MW)
- Préparez les nouvelles configurations des châssis ASR9K 0 et 1 (configuration admin + configuration).
- Préparer les nouvelles configurations du système final (périphérie client (CE), pare-feu (FW), commutateurs, etc.).
- Préparer les nouvelles configurations du système principal (noeuds P, noeuds PE (Provider Edge), réflecteur de route (RR), etc.).
- Vérifiez les nouvelles configurations, stockez-les sur le périphérique et à distance sur un serveur TFTP (Trivial File Transfer Protocol).
- Définir les tests d'accessibilité qui doivent être exécutés avant/pendant/après le MW.
- Collecter les sorties du plan de contrôle pour les protocoles IGP (Interior Gateway Protocol), BGP (Border Gateway Protocol), MPLS (Multiprotocol Label Switching), LDP (Label Distribution Protocol), etc. pour la comparaison avant/après.
- Ouvrez une demande de service proactive auprès de Cisco.
Étape 1. Connectez-vous au cluster ASR9000 et vérifiez la configuration actuelle
1. Vérifiez l'emplacement du châssis principal - de secours. Dans cet exemple, le châssis principal est 0:
RP/0/RSP0/CPU0:Cluster(admin)# show dsc --------------------------------------------------------- Node ( Seq) Role Serial# State --------------------------------------------------------- 0/RSP0/CPU0 ( 1279475) ACTIVE FOX1441GPND PRIMARY-DSC <<< Primary DSC in Ch1 0/RSP1/CPU0 ( 1223769) STANDBY FOX1432GU2Z NON-DSC 1/RSP0/CPU0 ( 0) ACTIVE FOX1432GU2Z BACKUP-DSC 1/RSP1/CPU0 ( 1279584) STANDBY FOX1441GPND NON-DSC
2. Vérifiez que toutes les cartes de ligne (LC)/RSP sont à l'état « IOS XR RUN » :
RP/0/RSP0/CPU0:Cluster# sh platform Node Type State Config State ----------------------------------------------------------------------------- 0/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 0/RSP1/CPU0 A9K-RSP440-TR(Standby) IOS XR RUN PWR,NSHUT,MON 0/0/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 0/0/0 A9K-MPA-4X10GE OK PWR,NSHUT,MON 0/0/1 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/1/CPU0 A9K-MOD80-TR IOS XR RUN PWR,NSHUT,MON 0/1/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/2/CPU0 A9K-40GE-E IOS XR RUN PWR,NSHUT,MON 1/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 1/RSP1/CPU0 A9K-RSP440-SE(Standby) IOS XR RUN PWR,NSHUT,MON 1/1/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/1/1 A9K-MPA-2X10GE OK PWR,NSHUT,MON 1/2/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/2/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 1/2/1 A9K-MPA-4X10GE OK PWR,NSHUT,MON
Étape 2. Configuration du seuil IRL minimum pour le châssis de secours
Le châssis de secours est le châssis équipé de la carte BACKUP-DSC. Il est mis hors service et décluster en premier. Dans cet exemple, le BACKUP-DSC se trouve dans le châssis 1.
Avec cette configuration, si le nombre d'IRL tombe en dessous du seuil minimum configuré (1 dans ce cas), toutes les interfaces sur le rack spécifié (rack de secours - châssis 1 dans ce cas) sont arrêtées :
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data min 1 spec rack 1 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
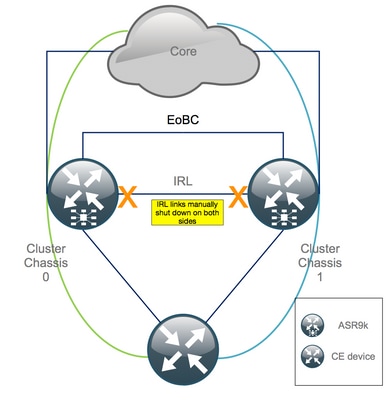
Étape 3. Arrêtez toutes les interfaces IRL et vérifiez les interfaces Error-Disable sur le châssis 1
1. Fermez tous les IRL existants. Dans cet exemple, vous pouvez voir un arrêt manuel de l'interface dans les deux châssis (active Ten0/x/x/x et standby Ten1/x/x/x) :
RP/0/RSP0/CPU0:Cluster(config)# interface Ten0/x/x/x shut interface Ten0/x/x/x shut […] interface Ten1/x/x/x shut interface Ten1/x/x/x shut […] commit
2. Vérifiez que toutes les listes de contrôle d’accès configurées sont désactivées :
RP/0/RSP0/CPU0:Cluster# show nv edge data forwarding location
0/RSP0/CPU0 est un exemple de <location>.
Après l'arrêt de toutes les interfaces IRL, le châssis 1 doit être complètement isolé du plan de données en déplaçant toutes les interfaces externes à l'état désactivé en cas d'erreur.
3. Vérifiez que toutes les interfaces externes du châssis 1 sont à l'état err-disabled et que tout le trafic passe par le châssis 0 :
RP/0/RSP0/CPU0:Cluster# show error-disable
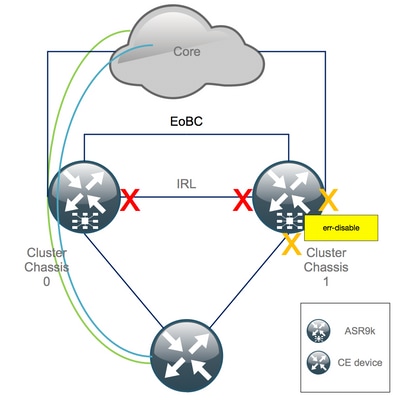
Étape 4. Arrêter toutes les liaisons EOBC et vérifier leur état

1. Fermez les liaisons EOBC sur tous les RSP :
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge control control-link disable 0 loc 0/RSP0/CPU0 nv edge control control-link disable 1 loc 0/RSP0/CPU0 nv edge control control-link disable 0 loc 1/RSP0/CPU0 nv edge control control-link disable 1 loc 1/RSP0/CPU0 nv edge control control-link disable 0 loc 0/RSP1/CPU0 nv edge control control-link disable 1 loc 0/RSP1/CPU0 nv edge control control-link disable 0 loc 1/RSP1/CPU0 nv edge control control-link disable 1 loc 1/RSP1/CPU0 commit
2. Vérifiez que toutes les liaisons EOBC sont désactivées :
RP/0/RSP0/CPU0:Cluster# show nv edge control control-link-protocols location 0/RSP0/CPU0
Après cette étape, les châssis de cluster sont complètement isolés les uns des autres en termes de contrôle et de plan de données. Toutes les liaisons du châssis 1 sont à l'état err-disable.
Remarque : désormais, les configurations doivent être effectuées sur le châssis 1 via la console RSP et n'affectent que le châssis local !
Étape 5. Connectez-vous au RSP actif du châssis 1 et supprimez l'ancienne configuration
Effacez la configuration existante sur le châssis 1 :
RP/1/RSP0/CPU0:Cluster(config)# commit replace RP/1/RSP0/CPU0:Cluster(admin-config)# commit replace
Remarque : vous devez d'abord remplacer la configuration pour la configuration en cours et seulement après effacer la configuration en cours admin. Cela est dû au fait que la suppression du seuil IRL dans la configuration en cours de l'administrateur ne « no shut » toutes les interfaces externes. Cela peut entraîner des problèmes dus à des ID de routeur dupliqués, etc.
Étape 6. Boot Chassis 1 en mode ROMMON
1. Définissez le registre de configuration pour démarrer dans ROMMON :
RP/1/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Vérifiez les variables de démarrage :
RP/1/RSP0/CPU0:Cluster(admin)# show variables boot
3. Rechargez les deux RSP du châssis 1 :
RP/1/RSP0/CPU0:Cluster# admin reload location all
Après cette étape, le châssis 1 démarre normalement dans ROMMON.
Étape 7. Supprimez les variables CLuster sur le châssis 1 dans ROMMON sur les deux RSP
Avertissement : le technicien sur site doit supprimer toutes les liaisons EOBC avant de continuer.
Conseil : il existe également une alternative pour définir les variables de cluster système. Section de vérification Annexe 2 : Définissez la variable Cluster sans démarrer le système dans rommon.
1. La procédure standard exige de connecter le câble de console au RSP actif sur le châssis 1, et de désactiver et de synchroniser la variable ROMMON du cluster :
unset CLUSTER_RACK_ID sync
2. Réinitialisez les registres de configuration à 0x102 :
confreg 0x102 reset
Le RSP actif est défini.
3. Connectez le câble de console au RSP de secours du châssis 1. Idéalement, les 4 RSP du cluster disposent d'un accès à la console pendant la fenêtre de maintenance.
Remarque : les actions décrites dans cette étape doivent être effectuées sur les deux RSP du châssis 1. Le RSP actif doit être démarré en premier.
Étape 8. Démarrez le châssis 1 en tant que système autonome et configurez-le en conséquence
Idéalement, la nouvelle configuration ou plusieurs extraits de configuration sont stockés sur chaque châssis ASR9k et chargés après le dégroupage. La syntaxe de configuration correcte doit être testée dans les travaux pratiques précédents. Si ce n'est pas le cas, configurez d'abord la console et les interfaces MGMT, avant de terminer la configuration sur le châssis 1, soit par copier-coller sur Virtual Teletype (VTY), soit en chargeant la configuration à distance à partir d'un serveur TFTP.
Remarque : les commandes load config et commit maintiennent toutes les interfaces à l'arrêt, ce qui permet une montée en charge contrôlée du service. load config et commit replace remplacent entièrement la configuration et activent les interfaces. Par conséquent, il est recommandé d'utiliser load config et commit.
Adaptez la configuration des systèmes d'extrémité connectés (FW, commutateurs, etc.) et des périphériques principaux (P, PE, RR, etc.) au châssis 1.
Étape 9. Restaurer les services principaux sur le châssis 1
- Commencez par débloquer manuellement les interfaces principales.
- Vérifier les contiguïtés/appairages LDP, Intermediate System to Intermediate System (IS-IS ou ISIS) et BGP.
- Vérifiez les tables de routage et assurez-vous que tous les préfixes ont été échangés.
Avertissement : méfiez-vous des minuteurs tels que le bit de surcharge ISIS (OL), le délai HSRP, le délai de mise à jour BGP, etc. avant de passer au basculement !
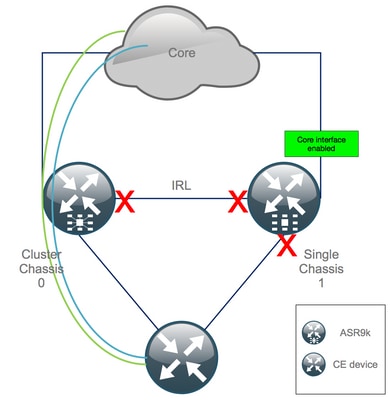
Étape 10. Basculement - Connectez-vous au RSP actif du châssis 0 et mettez toutes les interfaces en état Error-Disable
Attention : les étapes suivantes entraînent une interruption du service. Les interfaces du châssis 1 vers le sud sont toujours désactivées, tandis que le châssis 0 est isolé

Le temps d'attente par défaut est égal à 180s (3x60s) et représente le pire cas de convergence BGP. Il existe plusieurs options de conception et fonctionnalités BGP qui permettent un temps de convergence beaucoup plus rapide, comme le suivi de tronçon suivant BGP. Supposons qu'il y ait différents fournisseurs tiers présents dans le coeur qui se comportent différemment de Cisco IOS XR, vous devrez éventuellement accélérer la convergence BGP manuellement avec un logiciel arrêté des voisins BGP entre le châssis 0 et le RR, ou similaire, avant de déclencher le basculement :
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data minimum 1 specific rack 0 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
Comme toutes les interfaces IRL sont désactivées, le châssis 0 doit être isolé et toutes les interfaces externes doivent passer à l'état error-disabled.
Vérifiez que toutes les interfaces externes du châssis 0 sont à l'état err-disabled :
RP/0/RSP0/CPU0:Cluster# show error-disable
Le châssis 1 a été reconfiguré en tant que boîtier autonome. Il ne doit donc pas y avoir d'interfaces désactivées par erreur. La seule chose qu'il reste à faire sur le châssis 1 est d'activer les interfaces en périphérie.
Étape 11. Restaurer le côté sud sur le châssis 1
1. no shutdown all access interfaces.

Maintenez la liaison d’interconnexion (IRL précédente) hors tension pour l’instant.
2. Vérifiez les contiguïtés/appairages/DB IGP et BGP. Pendant que les protocoles IGP et BGP convergent, vous vous attendez à voir une certaine perte de trafic sur vos requêtes ping à partir du PE distant.
Étape 12. Connectez-vous au RSP actif du châssis 0 et supprimez la configuration
Effacez la configuration existante sur le châssis actif :
RP/0/RSP0/CPU0:Cluster(config)# commit replace RP/0/RSP0/CPU0:Cluster(admin-config)# commit replace
Remarque : vous devez d'abord remplacer la configuration pour la configuration en cours et seulement après effacer la configuration en cours admin. Cela est dû au fait que la suppression du seuil IRL dans la configuration en cours d'administration n'arrête pas toutes les interfaces externes. Cela peut entraîner des problèmes dus à des ID de routeur dupliqués, etc.
Étape 13. Boot Chassis 0 dans ROMMON
1. Définissez le registre de configuration pour démarrer dans ROMMON :
RP/0/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Vérifiez les variables de démarrage :
RP/0/RSP0/CPU0:Cluster# admin show variables boot
3. Rechargez les deux RSP du châssis de secours :
RP/0/RSP0/CPU0:Cluster# admin reload location all
Après cette étape, le châssis 0 démarre normalement en mode ROMMON.
Étape 14. Annuler la définition des variables de cluster sur le châssis 0 dans ROMMON sur les deux RSP
1. Connectez le câble de console au RSP actif sur le châssis 0.
2. Désactiver et synchroniser la variable ROMMON du cluster :
unset CLUSTER_RACK_ID sync
3. Réinitialisez les registres de configuration à 0x102 :
confreg 0x102 reset
Le RSP actif est défini.
4. Connectez le câble de console au RSP de secours sur le châssis 0.
Remarque : les actions décrites dans cette étape doivent être effectuées sur les deux RSP du châssis 1. Le RSP actif doit être démarré en premier.
Étape 15. Boot Chassis 0 en tant que système autonome et le configurer en conséquence
Idéalement, la nouvelle configuration ou plusieurs extraits de configuration sont stockés sur chaque châssis ASR9k et chargés après le dégroupage. La syntaxe de configuration correcte doit être testée dans les travaux pratiques précédents. Si ce n'est pas le cas, configurez d'abord la console et les interfaces MGMT, avant de terminer la configuration sur le châssis 0, soit par VTY (copier-coller), soit en chargeant la configuration à distance à partir d'un serveur TFTP.
Remarque : les commandes load config et commit maintiennent toutes les interfaces à l'arrêt, ce qui permet une montée en charge contrôlée du service. load config et commit replace remplacent entièrement la configuration et activent les interfaces. Par conséquent, il est recommandé d'utiliser load config et commit.
Adaptez la configuration des systèmes d'extrémité connectés (FW, commutateurs, etc.) et des périphériques principaux (P, PE, RR, etc.) au châssis 0.
Étape 16. Restaurer les services principaux sur le châssis 0
- Commencez par débloquer manuellement les interfaces principales.
- Vérifiez les contiguïtés/appairages LDP, ISIS, BGP.
- Vérifiez que les tables de routage et assurez-vous que tous les préfixes ont été échangés.
Avertissement : méfiez-vous des minuteurs tels que ISIS OL-Bit, HSRP delay, BGP Update delay, etc avant de passer au basculement !
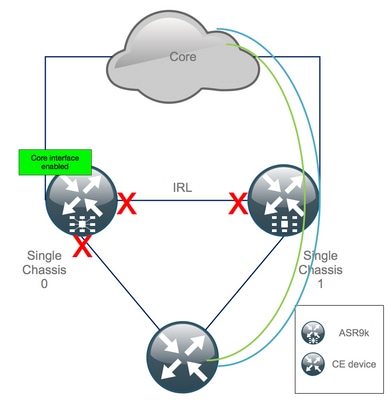
Étape 17. Restaurer le côté sud sur le châssis 0
1. no shutdown all access interfaces.
2. Vérifier les contiguïtés/appairages/DB IGP et BGP
3. Vérifiez que la liaison inter-châssis (IRL précédente) est activée, si nécessaire pour l'extension L2, etc.

Annexe 1 : Configuration d'un châssis unique
Modifications générales de configuration
Cette configuration de routeur doit être modifiée sur l'un des châssis :
- Adresses d’interface de bouclage.
- Numérotation d’interface (par exemple Te1/x/x/x -> Te0/x/x/x).
- Descriptions des interfaces.
- Adressage d'interface (lors de la division de faisceaux existants).
- Nouvelles interfaces BVI (lorsque le domaine L2 est à double résidence).
- Extension L2 (lorsque le domaine L2 est à double résidence).
- HSRP pour le routage statique dans l'accès.
- ID de routeur BGP/Open Shortest Path First (OSPF)/LDP.
- Distincteurs de route BGP.
- Homologues BGP.
- Type de réseau OSPF.
- ID SNMP (Simple Network Management Protocol), etc.
- Access Control List (ACL), Prefix-Sets, Routing Protocol for LLN (Low-Power and Lossy Networks) (RPL), etc.
- Nom de l'hôte.
Présentation du bundle
Assurez-vous que toutes les offres groupées sont examinées et appliquées à la nouvelle configuration double PE. Vous n'avez peut-être plus besoin de bundles et les périphériques double équipement client (CPE) à résidence s'adaptent à votre configuration ou vous avez besoin de MCLAG sur les périphériques PE et conservez les bundles vers les CPE.
Annexe 2 : Définition de la variable de cluster sans initialisation du système dans ROMMON
Il existe également une alternative pour définir les variables de cluster. Les variables de cluster peuvent être définies à l'avance en procédant comme suit :
RP/0/RSP0/CPU0:xr#run Wed Jul 5 10:19:32.067 CEST # cd /nvram: # ls cepki_key_db classic-rommon-var powerup_info.puf sam_db spm_db classic-public-config license_opid.puf redfs_ocb_force_sync samlog sysmgr.log.timeout.Z # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , CLUSTER_RACK_ID = 1, TFTP_RETRY_COUNT = 4, confreg = 0x2102 # nvram_rommonvar CLUSTER_RACK_ID 0 <<<<<<< to set CLUSTER_RACK_ID=0 # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , TFTP_RETRY_COUNT = 4, CLUSTER_RACK_ID = 0, confreg = 0x2102 #exit RP/0/RSP0/CPU0:xr#
Rechargez le routeur et démarrez-le en tant que boîtier autonome. Avec cette étape, vous pouvez sauter pour démarrer le routeur à partir de ROMMON.
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
1.0 |
05-Apr-2019 |
Première publication |
Contribution de
- Robert VerlicServices avancés
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)