Introduction
Ce document décrit les étapes de dépannage pour gérer les erreurs de mémoire sur les serveurs UCS.
Conditions préalables
Exigences
Cisco vous recommande de prendre connaissance des rubriques suivantes .
- Compréhension de base d'UCS.
- Compréhension de base de l'architecture de mémoire.
Composants utilisés
Les informations contenues dans ce document sont basées sur les versions de matériel et de logiciel suivantes :
- Serveurs de la gamme UCS M5, M6, M7 et supérieurs.
- UCS Manager
- Contrôleur de gestion intégré Cisco (CIMC)
- Mode géré Cisco Intersight (IMM)
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
Erreurs de mémoire
Des erreurs de mémoire se produisent lors d'une tentative de lecture d'un emplacement de mémoire. La valeur lue dans la mémoire ne correspond pas à la valeur qui est censée y être. Ces erreurs sont classées en deux types :
1. Erreurs logicielles
Les erreurs logicielles sont passagères et ne se répètent plus. Ces problèmes sont temporaires et peuvent souvent être corrigés par une nouvelle tentative de lecture ou de réécriture de l'emplacement mémoire.
2. Erreurs dures
Les défauts physiques permanents en sont la cause. La réécriture de l'emplacement mémoire et la nouvelle tentative d'accès en lecture n'éliminent pas une erreur matérielle. Par conséquent, cette erreur de mémoire n'est pas corrigible et la mémoire doit être remplacée à mesure que l'erreur continue de se répéter.
Erreurs corrigibles
Si des erreurs sont détectées et corrigées, elles sont considérées comme corrigibles. Pour ce faire, il suffit de relancer la lecture ou de calculer le contenu correct de la mémoire à l'aide de données ECC (Error Correction Code) et de réécrire les données appropriées dans la mémoire. Une fois qu'une erreur a été détectée et corrigée, le contrôleur de gestion intégré Cisco (IMC) consigne l'événement dans le journal des événements système.
En général, les erreurs corrigibles sont le résultat d'erreurs logicielles. Si des erreurs corrigibles persistent dans le même emplacement mémoire pendant une période prolongée, cela peut indiquer une erreur matérielle potentielle.
Correction adaptative des données sur deux périphériques (ADDC)
ADDC Sparing peut corriger deux défaillances de DRAM successives si elles résident dans la même région. ADDC déplace dynamiquement les données des bits défaillants vers la mémoire de réserve, empêchant ainsi les erreurs corrigibles de devenir incorrigibles. Un seuil d'erreurs ECC corrigibles est requis pour déclencher le mécanisme.
ADDC aide dans certains scénarios où les erreurs ECC corrigibles précèdent les erreurs ECC non corrigibles.
Réparation post-colis (PPR)
La fonction de réparation post-package (PPR) permet de réparer de manière permanente les zones mémoire défaillantes d'un module DIMM en exploitant les lignes de mémoire DRAM redondantes. Cette réparation permanente sur site permet une reprise rapide après des erreurs matérielles sans avoir à remplacer la barrette DIMM. Pour effectuer une réparation, le système doit connaître un événement ADDC et effectuer au moins un cycle de redémarrage. Cette activité de réparation n'affecte pas les performances ni la mémoire totale disponible pour le système d'exploitation.
PPR et ADDC sont activés par défaut, mais ils peuvent être configurés. PPR nécessite également l'activation du mode RAS de secours ADDC. Si le paramètre RAS n'est pas défini sur ADDC Sparing ou Platform Default, PPR n'est pas opérationnel. Le seul mode PPR pris en charge est Hard PPR, ce qui signifie que les réparations sont permanentes.
PCLS (Partial Cache Line Sparing)
Le contrôleur de mémoire comporte un mécanisme de prévention des erreurs. Il fonctionne en identifiant les petites parties défectueuses des données dans la mémoire. Ces emplacements défectueux sont enregistrés dans un répertoire spécial, avec les données de sauvegarde qui peuvent les remplacer. Lors de l'accès à la mémoire, s'il y a une erreur dans ces points défectueux, le contrôleur utilise les données de sauvegarde du répertoire pour s'assurer que tout fonctionne correctement.
Remarque : les fonctionnalités sont disponibles en fonction de l'architecture du processeur et de la version du micrologiciel exécutée sur le serveur. Assurez-vous que vous disposez de la dernière version recommandée pour mieux gérer les erreurs de mémoire.
Dépannage des défaillances RAS
UCS Manager
En général, ces défaillances apparaissent dans UCS Manager sous la forme d'un événement RAS.
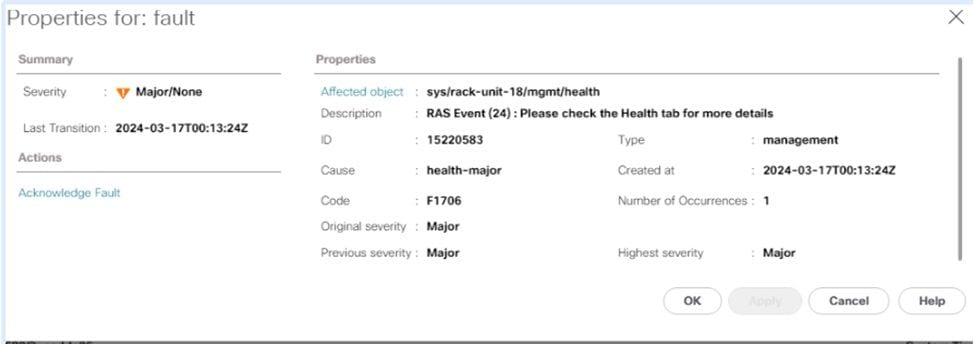
Dans le résumé de l'état de santé, vous pouvez trouver plus d'informations sur l'erreur, si PCLS ou PPR a été déclenché.
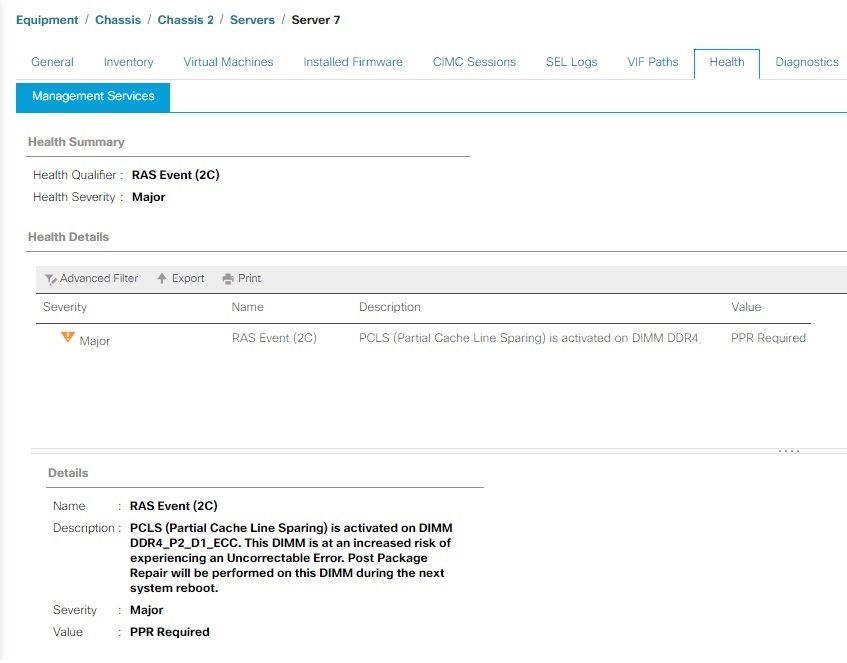
Exemple PCLS
Sur les serveurs M6 et plus récents, vous avez la possibilité d'activer le PCLS (Partial Cache Line Sparing) en tant qu'option BIOS, qui est un mécanisme de prévention des erreurs. Le serveur doit être redémarré dès que possible, afin que PPR puisse intervenir et réparer le module DIMM. Une fois le serveur redémarré, recherchez d'autres erreurs UCS Manager pour la même DIMM.
Comme l'alerte le mentionne, il est recommandé de redémarrer le serveur le plus rapidement possible, car il existe un risque associé d'erreur irrécupérable et, par conséquent, d'indisponibilité inattendue du serveur.
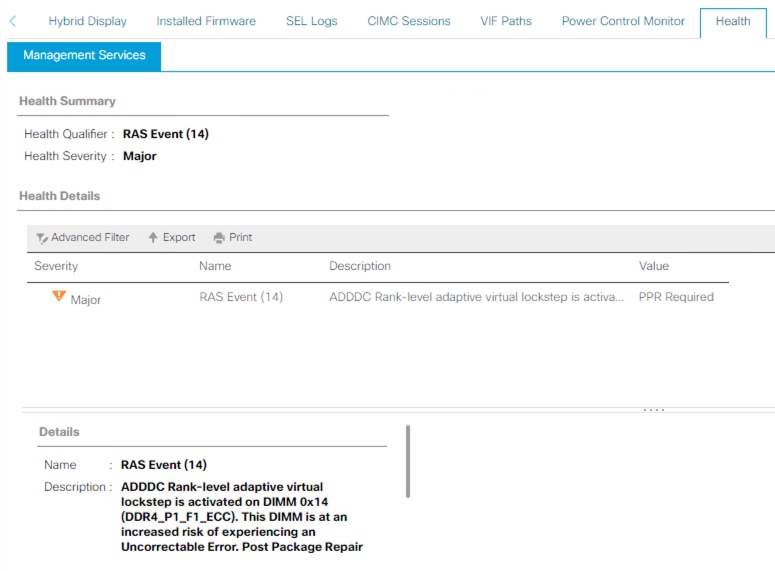
exemple PPR
ADDC et PPR sont activés sur le serveur et un événement RAS s'est produit. L'erreur suggère un redémarrage de PPR pour réparer le DIMM. Le serveur doit être redémarré dès que possible pour que PPR puisse démarrer et réparer le DIMM.
Une fois le serveur redémarré, recherchez d'autres erreurs UCS Manager pour la même DIMM.
Comme l'alerte le mentionne, il est recommandé de redémarrer le serveur le plus rapidement possible, car il existe un risque associé d'erreur irrécupérable et, par conséquent, d'indisponibilité inattendue du serveur.
Mode géré Intersight
ADDC est activé sur le serveur et un événement BANK VLS s'est produit, créant la défaillance que vous voyez. Dans ce scénario, l'étape suivante consiste à effectuer un redémarrage du serveur dès que possible pour permettre l'exécution de PPR.

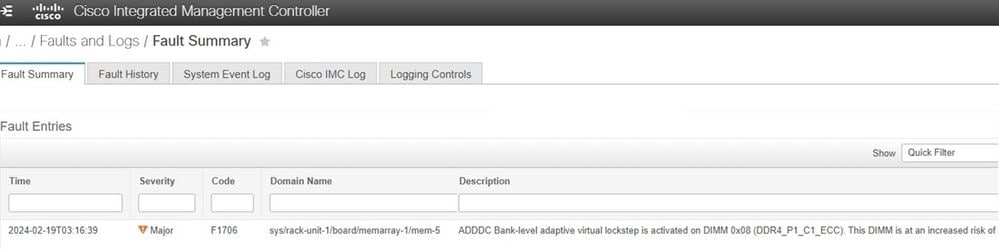
Contrôleur de gestion intégré Cisco (CIMC)
L'erreur apparaît comme indiqué lorsque vous utilisez le contrôleur de gestion intégré Cisco. Si le serveur a ADDC et qu'un événement VLS s'est produit, cela fonctionne comme prévu pour empêcher les erreurs non corrigibles.
Étapes de dépannage
- Vérifiez qu'aucune autre erreur DIMM n'est présente, par exemple Erreur irrécupérable.
- Planifier une fenêtre de maintenance.
- Placez un hôte en mode maintenance et redémarrez le serveur pour tenter une réparation permanente du module DIMM à l'aide de la fonction Post Package Repair (PPR).
Étapes de redémarrage UCSM
Remarque : vous pouvez également redémarrer le serveur à partir du système d'exploitation. Cet exemple utilise l'option de redémarrage de l'interface utilisateur du serveur.
Accédez à votre interface Web UCS Manager.
Serveur lame
Accédez à Equipment > Chassis > Server X.
Serveur intégré
Accédez à Equipment > Rack-Mounts > Server X.
Cliquez sur Console KVM.
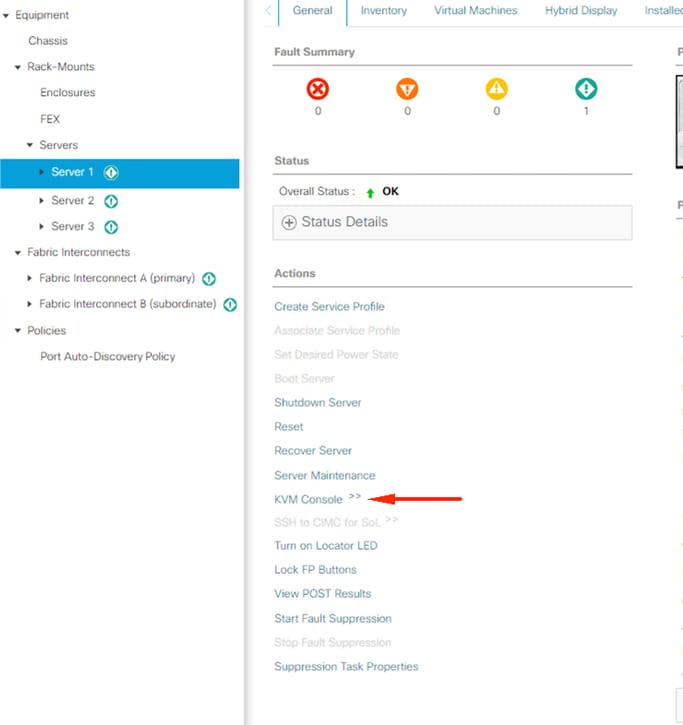
dans les fenêtres KVM, cliquez sur server actions, sélectionnez Reset, puis cliquez sur OK.
Surveillez le processus de redémarrage dans le KVM et assurez-vous que le système d'exploitation démarre correctement.
Étapes de redémarrage IMM
Accédez à l'onglet Serveurs, identifiez le serveur, puis cliquez sur le menu Action (trois points).
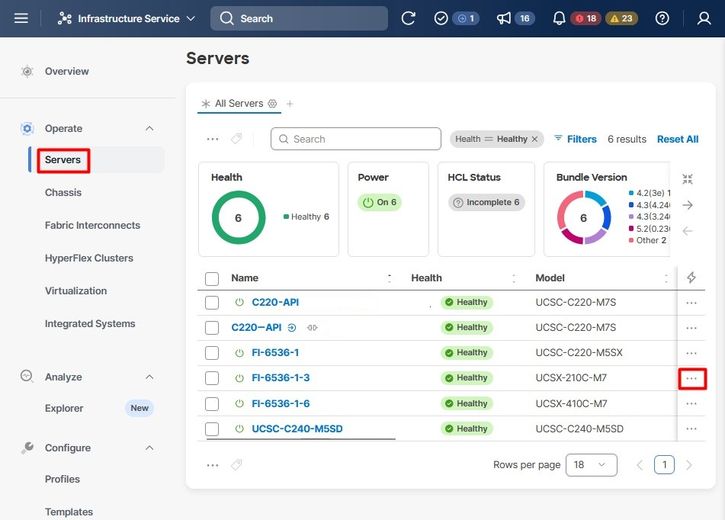
Sélectionnez ensuite le menu Power, puis l'option Power Cycle.
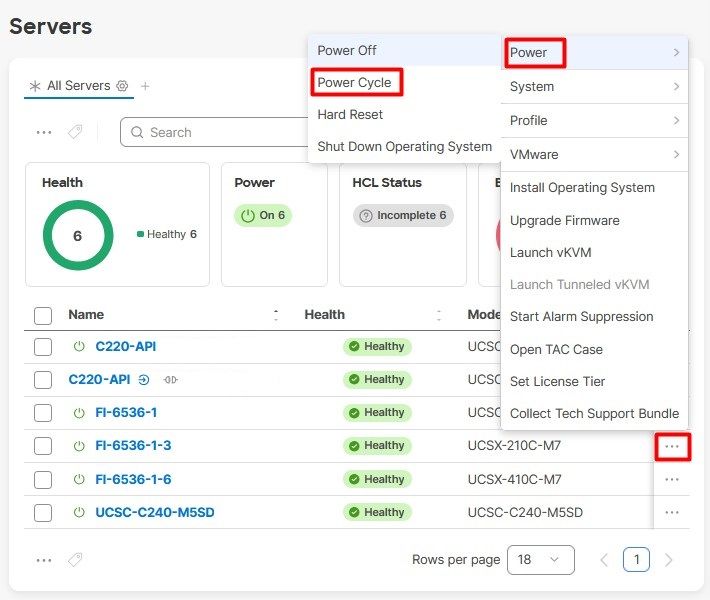
Cliquez sur le bouton Power Cycle pour confirmer l'action.
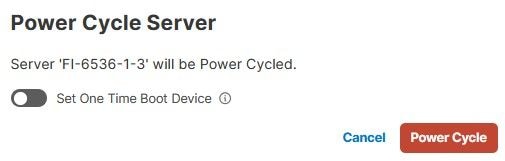
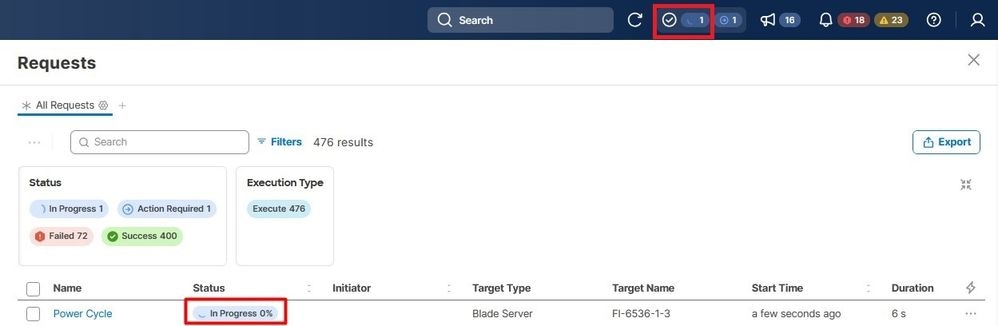
Validez la progression dans le menu Demandes.
Étapes de redémarrage CIMC
Accédez à l'option Host Power et sélectionnez Power Cycle.
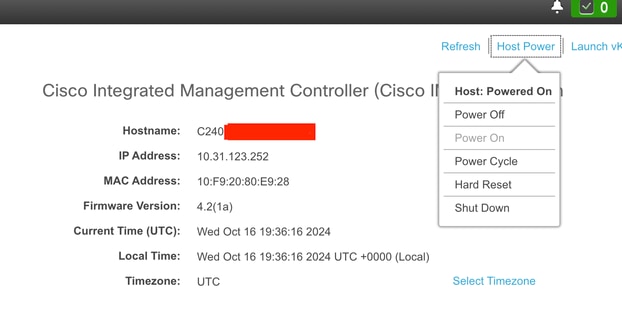
Lancez le KVM pour surveiller le processus de redémarrage et vous assurer que le système d'exploitation démarre correctement.
Surveiller les nouvelles défaillances
Si aucune erreur ne se produit après le redémarrage, ce qui signifie qu'il n'y a pas d'autre événement RAS ou d'erreur lié au DIMM, PPR a réussi et le serveur peut être remis en service.
Si de nouveaux événements ADDC se produisent, répétez le processus de redémarrage décrit dans les étapes précédentes pour effectuer des réparations permanentes supplémentaires avec PPR.
Si une erreur Uncorritable Error ou une erreur inexploitable se produit après le redémarrage, l'erreur indique qu'une mémoire doit être remplacée.
Remarque : si vous rencontrez l'une de ces défaillances, veuillez ouvrir un dossier auprès du TAC Cisco pour remplacer le module DIMM.
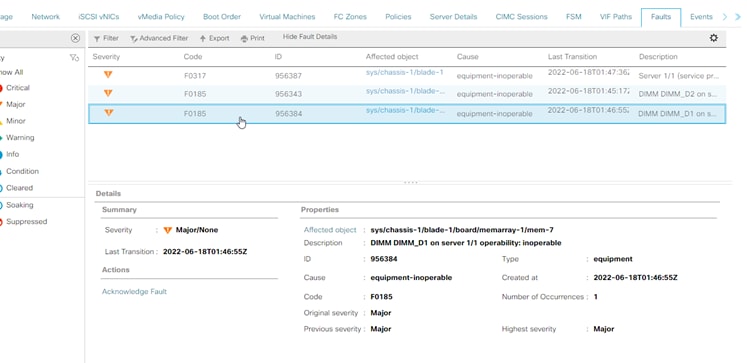
Erreur de mémoire non corrigible UCS Manager
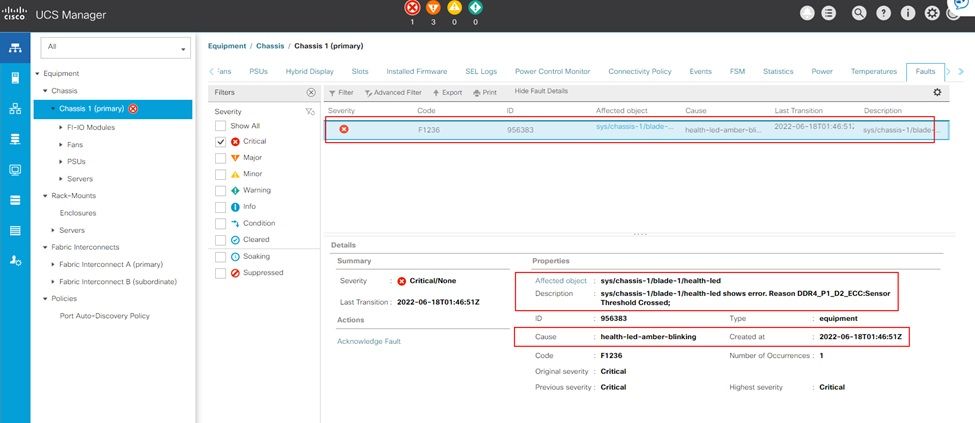
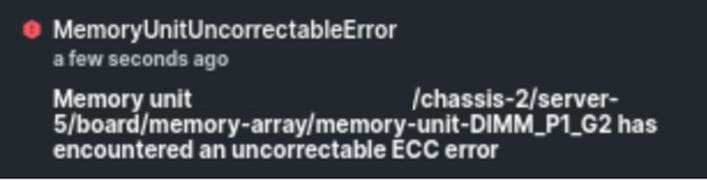
Erreur de mémoire IMM incorrigible
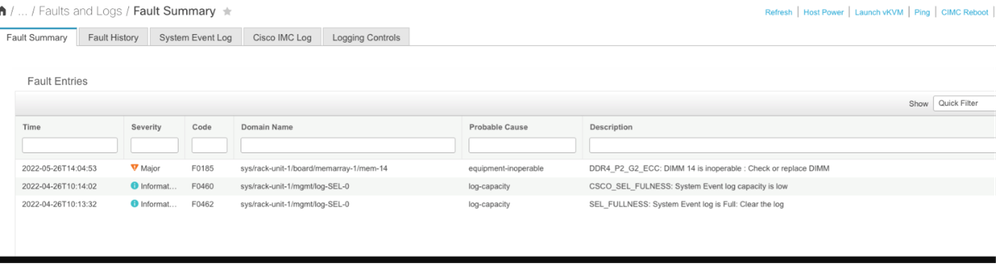
Erreur non corrigible. Le défaut indique que le module DIMM présente une erreur non corrigible et doit être remplacé.
Erreur de mémoire non corrigible CIMC
Informations connexes
 Commentaires
Commentaires