Introduction
Ce document décrit comment réinitialiser la réplication de base de données de Cisco Emergency Responder (CER).
Conditions préalables
Conditions requises
Aucune spécification déterminée n'est requise pour ce document.
Components Used
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques; cependant, la version utilisée pour créer ce document est la version 10 de l'URCE.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Procédure de réinitialisation de la réplication de base de données CER
Étapes récapitulatives
Étape 1. Détectez les entrées de la table de base de données distante à l'aide de l'interface de ligne de commande (CLI) du noeud principal CER.
Étape 2. Redémarrez les services sur les noeuds principal et secondaire.
Étape 3. Réinitialiser la réplication à partir de l'interface de ligne de commande du noeud principal CER.
Étape 4. Redémarrez le noeud secondaire.
Étape 5. Vérifier la réplication
Étape 6. Répéter le processus si nécessaire
Étapes détaillées
Dans l'interface de ligne de commande du serveur principal, supprimez les entrées de la table cerremote
Utilisez la commande run sql delete from cerremote pour supprimer les entrées de la table cerremote database, puis confirmez qu'il n'y a aucune entrée dans la table cerremote à l'aide de la commande run sql select name from cerremote.


À partir des services de redémarrage CLI des serveurs principal et secondaire
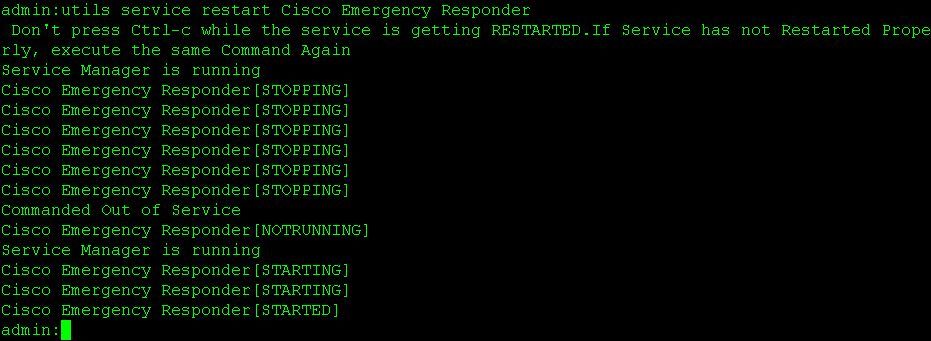
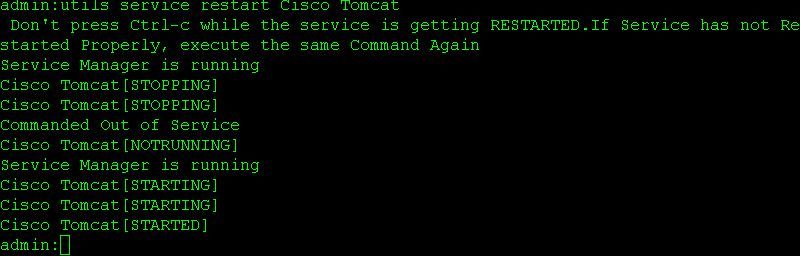
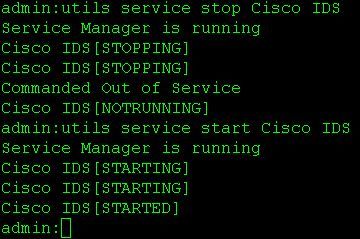
Utilisez les commandes ci-dessous pour redémarrer les services sur les noeuds principal et secondaire :
- utils service restart Cisco Emergency Responder
- utils service restart Cisco Tomcat
- utils service restart A Cisco DB Replicator
- utils service restart Cisco IDS ou utils service stop Cisco IDS et utils service start Cisco IDS

À partir de la réplication de réinitialisation CLI du serveur principal
À partir de l'interface de ligne de commande du noeud principal, utilisez la commande utils dbreplication reset all pour réinitialiser la réplication dans le cluster.

À partir de l'interface de ligne de commande du serveur secondaire, redémarrez le serveur
Une fois la réinitialisation terminée sur le noeud principal, une invite de redémarrage du noeud secondaire s’affiche. À ce stade, redémarrez le secondaire à partir de l'interface de ligne de commande à l'aide de la commande utils system restart.

Vérifier la réplication une fois que le secondaire est en service complet
Une fois le serveur secondaire en service complet, vérifiez la réplication de base de données à partir de l'interface de ligne de commande du serveur principal à l'aide de la commande utils dbreplication status.

La sortie de la commande status contient une commande d'affichage de fichier. Utilisez la commande d'affichage des fichiers pour confirmer qu'il n'y a aucun problème.
fichier view activelog er/trace/dbl/sdi/ReplicationStatus.YYYY_MM_DD_HH_MM_SS.out

La réplication peut être considérée comme ne configurant pas correctement si les résultats suivants sont vus plutôt que Connectés comme indiqué ci-dessus.
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED
-----------------------------------------------------------------------
g_cer10_cer10_0_2_10000_11 2 Active Local 0
g_cersub_cer10_0_2_10000_11 3 Active Connecting 165527
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED
-----------------------------------------------------------------------
g_cer10_cer10_0_2_10000_11 2 Active Local 0
g_cersub_cer10_0_2_10000_11 3 Active Disconnect 0
Répéter le processus si nécessaire
Si la réplication échoue toujours, vous devrez peut-être répéter cette procédure jusqu'à deux fois de plus. Si la réplication échoue après avoir effectué cette procédure 3 fois, supprimez et réinstallez l'abonné.
 Commentaires
Commentaires