Dépannage des problèmes de réplication de base de données Cisco Unified Communication Manager
Options de téléchargement
-
ePub (428.5 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (858.2 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Introduction
Le présent document explique comment diagnostiquer les problèmes de duplication de la base de données et indique les étapes nécessaires pour procéder au dépannage et résoudre ces problèmes.
Étapes pour diagnostiquer la duplication de la base de données
Cette section décrit les scénarios dans lesquels la réplication de base de données est interrompue et fournit la méthodologie de dépannage permettant de diagnostiquer et d'isoler le problème.
Étape 1 : vérification de la rupture de la réplication de base de données
Afin de déterminer si la duplication de votre base de données est défectueuse, vous devez connaître les différents états de l’outil de surveillance en temps réel (RTMT) de la duplication.
| Valeur | Signification | Description |
|---|---|---|
| 0 |
État d’initialisation |
La duplication est en cours de configuration. Un échec de configuration peut se produire si la réplication est dans cet état pendant plus d'une heure. |
| 1 |
Le nombre de duplications est incorrect. |
La configuration est toujours en cours. Cet état est rare dans les versions 6.x et 7.x. Dans la version 5.x, il indique que la configuration est toujours en cours. |
| 2 |
La duplication fonctionne bien. |
Les connexions logiques sont établies et les tableaux sont mis en correspondance avec les autres serveurs de la grappe. |
| 3 |
Les tableaux ne concordent pas. |
Des connexions logiques sont établies, mais il existe une incertitude quant à la correspondance des tables. Dans les versions 6.x et 7.x, tous les serveurs pourraient afficher l’état 3 même si un des serveurs de la grappe est en panne. Ce problème pourrait se produire parce que les autres serveurs ne savent pas s’il s’agit d’une mise à jour de la fonctionnalité à l’intention des utilisateurs (UFF) qui n’a pas été transmise de l’abonné aux autres périphériques de la grappe. |
| 4 |
Échec/abandon de la configuration |
Le serveur n’a plus de connexion logique active qui lui permet de recevoir des tableaux de base de données sur le réseau. Aucune duplication ne se produit dans cet état. |
Pour vérifier la réplication de la base de données, exécutez la commande utils dbreplication runtimestat à partir de l'interface de ligne de commande du noeud éditeur, comme illustré dans cette image.
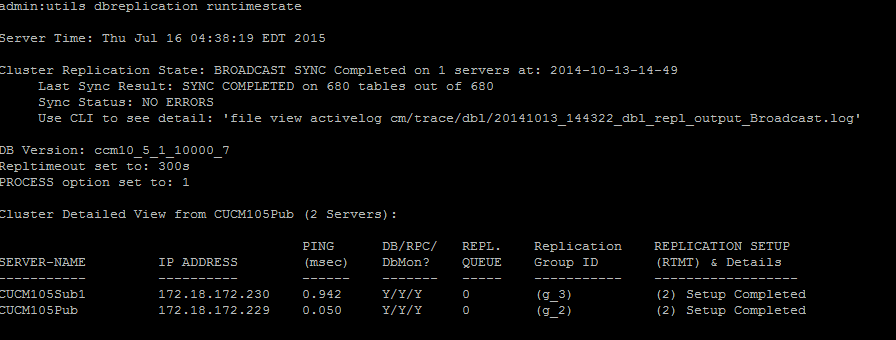
Dans le résultat, vérifiez que l’état de la duplication de la grappe ne contient pas les anciens renseignements de synchronisation. Cochez la même case et utilisez l'horodatage.
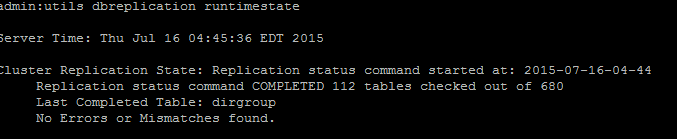
Si la synchronisation de diffusion n’est pas mise à jour avec une date récente, exécutez la commande utils dbreplication status pour vérifier tous les tableaux et la duplication. Si des erreurs ou des discordances sont découvertes, elles s’afficheront dans le résultat et l’état de l’outil RTMT changera en conséquence, comme l’illustre cette image.
o
Une fois la commande exécutée, l’uniformité de tous les tableaux est vérifiée et l’état exact de la duplication s’affiche.
Remarque : Autorisez la vérification de toutes les tables, puis poursuivez le dépannage.

Dès que l’état exact de la duplication s’affiche, vérifiez la configuration de la duplication (outil RTMT) et les détails dans le premier résultat. Vous devez vérifier l’état de chaque nœud. Si un nœud a un état autre que 2, continuez le dépannage.
Étape 2 : collecte de l'état de la base de données CM à partir de la page Cisco Unified Reporting sur CUCM
- Une fois que vous avez terminé l'étape 1, choisissez l'option Cisco Unified Reporting dans la liste déroulante Navigation de l'éditeur Cisco Unified Communications Manager (CUCM), comme illustré dans cette image.
2. Accédez à Rapports système et cliquez sur État de la base de données Unified CM, comme illustré dans cette image.
3. Générez un nouvel état, cliquez sur l'icône Générer un nouvel état comme illustré dans cette image.

4. Attendez que le nouveau rapport soit généré avec succès.

5. Une fois généré, cliquez sur l'icône pour télécharger le rapport et l'enregistrer afin de pouvoir le fournir à un ingénieur du centre d'assistance technique au cas où une demande de service (SR) aurait besoin d'être ouverte.

Étape 3. Vérification du rapport de base de données Unified CM de tout composant marqué comme erreur
Si les composants contiennent des erreurs, celles-ci sont signalées par une icône X rouge, comme illustré dans cette image.
-
Vérifiez que les bases de données locale et de publication sont accessibles.
- En cas d’erreur, vérifiez la connectivité du réseau entre les nœuds. Vérifiez si le service A Cisco DB s'exécute à partir de l'interface de ligne de commande du noeud et utilise la commande utils service list.
- Si le service A de base de données Cisco est défectueux, exécutez la commande utils service start A Cisco DB pour démarrer le service. En cas d'échec, contactez le TAC Cisco.
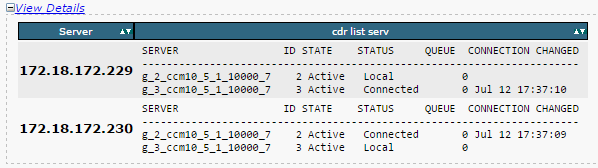
- Vérifiez que la liste des serveurs de duplication (cdr list serv) est remplie pour tous les nœuds.
Cette image illustre un résultat idéal.
Si la liste CDR (réplicateurs de bases de données Cisco) est vide pour certains nœuds, reportez-vous à l’étape 8.
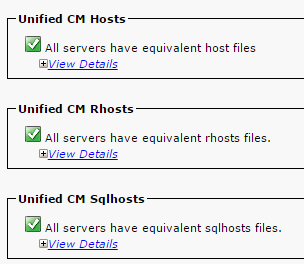
- Vérifiez que les hôtes, les Rhosts et les Sqlhosts Unified CM sont équivalents sur tous les nœuds.
Il s’agit d’une étape importante. Comme le montre l’image ci-dessous, les hôtes, les Rhosts et les Sqlhosts Unified CM sont équivalents sur tous les nœuds.
Les fichiers hôtes (Hosts) ne concordent pas :
Ce pourrait être le signe d’une activité incorrecte lorsqu’une adresse IP change pour le nom d’hôte sur le serveur.
Consultez le lien ci-dessous afin de changer l’adresse IP pour le nom d’hôte pour le CUCM.
Modifications de l’adresse IP et du nom d’hôte
Redémarrez ces services à partir de l'interface de ligne de commande du serveur de publication et vérifiez si la non-correspondance est résolue. Si la réponse est oui, passez à l'étape 8. Si la réponse est non, contactez le TAC Cisco. Générez un nouveau rapport chaque fois que vous apportez une modification à l’interface graphique (GUI) ou à la CLI pour vérifier si les changements sont inclus.
Cluster Manager ( utils service restart Cluster Manager)
A Cisco DB ( utils service restart A Cisco DB)
Les fichiers Rhosts ne concordent pas :
Si les fichiers Rhosts et les fichiers hôtes ne concordent pas, suivez les étapes dans la section Les fichiers hôtes (Hosts) ne concordent pas. Si seuls les fichiers Rhosts ne concordent pas, exécutez les commandes à partir de la CLI :
A Cisco DB ( utils service restart A Cisco DB ) Cluster Manager ( utils service restart Cluster Manager)
Générez un nouveau rapport et vérifiez si les fichiers Rhost sont équivalents sur tous les serveurs. Si la réponse est oui, passez à l'étape 8. Si la réponse est non, contactez le TAC Cisco.
Les fichiers Sqlhosts ne concordent pas :
Si les fichiers Sqlhosts et les fichiers hôtes ne concordent pas, suivez les étapes dans la section Les fichiers hôtes (Hosts) ne concordent pas. Si seuls les fichiers Sqlhosts ne concordent pas, exécutez la commande à partir de la CLI :
utils service restart A Cisco DB
Générez un nouveau rapport et vérifiez si les fichiers Sqlhost sont équivalents sur tous les serveurs. Si oui, passez à l'étape 8. Si non, contactez le TAC Cisco
-
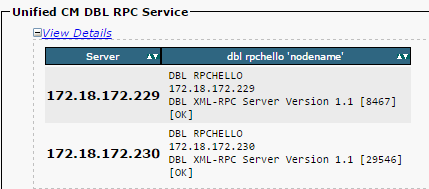
Vérifiez que l’appel de procédure distant de la couche de base de données (DBL RPC) hello réussit, comme l’illustre cette image.
Si l’appel RPC hello ne fonctionne pas pour un nœud en particulier :
- Vérifiez la connectivité du réseau entre le nœud visé et l’éditeur.
- Vérifiez que le numéro de port 1515 est autorisé sur le réseau.
Consultez le lien suivant pour en savoir plus sur l’utilisation des ports TCP/UDP :
Cisco Unified Communications Manager – Utilisation des ports TCP et UDP
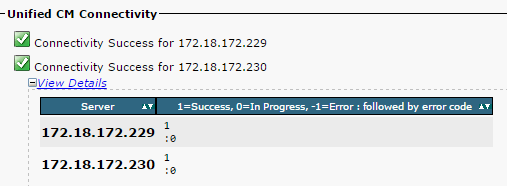
- Vérifiez la bonne connectivité du réseau entre les nœuds, comme l’illustre cette image :

Si la connectivité réseau échoue pour les noeuds :
- Vérifiez l’accessibilité au réseau entre les nœuds.
- Vérifiez que les numéros de ports TCP/UDP appropriés sont autorisés sur le réseau.
Générez un nouveau rapport et vérifiez si la connexion a réussi. En cas d’échec de la connexion, passez à l’étape 8.
Étape 4. Vérification des composants individuels qui utilisent la commande Utils Diagnose Test
La commande utils diagnose test vérifie tous les composants et renvoie une valeur de réussite ou d’échec. Les composants essentiels au bon fonctionnement de la duplication de la base de données sont les suivants :
-
Connectivité du réseau :
La commande validate_network vérifie tous les aspects de la connectivité du réseau pour tous les nœuds de la grappe. S’il y a un problème de connectivité, une erreur s’affiche souvent sur le serveur de noms de domaine (DNS) ou le serveur de noms de domaine inversé (RDNS). La commande validate_network effectue l’opération en 300 secondes. Voici les messages d’erreur courants pour les tests de connectivité du réseau :
1. Erreur « La communication intra-cluster est interrompue », comme illustré dans cette image.

- Motif
Cette erreur se produit lorsqu’un ou plusieurs nœuds de la grappe ont un problème de connectivité au réseau. Vérifiez que tous les nœuds sont accessibles par ping.
- Effet
Une communication intra-grappe défectueuse entraîne des problèmes de duplication de la base de données.
2. La recherche DNS inverse a échoué.
- Motif
Cette erreur se produit en cas d’échec de la recherche DNS inversée sur un nœud. Cependant, vous pouvez vérifier si le DNS est configuré et fonctionne correctement lorsque vous utilisez ces commandes :
utils network eth0 all - Shows the DNS configuration (if present) utils network host <ip address/Hostname> - Checks for resolution of ip address/Hostname
- Effet
Si le DNS ne fonctionne pas correctement, il peut provoquer des problèmes de réplication de base de données lorsque les serveurs sont définis et utilisent les noms d'hôte.
-
Accessibilité du protocole NTP (Network Time Protocol) :
Le NTP est chargé de synchroniser l'heure du serveur avec l'horloge de référence. L’éditeur synchronise toujours l’heure avec le périphérique dont l’adresse IP est répertoriée en tant que serveurs NTP, tandis que les abonnés synchronisent l’heure avec celle de l’éditeur.
Il est extrêmement important que le NTP soit entièrement fonctionnel afin d’éviter tout problème de duplication de la base de données.
Il est essentiel que la strate NTP (nombre de sauts vers l'horloge de référence parente) soit inférieure à 5, sinon elle est jugée non fiable.
Effectuez ces étapes dans l’ordre ci-dessous afin de vérifier l’état NTP :
- Utilisez la commande utils diagnose test pour vérifier le résultat, comme l’illustre cette image.
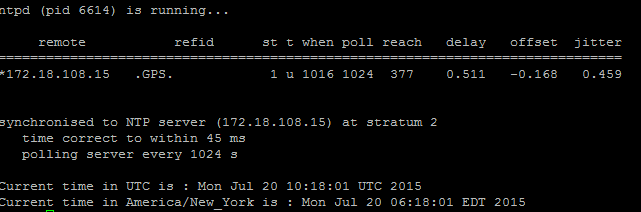
2. En outre, vous pouvez exécuter cette commande :
utils ntp status
Étape 5. Vérification de l’état de connectivité de tous les noeuds et vérification de leur authentification
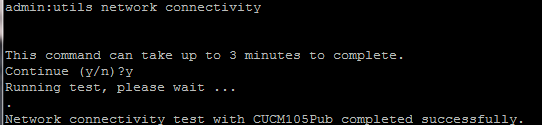
- Une fois l’étape 4 terminée, si aucun problème n’est signalé, exécutez la commande utils network connectivity sur tous les nœuds pour vérifier la connectivité aux bases de données, comme l’illustre cette image.

2. Si vous recevez le message d’erreur « Cannot send TCP/UDP packets » (Impossible d’envoyer des paquets TCP/UDP), vérifiez si votre réseau a effectué des retransmissions ou bloquez les ports TCP/UDP. La commande show network cluster vérifie l’authentification de tous les nœuds.
3. Si l’état du noeud n’est pas authentifié, assurez-vous que la connectivité réseau et le mot de passe de sécurité sont identiques sur tous les noeuds, comme illustré dans cette image.
Consultez les liens sur la modification ou la récupération des mots de passe de sécurité :
Comment réinitialiser les mots de passe sur CUCM
Récupération du mot de passe de l’administrateur du système d’exploitation CUCM
Étape 6. La commande Utils Dbreplication Runtimestate affiche les états « Out of Sync » ou « Not Requested »
Il est important de comprendre que la duplication de base de données est une tâche exigeante pour le réseau, car elle pousse les tableaux vers tous les nœuds de la grappe. Vérifiez les points suivants :
-
Les nœuds se trouvent dans le même centre de données/site : Tous les nœuds sont accessibles avec un temps aller-retour (RTT) inférieur. Si le RTT est anormalement élevé, vérifiez les performances du réseau.
-
Les nœuds sont dispersés sur le réseau étendu (WAN) : Assurez-vous que la connectivité réseau des noeuds est bien inférieure à 80 ms. Si certains nœuds ne sont pas en mesure de se joindre au processus de duplication, augmentez le paramètre à une valeur plus élevée, comme il est indiqué ci-dessous.
utils dbreplication setprocess <1-40>
Remarque : Lorsque vous modifiez ce paramètre, il améliore les performances de configuration de la réplication, mais consomme des ressources système supplémentaires.
-
L’expiration du délai de duplication dépend du nombre de nœuds dans la grappe. L’expiration du délai de duplication (par défaut : 300 secondes) est le temps pendant lequel l’éditeur attend que tous les abonnés envoient leurs messages définis. Calculez l’expiration du délai de duplication en fonction du nombre de nœuds dans la grappe.
Server 1-5 = 1 Minute Per Server Servers 6-10 = 2 Minutes Per Server Servers >10 = 3 Minutes Per Server.
Example: 12 Servers in Cluster : Server 1-5 * 1 min = 5 min, + 6-10 * 2 min = 10 min, + 11-12 * 3 min = 6 min, Repltimeout should be set to 21 Minutes.
Commandes pour vérifier/définir l’expiration du délai de réplication :
show tech repltimeout ( To check the current replication timeout value ) utils dbreplication setrepltimeout ( To set the replication timeout )
Les étapes 7 et 8 doivent être effectuées une fois la liste de contrôle remplie :
Liste de vérification :
- Tous les nœuds sont connectés les uns aux autres. Reportez-vous à l’étape 5.
- L’appel RPC est accessible. Reportez-vous à l’étape 3.
- Consultez le TAC Cisco avant de passer aux étapes 7 et 8 dans le cas de noeuds supérieurs à 8.
- Effectuez la procédure en dehors des heures d’ouverture.
Étape 7. Réparer toutes les tables/tables sélectives pour la réplication de base de données
Si la commande utils dbreplication runtimestate indique qu’il existe des erreurs ou que certains tableaux ne concordent pas, exécutez la commande :
Utils dbreplication repair all
Exécutez la commande utils dbreplication runtimestate pour vérifier de nouveau l’état.
Si l’état ne change pas, passez à l’étape 8.
Étape 8. Réinitialisation de la réplication de base de données
Reportez-vous à la séquence pour réinitialiser la réplication de base de données et démarrer le processus à partir de zéro.
utils dbreplication stop all (Only on the publisher) utils dbreplication dropadmindb (First on all the subscribers one by one then the publisher) utils dbreplication reset all ( Only on the publisher )
Pour surveiller le processus, exécutez la commande RTMT/utils dbreplication runtimestate.
Reportez-vous à la séquence ci-dessous pour réinitialiser la duplication de la base de données pour un nœud particulier :
utils dbreplication stop <sub name/IP> (Only on the publisher) utils dbreplcation dropadmindb (Only on the affected subscriber) utils dbreplication reset <sub name/IP> (Only on the publisher )
Si vous contactez le TAC Cisco pour obtenir de l'aide, assurez-vous que les résultats et les rapports suivants sont fournis :
utils dbreplication runtimestate utils diagnose test utils network connectivity
Rapports :
- Le rapport de base de données Cisco Unified Reporting CM (reportez-vous à l'étape 2).
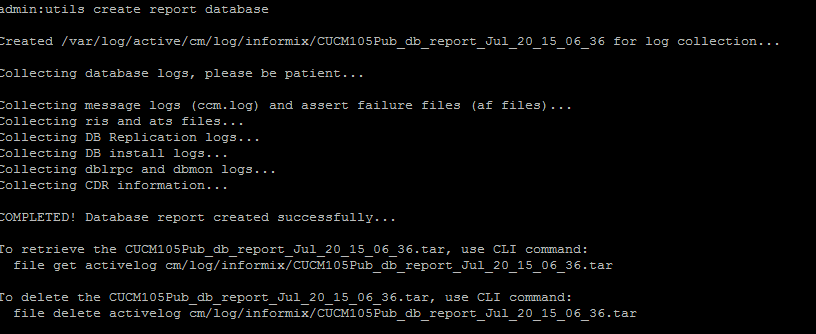
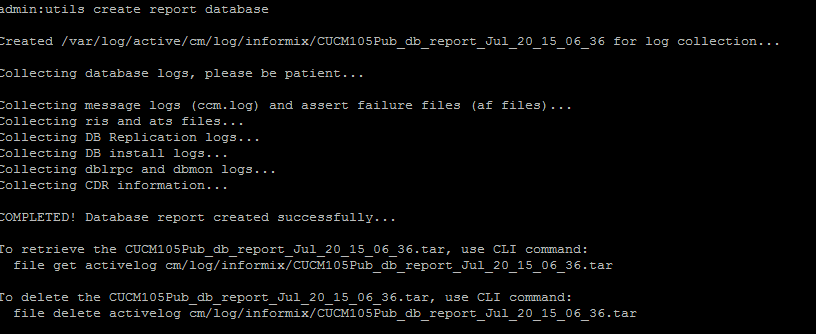
- La commande utils create report database de la CLI. Téléchargez le fichier .tar et utilisez un serveur SFTP.
Informations connexes
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
4.0 |
12-Nov-2024 |
Mise à jour du texte de remplacement, de la traduction automatique et du formatage. |
1.0 |
13-Aug-2021 |
Première publication |
Contribution d’experts de Cisco
- Kaustubh AcharekarIngénieur TAC Cisco
- Jose Pablo Villalobos UrenaIngénieur TAC Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)