Multichassis Multilink PPP (MMP)
Contenu
Introduction
Ce document décrit la prise en charge de Multilink PPP (MP) dans un environnement de pile ou multichâssis (parfois appelé MMP, pour Multichassis Multilink PPP), sur les plates-formes de serveur d'accès de Cisco Systems.
Conditions préalables
Conditions requises
Aucune condition préalable spécifique n'est requise pour ce document.
Components Used
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
Les informations présentées dans ce document ont été créées à partir de périphériques dans un environnement de laboratoire spécifique. All of the devices used in this document started with a cleared (default) configuration. Si vous travaillez dans un réseau opérationnel, assurez-vous de bien comprendre l'impact potentiel de toute commande avant de l'utiliser.
Termes associés
Il s'agit d'un glossaire de termes que ce document utilise :
-
Serveur d'accès : plates-formes de serveurs d'accès Cisco, y compris les interfaces RNIS et asynchrones pour fournir un accès à distance.
-
L2F : protocole de transfert de couche 2 (L2) (RFC provisoire expérimental). Il s'agit de la technologie de niveau liaison sous-jacente pour les MP multichâssis et les VPN.
-
Liaison : point de connexion fourni par un système. Une liaison peut être une interface matérielle dédiée (telle qu’une interface asynchrone) ou un canal sur une interface matérielle multicanal (telle qu’une interface PRI ou BRI).
-
MP : Multilink PPP Protocol (voir RFC 1717
 ).
). -
Multichassis MP—MP + SGBP + L2F + Vtemplate.
-
PPP : protocole point à point (reportez-vous à la RFC 1331
). -
Groupe rotatif : groupe d'interfaces physiques allouées pour composer ou recevoir des appels. Le groupe agit comme un pool à partir duquel vous pouvez utiliser n'importe quel lien pour composer ou recevoir des appels.
-
SGBP : Stack Group Bidding Protocol.
-
Groupe de piles : ensemble de deux systèmes ou plus qui sont configurés pour fonctionner comme un groupe et prendre en charge des groupes de processeurs avec des liaisons sur différents systèmes.
-
VPDN : réseau commuté privé virtuel. Transfert de liaisons PPP d'un fournisseur d'accès Internet (FAI) vers une passerelle Cisco Home Gateway.
-
Vtemplate : interface de modèle virtuel.
Remarque : pour plus d'informations sur les RFC référencées dans ce document, consultez RFC et autres normes prises en charge dans Cisco IOS version 11.3-No. 523, un bulletin produit ; Obtention de documents RFC et standard; ou RFC Index ![]() pour une liaison directement à InterNIC.
pour une liaison directement à InterNIC.
Conventions
Pour plus d'informations sur les conventions utilisées dans ce document, reportez-vous à Conventions relatives aux conseils techniques Cisco.
Définition du problème
MP offre aux utilisateurs une bande passante supplémentaire à la demande avec la possibilité de diviser et de recombiner les paquets sur un canal logique (faisceau) que forment plusieurs liaisons.
Cela réduit la latence de transmission sur les liaisons WAN lentes et permet également d'augmenter l'unité de réception maximale.
Du côté de la transmission, MP assure la fragmentation d'un seul paquet en plusieurs paquets à transmettre sur plusieurs liaisons PPP. À l’extrémité de réception, le point de gestion assure le réassemblage des paquets de plusieurs liaisons PPP dans le paquet d’origine.
Cisco prend en charge le point de gestion des systèmes d’extrémité autonomes, c’est-à-dire que plusieurs liaisons point de gestion du même client peuvent se terminer au niveau du serveur d’accès. Cependant, les FAI, par exemple, préfèrent allouer un seul numéro rotatif à plusieurs PRI sur plusieurs serveurs d’accès, et rendre leur structure de serveur évolutive et flexible aux besoins de l’entreprise.
Dans le logiciel Cisco IOS® Version 11.2, Cisco fournit cette fonctionnalité, de sorte que plusieurs liaisons MP du même client peuvent se terminer sur différents serveurs d'accès. Bien que les liaisons MP individuelles d'un même ensemble puissent se terminer sur différents serveurs d'accès, en ce qui concerne le client MP, cela est similaire à la terminaison sur un seul serveur d'accès.
Pour atteindre cet objectif, MP utilise le multichâssis MP.
Présentation fonctionnelle
La Figure 1 illustre l'utilisation de MP sur un serveur d'accès Cisco unique pour prendre en charge cette fonctionnalité.
Figure 1 : point de gestion sur un seul serveur d'accès Cisco 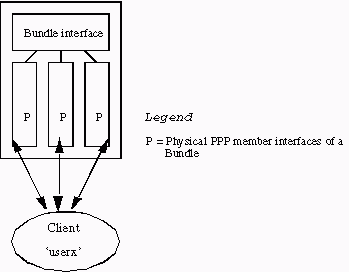
La Figure 1 illustre la connexion des interfaces membres du point de gestion à une interface de groupement. Dans un système autonome sans multichâssis MP activé, les interfaces membres sont toujours des interfaces physiques.
Pour prendre en charge un environnement empilé, outre le MP, ces trois sous-composants supplémentaires sont nécessaires :
-
SGBP
-
Vtemplate
-
couche 2F
Les sections suivantes de ce document expliquent ces composants en détail.
SGBP
Dans un environnement à serveurs d'accès multiples, l'administrateur réseau peut désigner un groupe de serveurs d'accès à appartenir à un groupe de piles.
Supposons qu'un groupe de pile se compose du système A et du système B. Un client MP distant appelé userx a la première liaison MP qui se termine au système A (systema). Le bundle userx est formé au niveau de systema. La prochaine liaison MP de userx se termine maintenant au niveau du système B (systembe). SGBP localise le bundle où réside userx sur systema. À ce stade, un autre composant, L2F, projette la deuxième liaison MP du systemba au systema. La liaison MP projetée rejoint ensuite le faisceau au niveau du système a.
Le protocole SGBP localise ainsi l'emplacement du faisceau d'un membre de pile dans un groupe de pile défini. SGBP arbitre également un membre de pile désigné pour la création du groupement. Dans l'exemple, lorsque la première liaison MP est reçue sur systema, systema et systembem (et tous les autres membres du groupe de pile) enchérissent en fait pour la création du lot. L'offre de systema est plus élevée (parce qu'elle a accepté la première liaison), donc SGBP la désigne pour la création de bundle.
Cette description du processus d'appel d'offres SGBP est quelque peu simpliste. En pratique, une offre SGBP d'un membre de pile est fonction de la localisation, d'une métrique pondérée configurable par l'utilisateur, du type de processeur, du nombre de faisceaux MP, etc. Ce processus d'appel d'offres permet la création de l'offre groupée sur un système désigné, même s'il ne dispose d'aucune interface d'accès. Par exemple, un environnement empilé peut se composer de 10 systèmes de serveur d'accès et de deux 4500, soit un groupe de piles de 12 membres.
Remarque : lorsque les offres sont égales, par exemple entre deux 4500, SGBP désigne aléatoirement l'une d'entre elles comme gagnante de l'offre. Vous pouvez configurer les 4500 de sorte qu'ils surenchérissent toujours sur les autres membres de la pile. Les 4500 deviennent ainsi des serveurs MP multichâssis déchargés spécialisés dans les fragmenteurs et les réassembleurs de paquets MP, une tâche adaptée à leur puissance CPU plus élevée par rapport aux serveurs d'accès.
En bref, SGBP est le mécanisme de localisation et d'arbitrage du multichâssis MP.
Interfaces d'accès virtuel
Les interfaces d'accès virtuel servent à la fois d'interfaces groupées (voir Figures 1 et Figure 2) et de liaisons PPP prévues (voir Figure 2). Ces interfaces sont créées dynamiquement et renvoyées au système à la demande.
Les interfaces de modèles virtuels servent de référentiels d'informations de configuration à partir desquelles les interfaces d'accès virtuelles sont clonées. Les configurations d’interface de numérotation constituent une autre source d’informations de configuration. La méthode de sélection de la source de configuration à partir de laquelle cloner une interface d'accès virtuelle apparaît dans Multichassis Multilink PPP (MMP) (Partie 2).
couche 2F
L2F assure la projection réelle de la liaison PPP vers un système d’extrémité désigné.
L2F effectue un fonctionnement PPP standard jusqu'à la phase d'authentification, où le client distant est identifié. La phase d'authentification n'est pas terminée localement. L2F, fourni avec le membre de pile cible de SGBP, projette la liaison PPP vers le membre de pile cible, où la phase d'authentification est reprise et achevée au niveau de la liaison PPP projetée. Le succès ou l'échec de l'authentification finale est ainsi effectué au niveau du membre de la pile cible.
L'interface physique d'origine qui a accepté l'appel entrant est dite L2F transférée. L’interface correspondante créée dynamiquement par L2F (lorsque l’authentification PPP réussit) est une interface d’accès virtuel projetée.
Remarque : l'interface d'accès virtuelle projetée est également clonée à partir de l'interface de modèle virtuelle (si elle est définie).
La Figure 2 décrit un groupe de piles stackq composé de systema, systembem et systemc.
Figure 2 : client appelant dans une pile 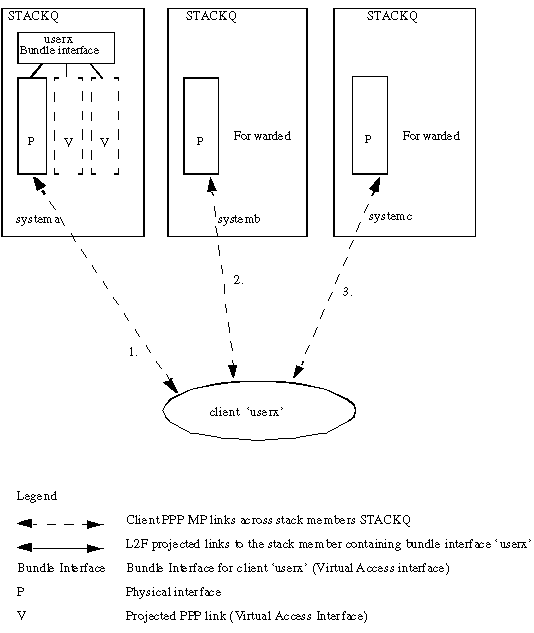
-
Appels client userx. La première liaison du système a reçoit l'appel. SGBP tente de localiser un bundle par userx existant parmi les membres du groupe de pile. S'il n'y en a pas, et parce que MP est négocié sur le PPP, une interface de bundle est créée sur systema.
-
systembe reçoit le deuxième appel de userx. Le protocole SGBP permet de déterminer si le système se trouve à l'emplacement du bundle. L2F permet de transférer la liaison de systembe à systema. Une liaison PPP projetée est créée sur systema. La liaison projetée est ensuite jointe à l'interface de faisceau.
-
systemc reçoit le troisième appel de userx. Là encore, SGBP localise le système où réside le bundle. L2F est utilisé pour transférer la liaison de systemc à systema. Une liaison PPP projetée est créée sur systema. La liaison projetée est ensuite jointe à l'interface de faisceau.
Remarque : une interface de bundle représente le bundle sur systema. Pour chaque appelant unique, les interfaces membres MP de ce même appelant aboutissent à une interface d'ensemble ou en proviennent.
Interface utilisateur
L'interface utilisateur Vtemplate est spécifiée nominalement ici. Pour plus d'informations, reportez-vous à la spécification fonctionnelle Modèle ![]() virtuel.
virtuel.
SGBP
-
sgbp group <name>
Cette commande globale définit un groupe de pile, attribue un nom au groupe et fait du système un membre de ce groupe de pile.
Remarque : vous ne pouvez définir globalement qu'un seul groupe de piles.
Définissez un groupe de piles appelé stackq :
systema(config)#sgbp group stackq
Remarque : le défi PPP CHAP ou la requête PPP PAP de systema porte désormais le nom stackq. Lorsque vous définissez le nom du groupe de piles sur le serveur d'accès, le nom remplace généralement le nom d'hôte défini pour le même système.
-
sgbp member <nom-homologue> <adresse-IP-homologue>
Cette commande globale spécifie les homologues dans le groupe de pile. Dans cette commande, <peer-name> est le nom d'hôte et <peer-IP-address> est l'adresse IP du membre de pile distant. Par conséquent, vous devez définir une entrée pour chaque membre du groupe de piles de la pile, à l'exception de vous-même. un serveur de noms de domaine (DNS) peut résoudre les noms d'homologues. Si vous avez un DNS, vous n'avez pas besoin d'entrer l'adresse IP.
systema(config)#sgbp member systemb 1.1.1.2 systema(config)#sgbp member systemc 1.1.1.3
-
sgbp seed-bid {default | déchargement | avant uniquement | <0-9999>}
Poids configurable avec lequel le membre de la pile enchérit pour une offre groupée.
Si le paramètre par défaut est défini sur tous les membres de la pile, le membre de la pile qui reçoit le premier appel pour l'utilisateur userx gagne toujours l'appel d'offre et héberge l'interface du bundle maître. Tous les appels suivants du même utilisateur vers un autre projet membre de la pile vers ce membre de la pile. Si vous ne définissez pas d'enchère initiale sgbp, la valeur par défaut est utilisée.
Si le déchargement est défini, il envoie l'offre pré-étalonnée par plate-forme qui se rapproche de la puissance du processeur, moins la charge du bundle.
Si < 0-9999 > est configuré, l'enchère envoyée est la valeur configurée par l'utilisateur moins la charge du bundle.
La charge du faisceau est définie comme le nombre de faisceaux actifs sur le membre de la pile.
-
Lorsque des membres de pile équivalents sont empilés pour recevoir des appels dans un groupe rotatif sur plusieurs PRI, émettez la commande sgbp seed-bid default across all stack members. Un groupe de piles de quatre AS5200 est un exemple de membres de pile équivalents. Le membre de la pile qui reçoit le premier appel pour l'utilisateur userx remporte toujours l'appel d'offre et héberge l'interface du bundle maître. Tous les appels ultérieurs destinés au même utilisateur à un autre membre de la pile concernent ce membre de la pile. Si plusieurs appels arrivent simultanément sur plusieurs membres de la pile, le mécanisme de rupture de lien SGBP rompt le lien.
-
Lorsque vous disposez d'une CPU de puissance supérieure disponible en tant que membre de pile par rapport aux autres membres de pile, vous pouvez tirer parti de la puissance relativement supérieure de ce membre de pile par rapport au reste (par exemple, une ou plusieurs CPU de puissance supérieure disponibles en tant que membre de pile par rapport aux autres membres de pile similaires ; par exemple, un 4500 et quatre AS5200).Vous pouvez définir le membre de pile haute puissance désigné comme serveur de déchargement avec la commande sgbp seed-bid offload. Dans ce cas, le serveur de déchargement héberge le bundle maître. Tous les appels des autres membres de la pile sont projetés vers ce membre de la pile. En fait, un ou plusieurs serveurs de déchargement peuvent être définis ; si les plates-formes sont identiques (équivalentes), les offres sont égales. Le mécanisme de départage du temps SGBP casse le temps et désigne l'une des plates-formes comme gagnante.
Remarque : si vous désignez deux plates-formes différentes comme serveurs de déchargement, celle dont la puissance de processeur est la plus élevée remporte l'appel d'offres.
-
Si vous avez des plates-formes différentes ou exactement les mêmes et que vous voulez désigner une ou plusieurs plates-formes comme serveurs de déchargement, vous pouvez manuellement définir la valeur d'enchère pour qu'elle soit significativement plus élevée que le reste avec la commande sgbp seed-bid 9999. Par exemple, un 4700 (désigné par l'offre initiale la plus élevée), deux 4000 et un 7000. Pour déterminer la valeur de l'enchère initiale associée à vos plates-formes particulières, utilisez show sgbp.
-
Dans un environnement multichâssis où les membres de la pile frontale se déchargent toujours vers un ou plusieurs serveurs de déchargement, il existe des cas où le membre de la pile frontale ne peut pas réellement se décharger, par exemple lorsque le groupement multiliaison est formé localement. Cela peut se produire, par exemple, lorsque tous les serveurs de déchargement sont en panne. Si l'administrateur réseau préfère que l'appel entrant raccroche à la place, émettez la commande sgbp seed-bid forward-only.
-
-
sgbp ppp-forward
Lorsque sgbp ppp-forward est défini, les appels PPP et MP sont projetés vers le gagnant de l'enchère SGBP. Par défaut, seuls les appels MP sont transférés.
-
show sgbp
Cette commande affiche l'état des membres du groupe de piles. Les états peuvent être ACTIVE, CONNECTING, WAITINFO ou IDLE. ACTIVE sur chaque membre du groupe de piles est le meilleur état. CONNECTING et WAITINFO sont des états de transition et vous ne devez les voir que lorsque vous êtes en transition vers ACTIVE. IDLE indique que le système de groupe de piles ne peut pas détecter le système membre de pile distant. Par exemple, si le système est arrêté pour maintenance, il n'y a pas de raison de s'inquiéter. Sinon, examinez quelques problèmes de routage ou d'autres problèmes entre ce membre de pile et systemd.
systema#show sgbp Group Name: stack Ref: 0xC38A529 Seed bid: default, 50, default seed bid setting Member Name: systemb State: ACTIVE Id: 1 Ref: 0xC14256F Address: 1.1.1.2 Member Name: systemc State: ACTIVE Id: 2 Ref: 0xA24256D Address: 1.1.1.3 Tcb: 0x60B34439 Member Name: systemd State: IDLE Id: 3 Ref: 0x0 Address: 1.1.1.4 -
show sgbp query
Affiche la valeur de l'enchère initiale actuelle.
systema# show sgbp queries Seed bid: default, 50 systema# debug sgbp queries %SGBPQ-7-MQ: Bundle: userX State: Query_to_peers OurBid: 050 %SGBPQ-7-PB: 1.1.1.2 State: Open_to_peer Bid: 000 Retry: 0 %SGBPQ-7-PB: 1.1.1.3 State: Open_to_peer Bid: 000 Retry: 0 %SGBPQ-7-PB: 1.1.1.4 State: Open_to_peer Bid: 000 Retry: 0 %SGBPQ-7-MQ: Bundle: userX State: Query_to_peers OurBid: 050 %SGBPQ-7-PB: 1.1.1.2 State: Rcvd Bid: 000 Retry: 0 %SGBPQ-7-PB: 1.1.1.3 State: Rcvd Bid: 000 Retry: 0 %SGBPQ-7-PB: 1.1.1.4 State: Rcvd Bid: 000 Retry: 0 %SGBPQ-7-DONE: Query #9 for bundle userX, count 1, master is local
MP
-
modèle virtuel multiliaison <1-9>
Il s'agit du numéro de modèle virtuel par lequel l'interface de l'offre groupée MP clone ses paramètres d'interface. Voici un exemple de la façon dont un point de gestion s'associe à un modèle virtuel. Une interface de modèle virtuelle doit également être définie :
systema(config)#multilink virtual-template 1 systema(config)#int virtual-template 1 systema(config-i)#ip unnum e0 systema(config-i)#encap ppp systema(config-i)#ppp multilink systema(config-i)#ppp authen chap
-
show ppp multilink
Cette commande affiche les informations de bundle pour les bundles MP :
systema#show ppp multilink Bundle userx 2 members, Master link is Virtual-Access4 0 lost fragments, 0 reordered, 0 unassigned, 100/255 load 0 discarded, 0 lost received, sequence 40/66 rcvd/sent members 2 Serial0:4 systemb:Virtual-Access6 (1.1.1.2)Cet exemple montre, sur le système membre du groupe de piles sur le groupe de piles stackq, que l'interface de l'ensemble userx est définie sur Virtual-Access4. Deux interfaces membres sont jointes à cette interface d'ensemble. Le premier est un canal PRI local et le second est une interface projetée à partir du système membre du groupe de pile.
Exemples
Référez-vous à Multichassis Multilink PPP (MMP) (Partie 2) pour voir ces exemples :
Reportez-vous également aux sections sur :
Informations connexes
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
1.0 |
29-Jan-2008 |
Première publication |
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)