Gestione dei livelli di servizio: White paper sulle procedure ottimali
Sommario
Introduzione
In questo documento vengono descritti la gestione dei livelli di servizio e gli accordi sui livelli di servizio (SLA) per le reti ad alta disponibilità. Include fattori di successo critici per la gestione dei livelli di servizio e indicatori di prestazioni che consentono di valutare il successo. Il documento fornisce inoltre dettagli significativi per gli SLA che seguono le linee guida delle procedure ottimali identificate dal team del servizio a elevata disponibilità.
Panoramica sulla gestione dei livelli di servizio
Storicamente, le organizzazioni di rete hanno soddisfatto requisiti di rete in espansione creando solide infrastrutture di rete e lavorando in modo reattivo per gestire singoli problemi di servizio. Quando si verifica un'interruzione, l'organizzazione crea nuovi processi, funzionalità di gestione o infrastrutture che impediscono il verificarsi di un'interruzione specifica. Tuttavia, a causa di una maggiore percentuale di modifiche e di requisiti di disponibilità in aumento, ora abbiamo bisogno di un modello migliorato per prevenire proattivamente downtime non pianificati e riparare rapidamente la rete. Molte organizzazioni di fornitori di servizi e aziende hanno cercato di definire meglio il livello di servizio richiesto per raggiungere gli obiettivi aziendali.
Fattori di successo critici
I fattori critici per il successo degli SLA vengono utilizzati per definire gli elementi chiave per la creazione di livelli di servizio ottenibili e per il mantenimento degli SLA. Per essere considerato un fattore di successo critico, un processo o una fase di processo deve migliorare la qualità dello SLA e favorire la disponibilità della rete in generale. Il fattore di successo critico deve inoltre essere misurabile in modo che l'organizzazione possa determinare il successo ottenuto rispetto alla procedura definita.
Per ulteriori informazioni, vedere Implementazione della gestione dei livelli di servizio.
Indicatori prestazioni
Gli indicatori di prestazione forniscono il meccanismo mediante il quale un'organizzazione misura i fattori critici di successo. In genere, questi vengono esaminati mensilmente per garantire il corretto funzionamento delle definizioni dei livelli di servizio o degli SLA. Il gruppo operazioni di rete e i gruppi di strumenti necessari possono eseguire le metriche riportate di seguito.
Nota: per le organizzazioni prive di SLA, si consiglia di eseguire definizioni dei livelli di servizio e revisioni dei livelli di servizio oltre alle metriche.
Gli indicatori di prestazione includono:
-
Definizione documentata dei livelli di servizio o SLA che include disponibilità, prestazioni, tempi di risposta del servizio reattivi, obiettivi di risoluzione dei problemi e gestione dei livelli di gravità.
-
Riunione mensile di analisi dei livelli di servizio per la verifica della conformità ai livelli di servizio e l'implementazione dei miglioramenti.
-
Metriche degli indicatori di prestazioni, tra cui disponibilità, prestazioni, tempi di risposta del servizio per priorità, tempo di risoluzione per priorità e altri parametri misurabili degli SLA.
Per ulteriori informazioni, vedere Implementazione della gestione dei livelli di servizio.
Flusso del processo di gestione dei livelli di servizio
Il flusso di processo di alto livello per la gestione dei livelli di servizio contiene due gruppi principali:
Fare clic sugli oggetti nel diagramma seguente per visualizzare i dettagli di tale passaggio.
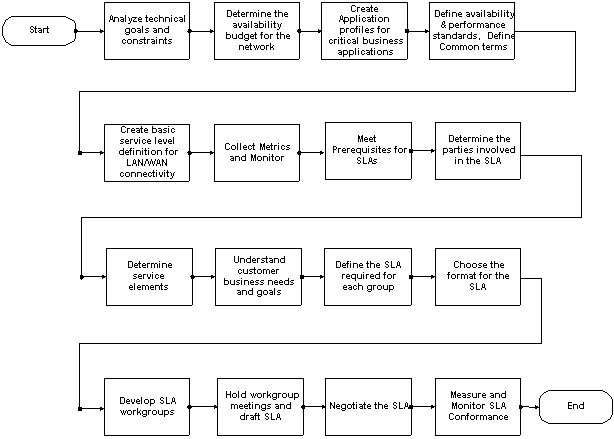
Implementazione della gestione dei livelli di servizio
L'implementazione della gestione dei livelli di servizio è costituita da sedici fasi suddivise nelle due categorie principali seguenti:
Definizione dei livelli di servizio di rete
I gestori di rete devono definire le regole principali in base alle quali la rete viene supportata, gestita e misurata. I livelli di servizio forniscono obiettivi per tutto il personale di rete e possono essere utilizzati come metrica nella qualità del servizio complessivo. È inoltre possibile utilizzare le definizioni dei livelli di servizio come strumento per definire il budget delle risorse di rete e come prova della necessità di finanziare una maggiore QoS. Forniscono inoltre un modo per valutare le prestazioni di fornitori e gestori.
Senza una definizione e una misurazione dei livelli di servizio, l'organizzazione non ha obiettivi chiari. Il livello di soddisfazione dei servizi può essere determinato da utenti che non si distinguono tra applicazioni, operazioni server/client o supporto di rete. L'allocazione del budget può essere più difficile perché il risultato finale non è chiaro all'organizzazione e, infine, l'organizzazione della rete tende ad essere più reattiva, non proattiva, nel migliorare il modello di rete e supporto.
Per creare e supportare un modello di livello di servizio, si consiglia di eseguire le operazioni riportate di seguito.
-
Definizione di standard di disponibilità e prestazioni e definizione di termini comuni.
-
Raccogliere le metriche e controllare la definizione del livello di servizio.
Passaggio 1: Analisi degli obiettivi e dei vincoli tecnici
Il modo migliore per iniziare l'analisi degli obiettivi e dei vincoli tecnici consiste nel brainstorming o nella ricerca di obiettivi e requisiti tecnici. Talvolta può essere utile invitare altri colleghi tecnici IT a partecipare a questa discussione, in quanto tali utenti hanno obiettivi specifici correlati ai propri servizi. Gli obiettivi tecnici includono livelli di disponibilità, throughput, jitter, ritardo, tempi di risposta, requisiti di scalabilità, introduzione di nuove funzionalità, nuove applicazioni, sicurezza, gestibilità e persino costi. L'organizzazione dovrebbe quindi esaminare i vincoli per raggiungere tali obiettivi, date le risorse disponibili. È possibile creare fogli di lavoro per ogni obiettivo con una spiegazione dei vincoli. Inizialmente, può sembrare che la maggior parte degli obiettivi non siano raggiungibili. Iniziare quindi ad assegnare priorità agli obiettivi o a ridurre le aspettative che possono ancora soddisfare i requisiti aziendali.
Ad esempio, è possibile che il livello di disponibilità sia del 99,999%, ovvero 5 minuti di inattività all'anno. Il raggiungimento di questo obiettivo è soggetto a numerosi vincoli, ad esempio singoli punti di errore nell'hardware, tempo medio di riparazione (MTTR, Mean Time To Repair) di hardware danneggiato in sedi remote, affidabilità della portante, funzionalità di rilevamento proattivo degli errori, tassi di modifica elevati e limitazioni correnti della capacità di rete. Di conseguenza, è possibile regolare l'obiettivo a un livello più raggiungibile. Il modello di disponibilità illustrato nella sezione successiva consente di impostare obiettivi realistici.
È inoltre possibile aumentare la disponibilità in determinate aree della rete che hanno meno vincoli. Quando l'organizzazione di rete pubblica gli standard di servizio per la disponibilità, i business group all'interno dell'organizzazione potrebbero trovare il livello inaccettabile. Questo è quindi il punto naturale per avviare discussioni sugli SLA o modelli di finanziamento/budget in grado di soddisfare i requisiti aziendali.
Lavorare per individuare tutti i vincoli o i rischi connessi al conseguimento dell'obiettivo tecnico. Assegnare priorità ai vincoli in termini di rischio o impatto maggiore rispetto all'obiettivo desiderato. In questo modo l'organizzazione può assegnare priorità alle iniziative di miglioramento della rete e determinare con quale facilità è possibile risolvere il problema. Esistono tre tipi di vincoli:
-
Tecnologia di rete, resilienza e configurazione
-
Procedure relative al ciclo di vita, tra cui la pianificazione, la progettazione, l'implementazione e il funzionamento
-
Carico di traffico o comportamento dell'applicazione corrente
La tecnologia di rete, la resilienza e i vincoli di configurazione sono limitazioni o rischi associati alla tecnologia, all'hardware, ai collegamenti, alla progettazione o alla configurazione correnti. Le limitazioni tecnologiche coprono qualsiasi vincolo imposto dalla tecnologia stessa. Ad esempio, nessuna tecnologia corrente consente tempi di convergenza inferiori al secondo in ambienti di rete ridondanti, che possono essere fondamentali per il supporto delle connessioni vocali in tutta la rete. Un altro esempio potrebbe essere la velocità raw che i dati possono attraversare sui collegamenti terrestri, che è di circa 100 miglia al millisecondo.
Le indagini sui rischi relativi alla resilienza dell'hardware di rete devono concentrarsi su topologia hardware, gerarchia, modularità, ridondanza e MTBF lungo percorsi definiti nella rete. I vincoli dei collegamenti di rete devono essere incentrati sui collegamenti di rete e sulla connettività dei vettori per le organizzazioni aziendali. I vincoli di collegamento possono includere la ridondanza e la diversità dei collegamenti, i limiti dei supporti, l'infrastruttura di cablaggio, la connettività dell'anello locale e la connettività su lunga distanza. I vincoli di progettazione si riferiscono alla progettazione fisica o logica della rete e includono tutto, dallo spazio disponibile per le apparecchiature alla scalabilità dell'implementazione del protocollo di routing. Tutti i progetti di protocolli e supporti devono essere considerati in relazione a configurazione, disponibilità, scalabilità, prestazioni e capacità. Devono essere presi in considerazione anche i vincoli dei servizi di rete, quali il protocollo DHCP (Dynamic Host Configuration Protocol), il DNS (Domain Name System), i firewall, i convertitori di protocollo e i convertitori di indirizzi di rete.
Le procedure relative al ciclo di vita definiscono i processi e la gestione della rete utilizzati per implementare soluzioni in modo coerente, rilevare e risolvere problemi, prevenire problemi di capacità o prestazioni e configurare la rete per la coerenza e la modularità. È necessario prendere in considerazione quest'area, in quanto l'esperienza e i processi sono in genere i fattori che contribuiscono maggiormente alla mancata disponibilità. Il ciclo di vita della rete si riferisce al ciclo di pianificazione, progettazione, implementazione e operazioni. All'interno di ognuna di queste aree, è necessario conoscere le funzionalità di gestione della rete, ad esempio la gestione delle prestazioni, la gestione della configurazione, la gestione degli errori e la sicurezza. È disponibile una valutazione del ciclo di vita della rete da parte dei servizi HAS (High Availability Services) dell'NSA Cisco che mostra gli attuali vincoli di disponibilità della rete associati alle pratiche del ciclo di vita della rete.
Il carico del traffico o i vincoli delle applicazioni correnti fanno semplicemente riferimento all'impatto del traffico e delle applicazioni correnti.
Sfortunatamente, molte applicazioni hanno vincoli significativi che richiedono un'attenta gestione. I requisiti di variazione, ritardo, throughput e larghezza di banda per le applicazioni correnti hanno in genere molti vincoli. Il modo in cui l'applicazione è stata scritta può anche creare vincoli. La creazione di profili delle applicazioni consente di comprendere meglio questi problemi. la sezione successiva tratta questa funzione. L'analisi della disponibilità, del traffico, della capacità e delle prestazioni complessive attuali consente inoltre ai manager di rete di comprendere le aspettative e i rischi correnti dei livelli di servizio. Questo viene in genere eseguito tramite un processo denominato definizione della base di rete, che consente di definire le prestazioni, la disponibilità o le medie di capacità della rete per un periodo di tempo definito, in genere circa un mese. Queste informazioni vengono in genere utilizzate per la pianificazione della capacità e l'analisi dei trend, ma possono anche essere utilizzate per comprendere i problemi dei livelli di servizio.
Nel foglio di lavoro seguente viene utilizzato il metodo goal/constraint per l'obiettivo di esempio di prevenire un attacco alla sicurezza o un attacco Denial of Service (DoS). È inoltre possibile utilizzare questo foglio di lavoro per determinare la copertura dei servizi per ridurre al minimo gli attacchi alla sicurezza.
| Rischio o vincolo | Tipo di vincolo | Impatto potenziale |
|---|---|---|
| Gli strumenti di rilevamento DoS disponibili non sono in grado di rilevare tutti i tipi di attacchi DoS. | Tecnologia/resilienza | Alta |
| Non dispone del personale e dell'elaborazione necessari per reagire agli avvisi. | Pratiche del ciclo di vita | Alta |
| Criteri di accesso alla rete correnti non applicati. | Pratiche del ciclo di vita | Media |
| La connessione a Internet a larghezza di banda inferiore può essere un fattore se per l'attacco viene utilizzata la congestione della larghezza di banda. | Capacità di rete | Media |
| Al momento, la configurazione della sicurezza per prevenire gli attacchi potrebbe non essere completa. | Tecnologia/resilienza | Media |
Passaggio 2: Determinare il budget di disponibilità
Un budget di disponibilità è la disponibilità teorica prevista della rete tra due punti definiti. Informazioni teoriche accurate sono utili in diversi modi:
-
L'organizzazione può utilizzare questo come obiettivo per la disponibilità interna e le deviazioni possono essere definite rapidamente e risolte.
-
Le informazioni possono essere utilizzate dai pianificatori di rete per determinare la disponibilità del sistema e garantire che la progettazione soddisfi i requisiti aziendali.
I fattori che contribuiscono alla mancata disponibilità o al tempo di interruzione includono guasti hardware, errori software, problemi ambientali e di alimentazione, errori del collegamento o della portante, progettazione della rete, errori umani o mancanza di processo. È necessario valutare attentamente ciascuno di questi parametri quando si valuta il budget di disponibilità complessivo per la rete.
Se attualmente l'organizzazione misura la disponibilità, potrebbe non essere necessario un budget di disponibilità. Utilizzare la misurazione della disponibilità come base per stimare il livello di servizio corrente utilizzato per una definizione del livello di servizio. Tuttavia, può essere interessante confrontare i due per comprendere la potenziale disponibilità teorica rispetto al risultato effettivo misurato.
La disponibilità è la probabilità che un prodotto o un servizio funzioni quando necessario. Vedere le seguenti definizioni:
-
Disponibilità
-
1 - (tempo totale di interruzione della connessione) / (tempo totale di connessione in servizio)
-
1 - [Sigma(num connessioni interessate dall'interruzione i X durata dell'interruzione i)] / (num connessioni in servizio X tempo operativo)
-
-
Non disponibilità
1 - Disponibilità o tempo totale di interruzione della connessione per (guasto hardware, guasto software, problemi ambientali e di alimentazione, guasto del collegamento o della portante, progettazione della rete o errore dell'utente e del processo)
-
Disponibilità hardware
La prima area da esaminare è il potenziale guasto hardware e l'effetto sulla non disponibilità. Per determinare questo, l'organizzazione deve conoscere l'MTBF di tutti i componenti di rete e l'MTTR per i problemi hardware di tutti i dispositivi in un percorso tra due punti. Se la rete è modulare e gerarchica, la disponibilità di hardware sarà la stessa tra quasi due punti. Le informazioni MTBF sono disponibili per tutti i componenti Cisco e su richiesta per un account manager locale. Il programma Cisco NSA HAS utilizza anche uno strumento per determinare la disponibilità dell'hardware lungo i percorsi di rete, anche quando nel sistema sono presenti ridondanza del modulo, ridondanza dello chassis e ridondanza dei percorsi. Uno dei principali fattori di affidabilità hardware è l'MTTR. Le organizzazioni devono valutare la rapidità con cui possono riparare hardware danneggiato. Se l'organizzazione non dispone di un piano di riserva e si basa su un contratto Cisco SMARTnet™ standard, il tempo medio di sostituzione potenziale è di circa 24 ore. In un ambiente LAN tipico con ridondanza dei core e senza ridondanza degli accessi, la disponibilità approssimativa è del 99,99% con un MTTR di 4 ore.
-
Disponibilità del software
L'area successiva in cui indagare sono gli errori software. A scopo di misurazione, Cisco definisce i guasti software come coldstart del dispositivo causati da errori software. Cisco ha compiuto progressi significativi nella comprensione della disponibilità del software; tuttavia, le versioni più recenti richiedono tempo per la misurazione e sono considerate meno disponibili del software di distribuzione generale. La disponibilità del software di implementazione generale, ad esempio IOS versione 11.2(18), è stata valutata oltre il 99,9999%. Questo valore viene calcolato in base all'inizio effettivo del raffreddamento sui router Cisco, utilizzando sei minuti come tempo di riparazione (tempo di ricaricamento del router). Le organizzazioni con una varietà di versioni dovrebbero avere una disponibilità leggermente inferiore a causa della maggiore complessità, interoperabilità e tempi di risoluzione dei problemi più lunghi. Le organizzazioni con le versioni software più recenti dovrebbero avere una maggiore non disponibilità. Anche la distribuzione per la non disponibilità è abbastanza ampia, il che significa che i clienti potrebbero riscontrare una significativa non disponibilità o disponibilità in prossimità di una release di implementazione generale.
-
Disponibilità ambientale e di energia
È inoltre necessario considerare i problemi ambientali e di alimentazione nella disponibilità. I problemi ambientali riguardano la rottura dei sistemi di raffreddamento necessari per mantenere le apparecchiature a una determinata temperatura di esercizio. Molti dispositivi Cisco vengono semplicemente spenti quando non sono conformi alle specifiche, piuttosto che rischiare di danneggiare tutto l'hardware. Ai fini di un budget di disponibilità, verrà utilizzata l'alimentazione in quanto è la causa principale di non disponibilità in quest'area.
Sebbene le interruzioni dell'alimentazione siano un aspetto importante per determinare la disponibilità della rete, questa discussione è limitata in quanto non è possibile eseguire un'analisi teorica dell'alimentazione. L'organizzazione deve valutare la disponibilità di energia per i propri dispositivi in base all'esperienza nella propria area geografica, alle funzionalità di backup dell'alimentazione e ai processi implementati per garantire un'alimentazione di qualità costante a tutti i dispositivi.
Per una valutazione conservativa, si può affermare che un'organizzazione con generatori di backup, sistemi UPS (Uninterruptible-Power-Supply) e processi di implementazione dell'alimentazione di qualità potrebbe sperimentare sei 99,999% di disponibilità, mentre le organizzazioni senza questi sistemi potrebbero sperimentare una disponibilità al 99,99%, ovvero circa 36 minuti di inattività all'anno. Naturalmente è possibile adattare questi valori a valori più realistici in base alla percezione dell'organizzazione o ai dati effettivi.
-
Errore di collegamento o vettore
I guasti dei collegamenti e delle portanti sono fattori importanti che riguardano la disponibilità in ambienti WAN. Tenere presente che gli ambienti WAN sono semplicemente altre reti soggette agli stessi problemi di disponibilità della rete dell'organizzazione, inclusi guasti hardware, software, utente e di alimentazione.
Molte reti di portanti hanno già eseguito un budget di disponibilità sui propri sistemi, ma ottenere queste informazioni potrebbe essere difficile. Tenete presente che i vettori spesso hanno anche livelli di garanzia di disponibilità che hanno poca o nessuna base su un budget di disponibilità effettivo. Tali livelli di garanzia sono a volte semplicemente metodi di vendita e di marketing utilizzati per promuovere il vettore. In alcuni casi, queste reti pubblicano anche statistiche di disponibilità che appaiono estremamente buone. Tenete presente che queste statistiche possono essere applicate solo alle reti core completamente ridondanti e non influiscono sulla non disponibilità a causa dell'accesso al loop locale, che è un fattore importante per la non disponibilità nelle reti WAN.
La creazione di una stima della disponibilità per gli ambienti WAN deve essere basata sulle informazioni effettive del vettore e sul livello di ridondanza per la connettività WAN. Se un'organizzazione dispone di più strutture di accesso agli edifici, fornitori di loop locale ridondanti, accesso locale Synchronous-Optical-Network (SONET) e gestori ridondanti di collegamenti a lunga distanza con diversità geografica, la disponibilità della WAN sarà notevolmente migliorata.
Il servizio telefonico rappresenta un budget di disponibilità abbastanza preciso per la connettività di rete non ridondante in ambienti WAN. La connettività end-to-end per i telefoni ha un budget di disponibilità approssimativo del 99,94% utilizzando una metodologia di budget della disponibilità simile a quella descritta in questa sezione. Questa metodologia è stata utilizzata con successo in ambienti di dati con leggere variazioni e attualmente viene utilizzata come destinazione nelle specifiche dei cavi dei pacchetti per le reti cablate dei provider di servizi. Se applichiamo questo valore a un sistema completamente ridondante, possiamo supporre che la disponibilità della WAN si avvicinerà al 99,9999%. Naturalmente, pochissime organizzazioni dispongono di sistemi WAN completamente ridondanti e geograficamente distribuiti a causa dei costi e della disponibilità, quindi occorre valutare attentamente questa capacità.
Gli errori di collegamento in un ambiente LAN sono meno probabili. Tuttavia, i responsabili della pianificazione potrebbero voler assumere una piccola quantità di downtime a causa di connettori rotti o allentati. Per le reti LAN, una stima prudente indica una disponibilità pari a circa il 99,9999%, ovvero circa 30 secondi all'anno.
-
Progettazione della rete
La progettazione della rete è un altro importante contributo alla disponibilità. I progetti non scalabili, gli errori di progettazione e i tempi di convergenza della rete influiscono negativamente sulla disponibilità.
Nota: ai fini del presente documento, nella sezione seguente sono inclusi errori di progettazione o progettazione non scalabili.
La progettazione della rete è quindi limitata a un valore misurabile basato su errori software e hardware nella rete che causano il reindirizzamento del traffico. Questo valore è in genere denominato "tempo di cambio sistema" ed è un fattore delle funzionalità del protocollo di riparazione automatica all'interno del sistema.
Calcolare la disponibilità utilizzando gli stessi metodi per i calcoli di sistema. Tuttavia, non è valido a meno che il tempo di commutazione della rete non soddisfi i requisiti delle applicazioni di rete. Se il tempo di switchover è accettabile, rimuoverlo dal calcolo. Se il tempo di switchover non è accettabile, è necessario aggiungerlo ai calcoli. Ad esempio, è possibile utilizzare il protocollo VoIP (Voice over IP) in un ambiente in cui il tempo di cambio effettivo o stimato è di 30 secondi. In questo esempio gli utenti interromperanno semplicemente il telefono e riproveranno. Gli utenti vedranno questo periodo di tempo come non disponibile, ma non è stato stimato nel budget di disponibilità.
Calcolare la non disponibilità dovuta al tempo di commutazione del sistema analizzando la disponibilità teorica di software e hardware lungo percorsi ridondanti, in quanto il passaggio avverrà in quest'area. È necessario conoscere il numero di dispositivi che possono guastarsi e causare lo switchover nel percorso ridondante, l'MTBF di tali dispositivi e il tempo di switchover. Un semplice esempio potrebbe essere un MTBF di 35.433 ore per ciascuno dei due dispositivi identici ridondanti e un tempo di switchover di 30 secondi. Dividendo 35.433 per 8.766 (ore all'anno in media per includere gli anni bisestili), vediamo che il dispositivo fallirà una volta ogni quattro anni. Se si utilizzano 30 secondi come tempo di switchover, si può presumere che ogni dispositivo sperimenterà, in media, 7,5 secondi all'anno di non disponibilità dovuta al switchover. Poiché gli utenti possono passare attraverso uno di questi percorsi, il risultato viene raddoppiato a 15 secondi all'anno. Se calcolato in secondi all'anno, il tempo di disponibilità dovuto allo switchover può essere calcolato come 99,99999785% in questo semplice sistema. Questo valore può essere superiore in altri ambienti a causa del numero di dispositivi ridondanti presenti nella rete in cui lo switchover è un potenziale.
-
Errore e processo utente
Gli errori degli utenti e i problemi di disponibilità dei processi sono le cause principali della mancata disponibilità nelle reti aziendali e delle portanti. Circa l'80% della mancata disponibilità è dovuto a problemi quali il mancato rilevamento di errori, errori di modifica e problemi di prestazioni.
Le organizzazioni non intendono utilizzare quattro volte tutte le altre situazioni di non disponibilità teoriche per determinare il budget di disponibilità, tuttavia le prove indicano che questo è il caso in molti ambienti. La sezione successiva tratta in modo più approfondito questo aspetto della non disponibilità.
Poiché in teoria non è possibile calcolare la quantità di non disponibilità a causa di errori e processi dell'utente, è consigliabile rimuovere questo valore rimosso dal budget di disponibilità e che le organizzazioni si impegnino per la perfezione. L'unica avvertenza è che le organizzazioni devono comprendere il rischio attuale di disponibilità nei propri processi e livelli di esperienza. Una volta meglio compresi questi rischi e gli inibitori, i pianificatori della rete potrebbero voler prendere in considerazione una certa quantità di non disponibilità dovuta a questi problemi. Il programma HAS di Cisco analizza questi problemi e può aiutare le organizzazioni a comprendere la potenziale non disponibilità dovuta a problemi di processo, errori degli utenti o problemi di competenza.
-
Determinazione del budget di disponibilità finale
È possibile determinare il budget di disponibilità complessivo moltiplicando la disponibilità per ciascuna delle aree definite in precedenza. Questa operazione viene in genere eseguita in ambienti omogenei in cui la connettività tra due punti è simile, ad esempio un ambiente LAN modulare gerarchico o un ambiente WAN standard gerarchico.
In questo esempio, il budget di disponibilità viene eseguito per un ambiente LAN modulare gerarchico. L'ambiente utilizza generatori di backup e sistemi UPS per tutti i componenti di rete e gestisce correttamente l'alimentazione. L'organizzazione non utilizza il VoIP e non desidera considerare il tempo di commutazione del software. Le stime sono:
-
Disponibilità del percorso hardware tra due endpoint = 99,99%
-
Disponibilità del software utilizzando l'affidabilità del software GD come riferimento = disponibilità al 99,9999%
-
Disponibilità di ambiente e alimentazione con sistemi di backup = 99,999% di disponibilità
-
Errore di collegamento in ambiente LAN = disponibilità al 99,9999%
-
Tempo di cambio sistema senza factoring = disponibilità al 100%
-
Si presume che la disponibilità dei processi e degli errori dell'utente sia perfetta = disponibilità al 100%
Il budget di disponibilità finale che le organizzazioni devono raggiungere è pari a 0,9999 X 0,999999 X 0,999999 X 0,999999 = 0,999896 o a una disponibilità del 99,9896%. Se si considera la potenziale non disponibilità dovuta a un errore dell'utente o del processo e si presume che la non disponibilità sia 4 volte superiore a causa di fattori tecnici, è possibile supporre che il budget relativo alla disponibilità sia pari al 99,95%.
L'analisi di questo esempio indica che la disponibilità della LAN diminuirebbe in media del 99,95-99,989%. Questi numeri possono ora essere utilizzati come obiettivo del livello di servizio per l'organizzazione di rete. È possibile ottenere ulteriore valore misurando la disponibilità nel sistema e determinando la percentuale di non disponibilità dovuta a ognuna delle sei aree sopra indicate. Ciò consente all'organizzazione di valutare correttamente fornitori, vettori, processi e personale. Il numero può essere utilizzato anche per definire le aspettative all'interno dell'azienda. Se il numero non è accettabile, assegnare risorse aggiuntive in budget per ottenere i livelli desiderati.
Può essere utile per i gestori di rete comprendere la quantità di tempi di inattività a un determinato livello di disponibilità. Il tempo di inattività in minuti per un periodo di un anno, dato l'eventuale livello di disponibilità, è:
Minuti di inattività in un anno = 525600 (livello di disponibilità X 5256)
Se si utilizza il livello di disponibilità del 99,95%, il risultato sarà uguale a 525600 - (99,95 X 5256), ovvero 262,8 minuti di inattività. Per la definizione di disponibilità sopra riportata, questo valore corrisponde alla quantità media di tempo di inattività per tutte le connessioni in servizio nella rete.
-
Passaggio 3: Crea profili applicazione
I profili applicazione consentono all'organizzazione di rete di comprendere e definire i requisiti dei livelli di servizio di rete per le singole applicazioni. In questo modo è possibile garantire che la rete supporti i requisiti delle singole applicazioni e i servizi di rete in generale. I profili dell'applicazione possono inoltre fungere da base documentata per il supporto dei servizi di rete quando i gruppi di applicazioni o di server segnalano il problema alla rete. In ultima analisi, i profili delle applicazioni consentono di allineare gli obiettivi dei servizi di rete ai requisiti delle applicazioni o delle attività aziendali confrontando i requisiti delle applicazioni, ad esempio prestazioni e disponibilità, con obiettivi realistici di servizio di rete o limitazioni correnti. Ciò è importante non solo per la gestione dei livelli di servizio, ma anche per la progettazione complessiva della rete top-down.
Creare profili applicazione ogni volta che si introducono nuove applicazioni nella rete. Potrebbe essere necessario un accordo tra il gruppo di applicazioni IT, i gruppi di amministrazione del server e la rete per implementare la creazione di profili di applicazioni per i servizi nuovi ed esistenti. Profili completi per applicazioni aziendali e applicazioni di sistema. Le applicazioni aziendali possono includere la posta elettronica, il trasferimento di file, la navigazione sul Web, l'imaging medico o la produzione. Le applicazioni di sistema possono includere distribuzione software, autenticazione utente, backup di rete e gestione di rete.
Il profilo dell'applicazione deve essere creato da un analista di rete e da un'applicazione o da un'applicazione di supporto del server. Le nuove applicazioni possono richiedere l'uso di un analizzatore di protocolli e di un emulatore WAN con emulazione ritardata per caratterizzare correttamente i requisiti delle applicazioni. Questo aiuta a identificare la larghezza di banda necessaria, il ritardo massimo per l'usabilità delle applicazioni e i requisiti di jitter. Questa operazione può essere eseguita in un ambiente lab se si dispone dei server necessari. In altri casi, ad esempio con il VoIP, i requisiti di rete, tra cui jitter, ritardo e larghezza di banda, sono ben pubblicati e non sarà necessario eseguire test di laboratorio. Un profilo applicazione deve includere i seguenti elementi:
-
Nome applicazione
-
Tipo di applicazione
-
Nuova applicazione?
-
Importanza aziendale
-
Requisiti di disponibilità
-
Protocolli e porte utilizzati
-
Larghezza di banda utente stimata (kbps)
-
Numero e ubicazione degli utenti
-
Requisiti di trasferimento dei file (inclusi tempo, volume ed endpoint)
-
Impatto dell'interruzione della rete
-
Ritardo, instabilità e requisiti di disponibilità
L'obiettivo del profilo dell'applicazione è comprendere i requisiti aziendali per l'applicazione, l'importanza per l'azienda e i requisiti di rete, quali larghezza di banda, ritardo e jitter. Inoltre, l'organizzazione di rete dovrebbe comprendere l'impatto dei tempi di inattività della rete. In alcuni casi è necessario riavviare l'applicazione o il server, con un conseguente aumento significativo dei tempi di inattività. Una volta completato il profilo dell'applicazione, è possibile confrontare le funzionalità generali della rete e allineare i livelli di servizio della rete ai requisiti aziendali e applicativi.
Passaggio 4: Definizione degli standard di disponibilità e prestazioni
Gli standard di disponibilità e prestazioni definiscono le aspettative di servizio per l'organizzazione. Queste possono essere definite per aree diverse della rete o applicazioni specifiche. Le prestazioni possono essere definite anche in termini di ritardo di andata e ritorno, jitter, throughput massimo, impegni di larghezza di banda e scalabilità complessiva. Oltre a definire le aspettative relative al servizio, l'organizzazione deve anche provvedere a definire ciascuno degli standard del servizio in modo che gli utenti e i gruppi IT che lavorano con la rete comprendano appieno lo standard del servizio e il modo in cui esso si rapporta ai requisiti di amministrazione delle applicazioni o dei server. Gli utenti e i gruppi IT devono inoltre comprendere come misurare lo standard del servizio.
I risultati dei passi precedenti di definizione del livello di servizio aiuteranno a creare lo standard. A questo punto, l'organizzazione di rete deve avere una chiara comprensione dei rischi e dei vincoli correnti della rete, una comprensione del comportamento dell'applicazione e una base di riferimento per l'analisi teorica della disponibilità.
-
Definire le aree geografiche o applicative in cui verranno applicati gli standard del servizio.
ad esempio per quanto riguarda la connettività LAN del campus, WAN domestica, extranet o dei partner. In alcuni casi, l'organizzazione può avere obiettivi di livello di servizio diversi all'interno di un'area. Ciò non è raro per le aziende o le organizzazioni di fornitori di servizi. In questi casi, non sarebbe raro creare diversi standard dei livelli di servizio basati sui singoli requisiti di servizio. Questi possono essere classificati come standard di servizio in oro, argento e bronzo all'interno di un'area geografica o di servizio.
-
Definire i parametri degli standard di assistenza.
La disponibilità e il ritardo di andata e ritorno sono gli standard più comuni per i servizi di rete. All'occorrenza, è possibile includere anche il throughput massimo, l'impegno minimo per la larghezza di banda, le jitter, le percentuali di errore accettabili e le funzionalità di scalabilità. Prestare attenzione quando si esamina il parametro del servizio per i metodi di misurazione. Indipendentemente dal fatto che il parametro passi a un contratto di servizio, l'organizzazione deve considerare come il parametro del servizio possa essere misurato o giustificato in caso di problemi o disaccordi di servizio.
Dopo aver definito le aree di assistenza e i parametri di assistenza, utilizzare le informazioni dei passi precedenti per creare una matrice di standard di assistenza. L'organizzazione dovrà inoltre definire le aree che possono creare confusione negli utenti e nei gruppi IT. Ad esempio, il tempo di risposta massimo sarà molto diverso per un ping andata e ritorno rispetto a quando si preme Invio in una posizione remota per un'applicazione specifica. Nella tabella seguente sono riportati gli obiettivi prestazionali negli Stati Uniti.
| Area di rete | Destinazione disponibilità | Metodo di misurazione | Target tempo medio di risposta di rete | Tempo di risposta massimo accettato | Metodo di misurazione del tempo di risposta |
|---|---|---|---|---|---|
| LAN | 99.99% | Minuti utente interessati | Meno di 5 ms | 10 ms | Risposta ping andata e ritorno |
| WAN | 99.99% | Minuti utente interessati | Meno di 100 ms (ping di andata e ritorno) | 150 ms | Risposta ping andata e ritorno |
| WAN ed Extranet critiche | 99.99% | Minuti utente interessati | Meno di 100 ms (ping di andata e ritorno) | 150 ms | Risposta ping andata e ritorno |
Passaggio 5: Definizione servizio di rete
Questo è l'ultimo passo verso la gestione dei livelli di servizio di base. definisce i processi reattivi e proattivi e le funzionalità di gestione della rete implementate per raggiungere gli obiettivi dei livelli di servizio. Il documento finale è in genere denominato piano di supporto alle operazioni. La maggior parte dei piani di supporto delle applicazioni include solo requisiti di supporto reattivo. In ambienti ad elevata disponibilità, l'organizzazione deve anche prendere in considerazione processi di gestione proattivi che verranno utilizzati per isolare e risolvere i problemi di rete prima che vengano avviate le chiamate di assistenza utente. Nel complesso, il documento finale dovrebbe:
-
Descrivere il processo reattivo e proattivo utilizzato per raggiungere l'obiettivo del livello di servizio
-
Modalità di gestione del processo del servizio
-
Modalità di misurazione dell'obiettivo del servizio e del processo del servizio.
In questa sezione vengono forniti alcuni esempi di definizioni di servizi reattivi e proattivi da prendere in considerazione per molte organizzazioni di fornitori di servizi e aziende. L'obiettivo della creazione delle definizioni dei livelli di servizio è quello di creare un servizio che soddisfi gli obiettivi di disponibilità e prestazioni. A tale scopo, l'organizzazione deve creare il servizio tenendo presenti i vincoli tecnici correnti, il budget di disponibilità e i profili delle applicazioni. In particolare, l'organizzazione deve definire e creare un servizio che identifichi e risolva i problemi in modo coerente e rapido entro i tempi previsti dal modello di disponibilità. L'organizzazione deve inoltre definire un servizio in grado di identificare e risolvere rapidamente i potenziali problemi di servizio che, se ignorati, influiranno sulla disponibilità e sulle prestazioni.
Non è possibile ottenere il livello di servizio desiderato durante la notte. Carenze quali scarsa competenza, limitazioni dei processi correnti o personale inadeguato possono impedire all'organizzazione di raggiungere gli standard o gli obiettivi desiderati, anche dopo le precedenti fasi di analisi del servizio. Non esiste un metodo preciso per far corrispondere il livello di servizio richiesto agli obiettivi desiderati. A tale scopo, l'organizzazione deve misurare gli standard di assistenza e i parametri di assistenza utilizzati per supportare gli standard di assistenza. Quando l'organizzazione non soddisfa gli obiettivi del servizio, deve quindi esaminare le metriche del servizio per comprendere il problema. In molti casi, è possibile aumentare il budget per migliorare i servizi di supporto e apportare i miglioramenti necessari per raggiungere gli obiettivi desiderati. Nel tempo l'organizzazione può apportare diverse modifiche, sia all'obiettivo del servizio che alla definizione del servizio, per allineare i servizi di rete e i requisiti aziendali.
Ad esempio, un'organizzazione potrebbe ottenere il 99% di disponibilità quando l'obiettivo era molto più elevato con una disponibilità del 99,9%. Esaminando le metriche di assistenza e supporto, i rappresentanti dell'organizzazione hanno rilevato che la sostituzione dell'hardware richiede circa 24 ore, molto più tempo rispetto alla stima originale, poiché l'organizzazione ne aveva preventivate solo quattro. Inoltre, l'organizzazione ha rilevato che le funzionalità di gestione proattiva vengono ignorate e che i dispositivi di rete ridondanti non vengono ripristinati. Hanno anche scoperto di non avere il personale per apportare dei miglioramenti. Di conseguenza, dopo aver preso in considerazione la riduzione degli attuali obiettivi di servizio, l'organizzazione ha preventivato ulteriori risorse necessarie per raggiungere il livello di servizio desiderato.
Le definizioni dei servizi devono includere sia le definizioni di supporto reattivo che le definizioni proattive. Le definizioni reattive definiscono il modo in cui l'organizzazione reagirà ai problemi dopo che questi saranno stati identificati a causa di un reclamo dell'utente o delle funzionalità di gestione della rete. Le definizioni proattive descrivono come l'organizzazione identificherà e risolverà potenziali problemi di rete, tra cui la riparazione di componenti di rete "standby" danneggiati, il rilevamento degli errori, le soglie di capacità e gli aggiornamenti. Nelle sezioni seguenti vengono forniti esempi di definizioni dei livelli di servizio sia reattive che proattive.
Definizioni dei livelli di servizio reattivi
Le seguenti aree dei livelli di servizio vengono in genere misurate utilizzando le statistiche del database dell'help desk e l'audit periodico. Questa tabella mostra un esempio di gravità del problema per un'organizzazione. Si noti che il grafico non include la modalità di gestione delle richieste di nuovi servizi, che possono essere gestite da un contratto di servizio o da un'analisi di simulazione delle prestazioni e del profilo delle applicazioni aggiuntive. In genere, la gravità 5 può essere una richiesta di nuovo servizio se gestita tramite lo stesso processo di supporto.
| Gravità 1 | Gravità 2 | Gravità 3 | Gravità 4 |
|---|---|---|---|
| Grave impatto aziendale Segmento server o utente LAN inattivo Sito WAN critico inattivo | Elevato impatto aziendale attraverso perdita o degrado, possibile soluzione alternativa in sede LAN del campus inattiva; 5-99 utenti interessati Sito WAN nazionale inattivo Sito WAN internazionale impatto critico sulle prestazioni | Alcune funzionalità di rete specifiche sono andate perse o danneggiate, ad esempio la perdita di ridondanza Prestazioni LAN del campus ha avuto ripercussioni sulla ridondanza LAN persa | Query funzionale o errore che non ha alcun impatto aziendale sull'organizzazione |
Una volta definita la gravità del problema, definire o esaminare il processo di supporto per creare le definizioni di risposta del servizio. In generale, le definizioni di risposta ai servizi richiedono una struttura di supporto su più livelli abbinata a un sistema di supporto software per l'help desk per tenere traccia dei problemi tramite ticket. Le metriche devono inoltre essere disponibili sui tempi di risposta e di risoluzione per ciascuna priorità, sul numero di chiamate per priorità e sulla qualità di risposta/risoluzione. Per definire il processo di supporto, consente di definire gli obiettivi di ogni livello di supporto nell'organizzazione e i relativi ruoli e responsabilità. Ciò consente all'organizzazione di comprendere i requisiti delle risorse e i livelli di esperienza per ogni livello di supporto. Nella tabella seguente viene fornito un esempio di organizzazione di supporto su più livelli con linee guida per la risoluzione dei problemi.
| Livello di supporto | Responsabilità | Obiettivi |
|---|---|---|
| Supporto di livello 1 | Supporto a tempo pieno per l'help desk Rispondere alle chiamate di supporto, risolvere problemi, lavorare fino a 15 minuti sui problemi, inoltrare richieste di assistenza e inoltrare la richiesta al supporto di livello 2 appropriato | Risoluzione del 40% delle chiamate in arrivo |
| Supporto di livello 2 | Monitoraggio delle code, gestione della rete, monitoraggio delle stazioni Impostazione di ticket per problemi identificati dal software Implementazione Esecuzione di chiamate dal livello 1, dal fornitore e dal livello 3 Escalation Assunzione della proprietà della chiamata fino alla risoluzione | Risoluzione del 100% delle chiamate al livello 2 |
| Supporto di livello 3 | Fornire supporto immediato al livello 2 per tutti i problemi di priorità 1 Convenire di risolvere tutti i problemi non risolti dal livello 2 entro il periodo di risoluzione degli SLA | Nessun problema diretto |
Il passaggio successivo consiste nella creazione della matrice per la risposta al servizio e la definizione del servizio di risoluzione. In questo modo vengono definiti gli obiettivi relativi alla velocità di risoluzione dei problemi, inclusa la sostituzione dell'hardware. È importante definire gli obiettivi in quest'area poiché i tempi di risposta e di ripristino dei servizi influiscono direttamente sulla disponibilità della rete. Anche i tempi di risoluzione dei problemi devono essere allineati con il budget di disponibilità. Se nel budget della disponibilità non vengono presi in considerazione numerosi problemi di alta gravità, l'organizzazione può quindi lavorare per comprendere la causa di tali problemi e individuare un possibile rimedio. Vedere la tabella seguente:
| Gravità del problema | Risposta dell'help desk | Risposta di livello 2 | Livello 2 in loco | Sostituzione hardware | Risoluzione dei problemi |
|---|---|---|---|---|---|
| 1 | Escalation immediata al livello 2, network operations manager | 5 minuti | 2 ore | 2 ore | 4 ore |
| 2 | Escalation immediata al livello 2, network operations manager | 5 minuti | 4 ore | 4 ore | 8 ore |
| 3 | 15 minuti | 2 ore | 12 ore | 24 ore | 36 ore |
| 4 | 15 minuti | 4 ore | 3 giorni | 3 giorni | 6 giorni |
Oltre alla risposta e alla risoluzione dei problemi, è possibile creare una matrice per l'escalation. La matrice di escalation consente di garantire che le risorse disponibili siano focalizzate sui problemi che influiscono gravemente sul servizio. In generale, quando gli analisti si concentrano sulla risoluzione dei problemi, raramente si concentrano sull'impiego di ulteriori risorse per risolvere il problema. Definire quando devono essere notificate risorse aggiuntive contribuisce a promuovere la consapevolezza dei problemi nella gestione e può generalmente contribuire a portare a future misure proattive o preventive. Vedere la tabella seguente:
| Tempo trascorso | Gravità 1 | Gravità 2 | Gravità 3 | Gravità 4 |
|---|---|---|---|---|
| 5 minuti | Responsabile delle operazioni di rete, supporto di livello 3, responsabile delle reti | |||
| 1 ora | Aggiornamento a Network Operations Manager, supporto di livello 3, responsabile delle reti | Aggiornamento a Network Operations Manager, supporto di livello 3, responsabile delle reti | ||
| 2 ore | Escalation a VP, aggiornamento a director, operations manager | |||
| 4 ore | Root cause analysis per VP, director, operations manager, supporto di livello 3, non risolta richiede notifica CEO | Escalation a VP, aggiornamento a director, operations manager | ||
| 24 ore | Gestione operazioni di rete | |||
| 5 giorni | Gestione operazioni di rete |
Finora, le definizioni dei livelli di servizio si sono focalizzate sul modo in cui l'organizzazione di supporto alle operazioni reagisce ai problemi una volta identificati. Le organizzazioni operative hanno creato per anni piani di supporto operativo con informazioni simili a quelle sopra riportate. In questi casi, tuttavia, non è chiaro come l'organizzazione identificherà i problemi e quali saranno identificati. Le organizzazioni di rete più sofisticate hanno tentato di risolvere questo problema semplicemente creando obiettivi per la percentuale di problemi identificati in modo proattivo, a differenza dei problemi identificati in modo reattivo da segnalazioni o reclami degli utenti.
Nella tabella seguente viene illustrato come un'organizzazione potrebbe voler misurare le capacità di supporto proattivo e il supporto proattivo in generale.
| Area di rete | Percentuale di identificazione proattiva dei problemi | Percentuale di identificazione dei problemi reattivi |
|---|---|---|
| LAN | 80 % | 20 % |
| WAN | 80 % | 20 % |
Si tratta di un buon punto di partenza per definire definizioni di supporto più proattive perché è semplice e abbastanza facile da misurare, soprattutto se gli strumenti proattivi generano automaticamente problemi. Ciò consente inoltre di focalizzare gli strumenti e le informazioni di gestione della rete sulla risoluzione proattiva dei problemi anziché sulla root cause. Tuttavia, il problema principale di questo metodo è che non definisce i requisiti di supporto proattivo. In questo modo si creano generalmente lacune nelle funzionalità di gestione del supporto proattivo, con un conseguente aumento dei rischi di disponibilità.
Definizioni proattive dei livelli di servizio
Una metodologia più completa per la creazione di definizioni dei livelli di servizio include maggiori dettagli su come viene monitorata la rete e su come l'organizzazione operativa reagisce alle soglie NMS (Network Management Station) definite su base 7 x 24. Questo può sembrare un compito impossibile, considerato il numero di variabili MIB (Management Information Base) e la quantità di informazioni di gestione della rete disponibili pertinenti allo stato della rete. Potrebbe anche essere estremamente costoso e dispendioso in termini di risorse. Sfortunatamente, queste obiezioni impediscono a molti di implementare una definizione di servizio proattiva che, per natura, dovrebbe essere semplice, abbastanza facile da seguire e applicabile solo ai maggiori rischi di disponibilità o prestazioni nella rete. Se un'organizzazione ritiene che le definizioni dei servizi proattivi di base abbiano un valore aggiunto, è possibile aggiungere nel tempo più variabili senza alcun impatto significativo, purché venga implementato un approccio in più fasi.
Includere la prima area delle definizioni dei servizi proattivi in tutti i piani di supporto alle operazioni. La definizione del servizio indica semplicemente come il gruppo operativo identificherà e risponderà in modo proattivo alle condizioni di rete o di collegamento in diverse aree della rete. Senza questa definizione (o supporto di gestione), l'organizzazione può aspettarsi un supporto variabile, aspettative irrealistiche degli utenti e, in ultima analisi, una minore disponibilità della rete.
Nella tabella seguente viene illustrato come un'organizzazione potrebbe creare una definizione di servizio per le condizioni di collegamento/disattivazione del dispositivo. Nell'esempio viene illustrata un'organizzazione aziendale che potrebbe avere requisiti di notifica e risposta diversi in base all'ora del giorno e all'area della rete.
| Dispositivo di rete o collegamento non attivo | Metodo di rilevamento | Notifica 5 x 8 | Notifica 7 x 24 | Risoluzione 5 x 8 | Risoluzione 7 x 24 |
|---|---|---|---|---|---|
| LAN core | SNMP, trapping, polling di dispositivi e collegamenti | NOC crea un ticket per la risoluzione dei problemi, una pagina per il cercapersone LAN-duty | Pagina automatica cercapersone di servizio LAN, il responsabile di servizio LAN crea un ticket per la coda LAN principale | Analista LAN assegnato entro 15 minuti da NOC, riparazione secondo la definizione di risposta del servizio | Priorità 1 e 2 indagine e risoluzione immediate Priorità 3 e 4 coda per la risoluzione mattutina |
| WAN nazionale | SNMP, trapping, polling di dispositivi e collegamenti | NOC crea un trouble ticket, page WAN duty pager | Pagina automatica cercapersone di servizio WAN, persona di servizio WAN crea un ticket per la coda WAN | L'analista WAN viene assegnato entro 15 minuti dal NOC, riparato in base alla definizione di risposta del servizio | Priorità 1 e 2 indagine e risoluzione immediate Priorità 3 e 4 coda per la risoluzione mattutina |
| Extranet | SNMP, trapping, polling di dispositivi e collegamenti | NOC crea un ticket per la risoluzione dei problemi, cercapersone compito partner di paging | Cercapersone compito partner pagina automatica, persona compito partner crea un ticket problema per la coda partner | Analista partner assegnato entro 15 minuti da NOC, riparazione secondo la definizione di risposta del servizio | Priorità 1 e 2 indagine e risoluzione immediate; Priorità 3 e 4 coda per la risoluzione mattutina |
Le restanti definizioni dei livelli di servizio proattivi possono essere suddivise in due categorie: errori di rete e problemi di capacità/prestazioni. Solo una piccola percentuale di organizzazioni di rete dispone di definizioni dei livelli di servizio in queste aree. Di conseguenza, questi problemi vengono ignorati o gestiti sporadicamente. Ciò può risultare utile in alcuni ambienti di rete, ma gli ambienti ad alta disponibilità richiedono in genere una gestione proattiva e coerente dei servizi.
Le organizzazioni di rete tendono ad avere problemi con le definizioni proattive dei servizi per diversi motivi. Ciò è dovuto principalmente al fatto che non è stata eseguita un'analisi dei requisiti per la definizione di servizi proattivi in base ai rischi di disponibilità, al budget di disponibilità e ai problemi delle applicazioni. Ciò porta a requisiti poco chiari per le definizioni proattive dei servizi e a vantaggi poco chiari, soprattutto perché potrebbero essere necessarie ulteriori risorse.
Il secondo motivo riguarda il bilanciamento della quantità di gestione proattiva che può essere eseguita con risorse esistenti o nuove. Generare solo gli avvisi che hanno un impatto potenziale grave sulla disponibilità o sulle prestazioni. È inoltre necessario prendere in considerazione la gestione o i processi di correlazione degli eventi per garantire che non vengano generati più ticket proattivi per lo stesso problema. L'ultimo motivo per cui le organizzazioni potrebbero avere difficoltà è che la creazione di una nuova serie di avvisi proattivi può spesso generare un flusso iniziale di messaggi che in precedenza non venivano rilevati. Il gruppo operativo deve essere preparato per questo flusso iniziale di problemi e risorse aggiuntive a breve termine per correggere o risolvere queste condizioni non rilevate in precedenza.
La prima categoria di definizioni proattive dei livelli di servizio è rappresentata dagli errori di rete. Gli errori di rete possono essere ulteriormente suddivisi in errori di sistema che includono errori software o hardware, errori di protocollo, errori di controllo dei supporti, errori di precisione e avvisi ambientali. Lo sviluppo di una definizione del livello di servizio inizia con una comprensione generale di come verranno rilevate queste condizioni problematiche, chi le esaminerà e cosa accadrà quando si verificheranno. Se necessario, aggiungere messaggi o problemi specifici alla definizione del livello di servizio. Per garantire il successo, potrebbe essere necessario eseguire ulteriori operazioni nelle seguenti aree:
-
Responsabilità di supporto di livello 1, 2 e 3
-
Bilanciare la priorità delle informazioni di gestione della rete con la quantità di lavoro proattivo che il gruppo operativo può gestire in modo efficace
-
Requisiti di formazione per garantire che il personale di supporto possa gestire in modo efficace gli avvisi definiti
-
Metodologie di correlazione degli eventi per garantire che non vengano generati più ticket per lo stesso problema di root cause
-
Documentazione su messaggi o avvisi specifici che facilita l'identificazione degli eventi a livello di supporto di livello 1
Nella tabella seguente viene illustrata una definizione di livello di servizio di esempio per gli errori di rete che fornisce una chiara comprensione di chi è responsabile degli avvisi proattivi relativi agli errori di rete, di come verrà identificato il problema e di cosa si verificherà quando si verifica il problema. L'organizzazione potrebbe avere bisogno di ulteriori sforzi come sopra definito per garantire il successo
s.
| Categoria errore | Metodo di rilevamento | Soglia | Azione intrapresa |
|---|---|---|---|
| Errori software (arresti anomali imposti dal software) | Revisione giornaliera dei messaggi syslog tramite il visualizzatore syslog Eseguita dal supporto di livello 2 | Qualsiasi occorrenza per la priorità 0, 1 e 2 Oltre 100 occorrenze di livello 3 o superiore | Esamina il problema, crea la richiesta di assistenza e invia se si verifica un nuovo problema o se il problema richiede attenzione |
| Errori hardware (arresti anomali causati dall'hardware) | Revisione giornaliera dei messaggi syslog tramite il visualizzatore syslog Eseguita dal supporto di livello 2 | Qualsiasi occorrenza per la priorità 0, 1 e 2 Oltre 100 occorrenze di livello 3 o superiore | Esamina il problema, crea la richiesta di assistenza e invia se si verifica un nuovo problema o se il problema richiede attenzione |
| Errori di protocollo (solo protocolli di routing IP) | Revisione giornaliera dei messaggi syslog tramite il visualizzatore syslog Eseguita dal supporto di livello 2 | Dieci messaggi al giorno con priorità 0, 1 e 2 Oltre 100 occorrenze di livello 3 o superiore | Esamina il problema, crea la richiesta di assistenza e invia se si verifica un nuovo problema o se il problema richiede attenzione |
| Errori di controllo supporti (solo FDDI, POS e Fast Ethernet) | Revisione giornaliera dei messaggi syslog tramite il visualizzatore syslog Eseguita dal supporto di livello 2 | Dieci messaggi al giorno con priorità 0, 1 e 2 Oltre 100 occorrenze di livello 3 o superiore | Esamina il problema, crea la richiesta di assistenza e invia se si verifica un nuovo problema o se il problema richiede attenzione |
| Messaggi ambientali (alimentazione e temperatura) | Revisione giornaliera dei messaggi syslog tramite il visualizzatore syslog Eseguita dal supporto di livello 2 | Qualsiasi messaggio | Creazione di ticket e invio di nuovi problemi |
| Errori di precisione (errori di input del collegamento) | Polling SNMP a intervalli di 5 minuti Eventi di soglia ricevuti da NOC | Errori di input o output Un errore in qualsiasi intervallo di 5 minuti in qualsiasi collegamento | Creazione di una richiesta di assistenza per nuovi problemi e invio al supporto di livello 2 |
L'altra categoria di definizioni proattive dei livelli di servizio si applica alle prestazioni e alla capacità. La vera gestione delle prestazioni e della capacità include la gestione delle eccezioni, la definizione delle basi e dei trend e l'analisi di simulazione. La definizione del livello di servizio si limita a definire le soglie di eccezione relative a prestazioni e capacità e le soglie medie che consentono di avviare un'indagine o un aggiornamento. Queste soglie possono quindi essere applicate in qualche modo a tutti e tre i processi di gestione delle prestazioni e della capacità.
Le definizioni dei livelli di servizio di capacità e prestazioni possono essere suddivise in diverse categorie: collegamenti di rete, dispositivi di rete, prestazioni end-to-end e prestazioni delle applicazioni. Lo sviluppo di definizioni dei livelli di servizio in queste aree richiede conoscenze tecniche approfondite relative ad aspetti specifici della capacità dei dispositivi, della capacità dei supporti, delle caratteristiche QoS e dei requisiti delle applicazioni. Per questo motivo, è consigliabile che i progettisti di rete sviluppino definizioni dei livelli di servizio relative alle prestazioni e alla capacità con l'input del fornitore.
Analogamente agli errori di rete, lo sviluppo di una definizione del livello di servizio per la capacità e le prestazioni inizia con una comprensione generale di come verranno rilevate queste condizioni di problema, chi le esaminerà e cosa accadrà quando si verificheranno. Se necessario, è possibile aggiungere definizioni di eventi specifiche alla definizione del livello di servizio. Per garantire il successo, potrebbe essere necessario eseguire ulteriori operazioni nelle seguenti aree:
-
Una chiara comprensione dei requisiti di prestazioni delle applicazioni
-
Indagine tecnica approfondita sui valori di soglia che hanno un senso per l'organizzazione in base ai requisiti aziendali e ai costi complessivi
-
Requisiti di aggiornamento fuori ciclo e ciclo
-
Responsabilità di supporto di livello 1, 2 e 3
-
Priorità e criticità delle informazioni di gestione della rete bilanciate dalla quantità di lavoro proattivo che il gruppo operativo può gestire in modo efficace
-
Requisiti di formazione per garantire che il personale di supporto comprenda i messaggi o gli avvisi e sia in grado di gestire efficacemente le condizioni definite
-
Metodologie o processi di correlazione degli eventi per garantire che non vengano generati più ticket per lo stesso problema di root cause
-
Documentazione su messaggi o avvisi specifici che facilita l'identificazione degli eventi a livello di supporto di livello 1
Nella tabella seguente viene illustrata una definizione di livello di servizio di esempio per l'utilizzo dei collegamenti che fornisce una chiara comprensione di chi è responsabile degli avvisi proattivi di errore di rete, come verrà identificato il problema e cosa accadrà quando si verifica il problema. Per garantire il successo, l'organizzazione potrebbe aver bisogno di ulteriori sforzi, come sopra definito.
| Area di rete/supporto | Metodo di rilevamento | Soglia | Azione intrapresa |
|---|---|---|---|
| Collegamenti backbone e distribuzione LAN campus | Polling SNMP a intervalli di 5 minuti intercettazioni eccezioni RMON su collegamenti core e di distribuzione | 50% di utilizzo in intervalli di 5 minuti 90% di utilizzo tramite trap eccezione | Notifica tramite posta elettronica a gruppo di alias di posta elettronica prestazioni per valutare i requisiti QoS o pianificare l'aggiornamento per i problemi ricorrenti |
| Collegamenti WAN nazionali | Polling SNMP a intervalli di 5 minuti | 75% di utilizzo in intervalli di 5 minuti | Notifica tramite posta elettronica a gruppo di alias di posta elettronica prestazioni per valutare i requisiti QoS o pianificare l'aggiornamento per i problemi ricorrenti |
| Collegamenti WAN Extranet | Polling SNMP a intervalli di 5 minuti | 60% di utilizzo in intervalli di 5 minuti | Notifica tramite posta elettronica a gruppo di alias di posta elettronica prestazioni per valutare i requisiti QoS o pianificare l'aggiornamento per i problemi ricorrenti |
Nella tabella seguente vengono definite le definizioni dei livelli di servizio per le soglie di capacità e prestazioni dei dispositivi. Garantire la creazione di soglie significative e utili per prevenire problemi di rete o problemi di disponibilità. Si tratta di un'area molto importante perché i problemi relativi alle risorse del control plane del dispositivo non controllati possono avere un grave impatto sulla rete.
| Cisco 7500 | CPU, memoria, buffer | Polling SNMP a intervalli di -5 minuti notifica RMON per la CPU | CPU al 75% durante intervalli di 5 minuti, 99% tramite notifica RMON Memoria al 50% durante intervalli di 5 minuti Buffer al 99% di utilizzo | Notifica via e-mail al gruppo di alias di posta elettronica prestazioni e capacità per risolvere i problemi o pianificare l'aggiornamento della CPU RMON al 99%, posizionare il trouble ticket e cercapersone di supporto livello 2 |
| Cisco 2600 | CPU, memoria | Polling SNMP a intervalli di 5 minuti | CPU al 75% per intervalli di 5 minuti Memoria al 50% per intervalli di 5 minuti | Notifica via e-mail al gruppo di alias di posta elettronica capacità e prestazioni per risolvere i problemi o pianificare l'aggiornamento |
| Catalyst 5000 | Utilizzo backplane, memoria | Polling SNMP a intervalli di 5 minuti | Backplane con il 50% di utilizzo Memoria con il 75% di utilizzo | Notifica via e-mail al gruppo di alias di posta elettronica capacità e prestazioni per risolvere i problemi o pianificare l'aggiornamento |
| LightStream® 1010 ATM switch | CPU, memoria | Polling SNMP a intervalli di 5 minuti | CPU al 65% di utilizzo Memoria al 50% di utilizzo | Notifica via e-mail al gruppo di alias di posta elettronica capacità e prestazioni per risolvere i problemi o pianificare l'aggiornamento |
Nella tabella seguente vengono definite le definizioni dei livelli di servizio per le prestazioni e la capacità end-to-end. Queste soglie sono generalmente basate sui requisiti dell'applicazione, ma possono essere utilizzate anche per indicare alcuni tipi di problemi di prestazioni o capacità della rete. La maggior parte delle organizzazioni con definizioni dei livelli di servizio per le prestazioni crea solo una manciata di definizioni delle prestazioni, in quanto la misurazione delle prestazioni da ogni punto della rete a ogni altro richiede risorse significative e crea un elevato sovraccarico di rete. Questi problemi di prestazioni end-to-end possono essere rilevati anche nelle soglie di capacità del collegamento o del dispositivo. È consigliabile utilizzare definizioni generali per area geografica. Se necessario, è possibile aggiungere alcuni siti o collegamenti critici.
| Area di rete/supporto | Metodo di misurazione | Soglia | Azione intrapresa |
|---|---|---|---|
| LAN campus | Nessuno Nessun problema previsto Difficoltà di misurazione dell'intera infrastruttura LAN | tempo di risposta round-trip di 10 millisecondi o inferiore in qualsiasi momento | Notifica tramite posta elettronica a gruppo di alias di posta elettronica capacità e prestazioni per risolvere il problema o pianificare l'aggiornamento |
| Collegamenti WAN nazionali | Misurazione corrente da SF a NY e SF a Chicago utilizzando solo l'eco ICMP Internet Performance Monitor (IPM) | Tempo di risposta di andata e ritorno di 75 millisecondi in media su un periodo di 5 minuti | Notifica tramite posta elettronica al gruppo di alias di posta elettronica di prestazioni per valutare i requisiti QoS o pianificare l'aggiornamento per i problemi ricorrenti |
| Da San Francisco a Tokyo | Misurazione corrente da San Francisco a Bruxelles utilizzando IPM e ICMP echo | Tempo di risposta di andata e ritorno di 250 millisecondi in media su un periodo di 5 minuti | Notifica tramite posta elettronica al gruppo di alias di posta elettronica di prestazioni per valutare i requisiti QoS o pianificare l'aggiornamento per i problemi ricorrenti |
| San Francisco a Bruxelles | Misurazione corrente da San Francisco a Bruxelles utilizzando IPM e ICMP echo | Tempo di risposta di andata e ritorno di 175 millisecondi in media su un periodo di 5 minuti | Notifica tramite posta elettronica al gruppo di alias di posta elettronica di prestazioni per valutare i requisiti QoS o pianificare l'aggiornamento per i problemi ricorrenti |
L'area finale per la definizione dei livelli di servizio è quella relativa alle prestazioni delle applicazioni. Le definizioni dei livelli di servizio per le prestazioni delle applicazioni vengono in genere create dal gruppo di amministrazione dell'applicazione o del server, in quanto le prestazioni e la capacità dei server stessi rappresentano probabilmente il fattore più importante nelle prestazioni delle applicazioni. Le organizzazioni di rete possono ottenere enormi vantaggi creando definizioni dei livelli di servizio per le prestazioni delle applicazioni di rete, in quanto:
-
le definizioni e la misurazione dei livelli di servizio possono contribuire a eliminare i conflitti tra i gruppi.
-
le definizioni dei livelli di servizio per le singole applicazioni sono importanti se QoS è configurato per le applicazioni chiave e se il traffico di altro tipo è considerato facoltativo.
Se si sceglie di creare e misurare le prestazioni delle applicazioni, è consigliabile non misurare le prestazioni con il server stesso. In questo modo è possibile distinguere tra problemi di rete e problemi di server o applicazioni. Usare le sonde per il software dell'agente di disponibilità del sistema in esecuzione sui router Cisco e l'IPM Cisco che controlla il tipo di pacchetto e la frequenza di misurazione.
Nella tabella seguente viene illustrata una semplice definizione del livello di servizio per le prestazioni delle applicazioni.
| Applicazione | Metodo di misurazione | Soglia | Azione intrapresa |
|---|---|---|---|
| Applicazione Enterprise Resource Planning (ERP) Porta TCP 1529 da Bruxelles a SF | Bruxelles a San Francisco utilizzando la porta di misurazione IPM 1529 round-trip performance Brussels gateway a SFO gateway 2 | Tempo di risposta di andata e ritorno di 175 millisecondi in media su un periodo di 5 minuti | Notifica tramite posta elettronica al gruppo di alias di posta elettronica di prestazioni per valutare il problema o pianificare l'aggiornamento per i problemi ricorrenti |
| Applicazione ERP Porta TCP 1529 Tokyo - SF | Bruxelles a San Francisco utilizzando la porta di misurazione IPM 1529 round-trip performance Brussels gateway a SFO gateway 2 | Tempo di risposta di andata e ritorno di 200 millisecondi in media su un periodo di 5 minuti | Notifica tramite posta elettronica al gruppo di alias di posta elettronica di prestazioni per valutare il problema o pianificare l'aggiornamento per i problemi ricorrenti |
| Applicazione di supporto clienti Porta TCP 1702 Sydney to SF | Sydney a San Francisco utilizzando la porta di misurazione IPM 1702 round-trip performance Sydney gateway to SFO gateway 1 | Tempo di risposta di andata e ritorno di 250 millisecondi in media su un periodo di 5 minuti | Notifica tramite posta elettronica al gruppo di alias di posta elettronica di prestazioni per valutare il problema o pianificare l'aggiornamento per i problemi ricorrenti |
Passaggio 6: Raccolta metriche e monitoraggio
le definizioni dei livelli di servizio non hanno alcun valore se l'organizzazione non raccoglie le metriche e ne controlla il successo. Nella creazione di una definizione di livello di servizio critico, definire come verrà misurato e riportato il livello di servizio. La misurazione del livello di servizio determina se l'organizzazione sta raggiungendo gli obiettivi e identifica anche la causa principale dei problemi di disponibilità o prestazioni. Considerare inoltre l'obiettivo quando si sceglie un metodo per misurare la definizione del livello di servizio. Per ulteriori informazioni, vedere Creazione e gestione degli SLA.
Il monitoraggio dei livelli di servizio implica l'organizzazione di una riunione di revisione periodica, in genere ogni mese, per discutere del servizio periodico. Discutere tutte le metriche e stabilire se sono conformi agli obiettivi. Se non sono conformi, determinare la root cause del problema e implementare i miglioramenti. Dovresti anche coprire le iniziative in corso e i progressi nel miglioramento delle singole situazioni.
Creazione e gestione degli SLA
Le definizioni dei livelli di servizio sono un valido elemento di base in quanto contribuiscono a creare un QoS coerente nell'intera organizzazione e a migliorare la disponibilità. Il passo successivo è rappresentato dagli SLA, che rappresentano un miglioramento in quanto allineano gli obiettivi aziendali e i requisiti di costo direttamente alla qualità del servizio. Il contratto di servizio ben strutturato funge quindi da modello per l'efficienza, la qualità e la sinergia tra la comunità di utenti e il gruppo di supporto, mantenendo processi e procedure chiari per i problemi o le problematiche di rete.
Gli SLA offrono diversi vantaggi:
-
Gli SLA stabiliscono una responsabilità bilaterale per il servizio, il che significa che gli utenti e i gruppi di applicazioni sono anche responsabili del servizio di rete. Se non contribuiscono a creare uno SLA per un servizio specifico e a comunicare l'impatto aziendale con il gruppo di rete, possono essere effettivamente responsabili del problema.
-
Gli SLA consentono di determinare gli strumenti e le risorse standard necessari per soddisfare i requisiti aziendali. Decidere quante persone e quali strumenti utilizzare senza accordi sui livelli di servizio è spesso una proposta di budget. Il servizio potrebbe essere sovraprogettato, con conseguenti spese eccessive o sottoprogettate, con conseguenti obiettivi aziendali non raggiunti. Il tuning degli accordi sui livelli di servizio consente di raggiungere un livello ottimale bilanciato.
-
Lo SLA documentato crea un veicolo più chiaro per definire le aspettative relative ai livelli di servizio.
Per creare gli SLA dopo la creazione delle definizioni dei livelli di servizio, è consigliabile eseguire le operazioni riportate di seguito. Per creare gli SLA dopo la creazione delle definizioni dei livelli di servizio, è consigliabile eseguire le operazioni riportate di seguito.
7. Soddisfare i prerequisiti per gli SLA.
8. Determinare le parti coinvolte nello SLA.
9. Determinare gli elementi del servizio.
10. Comprendere le esigenze e gli obiettivi aziendali del cliente
11. Definire lo SLA richiesto per ciascun gruppo.
12. Scegliere il formato del contratto di servizio
13. Sviluppo di gruppi di lavoro SLA
14. Organizzare riunioni dei gruppi di lavoro e redigere lo SLA.
16. Misurare e monitorare la conformità agli SLA.
Passaggio 7: Soddisfare i prerequisiti per gli SLA
Gli esperti dello sviluppo degli SLA IT hanno identificato tre prerequisiti per il successo degli SLA. Sfortunatamente, le organizzazioni che non raggiungono questi obiettivi possono aspettarsi problemi nel processo SLA e dovrebbero considerare i potenziali problemi legati al processo SLA. Non implementare gli SLA non è dannoso se l'organizzazione di rete può creare definizioni dei livelli di servizio che soddisfino i requisiti aziendali generali. Di seguito sono elencati i prerequisiti per il processo SLA:
-
La vostra azienda deve avere una cultura orientata ai servizi.
L'organizzazione deve innanzitutto soddisfare le esigenze dei clienti. È necessario un impegno prioritario verso l'alto verso il basso per l'assistenza, in modo da comprendere appieno le esigenze e la percezione del cliente. Eseguire sondaggi sulla soddisfazione dei clienti e iniziative di assistenza orientate ai clienti.
Un altro indicatore del servizio potrebbe essere che l'organizzazione definisce la soddisfazione del servizio o del supporto come un obiettivo aziendale. Non è raro che ciò accada perché le organizzazioni IT sono ora fortemente legate al successo complessivo dell'organizzazione.
La cultura dell'assistenza è importante perché il processo SLA consiste fondamentalmente nell'apportare miglioramenti in base alle esigenze del cliente e ai requisiti aziendali. Se le organizzazioni non lo hanno fatto in passato, il processo relativo agli accordi sui livelli di servizio risulterà difficile.
-
Tutte le attività IT devono essere guidate da iniziative di clienti e aziende.
La visione o le missioni aziendali devono essere allineate alle iniziative dei clienti e delle aziende, che a loro volta guidano tutte le attività IT, inclusi gli SLA. Troppo spesso viene creata una rete per soddisfare un determinato obiettivo, ma il gruppo di rete perde di vista tale obiettivo e i successivi requisiti aziendali. In questi casi, alla rete viene assegnato un bilancio prestabilito, che può reagire in modo eccessivo alle esigenze attuali o sottostimare gravemente il fabbisogno, con conseguente fallimento.
Quando le iniziative dei clienti e delle aziende sono allineate con le attività IT, l'organizzazione di rete può essere più facilmente in sintonia con le nuove implementazioni di applicazioni, i nuovi servizi o altri requisiti aziendali. La relazione e l'attenzione generale comune per il raggiungimento degli obiettivi aziendali sono presenti e tutti i gruppi vengono eseguiti come un team.
-
È necessario eseguire il commit al processo e al contratto SLA.
In primo luogo, occorre impegnarsi ad apprendere il processo SLA per sviluppare accordi efficaci. In secondo luogo, è necessario soddisfare i requisiti di servizio indicati nel contratto. Non aspettatevi di creare accordi sui livelli di servizio (SLA) potenti senza un contributo significativo e senza l'impegno di tutti i soggetti coinvolti. Questo impegno deve provenire anche dalla direzione e da tutti i soggetti associati al processo SLA.
Passaggio 8: Determinare le parti coinvolte nello SLA
Gli SLA di rete a livello aziendale dipendono in larga misura da elementi di rete, elementi di amministrazione dei server, supporto dell'help desk, elementi delle applicazioni e requisiti aziendali o degli utenti. Normalmente la gestione di ogni area sarà coinvolta nel processo SLA. Questo scenario è particolarmente utile quando l'organizzazione sta creando accordi sui livelli di servizio (SLA) di supporto reattivo di base. Le organizzazioni con requisiti di maggiore disponibilità possono richiedere assistenza tecnica durante il processo SLA per risolvere problemi quali budget di disponibilità, limiti delle prestazioni, creazione di profili delle applicazioni o capacità di gestione proattiva. Per aspetti più proattivi relativi agli SLA di gestione, si consiglia di rivolgersi a un team tecnico di architetti di rete e di architetti di applicazioni. L'assistenza tecnica può avvicinarsi molto più strettamente alle capacità di disponibilità e di prestazione della rete e a quanto sarebbe necessario per raggiungere obiettivi specifici.
Gli accordi sui livelli di servizio (SLA) per i fornitori di servizi in genere non includono l'input dell'utente in quanto sono stati creati al solo scopo di ottenere un vantaggio competitivo sugli altri fornitori di servizi. In alcuni casi, i dirigenti di livello superiore creano questi SLA a livelli di disponibilità o prestazioni molto elevati per promuovere il servizio e fornire obiettivi interni ai dipendenti interni. Altri fornitori di servizi si concentreranno sugli aspetti tecnici del miglioramento della disponibilità creando definizioni dei livelli di servizio efficaci che siano misurate e gestite internamente. In altri casi, entrambi gli sforzi si verificano contemporaneamente ma non necessariamente insieme o con gli stessi obiettivi.
La scelta delle parti coinvolte nello SLA dovrebbe quindi basarsi sugli obiettivi dello SLA. Alcuni obiettivi possibili sono:
-
Rispetto degli obiettivi aziendali di supporto reattivo
-
Fornire il massimo livello di disponibilità definendo SLA proattivi
-
Promozione o vendita di un servizio
Passaggio 9: Determinazione degli elementi del servizio
Gli SLA di assistenza/supporto principali sono in genere composti da numerosi componenti, tra cui il livello di supporto, il modo in cui verrà misurato, il percorso di riassegnazione degli SLA e i problemi di budget. Gli elementi di servizio per gli ambienti ad alta disponibilità devono includere definizioni di servizio proattive e obiettivi reattivi. Ulteriori informazioni sono:
-
Supporto on site negli orari lavorativi e procedure per il supporto fuori orario
-
Definizioni delle priorità, inclusi il tipo di problema, il tempo massimo per iniziare a lavorare sul problema, il tempo massimo per risolvere il problema e le procedure di escalation
-
Prodotti o servizi da supportare, classificati in ordine di criticità aziendale
-
Supporto per le aspettative in termini di competenze, livelli di prestazioni, creazione di rapporti sullo stato e responsabilità degli utenti per la risoluzione dei problemi
-
Problemi e requisiti a livello di supporto per le unità geografiche o aziendali
-
Metodologia e procedure di gestione dei problemi (sistema di registrazione delle chiamate)
-
Obiettivi dell'help desk
-
Rilevamento errori di rete e risposta del servizio
-
Misurazione della disponibilità della rete e creazione di rapporti
-
Misurazione e reporting della capacità e delle prestazioni della rete
-
Procedure di risoluzione dei conflitti
-
Finanziamento dello SLA implementato
Gli SLA delle applicazioni o dei servizi in rete possono avere esigenze aggiuntive in base ai requisiti dei gruppi di utenti e alla criticità aziendale. L'organizzazione di rete deve prestare particolare attenzione a queste esigenze aziendali e sviluppare soluzioni specializzate che si adattino alla struttura di supporto generale. L'integrazione nella cultura generale del supporto è fondamentale perché è importante non creare un servizio di prima qualità destinato solo ad alcuni individui o gruppi. In molti casi, questi requisiti aggiuntivi possono essere suddivisi in categorie di soluzioni. Ad esempio, una soluzione di platino, oro e argento basata sulle esigenze aziendali. Vedere i seguenti esempi di requisiti SLA per esigenze aziendali specifiche.
Nota: la struttura di supporto, il percorso di escalation, le procedure dell'help desk, la misurazione e le definizioni delle priorità devono rimanere sostanzialmente invariate per mantenere e migliorare una cultura del servizio coerente.
-
Requisiti di larghezza di banda e funzionalità per burst
-
Requisiti di prestazioni
-
Requisiti e definizioni QoS
-
Requisiti di disponibilità e ridondanza per creare una matrice di soluzioni
-
Requisiti, metodologia e procedure di monitoraggio e comunicazione
-
Criteri di aggiornamento per elementi di applicazioni/servizi
-
Requisiti di finanziamento fuori bilancio o metodologia di addebito incrociato
Ad esempio, è possibile creare categorie di soluzioni per la connettività dei siti WAN. La soluzione platinum sarebbe fornita con servizi gemelli T1 al sito. Un vettore diverso fornirebbe ciascuna linea T1. Nel sito saranno configurati due router, in modo che se si verifica un errore in uno dei router o T1, il sito non subirà interruzioni. Il servizio Gold avrebbe avuto due router, ma sarebbe stato utilizzato il Frame Relay di backup. Questa soluzione può avere una larghezza di banda limitata per la durata dell'interruzione. La soluzione Silver avrebbe un solo router e un solo servizio vettore. Ognuna di queste soluzioni sarebbe presa in considerazione per diversi livelli di priorità per i ticket problematici. Alcune organizzazioni possono richiedere una soluzione Platinum o Gold se per un'interruzione è necessario un ticket con priorità 1 o 2. Le organizzazioni dei clienti possono quindi finanziare il livello di servizio richiesto. Nella tabella seguente viene illustrato un esempio di organizzazione che offre tre livelli di servizio, a seconda delle esigenze aziendali relative alla connettività Extranet.
| Soluzione | Platino | Oro | Argento |
|---|---|---|---|
| Dispositivi | Router ridondanti per connettività WAN | Router ridondante per il backup nel sito principale | Nessuna ridondanza del dispositivo |
| WAN | Connettività T1 ridondante, più vettori | Connettività T1 con backup Frame Relay | Nessuna ridondanza WAN |
| Requisiti di larghezza di banda e burst | T1 ridondante con condivisione del carico per burst | Condivisione del carico, backup Frame Relay solo per applicazioni critiche; Solo Frame Relay 64K CIR | FINO A T1 |
| Prestazioni | Tempo di risposta round-trip coerente di 100 ms o inferiore | Tempo di risposta 100 ms o inferiore previsto 99,9% | Tempo di risposta 100 ms o inferiore previsto 99% |
| Requisiti di disponibilità | 99.99% | 99.95% | 99.9% |
| Priorità dell'help desk in caso di inattività | Priorità 1: inattività del servizio business-critical | Priorità 2: interruzione del servizio con impatto sul business | Priorità 3: connettività aziendale non disponibile |
Passaggio 10: Comprendere le esigenze e gli obiettivi aziendali del cliente
Questo passo conferisce allo sviluppatore dello SLA una grande credibilità. Grazie alla comprensione delle esigenze dei vari business group, il documento iniziale SLA sarà molto più vicino ai requisiti aziendali e al risultato desiderato. Cercate di comprendere il costo dei tempi di inattività per il servizio del cliente. Stima in termini di perdita di produttività, ricavi e avviamento del cliente. Ricorda che anche i collegamenti semplici con poche persone possono avere un impatto significativo sui ricavi. In questo caso, è necessario aiutare il cliente a comprendere i rischi di disponibilità e prestazioni che possono verificarsi, in modo che l'organizzazione possa comprendere meglio il livello di servizio necessario. Se non si esegue questa operazione, è possibile che molti clienti richiedano semplicemente una disponibilità del 100%.
Lo sviluppatore SLA deve inoltre comprendere gli obiettivi aziendali e la crescita dell'organizzazione per supportare gli aggiornamenti di rete, il carico di lavoro e la definizione del budget. È inoltre utile comprendere le applicazioni che verranno utilizzate. È auspicabile che l'organizzazione disponga di profili di applicazione per ogni applicazione, ma in caso contrario, è consigliabile valutare l'applicazione dal punto di vista tecnico per determinare i problemi relativi alla rete.
Passaggio 11: Definizione dello SLA richiesto per ciascun gruppo
Gli SLA di supporto principali devono includere business unit critiche e rappresentazioni di gruppi funzionali, quali operazioni di rete, operazioni server e gruppi di supporto delle applicazioni. Questi gruppi dovrebbero essere riconosciuti in base alle esigenze delle imprese e alla loro parte nel processo di assistenza. La presenza di rappresentanti di molti gruppi consente inoltre di creare una soluzione di supporto generale equa senza preferenze o priorità per i singoli gruppi. Ciò può indurre un'organizzazione di supporto a fornire il servizio di assistenza principale a singoli gruppi, uno scenario che potrebbe compromettere la cultura generale del servizio dell'organizzazione. Ad esempio, un cliente potrebbe insistere sul fatto che la sua applicazione è la più importante all'interno dell'azienda quando in realtà il costo del downtime per tale applicazione è significativamente inferiore rispetto ad altri in termini di perdita di ricavi, di produttività e di avviamento del cliente.
Le diverse unità operative all'interno dell'organizzazione avranno requisiti diversi. Uno degli obiettivi dello SLA di rete dovrebbe essere la definizione di un unico formato generale che soddisfi diversi livelli di servizio. Questi requisiti sono generalmente disponibilità, QoS, prestazioni e MTTR. Nell'SLA di rete, queste variabili vengono gestite assegnando priorità alle applicazioni aziendali per il tuning QoS potenziale, definendo le priorità dell'help desk per la MTTR dei diversi problemi che hanno un impatto sulla rete e sviluppando una matrice di soluzioni che consenta di gestire requisiti di disponibilità e prestazioni diversi. Un esempio di semplice matrice di soluzioni per un'azienda di produzione può essere simile alla seguente tabella. È possibile aggiungere informazioni su disponibilità, QoS e prestazioni.
| Unità operativa | Applicazioni | Costo del downtime | Priorità del problema in caso di inattività | Requisiti server/rete |
|---|---|---|---|---|
| Produzione | ERP | Alta | 1 | Massima ridondanza |
| Assistenza clienti | Assistenza clienti | Alta | 1 | Massima ridondanza |
| Progettazione | File server, progettazione ASIC | Media | 2 | Ridondanza core LAN |
| Marketing | File server | Media | 2 | Ridondanza core LAN |
Passaggio 12: Scegliere il formato del contratto di servizio
Il formato dello SLA può variare in base alle esigenze del gruppo o ai requisiti organizzativi. Di seguito è riportato un esempio di struttura consigliata per lo SLA di rete:
-
Scopo dell'accordo
-
Parti che partecipano all'accordo
-
Obiettivi dell'accordo
-
-
Servizi forniti e prodotti supportati
-
Servizio di help desk e monitoraggio delle chiamate
-
Definizioni della gravità del problema in base all'impatto aziendale per le definizioni MTTR
-
Priorità dei servizi business-critical per le definizioni QoS
-
Categorie di soluzioni definite in base ai requisiti di disponibilità e prestazioni
-
Requisiti per la formazione
-
Requisiti di pianificazione della capacità
-
Requisiti di escalation
-
Reporting
-
Soluzioni di rete
-
Nuove richieste di soluzione
-
Prodotti o applicazioni non supportati
-
-
Politiche aziendali
-
Supporto durante l'orario di lavoro
-
Definizioni di supporto fuori orario
-
Copertura ferie
-
Numeri di telefono
-
Previsione del carico di lavoro
-
Risoluzione delle lamentele
-
Criteri di autorizzazione del servizio
-
Responsabilità di protezione di utenti e gruppi
-
-
Procedure di gestione dei problemi
-
Avvio chiamata (utente e automatico)
-
Rapporto tra risposta di primo livello e riparazione delle chiamate
-
Registrazione delle chiamate e conservazione dei record
-
Responsabilità del chiamante
-
Diagnosi dei problemi e requisiti di chiusura delle chiamate
-
Rilevamento dei problemi di gestione della rete e risposta del servizio
-
Categorie o definizioni per la risoluzione dei problemi
-
Gestione dei problemi cronici
-
Gestione chiamate di eccezione/problemi critici
-
-
Obiettivi di qualità del servizio
-
Definizioni di qualità
-
Definizioni di misurazione
-
Obiettivi di qualità
-
Tempo medio per avviare la risoluzione del problema in base alla priorità
-
Tempo medio per la risoluzione del problema in base alla priorità
-
Tempo medio per la sostituzione dell'hardware in base alla priorità del problema
-
Disponibilità e prestazioni della rete
-
Gestione della capacità
-
Gestione della crescita
-
Creazione di rapporti sulla qualità
-
-
Personale e budget
-
Modelli di assegnazione del personale
-
Budget operazioni
-
-
Manutenzione del contratto
-
Pianificazione revisione conformità
-
Report e analisi delle prestazioni
-
Riconciliazione delle metriche dei report
-
Aggiornamenti periodici SLA
-
-
Approvazioni
-
Allegati ed esibizioni
-
Diagrammi di flusso di chiamata
-
Matrice di escalation
-
Matrice di soluzioni di rete
-
Esempi di report
-
Passaggio 13: Sviluppo di gruppi di lavoro SLA
Il passo successivo consiste nell'identificare i partecipanti al gruppo di lavoro SLA, incluso un responsabile del gruppo. Il gruppo di lavoro può includere utenti o responsabili di business unit, gruppi funzionali o rappresentanti di una base geografica. Questi individui comunicano i problemi relativi agli SLA ai rispettivi gruppi di lavoro. I responsabili e i responsabili decisionali che possono concordare gli elementi chiave del contratto di servizio dovrebbero partecipare. Possono includere responsabili e tecnici che possono contribuire a definire i problemi tecnici relativi agli SLA e a prendere decisioni a livello di IT (ad esempio, help desk manager, server operations manager, application manager e network operations manager).
Il gruppo di lavoro sugli SLA di rete dovrebbe inoltre comprendere un'ampia rappresentanza delle applicazioni e delle imprese al fine di ottenere un accordo su un unico SLA di rete che comprenda molte applicazioni e servizi. Il gruppo di lavoro deve essere autorizzato a classificare i processi e i servizi business-critical per la rete, nonché i requisiti di disponibilità e prestazioni per i singoli servizi. Queste informazioni verranno utilizzate per creare priorità per diversi tipi di problemi che hanno un impatto sulle attività aziendali, assegnare priorità al traffico business-critical sulla rete e creare soluzioni di rete standard future basate sui requisiti aziendali.
Passaggio 14: Tenere riunioni di gruppo di lavoro e redigere lo SLA
Il gruppo di lavoro dovrebbe inizialmente creare una carta del gruppo di lavoro. La carta dovrebbe esprimere gli obiettivi, le iniziative e i tempi per l'accordo sui livelli di servizio. Successivamente il gruppo dovrebbe elaborare piani di attività specifici e stabilire calendari per lo sviluppo e l'attuazione dello SLA. Il gruppo dovrebbe inoltre sviluppare il processo di rendicontazione per misurare il livello di sostegno rispetto ai criteri di sostegno. Il passo finale è la creazione della bozza di accordo SLA.
Il gruppo di lavoro sugli SLA di rete dovrebbe riunirsi una volta alla settimana per sviluppare gli SLA. Dopo la creazione e l'approvazione dello SLA, il gruppo può organizzare riunioni mensili o anche trimestrali per gli aggiornamenti dello SLA.
Passaggio 15: Negoziare lo SLA
L'ultimo passo per la creazione dello SLA è la negoziazione finale e la conclusione. Questo passaggio include:
-
Revisione della bozza
-
Negoziazione dei contenuti
-
Modifica e revisione del documento
-
Ottenere l'approvazione finale
Questo ciclo di revisione della bozza, di negoziazione del contenuto e di revisione può richiedere più cicli prima che la versione finale venga inviata alla direzione per l'approvazione.
Dal punto di vista del gestore della rete, è importante negoziare risultati raggiungibili che possano essere misurati. Provare a eseguire il backup degli accordi su prestazioni e disponibilità con quelli di altre organizzazioni correlate. Ciò può includere definizioni di qualità, definizioni di misurazione e obiettivi di qualità. Tenere presente che l'aggiunta di un servizio equivale a una spesa aggiuntiva. Accertarsi che i gruppi di utenti comprendano che livelli di servizio aggiuntivi costeranno di più e lasciare loro la decisione se si tratta di un requisito aziendale critico. È possibile eseguire facilmente un'analisi dei costi su molti aspetti dello SLA, ad esempio i tempi di sostituzione dell'hardware.
Passaggio 16: Misurazione e monitoraggio della conformità agli SLA
La misurazione della conformità agli SLA e la generazione di report sono aspetti importanti del processo SLA che contribuiscono a garantire la coerenza e i risultati a lungo termine. In generale, si consiglia di misurare ogni componente principale di uno SLA e di applicare una metodologia di misurazione prima dell'implementazione dello SLA. Incontri mensili tra utenti e gruppi di supporto per analizzare le misurazioni, identificare le cause principali dei problemi e proporre soluzioni per soddisfare o superare i requisiti dei livelli di servizio. In questo modo il processo SLA risulta simile a qualsiasi programma moderno di miglioramento della qualità.
La sezione seguente fornisce ulteriori dettagli su come la gestione all'interno di un'organizzazione può valutare i propri SLA e la gestione complessiva dei livelli di servizio.
Indicatori delle prestazioni della gestione dei livelli di servizio
Gli indicatori di prestazioni della gestione dei livelli di servizio forniscono un meccanismo per monitorare e migliorare i livelli di servizio come misura di successo. Ciò consente all'organizzazione di reagire più rapidamente ai problemi di assistenza e di comprendere più facilmente i problemi che influiscono sul servizio o sul costo dei tempi di inattività nell'ambiente. La mancata misurazione delle definizioni dei livelli di servizio nega inoltre qualsiasi attività proattiva positiva svolta perché l'organizzazione è costretta a un atteggiamento reattivo. Nessuno chiamerà dicendo che il servizio funziona alla grande, ma molti utenti chiameranno dicendo che il servizio non soddisfa le loro esigenze.
Gli indicatori di prestazione della gestione dei livelli di servizio sono pertanto un requisito fondamentale per la gestione dei livelli di servizio, in quanto forniscono gli strumenti per comprendere appieno i livelli di servizio esistenti e apportare modifiche in base alle problematiche correnti. Su questa base, è possibile fornire un supporto proattivo e migliorare la qualità. Quando l'organizzazione esegue la root cause analysis dei problemi e apporta miglioramenti alla qualità, questa può essere la metodologia migliore per migliorare la disponibilità, le prestazioni e la qualità del servizio disponibile.
Si consideri ad esempio il seguente scenario reale. La società X riceveva numerose lamentele da parte degli utenti, secondo cui la rete era spesso fuori uso per lunghi periodi di tempo. Misurando la disponibilità, l'azienda ha scoperto che il problema principale erano alcuni siti WAN. Un'indagine più attenta di questi punti di vista ha rivelato che la maggior parte dei problemi riguardavano alcuni siti WAN. La causa principale è stata trovata e l'organizzazione ha risolto il problema. L'organizzazione definisce quindi gli obiettivi dei livelli di servizio per la disponibilità e conclude accordi con i gruppi di utenti. Le misurazioni future hanno identificato rapidamente i problemi a causa della non conformità agli SLA. Il gruppo di networking è stato quindi considerato come dotato di maggiore professionalità, competenza e una risorsa generale per l'organizzazione. Il gruppo è passato da un approccio reattivo a uno proattivo, contribuendo così alla redditività dell'azienda.
Purtroppo, la maggior parte delle organizzazioni di rete dispone attualmente di definizioni dei livelli di servizio limitate e di indicatori di prestazioni inesistenti. Di conseguenza, dedicano la maggior parte del loro tempo a reagire ai reclami o ai problemi degli utenti anziché identificare proattivamente la root cause e creare un servizio di rete che soddisfi i requisiti aziendali.
Per determinare il successo del processo di gestione dei livelli di servizio, utilizzare gli indicatori di prestazioni SLA seguenti:
-
Definizione documentata dei livelli di servizio o SLA che include disponibilità, prestazioni, tempi di risposta del servizio reattivi, obiettivi di risoluzione dei problemi e gestione dei livelli di gravità
-
Metriche degli indicatori di prestazioni, inclusi disponibilità, prestazioni, tempi di risposta del servizio per priorità, tempo di risoluzione per priorità e altri parametri misurabili degli SLA
-
Riunioni mensili di gestione dei livelli di servizio per esaminare la conformità ai livelli di servizio e implementare i miglioramenti
Definizione documentata dei livelli di servizio
Il primo indicatore di prestazioni è semplicemente un documento che descrive in dettaglio lo SLA o la definizione del livello di servizio. Gli obiettivi principali della definizione del livello di servizio dovrebbero essere la disponibilità e le prestazioni, in quanto si tratta dei requisiti utente principali.
Gli obiettivi secondari sono importanti in quanto aiutano a definire come verranno raggiunti i livelli di disponibilità o prestazioni. Ad esempio, se l'organizzazione ha obiettivi di disponibilità e prestazioni aggressivi, sarà importante evitare che si verifichino problemi e risolverli rapidamente quando si verificano. Gli obiettivi secondari consentono di definire i processi necessari per raggiungere i livelli di disponibilità e prestazioni desiderati.
Gli obiettivi secondari reattivi includono:
-
Tempo di risposta del servizio reattivo per priorità di chiamata
-
Obiettivi della risoluzione dei problemi o MTTR
-
Procedure di segnalazione dei problemi.
Gli obiettivi secondari proattivi includono:
-
Rilevamento disconnessione dispositivo o collegamento disattivato
-
Rilevamento errori di rete
-
Rilevamento dei problemi di capacità o prestazioni.
La definizione del livello di servizio per gli obiettivi principali, la disponibilità e le prestazioni deve includere:
L'obiettivo
-
Modalità di misurazione dell'obiettivo
-
Parti responsabili della misurazione della disponibilità e delle prestazioni
-
Parti responsabili degli obiettivi di disponibilità e prestazioni
-
Processi di non conformità
Se possibile, si raccomanda di differenziare i responsabili della misurazione e i responsabili dei risultati per evitare un conflitto di interessi. Occasionalmente, potrebbe inoltre essere necessario regolare i numeri di disponibilità a causa di errori di aggiunta/spostamento/modifica, errori non rilevati o problemi di misurazione della disponibilità. La definizione del livello di servizio può inoltre includere un processo di modifica dei risultati per migliorare l'accuratezza ed evitare modifiche non corrette. Per le metodologie di misurazione della disponibilità e delle prestazioni, vedere la sezione successiva.
La definizione del livello di servizio per gli obiettivi secondari reattivi definisce il modo in cui l'organizzazione risponderà ai problemi a livello di rete o IT dopo averli identificati, inclusi:
-
Definizioni priorità problemi
-
Tempo di risposta del servizio reattivo per priorità di chiamata
-
Obiettivi della risoluzione dei problemi, o MTTR
-
Procedure di segnalazione dei problemi
In generale, questi obiettivi definiscono chi sarà responsabile dei problemi in qualsiasi momento e fino a che punto i responsabili dovrebbero abbandonare le loro attuali mansioni per lavorare sui problemi definiti. Analogamente ad altre definizioni dei livelli di servizio, il documento relativo ai livelli di servizio deve descrivere in dettaglio le modalità di misurazione degli obiettivi, le parti responsabili della misurazione e i processi di non conformità.
La definizione del servizio per gli obiettivi secondari proattivi definisce il modo in cui l'organizzazione fornisce il supporto proattivo, inclusa l'identificazione delle condizioni di inattività, disattivazione o arresto dei dispositivi di rete, condizioni di errore di rete e soglie di capacità di rete. Stabilire obiettivi che promuovano la gestione proattiva perché la gestione proattiva di qualità aiuta a eliminare i problemi e a risolverli più rapidamente. A tale scopo, in genere viene impostato un obiettivo per il numero di casi proattivi creati e risolti senza notifica all'utente. Molte organizzazioni impostano un contrassegno nel software dell'help desk per identificare casi proattivi e casi reattivi a tale scopo. Il documento sui livelli di servizio dovrebbe inoltre contenere informazioni su come verrà misurato l'obiettivo, sui responsabili della misurazione e sui processi di non conformità.
Metriche degli indicatori di prestazioni
Si consiglia sempre di misurare qualsiasi obiettivo di livello di servizio definito, in modo da consentire all'organizzazione di misurare i livelli di servizio, identificare la root cause dei problemi di servizio che impediscono l'obiettivo principale di disponibilità e prestazioni e apportare miglioramenti mirati a obiettivi specifici. Nel complesso, le metriche sono semplicemente uno strumento che consente ai responsabili di rete di gestire la coerenza dei livelli di servizio e di apportare miglioramenti in base ai requisiti aziendali.
Sfortunatamente, molte organizzazioni non raccolgono informazioni su disponibilità, prestazioni e altre metriche. Le organizzazioni attribuiscono questo valore all'impossibilità di fornire precisione completa, costi, sovraccarico di rete e risorse disponibili. Questi fattori possono influire sulla capacità di misurare i livelli di servizio, ma l'organizzazione deve concentrarsi sugli obiettivi generali per gestire e migliorare i livelli di servizio. Molte organizzazioni sono state in grado di creare metriche a basso costo e a basso sovraccarico che potrebbero non fornire la precisione completa, ma soddisfare questi obiettivi principali.
La misurazione della disponibilità e delle prestazioni è un'area spesso trascurata nelle metriche dei livelli di servizio. Le organizzazioni che hanno successo con queste metriche utilizzano due metodi piuttosto semplici. Uno dei metodi consiste nell'inviare ai bordi i pacchetti ping ICMP (Internet Control Message Protocol) da una posizione centrale nella rete. Questo metodo consente inoltre di ottenere prestazioni ottimali. Anche le organizzazioni che hanno successo con questo metodo raggruppano i dispositivi simili in "gruppi di disponibilità", come i dispositivi LAN o gli uffici locali. Anche questo aspetto è interessante, in quanto le organizzazioni hanno in genere obiettivi di livello di servizio diversi per aree geografiche o aree business-critical diverse della rete. Questo consente al gruppo di metriche di calcolare la media di tutti i dispositivi con il gruppo di disponibilità per ottenere un risultato ragionevole.
L'altro metodo efficace per calcolare la disponibilità consiste nell'utilizzare i ticket per la risoluzione dei problemi e una misurazione chiamata IUM (Impacted user minutes). Questo metodo visualizza in una tabella il numero di utenti interessati da un'interruzione e lo moltiplica per il numero di minuti dell'interruzione. Se espresso come percentuale dei minuti totali nel periodo di tempo, può essere facilmente convertito in disponibilità. In entrambi i casi, può anche essere utile identificare e misurare la root cause dei tempi di inattività in modo da poter individuare più facilmente i miglioramenti. Le categorie di root cause includono problemi hardware, problemi software, problemi di collegamento o di portante, problemi di alimentazione o di ambiente, errori di modifica ed errori utente.
Gli obiettivi del supporto reattivo misurabili includono:
-
Tempo di risposta del servizio reattivo per priorità di chiamata
-
Obiettivi della risoluzione dei problemi, o MTTR
-
Tempi di segnalazione dei problemi
Misurare gli obiettivi del supporto reattivo generando report dai database dell'help desk, inclusi i seguenti campi:
-
Ora in cui una chiamata è stata inizialmente segnalata (o immessa nel database)
-
Ora in cui la chiamata è stata accettata da un utente che lavora sul problema
-
L'ora in cui il problema è stato segnalato
-
Ora di chiusura del problema
Queste metriche possono richiedere l'influenza della gestione per immettere in modo coerente i problemi nel database e aggiornarli in tempo reale. In alcuni casi, le organizzazioni sono in grado di generare automaticamente ticket per la risoluzione dei problemi per eventi di rete o richieste di posta elettronica. Ciò consente di identificare con precisione l'ora di inizio di un problema. I report generati da questo tipo di metrica ordinano normalmente i problemi in base alla priorità, al gruppo di lavoro e all'utente per determinare i potenziali problemi.
La misurazione dei processi di supporto proattivo è più difficile in quanto richiede il monitoraggio del lavoro proattivo e il calcolo di alcune misurazioni della sua efficacia. Poco lavoro è stato fatto in questo settore. È chiaro, tuttavia, che solo una piccola percentuale di persone segnalerà effettivamente i problemi di rete a un help desk e, quando segnalerà il problema, ci vorrà del tempo per spiegare il problema o isolare il problema come correlato alla rete. Non tutti i casi proattivi avranno un effetto immediato sulla disponibilità e sulle prestazioni a causa di guasti ai dispositivi ridondanti o i collegamenti avranno un impatto minimo sugli utenti finali.
Le organizzazioni che implementano definizioni o accordi proattivi sui livelli di servizio lo fanno a causa dei requisiti aziendali e dei potenziali rischi di disponibilità. La misurazione viene quindi effettuata in termini di quantità o percentuale di casi proattivi, in contrapposizione ai casi reattivi generati dagli utenti. È consigliabile misurare il numero di casi proattivi in ogni area. Queste categorie includono dispositivi inattivi, collegamenti inattivi, errori di rete e violazioni di capacità. È inoltre possibile utilizzare il modello di disponibilità e i casi proattivi per determinare l'effetto della disponibilità ottenuto implementando definizioni proattive dei servizi.
Revisione della gestione dei livelli di servizio
Un'altra misura del successo della gestione dei livelli di servizio è la revisione della gestione dei livelli di servizio. A tale scopo, è necessario che gli accordi sui livelli di servizio siano stati implementati o meno. Esegue l'analisi della gestione dei livelli di servizio in un incontro mensile con i responsabili della misurazione e della fornitura di livelli di servizio definiti. I gruppi di utenti possono essere presenti anche quando sono coinvolti accordi sui livelli di servizio. Lo scopo dell'incontro è quindi quello di esaminare le prestazioni delle definizioni dei livelli di servizio misurati e apportare miglioramenti.
Ogni riunione deve avere un'agenda definita che comprenda:
-
Analisi dei livelli di servizio misurati per il periodo specificato
-
Analisi delle iniziative di miglioramento definite per singole aree
-
Metriche dei livelli di servizio correnti
-
Discussione sui miglioramenti necessari in base all'attuale insieme di metriche.
Nel tempo, l'organizzazione può anche valutare la conformità dei livelli di servizio per determinare l'efficacia del gruppo. Questo processo non è diverso da un cerchio di qualità o da un processo di miglioramento della qualità. L'incontro aiuta a risolvere i singoli problemi e a determinare le soluzioni in base alla root cause.
Riepilogo sulla gestione dei livelli di servizio
In sintesi, la gestione dei livelli di servizio consente alle organizzazioni di passare da un modello di supporto reattivo a un modello di supporto proattivo in cui la disponibilità della rete e i livelli di prestazioni sono determinati dai requisiti aziendali, non dall'ultima serie di problemi. Il processo contribuisce a creare un ambiente in cui i livelli di servizio sono costantemente migliorati e la competitività aziendale è aumentata. La gestione dei livelli di servizio è anche il componente di gestione più importante per la gestione proattiva della rete. Per questo motivo, la gestione dei livelli di servizio è consigliata in tutte le fasi di pianificazione e progettazione della rete e deve iniziare con qualsiasi architettura di rete appena definita. Ciò consente all'organizzazione di implementare le soluzioni in modo corretto la prima volta, riducendo al minimo i tempi di inattività o la rielaborazione.
 Feedback
Feedback